SparkSQL
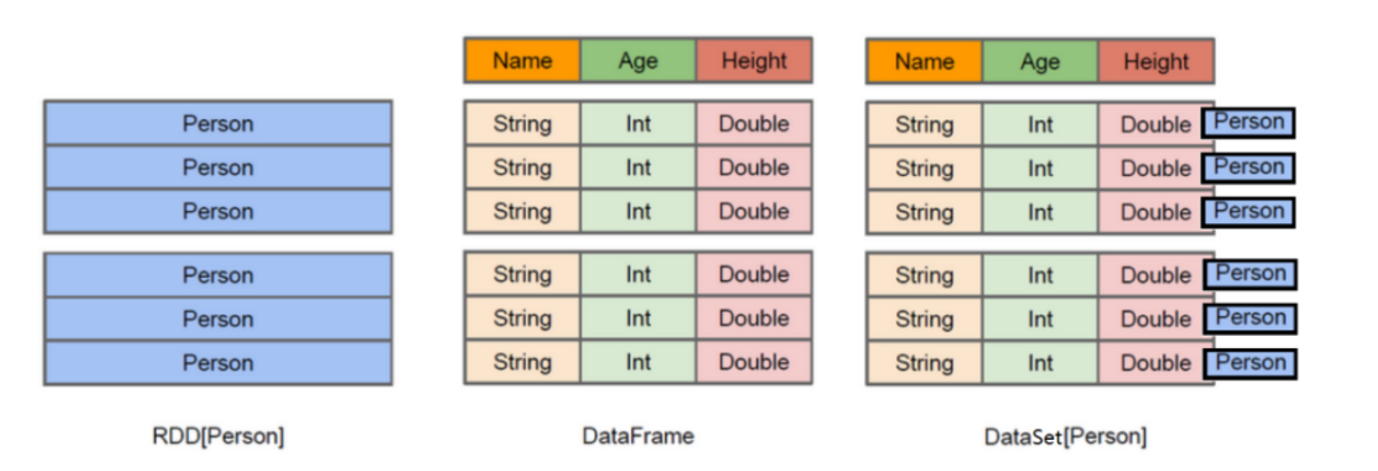
数据抽象
SparkCore 的数据抽象:RDD
SparkStreaming 的数据抽象:DStream,底层是RDD
SparkSQL 的数据抽象:DataFrame 和 DataSet,底层是RDD
泛型
泛型:是一种把明确类型的工作推迟到创建对象或者调用方法的时候才去明确的特殊的类型。也就是说在泛型使用过程中,操作的数据类型被指定为一个参数,而这种参数类型可以用在类、方法和接口中,分别被称为
泛型类、泛型方法、泛型接口。
注意:一般在创建对象时,将未知的类型确定具体的类型。当没有指定泛型时,默认类型为Object类型。由于ArrayList可以存放任意类型的元素。例子中添加了一个String类型,添加了一个Integer类型,再使用时都以String的方式使用,导致取出时强制转换为String类型后,引发了ClassCastException,因此程序崩溃了。 这显然不是我们所期望的,如果程序有潜在的错误,我们更期望在编译时被告知错误,而不是在运行时报异常。而为了解决类似这样的问题(在编译阶段就可以解决),在jdk1.5后,泛型应运而生。让你在设计API时可以指定类或方法支持泛型,这样我们使用API的时候也变得更为简洁,并得到了编译时期的语法检查。 我们将第一行声明初始化ArrayList的代码更改一下,编译器就会在编译阶段就能够帮我们发现类似这样的问题。现在再看看效果。 ArrayList<String> arrayList = new ArrayList<>();
DataFrame
DataFrame = RDD - 泛型 + Schema约束(指定了字段名和类型) + SQL操作 +优化
DataFrame 就是在RDD的基础上做了进一步的封装,支持SQL操作!
DataFrame 就是一个分布式表。
DataSet
DataSet = DataFrame + 泛型
DataSet = RDD + Schema约束(指定了字段名和类型) + SQL操作 +优化
DataSet 就是在RDD的基础之上做了进一步的封装,支持SQL操作!
DataSet 就是一个分布式表!
有类型和无类型的API

注意:因为Python和R没有编译时类型安全,所以我们只有称之为DataFrame的无类型API。
DataFrame 是特殊的 DataSet,从概念上来说,你可以把DataFrame当作一些通用对象Dataset[Row]的集合的一个别名,而一行就是一个通用的无类型的JVM对象。
df没有泛型,不能直接使用split
案例一:加载数据成分布式表
{"name": "jack","tel": "1388888888"}
{"name": "jack","tel": 13888888888,"age":18}
{"name": "jack","tel": "1388888888","age": "18"}
package com.gtja.spark.sparksql
import org.apache.spark.sql.{DataFrame, SparkSession}
/*
* @Description: 加载数据成为分布式表
* @Auther: wsy
* @Date: 2023/05/25/11:16
*/
object Demo01 {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val spark: SparkSession = SparkSession.builder()
.appName("sparksql")
.master("local[*]")
.getOrCreate()
val sc = spark.sparkContext
sc.setLogLevel("WARN") //配置了log4j.properties,这个可以不用配置
//TODO 1.加载数据
val df: DataFrame = spark.read.json("data/input/words.json")
//TODO 2.处理数据
//TODO 3.输出结果
df.printSchema()
df.show()
//TODO 4.关闭资源
spark.stop()
}
}
控制台打印
root
|-- age: string (nullable = true)
|-- name: string (nullable = true)
|-- tel: string (nullable = true)
+----+----+-----------+
| age|name| tel|
+----+----+-----------+
|null|jack| 1388888888|
| 18|jack|13888888888|
| 18|jack| 1388888888|
+----+----+-----------+
案例二:将RDD转为DataFrame
使用样例类
1 zhangsan 20
2 lisi 29
3 wangwu 25
4 tianqi 35
6 kobe 40
package com.gtja.spark.sparksql
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
/*
* @Description:
* @Auther: wsy
* @Date: 2023/05/25/13:41
*/
object Demo02_RDD2DataFrame1 {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//TODO 1.加载数据
val lines: RDD[String] = sc.textFile("data/input/person.txt")
//TODO 2.处理数据
val personRDD: RDD[Person] = lines.map(line => {
val arr = line.split("\\W+")
Person(arr(0).toInt, arr(1), arr(2).toInt)
})
//RDD-->DF
import spark.implicits._
val personDF: DataFrame = personRDD.toDF()
//TODO 3.输出结果
personDF.printSchema()
personDF.show()
//TODO 4.关闭资源
spark.stop()
}
case class Person(id:Int,name:String,age:Int)
}
控制台打印
root
|-- id: integer (nullable = false)
|-- name: string (nullable = true)
|-- age: integer (nullable = false)
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 20|
| 2| lisi| 29|
| 3| wangwu| 25|
| 4| tianqi| 35|
| 6| kobe| 40|
+---+--------+---+
指定类型+列名
package com.gtja.spark.sparksql
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
/*
* @Description:
* @Auther: wsy
* @Date: 2023/05/25/14:01
*/
object Demo02_RDD2DataFrame2 {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//TODO 1.加载数据
val lines: RDD[String] = sc.textFile("data/input/person.txt")
//TODO 2.处理数据
val tupleRDD: RDD[(Int, String, Int)] = lines.map(line => {
val arr = line.split("\\W+")
(arr(0).toInt, arr(1), arr(2).toInt)
})
//RDD-->DF
import spark.implicits._
val personDF = tupleRDD.toDF("id", "name", "age")
//TODO 3.输出结果
personDF.printSchema()
personDF.show()
//TODO 4.关闭资源
spark.stop()
}
}
自定义Schema
package com.gtja.spark.sparksql
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
/*
* @Description: RDD2DataFrame-自定义Schema
* @Auther: wsy
* @Date: 2023/05/25/14:13
*/
object Demo02_RDD2DataFrame3 {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//TODO 1.加载数据
val lines: RDD[String] = sc.textFile("data/input/person.txt")
//TODO 2.处理数据
val rowRDD = lines.map(line => {
val arr: Array[String] = line.split("\\W+")
Row(arr(0).toInt, arr(1), arr(2).toInt)
})
//RDD-->DF
import spark.implicits._
val schema: StructType = StructType(List(
StructField("id", IntegerType, false),
StructField("name", StringType, false),
StructField("age", IntegerType, false)
))
val personDF: DataFrame = spark.createDataFrame(rowRDD, schema)
//TODO 3.输出结果
personDF.printSchema()
personDF.show()
//TODO 4.关闭资源
spark.stop()
}
}
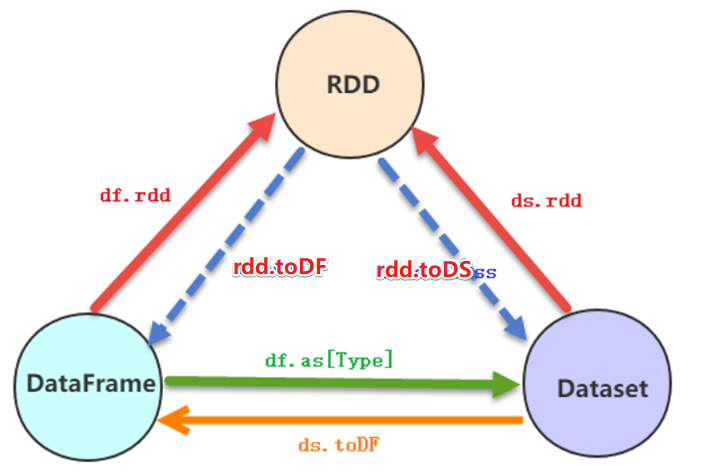
案例三:RDD-DF-DS相互转换
package com.gtja.spark.sparksql
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/*
* @Description: SparkSQL-RDD_DF_DS相互转换
* @Auther: wsy
* @Date: 2023/05/25/15:06
*/
object Demo03_RDD_DF_DS {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//TODO 1.加载数据
val lines: RDD[String] = sc.textFile("data/input/person.txt")
//TODO 2.处理数据
val personRDD: RDD[Person] = lines.map(line => {
val arr = line.split("\\W+")
Person(arr(0).toInt, arr(1), arr(2).toInt)
})
//转换1:RDD-->DF
import spark.implicits._
val personDF: DataFrame = personRDD.toDF()
//转换2:RDD-->DS (DS 比 DF 多了泛型)
val personDS: Dataset[Person] = personRDD.toDS()
//转换3:DF-->RDD,注意:DF没有泛型,转为RDD时使用的是Row
val rdd: RDD[Row] = personDF.rdd
//转换4:DS-->RDD
val rdd1: RDD[Person] = personDS.rdd
//转换5:DF-->DS
val ds: Dataset[Person] = personDF.as[Person]
//转换6:DS-->DF
val df: DataFrame = personDS.toDF()
//TODO 3.输出结果
rdd.foreach(println)
personDF.printSchema()
personDF.show()
spark.stop()
}
case class Person(id: Int, name: String, age: Int)
}
控制台打印
[1,zhangsan,20]
[4,tianqi,35]
[2,lisi,29]
[6,kobe,40]
[3,wangwu,25]
root
|-- id: integer (nullable = false)
|-- name: string (nullable = true)
|-- age: integer (nullable = false)
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 20|
| 2| lisi| 29|
| 3| wangwu| 25|
| 4| tianqi| 35|
| 6| kobe| 40|
+---+--------+---+
案例四:SparkSQL花式查询
在SparkSQL模块中,将结构化数据封装到DataFrame或Dataset集合后,提供了两种方式分析处理数据:
1、SQL编程,将DataFrame/Dataset注册为临时视图或表,编写SQL语句,类似HiveSQL;
2、DSL编程,调用DataFrame/Dataset API,类似RDD中函数;
需求一、SQL和DSL两种方式实现各种查询
package com.gtja.spark.sparksql
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
/*
* @Description:
* @Auther: wsy
* @Date: 2023/05/25/15:36
*/
object Demo04_Query {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val spark = SparkSession.builder().appName("SparkSql").master("local[*]").getOrCreate()
val sc = spark.sparkContext
sc.setLogLevel("WARN")
//TODO 1.加载数据
val lines: RDD[String] = sc.textFile("data/input/person.txt")
//TODO 2.处理数据
val personRDD: RDD[Person] = lines.map(line => {
val arr = line.split("\\W+")
Person(arr(0).toInt, arr(1), arr(2).toInt)
})
//RDD-->DF
import spark.implicits._
val personDF = personRDD.toDF()
//TODO ===========SQL==============
//注册表名
//personDF.registerTempTable("")//过期的
//personDF.createOrReplaceGlobalTempView("")//创建全局的,夸SparkSession也可以用,但是生命周期太长!
personDF.createOrReplaceTempView("t_person")//创建临时的,当前SparkSession也可以用
//=1.查看name字段的数据
spark.sql("select name from t_person").show()
//=2.查看 name 和age字段数据
spark.sql("select name ,age from t_person").show()
//=3.查询所有的name和age,并将age+1
spark.sql("select name ,age ,age + 1 from t_person").show()
//=4.过滤age大于等于25的
spark.sql("select name,age from t_person where age > 25").show()
//=5.统计年龄大于30的人数
spark.sql("select count(1) as bigAge from t_person where age >30").show()
//=6.按年龄进行分组并统计相同年龄的人数
spark.sql("select age,count(1) from t_person group by age").show()
//=7.查询姓名=张三的
spark.sql("select * from t_person where name = 'zhangsan'").show()
//TODO ===========DSL:面向对象的SQL==============
//=1.查看name字段的数据[三种方式]
personDF.select("name").show()
personDF.select($"name").show()
personDF.select(personDF.col("name")).show()
//=2.查看 name 和age字段数据
personDF.select("name","age").show()
//=3.查询所有的name和age,并将age+1
personDF.select($"name",$"age",$"age" + 1).show()
//=4.过滤age大于等于25的 //注意$ 和 ' 是把字符串转为了Column列对象
personDF.select("name","age").filter("age > 25").show()
personDF.select($"name",$"age").filter("age > 25").show()
personDF.select($"name",$"age").filter('age > 25).show()
//=5.统计年龄大于30的人数
personDF.select('name,'age).filter('age > 25).show()
//=6.按年龄进行分组并统计相同年龄的人数
personDF.groupBy('age).count().show()
//=7.查询姓名=张三的
personDF.select('*).filter("name = 'zhangsan'").show()
spark.stop()
}
case class Person(id:Int,name:String,age:Int)
}
案例五:SparkSQL实现WordCount
需求:使用SparkSQL的SQL和DSL两种方式完成WordCount
flink spark flink
java java scala
logstash es flink spark
package com.gtja.spark.sparksql
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/*
* @Description:
* @Auther: wsy
* @Date: 2023/05/25/16:14
*/
object Demo05_WordCount {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val spark = SparkSession.builder().appName("sparksql").master("local[*]").getOrCreate()
val sc = spark.sparkContext
sc.setLogLevel("WARN")
import spark.implicits._
//TODO 1.加载数据[三种方式]
val wordsRDD: RDD[String] = sc.textFile("data/input/words.txt")
val df: DataFrame = spark.read.text("data/input/words.txt")
val ds: Dataset[String] = spark.read.textFile("data/input/words.txt")
// wordsRDD.foreach(println)
// df.printSchema()
// df.show()
// ds.printSchema()
// ds.show()
//TODO 2.处理数据
//注意:df没有泛型,不能直接使用split
val words = ds.flatMap(_.split("\\W+"))
// words.printSchema()
// words.show()
//TODO ===SQL===
//注册临时表名
words.createOrReplaceTempView("t_wordCount")
val sql: String =
"""
|select value,count(1) as counts
|from t_wordCount
|group by value
|order by counts desc
|""".stripMargin
spark.sql(sql).show()
//TODO ===DSL===
words.groupBy('value)
.count()
.orderBy('count.desc)
.show()
spark.stop()
}
}
案例六:多数据源支持
读:spark.read.格式(路径) //底层 spark.read.format("格式").load(路径)
写:df.writer..格式(路径) //底层 df.writer.format("格式").save(路径)
- data/in/json/part-00000-b5ffbdfd-17fa-4f11-9053-595b6ce3171e-c000.json
{"id":1,"name":"zhangsan","age":20}
{"id":2,"name":"lisi","age":29}
{"id":3,"name":"wangwu","age":25}
{"id":4,"name":"zhaoliu","age":30}
{"id":5,"name":"tianqi","age":35}
{"id":6,"name":"kobe","age":40}
package com.gtja.spark.sparksql
import org.apache.spark.SparkContext
import org.apache.spark.sql.{Dataset, SaveMode, SparkSession}
import java.util.Properties
/*
* @Description: 支持的外部数据源,支持的文件格式:text/json/csv/parquet/orc....,支持文件系统/数据库
* @Auther: wsy
* @Date: 2023/05/25/16:34
*/
object Demo06_DataSource {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
import spark.implicits._
//TODO 1.加载数据
val ds: Dataset[String] = spark.read.textFile("data/in/json")
// ds.printSchema()
// ds.show()
//TODO 3.输出结果
ds.coalesce(1).write.mode(SaveMode.Overwrite).json("data/output/json") //底层 format("json").save(path)
val prop = new Properties()
prop.setProperty("user", "root")
prop.setProperty("password", "root")
//输出到mysql
ds.coalesce(1).write.mode(SaveMode.Overwrite).jdbc("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "person", prop) //表会自动创建
spark.stop()
}
}
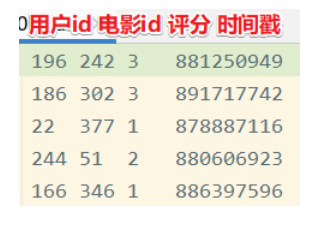
案例七:电影数据分析
需求:对电影评分数据进行统计分析,分别使用DSL编程和SQL编程,获得电影平均分Top10,要求电影的评分次数大于200,部分测试数据如下
- movieDF.printSchema()
root
|-- user: integer (nullable = false)
|-- movieId: string (nullable = true)
|-- score: integer (nullable = false)
|-- timestamp: long (nullable = false)
注:nullable:表示是否为空,如果要更改,需要自定义schema,参考案例二:自定义Schema
package com.gtja.spark.sparksql
import org.apache.spark.sql.execution.streaming.FileStreamSource.Timestamp
import org.apache.spark.sql.{Dataset, SparkSession}
/*
* @Description: 统计评分次数>200的电影平均分Top10
* @Auther: wsy
* @Date: 2023/05/25/16:58
*/
object Demo07_MovieDataAnalysis {
def main(args: Array[String]): Unit = {
//0、加载sparkSql环境
val spark = SparkSession.builder().appName("Demo07_MovieDataAnalysis")
.master("local[*]").config("spark.sql.shuffle.partitions", "4") //本次测试时将分区数设置小一点,实际开发中可以根据集群规模调整大小,默认200
.getOrCreate() //getOrCreate() 获取现有的 SparkSession
import spark.implicits._
//1、获取源数据
val ds: Dataset[String] = spark.read.textFile("data/in/rating_100k.data")
//2、处理数据,将数据转换成分布式表
val movieDF = ds.map(line => {
val arr = line.split("\\W+")
Film(arr(0).toInt, arr(1), arr(2).toInt, arr(3).toLong)
})
// movieDF.printSchema()
// movieDF.show()
//注册临时表
movieDF.createOrReplaceTempView("t_film")
//TODO SparkSQL SQL
// where counts > 200 ,这里不能使用 where 要使用 having
val sql: String =
"""
|select movieId , avg(score) as avgScore ,count(movieId) as counts
|from t_film
|group by movieId
|having counts > 200
|order by avgScore desc
|limit 10
|""".stripMargin
spark.sql(sql).show()
//TODO ======DSL
import org.apache.spark.sql.functions._
movieDF.groupBy('movieId).agg(
avg('score) as "avgscore",
count("movieId") as "counts"
).filter('counts > 200)
.orderBy('avgscore.desc)
.limit(10)
.show()
spark.stop()
}
case class Film(user: Int, movieId: String, score: Int, timestamp: Timestamp)
}
控制台打印
+-------+------------------+------+
|movieId| avgscore|counts|
+-------+------------------+------+
| 318| 4.466442953020135| 298|
| 483| 4.45679012345679| 243|
| 64| 4.445229681978798| 283|
| 603|4.3875598086124405| 209|
| 12| 4.385767790262173| 267|
| 50|4.3584905660377355| 583|
| 427| 4.292237442922374| 219|
| 357| 4.291666666666667| 264|
| 98| 4.28974358974359| 390|
| 127| 4.283292978208232| 413|
+-------+------------------+------+
案例八:SparkSQL-UDF
无论Hive还是SparkSQL处理数据时,往往需要使用函数,SparkSQL模块本身自带很多实现公共功能的函数,在org.a[ache.spark.sql.functions中。SparkSQL与Hive一样支持特定函数:UDF和UDAF,尤其是UDF函数在实际项目中使用最为广泛。
- 回顾Hive中自定义函数有三种类型:
1.UDF 函数
一对一的关系,输入一个值经过函数以后输出一个值;
在Hive中继承UDF类,方法名称为evalute,返回值不能为void,其实就是实现一个方法;
2.UDAF 聚合函数
多对一的关系,输入多个值输出一个值,通常与groupBy联合使用;
3.UDTF 函数
一对多的关系,输入一个值输出多个值(一行变多行);
用户自定义生成函数,有点像flatMap
需求: 加载文件中的数据并使用SparkSQL-UDF将数据转为大写
hello
haha
hehe
xixi
package com.gtja.spark.sparksql
import org.apache.spark.SparkContext
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.{Dataset, SparkSession}
/*
* @Description:
* @Auther: wsy
* @Date: 2023/05/26/09:35
*/
object Demo08_UDF {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]")
.config("spark.sql.shuffle.partitions", "4")//本次测试时将分区数设置小一点,实际开发中可以根据集群规模调整大小,默认200
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
import spark.implicits._
//TODO 1.加载数据
val ds: Dataset[String] = spark.read.textFile("data/in/udf.txt")
// ds.printSchema()
// ds.show()
//TODO 2.处理数据
//需求:使用SparkSQL-UDF将数据转为大写
//TODO ======SQL
//TODO 自定义UDF函数
spark.udf.register("small2big",(value:String)=>{
value.toUpperCase()
})
ds.createOrReplaceTempView("t_word")
val sql:String =
"""
|select value,small2big(value) as bigValue
|from t_word
|""".stripMargin
spark.sql(sql).show()
//TODO ======DSL
//TODO 自定义UDF函数
import org.apache.spark.sql.functions._
val small2big2: UserDefinedFunction = udf((value:String)=>{
value.toUpperCase()
})
ds.select('value,small2big2('value).as("bigValue")).show()
spark.stop()
}
}
控制台打印
+-----+--------+
|value|bigValue|
+-----+--------+
|hello| HELLO|
| haha| HAHA|
| hehe| HEHE|
| xixi| XIXI|
+-----+--------+
SparkOnHive 重要
SparkOnHive:Spark诞生之后,Spark提出的,是仅仅使用Hive的元素(库/表/字段/位置信息...),剩下的用SparkSQL的,如执行引擎,语法解析,物理执行计划,SQL优化。
注意:需要先启动Hive的metastore
nohup /export/server/hive/bin/hive --service metastore &
SparkSQL命令行中整合Hive
0.注意:Spark3.0.1整合hive要求hive版本>=2.3.7
1.注意:需要启动Hive的metastore ----node02
nohup /export/server/hive/bin/hive --service metastore &
2.把hive的配置文件hive-site.xml拷贝到spark/conf目录,把mysql驱动上传到spark/jars里面-node01 (也可以把配置文件和jar分发到其他机器,在其他机器使用SparkSQL操作hive)
3.启动spark/bin下的spark-sql命令行--node01
/export/server/spark/bin/spark-sql
4.执行sql语句--node1
show databases; show tables; CREATE TABLE person (id int, name string, age int) row format delimited fields terminated by ' '; LOAD DATA LOCAL INPATH 'file:///root/person.txt' INTO TABLE person; show tables; select * from person;
vim /root/person.txt
1 zhangsan 20
2 lisi 29
3 wangwu 25
4 zhaoliu 30
5 tianqi 35
6 kobe 40
SparkSQL代码中整合Hive
0.导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
1.注意:需要先启动Hive的metastore
nohup /export/server/hive/bin/hive --service metastore &
2.编写代码
package cn.itcast.sql
import org.apache.spark.SparkContext
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.{Dataset, SparkSession}
/**
* Author itcast
* Desc 演示SparkSQL-使用SparkSQL-UDF将数据转为大写
*/
object Demo09_Hive {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境---需要增加参数配置和开启hivesql语法支持
val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]")
.config("spark.sql.shuffle.partitions", "4")//本次测试时将分区数设置小一点,实际开发中可以根据集群规模调整大小,默认200
.config("spark.sql.warehouse.dir", "hdfs://node1:8020/user/hive/warehouse")//指定Hive数据库在HDFS上的位置
.config("hive.metastore.uris", "thrift://node02:9083")
.enableHiveSupport()//开启对hive语法的支持
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
import spark.implicits._
//TODO 1.操作Hive
spark.sql("show databases").show(false)
spark.sql("show tables").show(false)
spark.sql("CREATE TABLE person4 (id int, name string, age int) row format delimited fields terminated by ' '")
spark.sql("LOAD DATA LOCAL INPATH 'file:///D:/person.txt' INTO TABLE person4")
spark.sql("show tables").show(false)
spark.sql("select * from person4").show(false)
spark.stop()
}
}
Spark分布式SQL引擎
