图形渲染多处理器系统分析(上)
前面已经详细讨论了处理器的设计和实现,以及优化其性能的几种方法,如管线。通过优化处理器和内存系统,可以显著提高程序的性能。问题是,这足够了吗?有没可能做得更好?
简短答案:也许不是。从处理器性能有其局限性开始说起。不可能单独提高处理器的速度,即使是非常复杂的超标量处理器和高度优化的内存系统,通常不可能将IPC增加超过50%。其次,由于功率和温度的考虑,很难将处理器频率提高到3 GHz以上。在过去相当多年中,处理器频率基本保持不变,由此CPU性能的增长也非常缓慢。
下面两图中证明了以上论述。下图显示了英特尔、AMD、Sun、高通和富士通等多家供应商从2001年到2010年发布的处理器的峰值频率。我们观察到,频率或多或少保持不变(大多在1 GHz到2.5 GHz之间),这些趋势表明频率没有逐渐增加。预计在不久的将来,处理器的频率也将限制在3 GHz。

CPU频率。
下图显示了2001年至2010年同一组处理器的Spec Int 2006平均得分。我们观察到,随着时间的推移,CPU性能逐渐饱和,提高性能变得越来越困难。

CPU性能。
尽管单个处理器的性能预计在未来不会显著提高,但计算机架构的未来并不黯淡,因为处理器制造技术正在稳步进步,导致更小更快的晶体管。直到20世纪90年代末,处理器设计者一直在利用晶体管技术的进步,通过实现更多功能来增加处理器的复杂性。然而,由于复杂度和功耗的限制,2005年后,设计师们转而使用更简单的处理器。供应商没有在处理器中实现更多功能,而是决定在单个芯片上安装多个处理器,有助于同时运行多个程序。或者,可以将单个程序拆分为多个部分,并行运行所有部分。
这种使用多个并行运行的计算单元的范例称为多处理(multiprocessing)。多处理是一个相当通用的术语,可以指同一芯片中的多个处理器并行工作,也可以指跨芯片的多个并行处理器。多处理器是一种支持多处理的硬件,当我们在一个芯片中有多个处理器时,每个处理器都被称为一个核心,而这个芯片被称为多核(multicore)处理器。
我们正处于多处理器(multiprocessors)时代,尤其是多核(multicore)系统。每个芯片的核数大约每两年增加两倍,正在编写新的应用程序来利用这些额外的硬件。大多数专家认为计算的未来在于多处理器系统。
在开始设计不同类型的多处理器之前,让我们先来看看多处理器的背景和历史。
1 多处理器背景
在60年代和70年代,大型计算机主要被银行和金融机构使用。他们拥有越来越多的消费者,因此需要能够每秒执行越来越多事务的计算机。通常,只有一个处理器被证明不足以提供所需的计算吞吐量。因此,早期的计算机设计师决定在一台计算机中安装多个处理器。处理器可以共享计算负载,从而增加整个系统的计算吞吐量。
最早的多处理器之一是Burroughs 5000,它有两个处理器:A和B。A是主处理器,B是辅助处理器。当负载很高时,处理器A给处理器B一些工作要做。当时几乎所有其他主要供应商都有多处理器产品,如IBM 370、PDP 11/74、VAX-11/782和Univac 1108-II,这些计算机支持第二个CPU芯片,已连接到主处理器。在所有这些早期机器中,第二个CPU位于第二个芯片上,该芯片通过导线或电缆与第一个CPU物理连接。它们有两种类型:对称和不对称。对称多处理器由多个处理器组成,每个处理器都是相同类型的,并且可以访问操作系统和外围设备提供的服务。非对称多处理器为不同的处理器分配不同的角色,通常有一个独特的处理器来控制操作系统和外围设备,其余的处理器都是从机,它们从主处理器获取工作,并返回结果。
对称多处理器(Symmetric Multiprocessing):此范例将多处理器系统中的所有组成处理器视为相同的,每个处理器都可以平等地访问操作系统和I/O外围设备,也称为SMP系统。
非对称多处理器(Asymmetric Multiprocessing):此范例并不将多处理器系统中的所有组成处理器视为相同的,通常有一个主处理器独占控制操作系统和I/O设备,将工作分配给其他处理器。
早期,第二个处理器使用一组电缆连接到主处理器,通常位于主计算机的不同区域。请注意,在那个年代,电脑曾经有一个房间那么大。随着小型化程度的提高,两个处理器逐渐接近。在80年代末和90年代初,公司开始在同一主板上安装多个处理器。主板是一块印刷电路板,包含计算机使用的所有芯片,带有芯片和金属线的大型绿色电路板是主板。到了90年代末,在一块主板上可以有四到八个处理器,它们通过专用高速总线相互连接。
渐渐地,多核处理器的时代开始了,同一芯片中有多个处理器。2001年,IBM率先推出了名为Power 4的双核(2核)多核处理器,2005年,英特尔和AMD也推出了类似产品。截至2022年,有16、32、64甚至更多核心的多核处理器可供选择。
现在更深入地了解一下1960年至2012年间处理器世界发生了什么。在六十年代,一台电脑通常只有一个房间那么大,而今,口袋里装着一台电脑。在60年代早期,手机中的处理器比IBM 360机器快约160万倍,它的功率效率也提高了几个数量级。计算机技术持续发展的主要驱动因素是晶体管的小型化,晶体管在六十年代曾经有几毫米的沟道长度,现在大约有20-30纳米长。1971年,一个典型的芯片曾经有2000-3000个晶体管,如今的一个芯片有数十亿个晶体管。
在过去的四十到五十年中,每个芯片的晶体管数量大约每1-2年翻一番。事实上,英特尔的联合创始人戈登·摩尔(Gordon Moore)在1965年就预测到了这一趋势。摩尔定律预测,芯片上的晶体管数量预计每一到两年就会翻一番。最初,摩尔曾预测每年翻倍的时间,随着时间的推移,这段时间已经变成了大约2年。由于制造技术、新材料和制造技术的稳步发展,这种情况预计会发生。
摩尔定律自20世纪60年代中期提出以来,几乎一直成立。如今,几乎每两年,晶体管的尺寸就会缩小√22倍,确保了晶体管的面积缩小一倍,从而可以使芯片上的晶体管数量增加一倍。让我们将特征尺寸(feature size)定义为可以在芯片上制造的最小结构的尺寸。下表显示了过去10年英特尔处理器的功能大小,我们观察到特征大小每两年大约减少√22(1.41)倍,导致晶体管数量加倍。
|
年份 |
特征尺寸 |
|
2001 |
130 nm |
|
2003 |
90 nm |
|
2005 |
65 nm |
|
2007 |
45 nm |
|
2009 |
32 nm |
|
2011 |
22 nm |
请注意,摩尔定律是一个经验定律。然而,由于它在过去四十年中正确预测了趋势,因此在技术文献中被广泛引用。它直接预测了晶体管尺寸的小型化,更小的晶体管更省电、更快。传统上,设计师们利用这些优势来设计具有额外晶体管的更大处理器,他们使用额外的晶体管预算来增加不同单元的复杂性,增加缓存大小,增加问题宽度和功能单元的数量。其次,管线阶段的数量也在稳步增加,直到2002年左右,时钟频率也随之增加。然而,2002年之后,计算机架构的世界发生了根本性的变化。突然间,电力和温度成了主要问题。处理器功耗曲线开始超过100瓦,芯片温度开始超过100摄氏度,这些限制显著地结束了处理器复杂性和时钟频率的扩展。
相反,设计师开始在不改变其基本设计的情况下,为每个芯片封装更多的内核,确保了每个核的晶体管数量保持不变。根据摩尔定律,核的数量每两年翻一番,开启了多核处理器的时代,处理器供应商开始将芯片上的核数量增加一倍。在未来不久,每个芯片的核数预计普遍达到64、128个甚至更多。
除了常规的多核处理器,还有另一个重要的发展。除了每个芯片有4个大内核,还有一些架构在芯片上有64-256个非常小的内核,例如图形处理器。这些处理器也遵循摩尔定律,每2年将其内核翻倍,被越来越多地用于计算机图形学、数值计算和科学计算。也可以拆分处理器的资源,使其支持两个程序计数器,并同时运行两个程序,这些特殊类型的处理器被称为多线程处理器。
本章让读者了解多处理器设计的广泛趋势,首先从软件的角度来看多处理,一旦确定了软件需求,将着手设计支持多处理的硬件,将广泛考虑多核、多线程和矢量处理器。
2 多处理器系统软件
2.1 强和松散耦合多处理
松散耦合多处理(Loosely Coupled Multiprocessing)是在多处理器上并行运行多个不相关的程序。
强耦合多处理(Strongly Coupled Multiprocessing)是在多处理器上并行运行一组共享内存空间、数据、代码、文件和网络连接的程序。
本文将主要研究强耦合多处理,并主要关注通过共享大量数据和代码来允许一组程序协同运行的系统。
2.2 共享内存与消息传递
计算机架构师按照不同的模式为多处理器设计了一套协议。第一个范例被称为共享内存,所有单独的程序都看到内存系统的相同视图,如果程序A将x的值更改为5,则程序B立即看到更改。第二种设置称为消息传递,多个程序通过传递消息相互通信。共享内存范例更适合强耦合多处理器,消息传递范例更适合松散耦合多处理器。请注意,可以在强耦合多处理器上实现消息传递。同样,也可以在松散耦合的多处理器上实现共享内存的抽象,被称为分布式共享内存(distributed shared memory),但通常不是常态。
共享内存
让我们尝试使用多处理器并行添加n个数字,它的代码如下所示,使用OpenMP语言扩展用C++编写了代码。假设所有的数字都已经存储在一个称为numbers.的数组中,数组编号有SIZE个条目,假设可以启动的并行子程序的数量等于N。
/* 变量声明 */
int partialSums[N];
int numbers[SIZE];
int result = 0;
/* 初始化数组 */
(...)
/* 并行代码 */
#pragma omp parallel
{
/* get my processor id */
int myId = omp_get_thread_num();
/* add my portion of numbers */
int startIdx = myId * SIZE/N;
int endIdx = startIdx + SIZE/N;
for(int jdx = startIdx; jdx < endIdx; jdx++)
partialSums[myId] += numbers[jdx];
}
/* 顺序代码 */
for(int idx=0; idx < N; idx++)
result += partialSums[idx];
除了指令#pragma omp parallel之外,很容易将代码误认为是常规顺序程序,这是在并行程序中添加的唯一额外语义差异,它将此循环的每个迭代作为单独的子程序启动,每个这样的子程序都被称为线程。线程通过修改共享内存空间中内存位置的值与它们通信,每个线程都有自己的一组局部变量,其他线程无法访问这些变量。
迭代次数或启动的并行线程数是预先设置的系统参数,通常等于处理器的数量,上述代码中等于N。因此,并行启动代码的并行部分的N个副本,每个副本在单独的处理器上运行。请注意,程序的每个副本都可以访问在调用并行部分之前声明的所有变量,例如,可以访问partialSums和numbers数组。每个处理器都调用函数omp_get_thread_num,该函数返回线程的id。每个线程都使用线程id来查找需要添加的数组范围,在数组的相关部分中添加所有条目,并将结果保存在partialSums数组中相应的条目中。一旦所有线程都完成了它们的工作,顺序部分就开始了,这段顺序代码可以在任何处理器上运行,是由操作系统或并行编程框架在运行时动态做出的。为了得到最终结果,必须将顺序部分中的所有部分和相加。
计算的图形表示如下图所示。父线程生成一组子线程,做各自的工作,完成后最终连接,父线程接管并聚合并行结果。此例也是Fork-Join范例的一个具体示例。
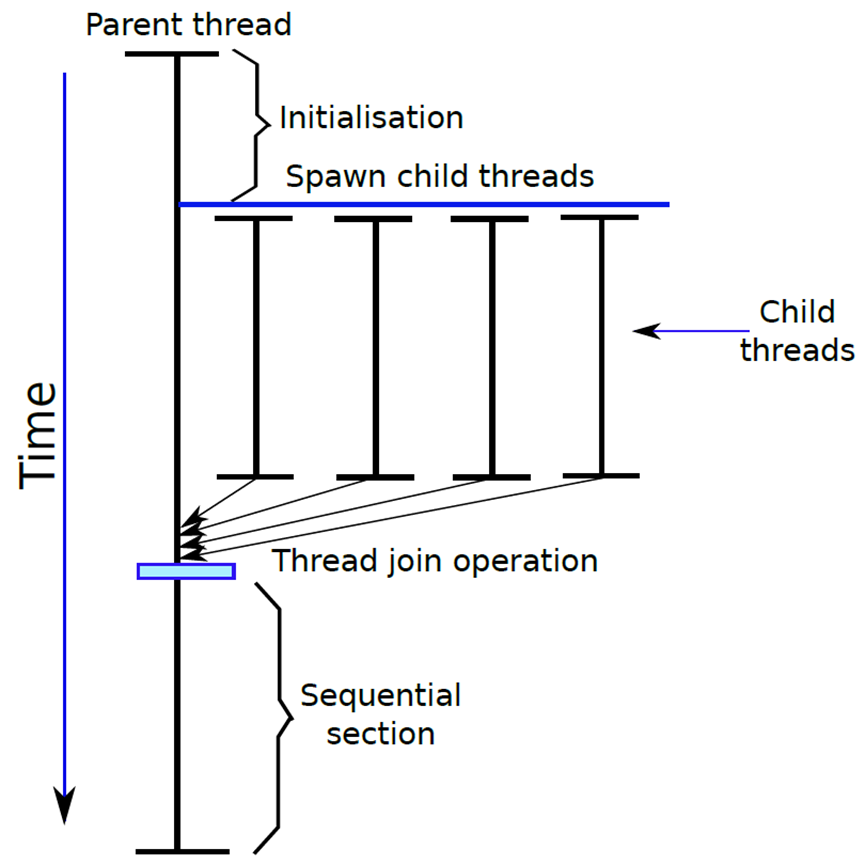
并行加法程序的图形表示。
有几个要点需要注意。每个线程都有自己的堆栈,可以使用其堆栈声明其局部变量。一旦完成,堆栈中的所有局部变量都将被销毁。要在父线程和子线程之间传递数据,必须使用两个线程都可以访问的变量,所有线程都需要全局访问这些变量,子线程可以自由地修改这些变量,甚至可以使用它们相互通信。此外,它们还可以自由调用操作系统,并写入外部文件和网络设备。一旦所有线程完成执行,它们就执行一个联接操作,并释放它们的状态,父线程接管并完成聚合结果的角色。join是线程之间同步操作的一个示例,线程之间可以有许多其他类型的同步操作。有一组复杂的结构,线程可以用来协同执行非常复杂的任务,添加一组数字是一个非常简单的例子。多线程程序可以用于执行其他复杂任务,如矩阵代数,甚至可以并行求解微分方程。
消息传统
接下来简单地看看消息传递,只给读者一个消息传递程序的概况,在这种情况下,每个程序都是一个单独的实体,不与其他程序共享代码或数据。它是一个进程,其中进程被定义为程序的运行实例,通常不与任何其他进程共享其地址空间。
现在快速定义消息传递语义,主要使用两个函数:send和receive,如下表所示。send(pid, val)函数用于向id等于pid的进程发送整数(val),receive(pid)用于接收id等于pid的进程发送的整数。如果pid等于ANYSOURCE,那么接收函数可以返回任何进程发送的值。我们的语义基于流行的并行编程框架MPI(消息传递接口),MPI调用有更多的参数,语法相对复杂。
|
函数 |
语意 |
|
send(pid, val) |
将整数val发送给id等于pid的进程。 |
|
receive(pid) |
1、 从进程pid接收整数。 |
现在考虑以下示例并行添加n个数字的相同示例。假设所有的数字都存储在numbers数组中,并且这个数组可用于所有N个处理器,numbers元素数为SIZE。为了简单起见,假设SIZE可被N整除。
/* start all the parallel processes */
SpawnAllParallelProcesses();
/* For each process execute the following code */
int myId = getMyProcessId();
/* 计算部分和 */
int startIdx = myId * SIZE/N;
int endIdx = startIdx + SIZE/N;
int partialSum = 0;
for(int jdx = startIdx; jdx < endIdx; jdx++)
partialSum += numbers[jdx];
/* 所有非根节点将其部分和发送到根 */
if(myId != 0)
{
send (0, partialSum);
}
else
{
/* 处理根节点 */
int sum = partialSum;
for (int pid = 1; pid < N; pid++)
{
sum += receive(ANYSOURCE);
}
/* 关闭所有进程 */
shutDownAllProcesses();
return sum;
}
3 多处理器的设计空间
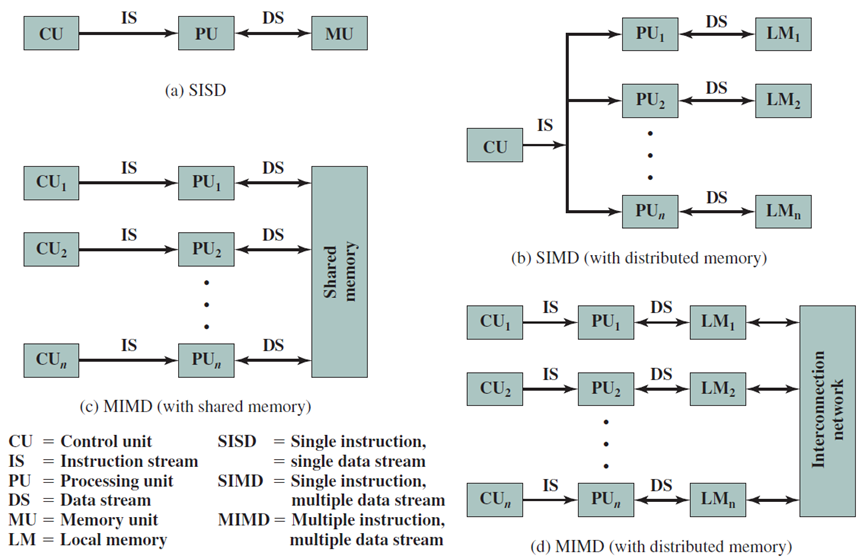
迈克尔·弗林(Michael J.Flynn)在1966年提出了著名的弗林对多处理器的分类,他从观察到不同处理器的集成可能共享代码、数据或两者兼而有之开始。有四种可能的选择:SISD(单指令单数据)、SIMD(单指令多数据)、MISD(多指令单数据)和MIMD(多指令多数据),下面描述这些类型的多处理器:
- SISD:是一个标准的单处理器,具有单个流水线。SISD处理器可以被看作是一组只有单个处理器的多处理器的特例。
- SIMD:SIMD处理器可以在一条指令中处理多个数据流,例如SIMD指令可以用一条指令将4组数字相加。现代处理器将SIMD指令纳入其指令集,并具有特殊的SIMD执行单元,例如包含SIMD指令集的SSE集的x86处理器。图形处理器和矢量处理器是高度成功的SIMD处理器的特殊例子。

多线程SIMD处理器数据路径的简化框图。。
- MISD:MISD系统在实践中非常罕见,主要用于可靠性要求非常高的系统中。例如,大型商用飞机通常有多个处理器运行同一程序的不同版本,最终结果由表决(voting)决定。例如,一架飞机可能有一个MIPS处理器、一个ARM处理器和一个x86处理器,每个处理器都运行着相同程序的不同版本,如自动驾驶系统,它们有多个指令流,但只有一个数据源。专用投票电路(dedicated voting circuit)计算三个输出的多数投票。例如,由于程序或处理器中的错误,其中一个系统可能错误地决定左转,而其他两个系统都可能做出正确的右转决定,在这种情况下,投票电路将决定右转。由于MISD系统几乎从未在实践中使用过,除了特殊的例子,本文不再讨论它们。
- MIMD:MIMD系统是目前最流行的多处理器系统,它们有多个指令流和多个数据流,多核处理器和大型服务器都是MIMD系统。多个指令流意味着指令来自多个来源,每个源都有其唯一的位置和相关的程序计数器。MIMD范式的两个重要分支在过去几年中形成。
第一个是SPMD(单程序多数据),第二个是MPMD(多程序多数据),大多数并行程序以SPMD风格编写。同一程序的多个副本在不同的内核或独立的处理器上运行,然而,每个单独的处理单元都有单独的程序计数器,因此可以感知不同的指令流。有时,SPMD程序的编写方式会根据线程ID执行不同的操作,SPMD的优点是我们不必为不同的处理器编写不同的程序。同一程序的部分可以在所有处理器上运行,尽管它们的行为可能不同。
一个对比的范例是MPMD,在不同处理器上运行的程序实际上是不同的,它们对于具有异构处理单元的专用处理器更有用。通常只有一个主程序将工作分配给从程序,从属程序完成分配给它们的工作量,然后将结果返回给主程序。这两个程序的工作性质实际上非常不同,通常不可能将它们无缝地组合到一个程序中。
在MIMD组织中,处理器是通用的,每个处理器都能够处理执行适当数据转换所需的所有指令。MIMD可以通过处理器通信的方式进一步细分(下图)。

如果处理器共享一个公共存储器,则每个处理器访问存储在共享内存中的程序和数据,处理器通过该内存相互通信,这种系统最常见的形式是对称多处理器(SMP)。在SMP中,多个处理器通过共享总线或其他互连机制共享单个内存或内存池,区别特征在于,对于每个处理器,对任何内存区域的内存访问时间大致相同。前些年的一个发展是非均匀内存访问(NUMA)组织,如下图所述。顾名思义,NUMA处理器对不同内存区域的内存访问时间可能不同。
从上面的描述可以清楚地看出,我们需要关注的系统是SIMD和MIMD。由于MISD系统很少使用,不再讨论,下面首先讨论MIMD多处理,注意只描述MIMD多处理的SPMD变体,因为SPMD是最常见的方法。
4 MIMD多处理器
现在让我们更深入地研究基于强耦合共享内存的MIMD机器,首先从软件的角度来看它们,从软件的角度制定了这些机器的广泛规格之后,可以继续对硬件的设计进行简要概述。请注意,并行MIMD机器的设计可能需要一整本书来描述。
将共享内存MIMD机器的软件接口称为逻辑角度(logical point of view),并将多处理器的实际物理设计称为物理角度(physical point of view)。当描述逻辑角度时,主要关心的是多处理器相对于软件的行为,硬件对其行为有什么保证,软件可以期待什么,包括正确性、性能,甚至是故障恢复能力。物理角度与多处理器的实际设计有关,包括处理器、存储系统和互连网络的物理设计。请注意,物理角度必须符合逻辑角度。此处采用了与单处理器类似的方法,首先通过查看汇编代码来解释软件视图(架构),然后通过描述流水线处理器(组织)为汇编代码提供了一个实现。
4.1 逻辑视角
下图显示了共享内存MIMD多处理器的逻辑视图。每个处理器都连接到存储代码和数据的内存系统,其程序计数器指向它正在执行的指令的位置,即在内存的代码段,此段通常是只读的,因此不受我们有多处理器这一事实的影响。
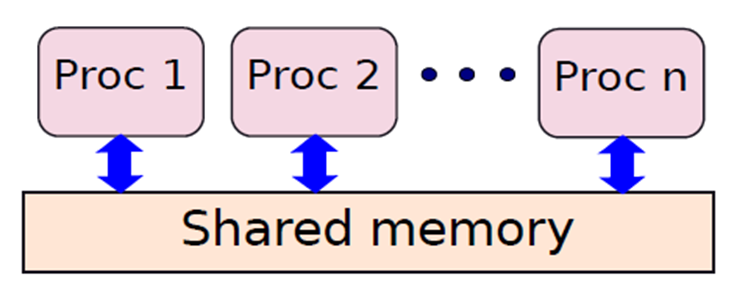
多处理器系统的逻辑视图。
实现共享内存多处理器的主要挑战是正确处理数据访问。上图显示了一种方案,其中每个计算处理器都连接到内存,并将其视为一个黑盒。如果考虑具有不同虚拟地址空间的进程系统,就没有问题。每个处理器都可以处理其数据的私有副本,由于内存占用实际上是不相交的,可以很容易地在这个系统中运行一组并行进程。然而,当研究具有多个线程的共享内存程序,并且存在跨线程的数据共享时,主要的复杂性就出现了。请注意,我们还可以通过将不同的虚拟页面映射到同一物理帧来跨进程共享内存,把这种情况视为并行多线程软件的一种特殊情况。
一组并行线程通常共享其虚拟和物理地址空间,但线程也有私有数据,这些数据保存在它们的堆栈中。有两种方法可以实现不相交的堆栈。第一,所有线程都可以有相同的虚拟地址空间,不同的堆栈指针可以从虚拟地址空间中的不同点开始,需要进一步确保线程堆栈的大小不足以与另一个线程的堆栈重叠。另一种方法是将不同线程的虚拟地址空间的堆栈部分映射到不同的内存帧,每个线程可以在其页面表中为堆栈部分有不同的条目,但对于虚拟地址空间的其余部分(如代码、只读数据、常量和堆变量)有共同的条目。
在任何情况下,并行软件复杂性的主要问题都不是因为代码是只读的,也不是因为线程之间不共享的局部变量,主要问题是由于数据值可能在多个线程之间共享。这就是并行程序的强大之处,也使它们变得非常复杂。在前面展示的并行添加一组数字的示例中,我们可以清楚地看到通过共享内存共享值和计算结果所获得的优势。
然而,跨线程共享值并不是那么简单,是一个相当深刻的话题,本文简要地看一下其中的两个重要主题,即连贯性(coherence)和内存一致性(memory consistency)。当在缓存上下文中提到一致性时,一致性也称为缓存一致性。然而,一致性不仅仅限于缓存,它是一个通用术语。
一致性
内存系统中的一致性是指多个线程访问同一位置的方式。当多个线程访问同一内存位置时,许多不同的行为都是可能的,有些行为直觉上是错误的,但也有可能。在研究一致性之前,需要注意,在内存系统中,有许多不同的实体,如缓存、写入缓冲区和不同类型的临时缓冲区。处理器通常将值写入临时缓冲区,然后恢复其操作。内存系统的工作是将数据从这些缓冲区传输到缓存子系统中的某个位置。因此,在内部,给定的内存地址可能在给定的时间点与许多不同的物理位置相关联。其次,将数据从处理器传输到存储器系统中的正确位置(通常是缓存块)的过程不是瞬时的,内存读取或写入请求有时需要超过几十个周期才能到达其位置。如果内存流量很大,这些内存请求消息可能会等待更长时间,消息也可以与之后发送的其他消息重新排序。
让我们假设内存对于所有处理器来说都像一个大的字节数组,尽管在内部,它是一个由不同组件组成的复杂网络,这些组件努力为读/写操作提供简单的逻辑抽象。多处理器内存系统的内部复杂性导致了访问同一组共享变量的程序的几种有趣行为。
让我们考虑一组示例。在每个示例中,所有共享值都被初始化为0,所有局部变量都以t开头,如t1、t2和t3。假设线程1写入跨线程共享的变量x,紧接着,线程2尝试读取其值。
// Thread 1:
x = 1
// Thread 2:
t1 = x
线程2是否保证读取1?或者,它可以得到以前的值0吗?如果线程2在2 ns甚至10 ns后读取x的值,该怎么办?一个线程中的写入传播到其他线程所需的时间是多少?这些问题的答案取决于内存系统的实现。如果内存系统有快速总线和快速缓存,那么写操作可以很快地传播到其他线程。但是,如果总线和缓存很慢,那么其他线程可能需要更多时间才能看到对共享变量的写入。
现在,把这个例子进一步复杂化,假设线程1写入x两次:
// Thread 1:
x = 1
x = 2
// Thread 2:
t1 = x
t2 = x
现在让我们看看一系列可能的结果:(t1,t2)=(1,2)、(t1,t2) = (0,1)都是可能的,当t1在线程1启动之前写入,而t2在线程1的rst语句完成之后写入时,这是可能的。同样,可以系统地列举所有可能结果的集合,这些结果是:(0,0)、(0,1)、(0,2)、(1,1)、(1,2)和(2,2)。有趣的问题是,结果(2,1)是否可能?如果对x的第一次写入在内存系统中被延迟,而第二次写入超过了它,这也许是可能的,但问题是我们是否应该允许这种行为。
答案是否定的。如果我们允许这种行为,那么实现多处理器内存系统无疑会变得更简单,但编写和推理并行程序将变得非常困难。因此,大多数多处理器系统都不允许这种行为。
现在稍微正式地看看多个线程访问同一内存位置的问题。我们理想地希望内存系统是连贯的,意味着在处理对同一内存地址的不同访问时,它应该遵守一组规则,以便更容易编写程序。
存储器访问同一内存地址的行为称为一致性(coherence)。
通常,一致性有两个公理:
- 完成(Completion):写入必须最终完成。此公理表示,内存系统中永远不会丢失任何写入,例如不可能将值10写入变量x,而写入请求会被内存系统丢弃,它需要到达x对应的内存位置,然后需要更新其值,稍后可能会被另一个写入请求覆盖。然而,底线是写请求需要在将来的某个时间点更新内存位置。
- 顺序(Order):对同一内存地址的所有写入都需要被所有线程以相同的顺序看到。此公理表示,所有线程都认为对内存位置的所有写入顺序相同,意味着不可能读取上面案例中的(2,1),因为线程1知道2是在1之后写入到存储位置x的,根据顺序公理,所有其他线程都需要感知到写入x的相同顺序,它们对x的感知不能与线程1的感知不同,因此,它们不能在1之后读取2。一致性的公理具有直观的意义,基本上意味着所有的写入最终都会完成,单处理器系统也是如此。其次,所有处理器都看到单个内存位置的相同视图,如果其值从0变为1变为2,则所有处理器都会看到相同的变化顺序(0-1-2),没有处理器以不同的顺序看到更新。这进一步意味着,无论内存系统如何在内部实现,在外部,每个内存位置都被视为可全局访问的单个位置。
内存一致性
一致性是指对同一内存位置的访问,如何访问不同的存储位置?可用一系列例子来解释。
// Thread 1:
x = 1;
y = 1;
// Thread 2:
t1 = y;
t2 = x;
现在从直观的角度来看t1和t2的允许值,总是可以获得(t1,t2)=(0,0),当线程2在线程1之前调度时,可能会发生这种情况。还可能获得(t1,t2)=(1,1),当线程2在线程1完成后调度时,会发生这种情况。同样,可以读取(t1,t2)=(0,1)。下图显示了如何获得所有三种结果。
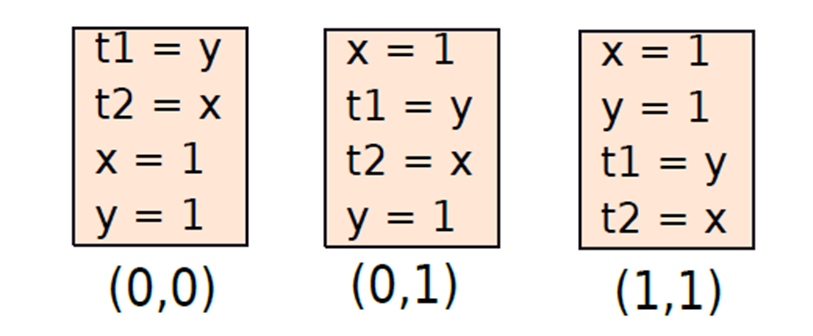
所有可能结果的示意图。
有趣的问题是(t1,t2)=(1,0)是否被允许?当对x的写入被内存系统以某种方式延迟,而对y的写入很快完成时,就会发生这种情况。在这种情况下,t1将获得y的更新值,t2将获得x的旧值。是否允许这种行为?很明显,如果允许这种行为,就很难对软件和并行算法的正确性进行推理,编程也将变得困难。然而,如果允许这种行为,那么硬件设计就会变得更简单,因为不必为软件提供强有力的保证。
答案显然没有对错之分?完全取决于我们想要如何编程软件,以及硬件设计师想要为软件编写人员构建什么。但是,这个例子仍然有一些非常深刻的东西,(t1,t2)=(1,0)的特例。为了找出原因,再次查看上图,我们已经能够通过在两个线程的指令之间创建交错来推理三个结果。在这些交错中,同一线程中的指令顺序与程序中指定的顺序相同,称为程序顺序(program order)。
与每个组成线程的控制流语义一致的指令顺序(可能属于多个线程)称为程序顺序(program order)。线程的控制流语义被定义为一组规则,用于确定在给定指令之后可以执行哪些指令,例如,单周期处理器执行的指令集总是按程序顺序执行。
很明显,我们不能通过按程序顺序交错线程来生成结果(t1,t2)=(1,0)。
如果我们能从可能的输出集合中排除输出(1,0),那就好了,将允许编写并行软件,很容易地预测可能的结果。确定并行程序可能结果集的内存系统模型称为内存模型(memory model)。
确定并行程序可能结果集的内存系统模型称为内存模型(memory model)。
顺序一致性(Sequential Consistency)
我们可以有不同类型的内存模型,对应于不同类型的处理器,最重要的内存模型之一是顺序一致性(Sequential Consistency,SC)。顺序一致性表示,只允许通过按程序顺序交错线程生成那些结果,意味着上图所示的所有结果都是允许的,因为它们是通过以所有可能的方式交错线程1和线程2生成的,而不会违反它们的程序顺序。然而,结果(t1,t2)=(1,0)是不允许的,因为它违反了程序顺序,在顺序一致的内存模型中是不允许的。请注意,一旦我们按照程序顺序交错多个线程,就等于说我们有一个处理器在一个周期中执行一个线程的指令,可能在下一个周期执行另一个其他线程的指令。因此,处理多个线程的单处理器产生SC执行。事实上,如果我们考虑模型的名称,“sequential”一词来源于这样一个概念,即执行等同于单处理器以某种顺序顺序执行所有线程的指令。
如果一组并行线程的执行结果等同于单个处理器以某种顺序执行来自所有线程的指令的结果,则内存模型是顺序一致的。或者,可以将序列一致性定义为一个内存模型,其一组可能的结果是可以通过按程序顺序交错一组线程来生成的结果。
序列一致性是一个非常重要的概念,在计算机体系结构和分布式系统领域得到了广泛的研究。它通过将并行系统上的执行等同于顺序系统上的运行,将并行系统简化为具有一个处理器的串行系统。需要注意的一点是,SC并不意味着一组并行程序的执行结果始终相同,取决于线程的交错方式以及线程到达的时间,但某些结果是不允许的。
弱一致性(Weak Consistency)
SC的实施是有代价的,使软件变得简单,但使硬件变得非常慢。为了支持SC,通常需要等待读取或写入完成,然后才能将下一次读取或写入发送到内存系统。当任何处理器的所有后续读取都将获得W已写入的值或稍后写入同一位置的值时,写入请求W完成。读取数据后,读取请求完成,而最初写入数据的写入请求完成。
这些要求/限制成为高性能系统的瓶颈,因此计算机架构社区已经转向违反SC的弱内存模型。弱内存模型将允许以下多线程代码段中的结果(t1,t2)=(1,0)。
// Thread 1:
x = 1
y = 1
// Thread 2:
t1 = y
t2 = x
弱一致性(weakly consistent ,WC)内存模型不符合SC,通常允许任意内存排序。
弱内存模型有不同的类型,一个通用的变体是弱一致性(WC)。现在尝试找出为什么WC允许(1,0)结果,假设线程1在核心1上运行,线程2在核心2上运行。此外,假设对应于x的内存位置在核心2附近,对应于y的内存位置位于核心1附近。还假设从核心1附近向核心2发送请求需要数十个周期,并且延迟是可变的。
首先研究核心1的流水线的行为。从核心1流水线的角度来看,一旦将内存写入请求移交给内存系统,则认为内存写入指令已完成,指令进入RW阶段。因此,在这种情况下,处理器将在第-n个周期中将对x的写入移交给内存系统,然后在第(n+1)个周期中将写入传递给y。对y的写入将很快到达y的内存位置,而对x的写入将需要很长时间。
同时,核心2将尝试读取y的值。假设读取请求在写入请求(到y)到达y之后到达y的内存位置,将得到y的新值,该值等于1。随后,核心2将对x发出读操作,对x的读操作可能在对x的写操作到达x之前到达x的内存位置。在这种情况下,它将获取x的旧值,即0。因此,结果(1,0)在弱内存模型中是可能的。
为了避免这种情况,我们可以等待对x的写入完全完成,然后再向y发出写入请求,这样做虽然是正确的,但是一般来说,当我们写入共享内存位置时,其他线程不会在完全相同的时间点读取它们。我们无法在运行时区分这两种情况,因为处理器之间不共享它们的内存访问模式。为了提高性能,将每个内存请求延迟到前一个内存请求完成是不值得的。因此,高性能实现更喜欢允许来自同一线程的内存访问由内存系统重新排序的内存模型。我们将在后续小节中研究避免(1,0)结果的方法。
大多数处理器都假定内存请求在离开管线后的某个时间点瞬间完成,此外,所有线程都假定内存请求在完全相同的时间点瞬间完成。内存请求的这个属性称为原子性(atomicity)。其次,需要注意,内存请求的完成顺序可能与它们的程序顺序不同。当完成顺序与每个线程的程序顺序相同时,内存模型遵循SC,如果完成顺序与程序顺序不同,则内存模型是WC的变体。
当内存请求在发出后的某个时间点被所有线程感知为瞬时执行时,称其为原子的(atomic)或观察原子性(observe atomicity)。
准确地说,对于每个内存请求,都有三个感兴趣的事件,即开始、结束和完成。让我们考虑一个写请求。当指令将请求发送到MA阶段的L1缓存时,请求开始。当指令移动到RW阶段时,请求完成。在现代处理器中,无法保证在内存请求完成时写入会到达目标内存位置,写入请求到达内存位置且写入对所有处理器可见的时间点称为完成时间。在简单的处理器中,完成请求的时间介于开始时间和结束时间之间。然而,在高性能处理器中,情况并非如此。此概念如下图所示。

读请求怎么样?大多数人会天真地认为读取的完成时间介于开始时间和结束时间之间,因为它需要返回内存位置的值。然而,这并不完全正确,因为读取可能会返回尚未完成的写入的值。在要求写入原子性(写入瞬间完成的错觉)的内存模型中,只有当相应的写入请求完成时,读取才完成。所有假定写原子性的内存一致性模型都是使用内存访问完成顺序的属性来定义的。
在弱内存模型中,不遵循同一线程中独立内存操作之间的顺序。例如,当我们写到x,然后写到y时,线程2发现它们的顺序相反。然而,属于同一线程的从属内存指令的操作顺序始终受到遵循。例如,如果将变量x的值设置为1,然后在同一线程中读取它,我们将得到1或稍后写入x的值,所有其他线程都会感知内存请求的顺序相同。在由同一线程进行的从属内存访问之间,绝不存在任何内存顺序冲突(参见下图)。

多线程程序中内存请求的实际完成时间。
现在说明使用不遵守任何顺序规则的弱内存模型的困难。假设一个顺序一致的系统,让我们编写并行加法程序。请注意,不使用OpenMP,因为OpenMP在幕后做了很多工作,以确保程序在内存模型较弱的机器上正确运行。让我们定义一个并行构造,它并行运行一个代码块,以及一个getThreadId()函数,它返回线程的标识符,线程id的范围是从0到N-1。并行加法函数的代码如下所示。假设在并行部分开始之前,所有数组都被初始化为0,在并行部分中,每个线程将其部分数字相加,并将结果写入数组中相应的条目partialSums。完成后,它将完成数组中的条目设置为1。
/* variable declaration */
int partialSums[N];
int finished[N];
int numbers[SIZE];
int result = 0;
int doneInit = 0;
/* initialise all the elements in partialSums and finished to 0 */
(...)
doneInit = 1;
/* parallel section */
parallel
{
/* wait till initialisation */
while (!doneInit()){};
/* compute the partial sum */
int myId = getThreadId();
int startIdx = myId * SIZE/N;
int endIdx = startIdx + SIZE/N;
for(int jdx = startIdx; jdx < endIdx; jdx++)
partialSums[myId] += numbers[jdx];
/* set an entry in the finished array */
finished[myId] = 1;
}
/* wait till all the threads are done */
do
{
flag = 1;
for (int i=0; i < N; i++)
{
if(finished[i] == 0)
{
flag = 0;
break;
}
}
} while (flag == 0);
/* compute the final result */
for(int idx=0; idx < N; idx++)
result += partialSums[idx];
现在阐述需要聚合结果的线程,它需要等待所有线程完成计算部分和的工作,通过等待完成的数组中的所有条目都等于1来实现这一点。一旦确定完成的数组的所有条目均等于1,它就继续将所有部分和相加,以获得最终结果。可以很容易验证,如果假设一个顺序一致的系统,那么这段代码会正确执行。她需要注意的是,只有当读取数组中的所有条目完成为1时,才计算结果。如果计算部分和并写入partialSums数组,则完成数组中的条目等于1。由于我们添加了partialSums数组的元素来计算最终结果,因此可以得出结论,它是正确计算的。
现在考虑一个弱内存模型,在上面的示例中以顺序一致性隐式假设,当最后一个线程读取finished[i]为1时,partialSums[i]包含部分和的值。然而,如果假设弱内存模型,则此假设不成立,因为内存系统可能会将写入重新排序为finished[i]和partialSums[i]。因此,在具有弱内存模型的系统中,写入完成的数组可能发生在写入partialSums数组之前。在这种情况下,finished[i]等于1的事实并不保证partialSums[i]包含更新的值。这种区别正是顺序一致性对程序员非常友好的原因。
在弱内存模型中,同一线程发出的内存访问总是被该线程认为是按程序顺序进行的。但是,其它线程可以不同地感知内存访问的顺序。
回到确保并行加法示例正确运行的问题上。摆脱困境的唯一方法是有一种机制,确保在另一个线程读取完成[i]为1之前完成对partialSums[i]的写入。我们可以使用一种称为栅栏(fence)的通用指令,此指令确保在栅栏开始后的任何读取或写入之前完成栅栏之前发出的所有读取和写入。简单地说,我们可以通过在每条指令后插入栅栏,将弱内存模型转换为顺序一致的模型。然而,这可能会导致大量开销,最好在需要时引入最少数量的栅栏指令。下面通过添加围栏指令,为弱内存模型并行添加一组数字。
/* variable declaration */
int partialSums[N];
int finished[N];
int numbers[SIZE];
int result = 0;
/* initialise all the elements in partialSums and finished to 0 */
(...)
/* fence */
/* 确保并行部分可以读取初始化的数组 */
fence();
/* All the data is present in all the arrays at this point */
/* parallel section */
parallel
{
/* get the current thread id */
int myId = getThreadId();
/* compute the partial sum */
int startIdx = myId * SIZE/N;
int endIdx = startIdx + SIZE/N;
for(int jdx = startIdx; jdx < endIdx; jdx++)
partialSums[myId] += numbers[jdx];
/* fence */
/* 确保在partialSums[i]之后写入finished[i] */
fence();
/* set the value of done */
finished[myId] = 1;
}
/* wait till all the threads are done */
do
{
flag = 1;
for (int i=0; i < N; i++)
{
if(finished[i] == 0)
{
flag = 0;
break;
}
}
} while (flag == 0) ;
/* sequential section */
for(int idx=0; idx < N; idx++)
result += partialSums[idx];
上述代码显示了弱内存模型的代码,代码与顺序一致内存模型的代码大致相同,唯一的区别是我们增加了两个额外的栅栏指令。我们假设一个名为fence()的函数在内部调用fence指令,在调用所有并行线程之前,首先调用fence(),确保初始化数据结构的所有写入都已完成。随后开始并行线程,并行线程完成计算和写入部分和的过程,然后再次调用fence操作,以确保在完成[myId]设置为1之前,所有部分和都已计算并写入内存中各自的位置。其次,如果最后一个线程读取finished[i]为1,就可以确定partialSums[i]的值是最新的并且正确的。因此,尽管内存模型较弱,该程序仍能正确执行。
因此,如果程序员意识到弱内存模型并在正确的位置插入栅栏,那么弱内存模型不会影响正确性。尽管如此,程序员有必要理解弱内存模型,否则,会因为程序员没有考虑底层内存模型,导致并行程序中会出现很多细微的错误。弱内存模型目前被大多数处理器使用,因为它们允许我们构建高性能内存系统。相比之下,顺序一致性非常有限,除了MIPS R10000,没有其他主要供应商提供具有顺序一致性的机器,目前所有基于x86和ARM的机器都使用不同版本的弱内存模型。
4.2 物理视角
我们研究了多处理器内存系统逻辑视图的两个重要方面,即连贯性和一致性,需要实现一个兼顾这两个属性的内存系统。本节将研究多处理器内存系统的设计空间,并提供设计备选方案的概述。为多处理器存储器系统设计高速缓存有两种方法:第一种设计称为共享缓存,其中单个缓存在多个处理器之间共享。第二种设计使用一组专用缓存,其中每个处理器或一组处理器通常都有一个专用缓存。所有的私有缓存协作提供共享缓存的错觉,这就是所谓的缓存一致性(cache coherence)。
本节将研究共享缓存的设计和私有缓存的设计,介绍确保内存一致性的问题,最终将得出结论,有效实现给定的一致性模型(如顺序一致性或弱一致性)是困难的,并且是高级计算机体系结构课程中的一个研究主题,本文提出了一个简单的解决方案。
多处理器内存系统:共享和私有缓存
首先考虑一级缓存。可以给每个处理器单独的指令缓存,指令表示只读数据,通常在程序执行期间不会改变。由于共享不是问题,所以每个处理器都可以从其小型专用指令缓存中受益,主要问题是数据缓存。设计数据缓存有两种可能的方法,可以有共享缓存,也可以有私有缓存。共享缓存是所有处理器都可以访问的单个缓存,私有缓存只能由一个处理器或一组处理器访问。可以有共享缓存的层次结构,也可以有私有缓存的层次结构,甚至可以在同一系统中有共享和私有缓存的组合,如下图所示。
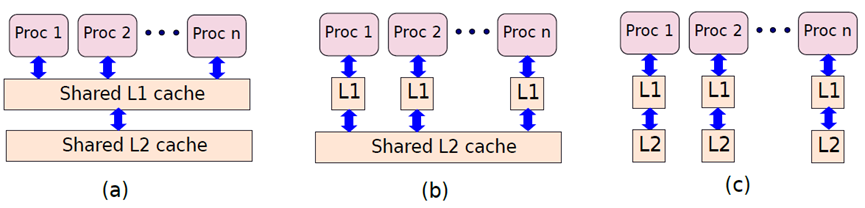
具有共享和私有缓存的系统示例。
现在评估一下共享缓存和私有缓存之间的权衡。共享缓存可供所有处理器访问,并且包含缓存内存位置的单个条目,通信协议很简单,就像任何常规缓存访问一样。额外的复杂性主要是因为我们需要正确地调度来自不同处理器的请求。然而,以简单为代价,共享缓存也有其问题,为了服务来自所有处理器的请求,共享缓存需要有大量的读写端口来同时处理请求。不幸的是,缓存的大小大约是端口数的平方。此外,共享缓存需要容纳当前运行的所有线程的工作集,因此,共享缓存往往变得非常大和缓慢。由于物理限制,很难在所有处理器附近放置共享缓存。相比之下,私有缓存通常要小得多,服务请求的核心更少,读/写端口数量更少。因此,它们可以放置在与其关联的处理器附近。因此,私有缓存的速度要快得多,因为它可以放在离处理器更近的地方,而且大小也要小得多。
为了解决共享缓存的问题,设计者经常使用私有缓存,尤其是在内存层次结构的更高层。私有缓存只能由一个处理器或一小组处理器访问,它们体积小,速度快,耗电量小。私有缓存的主要问题是它们需要为程序员提供共享缓存的假象,例如,一个具有两个处理器的系统,以及与每个处理器关联的专用数据缓存。如果一个处理器写入内存地址x,则另一个处理器需要知道该写入。然而,如果它只访问其私有缓存,那么它将永远不会知道写入地址x,意味着写入地址x丢失,因此系统不一致。因此,需要绑定所有处理器的私有缓存,使它们看起来像一个统一的共享缓存,并遵守一致性规则。缓存上下文中的一致性通常称为缓存一致性(cache coherence)。保持缓存一致性是私有缓存的另一个复杂性来源,并限制了其可扩展性。它适用于小型私人缓存,然而,对于更大的私有缓存,维护一致性的开销变得令人望而却步。对于大型低级别缓存,共享缓存更合适。其次,通常会跨多个私有缓存进行一些数据复制,但会浪费空间。
一组私有缓存上下文中的一致性称为缓存一致性(cache coherence)。
通过实现缓存一致性协议,可以将一组不相交的私有缓存转换为软件共享缓存。下表概述共享缓存和私有缓存之间的主要权衡。
|
属性 |
私有缓存 |
共享缓存 |
|
面积 |
低 |
高 |
|
速度 |
快 |
慢 |
|
接近处理器 |
近 |
远 |
|
尺寸扩展性 |
低 |
高 |
|
数据复制 |
是 |
否 |
|
复杂度 |
高(需缓存一致性) |
低 |
从表中可以清楚地看出,一级缓存最好是私有的,因为可获得低延迟和高吞吐量。然而,较低级别需要更大的尺寸,并且服务的请求数量要少得多,因此它们应该包括共享缓存。接下来描述一致的私有缓存和大型共享缓存的设计。为了简单起见,只考虑单层私有缓存,而不考虑分层私有缓存,它们会引入额外的复杂性。先讨论共享缓存的设计,因为它们更简单。
4.3 共享缓存
在共享缓存的最简单实现案例中,可以将其实现为单处理器中的常规缓存,但在实践中它被证明是一种非常糟糕的方法,原因是在单处理器中,只有一个线程访问缓存;然而在多处理器中,多个线程可能会访问缓存,因此我们需要提供更多的带宽。如果所有线程都需要访问相同的数据和标记数组,那么要么请求必须暂停,要么必须增加数组中的端口数,导致面积和功率产生非常负面的后果。最后,根据摩尔定律,缓存大小(尤其是L2和L3)大致加倍,如今片上缓存的大小可达4-16 MB甚至更多。如果对整个缓存使用单个标签数组,那么它将非常大且速度很慢。术语最后一级缓存(last level cache,LLC)定义为在内存层次结构中位置最低的片上缓存(主内存最低),例如,如果多核处理器有一个连接到主内存的片上L3高速缓存,那么LLC就是L3高速缓冲内存。后面会经常使用术语LLC。
要创建一个可以同时支持多个线程的多兆字节LLC,需要将其拆分为多个子缓存。假设有一个4 MB的LLC,在一个典型的设计中,它将被分成8-16个更小的子缓存(subcache),每个子缓存的大小为256-512 KB,这是可接受的大小。每个子缓存本身就是一个缓存,称为缓存库(cache bank)。因此,实际上将一个大型缓存拆分为一组缓存库,缓存库可以是直接映射的,也可以设置为关联的。访问多库缓存有两个步骤:首先计算库地址,然后在库执行常规缓存访问。用一个例子来解释,考虑一个16组、4 MB的缓存,每个库包含256KB的数据,4 MB=222222字节,可以将位19-22专用于选择存地址。注意,在这种情况下,库选择与关联性无关。选择一个库后,可以在块内的偏移量、集合索引和标签之间分割剩余的28位。
将缓存划分为多个库有两个优点。第一,减少了每个库的争用量。如果我们有4个线程和16个库,那么2个线程访问同一库的概率很低。其次,由于每个库都是一个较小的缓存,因此它更省电、更快。因此,我们实现了支持多线程和设计快速缓存的双重目标。
4.4 私有缓存
我们的目的是使一组私有缓存的行为就像是一个大型共享缓存,从软件的角度来看,我们不应该知道缓存是私有的还是共享的。系统的概念图如下图所示,它显示了一组处理器及其相关缓存,这组缓存形成一个缓存组,整个缓存组需要显示为一个缓存。
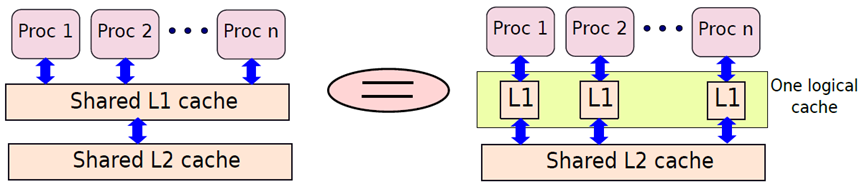
具有许多处理器及其私有缓存的系统。其中左侧是软件视角,而右侧是硬件视角。
这些缓存通过内部网络连接,内部网络可以从简单的共享总线类型拓扑到更复杂的拓扑。假设所有缓存都连接到共享总线,共享总线允许在任何时间点使用单个写入器和多个读取器。如果一个缓存将消息写入总线,那么所有其他缓存都可以读取该消息。拓扑结构如下图所示。请注意,总线在写入消息的任何时间点只提供对一个缓存的独占访问,因此所有缓存都感知到相同的消息顺序。一种与连接在共享总线上的缓存实现缓存一致性的协议称为监听协议(snoopy protocol)。
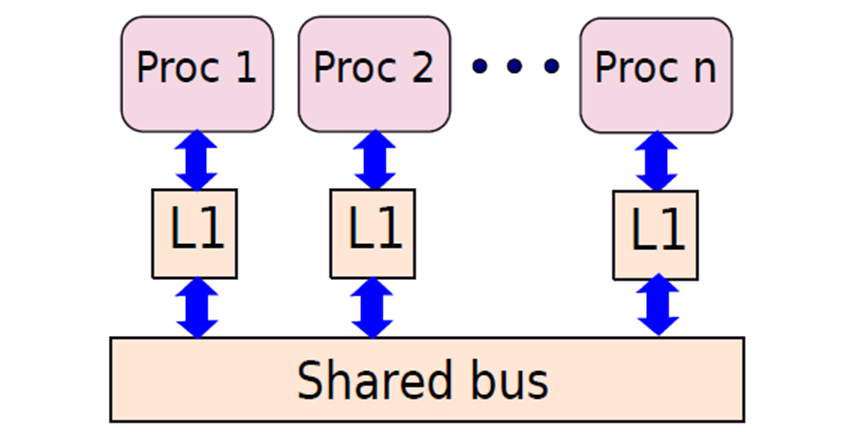
与共享总线连接的缓存。
现在让我们从一致性的两个公理的角度来考虑史努比协议的操作:写入总是完成(完成公理),并且所有处理器都以相同的顺序看到对同一块的写入(顺序公理)。如果缓存i希望对一个块执行写入操作,那么该写入需要最终对所有其他缓存可见。我们需要这样做来满足完成公理,因为不允许丢失写请求。其次,对同一块的不同写入需要以相同的顺序到达可能包含该块的所有缓存(顺序公理),以确保对于任何给定的块,所有缓存感知到相同的更新顺序。共享总线自动满足顺序公理的要求。
下面给出两个监听协议的设计:写更新(write-update)和写无效(write-invalidate)。
写更新协议
现在让我们设计一个协议,假设一个私有缓存保存一个写请求的副本,并将写请求广播到所有缓存。此策略确保写入永远不会丢失,并且所有缓存都以相同的顺序感知到同一块的写入消息。此策略要求无论何时写入都要广播,是一个很大的额外开销,然而,这一策略依然奏效。
现在将读取纳入协议。对位置x的读取可以首先检查私有缓存,以查看其副本是否已经可用。如果有效副本可用,则可以将该值转发给请求处理器。但是,如果存在缓存未命中,那么它可能与缓存组中的另一个姐妹缓存一起存在,或者可能需要从较低级别获取。首先检查该值是否存在于姐妹缓存中,此处遵循相同的流程,缓存向所有缓存广播读取请求,如果任何一个缓存具有该值,则它会进行回复,并将该值发送到请求缓存。请求缓存插入该值,并将其转发给处理器。但是,如果它没有从任何其他缓存获得任何回复,那么它将启动对较低级别的读取。
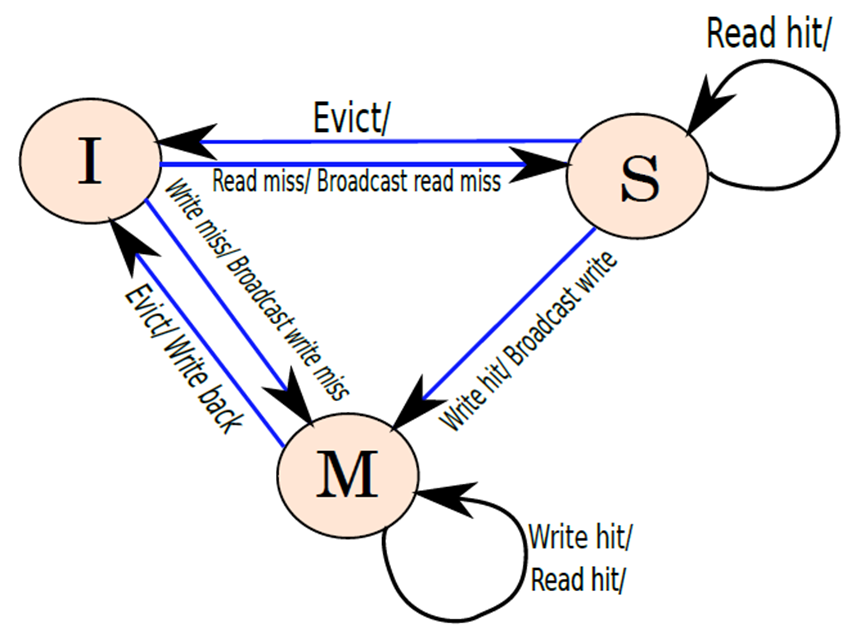
该协议称为写更新(write-update)协议。每个缓存块需要保持三种状态:M、S和I。M表示修改后的状态,表示缓存已经修改了块,S(共享)表示缓存未修改块,I(无效)表示块不包含有效数据。
下图显示了每个缓存块的有限状态机(FSM),该FSM由高速缓存控制器执行,状态转换的格式是:事件/动作。如果缓存控制器被发送了一个事件,那么它会采取相应的动作,可能包括状态转换。请注意,在某些情况下,动作字段为空,意味着在这些情况下,不采取任何行动。请注意,缓存块的状态是其在标记数组中的条目的一部分,如果缓存中不存在块,则其状态被假定为无效(I)。值得一提的是,下图显示了处理器生成的事件的转换,它不显示缓存组中其他缓存通过总线发送的事件的操作。
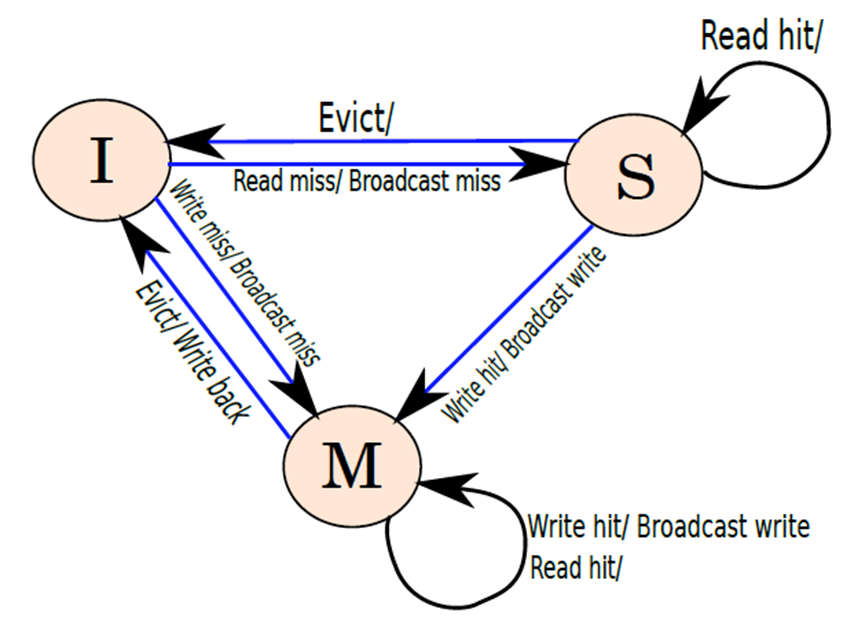
写更新协议中的状态转换图。
所有块最初都处于I状态。如果存在读取未命中,则它将移动到S状态,还需要向缓存组中的所有缓存广播读未命中,并从姊妹缓存或较低级别获取值。请注意,我们首先优先考虑姊妹缓存,因为它可能修改了块而没有将其写回较低级别。类似地,如果在I状态中存在写入未命中,那么需要从另一个姊妹缓存中读取块(如果它可用),并移动到M状态。如果没有其他姐妹缓存具有该块,那么需要从内存层次结构的较低级别读取该块。
如果在S状态下有读取命中,就可以无缝地将数据传递给处理器。但如果要写入S状态的块,就需要将写入广播到所有其他缓存,以便它们获得更新的值。一旦缓存从总线获取了其写入请求的副本,它就可以将值写入块,并将其状态更改为M。要将处于S状态的块逐出,只需要将其从缓存中逐出,此时没有必要写回其值,因为块尚未修改。
现在考虑M状态。如果需要读取M状态的块,那么可以从缓存中读取它,并将值发送给处理器。没有必要发送任何消息,但如果希望写入它,则需要在总线上发送写入请求。一旦缓存看到自己的写入请求到达共享总线,它就可以将其值写入其专用缓存中的内存位置。要回收M状态的块,需要将其写回内存层次结构中的较低级别,因为它已被修改。
每个总线都有一个称为仲裁器(arbiter)的专用结构,它接收来自不同缓存的使用总线的请求,按FIFO顺序将总线分配给缓存。总线仲裁器的示意图如下图所示,是一个非常简单的结构,包含一个在总线上传输的请求队列。每个周期它从队列中提取一个请求,并向相应的缓存授予在总线上传输消息的权限。

总线仲裁器结构。
现在考虑一个姐妹缓存。每当它从总线收到一条未命中消息时,它就会检查缓存以确定是否有该块。如果有缓存命中,它就将块发送到总线上,或直接发送到请求缓存。它如果接收到另一个缓存的写入通知,就会更新其缓存中存在的块的内容。
目录协议
请注意,在监听协议中,我们总是广播写入、读取未命中或写入未命中,实际上只需要向那些包含块副本的缓存发送消息。目录协议(directory protocol)使用称为目录的专用结构来维护此信息,对于每个块地址,目录维护一个共享者列表。共享者是可能包含该块的缓存的id,共享者列表通常是可能包含给定块的缓存的超集。我们可以将共享者列表保持为位向量(每个共享者1位),如果位为1,则缓存包含一个副本,否则不包含。
带有目录的写更新协议修改如下。缓存不是在总线上广播数据,而是将其所有消息发送到目录。对于读或写未命中,目录从姊妹缓存中获取块(如果它有副本),然后它将块转发到请求缓存。类似地,对于写入,目录只将写入消息发送到那些可能有块副本的缓存,当缓存插入或回收块时,需要更新共享者列表。最后,为了保持一致性,目录需要确保所有缓存以相同的顺序获取消息,并且不会丢失任何消息。目录协议最大限度地减少了需要发送的消息的数量,因此更具可扩展性。
监听协议(Snoopy Protocol):在监听协议中,所有缓存都连接到共享总线。缓存将每条消息广播到其他缓存。
目录协议(Directory Protocol):在目录协议中,通过添加一个称为目录的专用结构来减少消息的数量。该目录维护可能包含块副本的缓存列表,只向列表中的缓存发送给定块地址的消息。
为什么需要等待总线的广播来执行写入?
答:让我们假设情况并非如此,处理器1希望将1写入x,处理器2希望将2写入x。然后,它们将首先分别将1和2写入x的副本,然后广播写入,因此两个处理器将以不同的顺序看到对x的写入。这违反了秩序公理。但是,如果它们等待写入请求的副本从总线到达,那么它们将以相同的顺序写入x。总线有效地解决了处理器1和2之间的冲突,并对一个请求进行排序。
写无效协议
我们需要注意的是,为每次写入广播写入请求是不必要的开销,有可能大多数块在一开始就不共享,所以不需要在每次写入时发送额外的消息。让我们尝试通过提出写无效协议来减少写更新协议中的消息数量,此处可以使用监听协议,也可以使用目录协议。下面展示一个监听协议的示例。
为每个块保持三个状态:M、S和I,但改变状态的含义:
- 无效状态(I)保留相同含义,意味着该条目实际上不存在于缓存中。
- 共享状态(S)意味着缓存可以读取块,但不能写入块,在共享状态下,可以在不同的缓存中拥有同一块的多个副本。由于共享状态假定块是只读的,因此具有块的多个副本不会影响缓存一致性。
- M(已修改)状态表示缓存可以写入块。如果一个块处于M状态,那么缓存组中的所有其他缓存都需要使该块处于I状态。不允许任何其他缓存具有S或M状态的块的有效副本,这就是写无效协议不同于写更新协议的地方。它一次只允许一个写入,或者一次允许多个读取,绝不允许读和写同时共存。通过限制在任何时间点对块具有写访问权限的缓存数量,可以减少消息的数量。
内部机制如下。写更新协议不必在读命中时发送任何消息,所以当写命中时发送了额外的消息,我们希望消除之。它需要发送额外的消息,因为多个缓存可以同时读取或写入一个块。写无效协议已经消除了这种行为,如果一个块处于M状态,那么没有其他缓存包含该块的有效副本。
下图显示了由于处理器的动作而导致的状态转换图,状态转换图与写更新协议的状态转换图基本相同。让我们看看差异。第一种是,我们定义了三种类型的消息放在总线上,即写入、写入未命中和读取未命中。当从I状态转换到S状态时,将读取未命中放在总线中。如果姊妹高速缓存没有回复数据,则高速缓存控制器从较低级别读取块。S状态的语义保持不变,要写入S状态的块,我们需要在总线上写入写入消息后转换到M状态。现在,当一个块处于M状态时,可以确信没有其他缓存包含有效副本,可以自由地读写M状态的块,没有必要在总线上发送任何信息。如果处理器决定将M状态的块逐出,则需要将其数据写入较低级别。
由于处理器的动作导致的块的状态转换图。
下图显示了由于总线上接收到的消息而导致的状态转换。在S状态下,如果我们得到一个读未命中,那么这意味着另一个缓存想要对该块进行读访问。包含该块的任何缓存都会将该块的内容发送给它。这个过程可以按如下方式编排。所有具有块副本的缓存都试图访问总线。访问总线的rst缓存将块的副本发送到请求缓存。其余的缓存立即知道块的内容已被传输。他们随后停止了尝试。如果我们在S状态下收到写入或写入未命中消息,那么块将转换到I状态。
现在让我们考虑M状态。如果某个其他缓存发送写入未命中消息,则包含该块的缓存的缓存控制器将向其发送块的内容,并转换为I状态。但是,如果发生读取未命中,则需要执行一系列步骤,假设可以无缝地回收处于S状态的块,因此,有必要在移动到S状态之前将数据写入较低级别。随后,原本具有块的高速缓存也将块的内容发送到请求高速缓存,并将块的状态转换为S状态。
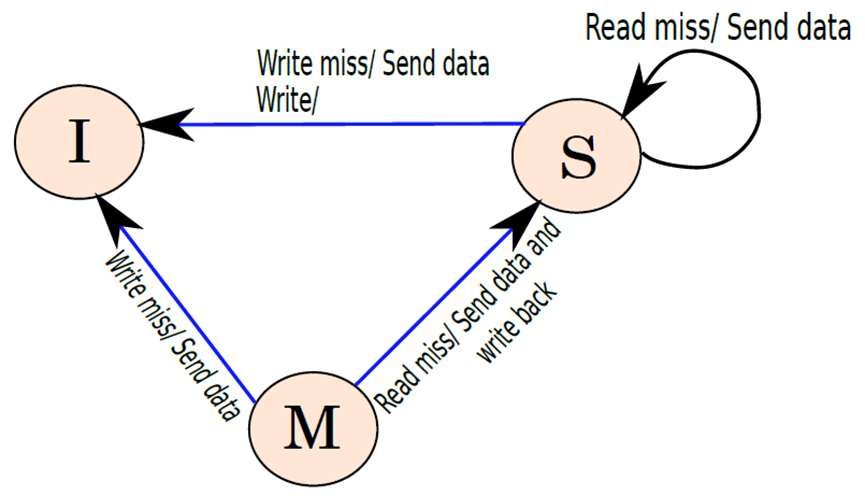
由于总线上的消息导致的块状态转换图。
使用目录的写无效协议
使用目录实现写无效协议相当简单。状态转换图几乎保持不变,没有广播消息,而是将其发送到目录,目录将消息发送给块的共享者。
现在阐述块的生命周期。每当从较低级别引入块时,都会初始化一个目录条目,它只有一个共享者,是从较低级别带来它的缓存。现在,如果块中存在读取未命中,则目录会继续添加共享程序。但如果存在写入未命中,或者处理器决定写入块,则会向目录发送写入或写入未命中消息。该目录清理共享者列表,并只保留一个共享者,即执行写访问的处理器。当一个块被逐出时,它的缓存会通知目录,目录会删除一个共享程序。当共享者集变空时,可以删除目录条目。
可以通过添加一个称为独占(Exclusive,E)状态的附加状态来改进写无效和更新协议,E状态可以是从存储器层次结构的较低级别获取的每个缓存块的初始状态,此状态存储块独占地属于缓存的事实。但是,缓存对其具有只读访问权限,而没有写访问权限。对于E到M的转换,不必在总线上发送写未命中或写消息,因为块只由一个缓存拥有。如果需要,可以无缝地将数据从E状态中逐出。