前言
我们在上一篇中讲了 自定义 Git Hook, 那么前端同学有没有对 husky 的工作原理产生好奇呢,为什么 husky 可以让 git 执行他指定目录下的 hooks 目录呢?
我们这一篇文章就带大家通过源码分析一下 husky 的工作原理,同时基于 husky 源码我们拓展讲一下如何使用 Node.js 编写 cli 工具。
之前我简单的看过一遍 husky 的源码,感觉也没什么复杂的东西,这次为了文章时,为了严谨仔细的看了一遍,才发现里面的一些细节还没仔细想过。
husky 工作流程
本来是想将工作原理放到源码解读中一块讲,但写着写着内容有些繁杂,反倒是不好串联起整个流程,所以这里先通过 husky 的安装流程来将主要的工作原理讲解一下。
husky 整个安装主要有以下几步:
- 安装 husky 依赖:
npm install -D husky - 安装 husky 目录:
npx husky install - 添加 npm prepare 钩子:
npm pkg set scripts.prepare="husky install" - 添加 git pre-commit 钩子:
npx husky add .husky/pre-commit "npm run test"
依次执行完这四步,我们就完成了 husky 的安装以及 一个 pre-commit 钩子的创建,我们依次讲解一下。
- 安装
husky依赖这一步相信大家都了解,这里直接略过。 npx husky install命令,是为了在项目中创建一个git hook目录,同时将本地git的hook目录指向项目内的husky目录。- npm 中也有一些生命周期钩子,
prepare就是其中一个,以下是对他的运行时机介绍:- 在
npm publish和npm pack期间运行 - 在本地
npm install时运行 - 在
prepublish和prepublishOnly期间运行
- 在
npx husky add命令用于添加 git hook 脚本, 这个命令中自动添加了文件头及文件可执行权限。
总的来说,当执行 npx husky install 时,会通过一个 git 命令,将 git hook 的目录指向 husky 的目录,由于 git 仓库的设置不会同步到远程仓库,所以 husky 巧妙地通过添加 npm 钩子以保证新拉取的仓库在执行 install 后会自动将 git hook 目录指向 husky 的目录。
源码浅析
husky 的源码非常精简,核心代码只有三个文件:bin.ts,index.ts,husky.sh 我们依次来看。
bin.ts
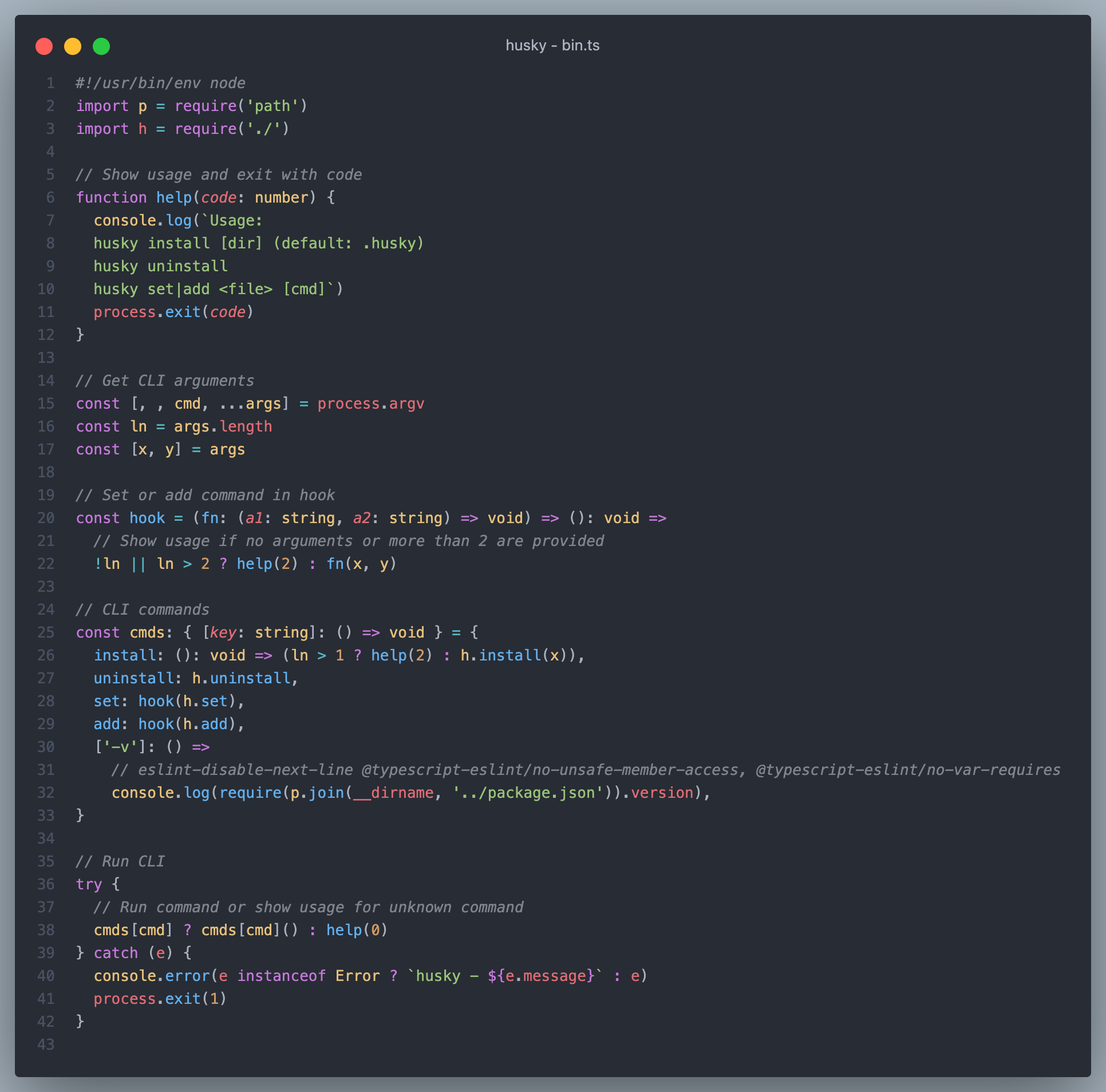
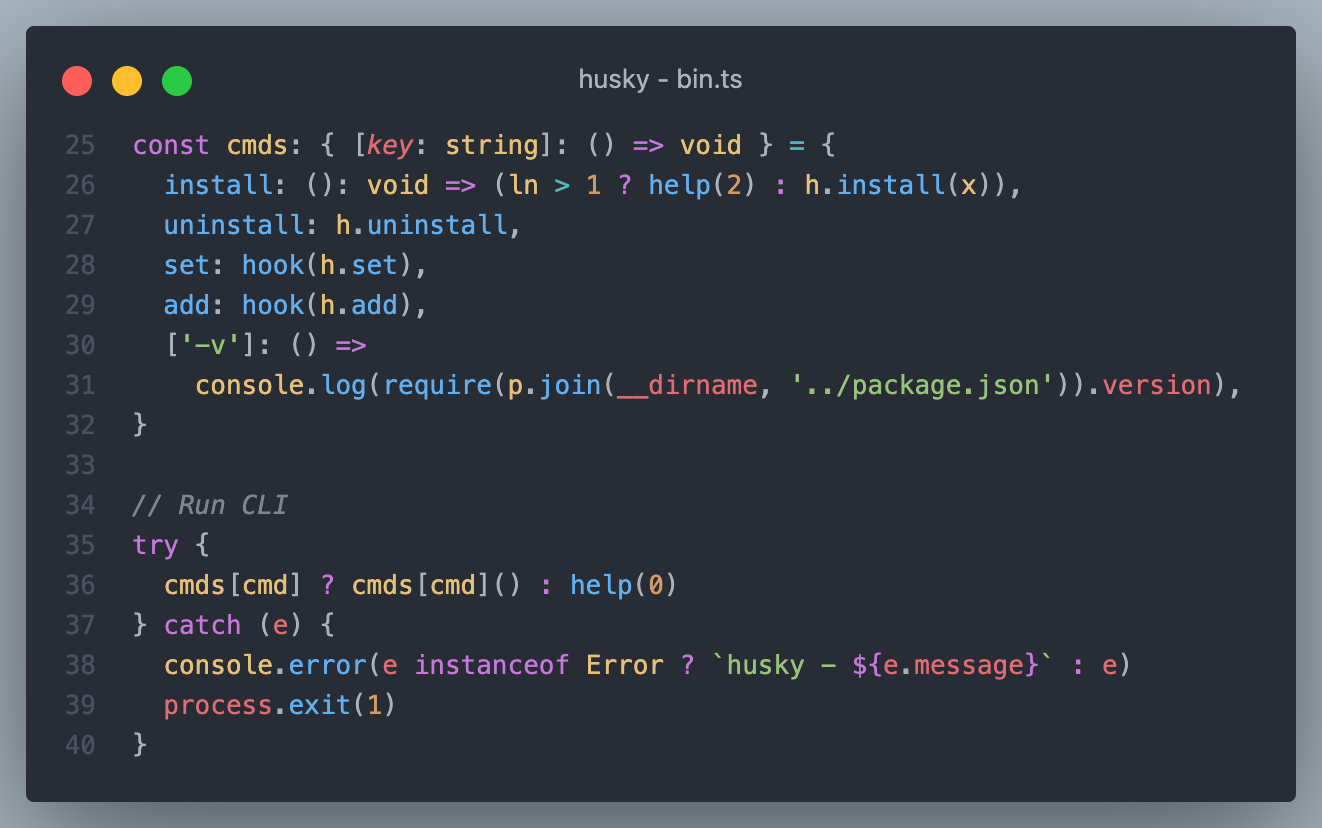
bin.ts 仅仅 43 行代码,内容也非常简单,考虑到没有使用过 Node.js 编写过 cli 工具的同学,我们讲几个知识点。
模块导入语法
import p = require('path')
import h = require('./')
打开 bin.ts 文件,映入眼帘的是这两行导入语句,看了一眼没感觉什么不对,又看了一眼,感觉好像有点怪,不确定,在仔细看了看,啊?import xxx = require('xxx') 这又是什么高级语法,怎么 import 和 require 还能混用呢?究竟是 import 除了轨,还是 require 劈了腿?
由于确信无论是 Node.js 还是 es module 都不支持这种语法,所以推测是 ts 中的语法,果不其然,在 ts 文档中找到相关说明
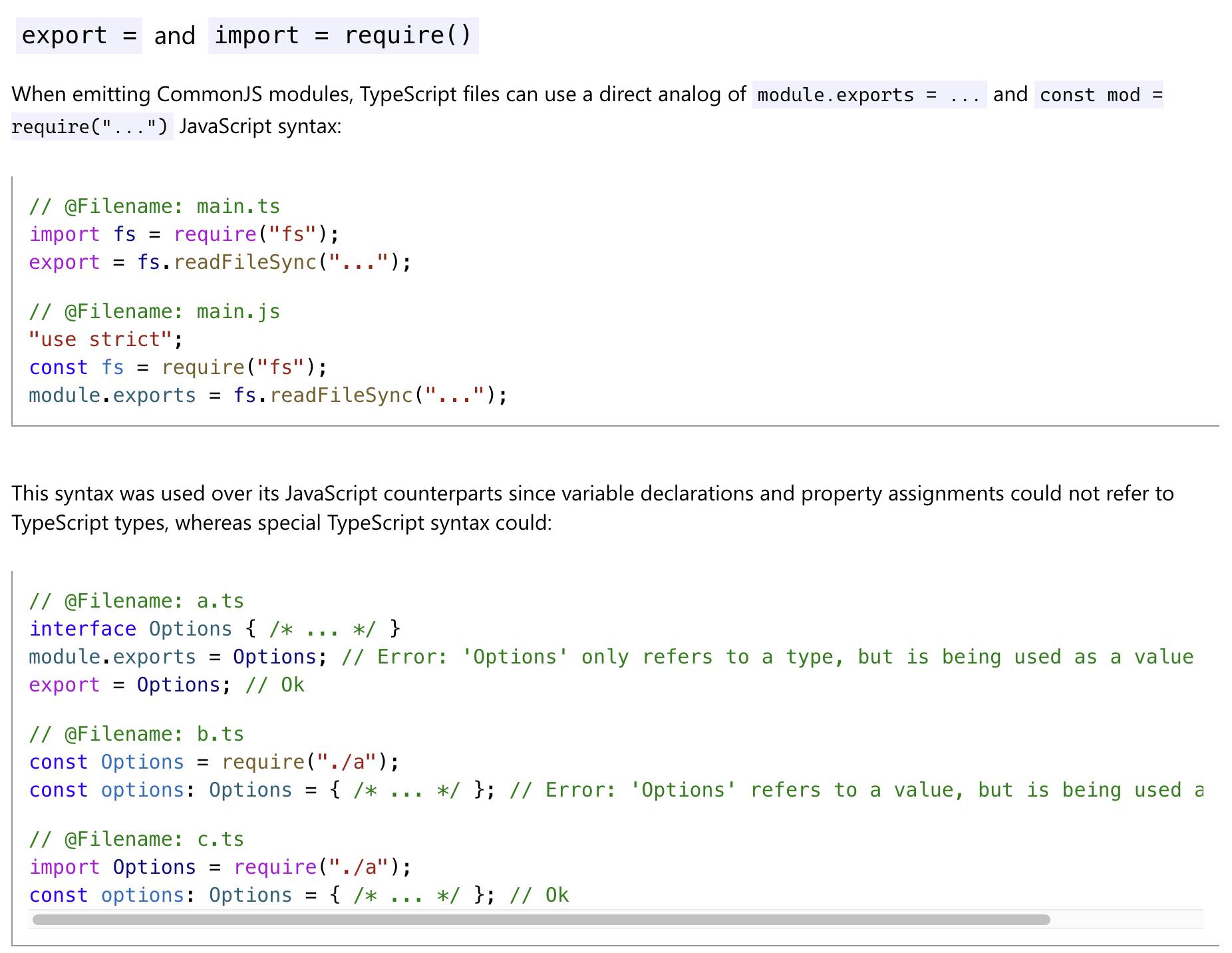
在 TypeScript 中支持 import 和 require 两种导入模块方式。由于 · 语法比较新,如果模块不支持 import,则可以使用 require。
要在 TypeScript 中使用 require,可以编写 import xxx = require('package') 这种语法用于导入 CommonJS 模块 。
npm 中的可执行文件
相信大家一定使用过 npm 安装的 cli 工具,比如 webpack, vite, @vue/cli,create-react-app,eslint 等等,这些工具都有一个特点,便是当全局安装包时,我们可以直接通过命令行调用,如下例:
那么,这些 cli 工具都是怎么做到?
其实很简单,想要实现此功能,只要在 package.json 中配置 bin 字段即可,bin 字段用于指定可执行文件的入口,通过这个属性,可以将脚本或工具作为全局命令行工具安装,并在命令行中直接调用。
bin 字段可以配置一个字符串,或者是一个对象,当配置为对象时,key 是将在全局环境中可用的命令名称,而val是相对于项目根目录中的可执行文件路径,在 husky 中的 bin 配置为 lib/bin.js,直接指定了可执行文件的路径,则它的命令名称为包的名称,即husky:
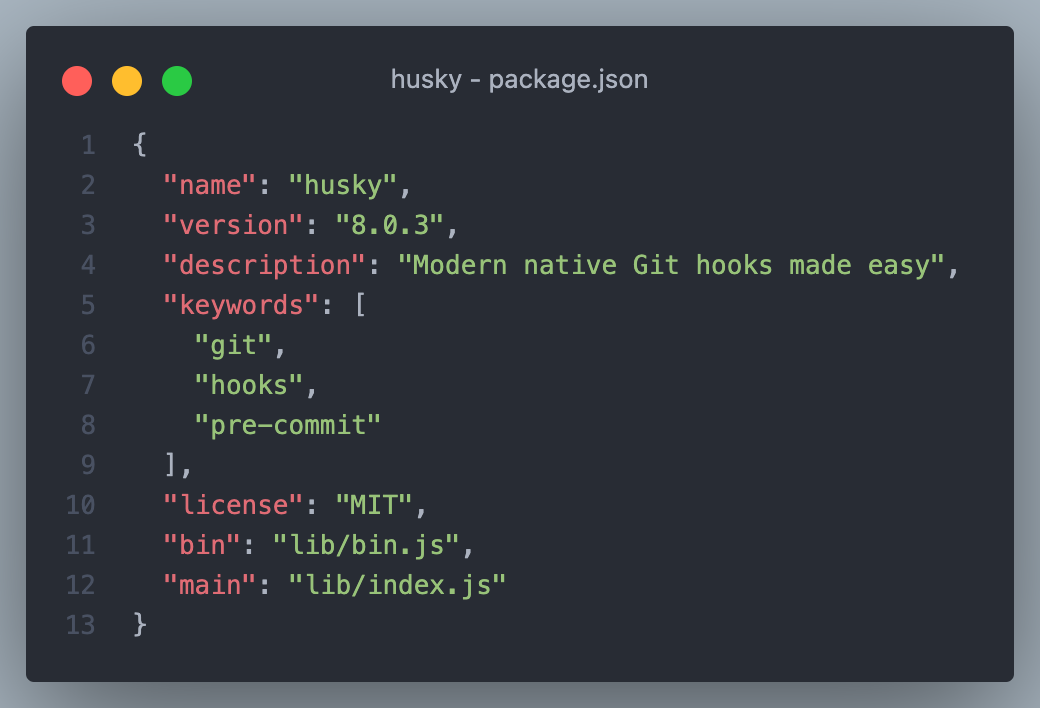
在全局安装该软件包时,会将该文件链接到全局 bins 目录中来执行 bin 字段中指定的文件,因此可以通过名称来运行。当该软件包作为依赖关系安装到另一个软件包时,该文件将被链接到该软件包中,可直接通过 npm exec 执行,或在其他脚本中通过 npm run-script 以名称调用。
获取命令行参数
我们在上面使用 create-react-app 创建项目时,传入了一个 my-react-app 的参数,这才让 cra 知道创建的项目名称叫什么,那我们如何在 Node.js 中获取用户传入的参数呢?
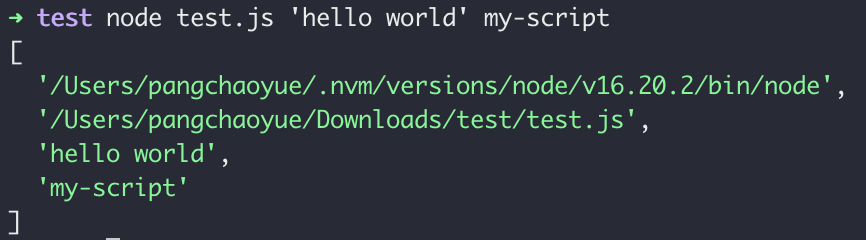
在 Node.js 项目中,我们可以通过 process.argv 获取整个调用时的命令行参数,process.argv 是 Node.js 中的全局变量,它是一个包含命令行参数的数组,这个数组的第一个元素是 Node.js 的可执行文件路径,第二个元素是当前执行的脚本文件路径,后面的元素是传递给脚本的命令行参数。
我们创建一个 test.js 的文件,并在里面添加一行代码:
console.log(process.argv)
我们直接通过 Node.js 调用这个脚本,同时传入两个参数 'hello world' 、my-script,之所以 hello world 加了引号,是因为没有引号的情况下,命令行会根据空格进行拆分成两个参数,如果加了引号才会算是一个参数,如下图输出的下标 2, 3 就是我们传入的参数。
在实际开发中,我们一般通过解构的方式获取用户传入参数,例如在 husky 中通过 const [, , cmd, ...args] = process.argv 获取了用户调用的命令与其他参数,在后面又创建了一个 cmds 的命令映射,在通过 cmds[cmd] 获取需要执行的方法并调用。
index.ts
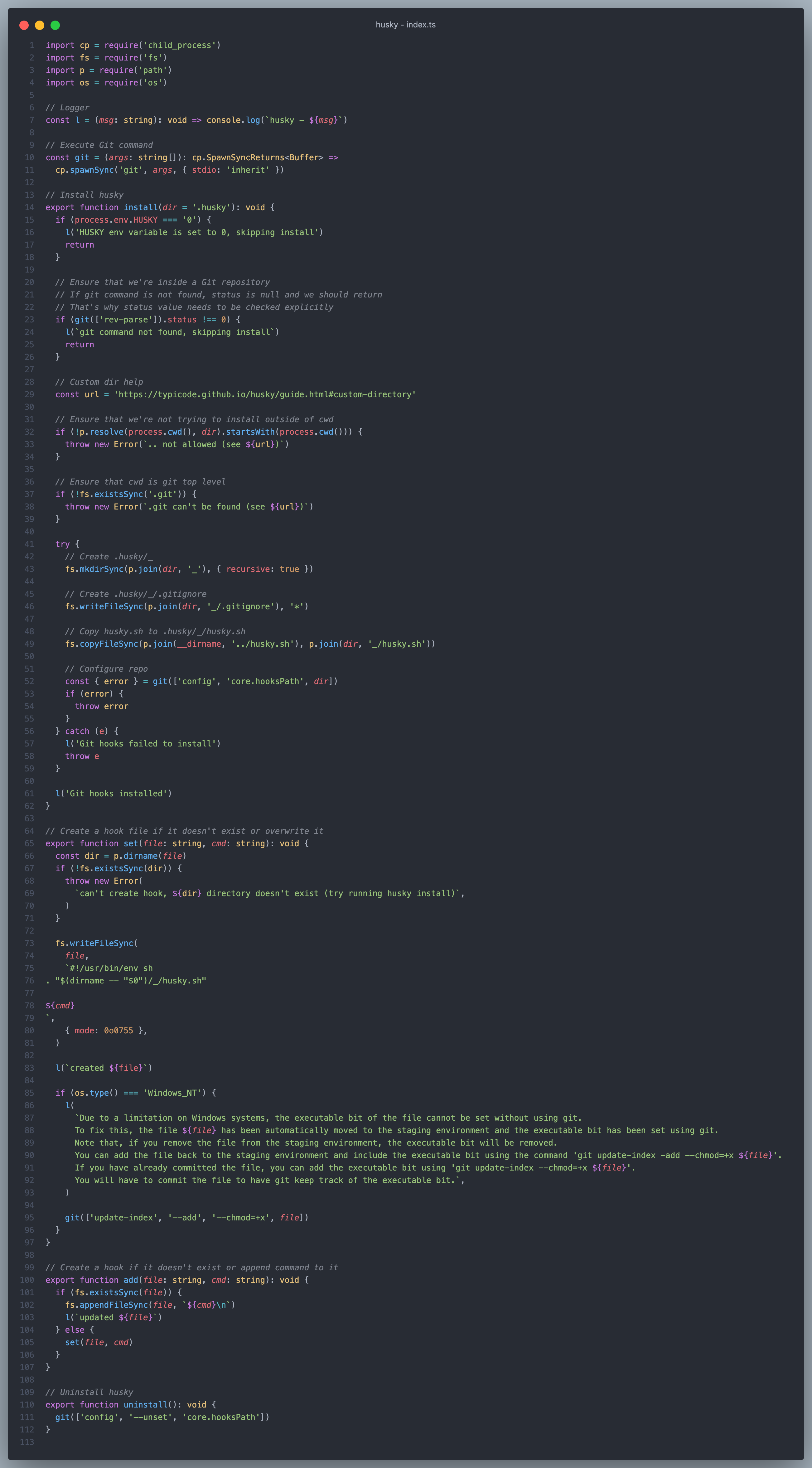
index.ts 是 Husky 的核心逻辑,主要包含了一些用于安装、配置和卸载 Git 钩子的函数。
以下是对主要函数的简要分析:
git函数: 用于执行 Git 命令child_process.spawn是 Node.js 中用于创建子进程的函数之一。它通过派生(spawn)一个新的进程来执行指定的命令。这个方法返回一个可写入的流(ChildProcess对象),该流代表子进程的标准输入、输出和错误。child_process.spawnSync是spawn的同步方法,这里用来同步执行 Git 命令,并获取执行结果。- 该函数接受一个参数
args,这是一个字符串数组,包含要传递给 Git 命令的参数。
install函数: 用于安装 Husky,即设置 Git 钩子以运行 Husky。- 它首先检查环境变量
HUSKY是否被设置为 '0',如果是,则跳过安装。 - 然后,它使用
git rev-parse命令检查当前目录是否在 Git 仓库中,如果不是,则跳过安装。 - 接着,它创建
.husky/_目录和.husky/_/.gitignore文件,并拷贝husky.sh文件到.husky/_/husky.sh。 - 最后,它通过
git config命令配置 Git 仓库的core.hooksPath为指定的目录。
- 它首先检查环境变量
set函数: 创建或覆盖 Git 钩子文件- 它接受两个参数,
file表示要创建或覆盖的文件路径,cmd表示要执行的命令。 - 在创建文件时,它会在文件中写入 Husky 的启动脚本和用户指定的命令,并设置文件的执行权限。
- 它接受两个参数,
add函数: 追加 Git 钩子文件- 如果文件已存在,则追加用户指定的命令,否则,调用
set函数创建新的 Git 钩子文件。
- 如果文件已存在,则追加用户指定的命令,否则,调用
uninstall函数:uninstall函数用于卸载 Husky,即将 Git 仓库的core.hooksPath配置项删除。
husky 的代码逻辑清晰简单,在此就不对各个函数做过多的解释,以下对其中涉及到的一些特殊知识点详细介绍一下。
指定 git hook 目录
在 install 函数中,通过调用 git config core.hooksPath .husky 命令指定 .husky 目录为 hooks
目录。
默认情况下,Git 会在 $GIT_DIR/hooks 目录下查找钩子,如果将其设置为不同的路径,例如 /etc/git/hooks,Git 就会尝试在该目录下查找钩子,例如 /etc/git/hooks/commit-msg。
mode 0o0755
在第 80 行中,写入文件时设置了参数 { mode: 0o0755 },那么这个 mode 及 0o0755 是做什么用的呢?
这个参数实际用于在 Linux 和类 Unix 系统中设置文件权限的选项,表示将文件的权限设置为 0755,这里用于创建 Git 钩子文件并设置文件的权限,0o0755 允许文件的所有者具有读、写和执行权限。这个权限设置用于确保 Husky 的 Git 钩子文件具有足够的权限,以便在执行时被正常调用。
关于 Linux 和类 Unix 系统文件权限,这里不准备展开讲了,准备再开一篇文章详细讲解一下。
window 下可执行文件授权
在第 95 行中,执行了 git update-index --add --chmod=+x file 命令,这是一个 Git 底层命令,--chmod=+x 是通过 Git 为文件添加可执行权限。
在 Windows 系统上,由于文件系统不同,不能像在类Unix系统上那样直接设置文件的执行权限位。因此,为了在 Windows 上模拟文件的可执行权限,通过将文件添加到 Git 的暂存区并使用 git update-index 命令设置文件的执行权限。
想要了解更多关于该问题的介绍,请阅读:windows 下文件授权问题
husky.sh
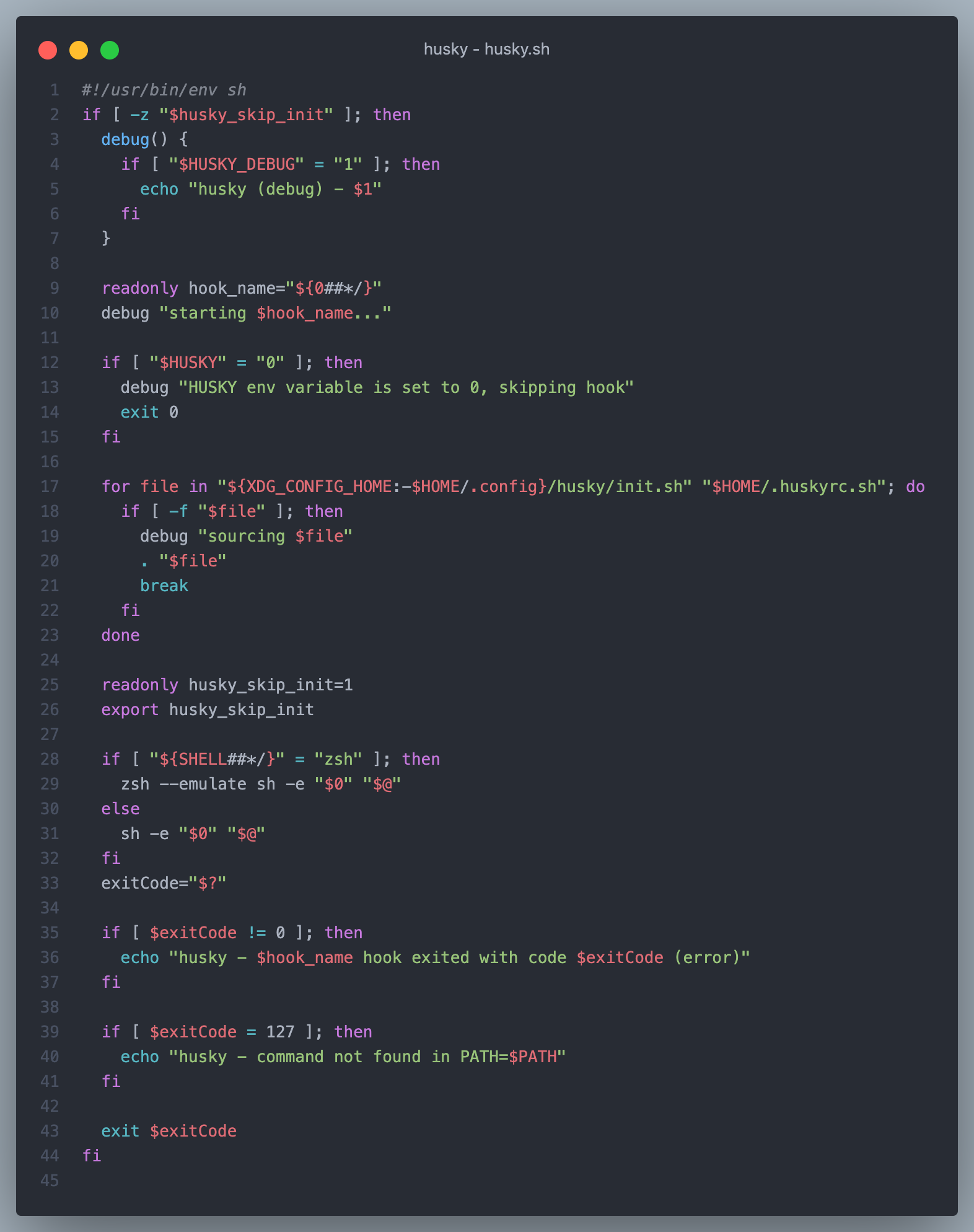
husky.sh 的作用是初始化 git hook 脚本的环境,同时提供了 debug 日志和本地配置的功能。
整个 husky 的源码中,就数这个 shell 脚本中的知识盲区比较多,这也是因为 shell 这块确实没怎么系统的学过,相对比较薄弱。
$
${0##*/} 是一种参数展开的形式,用于获取脚本的名称(去除路径部分)。
$0代表脚本本身的名称。##*/表示从脚本名称中删除所有路径(包括最后一个斜杠/及其之前的部分)。
${0##*/} 的作用是获取脚本名称中的文件名部分,即只保留文件名而去除路径信息。这在脚本中可能用于日志记录、输出信息等场景,以显示纯粹的文件名而不包含路径。
类似的,像脚本中下面的${SHELL##*/} 是获取用户的命令行 shell

XDG_CONFIG_HOME
XDG_CONFIG_HOME 是 XDG 基本目录规范的一部分。它指定了用户特定配置文件应存储的基本目录。如果 XDG_CONFIG_HOME 没有设置或为空,则应使用默认值 $HOME/.config。 XDG_CONFIG_HOME 的位置可以根据 Linux 发行版的不同方式进行定义。例如,在 Debian/Ubuntu 中,可以在 /etc/profile 中定义它,以影响所有用户的系统范围更改,或在 ~/.profile 中定义它,仅影响当前用户。在 Arch Linux 中,它由 /etc/profile 定义,使用 /etc/profile.d 脚本 。
检查当前 Shell 环境类型
在 28-32 行,Husky 在脚本中检查当前 Shell 环境类型,如果是 Zsh 就使用 zsh --emulate sh -e "$0" "$@" 运行脚本,如果不是,则使用 sh -e "$0" "$@" 运行脚本。
这样的选择性执行方式允许在 Windows 上使用类 Unix 的 Shell(例如 Git Bash、WSL)来运行脚本,以确保脚本的可移植性。
--emulate是 Zsh Shell 中的一个选项,用于启用兼容特定 Shell 的模式。在 Husky 脚本中,--emulate sh表示使用 Zsh 以兼容sh的方式来执行脚本。- 在 Shell 中,
-e选项是用于在脚本中遇到任何命令返回非零(失败)退出码时立即退出的选项。 "$0"代表脚本本身的名称,在 husky 中会获取到上层调用husky.sh的脚本名称,如:pre-commit、commit-msg等 git hook 文件名。"$@"表示传递给脚本的所有参数。这个特殊的变量会将所有参数作为一个数组传递,保留参数中的空格和引号。
结语
本来洋洋洒洒写了好几千字,后来通读了一遍感觉零散的知识点太多,反而影响了这篇文章本来的意义,所以又删改了一遍,但总感觉有些地方讲的不清不楚,有点难受。
关于 husky 的实现主要是依赖于 git config core.hooksPath 指定目录 和 npm prepare 钩子,严格来讲,如果不使用 husky 只使用这两个命令也是可以的,区别在于 husky 对跨平台一致性问题做了一些处理,同时避免了一些重复工作。