文本三剑客
1. grep
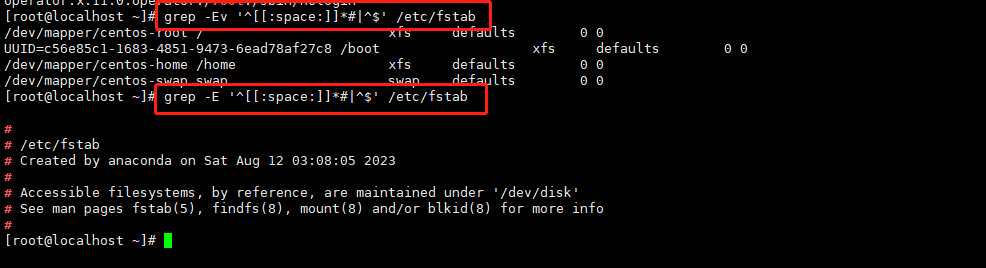
grep [选项]… 查找条件 目标文件
-
-i:查找时忽略大小写
-
-v:反向查找,输出与查找条件不相符的行
-
-o 只显示匹配项
-
-f 对比两个文件的相同行
-
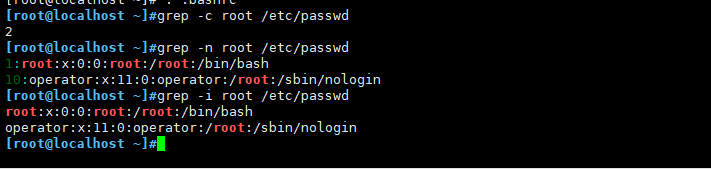
-c 匹配的行数([root@localhost ~]# grep -c root passwd 2)
选项:
-color=auto 对匹配到的文本着色显示

-m # 匹配#次后停止

-v 显示不被pattern匹配到的行,即取反
-i 忽略字符大小写 -n 显示匹配的行号 -c 统计匹配的行数
-o 仅显示匹配到的字符串 -q 静默模式,不输出任何信息 -A # after, 后#行
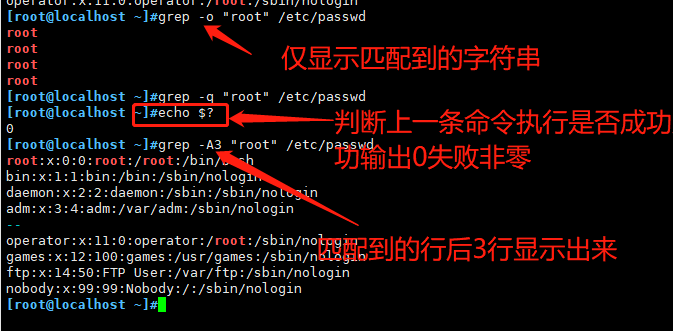
-B # before, 前#行 -C # context, 前后各#行 -e 实现多个选项间的逻辑or关系,如:grep –e ‘cat ' -e ‘dog' file
[root@localhost ~]#grep -e root -e bash /etc/passwd#包含root或者包含bash 的行

grep -E "root|bash" /etc/passwd
开启扩展正则表达式

-w 匹配整个单词
grep -w root /etc/passwd

-E 使用ERE,相当于egrep -F 不支持正则表达式,相当于fgrep -f file 根据模式文件,处理两个文件相同内容 把第一个文件作为匹配条件 -r 递归目录,但不处理软链接 -R 递归目录,但处理软链接
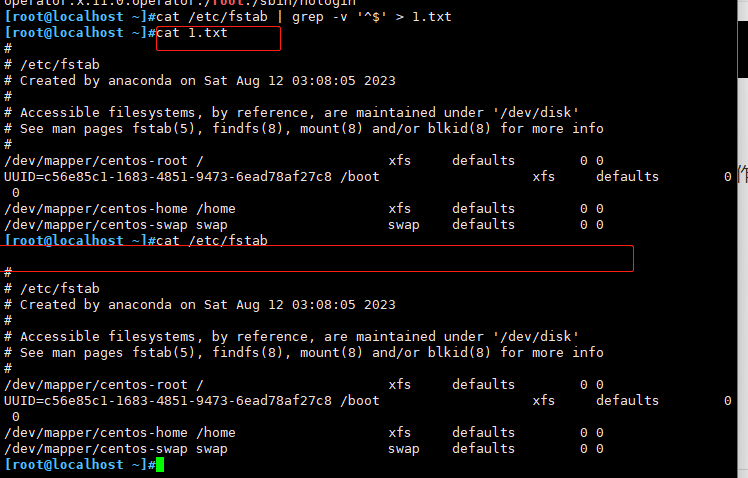
cat /etc/fstab | grep -v '^$' > 1.txt
#将非空行写入到1.txt文件
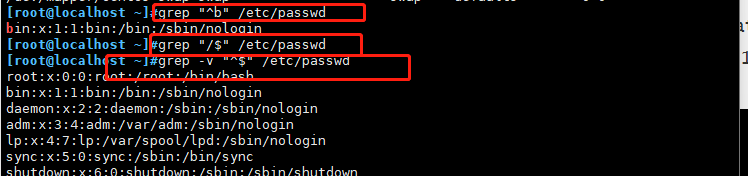
[root@localhost ~]#grep "^b" /etc/passwd //过滤已b开头
grep '/$' 123.txt //过滤已/结尾
grep -v "^$" 123.txt //过滤非空行
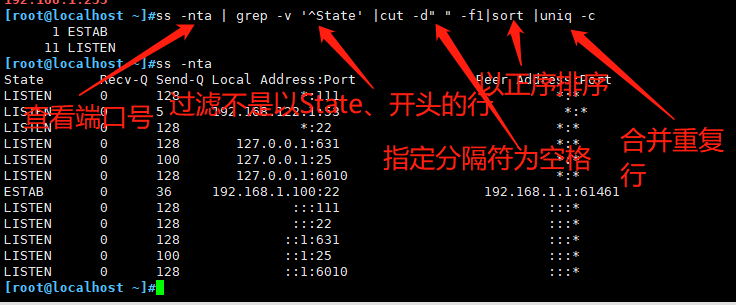
统计当前主机的连接状态
ss -nta | grep -v '^State' |cut -d" " -f1|sort |uniq -c
统计当前连接主机数
ss -nt |tr -s " "|cut -d " " -f5|cut -d ":" -f1 |sort|uniq -c

2.sed
sed 即 Stream EDitor,和 vi 不同,sed是行编辑器
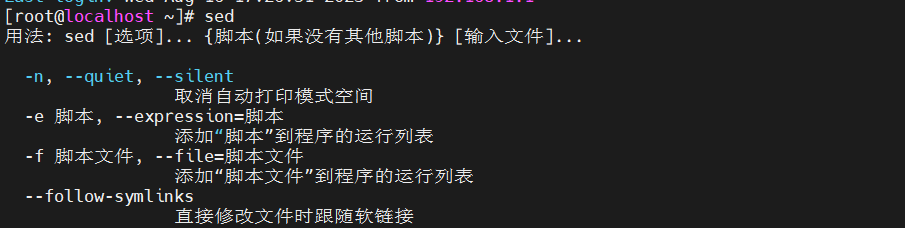
Sed是从文件或管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行,直到最后一行。每当处理一行时,把当前处理的行存储在临时缓冲区中,称为模式空间(PatternSpace),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。一次处理一行的设计模式使得sed性能很高,sed在读取大文件时不会出现卡顿的现象。如果使用vi命令打开几十M上百M的文件,明显会出现有卡顿的现象,这是因为vi命令打开文件是一次性将文件加载到内存,然后再打开。Sed就避免了这种情况,一行一行的处理,打开速度非常快,执行速度也很快
5.3.1基本用法
sed [option]... 'script;script;...' [input file...] 选项 自身脚本语法 支持标准输入管道
常用选项: -n 不输出模式空间内容到屏幕,即不自动打印 -e 多点编辑[root@www data]#sed -n -e '/^r/p' -e'/^b/p' /etc/passwd -f FILE 从指定文件中读取编辑脚本 -r, -E 使用扩展正则表达式 -i.bak 备份文件并原处编辑 -s 将多个文件视为独立文件,而不是单个连续的长文件流
基本用法
[root@localhost ~]#sed #提示错误
[root@localhost ~]#sed ' ' ####默认将输入内容打印出来,系统自带自动打印
[root@localhost ~]#sed '' /etc/fstab ####查看文件内容
[root@localhost ~]#sed '' </etc/fstab ####支持重定向
[root@localhost ~]#cat /etc/issue |sed '' #####也支持管道符

5.3.2sed脚本格式
单引号中间需要写脚本;脚本格式如下
'地址+命令'组成
-
不给地址:对全文进行处理(比如行号)
-
单地址: #:指定的行,$:最后一行 /pattern/:被此处模式所能够匹配到的每一行,正则表达式
-
地址范围: #,# #从#行到第#行,3,6 从第3行到第6行 #,+# #从#行到+#行,3,+4 表示从3行到第7行 /pat1/,/pat2/ 第一个正则表达式和第二个正则表达式之间的行
#,/pat/ 从#号行为开始找到 pat为止 /pat/,# 找到#号个pat为止
-
步进:~ 1~2 奇数行 2~2 偶数行
命令 p 打印当前模式空间内容,追加到默认输出之后 Ip 忽略大小写输出 d 删除模式空间匹配的行,并立即启用下一轮循环 a []text 在指定行后面追加文本,支持使用\n实现多行追加 i []text 在行前面插入文本 c []text 替换行为单行或多行文本 w file 保存模式匹配的行至指定文件 r file 读取指定文件的文本至模式空间中匹配到的行后 = 为模式空间中的行打印行号 ! 模式空间中匹配行取反处理 q 结束或退出sed
[root@localhost ~]#seq 10 | sed 'p' #带有自动打印功能,p又再打印一遍
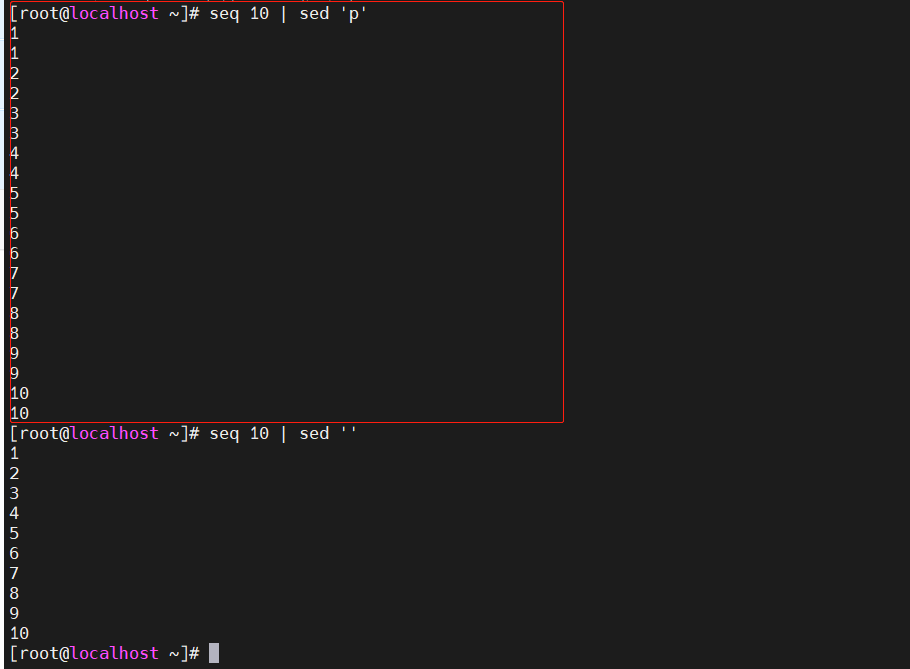
[root@localhost ~]#seq 10 | sed -n 'p' #-n 选项关闭自动打印功能
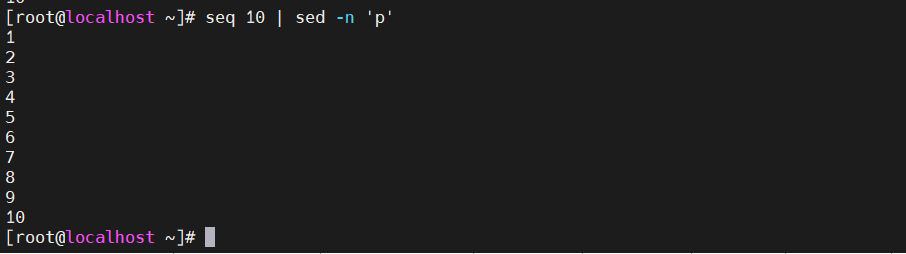
#如何加入地址 直接显示第三行 [root@localhost ~]#seq 10 | sed -n '3p' #直接显示第3行

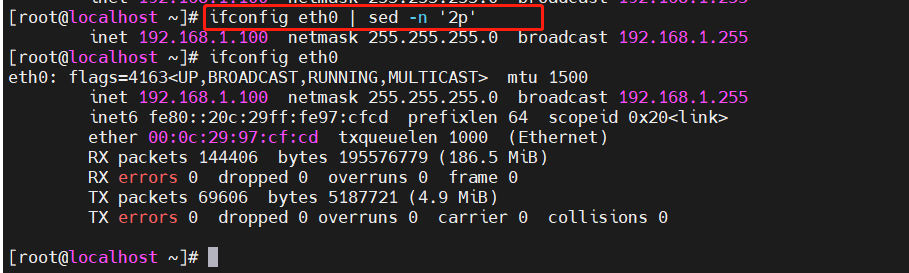
[root@localhost ~]#ifconfig ens33|sed -n ‘2p’ #直接显示第二行内容
###还支持正则表达式
[root@localhost ~]#sed '/root/p' /etc/passwd ###自动打印需要关闭否则会全部打印
root❌0:0:root:/root:/bin/bash 省略多行。。。。。。。。 rpc❌32:32:Rpcbind Daemon:/var/lib/rpcbind:/sbin/nologin

[root@localhost ~]#sed -n '/root/p' /etc/passwd ##将包含root的行打印出来 /root(需要匹配的内容)/p(打印) 文件名 ###与 grep root /etc/passwd 功能相同

####如何显示范围 行号,行号 [root@localhost ~]#seq 10|sed -n '3,6p' ###显示范围

[root@localhost ~]#seq 10|sed -n '3,+4p' ##3 往后加4行

###还可以匹配 两个正则表达式之间的行 举例子 [root@localhost ~]#cat /etc/passwd ###我想显示b开头 和f开头中间的行
sed -n '/^b/,/^f/p' /etc/passwd
基本格式 '/表达式1/,/表达式2/p' (不要忘记打印)p 文件名
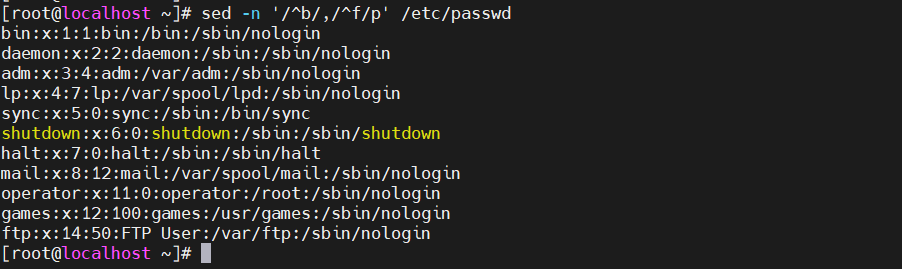
####匹配方式 如果有多个复合条件的表达式 先开始找b开头一直找到f开头 然后再重新找b开头,一找到f开头,没有f开头就全显示 重复循环
显示几点到几点分的日志####### 让你查找几点几分到几点几分之间的日志
sed -n '/2018:08:09/,/2018:09:42:37/p' access_log
#奇数偶数表示 [root@localhost ~]#seq 10|sed -n '1~2p'

[root@localhost ~]#seq 10|sed -n '2~2p'

[root@localhost ~]#seq 10|sed -n '3~3p'

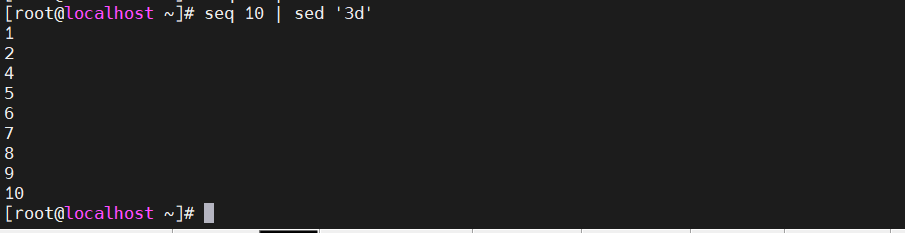
-d选项删除 [root@localhost ~]#seq 10 |sed '3d' ###将第三行删除
##修改文件内容,常常用于修改配置文件 -i 与 -i.bak 修改文件 修改文件前先备份
[root@localhost ~]#seq 10 >test.txt [root@localhost ~]#cat test.txt
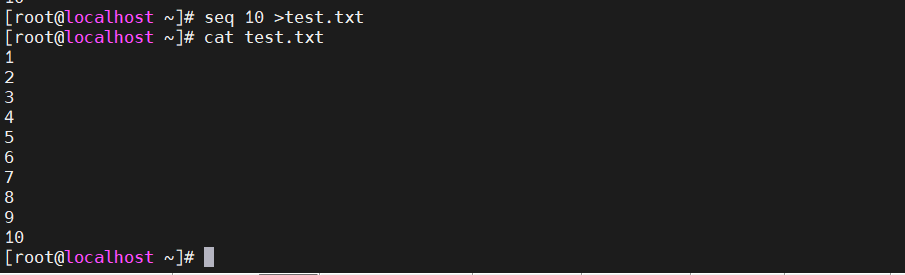
[root@localhost ~]#sed -i '2~2d' test.txt 删除偶数 [root@localhost ~]#cat test.txt

-a 后面追加
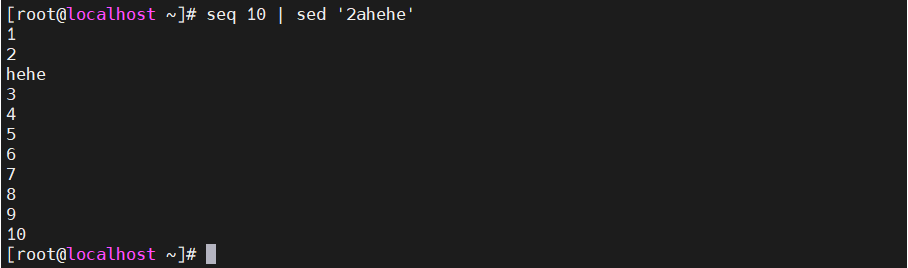
[root@localhost ~]#seq 10 |sed '2ahehe' ###第二行后追加hehe
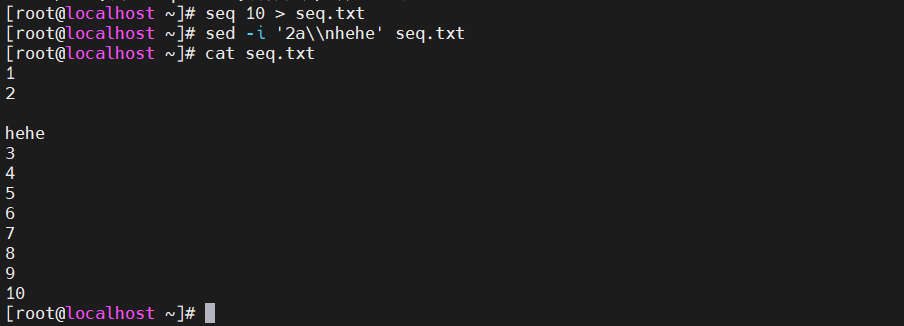
[root@localhost ky15]#sed -i '2a\n hehe' seq.txt #修改文件内部需要多加一个\
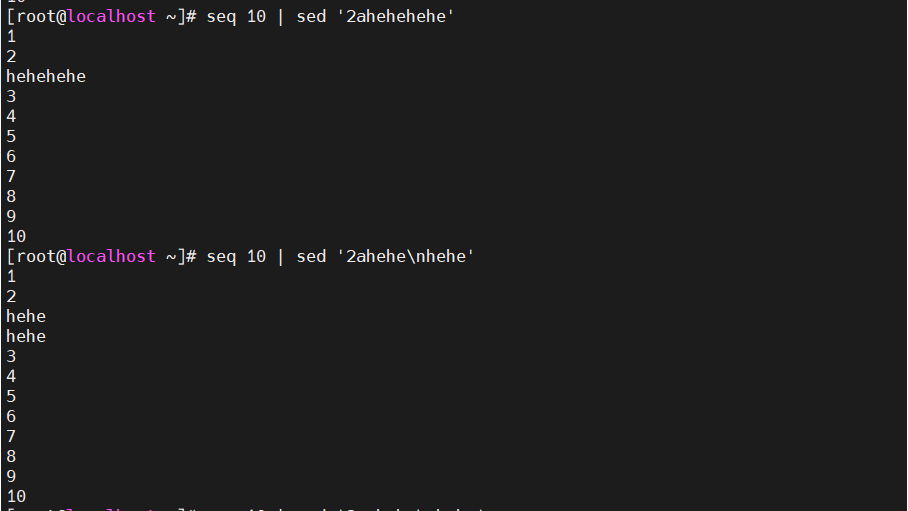
[root@localhost ~]#seq 10 |sed '2a \ hehe\nhaha' ###\表示空格 \n 表示换行
i前面插入
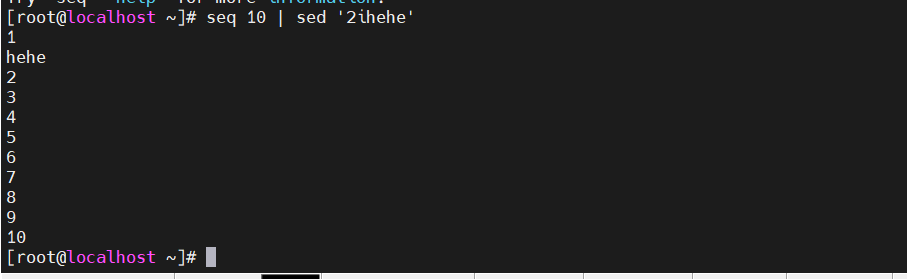
[root@localhost ~]#seq 10 |sed '2ihehe' #第二行前面插入hehe
c替换
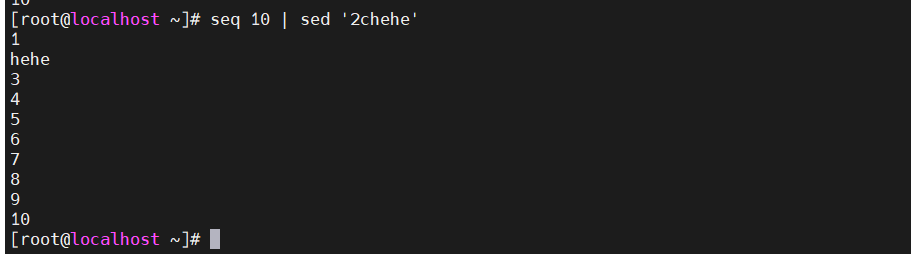
[root@localhost ~]#seq 10 |sed '2chehe' #第二行替换成hehe
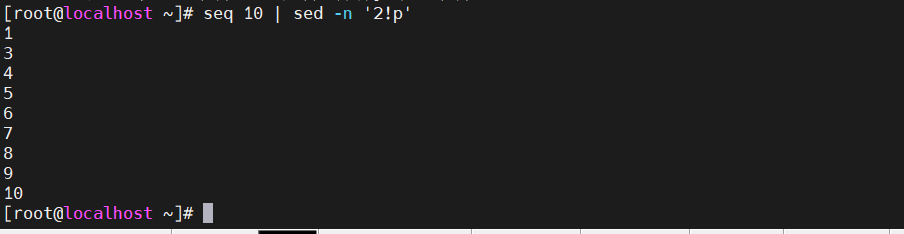
[root@localhost ~]# seq 10 |sed -n '2!p' #取反
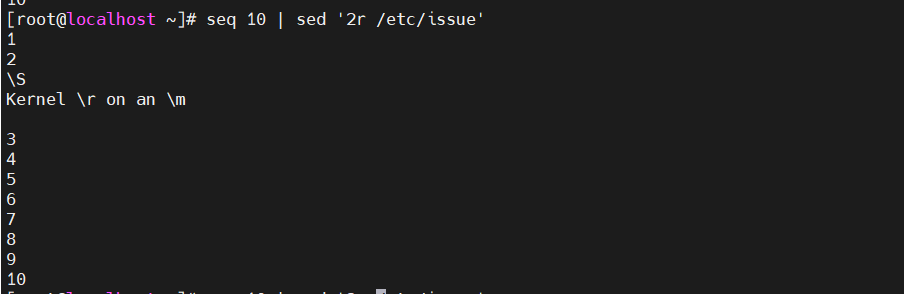
在打印第2行数字时,将读取并输出/etc/issue文件的内容
[root@localhost ~]# seq 10 | sed '2r /etc/issue'
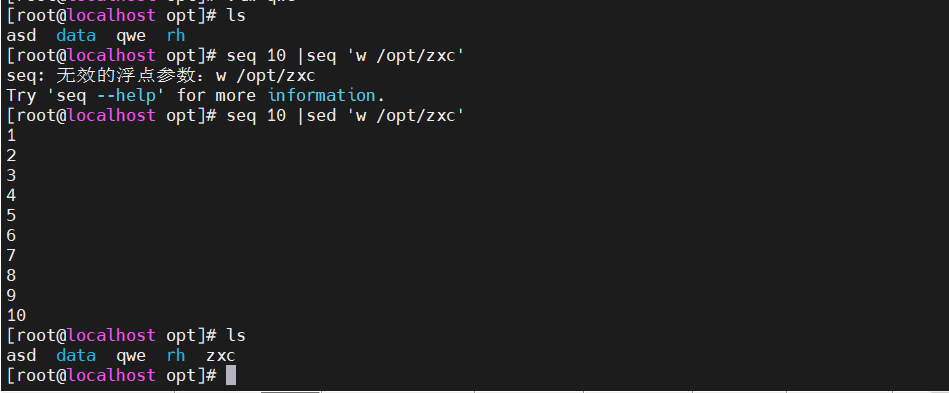
[root@localhost ~]# seq 10 |sed 'w /opt/asd'
该命令的作用是将从1到10的数字序列生成并逐行打印出来。然后,将每行数字写入到/opt/asd文件中。没有自动创建 , 如果asd有内容则会被覆盖
[root@localhost opt]# sed '2=' /etc/passwd
打印出/etc/passwd文件中的第2行的行号。

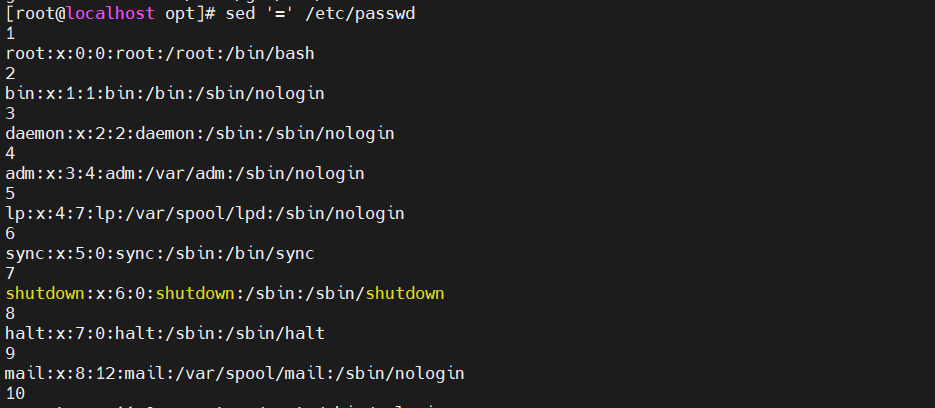
[root@localhost opt]# sed '=' /etc/passwd
打印行号
5.3.3搜索替代
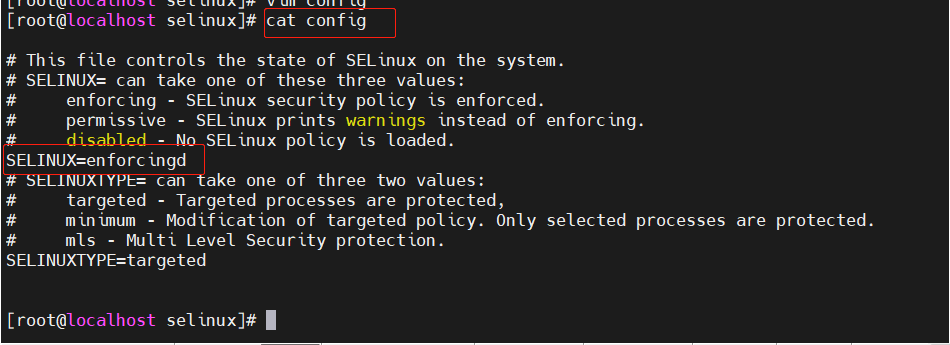
s/pattern/string/修饰符 查找替换,支持使用其它分隔符,可以是其它形式:s@@@,s### 替换修饰符: g 行内全局替换 p 显示替换成功的行 w /PATH/FILE 将替换成功的行保存至文件中 I,i 忽略大小写
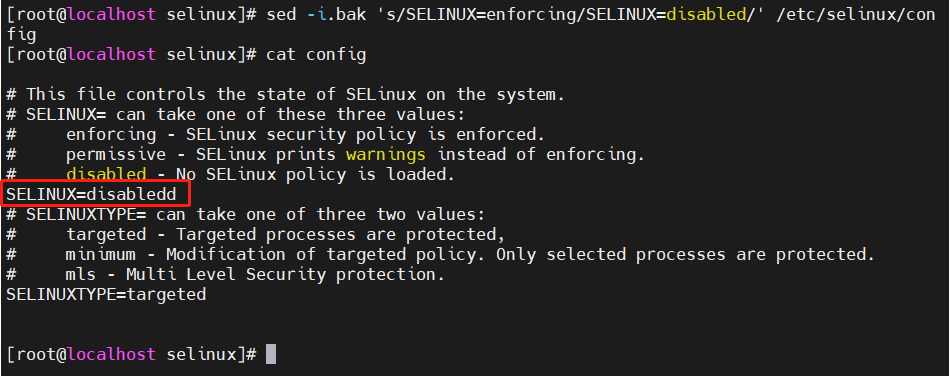
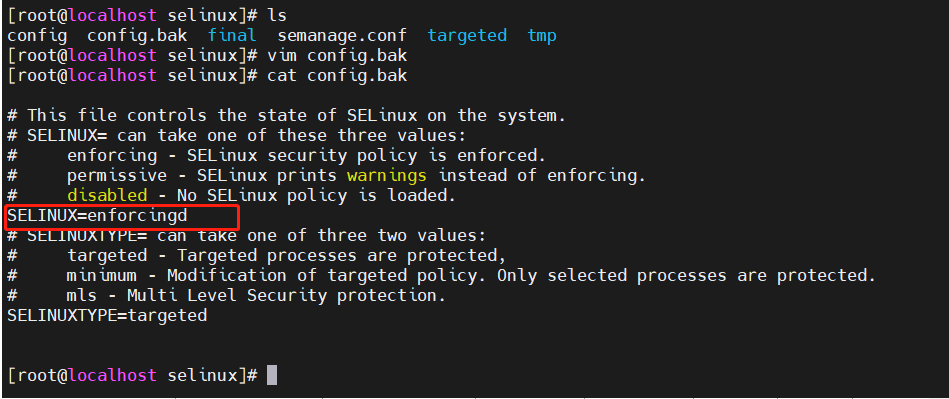
sed -i.bak 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
将/etc/selinux/config中的SELINUX=enforcing替换为SELINUX=disabled并将原配置文件保存在config.bak
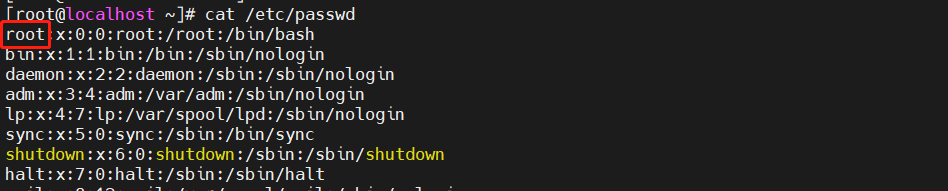
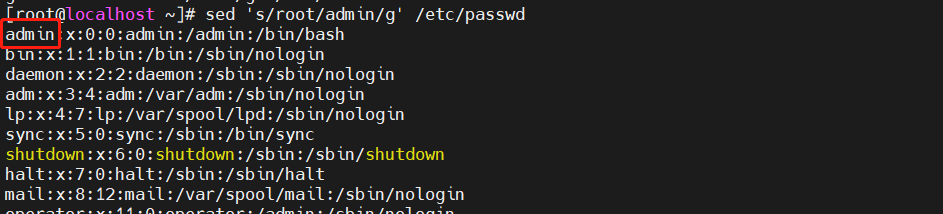
[root@localhost ~]#sed 's/root/admin/g' /etc/passwd
将/etc/passwd里的root替换为admin
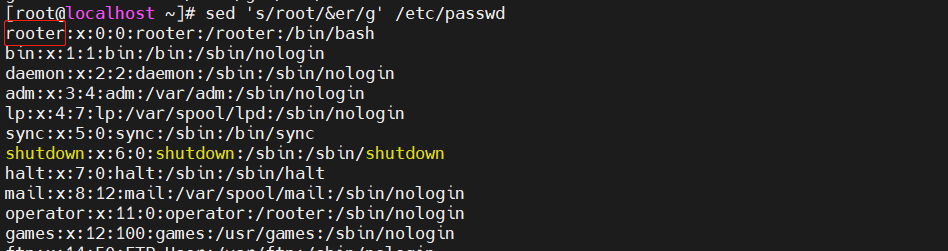
[root@localhost ~]#sed 's/root/&er/g' /etc/passwd #&指代之前的内容
[root@localhost ~]#echo 123abcxyz |sed -r 's/(123)(abc)(xyz)/\1/' ##分组 s//代表查找替换 ()代表分组 \1 代表留下的组
后向引用

[root@localhost ~]#echo 123xyzabc |sed -r 's/(123)(xyz)(abc)/\1\2/'

[root@localhost ~]#echo 123xyzabc |sed -r 's/(123)(xyz)(abc)/\1\3/'

[root@localhost ~]#ifconfig ens33|sed -rn '2s/.inet ([0-9.]+) ./\1/p'

[root@localhost ~]#echo /etc/sysconfig/network-scripts/ifcfg-ens33 |sed -nr 's@^(.*)/(/+)@\2@p'
s///可用别的代替s###或s@@@

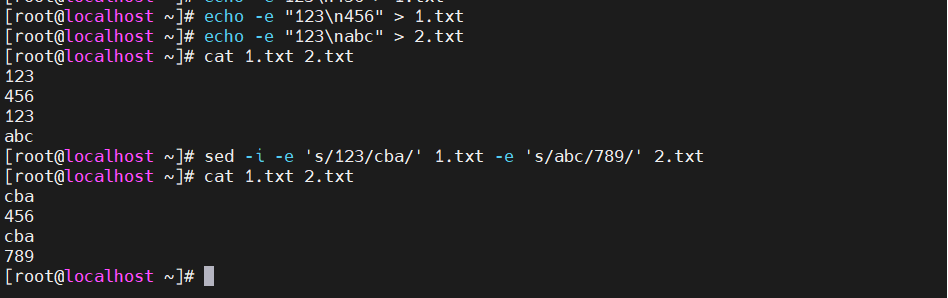
[root@localhost selinux]#cat 1.txt 2.txt
[root@localhost selinux]#sed -i -e 's/123/cba/' 1.txt -e 's/abc/789/' 2.txt
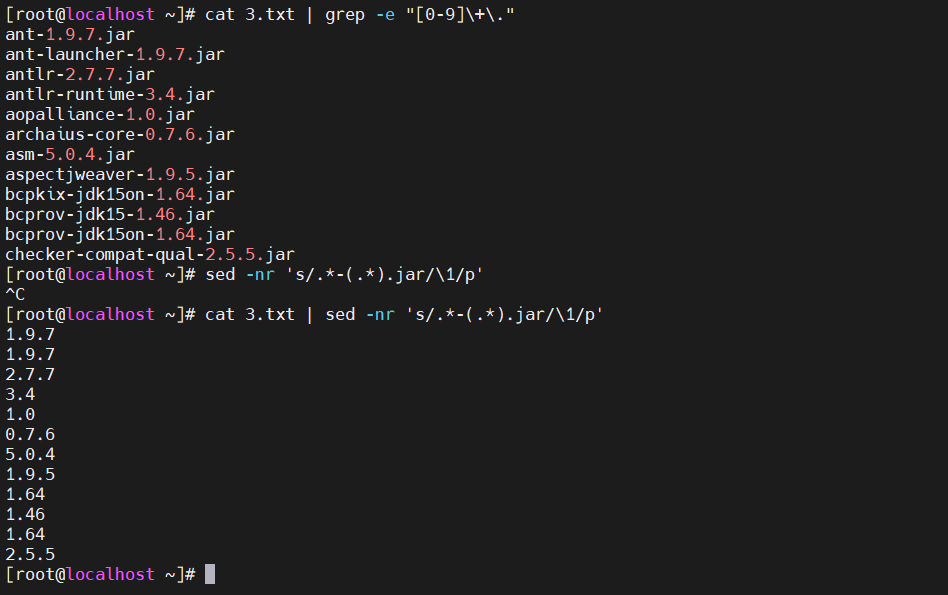
提取版本号
[root@localhost ~]# cat 3.txt | sed -nr 's/.-(.).jar/\1/p'
5.3.4 变量
[root@localhost ~]# sed -nr '/$name/p' /etc/passwd [root@localhost ~]# sed -nr ''/$name/p'' /etc/passwd

[root@www data]#sed -nr '/'$name'/p' /etc/passwd

6 AWK
gawk:模式扫描和处理语言,可以实现下面功能
vim: 是将整个文件加载到内存中 再进行编辑, 受限你的内存
awk(语言): 读取一行处理一行,
在 Linux/UNIX 系统中,awk 是一个功能强大的编辑工具,逐行读取输入文本,默认以空格或tab键作为分隔符作为分隔,并按模式或者条件执行编辑命令。而awk比较倾向于将一行分成多个字段然后进行处理。AWK信息的读入也是逐行
指定的匹配模式进行查找,对符合条件的内容进行格式化输出或者过滤处理,可以在无交互
的情况下实现相当复杂的文本操作,被广泛应用于 Shell 脚本,完成各种自动化配置任务。
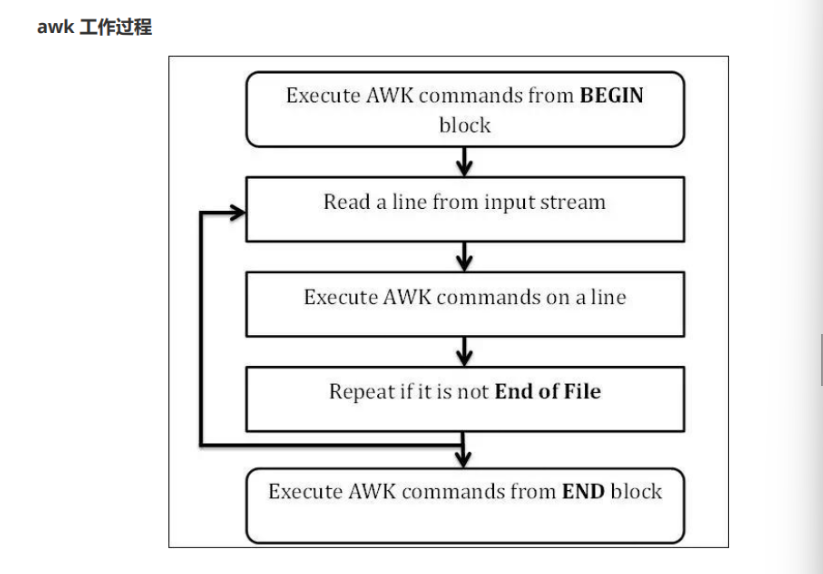
第一步:执行BEGIN{action;… }语句块中的语句 第二步:从文件或标准输入(stdin)读取一行,然后执行pattern{ action;… }语句块,它逐行扫描文件, 从第一行到最后一行重复这个过程,直到文件全部被读取完毕。 第三步:当读至输入流末尾时,执行END{action;…}语句块 BEGIN语句块在awk开始从输入流中读取行之前被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中 END语句块在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块 pattern语句块中的通用命令是最重要的部分,也是可选的。如果没有提供pattern语句块,则默认执行{ print },即打印每一个读取到的行,awk读取的每一行都会执行该语句块
工作原理:
前面提到 sed 命令常用于一整行的处理,而 awk 比较倾向于将一行分成多个“字段”然后再进行处理,且默认情况下字段的分隔符为空格或 tab 键。awk 执行结果可以通过 print 的功能将字段数据打印显示。
格式:
awk [options] 'program' var=value file…
awk 选项 模式 处理的动作 指定 '{print }'
-F 指定分隔符 -v 自定义变量 -f 脚本
awk [options] -f programfile var=value file…
#说明: program通常是被放在单引号中,并可以由三种部分组成 BEGIN语句块 模式匹配的通用语句块 END语句块
pattern{action statements;..} pattern:决定动作语句何时触发及触发事件,比如:BEGIN,END,正则表达式等 action statements:对数据进行处理,放在{}内指明,常见:print, printf
#常见选项: -F “分隔符” 指明输入时用到的字段分隔符,默认的分隔符是若干个连续空白符 -v(小v) var=value 变量赋值
awk [选项] '模式条件{操作}' 文件1 文件2....
awk -f|-v 脚本文件 文件1 文件2.....
6.1基础用法
print动作
[root@localhost ~]#awk '' #什么都不写 空没有效果

[root@localhost ~]#awk '{print}' ##在打印一遍

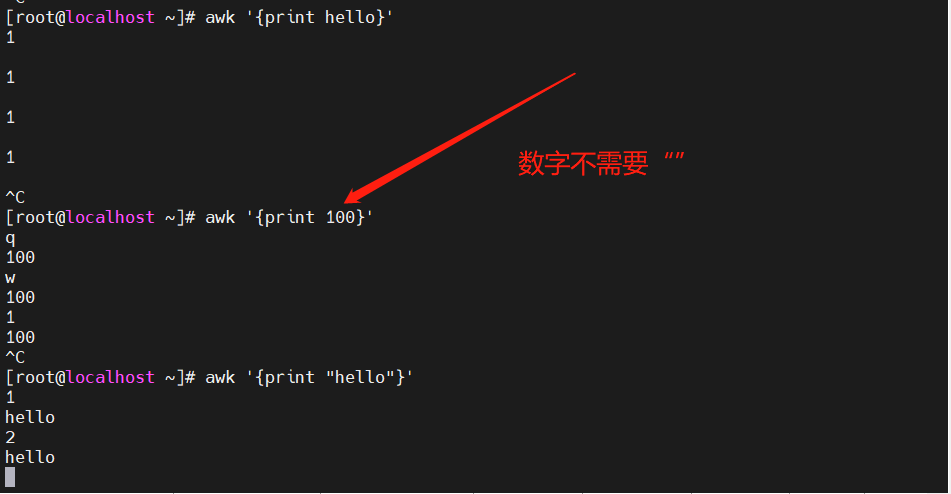
[root@localhost ~]#awk '{print "hello"}' #字符串需要添加双引号,单引号已被使用
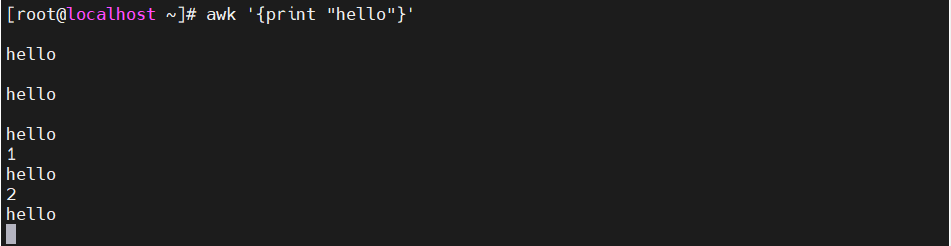
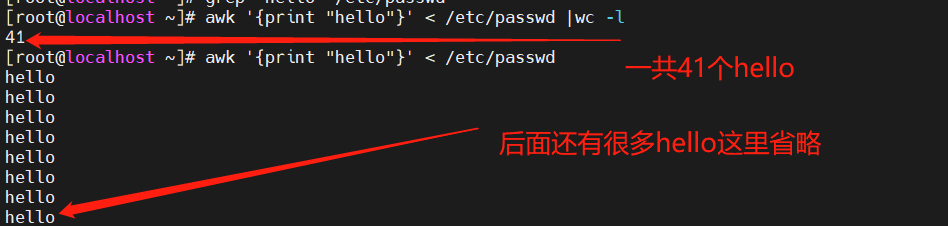
[root@localhost ~]#awk '{print "hello"}' < /etc/passwd
[root@localhost ~]# awk '{print "hello"}' < /etc/passwd |wc -l 41
输出的行数与/etc/passwd文件中的行数相同,每行都打印了"hello"字符串。
[root@localhost ~]#awk 'BEGIN{print 100+200}' #运算

BEGIN
[root@localhost ~]# awk 'BEGIN {print "hello"}' hello
#BEGIN比较特殊只打一行

[root@localhost ~]#awk -F: 'BEGIN {print "hello"} {print $1}' /etc/passwd |head -n3 #先处理BEGIN 中的式子

[root@localhost ~]#awk '{print 100}' #数字不需要“ ”
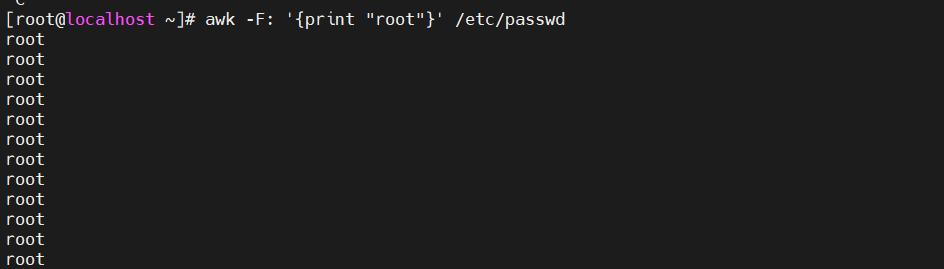
[root@localhost ~]#awk -F: '{print "root"}' /etc/passwd #打印root 多少行=passwd文件里的行数

[root@localhost ky15]#echo {a..b} |awk '{print $1}' #连续的空白符也可以
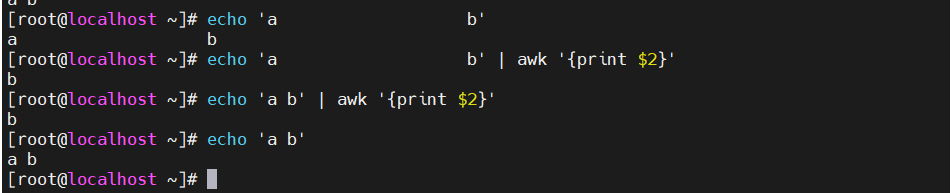
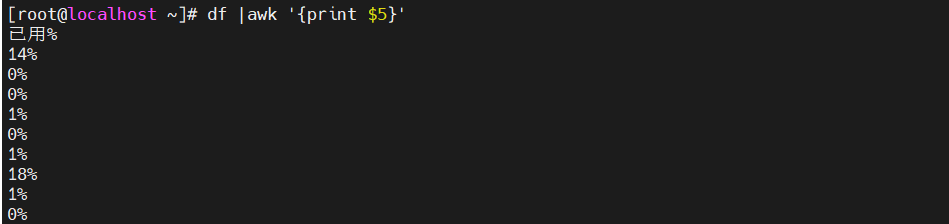
[root@localhost ky15]#df|awk '{print $5}' #分区利用率
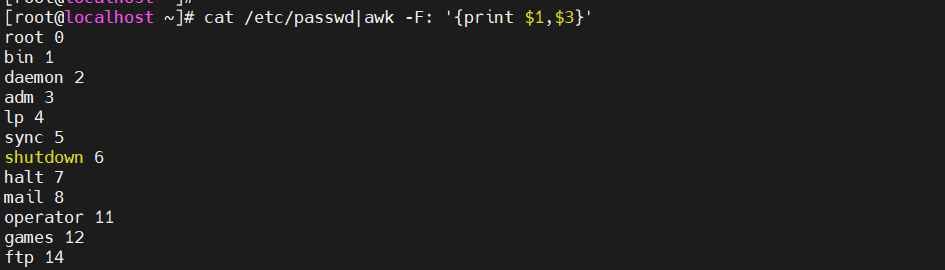
[root@localhost ky15]#cat /etc/passwd|awk -F: '{print $1,$3}' #指定冒号作为分隔符,打印第一列和第三列
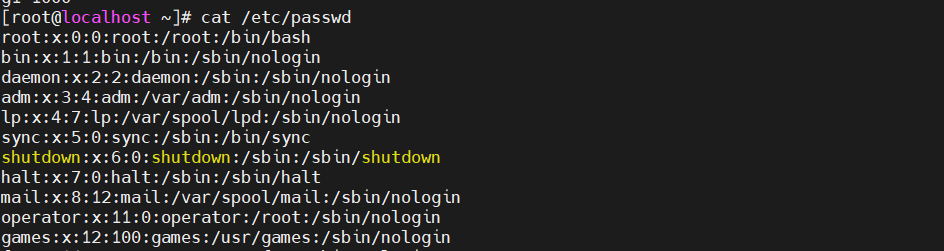
[root@localhost ky15]#cat /etc/passwd|awk -F: '{print $1":"$3}' #用冒号分隔开
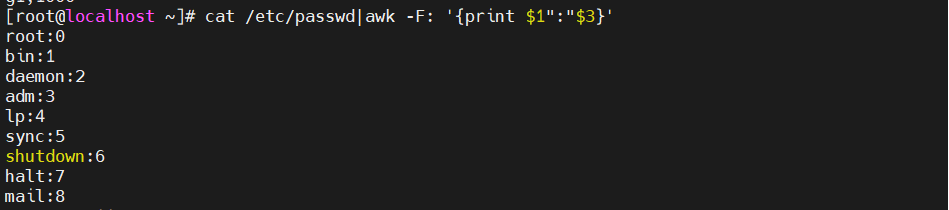
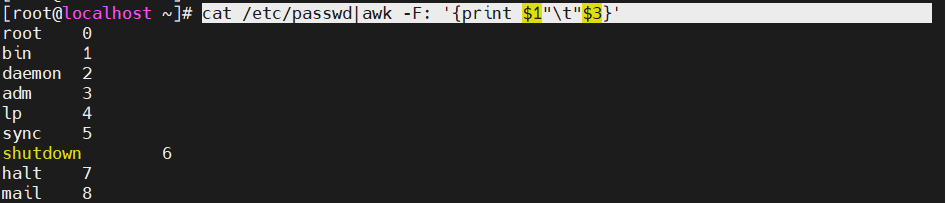
[root@localhost ky15]#cat /etc/passwd|awk -F: '{print $1"\t"$3}'
用制表符隔开
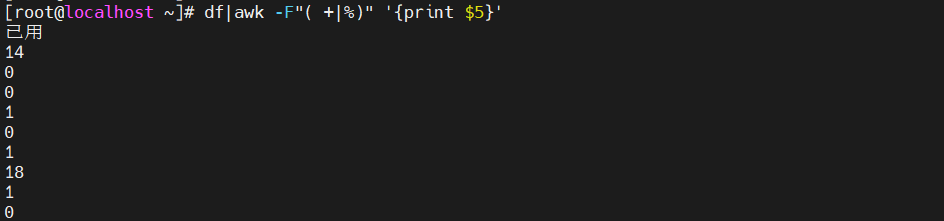
[root@localhost ~]#df|awk -F"( +|%)" '{print $5}'
一一格以上空格或%为分隔符
df |awk -F"[[:space:]]+|%" '{print $5}'
[[:space:]]是正则表达式中用于匹配空白字符的字符类。它可以匹配空格、制表符、换行符等各种空白字符。+一个以上
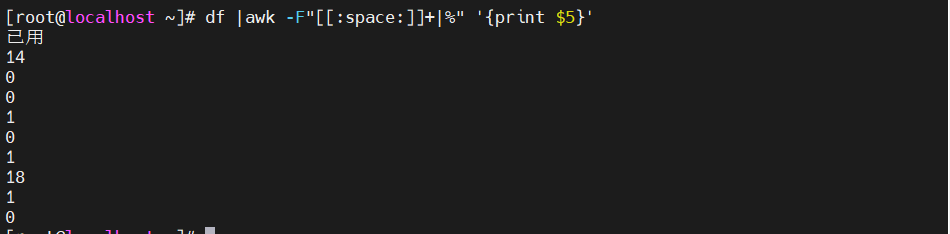
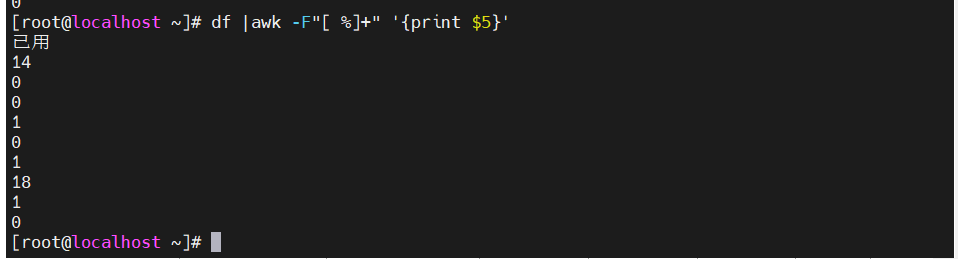
df |awk -F"[ %]+" '{print $5}'
取 ip地址
ifconfig ens33|sed -n '2p' |awk '{print $2}'
sed -n ‘2p’ 关闭自动打印, 打印出第二行
awk '{print $2}' 取第二个

hostname -I|awk {print $1}

[root@localhost ~]#wc -l /etc/passwd

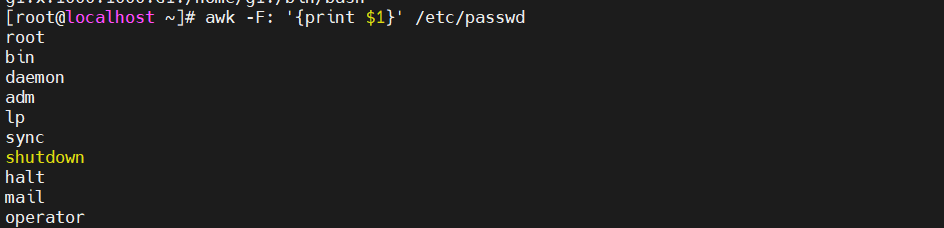
[root@localhost ~]#awk -F: '{print $0}' /etc/passwd #$0代表全部元素

[root@localhost ~]#awk -F: '{print $1}' /etc/passwd #代表第一列
[root@localhost ~]#awk -F: '{print $1,$3}' /etc/passwd #代表第一第三列

[root@localhost ~]#awk '/^root/{print}' passwd #打印出已root为开头的行

[root@localhost ~]#grep -c "/bin/bash$" passwd #统计当前已/bin/bash结尾的行 
BEGIN{}模式表示,在处理指定的文本前,需要先执行BEGIN模式中的指定动作; awk再处理指定的文本,之后再执行END模式中的指定动作,END{}语句中,一般会放入打印结果等语句。
[root@localhost ~]# awk 'BEGIN {x=0};/\/bin\/bash$/;{x++};END{print X}' /etc/passwd

先定义变量
[root@localhost ~]#awk 'BEGIN {x=0};/\/bin\/bash$/ {x++;print x,$0};END{print x}' passwd

6.2awk 常见的内置变量
-
FS :指定每行文本的字段分隔符,缺省为空格或制表符(tab)。与 “-F”作用相同 -v "FS=:"
-
OFS:输出时的分隔符
-
NF:当前处理的行的字段个数
-
NR:当前处理的行的行号(序数)
-
$0:当前处理的行的整行内容
-
$n:当前处理行的第n个字段(第n列)
-
FILENAME:被处理的文件名
-
RS:行分隔符。awk从文件上读取资料时,将根据RS的定义就把资料切割成许多条记录,而awk一次仅读入一条记录进行处理。预设值是\n
FS
[root@localhost ~]#awk -v FS=':' '{print $1FS$3}' /etc/passwd #此处FS 相当于于变量 -v 变量赋值 相当于 指定: 为分隔符

[root@localhost ky15]#awk -F: '{print $1":"$3}' /etc/passwd
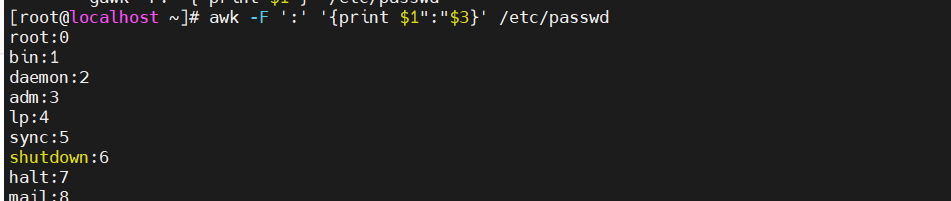
shell中的变量 [root@localhost ~]#fs=":";awk -v FS=$fs '{print $1FS$3}' /etc/passwd #定义变量传给FS

支持变量
[root@localhost ~]#fs=":";awk -v FS=$fs -v OFS="+" '{print $1,$3}' /etc/passwd #输出分隔符
-F -FS一起使用 -F 的优先级高

OFS
[root@localhost ~]#awk -v FS=':' -v OFS='==' '{print $1,$3}' /etc/passwd
RS
默认是已 \n (换行符)为一条记录的分隔符 不动他
[root@localhost ~]#echo $PATH | awk -v RS=':' '{print $0}'

NF
代表字段的个数
[root@localhost ~]# awk -F: '{print NF}' /etc/passwd

[root@localhost ~]# awk -F: '{print $NF}' /etc/passwd
$NF最后一个字段

[root@localhost ~]# df|awk '{print $(NF-1)}'
#倒数第二行
NR
行号
[root@localhost ~]# awk -F':' '{print $1,NR}' /etc/passwd

[root@localhost ~]# awk -F':' 'NR==2{print $1,NR}' /etc/passwd
只取第二行的第一个字段

[root@localhost ~]# awk -F':' 'NR==1,NR==3{print $1,NR}' /etc/passwd
#打印出1到3 行

[root@localhost ~]#awk '(NR%2)==0{print NR}' passwd #打印出函数取余数为0行 [root@localhost ~]#awk '(NR%2)==1{print NR}' passwd #打印出函数取余数为1的行 [root@localhost~]#awk 'NR>=3 && NR<=6{print NR,$0}' /etc/passwd
[root@localhost ~]#seq 10|awk 'NR>5 && NR<10' #取 行间 6 7 8 9
[root@localhost ~]#awk '$3>1000{print}' /etc/passwd #注意分隔符 #打印出普通用户 第三列 大于1000 的行
FNR
[root@localhost ~]# cat /etc/issue |wc -l 10 [root@localhost ~]# cat /etc/os-release |wc -l 16

[root@localhost ~]#awk '{print FNR}' /etc/issue /etc/os-release 
6.3自定义变量
[root@localhost ~]#awk -v test='hello' 'BEGIN{print test}' hello awk -v test1=test2="hello" 'BEGIN{test1=test2="hello";print test1,test2}'
awk -v test='hello gawk' '{print test}' /etc/fstab awk -v test='hello gawk' 'BEGIN{print test}' awk 'BEGIN{test="hello,gawk";print test}' awk -F: '{sex="male";print $1,sex,age;age=18}' /etc/passwd
6.4 模式
awk '模式{处理动作}'
不支持使用行号,但是可以使用变量NR 间接指定行号
gender ###正则表达式 /pat1/
匹配pat1 的行
/pat1/,/pat2/ #正则表达式1 到正则表达式2 之间的行 如果匹配不到2的表达式 会一直匹配到文末
pat1 正则表达式1 pat2 正则表达式2
#模糊匹配,用~表示包含,!~表示不包含
####比较操作符: ==, !=, >, >=, <, <=
#####逻辑 与:&&,并且关系 或:||,或者关系 非:!,取反
例子
[root@localhost ~]#seq 10 |awk 'NR>=3 && NR<=6'
3
4
5
6
[root@localhost ~]#awk 'NR>=3 && NR<=6{print NR,$0}' /etc/passwd
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
awk -F: '$3>=100 && $3<=1000{print $1}' /etc/passwd
取奇数偶数
[root@centos8 ~]#seq 10 | awk 'NR%2==0'
2
4
6
8
10
[root@centos8 ~]#seq 10 | awk 'NR%2==1'
1
[root@centos8 ~]#seq 10 | awk 'NR%2!=0'
1
3
5
7
9