综合设计——多源异构数据采集与融合应用综合实践
[码云地址](多源异构数据采集与融合应用综合实践: Call of Silence数据采集与融合综合实验 (gitee.com))
| 这个项目属于哪个课程 | 2023数据采集与融合技术 |
|---|---|
| 组名、项目简介 | 组名:Call of Silence 项目需求:设计出一个交互友好的多源异构数据的采集与融合的小应用 项目目标:通过在web端输入文本、图片、视频等多源数据进行内容提取并对其进行概括 技术路线:前端3件套(html、css、js)、flask、 |
| 团队成员学号 | 052103117、102102142、102102148、102102149、102102150、102102154、102102155、172109005 |
| 这个项目目标 | 对获取的多模态信息进行分析概括 |
| 其他参考文献 | [1]梁永侦.基于深度学习的图像风格迁移方法研究[J].计算机时代,2023,(08):107-112.DOI:10.16644/j.cnki.cn33-1094/tp.2023.08.024 [2]熊文楷.基于深度学习的中国画风格迁移[J].科技与创新,2023,(13):176-178.DOI:10.15913/j.cnki.kjycx.2023.13.054 [3]郑卓.基于深度学习的风格迁移技术研究[D].浙江工商大学,2023.DOI:10.27462/d.cnki.ghzhc.2023.001362 |
项目整体介绍
1、项目名称:多模态内容概括
2、项目背景:在当今社会,随着数字化时代的来临,信息呈现爆炸式增长,而这些信息涵盖了多种形态,本项目主要功能就是对获取的多模态信息进行分析概括,帮助用户从信息中快速获取主要内容。
3、项目意义:面对互联网时代的信息过载,用户更需要一种智能化的工具来过滤、提炼信息,以便更快速地获取关键信息。多模态信息分析程序的功能满足了这一需求,帮助用户从海量信息中快速获取主要内容。
4、技术路线:
-
数据采集
- 采用selenium框架对bilibili中视频、封面、音频等数据进行爬取
-
前端开发:
- 使用HTML、CSS和JavaScript进行界面设计,实现用户与系统的交互。
- 用于上传文本、图片和视频等文件。
-
后端开发:
- 利用flask框架进行后端搭建。
- 用于接收前端发送的请求,对收到的数据进行保存和处理,最后返回文本结果。
-
数据处理与分析:
- 文本分析:采用星火的接口对输入的文本内容进行分析概括。
- 图片分析:
- 采用星火的接口对输入的图片进行概括,将概括后的文本进行分析概括返回图片概括后的结果。
- 视频分析:对于视频分析,没有找到合适的模型和接口进行概括,因此我们采用提取视频中的音频,对音频内容进行概括。
- 采用百度的接口对输入的视频提取主要内容并返回给用户。
-
风格迁移:
- 输入俩张图片,一张作为被学习的风格图片,一张作为学习的融合图片,通过VGG19神经网络进行训练,得到的模型,可以将任意俩张图片进行风格迁移s
5、项目部分功能展示
①项目页面展示
②文本概括功能展示
③图片概括功能展示
④视频概括功能展示
个人分工
①数据采集
通过selenium框架爬取bilibili视频,由于bilibili中视频跟音频是分开的,因此我对视频跟音频分开爬取
import time
import urllib.request
import re
from selenium import webdriver
from scrapy.selector import Selector
import requests
import os
from lxml import etree
import re
def videoDownload1(url_):
try:
headers_ = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',
'Cookie': "buvid3=7014DDC0-BF1E-B121-F5A5-F10753C840B423630infoc; i-wanna-go-back=-1; _uuid=49BF2138-1E10F-D5F5-10898-D8311651B53927883infoc; FEED_LIVE_VERSION=V8; DedeUserID=171300042; DedeUserID__ckMd5=c65bec3211413192; CURRENT_FNVAL=4048; rpdid=|(J|)J~m~llk0J'uYm|)~klRl; header_theme_version=CLOSE; hit-new-style-dyn=1; hit-dyn-v2=1; is-2022-channel=1; fingerprint=fe5c7462625770aa2abce449a7c01fd2; buvid_fp_plain=undefined; b_nut=1691207170; b_ut=5; buvid_fp=fe5c7462625770aa2abce449a7c01fd2; LIVE_BUVID=AUTO4016915564967297; buvid4=1AE73807-AEA0-7078-DA57-7F9FE5C3D6F896987-023080912-A0g5nInZwV3VmJJT68FJxw%3D%3D; home_feed_column=5; SESSDATA=fc1266d3%2C1708653865%2C29c08%2A81-i-T9HQrucvpCVcPwSwXl5LmjTyduIzF9veu0KS9i2IwXK_xkcqlt1XQyxJ3sG-9HMSwLwAAKgA; bili_jct=068bc0a79f3fa7aa1a030e478dbf6d4b; sid=5yvjlnfi; browser_resolution=1920-971; bili_ticket=eyJhbGciOiJFUzM4NCIsImtpZCI6ImVjMDIiLCJ0eXAiOiJKV1QifQ.eyJleHAiOjE2OTMzNjY1MTcsImlhdCI6MTY5MzEwNzMxNywicGx0IjotMX0.I1Yfp8S9UIkU4S0G5vtBJfslPtgY7QLCj1dx9WQpyRmxKpZoA1qB5UYXNW4KBSZFGljMm7F1lbGXSGco7F79JZJ2sZNBvH9QiSVlmipzAJKaucIoFh6s3m1jpqjLp10r; bili_ticket_expires=1693366517; bp_video_offset_171300042=834376858445283367; b_lsid=1021245DB_18A3567E5C2; CURRENT_QUALITY=80; PVID=2"
}
response_ = requests.get(url_, headers=headers_)
str_data = response_.text
html_obj = etree.HTML(str_data) # 转换格式类型
res_ = html_obj.xpath('//title/text()')[0]
title_ = re.findall(r'(.*?)_哔哩哔哩', res_)[0]
title_ = title_.replace('/', '')
title_ = title_.replace(' ', '')
title_ = title_.replace('&', '')
title_ = title_.replace(':', '')
url_list_str = html_obj.xpath('//script[contains(text(),"window.__playinfo__")]/text()')[0]
# 纯视频的url
video_url = re.findall(r'"video":\[{"id":\d+,"baseUrl":"(.*?)"', url_list_str)[0]
# 纯音频的url
audio_url = re.findall(r'"audio":\[{"id":\d+,"baseUrl":"(.*?)"', url_list_str)[0]
# 设置跳转字段的headers
headers_ = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36',
'Referer': url_
}
# 获取纯视频的数据
response_video = requests.get(video_url, headers=headers_, stream=True)
bytes_video = response_video.content
# 获取纯音频的数据
response_audio = requests.get(audio_url, headers=headers_, stream=True)
bytes_audio = response_audio.content
# 获取文件大小, 单位为KB
video_size = int(int(response_video.headers['content-length']) / 1024)
audio_size = int(int(response_audio.headers['content-length']) / 1024)
# 保存纯视频的文件
title_1 = title_ + '!' # 名称进行修改,避免重名
title_1 = title_1.replace(':', '_')
with open(f'D:/python/exercise/数据采集大作业/video/{title_1}.mp4', 'wb') as f:
f.write(bytes_video)
with open(f'D:/python/exercise/数据采集大作业/audio/{title_1}.mp3', 'wb') as f:
f.write(bytes_audio)
ffmpeg_path = r".\ffmpeg.exe"
command = f'{ffmpeg_path} -i audio/{title_1}.mp3 -i video/{title_1}.mp4 -c copy ./video/{title_}/{title_}.mp4 -loglevel quiet'
os.system(command)
# 显示合成文件的大小
print(f'{title_} 下载完成')
except Exception as e:
print(f"下载失败: {e}")
return # 跳过当前视频的下载
browser = webdriver.Chrome()
url = 'https://www.bilibili.com/'
browser.get(url)
time.sleep(5)
js_height = 'return document.body.scrollHeight'
height = browser.execute_script(js_height)
for i in range(15):
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(5)
new_height = browser.execute_script(js_height)
height = new_height
content = browser.page_source
browser.quit()
selector = Selector(text=content)
rows = selector.xpath("//div[@class='bili-video-card is-rcmd']")
for row in rows:
href = row.xpath('.//a/@href').extract_first()
if href and href.startswith("https"):
videoDownload1(href)
结果展示
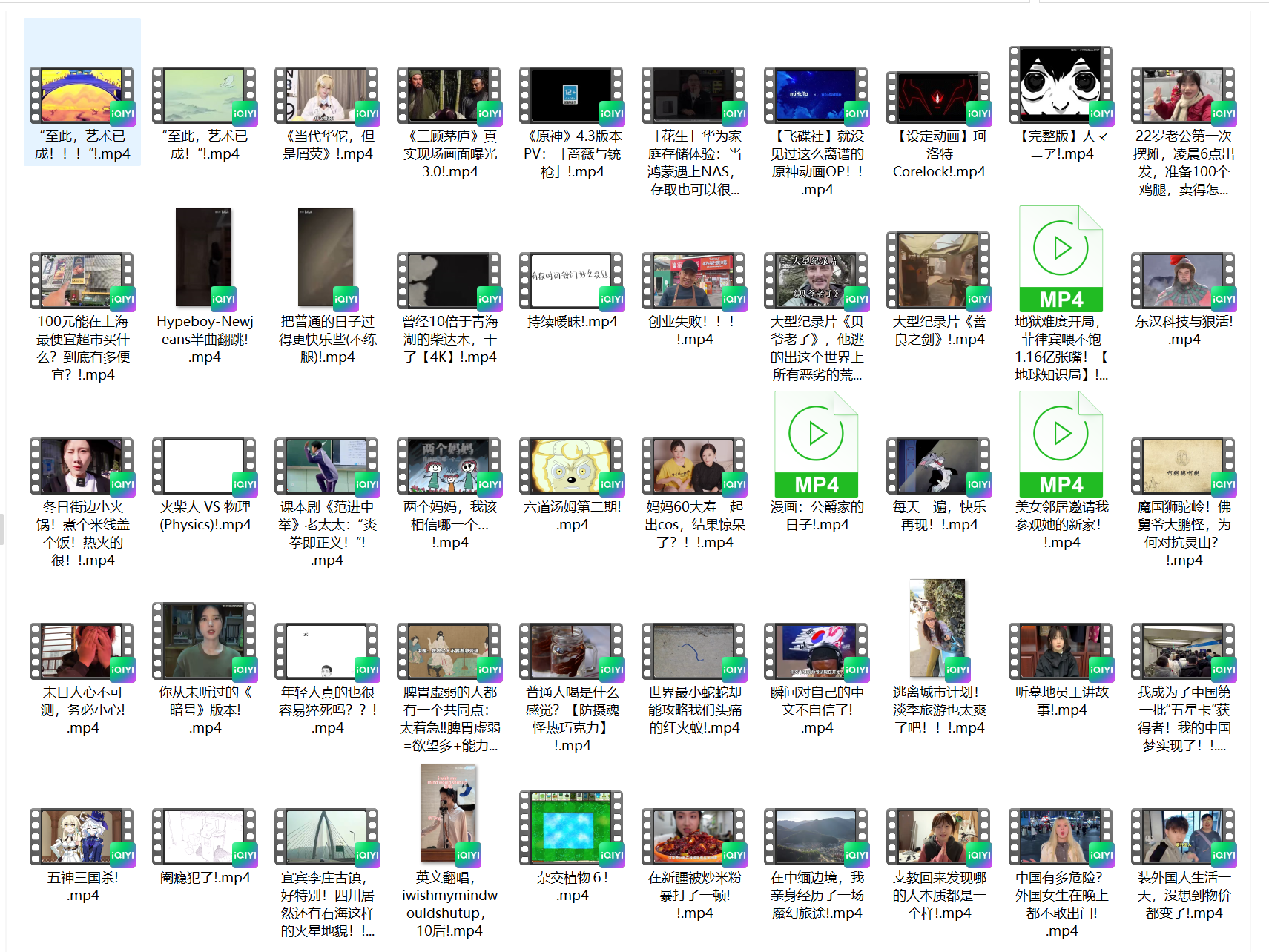
爬取视频结果展示
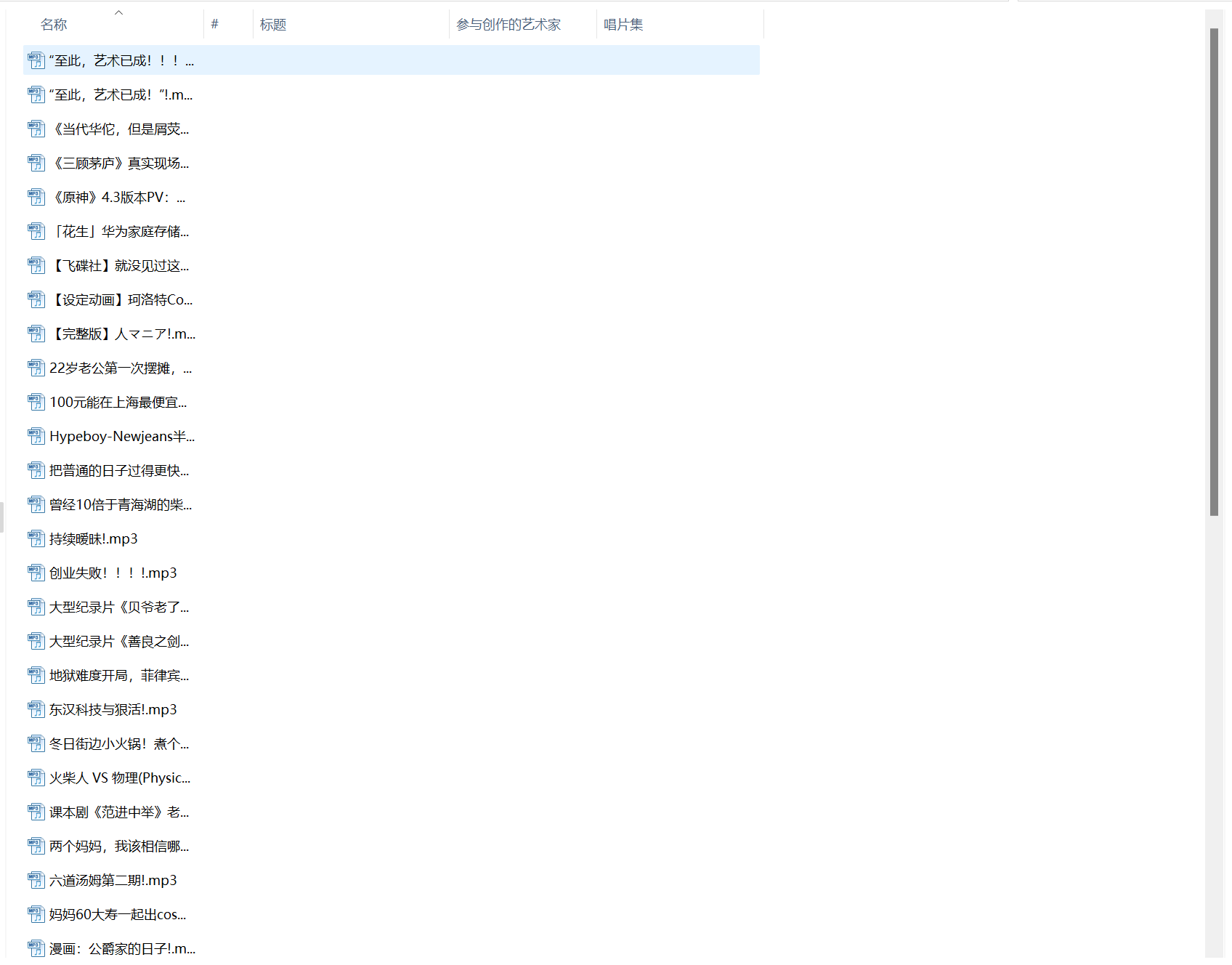
爬取音频结果展示
②算法调试
在这次综合实践中,我调用了百度的接口将视频中的音频提取出来,并对音频进行分析,使我们的项目能够对视频内容进行分析提取最终返回过程
代码展示:
import os
def mp4_to_wav(mp4_path, wav_path, sampling_rate):
"""
mp4 转 wav
:param mp4_path: .mp4文件路径
:param wav_path: .wav文件路径
:param sampling_rate: 采样率
:return: .wav文件
"""
# 如果存在wav_path文件,先删除。
if os.path.exists(wav_path): # 如果文件存在
# 删除文件,可使用以下两种方法。
os.remove(wav_path)
# 终端命令
command = "ffmpeg -i {} -ac 1 -ar {} {} && y".format(mp4_path, sampling_rate, wav_path)
print('命令是:',command)
# 执行终端命令
os.system(command)
if __name__ == '__main__':
mp4_path = "D:/python/exercise/数据采集大作业/test/test2.mp4"
wav_path = 'D:/python/exercise/数据采集大作业/test/atest2.wav'
sampling_rate = 16000
mp4_to_wav(mp4_path, wav_path, sampling_rate)
from aip import AipSpeech
# 从百度AI开放平台创建应用处获取
APP_ID = '44648474'
API_KEY = 'oiLoqI11gAl9sgN7nMIsBgCl'
SECRET_KEY = 'wxdg8rgnelbbBG5herHN6tyzxfy7T35u'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 读取文件
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
# 识别本地文件
def get_text():
result = client.asr(get_file_content('D:/python/exercise/数据采集大作业/test/atest2.wav'), 'wav', 16000, {
'dev_pid': 1536})
if 'result' in result and len(result['result']) > 0:
text = result['result'][0]
return text
else:
return "未能识别文本"
print(get_text())
③项目部署
将本次项目中的前、后端部署到华为云服务器上。因为是第一次部署,在过程中一直出现报错,但是最终还是成功部署到云服务器上,通过本次部署对华为云有着进一步的理解。