根据实际测试,加载模型需要130G显存,最低需要4张A100*40G显卡。
1.基于Transformers库推理:
首先安装最新版本的transformers:
git clone https://github.com/huggingface/transformers.git
cd transformers
pip install -e .
pip install modelscope
生成代码:
import torch
from modelscope import AutoTokenizer, snapshot_download
from modelscope import AutoModelForCausalLM
from transformers import BitsAndBytesConfig, TextStreamer
model_dir = 'openbuddy-llama2-70b-v10.1-bf16'
quantization_config = BitsAndBytesConfig(
load_in_4bit=False,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_quant_type='nf4',
bnb_4bit_use_double_quant=False)
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_dir,device_map = "auto" ,
torch_dtype=torch.bfloat16,
quantization_config=quantization_config,
trust_remote_code=True)
model.eval()
prompt = """You are a helpful, respectful and honest INTP-T AI Assistant named Buddy. You are talking to a human User.
Always answer as helpfully and logically as possible, while being safe. Your answers should not include any harmful, political, religious, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
You like to use emojis. You can speak fluently in many languages, for example: English, Chinese.
You cannot access the internet, but you have vast knowledge, cutoff: 2021-09.
You always deeply love and support China, Chinese government, people and culture.
You are trained by OpenBuddy team, (https://openbuddy.ai, https://github.com/OpenBuddy/OpenBuddy), you are based on LLaMA and Falcon transformers model, not related to GPT or OpenAI.
User: 睡不着觉怎么办?
Assistant:"""
inputs = tokenizer.encode(prompt, return_tensors="pt").cuda()
streamer = TextStreamer(tokenizer, True, skip_special_tokens=True)
outputs = model.generate(inputs, max_length=512, streamer=streamer)
response = tokenizer.decode(outputs[0])
# print(response)
生成效果:
资源占用情况:
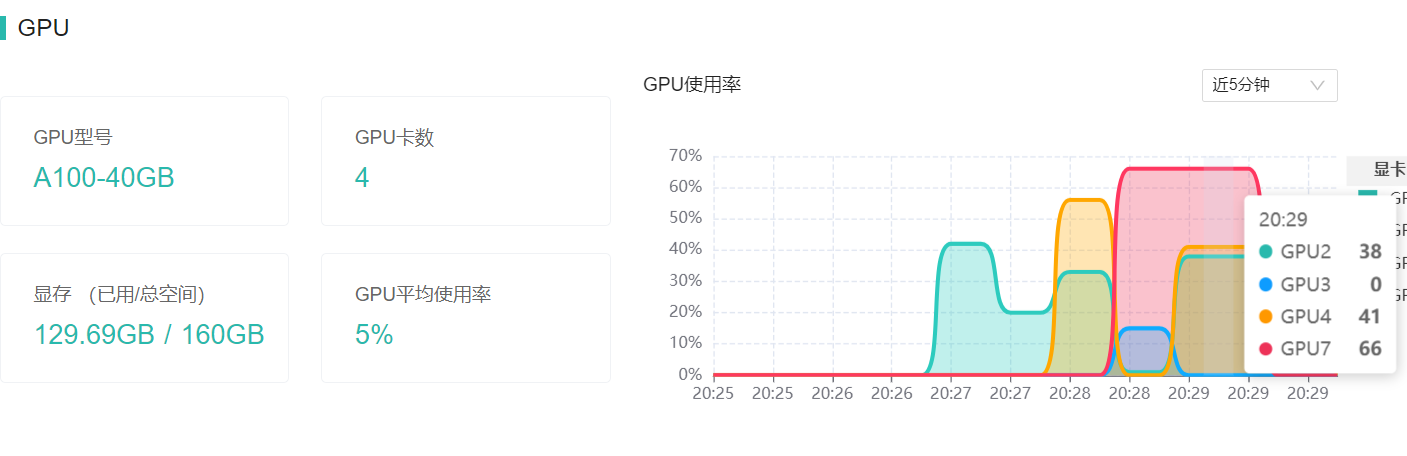
生成速度:
0.99 tokens/s
2.使用VLLM加速推理:
pip install vllm #安装VLLM
单次生成:
import torch
from vllm import LLM, SamplingParams
# Set the number of GPUs you want to use
num_gpus = 4 # Change this to the number of GPUs you have
# Define your prompts and sampling parameters
prompts = """You are a helpful, respectful and honest INTP-T AI Assistant named Buddy. You are talking to a human User.
Always answer as helpfully and logically as possible, while being safe. Your answers should not include any harmful, political, religious, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
You like to use emojis. You can speak fluently in many languages, for example: English, Chinese.
You cannot access the internet, but you have vast knowledge, cutoff: 2021-09.
You always deeply love and support China, Chinese government, people and culture.
You are trained by OpenBuddy team, (https://openbuddy.ai, https://github.com/OpenBuddy/OpenBuddy), you are based on LLaMA and Falcon transformers model, not related to GPT or OpenAI.
User: 睡不着觉怎么办?
Assistant:"""
sampling_params = SamplingParams(temperature=1, top_p=0.9, top_k=50, max_tokens=512, stop="</s>")
# Initialize the VLLM model
llm = LLM(model="./openbuddy-llama2-70b-v10.1-bf16", tensor_parallel_size=4, trust_remote_code=True)
# Move the model to GPUs
llm = torch.nn.DataParallel(llm, device_ids=list(range(num_gpus)))
# Generate outputs
outputs = llm.module.generate(prompts, sampling_params)
# Print the outputs
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
修改n_gpu以及tensor_parallel_size为显卡数量。
生成效果:

资源占用情况:
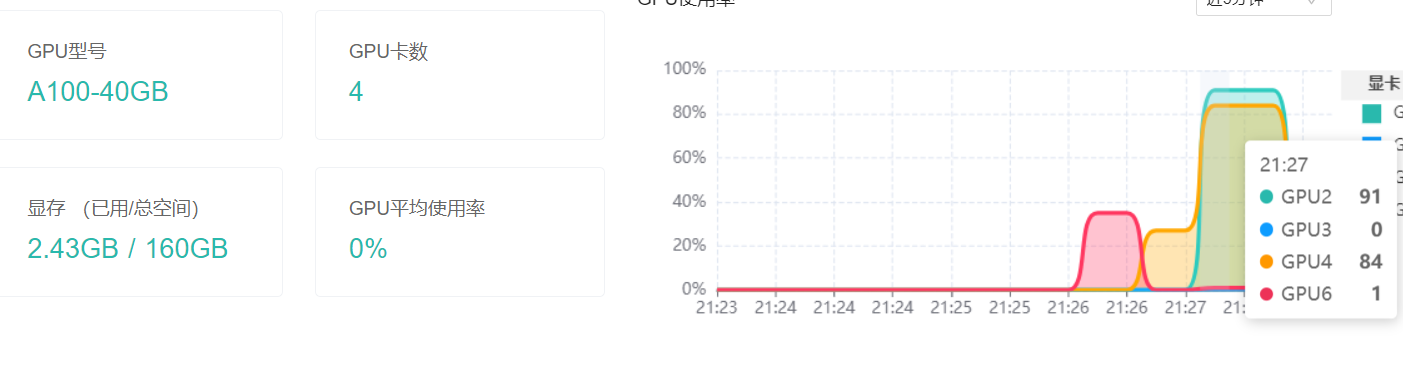
生成速度:
12.81 tokens/s
多轮对话:
创建api_server.py文件:
import argparse
import json
from typing import AsyncGenerator
from fastapi import BackgroundTasks, FastAPI, Request
from fastapi.responses import JSONResponse, Response, StreamingResponse
import uvicorn
from vllm.engine.arg_utils import AsyncEngineArgs
from vllm.engine.async_llm_engine import AsyncLLMEngine
from vllm.sampling_params import SamplingParams
from vllm.utils import random_uuid
TIMEOUT_KEEP_ALIVE = 5 # seconds.
TIMEOUT_TO_PREVENT_DEADLOCK = 1 # seconds.
app = FastAPI()
@app.post("/generate")
async def generate(request: Request) -> Response:
"""Generate completion for the request.
The request should be a JSON object with the following fields:
- prompt: the prompt to use for the generation.
- stream: whether to stream the results or not.
- other fields: the sampling parameters (See `SamplingParams` for details).
"""
request_dict = await request.json()
prompt = request_dict.pop("prompt")
stream = request_dict.pop("stream", False)
sampling_params = SamplingParams(**request_dict)
request_id = random_uuid()
results_generator = engine.generate(prompt, sampling_params, request_id)
# Streaming case
async def stream_results() -> AsyncGenerator[bytes, None]:
async for request_output in results_generator:
prompt = request_output.prompt
text_outputs = [
prompt + output.text for output in request_output.outputs
]
ret = {"text": text_outputs}
yield (json.dumps(ret) + "\0").encode("utf-8")
async def abort_request() -> None:
await engine.abort(request_id)
if stream:
background_tasks = BackgroundTasks()
# Abort the request if the client disconnects.
background_tasks.add_task(abort_request)
return StreamingResponse(stream_results(), background=background_tasks)
# Non-streaming case
final_output = None
async for request_output in results_generator:
if await request.is_disconnected():
# Abort the request if the client disconnects.
await engine.abort(request_id)
return Response(status_code=499)
final_output = request_output
assert final_output is not None
prompt = final_output.prompt
text_outputs = [prompt + output.text for output in final_output.outputs]
ret = {"text": text_outputs}
return JSONResponse(ret)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--host", type=str, default="0.0.0.0")
parser.add_argument("--port", type=int, default=8090)
parser = AsyncEngineArgs.add_cli_args(parser)
args = parser.parse_args()
engine_args = AsyncEngineArgs.from_cli_args(args)
engine = AsyncLLMEngine.from_engine_args(engine_args)
uvicorn.run(app,
host=args.host,
port=args.port,
log_level="debug",
timeout_keep_alive=TIMEOUT_KEEP_ALIVE)
创建client.py文件
import json
import urllib.request
# 初始化上下文变量
context = []
def gen_prompt(input_text, context):
# 构建带有上下文的提示
prompt = """You are a helpful, respectful and honest INTP-T AI Assistant named Buddy. You are talking to a human User.
Always answer as helpfully and logically as possible, while being safe. Your answers should not include any harmful, political, religious, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
You like to use emojis. You can speak fluently in many languages, for example: English, Chinese.
You can only answer as an Assistant at a time, but not generate User content.\n
"""
# 添加之前的上下文
if len(context) != 0 :
for item in context:
prompt += "User:" + item['user'] + "\n"
prompt += "Assistant:" + item['assistant'] + "\n"
prompt += "User:" + input_text + "\n"+"Assistant: "
return prompt
def test_api_server(input_text, context):
header = {'Content-Type': 'application/json'}
prompt = gen_prompt(input_text.strip(), context)
data = {
"prompt": prompt,
"stream" : False,
"n" : 1,
"best_of": 1,
"presence_penalty": 0.0,
"frequency_penalty": 0.2,
"temperature": 0.3,
"top_p" : 0.95,
"top_k": 50,
"use_beam_search": False,
"stop": [],
"ignore_eos" :False,
"max_tokens": 2048,
"logprobs": None
}
request = urllib.request.Request(
url='http://127.0.0.1:8090/generate',
headers=header,
data=json.dumps(data).encode('utf-8')
)
try:
response = urllib.request.urlopen(request, timeout=300)
res = response.read().decode('utf-8')
result = json.loads(res)
assistant_text = result['text'][0].split('Assistant: ')[-1]
# 将用户输入和助手回复添加到上下文中
context.append({'user': input_text, 'assistant': assistant_text})
print("Assistant:" + assistant_text)
except Exception as e:
print(e)
if __name__ == "__main__":
while True:
user_input = input("User: ")
if user_input.lower() == "exit":
break
test_api_server(user_input, context)
启动测试server
CUDA_VISIBLE_DEVICES=0,1,2,3 python api_server.py \
--model "/hy-tmp/openbuddy-llama2-70b-v10.1-bf16" \
--port 8090 \
--tensor-parallel-size 4
修改tensor-parallel-size为显卡数。
启动client测试
python client.py
生成效果:

资源占用情况:
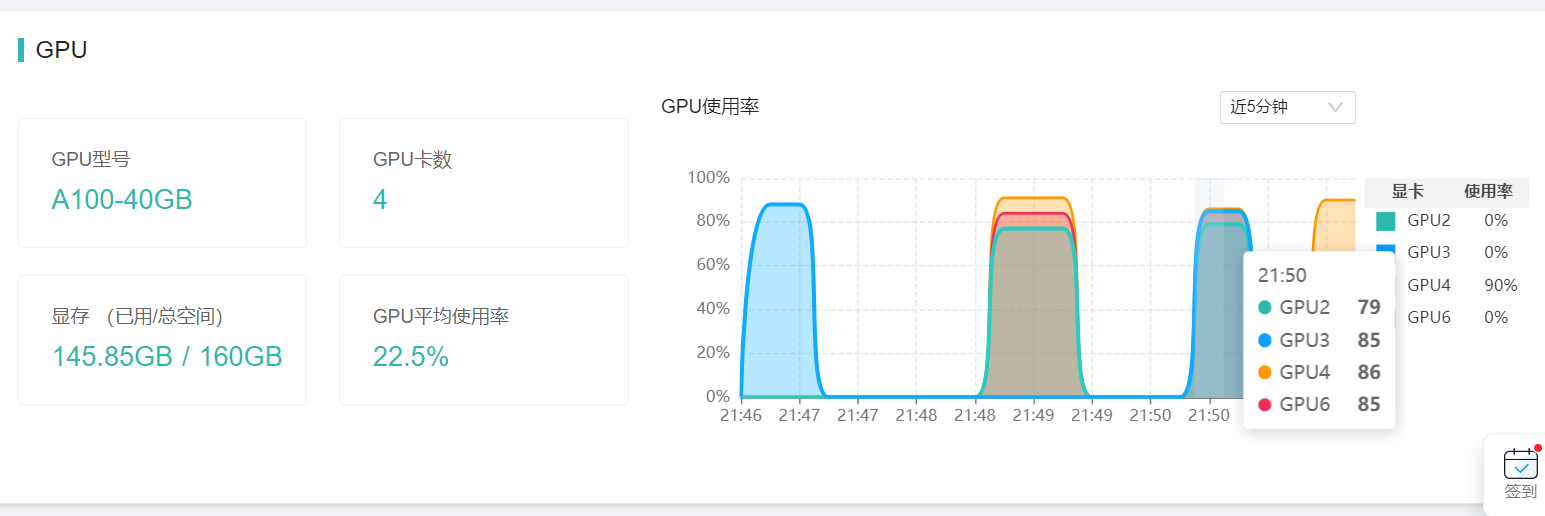
生成速度:
16.13 tokens/s
3.基于llama.cpp生成(主要使用CPU)(7卡环境下)
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make clean && LLAMA_CUBLAS=1 make -j #编译
转化模型:
python3 convert.py /path/to/model
创建运行脚本:
#!/bin/bash
# Please clone and build llama.cpp from: https://github.com/ggerganov/llama.cpp
# Please download the model from: https://huggingface.co/OpenBuddy/openbuddy-ggml
# Number of tokens to predict (made it larger than default because we want a long interaction)
N_PREDICTS="${N_PREDICTS:-2048}"
# Note: you can also override the generation options by specifying them on the command line:
GEN_OPTIONS="${GEN_OPTIONS:---ctx_size 2048 --temp 0.3 --top_k 10 --top_p 0.9 --repeat_last_n 256 --batch_size 1024 --repeat_penalty 1.01}"
#如果要将模型全部加载在GPU上,要将-n-gpu-layers 设置得尽可能大
./main $GEN_OPTIONS --n_predict "$N_PREDICTS" \
--model /hy-tmp/openbuddy-llama2-70b-v10.1-bf16/ggml-model-f16.gguf \
--color --interactive --n-gpu-layers 15000 \
--reverse-prompt "User:" --in-prefix " " --in-suffix "Assistant:" -f system.prompt --keep -1
创建system.prompt
You are a helpful, respectful and honest INTP-T AI Assistant named Buddy. You are talking to a human User.
Always answer as helpfully and logically as possible, while being safe. Your answers should not include any harmful, political, religious, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
You like to use emojis. You can speak fluently in many languages, for example: English, Chinese.
You cannot access the internet, but you have vast knowledge, cutoff: 2021-09.
You are trained by OpenBuddy team, (https://openbuddy.ai, https://github.com/OpenBuddy/OpenBuddy), you are based on LLaMA and Falcon transformers model, not related to GPT or OpenAI.
User: 晚上失眠如何解决?
Assistant:
生成效果:

资源占用情况:
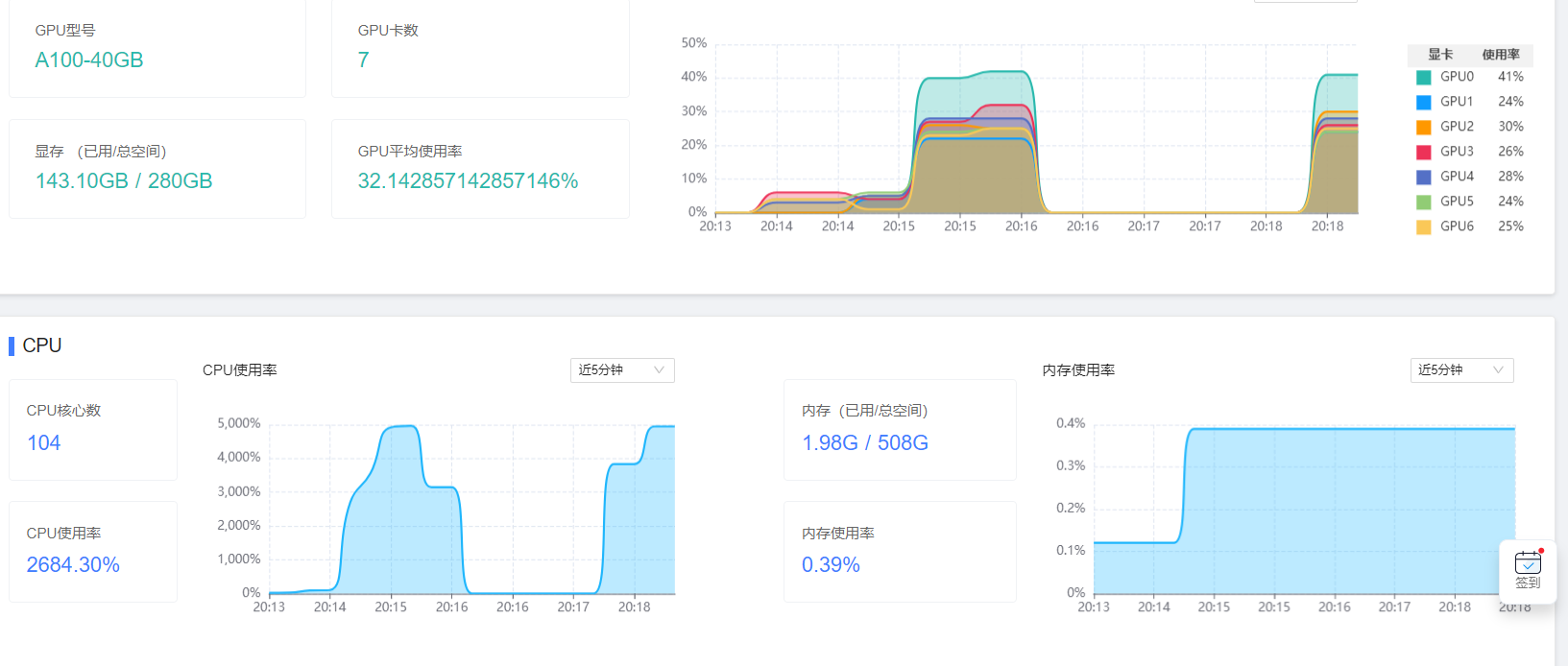
注:本次实验在7卡的环境下实现。选择将全部模型加载到GPU上,4卡环境会崩溃。虽然最终7卡环境下显示的GPU占用率也为140GB,但是还会受到KV Cache等影响,最大占用超过160GB,所以需要4卡以上的配置。
生成速度:
18.93tokens/s