论文地址:https://ieeexplore.ieee.org/document/9355309
源码地址:https://github.com/google-research/sputnik
背景
深度神经网络由大量的矩阵乘法运算和卷积运算组成,这些运算中使用的矩阵可以转化成稀疏矩阵,同时不损失模型的精度。这样就可以在准确率不变的情况下提升浮点运算效率,提高推理速度。例如可以用稀疏化算法生成神经网络,该网络中的权重矩阵是稀疏矩阵,其中大部分权重是0,用CSR格式存储,使用稀疏线性代数核加速运算,这已经被用于transformer架构的自注意力机制的加速运算。此外,利用稀疏性还可以在计算成本固定的情况下训练更大的模型来提高预测精度,在这种情况下训练过程中的所有计算都直接作用在矩阵的稀疏表示上。
然而现有的GPU等加速器上缺乏有效的kernel来进行稀疏矩阵运算,因此稀疏性很难用在实际应用中。此外在现有的并行架构上,稀疏线性代数核的性能会随着稀疏矩阵的性质(非0值的位置和稀疏度)发生显著变化,而现有的稀疏线性代数核主要针对科学计算中的稀疏矩阵做了优化,这些矩阵非常稀疏,其稀疏度在99%以上。而深度学习中稀疏矩阵并没有那么稀疏(为了保持预测精度),所以现有的稀疏线性代数核在深度学习中的效果并不好。深度学习中的稀疏矩阵和科学计算中的稀疏矩阵对比结果如下图所示,可以看到二者有很大不同。
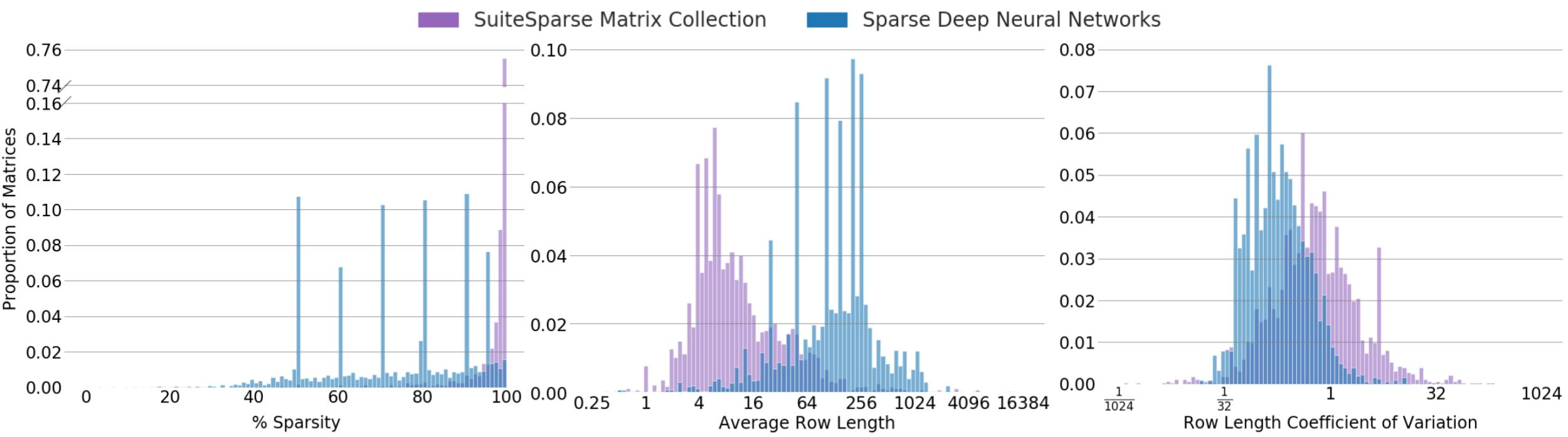
深度学习中使用的稀疏矩阵运算有两种,稀疏矩阵-矩阵乘(SPMM)和采样稠密-稠密矩阵乘(SDDMM)。SPMM的计算公式为AB⇒C,其中A是稀疏矩阵,B和C是稠密矩阵。SDDMM的计算公式为AB⊙C⇒D,其中A和B是稠密矩阵,C和D是稀疏矩阵。本文实现的是SDDMM在深度学习反向传播的特例,即如果C在某位置的元素非0则认为是1。
相关工作
目前已经有一些工作在GPU上实现高效的稀疏矩阵乘法,包括高效的稀疏矩阵存储格式、kernel设计原则、矩阵分片技术,本文在设计和实验部分对这些方法做了介绍并对比了性能。此外还有一些在CPU上实现的高效稀疏矩阵乘法,并把算法应用到特定领域,例如高效的稀疏Winograd卷积算法和移动处理器上的高效神经网络。
本文贡献
本文对大量的深度学习中的稀疏矩阵进行了分析,确定了可以加速计算的部分。
本文提出了一维tiling技术用于分解计算,这有助于重用操作数和提高可扩展性。
本文提出了两种技术:subwarp tiling和反向偏移内存对齐,这使得在稀疏结构中未对齐的内存地址上可以使用向量内存指令。
本文提出了行交换负载均衡策略,它是一种独立于特定并行方案的处理单元间负载均衡的方法。
问题和解决方案
分层一维tiling
这部分介绍了稀疏矩阵的分片方案,本文的思想改进自论文《Design Principles for Sparse Matrix Multiplication on the GPU》中的row-splitting,原文介绍的分片方案是把一个block映射到稀疏矩阵的多行(下图黄色部分),用每个warp加载稀疏矩阵的每一行,用每个线程加载稠密矩阵的每一列,如下图所示:
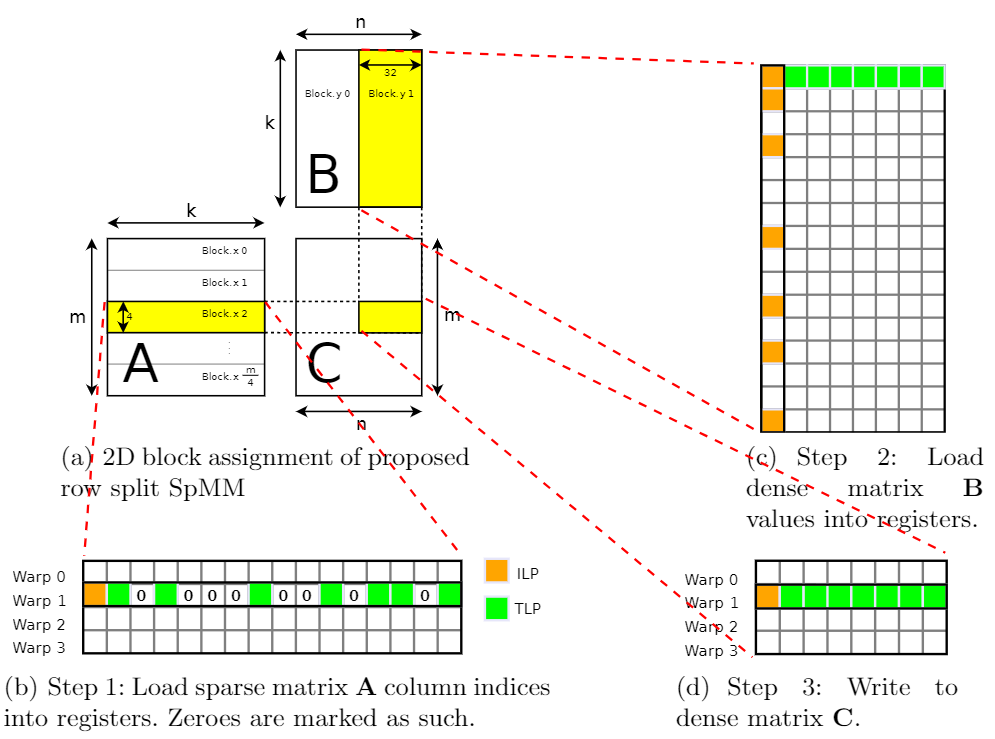
其中橙色表示ILP(指令级并行),绿色表示TLP(线程级并行)。
本文发现在深度学习中稠密矩阵的列数随着问题不同有很大的差异,因此把block映射到稀疏矩阵的一整行会导致block的大小不固定,因此本文把输出划分为多个tile,把block映射到每个tile,这样使得block的大小固定,有利于应对不同的问题,同时可以进行循环展开等进一步优化。对于m和k较小的问题还可以启用更多的block,可以提高GPU占用率。本文的划分方案如下图所示:
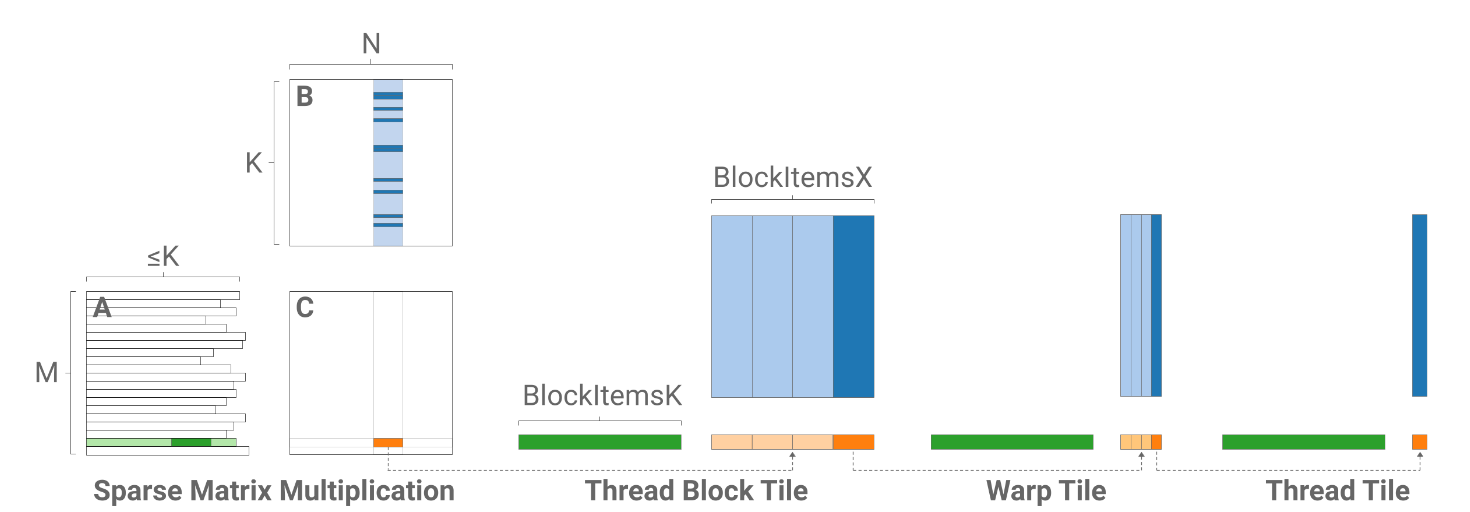
其中从左到右分别是乘法级别、block级别、warp级别和Thread级别。每个级别中深色的部分表示下个级别中使用的数据。可以看到在乘法级别每个block计算C中的一个tile,长度为BlockItemsX。每个block加载A的一整行和B中的深色部分(对应A非0位置)。在Block、Warp和Thread级别对列进行了划分。下面的伪代码展示了分层一维tiling算法:

向量内存操作
使用向量内存指令可以减少内存操作,但是在稀疏矩阵中使用向量内存指令存在两个问题,第一个是向量指令会同时加载多个操作数,例如在一个warp中使用宽度为4的向量指令会同时加载128个浮点数,而如果稀疏矩阵的行长小于128或者稠密矩阵的列长小于128就会出现predicated off,这限制了向量指令的使用。第二个问题是稀疏矩阵的内存对齐。因为稀疏矩阵的行长不是固定的,所以每一行的起始地址可能没有对齐。
针对第一个问题本文提出了Subwarp Tiling,即可以把每个warp的子集(subwarp)映射到输出矩阵的独立一维tile中,这样就减少了指令宽度带来的限制。而且这样做还可以在稠密矩阵列数较少的情况下把线程分布到输出矩阵的多个行中。一个问题是当subwarp处理输出矩阵的不同行时不能重用从稠密矩阵加载的值,但是不同的subwarp之间可能存在局部性,可以利用缓存。这种方法的主要缺点是加载不同长度的行会导致warp divergence,会造成warp中线程之间的负载不均衡。
针对第二个问题本文提出了反向偏移内存对齐(ROMA,reverse offset memory Alignment),该方法在每个block加载行偏移量并计算完行长度之后把偏移量递减到最近的对齐位置,并更新它要处理的非0数。为了保持正确性,在主循环第一次迭代中累加结果之前线程会不计算从前一行加载的任何值。ROMA方法不需要显式地填充稀疏矩阵,只是利用了前一行中的值,因此非常高效,只需要使用6条PTX指令就能实现。
Subwarp Tiling和ROMA方法的示意图如下:

图中的箭头表示warp要加载的位置,可以看到当行长小于加载数量时会出现predicted off(图中的×),而使用subwarp tiling可以让一个warp同时加载两行数据。
图中红色带下划线的地址是非对齐的地址,在右图中对这些地址向前一行偏移,使得所有地址都对齐,右图中的标号表示经过偏移后每一行的起始位置。
Row Swizzle 负载均衡
稀疏矩阵计算的负载不平衡有两个来源:第一个是有些warp或block分配了更少的工作,这使得一些SM比其他SM运行更少的作业。第二个是warp或block内的线程负载不均衡,这可能会导致warp divergence和数学单元、内存带宽的低效使用。本文认为解决这两个问题需要对工作负载进行重新映射使得每个处理单元的工作负载大致相同。本文把这种重映射过程叫做row swizzle,本文引入了两阶段的工作重映射:Row Binning:把block映射到SM使每个SM负载均衡;Row Bunding:对于跨行的warp,重新映射使得每个subwarp接收相同数量的工作。本文的映射思路如下图所示:
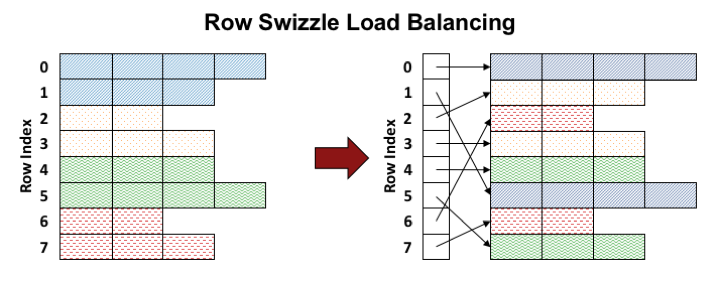
上图表示原始的分配情况,相同的颜色表示由同一个warp处理,按照row index自上而下执行。这样会导致SM之间负载不均衡和warp内线程之间负载不均衡。本文提出了一种启发式算法,如右图所示,首先把大小相近的行分到同一个bundles(用同一种颜色表示),这样能解决warp内负载不均衡。然后按照从大到小的顺序执行bundles,这样能解决SM之间的负载不均衡。
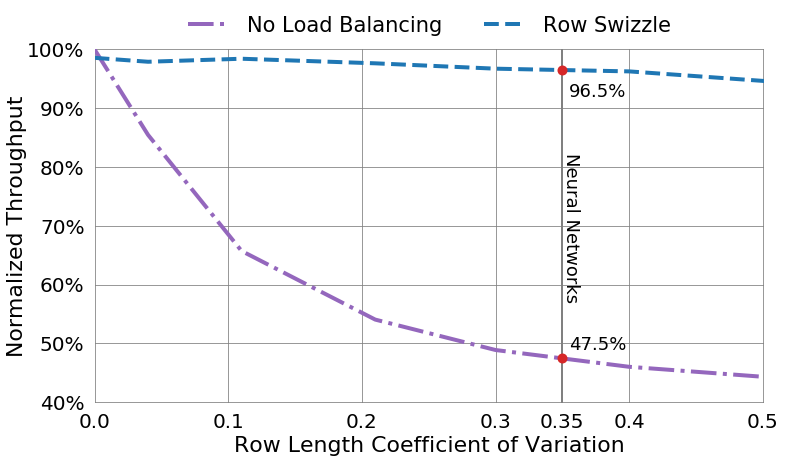
具体来说,首先创建一个数组存储row index,然后按照行的长度对row index进行排序,把长度相近的row index放入同一个bundle。第一个wave运行最长的bundles,在SM之间轮询调度。接下来的bundle按照从大到小的顺序执行。由于在深度学习中权重矩阵的拓扑通常不会发生变化,因此进行排序和分组的开销可以被分摊到多个步骤中。而且存储row index的开销相对于整个矩阵运算可以忽略不计。下图展示了使用Row Swizzle后的吞吐量对比,可以看到Row Swizzle有效地提升了吞吐量,特别是对于神经网络来说Row Swizzle保持了96.5%的吞吐量。
使用了向量内存指令和Row Swizzle方法之后的SPMM伪代码如下所示,其中深色部分为新添加的代码。

其他优化
- Index Pre-Scaling:在每个block中首先加载稀疏矩阵的值和索引到共享内存,然后由每个线程根据索引加载稠密矩阵的值,在这个过程中稀疏矩阵的行索引需要进行缩放,会产生开销。本文在加载稀疏矩阵的过程中首先对索引进行了转换,这样就不需要在加载稠密矩阵的过程中对索引进行额外的工作。
- Residue Handling:在加载稀疏矩阵时尽量使用128bit的向量内存指令把数据加载到共享内存中,然而由于稀疏矩阵的行长不固定且一般不是4的倍数,在加载完后通常会剩余一些数据,对这些剩余数据的高效处理非常重要。剩余数据处理和主循环分开,本文首先把共享内存的buffer设置成0,然后用向量内存指令加载数据,这样多出的部分为0,就不需要额外处理。另外把稠密矩阵的加载以及结果的计算分到两个循环中,并在每个循环的内循环进行无边界检查的循环展开。
- Mixed Precision:本文的方法支持混合精度计算。本文的默认使用fp32精度,在处理fp16数据时索引仍然使用16位整数,但是在进行计算时首先把fp16数据转成fp32数据,在计算完成后再转成fp16数据。
SDDMM kernel设计
-
Hierarchical 1-Dimensional Tiling:
SDDMM的一维tiling和SPMM的一维tiling相似,但是block不是映射到输出矩阵,而是映射到输出矩阵的非0区域,这是因为输出矩阵是稀疏矩阵,映射到非0区域能更好的分配线程而且易于实现。因为不能提前知道稀疏矩阵每一行非0值的个数,所以分配了足够数量的block来完成任务。每个block在启动时检查是否有工作要做,如果block不再被需要就提前返回。另一种方案是使用动态并行(dynamic parallelism),但是在测试中并没有发现动态并行的效果比分配足够数量的block更好,文中认为可能在矩阵更加稀疏时效果更好。第二个不同是SDDMM要对第二个稠密矩阵进行转置,因为两个稠密矩阵都是以行优先的方式存储,直接计算会导致非合并内存访问。本文并没有直接对共享内存中加载的右侧矩阵的值进行转置,因为这会消耗更多共享内存,而共享内存和L1缓存使用相同的空间,这样做就会导致L1缓存减少,从而极大影响程序的性能。本文的方案是映射到同一个tile的每个线程计算一部分值,然后通过warp shuffle指令进行规约,从而计算出最终值。
-
向量内存操作:
因为两个输入矩阵都是稠密矩阵,所以使用向量内存指令很容易。对于稀疏矩阵则使用标量加载,因为稀疏矩阵只在开始和结束时使用,所以不会显著影响性能。为了能更广泛地使用向量内存指令,SDDMM也使用了SPMM中的subwarp方法。 -
剩余数据处理:
因为SDDMM主要是稠密矩阵操作,所以计算的长度是相等的。负载均衡不是很重要,而且因为神经网络中的矩阵大多能被SIMT的宽度整除,所以剩余数据的处理也不是很重要。剩余数据的处理和主循环相同,没有使用循环拆分和循环展开进行优化。
实验验证
Kernel测试
Kernel测试分为稀疏矩阵乘测试和稀疏神经网络测试。
稀疏矩阵乘测试中使用的数据集来自ResNet-50的卷积操作,首先把卷积操作用im2col转成矩阵乘法,然后进行测试,数据集中共有3102个矩阵。测试平台是nVidia V100,benchmark是cuSPARSE库中的cusparseSpMM和cusparseConstrainedGeMM。因为cuSPARSE库中使用列优先,所以需要先用cuBLAS库进行显式转置操作,并记录在总时间内。测试结果如下图所示:
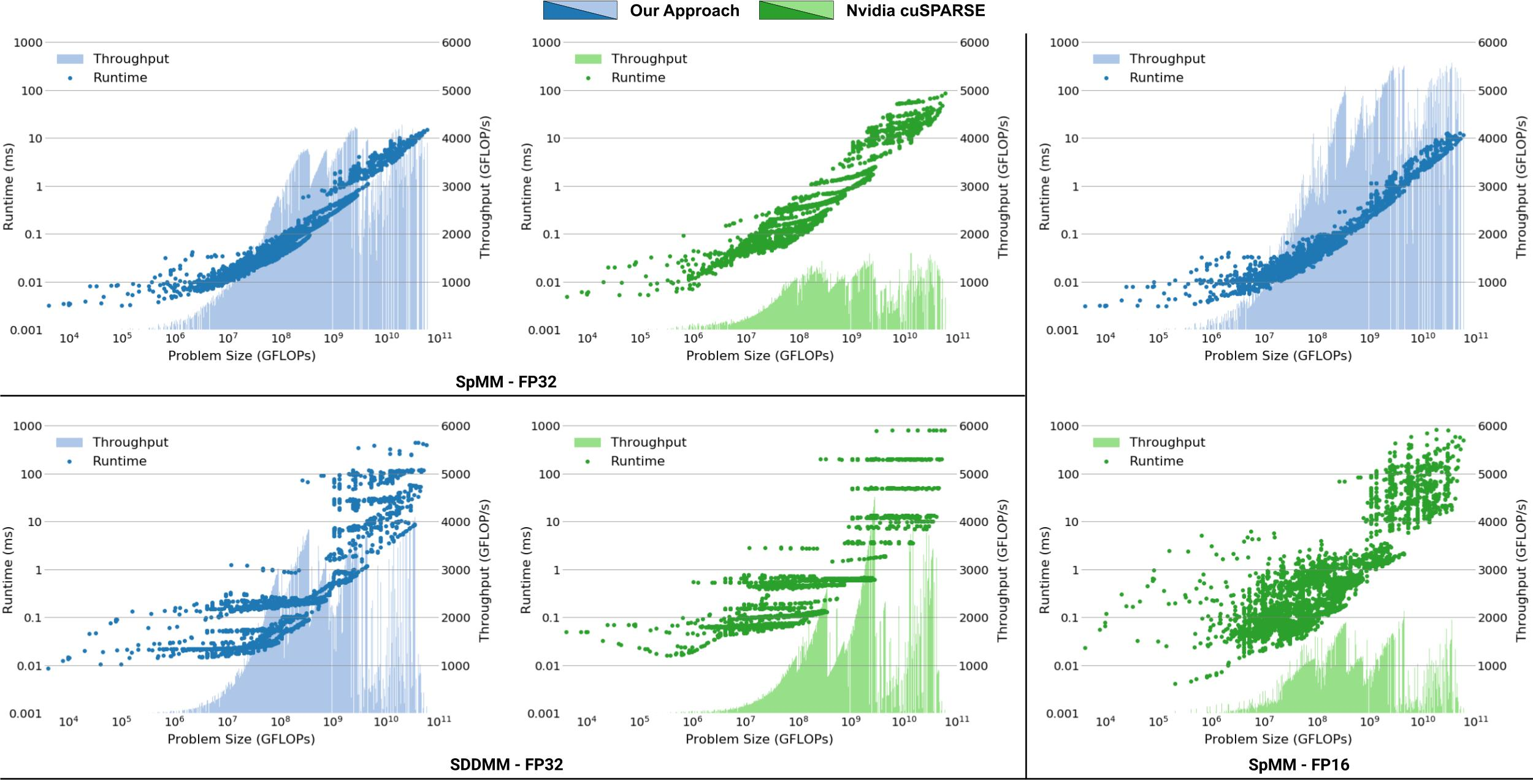
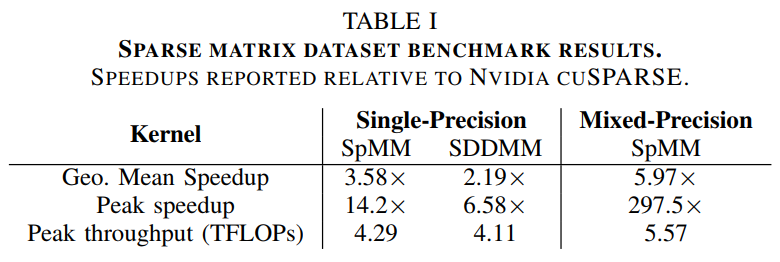
把本文的方法和cuSPARSE在运行时间和吞吐量上进行对比,可以看到本文的方法在FP32和FP16精度下效果都好于cuSPARSE中的实现。具体加速比见下表,可以看到本文的方法有了很大提升。
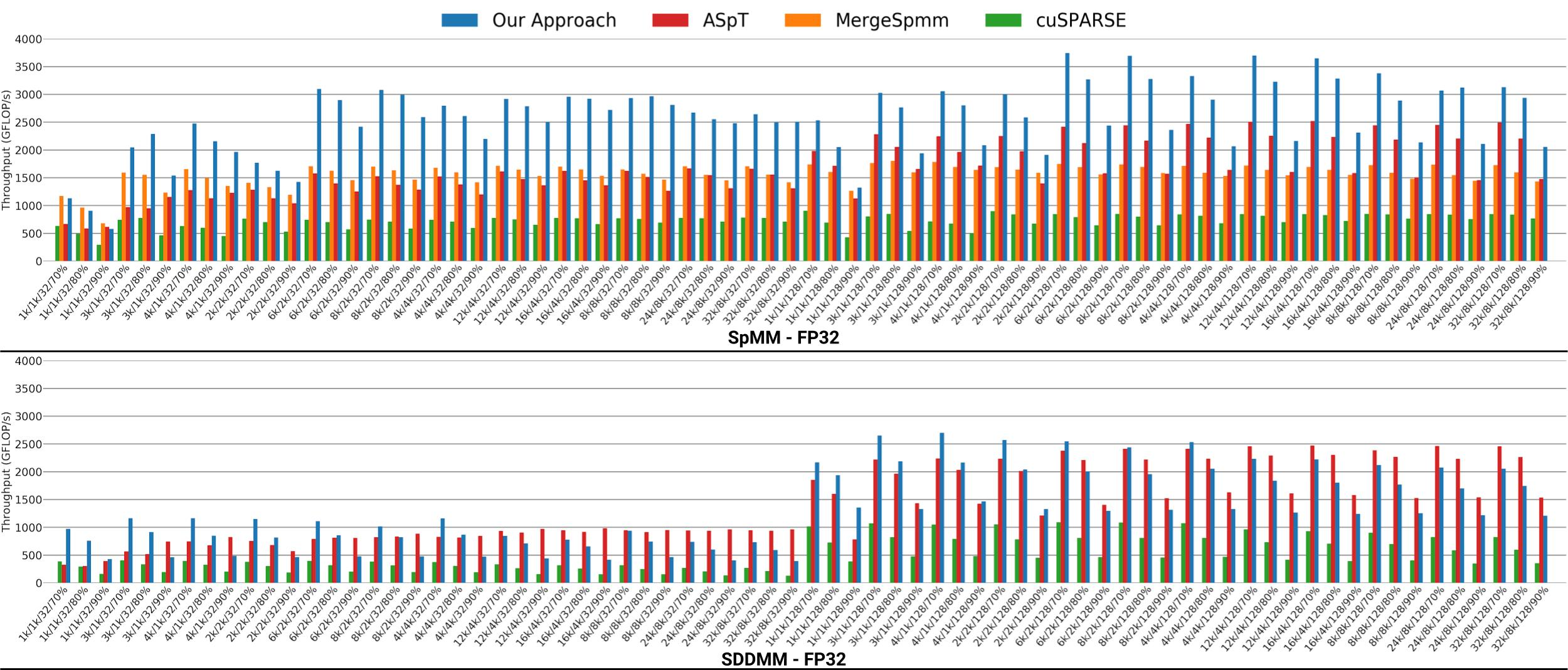
稀疏神经网络测试在RNN、GRU、LSTM三种神经网络上测试,对这三个神经网络用random uniform sparsity算法进行稀疏化,测试使用的state size分别为1k、2k、4k和8k,稀疏度分别为70%、80%和90%,batch size分别为32和128。测试设备为NVidia V100,比较对象为cuSPARSE库、论文《Design Principles for Sparse Matrix Multiplication on the GPU》中提出的MergeSpmm和论文《Adaptive sparse tiling for sparse matrix multiplication》中提出的ASpT。
比较结果如下图所示,可以看到本文的方法在SPMM上的效果要好于其他三种方法,在SDDMM上的效果与ASpT相同,且优于其他两种方法。
消融实验
这部分研究了使用不同的技术对加速效果的影响,实验结果如下表所示
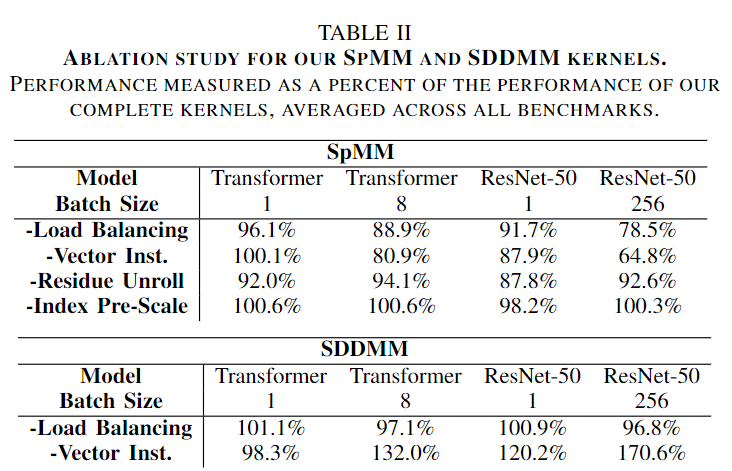
由上表可以看出在SpMM去掉Load Balancing和Vector Inst.之后性能出现了明显下降,说明这两种技术对SpMM的性能影响很大。而Residue Unroll影响较小,Index Pre-Scale影响最小。在SDDMM中Vector Inst.出现了异常值,取消向量化反而提升了性能,文中认为这些权重矩阵比较小,使用标量可以使每个线程处理更少的数据,因此可以对矩阵的大小使用启发式算法来提高性能。
应用:稀疏transformer
Transformer架构是一种流行的深度学习架构,它的公式为
Atrention(Q,K,V)=Softmax((QK^T)/√(d_k ))V
其中Q是query,K是key,V是value,d_k是序列中每个元素的特征数。上述计算中复杂度最高的是QK^T的计算,因此需要稀疏化来减少计算量。目前已经有很多工作对稀疏化transformer进行了研究。稀疏化之后的计算用到了SPMM和SDDMM。
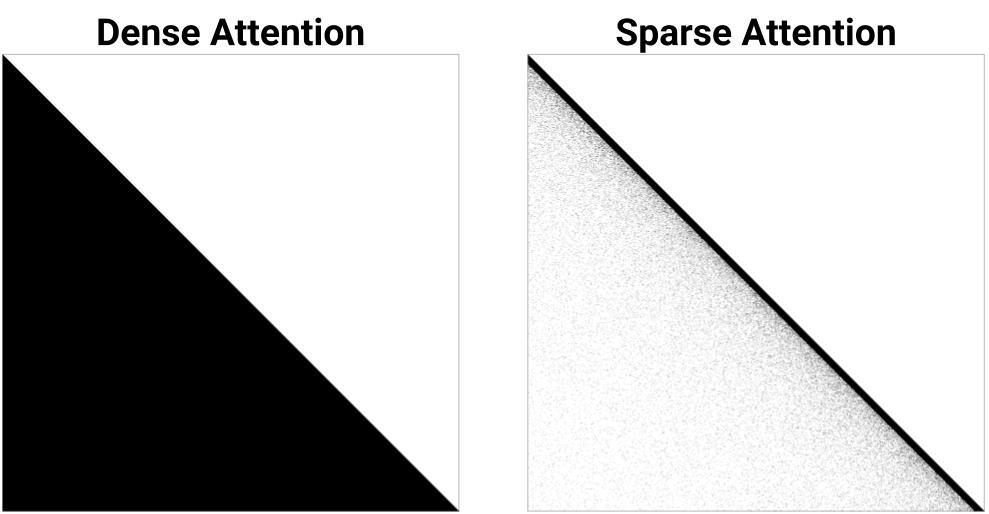
本实验在ImageNet-64×64上训练了一个带有稀疏注意力机制的transformer,数据集序列长度为12888,模型有三层,每层有8个注意力头,隐含层维度是1024,滤波器的尺寸为4096。训练时的batch size为8,共训练14000步,在训练过程中转换为稀疏表示,稀疏注意力如下图所示,黑色表示非0区域,白色表示0,仅下三角部分有数据,在非对角线区域进行稀疏化,离对角线越远稀疏化程度越高。
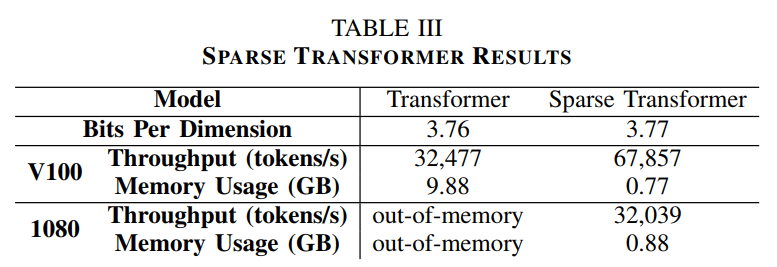
训练结果如下表所示,相比标准transformer,稀疏化的transformer在V100和1080上的吞吐量更高,且使用内存大幅减少。
应用:Sparse MobileNetV1
MobileNetV1是一种用于计算机视觉的高效卷积神经网络,它由深度可分离卷积(Depthwise Separable Convolution)组成,深度可分离卷积包括两个阶段:深度卷积(depthwise convolution) 和 逐点卷积(pointwise convolution),其中逐点卷积和普通的卷积相同,只是卷积核的尺寸为1×1,在深度卷积和逐点卷积后面都跟着一个批量归一化操作和一个ReLU操作。本实验把稀疏性引入到了1×1卷积中。
在实验中使用magnitude pruning算法将除了第一层之外的1×1卷积的稀疏性设置为90%。在训练阶段使用了32个加速器在ImageNet上训练了100个epoch,本实验主要关注推理阶段的性能,因此对训练阶段时间没有要求,所以在实验中把训练阶段的时间延长了10倍来使模型收敛。
在推理阶段把深度卷积和逐点卷积的所有的批量归一化操作融合到前面的线性操作中,把偏置操作和ReLU操作融合到一起。对于baseline中的普通1×1卷积使用nVidia cuBLAS进行加速运算,在baseline中也融合了偏置和ReLU。在稀疏模型中的四个1×1卷积操作上使用oracle kernel selector代替了本文的启发式算法,因为本文的启发式算法在这四个卷积上性能不是最优的。
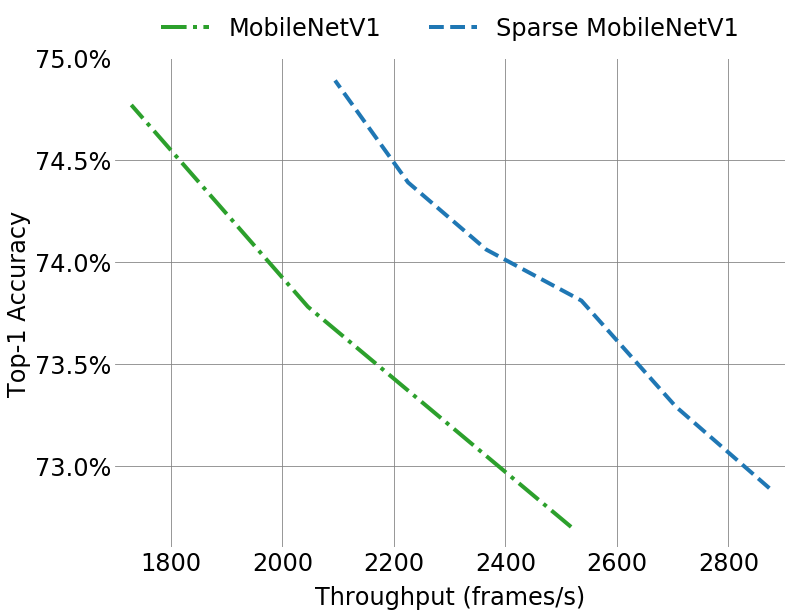
实验结果如下图所示,可以看到稀疏化的MobileNetV1相比普通的MobileNetV1在相同精度的情况下能提高吞吐量,在吞吐量相同的情况下精度更高。
具体对比结果如下表所示
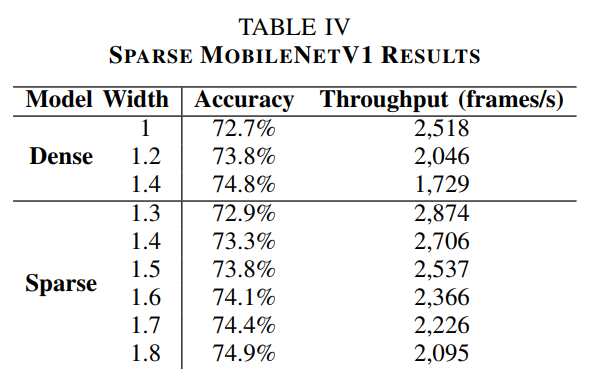
由表中可以看出稀疏模型相比密集模型在达到相同的精度时需要更大的宽度(即channel数),这是因为对模型进行稀疏化降低了模型的精度,而更大的宽度又需要更多的计算,因此好的稀疏化算法对提高精度、降低计算量非常重要。本文在实验中发现深度卷积成为性能瓶颈,因此对深度卷积的优化是未来的一个方向。
启发
本文介绍了一种高效的GPU上的稀疏矩阵算法,并把它应用在神经网络的稀疏化上。神经网络稀疏化是训练大规模神经网络的一种重要的方法,它通过对权重矩阵的采样来减少神经网络内存占用,从而能在计算成本一定的情况下训练更大规模的网络。因此设计高效的GPU稀疏矩阵乘算法对大规模神经网络训练具有重要意义。NVidia也在A100上用硬件实现了sparse tensor core来支持神经网络稀疏化,可以看到稀疏化是未来深度学习发展的一个重要方向。
- learning kernels sparse 论文 deeplearning kernels sparse论文 deep-learning deep-learning-based learning deep loss learning smooth deep nature-deep learning nature deep non-deep learning machine notes reinforcement introduction learning deep spatio-temporal-spectral deep-learning-based optimization learning deep for