从B树到LSM树
《数据库系统内幕》下文中很多图片源自这本书
B+树
在mysql原理中,进行过B+树与一些数据结构对比:
- B+树与B树
B+树只在叶子节点存储数据,B树非叶子节点也要存储数据,所以B+树的单个节点的数据量更小,在相同的磁盘I/O次数下,就能查询更多的节点
B+Tree叶子节点采用链表连接,适合基于范围的顺序查找 - B+树与二叉树
即使数据很大,B+树的高度依然维持在34层左右,也就是说一次数据查询操作只需要做34次的磁盘I/O操作
而二叉树的每个父节点的子节点个数只能是2个,比B+树高出不少
二叉树在顺序插入时可能退化为链表 - B+树与二叉平衡树
无论平衡还是自平衡的二叉树(红黑树)虽然解决了二叉树可能退化为链表的问题,但依然高度很高
且平衡操作(旋转等)复杂耗时 - B+树与哈希表
哈希表在做等值查询的时候效率很快,但不适合做范围查询 - B+树与跳表
即使数据很大,B+树的高度依然维持在3~4层左右,但跳表需要几十层,所以B+树的读性能会比跳表要好
那为什么redis使用跳表,因为redis读写全在内存里进行操作,不涉及磁盘IO,不关心磁盘读性能,同时跳表实现简单,相比B+树少了树分裂合并的开销,写方面更优
所以读多写少B+树,写多读少跳表
B树变体
写时复制B树
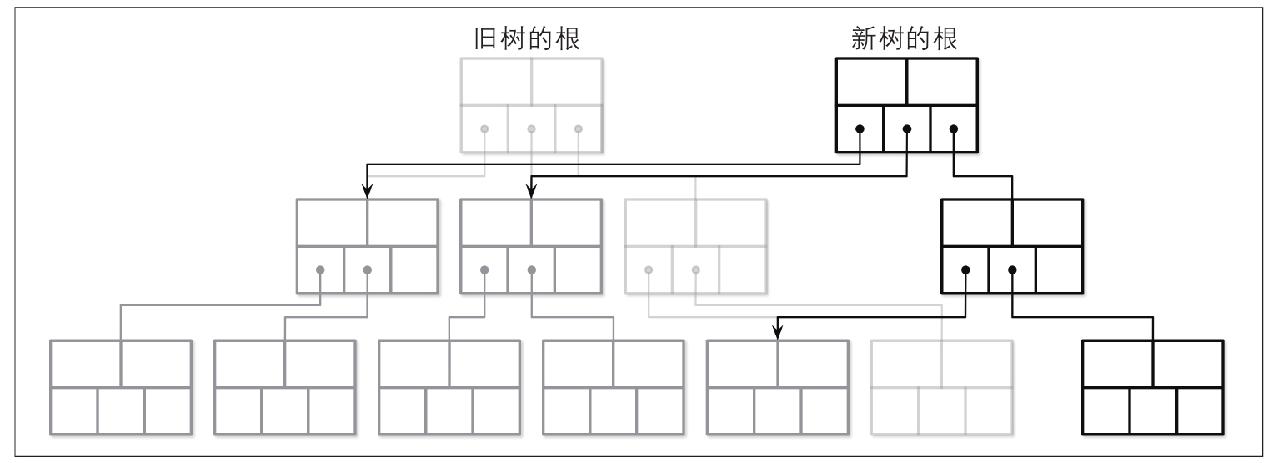
不使用锁,采用写时复制(copy on write技术)保证并发操作的数据完整性:当要修改页时,复制这个页,在复制的页上修改
缺点:写放大,修改一处就要复制多个页
优点:读不会阻塞写,系统崩溃也不会损坏页数据
惰性B树
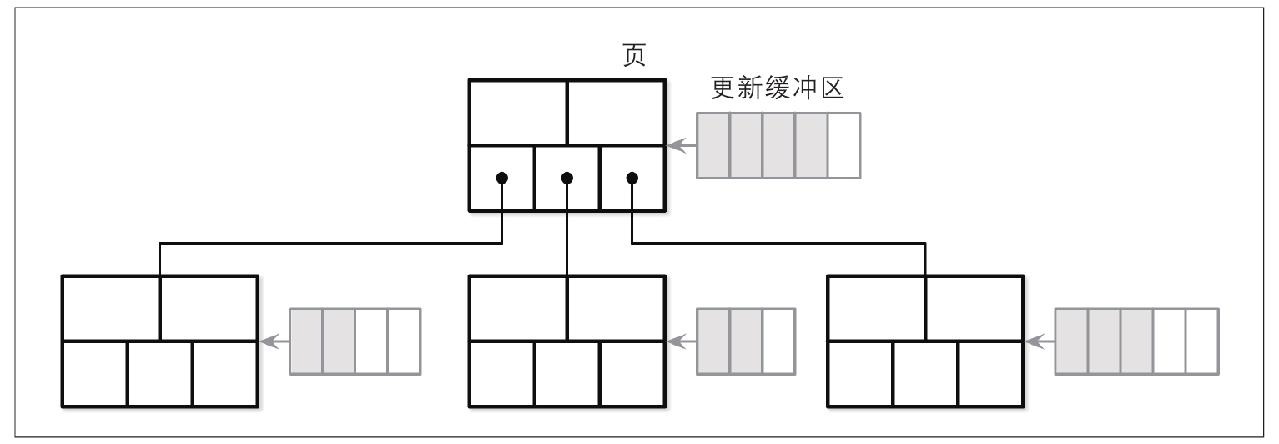
使用缓冲(mongodb存储引擎wiredtiger使用)
更新时,先将更新放入页的缓冲
读取时,将缓冲与原始页合并后再读取
写回时,将缓冲与原始页合并后再写回
缓冲使用跳表
优点:读写进程不必等待页的分裂与合并,这些都由后台进程执行
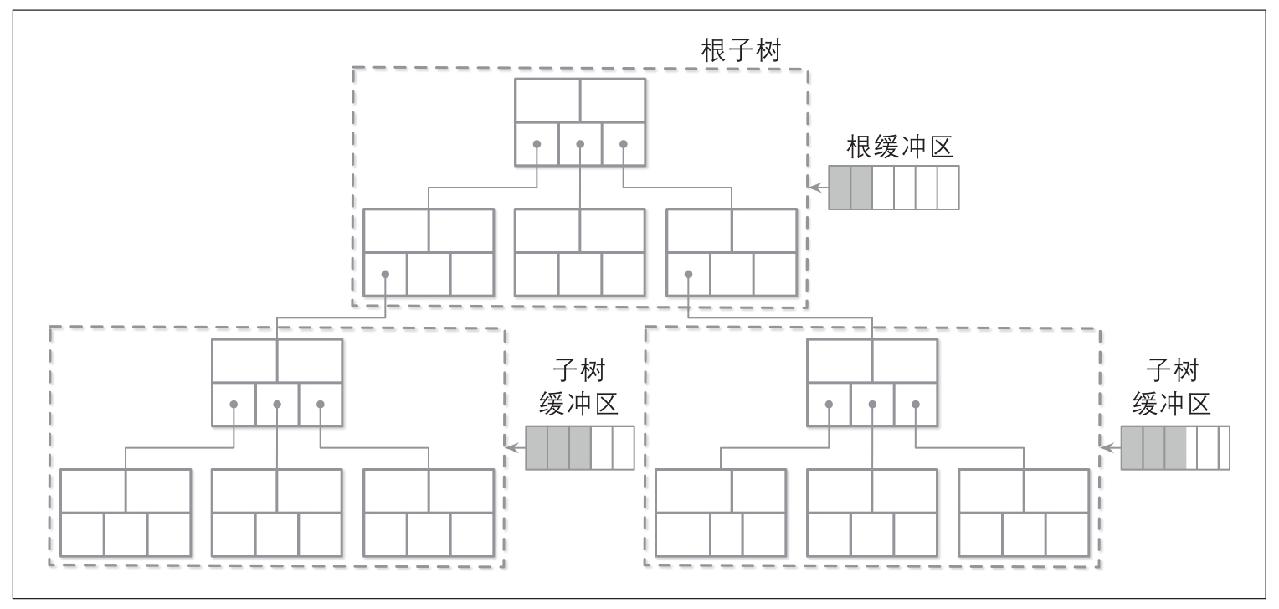
惰性自适应树
为子树使用批量操作的缓冲
数据更新首先加到根节点的更新缓冲,缓冲满了再递归加入子树的缓冲
优点:因此对于叶节点及上层节点的操作都是批量的,减少磁盘访问
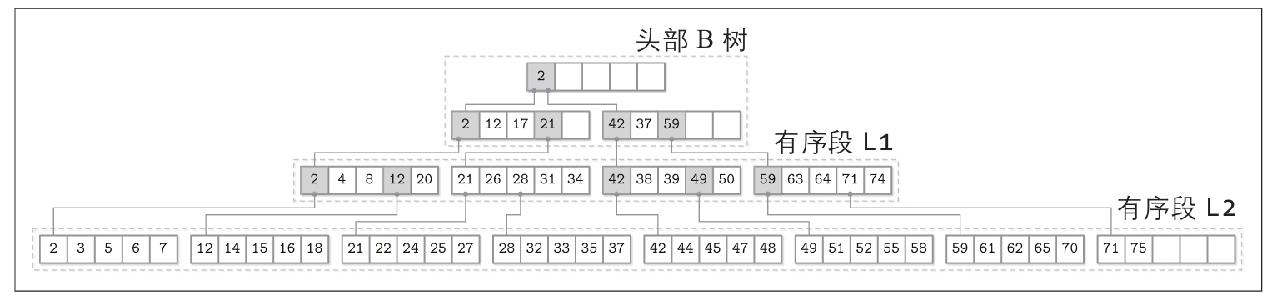
FD树
与lsm树类似
由一个可变的缓冲b树与多个不可变的有序段组成,b树被填满就转移到下一层不可变有序段中,依次再于下一层合并
为了优化相邻层查找,使用分级级联的方法:通过在序号较大的数组中每隔一个元素就将元素拉到序号较小的数组中来弥合元素之间的空隙

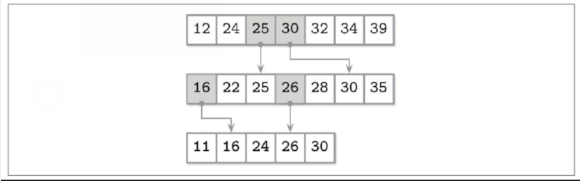
FD树是将低层头元素作为高层指针
BW树
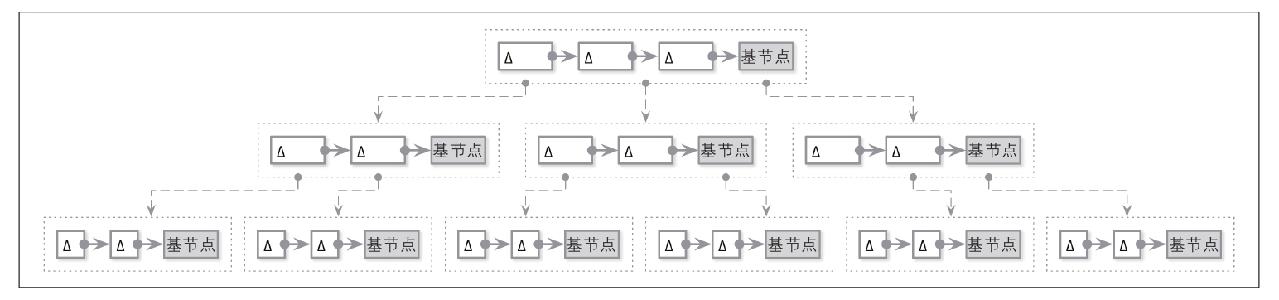
原地更新的B树存在的问题:
写放大:需要对整个页更新(每次更新覆盖整个页)
空间放大:保留额外空间来实现更新
并发控制:加锁复杂
更新节点单独用一个增量节点表示,并指向旧结点,使用CAS控制并发
优点:不需要额外预留空间
缺点:读取时需要遍历整个链
lsm树
插入,删除,更新都以追加写的方式进行,删除只记录一个墓碑
合并:采用多路归并排序算法,使用大小为N的优先队列(N为合并的表的个数),遍历这N个表,放入优先队列中,然后按序输出,最终合并完成
合并时如果有相同的键,通过时间戳比较前后顺序
B+树与lsm树
B+树是就地更新结构,更新时直接覆盖旧记录,所以写代价大,读代价小。B+树需要用latch实现并发控制
lsm树是异地更新结构,直接保存新记录到新位置,所以顺序写代价小,但是因为有多个记录,读代价大。lsm树采用追加的方式写基本不需要latch实现并发控制
lsm树优化
读优化:使用布隆过滤器
写优化:tiering(分层)合并策略,把一层的合并后直接放入下一层(这样每层都会有重复的数据)
无序lsm
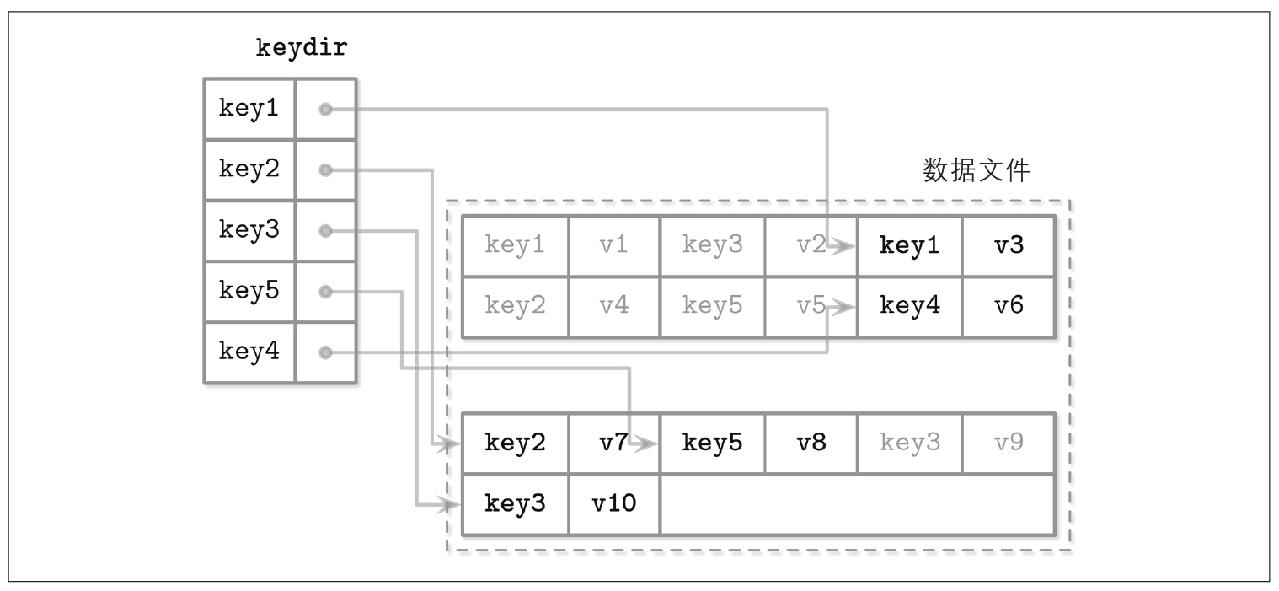
bitcask
只在内存中维护一个目录,目录每个键都指向最新的值,数据顺序追加到日志文件中
优点:简单,单点查询好
缺点:不支持范围查询,每次启动需要重建目录
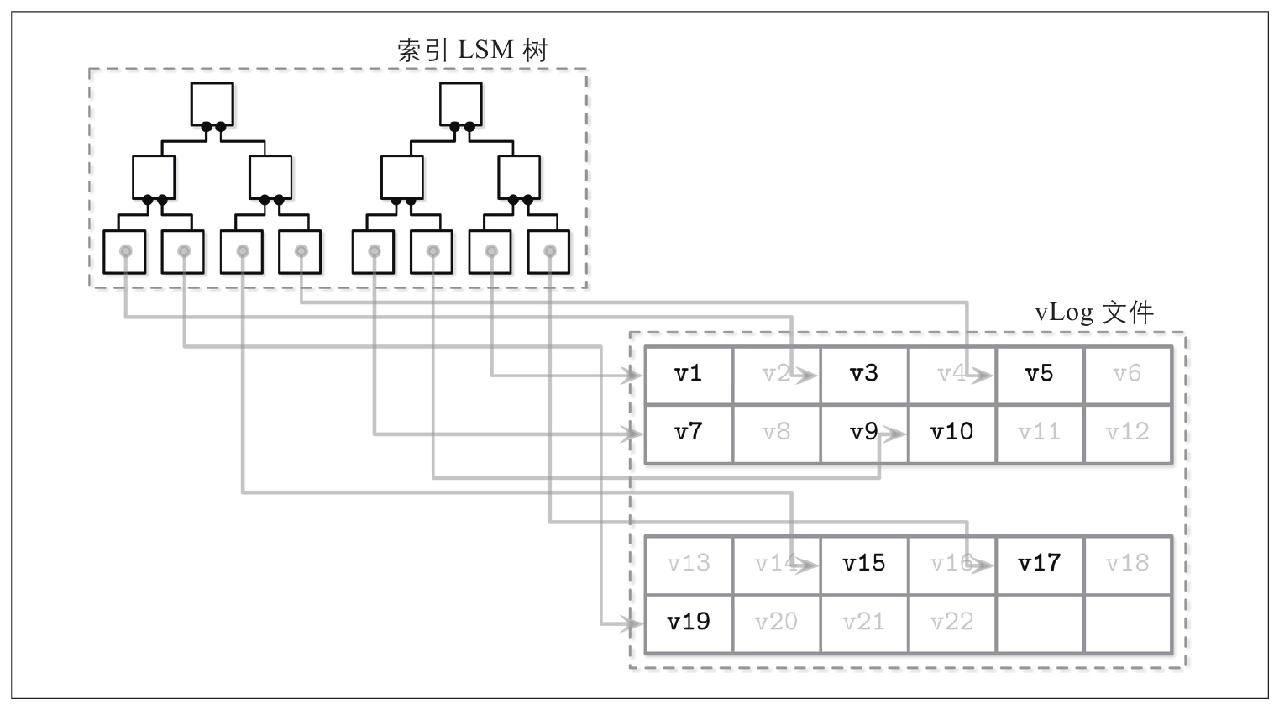
wisckey
键存储在排序的lsm树中,指向值,值无序顺序追加写入
虽然支持范围扫描,但是为随机IO
leveldb
网上总结分析的资料太多了,这里就收藏一下
Leveldb实现原理图文并茂,十分好,下图就源自这篇文章
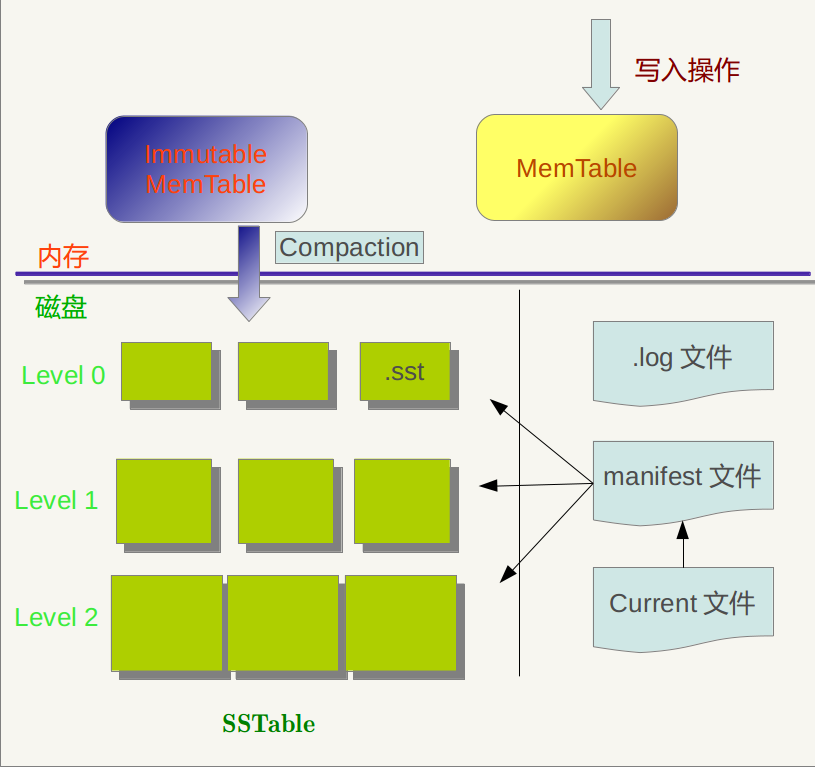
leveldb是LSM树的典型实现,单机KV存储引擎,上图是leveldb的主要组成部分。
基本组成
level自定义了字符串slice用于更方便地操作字符串
对数据有定长和变长编码两种方式,变长编码最高位1/0表示后续是否还有数据
跳表(有序链表,有与红黑树差不多的查找效率,但实现简单)
跳表原理
应用:leveldb memtable,Redis选择使用跳表,HBase写入LSM Tree结构的数据时使用跳表
布隆过滤器
判断一个元素是否在一个集合中,如果使用哈希表,额外占用空间
布隆过滤器只需要一系列比特和多个哈希函数,一个元素使用多个哈希计算,将计算结果对应位置的比特置为1
参数选定:k次哈希,m个bit位,n个元素,k=ln2*(m/n)时误差最低
哈希选定:MurMurHash2
应用场景:黑名单校验,快速去重,爬虫URL校验,leveldb/rocksdb快速判断数据是否已经在block中,避免频繁访问磁盘,解决缓存穿透问题:一直查询不存在的值,从而不断访问磁盘(解决:缓存空值和布隆过滤器)
优点:查询插入快都为O(1),节省内存
缺点:不能删除,可能有hash冲突
海量数据下使用mapreduce并行执行
为支持删除操作:计数布隆过滤器,布谷鸟过滤器