一、选题背景
随着互联网和移动互联网技术的不断发展,电子商务已经成为了一个全球性的发展趋势。越来越多的商家和消费者都开始使用电子商务平台进行线上交易,这在一定程度上改变了传统商业模式,并且对于消费者而言,电子商务平台也提供了更为便捷的购物体验。因此,对于电子商务销售的分析就显得尤为重要。通过对电子商务销售数据的分析,商家可以更好地理解消费者的需求和购买行为,并且根据这些数据进行产品调整和市场营销策略的优化,从而提高销售额和客户满意度。
二、数据可视化分析方案
1、研究思路:
(1)分析通过Shiprocket和INCREF进行的销售之间的盈利能力差异。这些数据可用于查看最大的利润率所在,并相应地制定战略。
(2)检查产品的完整成本结构及其所有组件及其对收入或盈利能力的贡献,即TP 1和2,MRP Old and Final MRP Old以及基于平台的MRP - Amazon,Myntra和Paytm等,基于货币的利润率等。
(3)利用历史数据构建预测模型,以预测跨多个类别/设备/平台(如亚马逊,Flipkart,Myntra等)的电子商务产品的未来销量和利润,并提供有关客户偏好的更多见解,以通过考虑尺寸/颜色/平台特定定价等功能来了解需求变化
2、从网址中下载数据后,在python环境中导入pandas、missingno等第三方库进行数据处理,经过数据清洗、检查数据等,再进行数据可视化处理。
3、数据集:www.data.world.com
4、参考:电子商务销售分析
三、数据可视化步骤
(1)
1 #导入库 2 import numpy as np # 线性代数 3 import pandas as pd # 数据处理 4 5 import os 6 for dirname, _, filenames in os.walk('C:\\Users\\Lenovo\\Desktop\\python'): 7 for filename in filenames: 8 print(os.path.join(dirname, filename))

(2)
添加库
1 pip install missingno
(3)
1 #数据可视化 2 import pandas as pd 3 import matplotlib.pyplot as plt 4 import seaborn as sns 5 import missingno as msno
(4)
1 df = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\Amazon Sale Report.csv') 2 df.info()

(5)
1 df.set_index('index', inplace = True) #数据处理
(6)
1 msno.matrix(df) #显示结果

(7)
1 msno.bar(df)
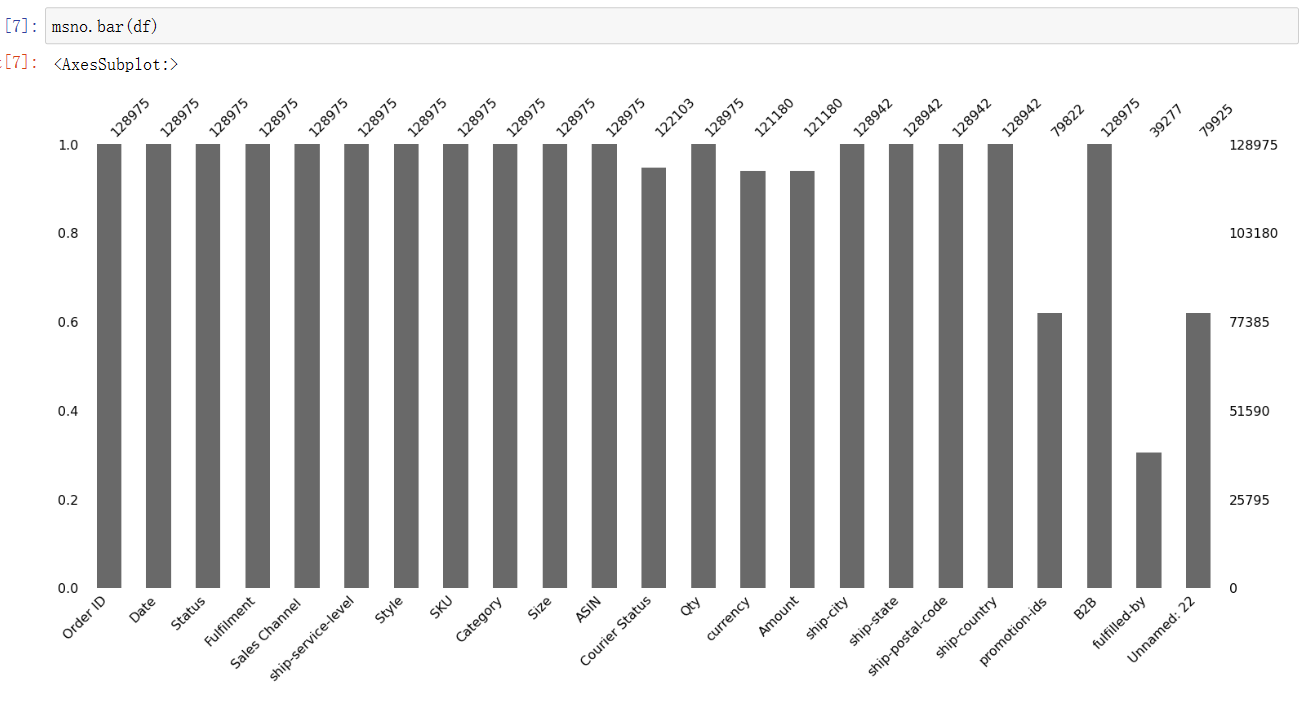
(8)
1 df.nunique()

(9)
1 df.apply(pd.unique)

(10)
1 l = len(df)
(11)
df.drop_duplicates(inplace = True)
(12)
1 a_l = len(df)
(13)
1 difference_len = l - a_l 2 3 print(f"{difference_len} rows have been removed! \n remaining rows {a_l} rows.")

(14)
1 df[df.isnull().any(axis = 1)]
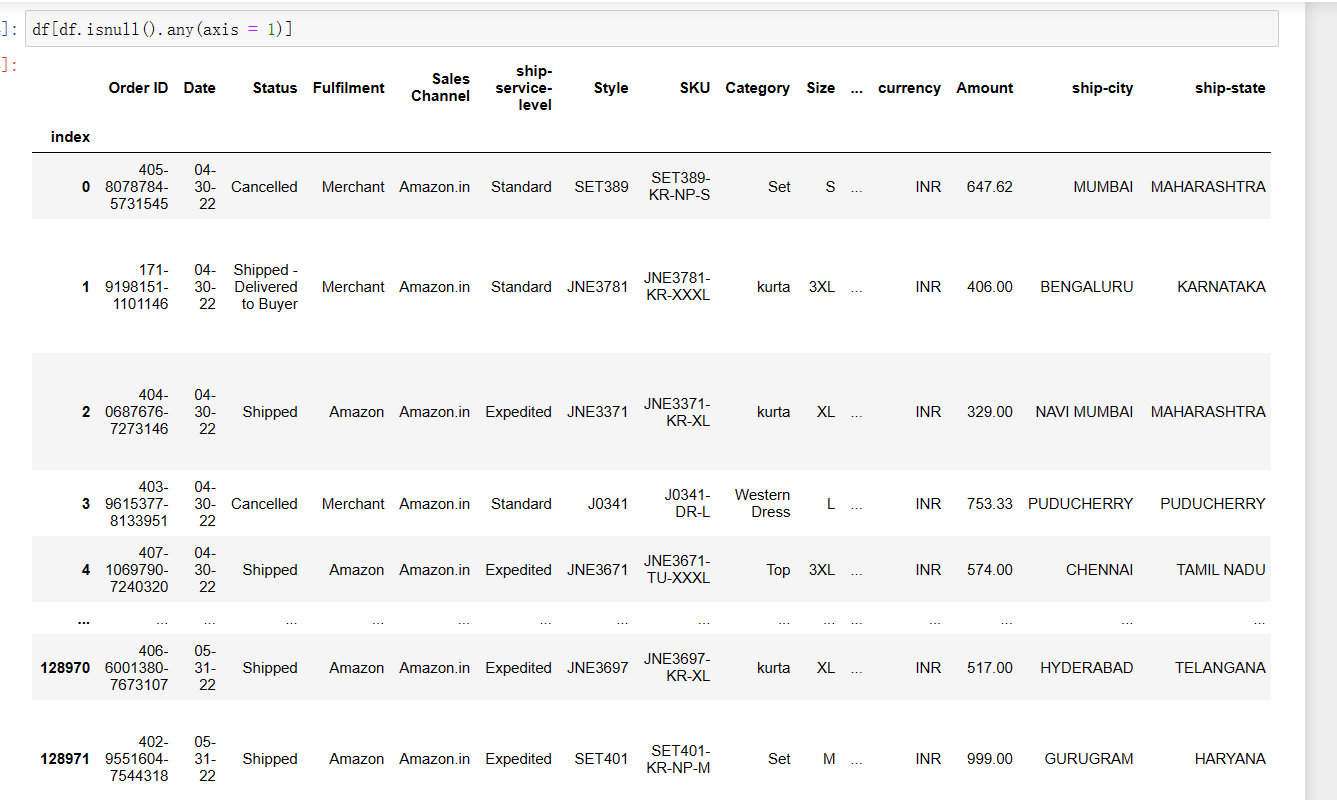
(15)
1 df[df['promotion-ids'].isnull()]
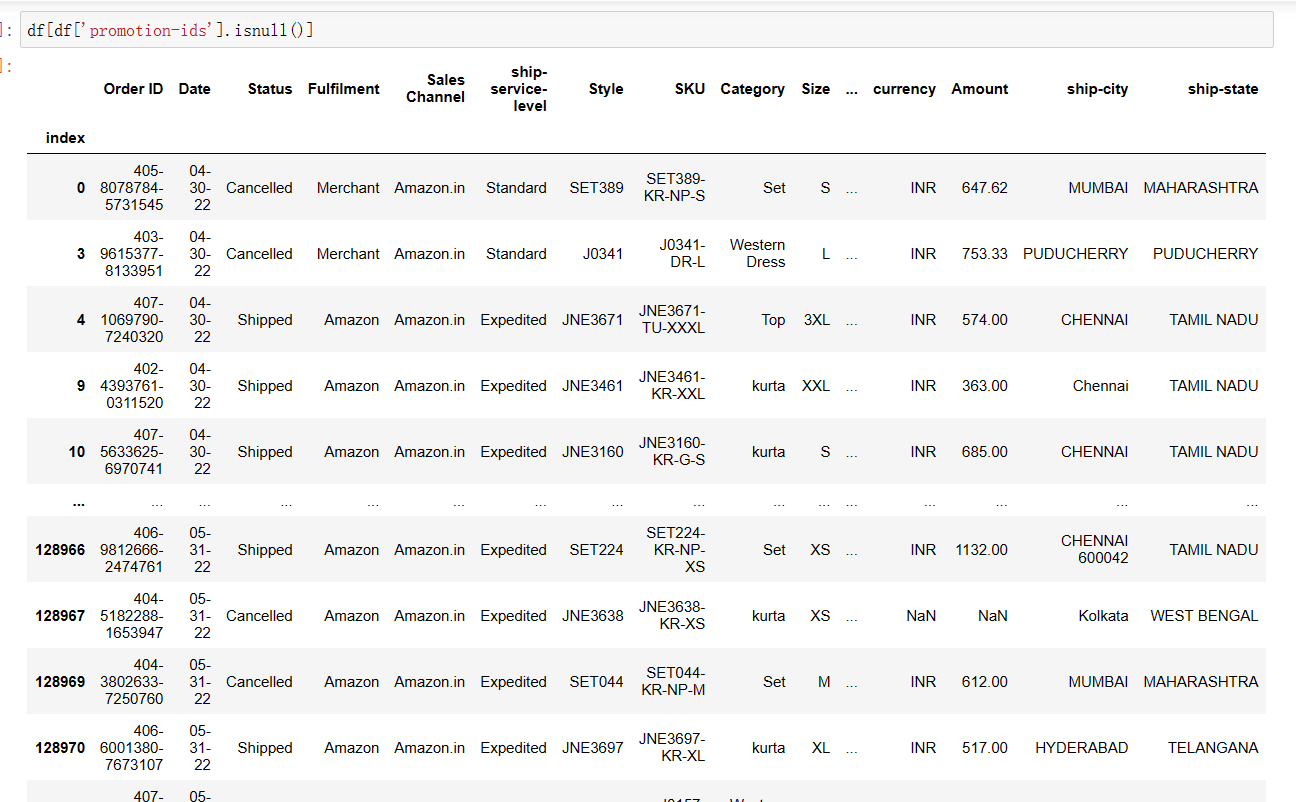
(16)
1 df['promotion-ids'].fillna('no promotion', inplace = True)
(17)
1 df['Courier Status'].fillna('unknown', inplace = True)
(18)
1 df[df['Amount'].isnull()]

(19)
1 df['Amount'].fillna(0, inplace = True)
(20)
1 msno.matrix(df)

(21)
1 df.drop(columns = ['currency'], inplace = True)
(22)
1 msno.matrix(df)
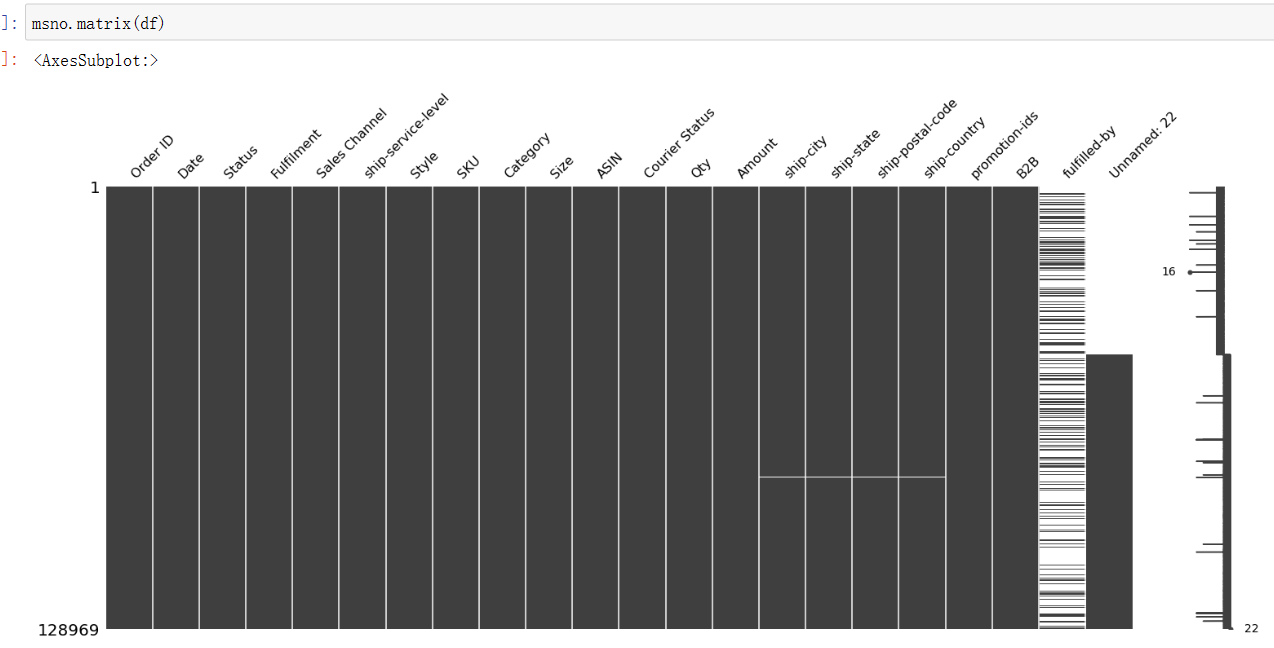
(23)
1 df.drop(columns = ['fulfilled-by'], inplace = True)
(24)
1 msno.matrix(df)

(25)
1 df.drop(columns = ['Unnamed: 22'], inplace = True)
(26)
1 msno.matrix(df)

(27)
1 df.head()

(28)
1 mapper = {'Order ID':'orderID', 'Date':'date', 'Status':'status', 'Fulfillment':'fulfillment'} 2 df.rename(columns = mapper, inplace = True) 3 df.head()
(29)
1 df['B2B'].replace([False, True], ['Consumer', 'Business'], inplace = True) 2 df.head()
(30)
1 df.info()
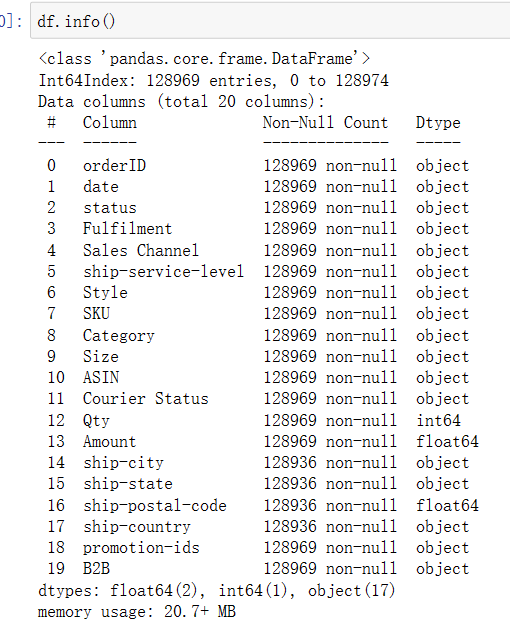
(31)
1 df[df['ship-city'].isnull()]
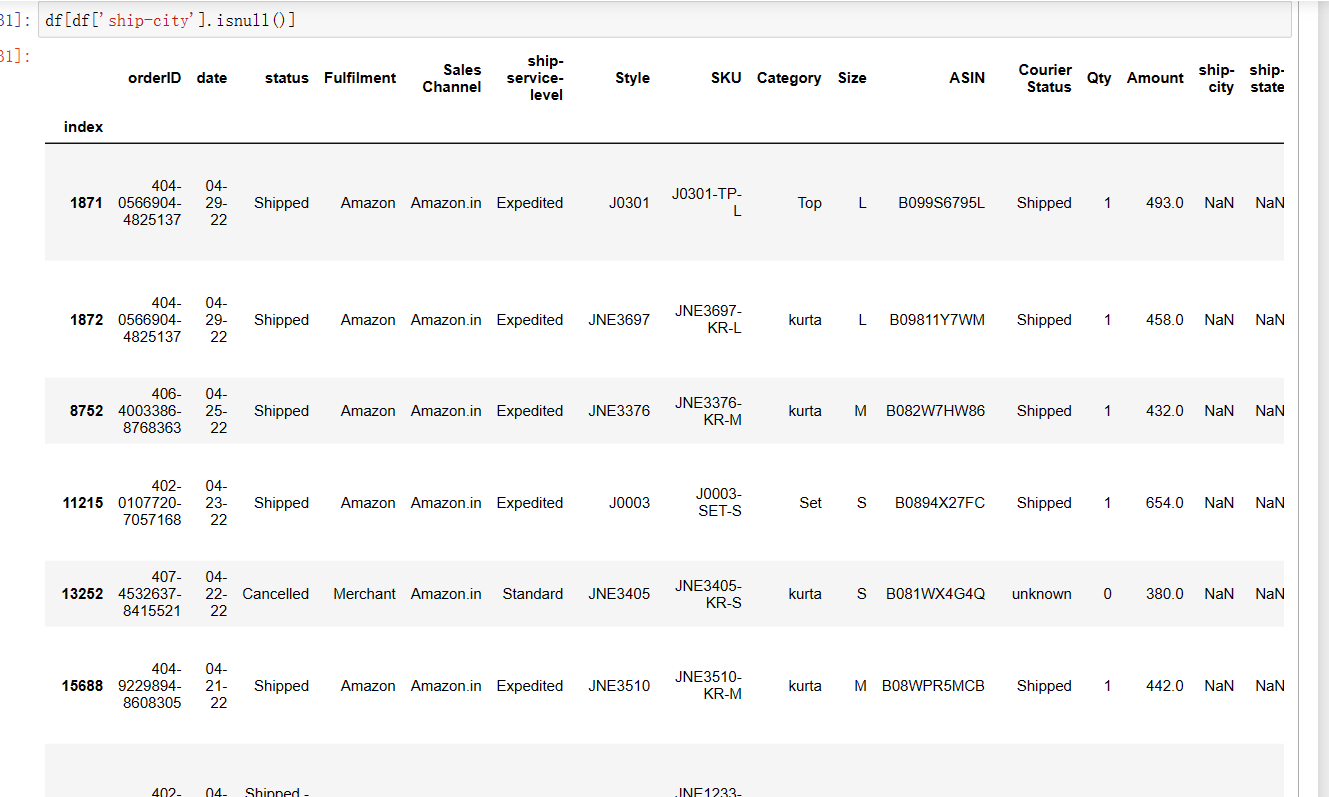
(32)
1 df['ship-city'].fillna('unknown', inplace = True) 2 df['ship-state'].fillna('unknown', inplace = True) 3 df['ship-postal-code'].fillna('unknown', inplace = True) 4 df['ship-country'].fillna('unknown', inplace = True)
(33)
1 msno.matrix(df)

(34)
1 df.info()
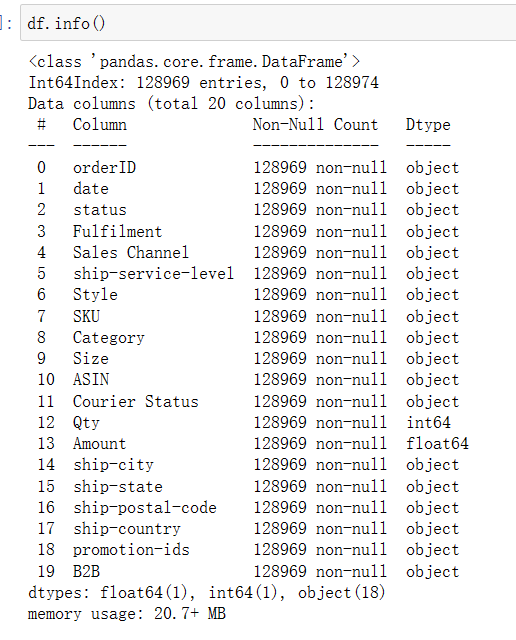
(35)
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 4 # 加载数据集 5 df1 = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\Sale Report.csv') 6 df2 = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\International sale Report.csv') 7 df3 = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\Amazon Sale Report.csv') 8 df4 = df1 9 10 # 设置绘图网格 11 fig, axs = plt.subplots(nrows=2, ncols=2, figsize=(15, 15)) 12 13 # 绘制图表 14 sizes = df1['Size'].value_counts() 15 sizes['Else'] = sizes[['XXXL', '4XL', '5XL', '6XL', 'FREE']].sum() 16 sizes = sizes.drop(labels=['XXXL', '4XL', '5XL', '6XL', 'FREE']) 17 total_stock = sizes.sum() 18 sizes_percentage = sizes / total_stock * 100 19 axs[0, 0].pie(sizes, labels=sizes.index, autopct='%1.1f%%') 20 axs[0, 0].set_title('Stock Distribution by Size',fontsize=20, x=0.5, y=1.05, pad=10) 21 22 # 从 CSV 文件加载数据 23 data = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\Sale Report.csv') 24 25 # 将大小映射到聚合大小 26 size_map = {'S': 'S', 'M': 'M', 'L': 'L', 'XL': 'XL', 'XXL': '2XL', 'XXXL': '3XL', '4XL': '4XL', '5XL': '5XL', '6XL': '6XL', 'FREE': 'FREE'} 27 data['AggregatedSize'] = data['Size'].map(size_map) 28 29 # 计算每个聚合大小的库存水平总和 30 data_by_aggregated_size = data.groupby('Size').sum().reset_index() 31 32 # 按库存水平降序对数据进行排序 33 data_by_aggregated_size = data_by_aggregated_size.sort_values('Stock', ascending=False) 34 35 # 突出显示前三个聚合大小 36 data_by_aggregated_size['Highlighted'] = False 37 data_by_aggregated_size.loc[0:2, 'Highlighted'] = True 38 39 # 创建条形图 40 bars = axs[0,1].bar(data_by_aggregated_size['Size'], data_by_aggregated_size['Stock']) 41 for i in range(len(bars)): 42 if i < 3: 43 bars[i].set_color('blue') 44 else: 45 bars[i].set_color('gray') 46 axs[0,1].set(xlabel='Size', ylabel='Stock') 47 axs[0,1].set_title('Stock Levels by Size', fontsize=20, x=0.5, y=1.05, pad=10) 48 49 50 # 绘制图表 51 valid_sizes = ['XS', 'S', 'M', 'L', 'XL', 'XXL', 'XXXL', '4XL', '5XL', '6XL', 'FREE'] 52 df2 = df2[df2['Size'].isin(valid_sizes)] 53 df2['PCS'] = pd.to_numeric(df2['PCS'], errors='coerce') 54 size_counts = df2.groupby('Size').size().reset_index(name='count') 55 size_counts = size_counts.sort_values(by='count', ascending=False) 56 top_sizes = size_counts.head(3) 57 other_sizes_count = size_counts.iloc[3:]['count'].sum() 58 other_sizes = pd.DataFrame({'Size': ['Else'], 'count': [other_sizes_count]}) 59 top_sizes = pd.concat([top_sizes, other_sizes], ignore_index=True) 60 total_sales = df2['PCS'].sum() 61 top_sizes['percentage'] = top_sizes['count'] / total_sales * 100 62 axs[1, 0].pie(top_sizes['percentage'], labels=top_sizes['Size'], autopct='%1.1f%%', startangle=90) 63 axs[1, 0].set_title('International Sale Size Distribution',fontsize=20, x=0.5, y=1.05, pad=10) 64 65 # 绘制图表 66 sizes = df3['Size'] 67 allowed_sizes = ['XS', 'S', 'M', 'L', 'XL', 'XXL', '3XL', '4XL', '5XL', '6XL', 'FREE'] 68 sizes = sizes[sizes.isin(allowed_sizes)] 69 size_counts = sizes.value_counts() 70 total_sales = df3['Qty'].sum() 71 top_sizes = size_counts[:3].index.tolist() 72 top_sizes_count = size_counts[top_sizes].sum() 73 top_sizes_percentage = top_sizes_count / total_sales * 100 74 else_count = size_counts.drop(top_sizes).sum() 75 else_percentage = else_count / total_sales * 100 76 labels = top_sizes + ['Else'] 77 values = [top_sizes_percentage] * len(top_sizes) + [else_percentage] 78 axs[1, 1].pie(values, labels=labels, autopct='%1.1f%%') 79 axs[1, 1].set_title('Amazon Sale Size Distribution',fontsize=20, x=0.5, y=1.05, pad=10) 80 81 # 调整子图之间的间距 82 plt.subplots_adjust(hspace=0.4, wspace=0.4) 83 84 # 显示绘制 85 plt.show()

(36)
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 4 # 将 CSV 文件读入pandas数据帧 5 df = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\Amazon Sale Report.csv') 6 7 # 筛选数据框以仅包括已发货和已取消的销售 8 filtered_df = df[df['Status'].isin(['Shipped', 'Cancelled'])] 9 10 # 按状态对筛选的数据框进行分组并计算计数 11 by_status = filtered_df.groupby('Status').count()['SKU'] 12 13 # 创建一个名为“分组状态”的新列,以将所有其他状态类型分组到 “其他状态” 14 df['Grouped Status'] = df['Status'].apply(lambda x: x if x in ['Shipped', 'Cancelled'] else 'Else Status') 15 16 # 按新的“分组状态”列对原始数据帧进行分组并计算计数 17 by_grouped_status = df.groupby('Grouped Status').count()['SKU'] 18 19 # 创建包含 2 行和 2 列的图形 20 fig, axs = plt.subplots(2, 2, figsize=(15, 15)) 21 22 # 创建条形图以按配送方式显示已取消的销售 23 cancelled_df = filtered_df[filtered_df['Status'] == 'Cancelled'] 24 by_fulfilment = cancelled_df.groupby('Fulfilment').count()['SKU'] 25 axs[0, 0].bar(by_fulfilment.index, by_fulfilment.values) 26 axs[0, 0].set_title('Cancelled Sales by Fulfilment Method',fontsize=20, x=0.5, y=1.05, pad=10) 27 28 # 按产品类别对取消的销售额进行分组并计算计数 29 by_category = cancelled_df.groupby('Category').count()['SKU'] 30 31 # 按已取消销售的计数对类别进行排序 32 by_category = by_category.sort_values(ascending=False) 33 34 # 保留前 5 个类别 35 top_category = by_category[:5] 36 37 # 计算每个顶级类别的取消销售百分比 38 category_percentages = (top_category / cancelled_df.shape[0]) * 100 39 40 # 创建条形图以按前 5 个产品类别显示已取消的销售额 41 axs[0, 1].bar(top_category.index, top_category.values) 42 axs[0, 1].set_title('Top 5 Cancelled Sales by Product Category',fontsize=20, x=0.5, y=1.05, pad=10) 43 44 # 将百分比标签添加到条形图 45 for i, v in enumerate(top_category.values): 46 axs[0, 1].text(i, v+5, f'{category_percentages.values[i]:.2f}%', ha='center') 47 48 49 50 # 创建条形图以按配送服务级别显示已取消的销售 51 by_shipping = cancelled_df.groupby('ship-service-level').count()['SKU'] 52 axs[1, 0].bar(by_shipping.index, by_shipping.values) 53 axs[1, 0].set_title('Cancelled Sales by Shipping Service Level',fontsize=20, x=0.5, y=1.05, pad=10) 54 55 # 创建饼图以显示销售的总体状态 56 by_status = filtered_df.groupby('Status').count()['SKU'] 57 by_status['Else Status'] = df.groupby('Grouped Status').count()['SKU']['Else Status'] 58 axs[1, 1].pie(by_status.values, labels=by_status.index) 59 axs[1, 1].set_title('Overall Sales Status',fontsize=20, x=0.5, y=1.05, pad=10) 60 61 # 调整子图之间的间距 62 plt.subplots_adjust(hspace=0.4) 63 64 # 显示图表 65 plt.show()
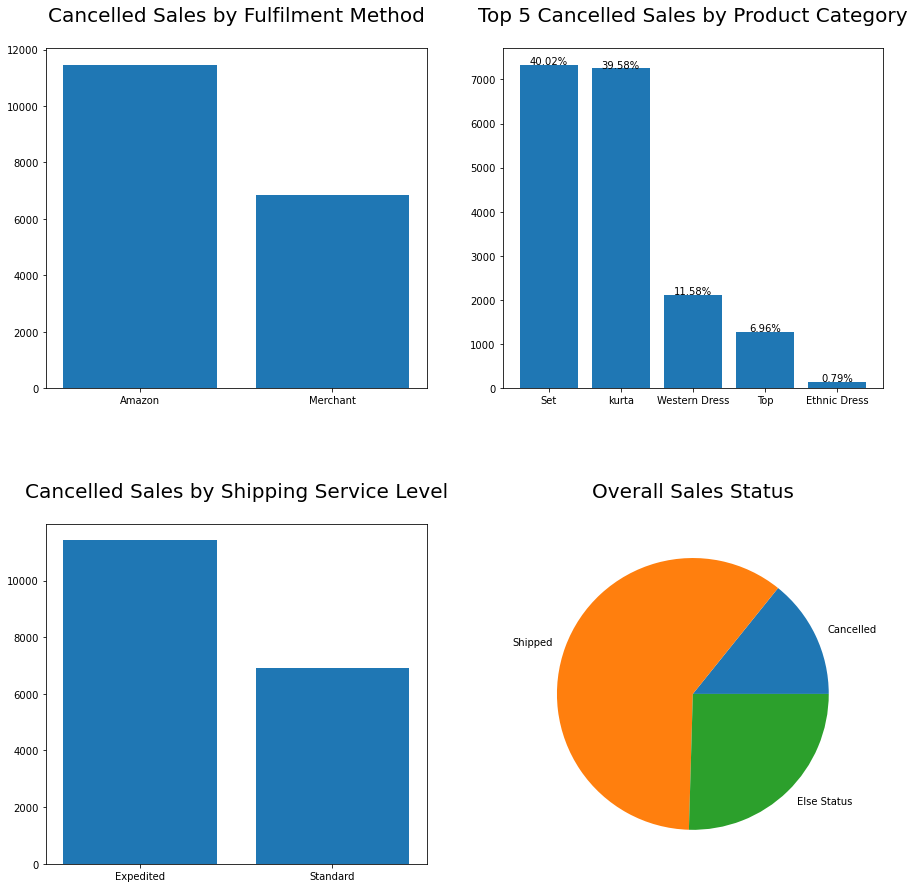
(37)
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 4 # 将 CSV 文件读入pandas数据帧 5 df = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\Amazon Sale Report.csv') 6 7 # 筛选数据框以仅包括已取消的销售 8 cancelled_df = df[df['Status'] == 'Cancelled'] 9 10 # 按配送方式和配送服务级别划分的团体取消销售 11 by_fulfilment_shipping = cancelled_df.groupby(['Fulfilment', 'ship-service-level']).count()['SKU'].reset_index() 12 13 # 创建条形图,按配送方式和配送服务级别显示已取消的销售 14 fig, ax = plt.subplots(figsize=(10, 10)) 15 by_fulfilment_shipping.groupby(['Fulfilment', 'ship-service-level']).sum()['SKU'].unstack().plot(kind='bar', ax=ax) 16 ax.set_title('Cancelled Sales by Fulfilment Method and Shipping Service Level', fontsize=20, x=0.5, y=1.05, pad=10) 17 ax.set_xlabel('Fulfilment Method',fontsize=20) 18 ax.set_ylabel('Cancelled Sales',fontsize=20) 19 ax.legend(title='Shipping Service Level', fontsize=20, title_fontsize=12) 20 21 # 显示绘制 22 plt.show()

四、总结
如今电子商务的兴起对社会和经济产生了深刻的影响,它打破了传统商业模式在各方面的限制,使商家和消费者可以通过互联网直接进行交易,人们可以通过互联网购买到任何地方的商品,无需花费时间和金钱到实体店铺购买。这种商业模式的改变不仅提高了交易效率,降低了交易成本,带动了电子商务、物流、支付等相关行业的快速发展,还创造了更多的商业机会。在这次数据可视化的分析过程中我们可以看出,占比越大,销售盈利能力越强,通过产品的销量和利润等方面数据的对比,商户选择的渠道会更加丰富。
1、通过对数据的分析得到的信息可用于以下几个方面:
(1)销售额:通过收集网购APP的销售数据,可以计算出销售额。可以分析销售额的趋势,比较不同时间段的销售情况,从而了解网购APP的销售情况和发展趋势。
(2)毛利率:毛利率是指销售收入减去销售成本后的净利润占销售收入的比例。通过分析毛利率可以了解网购APP的产品或服务成本和定价策略是否合理,是否存在价格竞争等问题。
(3)净利率:净利率是指销售收入减去所有开支后的净利润占销售收入的比例。通过分析净利率可以了解网购APP的营销费用、人力成本、技术开发成本等方面的开支情况,从而评估网购APP的盈利能力。
(4)用户留存率:用户留存率是指网购APP用户在一定时间内继续使用APP的比例。通过分析用户留存率可以了解网购APP的用户粘性和忠诚度,从而制定更加有效的用户留存策略。
(5)新用户获取成本:新用户获取成本是指为获取一个新用户所花费的成本。通过分析新用户获取成本可以了解网购APP的用户获取成本和用户获取效果,从而制定更加有效的用户获取策略。 综上所述,通过对网购APP的销售数据进行分析,可以深入了解网购APP的销售和盈利情况,从而制定更加有效的销售策略和盈利优化方案。
2、学习了数据可视化之后的感悟:
学习数据可视化让我深刻认识到数据可视化的重要性和作用。通过合适的图形化展示数据,我们可以更容易地发现数据中的规律和趋势,从而做出更加准确和有意义的决策。同时,数据可视化也是沟通与传递信息的重要方式,可以帮助我们向别人更好地展示数据的含义和价值。 在学习过程中,我也意识到了数据准备的重要性。只有经过严格的数据处理和清洗,才能保证展示出来的数据准确无误。同时,选择合适的图表类型和颜色也是很重要的,可以让图表更加直观和易于理解。 最后,我也发现了数据可视化所需要的技能和工具都比较多,需要不断地学习和练习。不过,只要有耐心和热情,通过不断地实践和反思,我相信可以逐渐提高自己的数据可视化能力。
3、不足之处:
绘制出的图表无法显示中文字符,第三方库安装不了,从CNDS上找的方法也没有顺利解决。
查找到的方法:



运行出错的代码:


完整代码
import numpy as np import pandas as pd import os for dirname, _, filenames in os.walk('C:\\Users\\Lenovo\\Desktop\\python'): for filename in filenames: print(os.path.join(dirname, filename)) import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import missingno as msno df = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\Amazon Sale Report.csv') df.info() df.set_index('index', inplace = True) msno.matrix(df) msno.bar(df) df.nunique() df.apply(pd.unique) l = len(df) df.drop_duplicates(inplace = True) a_l = len(df) difference_len = l - a_l print(f"{difference_len} rows have been removed! \n remaining rows {a_l} rows.") df[df.isnull().any(axis = 1)] df[df['promotion-ids'].isnull()] df['Amount'].fillna(0, inplace = True) msno.matrix(df) df.drop(columns = ['currency'], inplace = True) msno.matrix(df) df.drop(columns = ['fulfilled-by'], inplace = True) msno.matrix(df) df.drop(columns = ['Unnamed: 22'], inplace = True) msno.matrix(df) df.head() mapper = {'Order ID':'orderID', 'Date':'date', 'Status':'status', 'Fulfillment':'fulfillment'} df.rename(columns = mapper, inplace = True) df.head() df['B2B'].replace([False, True], ['Consumer', 'Business'], inplace = True) df.head() df.info() df[df['ship-city'].isnull()] df['ship-city'].fillna('unknown', inplace = True) df['ship-state'].fillna('unknown', inplace = True) df['ship-postal-code'].fillna('unknown', inplace = True) df['ship-country'].fillna('unknown', inplace = True) msno.matrix(df) df.info()
import pandas as pd import matplotlib.pyplot as plt df1 = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\Sale Report.csv') df2 = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\International sale Report.csv') df3 = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\Amazon Sale Report.csv') df4 = df1 fig, axs = plt.subplots(nrows=2, ncols=2, figsize=(15, 15)) sizes = df1['Size'].value_counts() sizes['Else'] = sizes[['XXXL', '4XL', '5XL', '6XL', 'FREE']].sum() sizes = sizes.drop(labels=['XXXL', '4XL', '5XL', '6XL', 'FREE']) total_stock = sizes.sum() sizes_percentage = sizes / total_stock * 100 axs[0, 0].pie(sizes, labels=sizes.index, autopct='%1.1f%%') axs[0, 0].set_title('Stock Distribution by Size',fontsize=20, x=0.5, y=1.05, pad=10) data = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\Sale Report.csv') size_map = {'S': 'S', 'M': 'M', 'L': 'L', 'XL': 'XL', 'XXL': '2XL', 'XXXL': '3XL', '4XL': '4XL', '5XL': '5XL', '6XL': '6XL', 'FREE': 'FREE'} data['AggregatedSize'] = data['Size'].map(size_map) data_by_aggregated_size = data.groupby('Size').sum().reset_index() data_by_aggregated_size = data_by_aggregated_size.sort_values('Stock', ascending=False) data_by_aggregated_size['Highlighted'] = False data_by_aggregated_size.loc[0:2, 'Highlighted'] = True bars = axs[0,1].bar(data_by_aggregated_size['Size'], data_by_aggregated_size['Stock']) for i in range(len(bars)): if i < 3: bars[i].set_color('blue') else: bars[i].set_color('gray') axs[0,1].set(xlabel='Size', ylabel='Stock') axs[0,1].set_title('Stock Levels by Size', fontsize=20, x=0.5, y=1.05, pad=10) valid_sizes = ['XS', 'S', 'M', 'L', 'XL', 'XXL', 'XXXL', '4XL', '5XL', '6XL', 'FREE'] df2 = df2[df2['Size'].isin(valid_sizes)] df2['PCS'] = pd.to_numeric(df2['PCS'], errors='coerce') size_counts = df2.groupby('Size').size().reset_index(name='count') size_counts = size_counts.sort_values(by='count', ascending=False) top_sizes = size_counts.head(3) other_sizes_count = size_counts.iloc[3:]['count'].sum() other_sizes = pd.DataFrame({'Size': ['Else'], 'count': [other_sizes_count]}) top_sizes = pd.concat([top_sizes, other_sizes], ignore_index=True) total_sales = df2['PCS'].sum() top_sizes['percentage'] = top_sizes['count'] / total_sales * 100 axs[1, 0].pie(top_sizes['percentage'], labels=top_sizes['Size'], autopct='%1.1f%%', startangle=90) axs[1, 0].set_title('International Sale Size Distribution',fontsize=20, x=0.5, y=1.05, pad=10) sizes = df3['Size'] allowed_sizes = ['XS', 'S', 'M', 'L', 'XL', 'XXL', '3XL', '4XL', '5XL', '6XL', 'FREE'] sizes = sizes[sizes.isin(allowed_sizes)] size_counts = sizes.value_counts() total_sales = df3['Qty'].sum() top_sizes = size_counts[:3].index.tolist() top_sizes_count = size_counts[top_sizes].sum() top_sizes_percentage = top_sizes_count / total_sales * 100 else_count = size_counts.drop(top_sizes).sum() else_percentage = else_count / total_sales * 100 labels = top_sizes + ['Else'] values = [top_sizes_percentage] * len(top_sizes) + [else_percentage] axs[1, 1].pie(values, labels=labels, autopct='%1.1f%%') axs[1, 1].set_title('Amazon Sale Size Distribution',fontsize=20, x=0.5, y=1.05, pad=10) plt.subplots_adjust(hspace=0.4, wspace=0.4) plt.show()
import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\Amazon Sale Report.csv') filtered_df = df[df['Status'].isin(['Shipped', 'Cancelled'])] by_status = filtered_df.groupby('Status').count()['SKU'] df['Grouped Status'] = df['Status'].apply(lambda x: x if x in ['Shipped', 'Cancelled'] else 'Else Status') by_grouped_status = df.groupby('Grouped Status').count()['SKU'] fig, axs = plt.subplots(2, 2, figsize=(15, 15)) cancelled_df = filtered_df[filtered_df['Status'] == 'Cancelled'] by_fulfilment = cancelled_df.groupby('Fulfilment').count()['SKU'] axs[0, 0].bar(by_fulfilment.index, by_fulfilment.values) axs[0, 0].set_title('Cancelled Sales by Fulfilment Method',fontsize=20, x=0.5, y=1.05, pad=10) by_category = cancelled_df.groupby('Category').count()['SKU'] by_category = by_category.sort_values(ascending=False) top_category = by_category[:5] category_percentages = (top_category / cancelled_df.shape[0]) * 100 axs[0, 1].bar(top_category.index, top_category.values) axs[0, 1].set_title('Top 5 Cancelled Sales by Product Category',fontsize=20, x=0.5, y=1.05, pad=10) for i, v in enumerate(top_category.values): axs[0, 1].text(i, v+5, f'{category_percentages.values[i]:.2f}%', ha='center') by_shipping = cancelled_df.groupby('ship-service-level').count()['SKU'] axs[1, 0].bar(by_shipping.index, by_shipping.values) axs[1, 0].set_title('Cancelled Sales by Shipping Service Level',fontsize=20, x=0.5, y=1.05, pad=10) by_status = filtered_df.groupby('Status').count()['SKU'] by_status['Else Status'] = df.groupby('Grouped Status').count()['SKU']['Else Status'] axs[1, 1].pie(by_status.values, labels=by_status.index) axs[1, 1].set_title('Overall Sales Status',fontsize=20, x=0.5, y=1.05, pad=10) plt.subplots_adjust(hspace=0.4) plt.show()
import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv('C:\\Users\\Lenovo\\Desktop\\python\\Amazon Sale Report.csv') cancelled_df = df[df['Status'] == 'Cancelled'] by_fulfilment_shipping = cancelled_df.groupby(['Fulfilment', 'ship-service-level']).count()['SKU'].reset_index() fig, ax = plt.subplots(figsize=(10, 10)) by_fulfilment_shipping.groupby(['Fulfilment', 'ship-service-level']).sum()['SKU'].unstack().plot(kind='bar', ax=ax) ax.set_title('Cancelled Sales by Fulfilment Method and Shipping Service Level', fontsize=20, x=0.5, y=1.05, pad=10) ax.set_xlabel('Fulfilment Method',fontsize=20) ax.set_ylabel('Cancelled Sales',fontsize=20) ax.legend(title='Shipping Service Level', fontsize=20, title_fontsize=12) plt.show()