1. 单词与向量
1.1 Term-document 矩阵
Term-document 矩阵是信息检索和文本挖掘中常用的一种表示方法,这种矩阵是一个二维表格,用来表示词(term)在文档(document)集合中的分布情况。在这个矩阵中,行通常代表词汇(terms),列代表文档。矩阵中的每一个元素,即 \((i, j)\) 位置的值,一般表示词汇 \(i\) 在文档 \(j\) 中出现的频率。

我们可以将向量可视化表示。
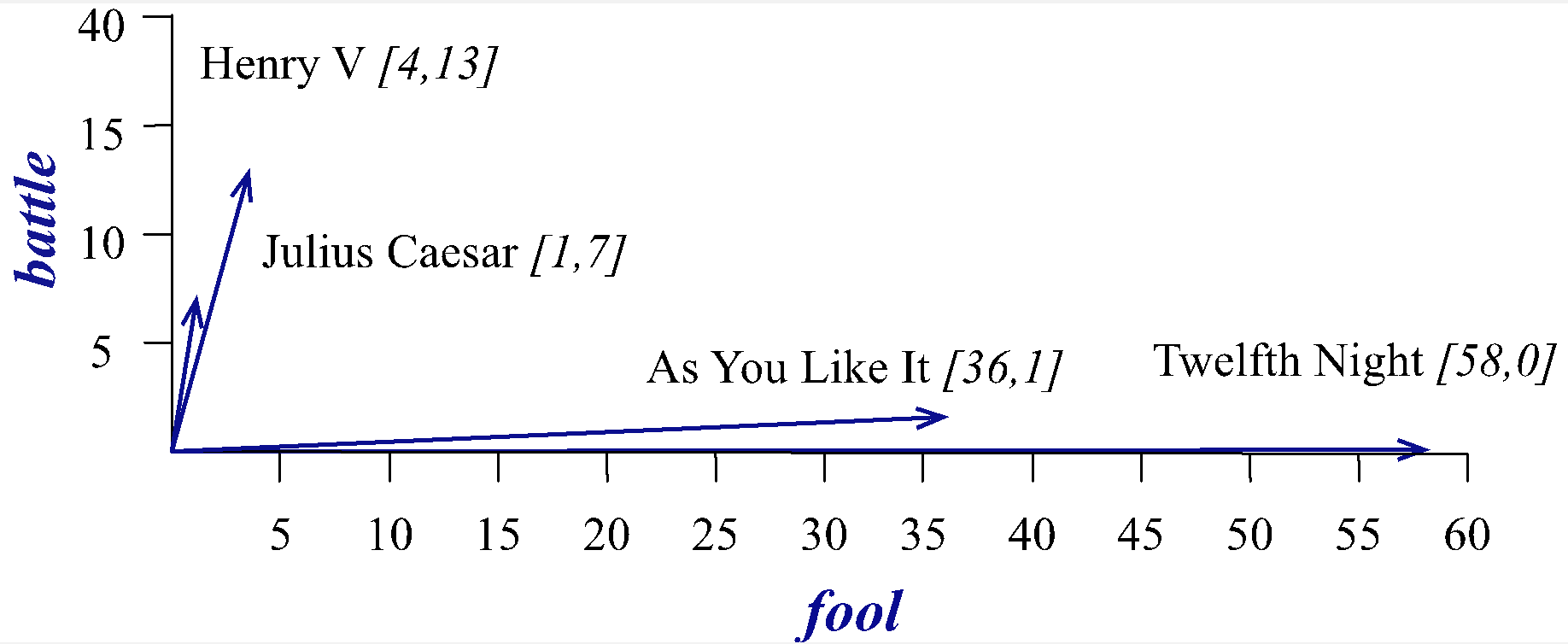
1.2 Term-Context 矩阵
Term-Context矩阵是一种表达文本数据的结构,与 Term-Document矩阵类似,但侧重点有所不同。在 Term-Context矩阵中,我们不是将词与文档相关联,而是将词与它们的上下文相关联。行表示词汇(terms),列表示上下文(context)

我们可以将向量可视化表示。
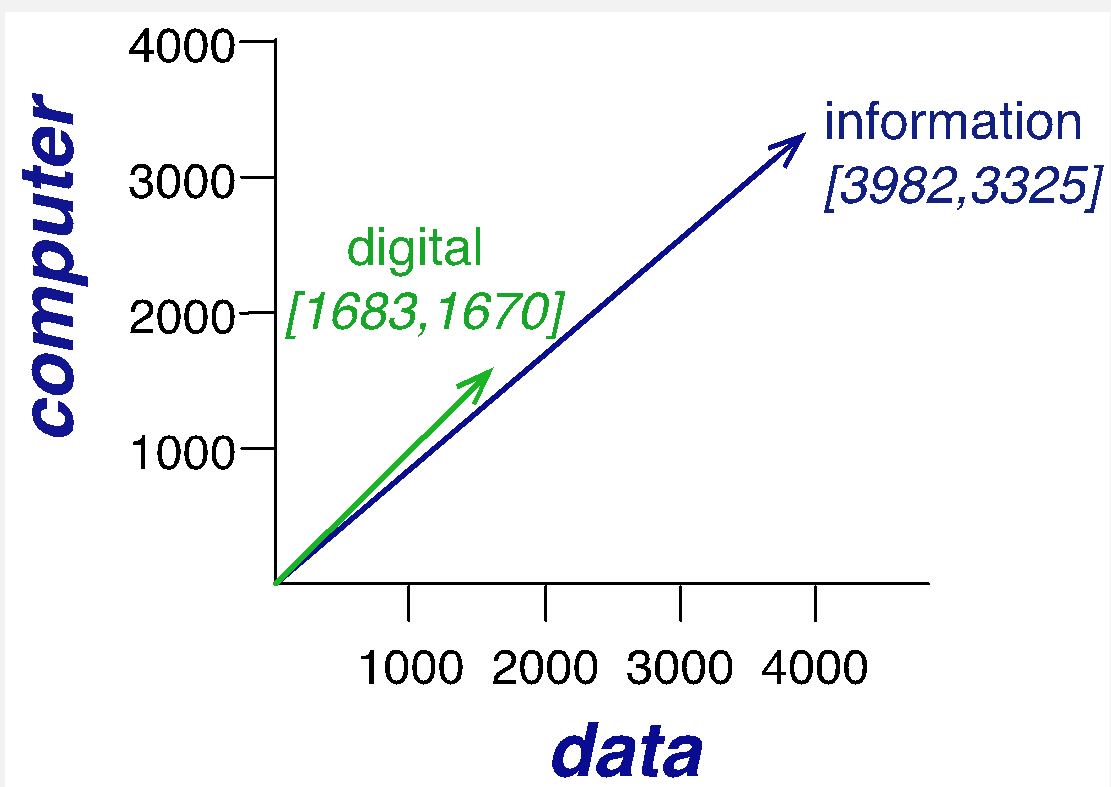
1.3 局限性
Term-Context 矩阵和 Term-Document 矩阵在文本挖掘和信息检索等任务中非常有用,表达方式也非常简洁。但是,它们很多时候都存在 数据稀疏 的问题,大多数词在大多数文档中不会出现,导致矩阵中的绝大部分元素是零。这会导致存储和计算效率非常低。
2. 余弦相似度
2.1 余弦相似度定义
两个向量的余弦值:
给定两个属性向量, \(A\) 和 \(B\),其余弦相似性 \(\theta\) 由点积和向量长度给出:
余弦相似度的取值范围从 -1 到 1。当两个向量的方向完全一致时,余弦相似度为 1;当它们完全相反时,余弦相似度为 -1;如果两个向量正交,则余弦相似度为 0,表示它们之间没有相关性。
在基于计数的词向量表示中,统计的频率非负,所以在这类问题中余弦相似度范围为 0 到 1.
2.2 余弦相似度计算实例
比如如下的矩阵,可以计算单词 "infomation" 和其他单词之间的相似度。显然,"information" 与 "digital" 更加相近。

余弦相似度也可以计算两个句子的相似度,首先得到两个句子中所有单词的词汇表,然后将单词映射到下标,这样就可以基于句子中这个单词出现的次数形成一个向量来表示一个句子。
3. TF-IDF
\(\text{TF-IDF}\)(词频-逆文档频率)是一种在文本挖掘和信息检索中常用的技术,主要用于评估一个单词对于一个文件集或一个语料库中一个文件的重要性。
3.1 TF
\(\text{TF}\) (\(\text{Term Frequency}\))表示词条在文本中出现的频率,简称词频。通常会被归一化(一般是词频除以文章总词数)。有如下公式:
其中 \(c_{ij}\) 表示词条 \(t_i\) 在文档 \(d_j\) 出现的次数,\(|d_j|\) 表示文档 \(d_j\) 的单词总数。
\(\text{TF}_{ij}\) 表示的就是词条 \(c_{ij}\) 在文档 \(d_j\) 中出现的频率。
3.2 IDF
\(\text{IDF}\) (\(\text{Inverse Document Frequency}\)),即逆文档频率,表示关键词的普遍程度。如果包含词条的文档越少, \(\text{IDF}\) 越大,则说明该词条具有很好的类别区分能力。
其中,\(|D|\) 表示文档的数量,\(\{j | t_i \in d_j\}\) 表示包含词条 \(t_i\) 的文档所组成的集合。加 1 主要是防止包含词条 \(t_i\) 的文档数量为 0 从而导致出现除以0的错误。不过不进行平滑处理也可以,但是前提是需要对数据进行预处理,去除从未出现过的罕见词,这样也不会担心分母为0的情况了。课件里的示例就是如此。
3.3 TF-IDF
\(\text{TF-IDF}\),即“词频-逆文档频率”(\(\text{Term Frequency-Inverse Document Frequency}\)),\(\text{TF-IDF}\) 的表达式为:
表示词条 \(t_i\) 在文档 \(d_j\) 的词频-逆文档频率。
3.4 典型示例
显然,课件里的示例并没有增加加一平滑处理。不过,可以看出单词 good 对应的维度的 tf-idf 值现在都变为 0,导致它被忽略。这也体现了自动过滤高频停用词的优点。
逆文档频率采用的公式为:\(\text{IDF}_i = \text{log}(\frac{|D|}{|\{j | t_i \in d_j \}|})\)

显然,一个单词在文档中出现的频次很高,但是在很多文档中也都有出现,那么这样的词的 \(\text{TF-IDF}\) 值会比较低,会被筛除。
3.5 TF-IDF的优缺点
-
优点
\(\text{TF-IDF}\) 算法简单易懂,计算效率高。
而且可以自动过滤停用词,如“的”、“是”等通用词在所有文档中都频繁出现,其逆文档频率会很低,导致其 \(\text{TF-IDF}\) 值也低,自然而然地被筛选出。
-
缺点
\(\text{TF-IDF}\) 侧重于文档中词的统计特性,而不理解词与词之间的语义关系。对于 同义词或多义词,无法区分。
在 \(\text{TF-IDF}\) 中,一个词在一份文档中的重要性是静态的,不会随上下文改变而改变。无法体现词条在上下文的重要性。
\(\text{TF-IDF}\) 未考虑单词在文档中的位置,序列或者其他结构信息,比如短语和语法结构。简单地说,就是 无法体现位置信息。