LLM的问题就是权重参数太大,无法在我们本地消费级GPU上进行调试,所以我们将介绍3种在训练过程中减少内存消耗,节省大量时间的方法:梯度检查点,LoRA和量化。
梯度检查点
梯度检查点是一种在神经网络训练过程中使动态计算只存储最小层数的技术。
为了理解这个过程,我们需要了解反向传播是如何执行的,以及在整个过程中层是如何存储在GPU内存中的。
1、前向和后向传播的基本原理
前向传播和后向传播是深度神经网络训练的两个阶段。
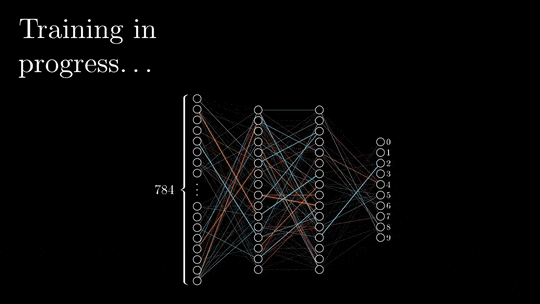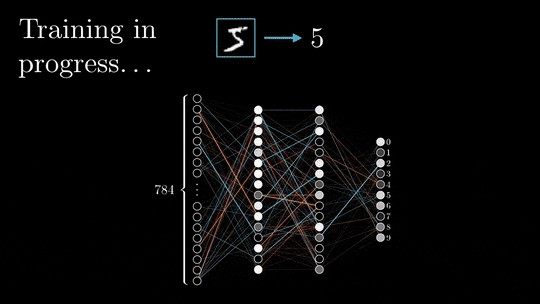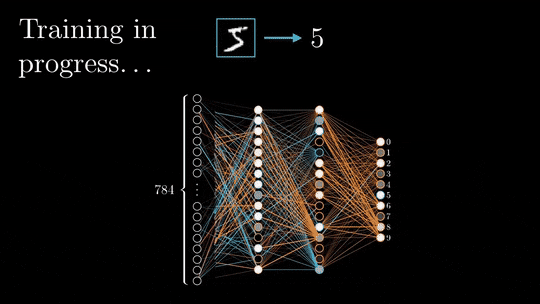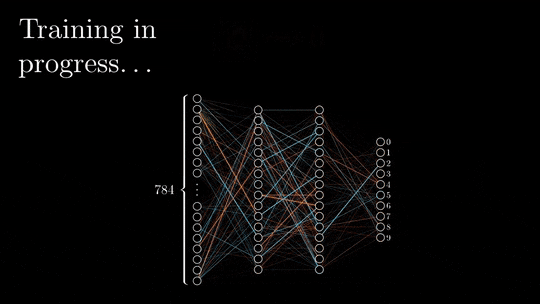
在前向传递过程中,输入被矢量化(将图像转换为像素,将文本转换为嵌入),并且通过一系列线性乘法和激活函数(如sigmoid或ReLU等非线性函数)在整个神经网络中处理每个元素。
神经网络的输出,被称为头部,被设计用来产生期望的输出,例如分类或下一个单词预测。然后将矢量化的预测结果与预期结果进行比较,并使用特定的损失函数(如交叉熵)计算损失。
基于损失值,以最小化损失为目标更新每层的权值和偏差。这个更新过程从神经网络的末端开始并向起点传播。
上面就是一个简单的过程,下面才是我们主要关注的:计算是如何存储在内存中的。
2、减少存储数量
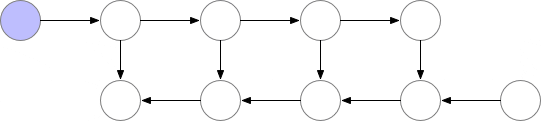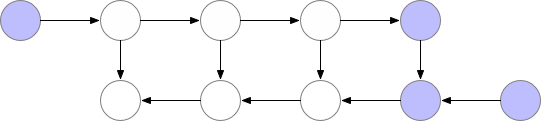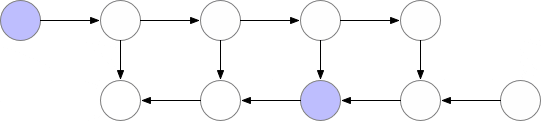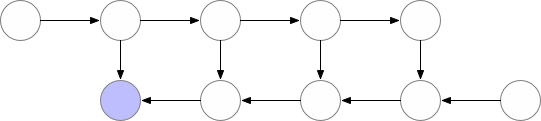
一种简单的方法是只保留反向传播所需的基本层,并在它们的使用完成后从内存中释放它们。
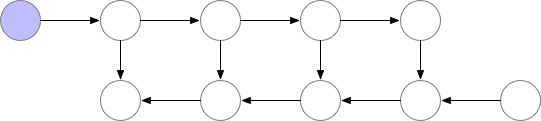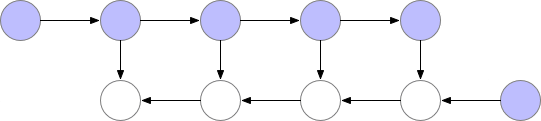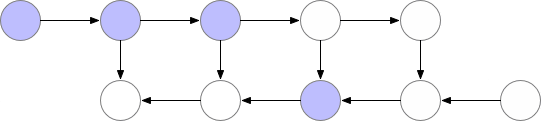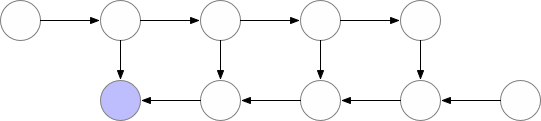
从上图可以看出,同时存储在内存中的层的最大数量并不是最优的。所以我们需要找到一种方法,在保持反向传播工作的同时,在内存中存储更少的元素。
3、减少计算时间
减少内存占用的一种方法是在神经网络开头的反向传播过程中重新计算每一层。
但是在这种情况下,计算时间会明显增加,使得训练在大模型的情况下不可行。
4、优化计算和内存梯度检查点
该技术通过保存“检查点”以计算反向传播期间“丢失”的层。该算法不是从头开始计算层,如前面的示例所示,而是从最近的检查点开始计算。

https://avoid.overfit.cn/post/7d68614b936a431a8973ff825091a795