如果你在你简历上写上了熟悉RabbitMQ,那么你在面试时很有可能会被问到,如何解决MQ消息积压?
要想将此问题回答完美,一定要多方面考虑。首先,我们要搞清楚是什么原因导致的消息积压。我列举了以下三种:
1)流量变大,而RabbitMQ服务器配置偏低,导致消息产生速度大于消费速度;
2)消费者故障,从而消息只增不减;
3)程序逻辑设计有问题,导致生产者持续生产消息,而消费者不消费或者消费慢;
当然,还有其它原因,上面三个已经能覆盖80%以上的问题。下面就以这三种情况分别来说说如何应对。
对于第一种情况,很明显就是资源不够了,解决方法也很简单,扩容即可。可以纵向扩容,即增加服务器资源,该加内存加内存,该加CPU加CPU。
如果纵向扩容不方便,那就横向扩容,即将单机改为集群模式,增加集群节点,并且增加消费者数量,让消费速度快起来!例如,原来是5个消费者,现在变成50个消费者!
对于第二种情况,要通过查看日志搞清楚为什么消费者会故障,据我多年经验,发生此类问题大概率是程序代码写的不够完美,跑着跑着导致内存溢出,然后消费者进程被杀。要想永久解决此问题,需要结合日志分析程序代码,优化代码。临时解决方法是写监控脚本,如果发现消费者进程中断,需要重启服务!
再来说第三个,这种情况发生的概率其实并不高,总之就是程序逻辑问题,判断的方法也很简单,持续观察服务器的资源耗费情况,如果内存、CPU一切都正常,但就是队列持续增长,而消费速度非常慢。此时,就需要好好查查程序代码了。当然,可以尝试增加消费者数量,看看是否有好转。
上面说的只是“亡羊补牢”的操作,但还没有说如何将当前已经积压的队列给快速消耗掉。
相信,当我们发现消息积压时,想必问题已经比较严重了,或者说已经影响到业务正常运转了,那么当务之急肯定是需要先将业务恢复正常。对于上面第二种情况,直接重启相关服务,让消费者恢复正常,定是首当其冲。
除此之外,还有一种“断尾求生”的骚操作,就是新开一个队列,将新产生的消息到新队列里,消费者也到新队列里消费。而老的队列,则需要做一个异步处理,慢慢消费掉即可。
当然,如果积压的消息不怎么重要,可有可无的话,那干脆直接删除掉,这样大家都省事不是。
最后再声明一下,本文只是理论性的话术,真正操作还需要一些开发技能的功底,但在面试时,能把上面几点说明白,这一道题大概率是可以过关的!
下面再通知大家一个事情:
如果你是老学员,也想再提升下自己!
其中,运维架构师课程会涵盖当前主流的运维技术:K8S、Devops、Prometheus、自动化、虚拟化等,学完课程至少可以达到下图中级进阶的水平,对于初学者,薪资在一线城市能达到10k+,而对于有一些经验的同学来说,提升后,薪资在一线城市能达到20k+!
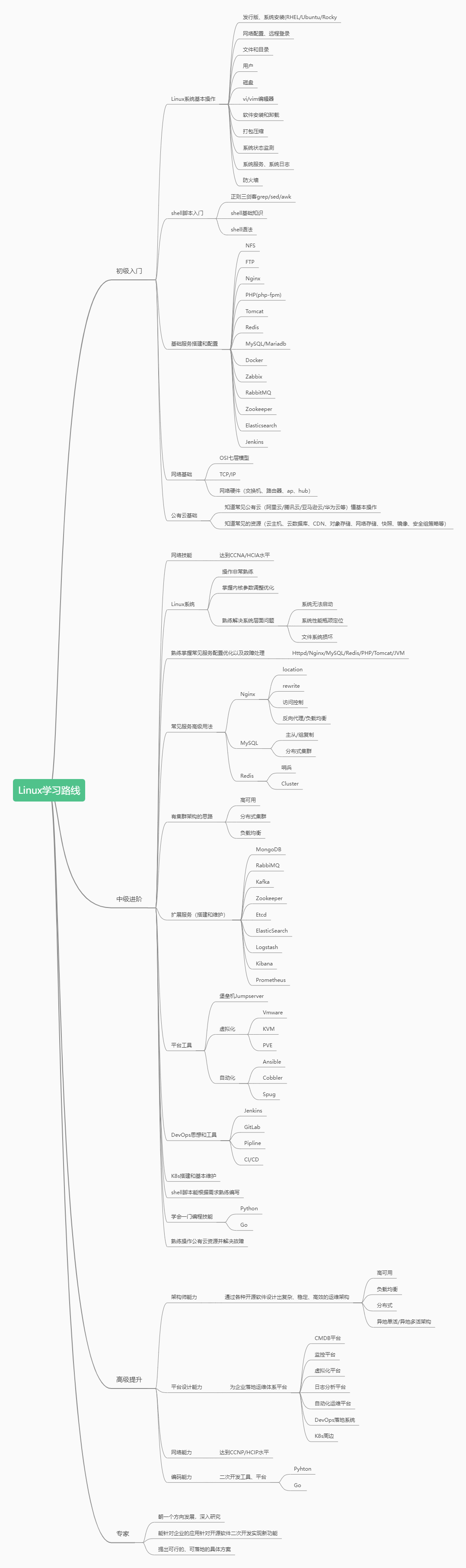
如上图,第二阶段目标如下:
● Linux系统相关操作非常熟练,掌握内核参数调优,熟练解决系统层面问题(系统无法启动、文件系统损坏、系统性能瓶颈定位)
● 对常见服务配置优化以及故障处理非常熟悉(Httpd、Nginx、PHP、MySQL、Redis、Tomcat、JVM等)
● 常见服务的高级用法:Nginx、MySQL高可用以及集群、Redis高可用以及集群
● 有集群架构的思路(高可用、负载均衡、分布式)
● 扩展服务:MongoDB、RabbiMQ、Kafka、Zookeeper、Etcd、ElasticSearch、Prometheus等
● 堡垒机(Jumpserver)、虚拟化(KVM、Vmware、PVE)、自动化(cobbler、Ansible、Spug)
● DevOps思想和工具使用(Jenkins、GitLab、Pipline、CI/CD)、K8s搭建和基本的维护
● Shell脚本可以熟练编写需求
● 掌握一门编程语言Python/Go,不求写项目,但会用,能实现局部功能(如写脚本工具、简单的二次开发)
● 熟练操作公有云资源并解决故障
当前大环境下,大多数人都难,而且短期内(一两年)恐怕不会很快转好,所以要想竞争过别人,唯有让自己技术过硬!