1. sklearn数据集
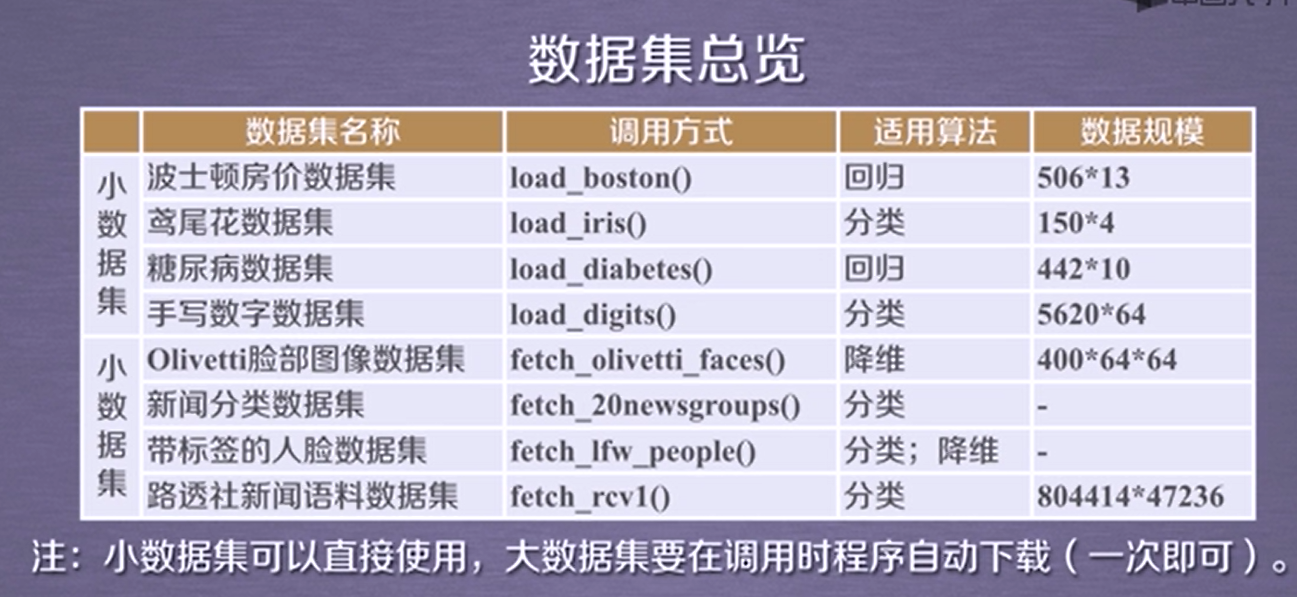
波士顿房价数据集
波士顿房价数据集包含506组数据,每条数据包含房屋以及房屋周围的详细信息。其中包括城镇犯罪率、一氧化氮浓度、住宅平均房间数、到中心区域的加权距离以及自住房平均房价等。因此,波士顿房价数据集能够应用到回归问题上。
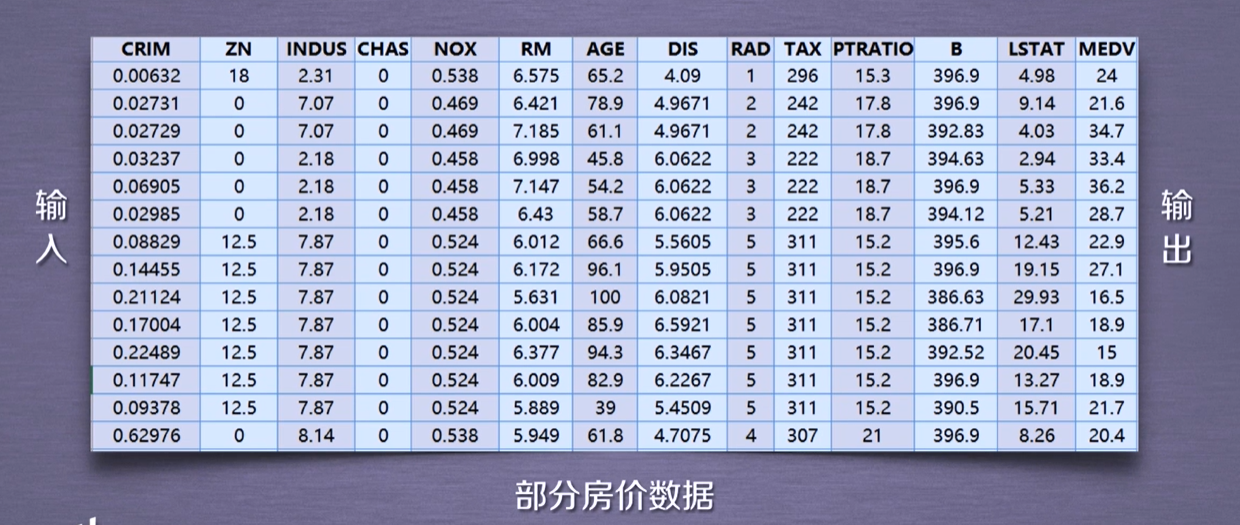
from sklearn.datasets import load_boston
boston = load_boston()
print(boston.data.shape)
#(506,13)
from sklearn.datasets import load_boston
data, target = load_boston(return_X_y=True)
print(data.shape) # (506,13)
print(target.shape) # (506)
鸢尾花数据集
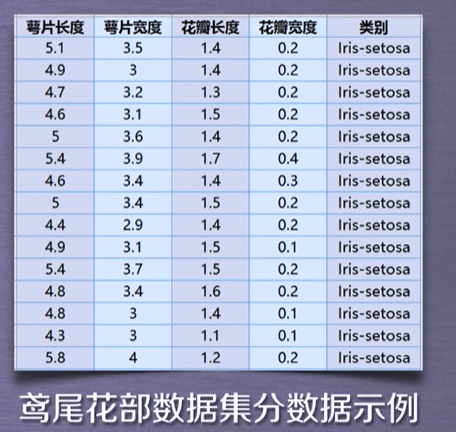
鸢尾花数据集采集的是鸢尾花的测量数据以及其所属的类别。测量数据包括: 萼片长度、萼片宽度、花瓣长度、花瓣宽度。
类别共分为三类: Iris_Setosa,Iris_Versicolour,Iris_Virginica。 z数据集可用于多分类问题。
使用sklearn.datasets.load_iris即可加载相关数据集
参数:
return_X_y: 若为True,则以( data,target )形式返回数据;默认为False,表示以字典形式返回数据全部信息(包括data和target )
from sklearn.datasets import load_iris
iris = load_iris()
print(iris.data.shape) # (150, 4)
print(iris.target.shape) # (150,)
print(list(iris.target_names)) # ['setosa', 'versicolor', 'virginica']
手写数字数据集
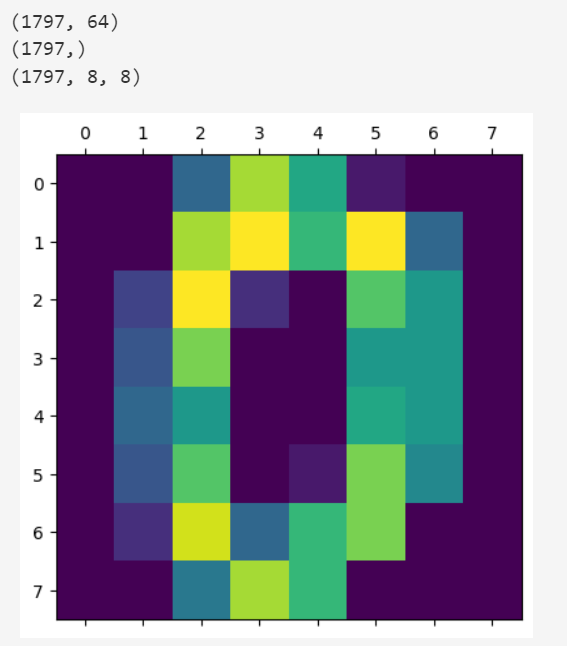
手写数字数据集包括1797个0-9的手写数字数据,每个数字由8*8大小的矩构成,矩阵中值的范围是0-16,代表颜色的深度

使用sklearn.datasets.load_digits即可加载相关数据集
参数:
return_X_y:若为True,则以( data, target ) 形式返回数据;默认为False,表示以字典形式返回数据全部信息(包括data和target )
n_class: 表示返回数据的类别数,如: n_class=5,则返
回0到4的数据样本
from sklearn.datasets import load_digits
digits = load_digits()
print(digits.data.shape)
print(digits.target.shape)
print(digits.images.shape)
import matplotlib.pyplot as plt
plt.matshow(digits.images[0])
plt.show()
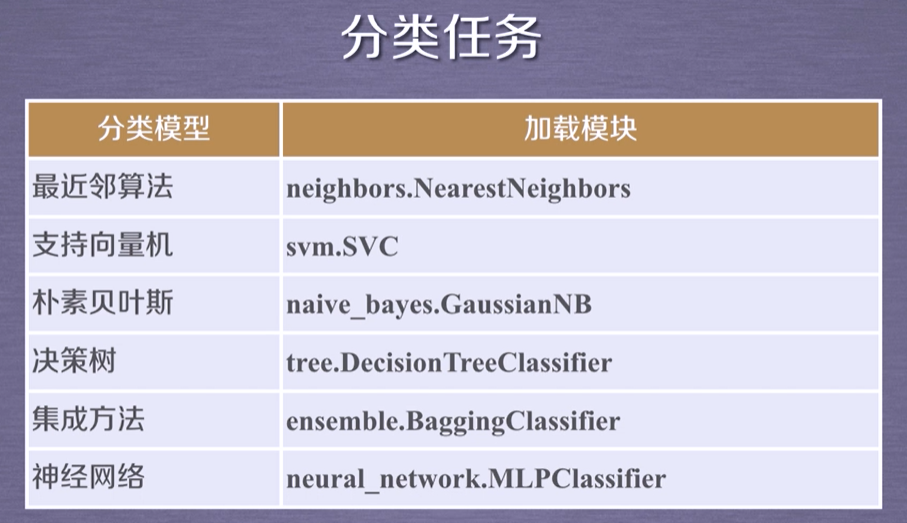
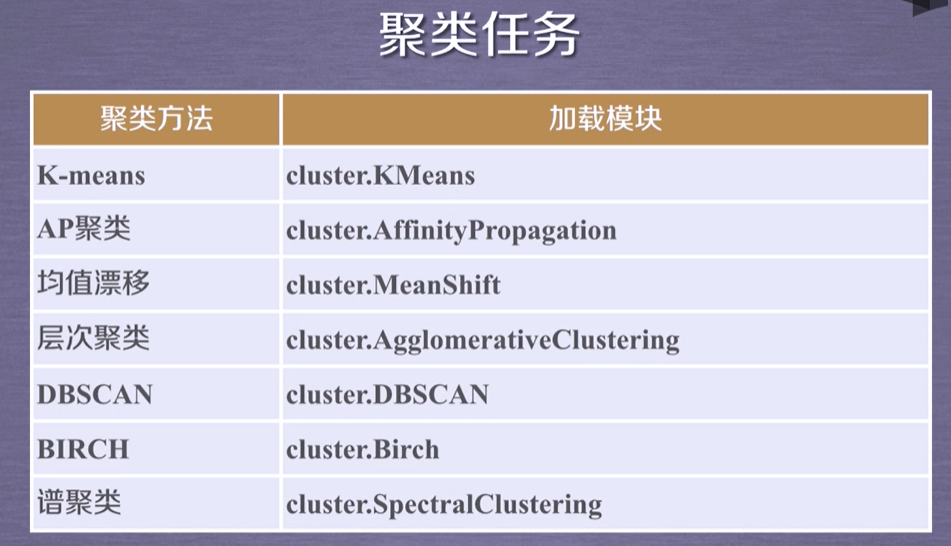
sklearn库的基本功能
sklearn库的共分为6大部分,分别用于完成分类任务、回归任务、聚类任务、降维任务、模型选择以及数据的预处理。