撰写本文的目的:记录本人在不参考其他任何形式的解决方法(思路/源码)、仅靠课程提供的资源(课本/参考资料)和Discord中high level的讨论的情况下,独立完成该课程的过程。
欢迎大家和我讨论学习中所遇到的问题。
由于gradescope中对non-cmu students还未开放Project#2,本文方法仅通过了本地测试,极有可能有错误(并发访问)
Project #2: Extendible Hash Index
先记录完成的过程,然后再总结和思考
准备
Due:四个星期左右(通过本地测试-4天左右+通过线上测试-待定)
在开始完成该项目之前,首先确保两件事
- 确保Project#1的代码实现是正确的,最好多提交几次,因为测试用例可能会有不同
- 一定要先从原bustub仓库pull最新的代码,不然可能会缺少一些给定的实现
实验环境:
- MacOS
- CLion/VSCode
Task #1-Read/Write Page Guards
-
数据成员:存储指针
- 指向BPM
- 指向Page对象
-
析构函数:确保当BasicPageGuard对象离开作用域的时候:自动调用
UnpinPage -
方法成员:除此之外,需要提供方法使得能够手动unpin
-
数据成员:writer-reader latch
- 可以尝试调用Page中的相关方法
-
方法成员:能够在对象离开作用域时,自动释放latch
BasicPageGuard/ReadPageGuard/WritePageGuard
对于BasicPageGuard
-
PageGuard(PageGuard &&that): Move constructor.-
参考C++Primer
- 移动构造的时候从给定对象中窃取资源而非拷贝资源,即移动构造函数不分配任何新内存
- 需要确保移后源对象销毁是安全的
-
-
operator=(PageGuard &&that): Move assignment operator. -
需要处理移动赋值对象是自身的情况
- 直接返回*this
-
否则,需要处理原page
- 按需调用Drop
- 类似于移动构造
- 按需调用Drop
-
Drop(): Unpin- 先clear
- 再调用UnpinPage
-
~PageGuard(): Destructor.-
需要先判断是否已经手动Drop
- 若否则直接调用Drop
-
-
read-only和write dataAPIs- 分别为
As和AsMutAs以const修饰符返回Page内部的dataAsMut则不然,并且注意AsMut会将PageGuard的成员变量is_dirty置为true
- 可以在编译时期检查
data用法是否正确:- 例如,在实现Task3或Task4的
Insert时,你可能认为某个部分仅仅是查阅了HeaderPage,因此以As返回,却没想到其实有可能在HeaderPage中无相应DirectoryPage后,会修改HeaderPage。例子可能不大恰当
- 例如,在实现Task3或Task4的
- 分别为
对于ReadPageGuard
-
移动构造和移动赋值都可以使用std::move完成
- std::move()移动赋值时,会对赋值guard调用析构函数并调用Drop,因此不必担心赋值后移后源对象会对page造成影响
-
需要注意Drop中资源的释放顺序,需要在Drop BasiPage之前释放RLatch,
-
可能会因为Unpin调用了RLatch而死锁
-
更重要的原因:先UnpinPage的话,可能会被replacer evit
-
-
需要在析构函数中判断是否已经手动drop/移动赋值/移动构造过,避免重复Drop导致重复释放Latch
对于WritePageGuard:同上
Upgrade
guarantee that the protected page is not evicted from the buffer pool during the upgrade
目前这两个函数我都没有使用到,或者说是不知道该如何实现以及使用:
- 如何实现?我本以为防止evict只需要将page的pin_count_++,但是并PageGuard不是Page的friend class,无法直接访问Page的私有成员
- 如何使用?我能想到该函数存在的原因,是新建一个需要修改的DirectoryPage或者BucketPage,但是没有
NewWritePageGuard和NewReadPageGuard函数的实现,只能NewPageGuard之后立刻Upgrade。- 我认为:实际上该线程新建的
Page目前只能该线程自己访问,并不需要使用Guard来保护啊 - 因此我在
InsertToNewDirectory和InsertToNewBucket中都只是用了BasicPageGuard并且调用了AsMut,而未使用WritePageGuard。并且这是能够通过本地测试的
- 我认为:实际上该线程新建的
Wrappers
FetchPageBasic(page_id_t page_id)FetchPageRead(page_id_t page_id)FetchPageWrite(page_id_t page_id)NewPageGuarded(page_id_t *page_id)
注释中说明得足够清晰,不再赘述
Tests

Task #2-Extendible Hash Table Pages
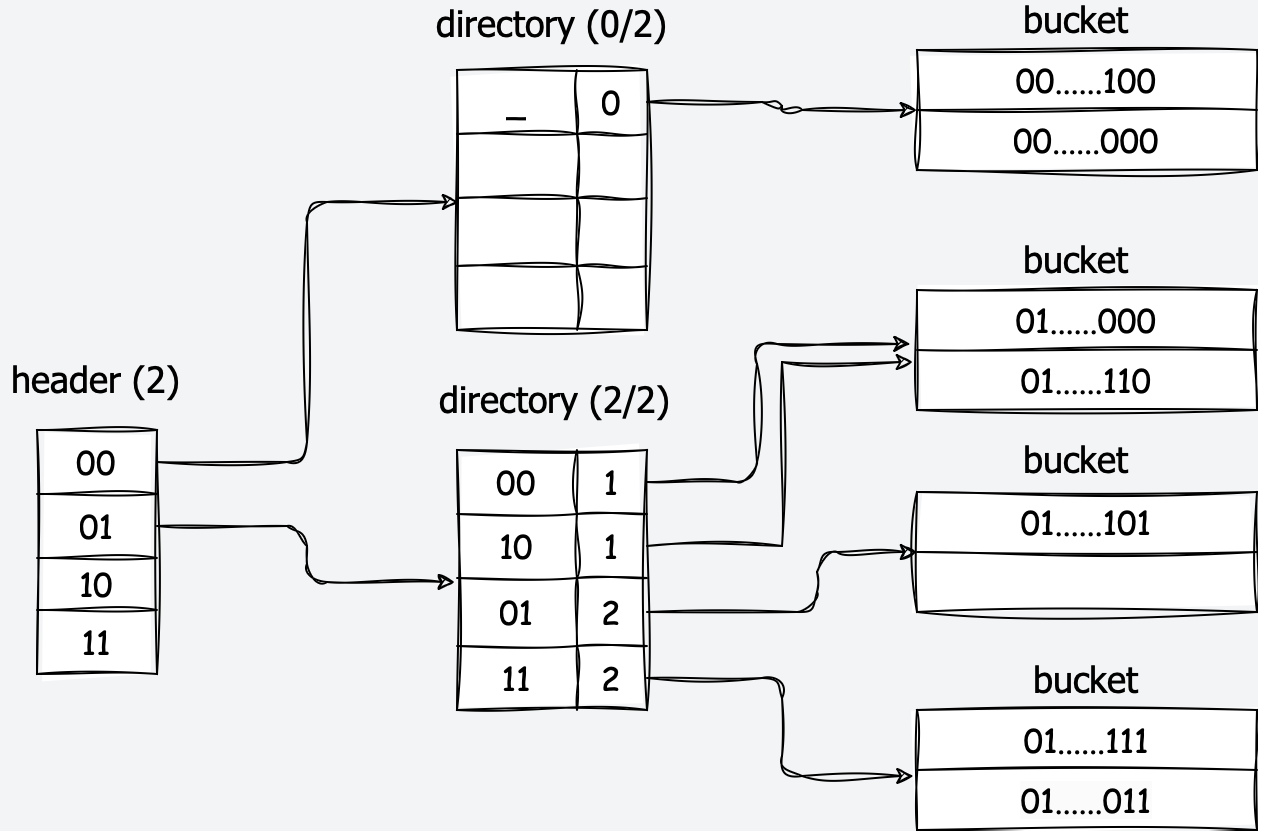
这里主要实现三层可扩展哈希表的三个部分,如上图所示:
- Header Page:
- 课本中的2-Level并没有该部分,该部分的max depth/prefix(例如上图中的2)是固定的
- 主要是用来索引能够索引到存储key的
BucketPage位置的Directory Page在Header Page中的位置(比较拗口)- 通过
HashToDirecotryIndex实现
- 通过
HeaderPage的优点(文档中提到):- More Direcotry Pages -> More Bucket Pages -> More Keys
- 并且由于
Latch Crabbing的并发策略,使得Header Page的Latch很快的被释放
- Directory Page
- 与课本中一致
- global depth = hash prefix:三个作用
- 用来限制某个时刻可以使用的Directory条目数量 $2^{global depth}$ 个
- 用来获得哈希值从LSB开始的global_depth个位,作为在dierctory中的索引,找到key所在的bucket
HashToBucketIndex实现
- 并且在某个bucket满时,通过比较
global depth和local depth来决定如何处理split
- local depth = bucket hash prefix
- 通过比较和global_depth的关系,判断指向当前bucket的指针数量,分裂时如何处理
- global depth = hash prefix:三个作用
- 与课本中一致
- Bucket Page
- 以数组的形式存储
<key, value - 注意本项目并不会处理
non-unque key,因此对于插入相同的key直接返回false(Insert函数)
- 以数组的形式存储
Task2中相关源码的注释并没有很详细,需要自己根据本地测试来判断该函数具体完成了什么工作
- 可以在实现
Header Pages和Directory Pages的时候,通过HeaderDirectoryPageSampleTest来测试或者Debug - 实现
Bucket Pages的时候,通过BucketPageSampleTest测试 - 例如:
HashToDirectoryIndex是通过hash value的max_depth个MSB求得的
Hash Table Header Pages
成员变量:
directory_page_ids:page_id(4B)的数组
-
元素个数:1<<9
- 即512个
-
占用内存:512*4 = 2048
max_depth_: 通过page_id(32位)哈希值的高max_depth_位,来判断page_id在directory_page_ids_中的位置
- 占用内存:4B
方法实现:
- [✅] HashToDirectoryIndex(uint32_t hash)
- 通过测试可以看到,实际上该函数是将hash的高max_depth_位,作为directory page id在数组directory_page_ids_的索引
- 将hash向右移动
32-max_depth_位,可以获得高max_depth_位对应的uint32_t表示 Hint: 考虑max_depth_为0的情况,实际上对于4B的整型右移32位是undefined?
- [✅] MaxSize():Get the maximum number of directory page ids the header page could handle
-
由于directory_page_ids中每个条目只能存放一个page id元素,因此directory_page_ids_最大能存入
HTABLE_HEADER_ARRAY_SIZEdirectory page id -
而
max_depth_- 对于线性探测解决冲突的哈希表:会决定
directory_page_ids的大小 - 不使用线性探测解决冲突:似乎并不会影响
directory_page_ids_的大小,
- 对于线性探测解决冲突的哈希表:会决定
-
根据题目要求,
Header Pages并没有使用线性探测,因此需要返回max_depth_能表示数的数量和HTABLE_HEADER_ARRAY_SIZE之中的较小值
Hash Table Directory Pages
成员变量:
max_depth_:
- 4B
- Header Page的directory page id数组中,所有的directory page拥有相同的max_depth值,代表一个directory能够用的掩码的最大位数
global_depth_:
-
4B
-
类似于: 课本中的bucket address table的global prefix,用来控制当前table使用条目的数量,上限是2^max_depth
-
简而言之:global_depth用来掩码hash value,以获得存储key的bucket在directory 中的索引
-
global_depth<=max_depth_
local_depth_s:数组
- 1B * (Size of array of Bucket page id )
- 类似于:课本中每个bucket持有的local prefix,用来按需生成bucket,进行local prefix后拥有相同值的entry指向同一个bucket
- 简而言之:local_depth用来掩码,使得确定其在哪个bucket page中
bucket_page_ids_
- 存储bucket page id的数组
方法实现:
- [✅] Init:
- 将global depth和local depth初始化0
- bucket page id初始化为-1或者其他特殊标记
- [✅] HashToBucketIndex:
- 类似于
Header Page中的HashToDirectoryIndex,只不过掩码长度为global_depth_,并且是将Hash值的低global_depth_位(从LSB开始)处理作为bucket在directory中的索引 - 像测试中直接
%Size()是极好的,但是我一开始脑子没转过来,- 一直想用位操作。。。?
- [✅] GetSplitImageIndex:
-
分两种情况:
- local_depth_ > global_depth_:代表后续需要double directory
- local_depth_ <= global_depth_
-
观察得到,为了获得directory扩展后当前bucket_idx分裂后映像的索引,只需要将bucket_idx的第新global_depth_位取反即可
-
两种情况可以使用同一种位运算来解决
-
只需要对原进行split的bucket_idx进行如下位运算
- 第一种情况:需要double directory
- 第global_depth_位与1异或
- 第二种情况:不需要double
- 第global_depth_-1位与1异或
- 其他位与0异或
- 第一种情况:需要double directory
-
- [✅] SetLocalDepth
-
同上,分两种情况
- 先根据local_dpth和global_depth的关系,获得split_bucket_idx
- 如何将两个bucket的local_depth同时设置为新的即可
- [✅] IncrGlobalDepth
-
需要找到当前directory可用的条目中,local_depth小于等于当前global_depth的项:
- 使得其在double后的split_entry拥有相同的bucket page id和local_depth
-
global_depth++
-
Hint: global_depth <= max_depth
- [✅] DecrGlobalDepth
- 直接将index在区间[2^{global_depth-1}, 2^{global_depth}-1]的两个数组元素初始化为
- [✅] GetGlobalDepthMask:
- 通过注释我们可以知道,
global_depth_是用于生成从哈希值的LSB开始的global_depth_mask - 而
Header Page中的max_depth_则是用于生成MSB的掩码
- [✅] GetLocalDepthMask:
- 同理
- [✅] CanShrink
-
判断是否存在local_depth与global_depth相同
-
如果没有,则说明所有<bucket_idx, split_bucket_idx>所包含的bucket page id都相同
- 因此table可以去除冗余部分,缩小一倍
-
Hash Table Bucket Page
成员变量:
size_:The number of key-value pairs the bucket is holding
max_size_:The maximum number of key-value pairs the bucket can handle
array_:An array of bucket page local depths
方法实现
Init:
-
对max_size_初始化
-
对于array_中的每一个pair<Key, Value>进行初始化
-
注意需要为Key和Value都指定一个特殊值,表示该部分为无效
-
可以直接使用构造列表,来直接构造模版类的临时对象:
- Key可以使用{-1}来与测试中的i==0区别,Value可以直接使用{}因为RID的默认构造函数会使用-1来表示无效
-
或者使用模版参数类型构造
- 同理
-
-
Lookup:
-
使用模版类对象cmp的重载函数(),来比较Key是否相同
- 返回0表示相同
注意Insert和Remove之后需要对size进行增减
Tests

Task #3-Extenable Hashing Implementation
课本中的实现步骤:Extendible Hash Table
最好也是参考着测试样例来实现
Each extendible hash table header/directory/bucket page corresponds to the content (i.e., the
data_part) of a memory page fetched by the buffer pool.Every time you read or write a page, you must first fetch the page from the buffer pool (using its unique
page_id), reinterpret cast it the corresponding type, and unpin the page after reading or writing it.We strongly encourage you to take advantage of the
PageGuardAPIs you implemented in Task #1 to achieve this.
假设:
- 只支持unique keys
注意:
-
需要使用Task2中的三种Page类和meta data(page id, global/local depth)来实现基于disk的hash table
-
不允许使用内存数据结构例如unordered_map
-
take a
Transaction*with default valuenullptr.template <typename KeyType,
typename ValueType,
typename KeyComparator> -
三种类型在Task #2的
Bucket Pages中都见过:KeyType:GenericKeyValueType:RIDKeyComparator: 比较两个Key的大小
实现bucket splitting/merging and directory growing/shrinking
- [✅] Empty Table
- 构造函数中新建一个Header Page,并Init
- 通过实现辅助函数
InsertToNewDirectory和InsertToNewBucket来实现按需生成Buckets
- [✅] Header Indexing
- Hash(key)
- 对hash value调用HashToDirectoryIndex
- [✅] Directory Indexing
- Hash(key)
- 对hash value调用HashToBucketIndex
- [✅] Bucket Splitting
-
按照课本上的步骤来实现即可
-
可以通过实现源码中给定的工具函数
UpdateDirectoryMapping来辅助实现- 可能该函数内部调用了
MigrateEntries函数,但是我并没有实现,直接在UpdateDirectoryMapping中实现了Rehash操作 - Hint:该函数如果直接在Insert中调用的话函数签名中可以自己修改并多传入两个
ExtendibleHTableBucketPageold_bucket_page:需要进行分裂,并rehash的bucketnew_bucket_page:新建的bucket- 这样可以不必重新
FetchPage
- 可能该函数内部调用了
-
- [ ] Bucket Merging
- 似乎没必要实现
- [ ] Directory Growing
- 可实现可不实现
- [ ] Directory Shrinking
- 只有当所有的local_depth_都小于global_depth时才进行
- 在
Task2中实现了相关操作
本地测试中似乎并没有测试到Bucket Merging, Directory Growing和Directory Shrinking,因此无法验证实现的正确性
Tests

Task #4-Concurrency Control
Latch Crabbing
- The thread traversing the index should acquire latches on hash table pages as necessary to ensure safe concurrent operations, and should release latches on parent pages as soon as it is possible to determine that it is safe to do so.
We recommend that you complete this task by using the
FetchPageWriteorFetchPageReadbuffer pool API
Note: You should never acquire the same read lock twice in a single thread. It might lead to deadlock.
Note: You should make careful design decisions on latching.
- Always holding a global latch the entire hash table is probably not a good idea.
PageGuard
Insert
- 的BasicPage尽量替换WritePageGuard,先不用Read;
GetValue:
- 可以全部使用ReadGuard
Remove:
- 只需要对bucket page使用write guard
需要使用Latch Crabbing策略来尽快而又安全地释放父Page的Latch
-
Crabbing:
-
先获得header page的page guard
-
然后尝试获得directory page的page guard
- 若成功获得,确保不会用到header时,再释放header page的page guard
-
尝试获得bucket page的page guard
- 若成功获得,确保不会用到directory时,释放directory page的page guard
-
ExtendibleHTableTest
先尝试通过单线程,验证实现Insert,Remove和GetValue不会使得一个线程对同一个page死锁

ExtendibleHTableConcurrentTest
InsertTest1

BUGs
-
- [✅] BUG
-
在Project #1中图方便,在NewPage直接使用了一把函数粒度的递归锁lock_guard
-
导致有一种死锁的可能:
-
线程一先调用Insert,并通过调用FetchWritePage获得了page0(即header page )的WLatch
-
线程二后调用Insert,也尝试通过调用FetchWritePage获得page0,但是进入到FetchPage后尝试获取page0的WLatch失败,只能waiting
- 注意,此时线程二拿到了BPM的递归锁lock_guard
-
线程一继续完成Insert:尝试InsertToNewDirectory时,内部也尝试调用NewWritePage获得bpm的递归锁。
-
最终导致了DeadLock
-
-
solution: 将lock_guard换为unique_mutex,并手动在获得Page的Latch之前解锁,在Unlatch之后加锁
-
- [✅] 新BUG
-
描述:使用该方法会导致BPM的并发问题,可能是unlock之后被其他线程修改了相应的部分
-
solution: 能确保BPM100分
- 不使用递归锁,不主动unlock,
- 只对NewPage, FetchPage和DeletePage加锁,
- 并且在FetchPage中处理已经在bufferpool情况的分支中不对Page加锁
-
- [✅] 新BUG
-
描述:
-
线程一:Insert->WritePageGuard.Drop->guard.Drop->Unpin(is_dirty=true)——waiting在Unpin获得BPM的latch步骤
-
线程二: Insert->FetchWritePageGuard->FetchPage——正在FetchPage中尝试读出某页的数据
- 报出异常,读出的位置为空数据
-
-
尝试LogOut:
- page id>50即超过了buffer pool的大小,某次新建page会导致evcit时,会有之前某个dirty page并没有flush回disk
- 某次NewPage时,并没有将该dirty page flush回disk,可能是UnPinPage时没有标志is_dirty_
-
可能solution:
- 不使用UpgradeWrite,该函数实现有问题,并没有在Upgrade期间对pin_count_++,导致drop中Unpin中不会将其的is_dirty写入到page的metadata中
-
-
- [✅] 新BUG
-
描述:
- 死锁
-
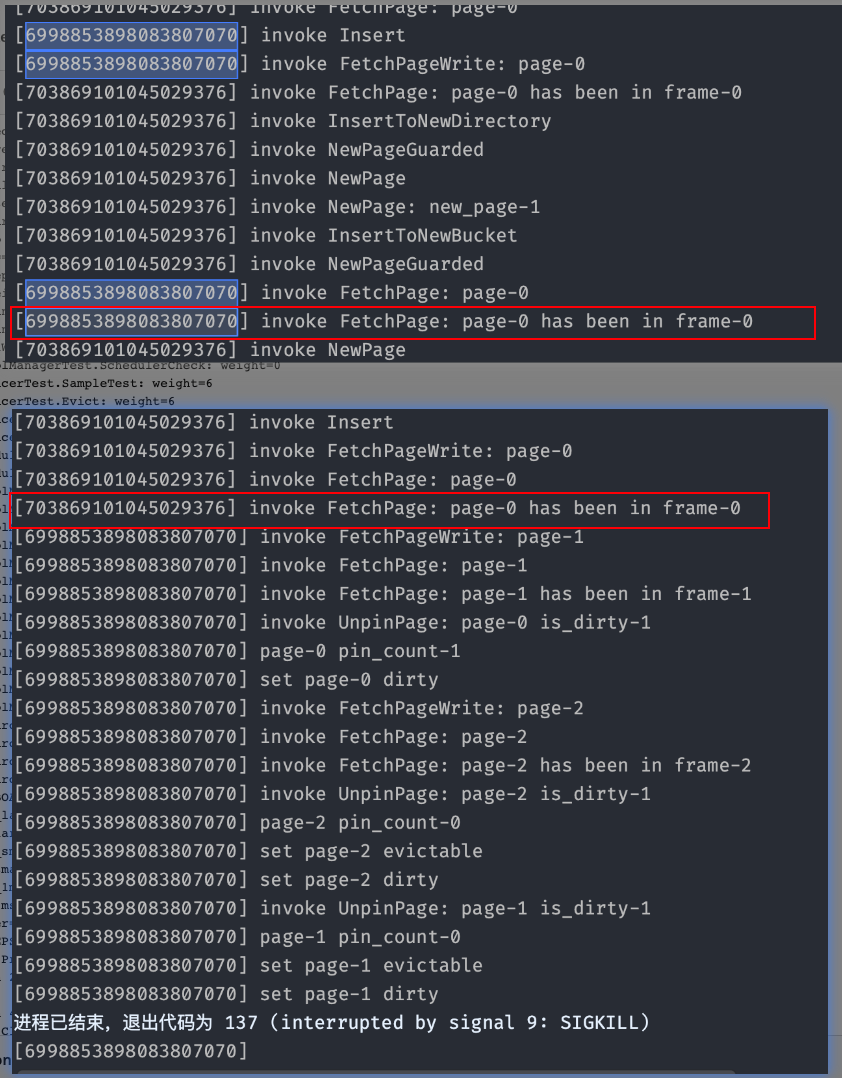
尝试Log Out线程编号:可以使用
std::hash(std::this_thread::get_id())返回当前线程的id(hash后)-
-
Debug过程中发现
UnpinPage函数在unpin page0(即header page),对其内部使用Page的读写锁是多此一举的,由于判断pin_count的目的就是判断是否有多线程正在使用该Page(读或者写)。通过BPM的线上测试也能证实这一点- 并且将Page锁去除后,该BUG消失
-
这时才想起来
header_page_guard.AsMut函数内部会访问Page的Data -
推测是两个线程在UnpinPage和AsMut中思索了???
-
-
solution:
- 去除UnpinPage内部的Page锁
-
-
-
-
-
- [✅] 误以为不会有non-unique key,原先处理由non-unique key导致的插入失败,直接throw了
-
For this semester, the hash table is intend to support only unique keys. This means that the hash table should return false if the user tries to insert duplicate keys.
-
solution: 返回false
-

InsertTest2
Pass in one go !

DeleteTest1
in one go +2 !!

DeleteTest2
in one go +3 !!!

MixTest1
in one go +4 !!!!

MixTest2
in one go +5 !!!!!

本文由mdnice多平台发布