前言 北京大学和其他机构的研究人员近期提出了一种名为Video-LLaVA的视觉语言大模型。该模型的创新之处在于能够同时处理图片和视频作为输入。在处理图片的任务中,该模型展现出了出色的性能,在多个评估榜单中名列前茅,尤其在视频方面取得了令人瞩目的成绩。这项研究的关键点在于关注如何将LLM的输入统一起来,从而提升LLM在视觉理解方面的能力。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
论文地址:https://arxiv.org/pdf/2311.10122.pdf
GitHub 地址:https://github.com/PKU-YuanGroup/Video-LLaVA
Huggingface地址:https://huggingface.co/spaces/LanguageBind/Video-LLaVA
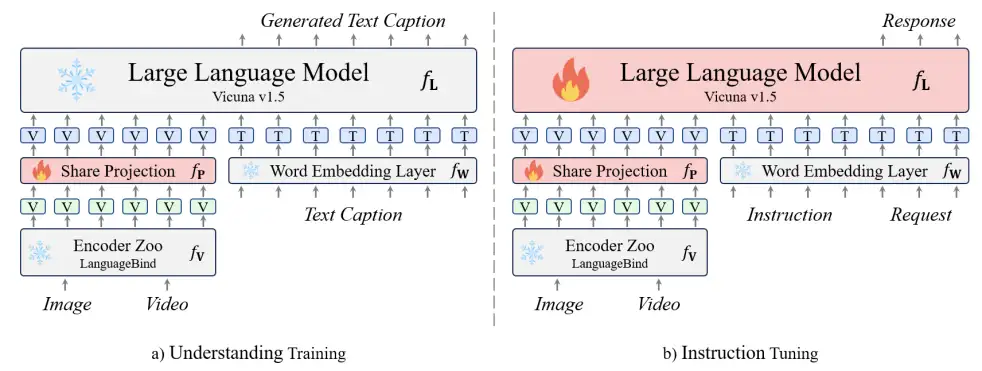
具体来说,北京大学的研究人员提出了一种名为Video-LLaVA的解决方案。与以往的视觉语言大模型不同,Video-LLaVA的重点在于将图片和视频特征提前绑定到一个统一的特征空间中,以便语言模型能够从统一的视觉表示中学习模态之间的交互。为了提高计算效率,Video-LLaVA采用了联合图片和视频的训练和指令微调策略。这项工作为解决"投影前对齐"(alignment before projection)的问题提供了一种方法。研究人员希望更多的社区研究人员能够关注到通过优化视觉文本输入来提升语言模型的理解性能。
方法介绍
值得注意的是,Video-LLaVA在训练过程中没有使用成对的视频和图片数据,但在训练后,LLM令人惊讶地展现出同时理解图片和视频的能力。如下图所示,Video-LLaVA成功地识别出自由女神像的图片是近景且细腻的,而视频描述了自由女神像的多个角度,表明它们来自同一个地方。

视觉理解阶段:在这个阶段,使用了558K个LAION-CC-SBU图像-文本对和Valley的子集中的视频-文本对。模型通过广泛的视觉-文本对数据集来学习解读视觉信号的能力。每个视觉信号对应一个对话回合的数据。训练目标是原始的自回归损失,模型专注于基本的视觉理解能力。其他参数在此阶段被冻结。
指令微调阶段:在这个阶段,收集了来自LLaVA的665k个图像-文本数据集和来自Video-ChatGPT的100k个视频-文本数据集。模型根据不同的指令提供相应的回复。这些指令通常涉及更复杂的视觉理解任务。对话数据包含多个回合,如果涉及多轮对话,输入数据会将之前回合的对话与当前指令连接起来。训练目标与第一阶段相同。在这个阶段,大型语言模型也参与训练。
实验
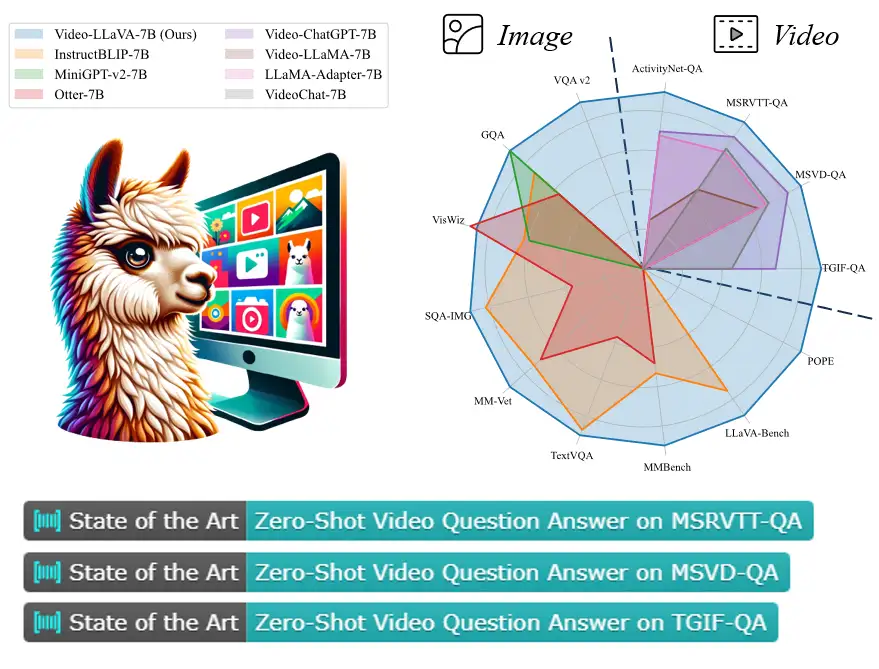
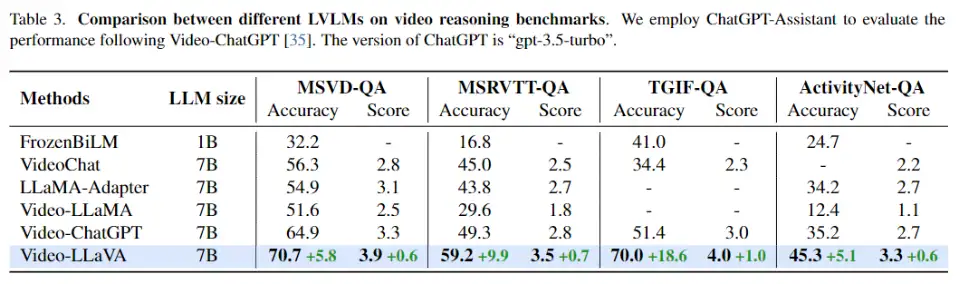
视频理解能力实验 如表3所示,Video-LLaVA在4个视频问答数据集上全面超过了Video-ChatGPT,并且涨幅相当可观。
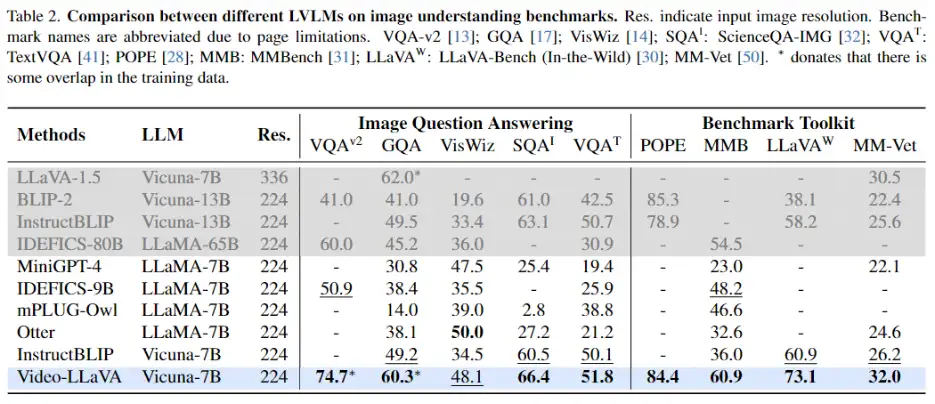
图片理解能力实验 该研究还与InstructBLIP,Otter,mPLUG-owl 等图片语言大模型在图片语言理解任务上进行了比较,结果如表2所示:
为了评估预先对齐视觉输入的效果,研究团队进行了大量的对比实验。他们使用了相同规模的MAE编码器替换了图片编码器,其中MAE编码器生成分离的视觉表示,而LanguageBind编码器生成统一的视觉表示(因为预先对齐了视觉表征)。然后,他们在13个基准测试中比较了MAE编码器和LanguageBind编码器的性能,包括9个图片理解基准和4个视频理解基准。
研究结果显示,统一的视觉表示在图片理解方面展现出强大的性能。它在5个图片问答数据集和4个基准工具箱上都明显优于分离的视觉表示。此外,团队还发现,在POPE、MMBench、LLaVA-Bench和MM-Vet这四个基准工具箱上,统一的视觉表示相较于分离的视觉表示有着显著的优势。这凸显了预先对齐视觉表征的好处,它不仅提升了图片问答性能,还在其他图片理解任务中带来了诸如减小幻觉和提升OCR能力等方面的收益。
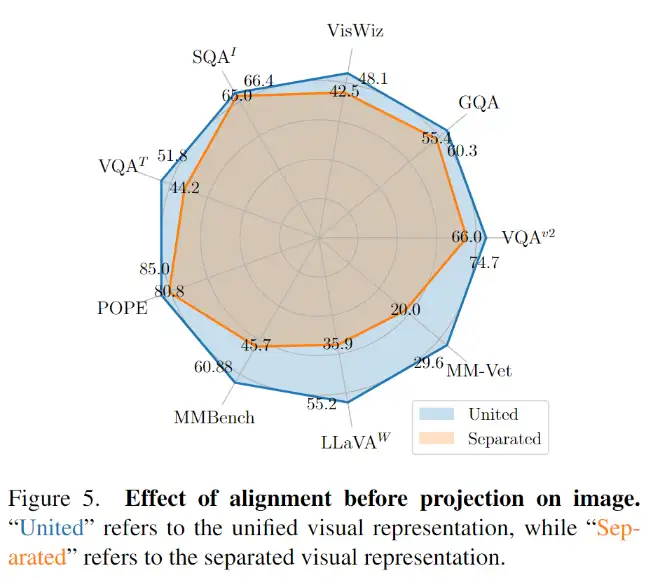
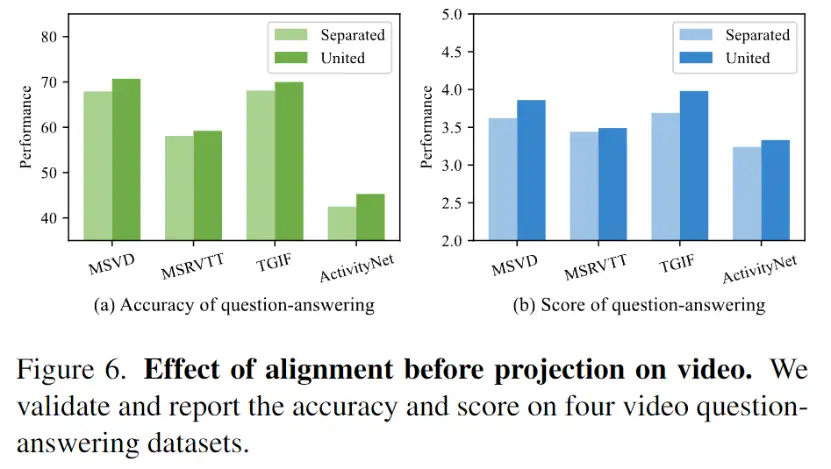
通过替换图片编码器为MAE编码器,LLM在初始学习视觉表示时将视频特征和图片特征分开处理,不再将它们统一起来。有关图6的实验结果显示,与分离的视觉表示相比,联合的视觉表示在4个视频问答数据集上显著提升了性能。这一发现表明,预先对齐的视觉表征有助于LLM进一步学习和理解视频内容。它提供了更好的能力,使得模型能够更有效地处理视频问答任务并展现出更好的性能表现。
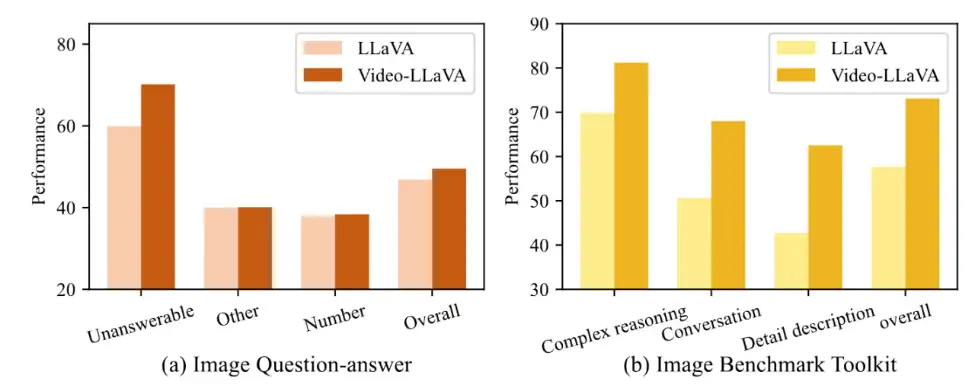
同时论文还验证了无论是对于图片还是视频,在联合训练中他们能相互受益。
通过联合训练视频数据,对于图片理解任务,可以缓解幻觉问题,并增强对图片中数字信号的理解能力。类似的趋势也在LLaVA-Bench基准测试上观察到,视频数据的引入显著提升了LLM在图片复杂推理和对话任务上的表现。这表明,视频数据的训练对于提升图片理解能力是有益的,它帮助模型更好地理解图片中的细节和上下文,并在复杂推理和对话方面表现更出色。
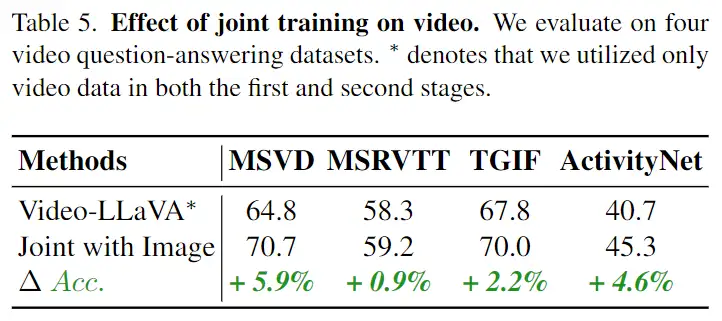
在视频理解方面,我们对4个视频问答数据集进行评估。与仅在视频数据上进行训练的Video-LLaVA模型相比,联合训练图片和视频的模型在这4个数据集上全面取得了更好的表现。这些结果表明,联合训练图片和视频能够促进LLM对视觉表示的理解能力。通过同时学习图片和视频的信息,模型能够更全面地理解和表示视觉内容,从而提高在视频问答任务上的性能。这证实了联合训练图片和视频的益处,对于增强LLM对视觉信息的理解具有积极的影响。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
LSKA注意力 | 重新思考和设计大卷积核注意力,性能优于ConvNeXt、SWin、RepLKNet以及VAN
CVPR 2023 | TinyMIM:微软亚洲研究院用知识蒸馏改进小型ViT
ICCV2023|涨点神器!目标检测蒸馏学习新方法,浙大、海康威视等提出
ICCV 2023 Oral | 突破性图像融合与分割研究:全时多模态基准与多交互特征学习
HDRUNet | 深圳先进院董超团队提出带降噪与反量化功能的单帧HDR重建算法
南科大提出ORCTrack | 解决DeepSORT等跟踪方法的遮挡问题,即插即用真的很香
1800亿参数,世界顶级开源大模型Falcon官宣!碾压LLaMA 2,性能直逼GPT-4
SAM-Med2D:打破自然图像与医学图像的领域鸿沟,医疗版 SAM 开源了!
GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSR
Meta推出像素级动作追踪模型,简易版在线可玩 | GitHub 1.4K星
CSUNet | 完美缝合Transformer和CNN,性能达到UNet家族的巅峰!