Numpy
简介
中文参考手册:https://www.numpy.org.cn/reference/
Numpy基于BSD开源。

Numpy(Numerical Python)是基于python进行科学计算和数学分析的重要基础库之一,大名鼎鼎。它包括:
- 一个强大的N维数组对象
- 复杂(广播)功能
- C/C++与FORTRAN代码的集成工具
- 强大的的线性代数、傅立叶变换和随机数功能
除了其明显的科学用途外,numpy还可以用作有效的通用数据多维容器。可以定义任意数据类型。这使得numpy能够无缝、快速地与各种数据库集成。Numpy本身并不提供建模函数,理解Numpy的数组以及基于数组的计算将有助于你更高效地使用基于数组的工具,比如Pandas。
Numpy在使用上的优势:
- 对大量数据的高效操作
- 内部将数据储存在连续的内存块上,这与Python内建的数据结构是不同的。Numpy的算法库是C语言编写的,在操作内存时,不需要任何类型检查或其它管理操作。Numpy数组使用的内存也小于其它Python内建序列。
- Numpy可以针对全量数组进行复杂计算而不需要编写Python循环,要快10到100倍,并且使用的内存也更少。
NumPy提供了两种基本的对象: ndarray( N-dimensional Array Object )和ufunc( UniversalFunction Object)。ndarray( 下文统一称为数组 )是存储单一数据类型的多维数组,而ufune则是能够对数组进行处理的函数。
看下面的例子:
>>> import numpy as np
>>> np.__version__
'1.16.2'
>>> my_arr = np.arange(1000000) # 以numpy的方式生成数组
>>> my_list = list(range(1000000))# 以Python列表的方式
>>> %time for _ in range(10):my_arr2 = my_arr*2 # np的操作时间
Wall time: 25.9 ms
>>> %time for _ in range(10):my_list2 = [x*2 for x in my_list] # Python列表的操作时间
Wall time: 991 ms
python中的数据结构
1、Python整型不仅仅是一个整型
标准的 Python 实现是用 C 语言编写的。这意味着每一个 Python 对象都是一个聪明的伪 C 语言结构体,该结构体不仅包含其值,还有其他信息。例如,当我们在 Python 中定义一个整型,例如 x = 10000 时,x 并不是一个“原生”整型,而是一个指针,指向一个 C 语言的复合结构体,结构体里包含了一些值。查看 Python 3.4 的源代码,可以发现整型(长整型)的定义,如下所示(C 语言的宏经过扩展之后):
struct _longobject {
long ob_refcnt;
PyTypeObject *ob_type;
size_t ob_size;
long ob_digit[1];
};
Python 3.4 中的一个整型实际上包括 4 个部分。
- ob_refcnt 是一个引用计数,它帮助 Python 默默地处理内存的分配和回收。
- ob_type 将变量的类型编码。
- ob_size 指定接下来的数据成员的大小。
- ob_digit 包含我们希望 Python 变量表示的实际整型值。
这意味着与 C 语言这样的编译语言中的整型相比,在 Python 中存储一个整型会有一些开销,正如图所示。
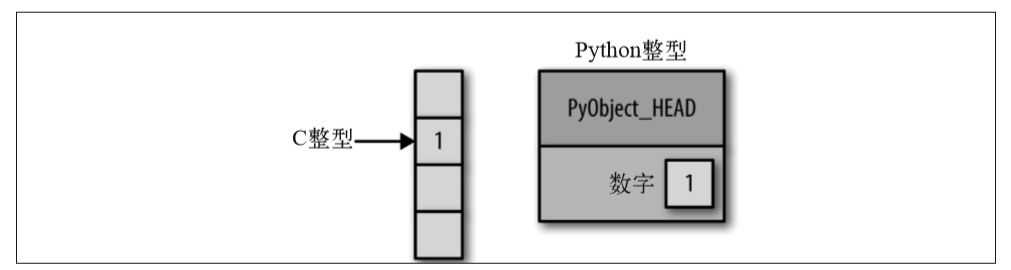
这里 PyObject_HEAD 是结构体中包含引用计数、类型编码和其他之前提到的内容的部分。两者的差异在于,C 语言整型本质上是对应某个内存位置的标签,里面存储的字节会编码成整型。而 Python 的整型其实是一个指针,指向包含这个 Python 对象所有信息的某个内存位置,其中包括可以转换成整型的字节。由于 Python 的整型结构体里面还包含了大量额外的信息,所以 Python 可以自由、动态地编码。但是,Python 类型中的这些额外信息也会成为负担,在多个对象组合的结构体中尤其明显。
2、Python列表不仅仅是一个列表
设想如果使用一个包含很多 Python 对象的 Python 数据结构,会发生什么? Python 中的标准可变多元素容器是列表。可以用如下方式创建一个整型值列表:
In [3]: L = list(range(10))
...: L
Out[3]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
In [4]: type(L[0])
Out[4]: int
或者创建一个字符串列表:
In [5]: L2 = [str(c) for c in L]
...: L2
Out[5]: ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
In [6]: type(L2[0])
Out[6]: str
因为 Python 的动态类型特性,甚至可以创建一个异构的列表:
In [7]: L3 = [True, "2", 3.0, 4]
...: [type(item) for item in L3]
Out[7]: [bool, str, float, int]
但是想拥有这种灵活性也是要付出一定代价的:为了获得这些灵活的类型,列表中的每一 项必须包含各自的类型信息、引用计数和其他信息;也就是说,每一项都是一个完整的 Python 对象。来看一个特殊的例子,如果列表中的所有变量都是同一类型的,那么很多信息都会显得多余——将数据存储在固定类型的数组中应该会更高效。动态类型的列表和固定类型的(NumPy 式)数组间的区别如图所示。
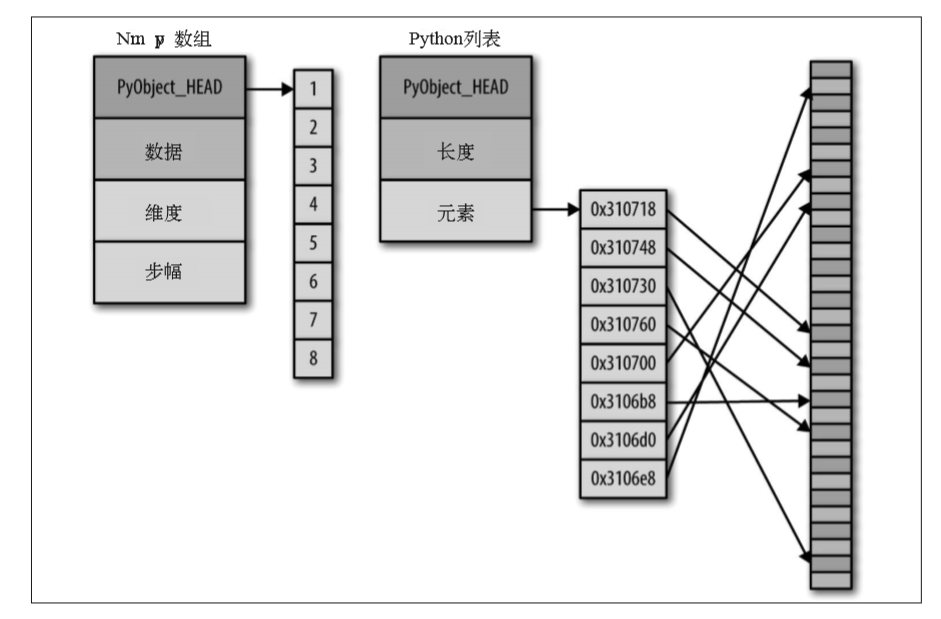
在实现层面,数组基本上包含一个指向连续数据块的指针。另一方面,Python 列表包含一 个指向指针块的指针,这其中的每一个指针对应一个完整的 Python 对象。另外,列表的优势是灵活,因为每个列表元素是一个包含数据和类型信息的完整结构体,而且列表可以用任意类型的数据填充。固定类型的 NumPy 式数组缺乏这种灵活性,但是能更有效地存储和操作数据。
3、固定类型数组 (array.array)
Python 提供了几种将数据存储在有效的、固定类型的数据缓存中的选项。内置的数组 (array)模块(在 Python 3.3 之后可用)可以用于创建统一类型的密集数组:
In[6]: import array
...: L = list(range(10))
...:A = array.array('i', L)
...:A
Out[6]: array('i', [0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
这里的 'i' 是一个数据类型码,表示数据为整型。
numpy中的ndarray对象
ndarray存储在内存中,其包含元数据和实际数据两部分。
元数据(metadata)
存储对目标数组的描述信息,如:dim、count、dimensions、dtype、data等。
实际数据
完整的数组数据
将实际数据和元数据分开存放,一方面提高了内存空间的使用效率,另一方面减少对实际数据的访问频率,提高性能。
特点
- Numpy数组是同质数组,即所有元素的数据类型必须相同
- Numpy数组的下标从0开始,最后一个元素的下标为数组长度减1
创建数组
| 函数 | 作用 |
|---|---|
| array.array() | 创建统一类型的密集数组 |
| numpy.array() | 从Python列表创建数组 |
| numpy.zeros() | 创建值都是0的数组 |
| numpy.ones() | 创建值都是1的数组 |
| numpy.empty() | 创建由n个整数型组成的未初始化的数组 |
| numpy.full() | 创建值都是指定值的数组 |
| numpy.arange() | 创建值是线性序列的数组 |
| numpy.linspance() | 创建由n个元素组成的平均分配在指定范围内的数组 |
| numpy.logspance() | 创建由n个元素组成的等比数组 |
| numpy.random.random() | 创建由(n,m)的、在0~1均匀分布的随机数组成的数组 |
| numpy.random.normal() | 创建由(n,m)的、均值为指定值,方差为指定值的正态分布的随机数数组 |
| numpy.random.randint() | 创建由(n,m)的、[a, b)区间的随机数数组 |
| numpy.eye() | 创建n*n的单位矩阵 |
| numpy.empty() | 创建一个由n个整型数组成的未初始化的数组 ,数组的值是内存空间中的任意值 |
| numpy.diag() | 创建主对角线为指定值,其他值为0的矩阵 |
Numpy的主要对象是同质的多维数组。其中的元素通常都是数字,并且是同样的类型,由一个正整数元组进行索引。每个元素在内存中占有同样大小的空间。在Numpy中,维度被称为‘轴’。
例如对于[1, 2, 1]我们说它有一个轴,并且长度为3。而[[ 1., 0., 0.], [ 0., 1., 2.]]则有两个轴,第一个轴的长度为2,第二个轴的长度为3。
创建数组的方式有很多种,比如使用array方法,并提供标准的Python列表或者元组作为参数。此时,数组的类型将根据序列中元素的类型推导出来。
1、array()
Numpy数组类的名字叫做ndarray,经常简称为array。要注意将numpy.array与标准Python库中的array.array区分开,后者只处理一维数组,并且功能简单。
np.array的代码定义如下:
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
各参数的含义:
- object:接收array。表示用于生成数组的数据对象,无默认值
- dtype:接收data-type。表示数值所需的数据类型,可选。如果未指定,则选择保存对象所需的最小内容。默认为None
- copy:可选,默认为True,对象被复制。
- order:C语言风格(按行)、FORTRAN风格(按列)或A(任意,默认)。
- subok:默认情况下,返回的数组被强制为基类数组。 如果为True,则返回子类。
- ndmin:接收int。指定返回数组的最小维数,默认为None。
>>> import numpy as np
>>> a = np.array([2,3,4])
>>> a
array([2, 3, 4])
>>> a.dtype
dtype('int32')
>>> b = np.array([1.2, 3.5, 5.1])
>>> b.dtype
dtype('float64')
常见的错误是直接将多个数值作为参数传递,正确的做法是将他们以列表或元组的方式传递,如下:
>>> a = np.array(1,2,3,4) # 错误
>>> a = np.array([1,2,3,4]) # 正确
array函数会自动将二维或三维序列转换为对应的二维或三维数组。
>>> b = np.array([(1.5,2,3), (4,5,6)])
>>> b
array([[ 1.5, 2. , 3. ],
[ 4. , 5. , 6. ]])
在创建的时候,可以显式地指定数据的类型:
>>> c = np.array( [ [1,2], [3,4] ], dtype=complex )
>>> c
array([[ 1.+0.j, 2.+0.j],
[ 3.+0.j, 4.+0.j]])
那么我们只能玩数字么?不是的,字符串也可以,只是我们不常用而已:
>>> s = 'hellow world'
>>> np.array(s)
array('hellow world', dtype='<U12')
很多时候,数组的元素最初都是未知的,但其大小形状是已知的。因此,numpy提供了几个函数来创建带有初始占位符内容的数组。
2、zeros()、ones()、empty()、full()
函数zeros创建一个都是0的数组,函数ones创建一个都是1的数组,函数empty创建一个初始内容是0或者垃圾值的数组,这取决于内存当时的状态。默认情况下,创建的数组的数据类型为float64。
>>> np.zeros((5,), dtype = np.float)
array([0., 0., 0., 0., 0.])
>>> np.zeros( (3,4) )
array([[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.]])
>>> np.ones( (2,3,4), dtype=np.int16 ) # 同样可以指定类型
array([[[ 1, 1, 1, 1],
[ 1, 1, 1, 1],
[ 1, 1, 1, 1]],
[[ 1, 1, 1, 1],
[ 1, 1, 1, 1],
[ 1, 1, 1, 1]]], dtype=int16)
>>> np.empty( (2,3) ) # 根据当前内存状态的不同,可能会返回未初始化的垃圾数值,不安全。
array([[0., 0., 0.],
[0., 0., 0.]])
>>> np.full((3,4), 2.22) # 创建一个全部由2.22组成的数组
array([[2.22, 2.22, 2.22, 2.22],
[2.22, 2.22, 2.22, 2.22],
[2.22, 2.22, 2.22, 2.22]])
3、arrange()
Numpy还提供了一个返回array序列的函数,而不是返回一个Python的列表,这就是常用的arange函数:
>>> np.arange( 10, 30, 5 )
array([10, 15, 20, 25])
>>> np.arange( 0, 2, 0.3 ) # 可以接受浮点类型的参数,比如这里的步长
array([ 0. , 0.3, 0.6, 0.9, 1.2, 1.5, 1.8])
其原型为:
numpy.arange(start, stop, step, dtype)
- start:范围的起始值,默认为0
- stop: 范围的终止值(不包含)
- step: 两个值的间隔,默认为1
- dtype: 返回ndarray的数据类型,如果没有提供,则会使用输入数据的类型。
4、linspance()
当arange函数使用浮点步长的时候,可能出现精度的问题。这种情况下,我们一般使用linspace函数,它的第三个参数指定在区间内均匀生成几个数,至于步长,系统会自动计算。
>>> from numpy import pi # 导入圆周率
>>> np.linspace( 0, 2, 9 ) # 从0到2之间的9个数
array([ 0. , 0.25, 0.5 , 0.75, 1. , 1.25, 1.5 , 1.75, 2. ])
>>> x = np.linspace( 0, 2*pi, 100 ) # 从0到2Π之间,生成100个数
>>> f = np.sin(x)
其原型为:
numpy.linspace(start, stop, num, endpoint, retstep, dtype)
- start: 序列的起始值
- stop: 序列的终止值,如果endpoint为True,则终止值包含于序列中
- num: 要生成的等间隔样例数量,默认为50
- endpoint: 序列中是否包含stop值,默认为Ture
- retstep: 如果为True,返回样例以及连续数字之间的步长
- dtype: 输出ndarray的数据类型
更多类似的函数有:array, zeros, zeros_like, ones, ones_like, empty, empty_like, arange, linspace, numpy.random.rand, numpy.random.randn, fromfunction, fromfile
数组属性
ndarray具有以下重要属性:
| 属性 | 描述 |
|---|---|
| ndarray.ndim | 数组的轴数量 |
| ndarray.shape | 数组的形状。这是一个整数元组。比如对于n行m列的矩阵,其shape形状就是(n,m)。而shape元组的长度则恰恰是上面的ndim值,也就是轴数。 |
| ndarray.size | 数组中所有元素的个数。这恰好等于shape中元素的乘积。 |
| ndarray.dtype | 数组中元素的数据类型。除了标准的Python类型,Numpy还提供一些自有的类型。 |
| ndarray.itemsize | 元素的字节大小。比如float64类型的itemsize为8(=64/8),而complex32的itemsize为4(=32/8)。 |
| ndarray.nbytes | 总字节数 = size x itemsize |
| ndarray.real | 复数数组的实部数组 |
| ndarray.imag | 复数数组的虚部数组 |
| ndarray.T | 数组对象的转置视图 |
| ndarray.flat | 扁平迭代器 |
| ndarray.data | 包含数组实际元素的缓冲区。通常我们不需要使用这个属性,因为我们将使用索引工具访问数组中的元素。 |
| ndarray.flags | 数组对象的一些状态指示或标签 |
ndarray.flags: 数组对象的一些状态指示或标签
- C_CONTIGUOUS (C):数组位于单一的、C语言风格的连续区段内
- F_CONTIGUOUS (F): 数组位于单一的、Fortran语言风格的连续区段内
- OWNDATA (O) :数组的数据是否从其它对象处借用
- WRITEABLE (W) :数据区域是否可写入。 将它设置为Flase会锁定数组,使其只读。
- ALIGNED (A) :数据元素会适当对齐
- UPDATEIFCOPY (U) :如果数组是另一数组的副本。当这个数组释放时,源数组会由这个数组中的元素更新
在实际使用中,我们通常使用import numpy as np来导入numpy并简写为np,这是国际惯例,请保持阵型。
>>> import numpy as np #导入numpy
>>> a = np.arange(15).reshape(3, 5) #创建一个数组并调整为3行5列
>>> a
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
>>> a.shape
(3, 5)
>>> a.ndim
2
>>> a.dtype.name # 根据版本和环境不同,可能不同,比如int64
'int32'
>>> a.itemsize
4
>>> a.size
15
>>> type(a)
<type 'numpy.ndarray'>
>>> b = np.array([6, 7, 8]) # 又一种生成数组的方法
>>> b
array([6, 7, 8])
>>> type(b)
<type 'numpy.ndarray'>
>>>print([elem for elem in a.flat])
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
数据类型
NumPy支持比Python更多种类的数值类型。下表列出了NumPy中定义的不同数据类型。
| 数据类型 | 描述 |
|---|---|
| bool_ | 存储为一个字节的布尔值(真或假) |
| int_ | 默认整数,相当于 C 的long,通常为int32或int64 |
| intc | 相当于 C 的int,通常为int32或int64 |
| intp | 用于索引的整数,相当于 C 的size_t,通常为int32或int64 |
| int8 | 1个字节(-128 ~ 127) |
| int16 | 16 位整数(-32768 ~ 32767) |
| int32 | 32 位整数(-2147483648 ~ 2147483647) |
| int64 | 64 位整数(-9223372036854775808 ~ 9223372036854775807) |
| uint8 | 8 位无符号整数(0 ~ 255) |
| uint16 | 16 位无符号整数(0 ~ 65535) |
| uint32 | 32 位无符号整数(0 ~ 4294967295) |
| uint64 | 64 位无符号整数(0 ~ 18446744073709551615) |
| float_ | float64的简写 |
| float16 | 半精度浮点:符号位,5 位指数,10 位尾数 |
| float32 | 单精度浮点:符号位,8 位指数,23 位尾数 |
| float64 | 双精度浮点:符号位,11 位指数,52 位尾数 |
| complex_ | complex128的简写 |
| complex64 | 复数,由两个 32 位浮点表示(实部和虚部) |
| complex128 | 复数,由两个 64 位浮点表示(实部和虚部) |
| complex256 | 复数,128位 |
| object | Python对象类型 |
| string_ | 修正的ASCII字符串类型 |
| unicode_ | 修正的Unicode类型 |
自定义复合类型
# 自定义复合类型
import numpy as np
data=[
('zs', [90, 80, 85], 15),
('ls', [92, 81, 83], 16),
('ww', [95, 85, 95], 15)
]
#第一种设置dtype的方式
a = np.array(data, dtype='U3, 3int32, int32')
print(a)
print(a[0]['f0'], ":", a[1]['f1'])
print("=====================================")
#第二种设置dtype的方式
b = np.array(data, dtype=[('name', 'str_', 2),
('scores', 'int32', 3),
('ages', 'int32', 1)])
print(b[0]['name'], ":", b[0]['scores'])
print("=====================================")
#第三种设置dtype的方式
c = np.array(data, dtype={'names': ['name', 'scores', 'ages'],
'formats': ['U3', '3int32', 'int32']})
print(c[0]['name'], ":", c[0]['scores'], ":", c.itemsize)
print("=====================================")
#第四种设置dtype的方式
d = np.array(data, dtype={'name': ('U3', 0),
'scores': ('3i4', 16),
'age': ('i4', 28)})
print(d[0]['names'], d[0]['scores'], d.itemsize)
print("=====================================")
#第五种设置dtype的方式
e = np.array([0x1234, 0x5667],
dtype=('u2', {'lowc': ('u1', 0),
'hignc': ('u1', 1)}))
print('%x' % e[0])
print('%x %x' % (e['lowc'][0], e['hignc'][0]))
print("=====================================")
#测试日期类型数组
f = np.array(['2011', '2012-01-01', '2013-01-01 01:01:01','2011-02-01'])
f = f.astype('M8[D]')
f = f.astype('int32')
print(f[3]-f[0])
print("=====================================")
a = np.array([[1 + 1j, 2 + 4j, 3 + 7j],
[4 + 2j, 5 + 5j, 6 + 8j],
[7 + 3j, 8 + 6j, 9 + 9j]])
print(a.T)
for x in a.flat:
print(x.imag)
类型字符码
| 类型 | 字符码 |
|---|---|
| np.bool_ | ? |
| np.int8/16/32/64 | i1/i2/i4/i8 |
| np.uint8/16/32/64 | u1/u2/u4/u8 |
| np.float/16/32/64 | f2/f4/f8 |
| np.complex64/128 | c8/c16 |
| np.str_ | U<字符数> |
| np.datetime64 | M8[Y] M8[M] M8[D] M8[h] M8[m] M8[s] |
字节序前缀,用于多字节整数和字符串:
</>/[=]分别表示小端/大端/硬件字节序。
类型字符码格式
<字节序前缀><维度><类型><字节数或字符数>
| 3i4 | 释义 |
|---|---|
| 3i4 | 大端字节序,3个元素的一维数组,每个元素都是整型,每个整型元素占4个字节。 |
| <(2,3)u8 | 小端字节序,6个元素2行3列的二维数组,每个元素都是无符号整型,每个无符号整型元素占8个字节。 |
| U7 | 包含7个字符的Unicode字符串,每个字符占4个字节,采用默认字节序。 |
每个内建类型都有一个唯一的字符代码:
- 'b':布尔值
- 'i':符号整数
- 'u':无符号整数
- 'f':浮点
- 'c':复数浮点
- 'm':时间间隔
- 'M':日期时间
- 'O':Python 对象
- 'S', 'a':字符串
- 'U':Unicode
- 'V':原始数据(void)
np.astype:显式地转换数据类型
使用astype时总是生成一个新的数组,即使你传入的dtype与原来的一样。
>>> a = np.arange(1, 6)
>>> a
array([1, 2, 3, 4, 5])
>>> a.dtype
dtype('int32')
>>> float_a = a.astype(np.float64)
>>> float_a.dtype
dtype('float64')
# 字符串转浮点
>>> numeric_string = np.array(['1.23', '-1.20', '33'], dtype=np.string_)
>>> numeric_string
array([b'1.23', b'-1.20', b'33'], dtype='|S5')
>>> numeric_string.astype(float)
array([ 1.23, -1.2 , 33. ])
# 使用其它数组的dtype
>>> int_array = np.arange(4)
>>> old = np.array([3.4,2.4,11.3])
>>> new = old.astype(int_array.dtype)
>>> old
array([ 3.4, 2.4, 11.3])
>>> new
array([ 3, 2, 11])
Numpy还有一些预先定义的特殊值:
比如:np.nan、np.pi、np.e
np.nan: 缺失值,或者理解为'不是一个数'
import numpy as np
a = np.array([np.nan, 1,2,np.nan,3,4,5])
a[~np.isnan(a)]
b = np.array([1, 2+6j, 5, 3.5+5j])
b[np.iscomplex(b)]
np.pi:圆周率 3.1415926...
np.e:自然数e 2.718281828459045...
通用函数
Numpy为我们提供了一些列常用的数学函数,比如sin、cos、exp等等,这些被称作‘通用函数’(ufunc)。在Numpy中,这些函数都是对数组的每个元素进行计算,并将结果保存在一个新数组中。
通用函数有两种存在形式:一元通用函数(unary ufunc)对单个输入操作,二元通用函数 (binary ufunc)对两个输入操作。
1、数组运算
| 运算符 | 对应通用函数 | 作用 |
|---|---|---|
| + | numpy.add() | 加 |
| - | numpy.subtract() | 减 |
| * | numpy.multiply() | 乘 |
| / | numpy.divide() | 除 |
| // | numpy.floor_divide() | 地板除 |
| ** | numpy.power() | 指数运算 |
| % | numpy.mod() | 求余 |
| @ | numpy.dot() | 矩阵乘法 |
对数组做基本的算术运算,将会对整个数组的所有元组进行逐一运算,并将运算结果保存在一个新的数组内,而不会破坏原始的数组。
>>> a = np.array( [20,30,40,50] )
>>> b = np.arange( 4 )
>>> b
array([0, 1, 2, 3])
>>> c = a-b
>>> c
array([20, 29, 38, 47])
>>> b**2
array([0, 1, 4, 9])
>>> 10*np.sin(a)
array([ 9.12945251, -9.88031624, 7.4511316 , -2.62374854])
>>> a<35
array([ True, True, False, False])
考虑一个问题,计算b的平方很好理解,各个元素自己算平方就好了。那么对于a-b这种,如果a和b的形状不一样呢?比如a长度为5,b长度为6:
>>> a = np.arange(5)
>>> b = np.arange(6)
>>> a,b
(array([0, 1, 2, 3, 4]), array([0, 1, 2, 3, 4, 5]))
>>> c=a-b
ValueError Traceback (most recent call last)
<ipython-input-27-508c408ffd98> in <module>()
----> 1 c=a-b
ValueError: operands could not be broadcast together with shapes (5,) (6,)
结果是弹出异常!不能这么操作!
另外,不同于数学中的矩阵乘法,使用星号做乘号时,numpy对数组的每个元素,一一对应的做乘法。如果要进行矩阵的乘法怎么办?使用@或者dot函数!
>>> A = np.array( [[1,1],
... [0,1]] )
>>> B = np.array( [[2,0],
... [3,4]] )
>>> A * B # 元素间相乘
array([[2, 0],
[0, 4]])
>>> A @ B #矩阵乘法
array([[5, 4],
[3, 4]])
>>> A.dot(B) # 矩阵乘法
array([[5, 4],
[3, 4]])
对于+=和 *= 这一类操作符,会修改原始的数组,而不是新建一个:
>>> a = np.ones((2,3), dtype=int)
>>> b = np.random.random((2,3))
>>> a *= 3
>>> a
array([[3, 3, 3],
[3, 3, 3]])
>>> b += a
>>> b
array([[ 3.417022 , 3.72032449, 3.00011437],
[ 3.30233257, 3.14675589, 3.09233859]])
>>> a += b # b不会自动地转换为整数类型,所以弹出异常
Traceback (most recent call last):
...
TypeError: Cannot cast ufunc add output from dtype('float64') to dtype('int64') with casting rule 'same_kind'
当对两个不同类型的数组进行运算操作时,将根据精度,选择最复杂的作为结果的类型:
>>> a = np.ones(3, dtype=np.int32)
>>> b = np.linspace(0,pi,3)
>>> b.dtype.name
'float64'
>>> c = a+b
>>> c
array([ 1. , 2.57079633, 4.14159265])
>>> c.dtype.name
'float64'
>>> d = np.exp(c*1j)
>>> d
array([ 0.54030231+0.84147098j, -0.84147098+0.54030231j,
-0.54030231-0.84147098j])
>>> d.dtype.name
'complex128'
2、绝对值
| 方法 | 作用 |
|---|---|
| abs() | 内置绝对值函数 |
| numpy.absolute() | 求绝对值;当处理复数时,返回该复数的幅度 |
| numpy.abs() | numpy.absolute()的别名 |
正如 NumPy 能理解 Python 内置的运算操作,NumPy 也可以理解 Python 内置的绝对值函数:
In[11]: x = np.array([-2, -1, 0, 1, 2])
abs(x)
Out[11]: array([2, 1, 0, 1, 2])
对应的 NumPy 通用函数是 np.absolute,该函数也可以用别名 np.abs 来访问:
In[12]: np.absolute(x)
Out[12]: array([2, 1, 0, 1, 2])
In[13]: np.abs(x)
Out[13]: array([2, 1, 0, 1, 2])
这个通用函数也可以处理复数。当处理复数时,绝对值返回的是该复数的幅度:
In[14]: x = np.array([3 - 4j, 4 - 3j, 2 + 0j, 0 + 1j])
np.abs(x)
Out[14]: array([ 5., 5., 2., 1.])
3、三角函数
| 方法 | 作用 |
|---|---|
| numpy.cos() | 余弦 |
| numpy.sin() | 正弦 |
| numpy.tan() | 余切 |
| numpy.arccos() | 反余弦 |
| numpy.arcsin() | 反正弦 |
| numpy.arctan() | 反余切 |
NumPy 提供了大量好用的通用函数,其中对于数据科学家最有用的就是三角函数。
In[15]: theta = np.linspace(0, np.pi, 3)
In[16]: print("theta = ", theta)
print("sin(theta) = ", np.sin(theta))
print("cos(theta) = ", np.cos(theta))
print("tan(theta) = ", np.tan(theta))
theta = [ 0. 1.57079633 3.14159265]
sin(theta) = [ 0.00000000e+00 1.00000000e+00 1.22464680e-16]
cos(theta) = [ 1.00000000e+00 6.12323400e-17 -1.00000000e+00]
tan(theta) = [ 0.00000000e+00 1.63312394e+16 -1.22464680e-16]
In[17]: x = [-1, 0, 1]
print("x = ", x)
print("arcsin(x) = ", np.arcsin(x))
print("arccos(x) = ", np.arccos(x))
print("arctan(x) = ", np.arctan(x))
x = [-1, 0, 1]
arcsin(x) = [-1.57079633 0. 1.57079633]
arccos(x) = [ 3.14159265 1.57079633 0. ]
arctan(x) = [-0.78539816 0. 0.78539816]
4、指数和对数
| 方法 | 作用 |
|---|---|
| numpy.exp() | 以e为底的指数运算 |
| numpy.exp2() | 以2为底的指数运算 |
| numpy.power() | 以n为底的指数运算 |
| numpy.ln() | 以e为底的对数运算 |
| numpy.log2() | 以2为底的对数运算 |
| numpy.log10() | 以10为底的对数运算 |
NumPy 中另一个常用的运算通用函数是指数运算:
In[18]: x = [1, 2, 3]
print("x =", x)
print("e^x =", np.exp(x))
print("2^x =", np.exp2(x))
print("3^x =", np.power(3, x))
x = [1, 2, 3]
e^x = [ 2.71828183 7.3890561 20.08553692]
2^x = [ 2. 4. 8.]
3^x = [ 3 9 27]
In[19]: x = [1, 2, 4, 10]
print("x =", x)
print("ln(x) =", np.log(x))
print("log2(x) =", np.log2(x))
print("log10(x) =", np.log10(x))
x = [1, 2, 4, 10]
ln(x) = [ 0. 0.69314718 1.38629436 2.30258509]
log2(x) = [ 0. 1. 2. 3.32192809]
log10(x) = [ 0. 0.30103 0.60205999 1. ]
5、聚合
当你面对大量的数据时,第一个步骤通常都是计算相关数据的概括统计值。最常用的概括统 计值可能是均值和标准差,这两个值能让你分别概括出数据集中的“经典”值,但是其他一 些形式的聚合也是非常有用的(如求和、乘积、中位数、最小值和最大值、分位数,等等)。
| 函数名称 | NaN安全版本 | 描述 |
|---|---|---|
| numpy.sum() | numpy.nansum | 计算元素的和 |
| numpy.cumsum() | 对行/列进行循环累加 | |
| numpy.prod() | numpy.nanumpyrod | 计算元素的积 |
| numpy.mean() | numpy.nanmean | 计算元素的平均值 |
| numpy.std() | numpy.nanstd | 计算元素的标准差 |
| numpy.var() | numpy.nanvar | 计算元素的方差 |
| numpy.min() | numpy.nanmin | 找出最小值 |
| numpy.max() | numpy.nanmax | 找出最大值 |
| numpy.argmin() | numpy.nanargmin | 找出最小值的索引 |
| numpy.argmax() | numpy.nanargmax | 找出最大值的索引 |
| numpy.median() | numpy.nanmedian | 计算元素的中位数 |
| numpy.percentile() | numpy.nanumpyercentile | 计算基于元素排序的统计值 |
| numpy.any() | N/A | 验证任何一个元素是否为真 |
| numpy.all() | N/A | 验证所有元素是否为真 |
许多一元操作(例如计算数组中所有元素的总和)都作为ndarray类的方法实现:
>>> a = np.random.random((2,3))
>>> a
array([[ 0.18626021, 0.34556073, 0.39676747],
[ 0.53881673, 0.41919451, 0.6852195 ]])
>>> a.sum() # 计算所有元素的总和
2.5718191614547998
>>> a.min() #找出最小值
0.1862602113776709
>>> a.max() #找出最大值
0.6852195003967595v
默认情况下,这些操作都会应用于整个数组,就好像它是一个数字列表,而不管其形状如何。但是,通过指定轴参数,可以沿数组的指定轴应用操作:
>>> b = np.arange(12).reshape(3,4)
>>> b
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>>
>>> b.sum(axis=0) # 对每一列进行求和
array([12, 15, 18, 21])
>>>
>>> b.min(axis=1) # 找出每一行的最小值
array([0, 4, 8])
>>>
>>> b.cumsum(axis=1) # 对每行进行循环累加
array([[ 0, 1, 3, 6],
[ 4, 9, 15, 22],
[ 8, 17, 27, 38]])
6、其他通用函数
>>> B = np.arange(3)
>>> B
array([0, 1, 2])
>>> np.exp(B)
array([ 1. , 2.71828183, 7.3890561 ])
>>> np.sqrt(B)
array([ 0. , 1. , 1.41421356])
>>> C = np.array([2., -1., 4.])
>>> np.add(B, C)
array([ 2., 0., 6.])
>>> x = np.array([1.5,1.6,1.7,1.8])
>>> i,j = np.modf(x)
>>> i,j
(array([0.5, 0.6, 0.7, 0.8]), array([1., 1., 1., 1.]))
>>> x = np.array([[1,4],[6,7]])
>>> y = np.array([[2,3],[5,8]])
>>> np.maximum(x,y) # 二元通用函数
array([[2, 4],
[6, 8]])
>>> np.minimum(x,y)
array([[1, 3],
[5, 7]])
下面是部分一元通用函数:
| 函数名 | 描述 |
|---|---|
| abs | 逐个元素进行绝对值计算 |
| fabs | 复数的绝对值计算 |
| sqrt | 平方根 |
| square | 平方 |
| exp | 自然指数函数 |
| log | e为底的对数 |
| log10 | 10为底的对数 |
| log2 | 2为底的对数 |
| sign | 计算每个元素的符号值 |
| ceil | 计算每个元素的最高整数值 |
| floor | 计算每个元素的最小整数值 |
| rint | 保留到整数位 |
| modf | 分别将元素的小数部分和整数部分按数组形式返回 |
| isnan | 判断每个元素是否为NaN,返回布尔值 |
| isfinite | 返回数组中的元素是否有限 |
| isinf | 返回数组中的元素是否无限 |
| cos | 余弦 |
| sin | 正弦 |
| tan | 余切 |
| arccos | 反余弦 |
| arcsin | 反正弦 |
| arctan | 反余切 |
下面是部分二元通用函数:
| 函数名 | 描述 |
|---|---|
| add | 将数组的对应元素相加 |
| subtract | 在第二个数组中,将第一个数组中包含的元素去除 |
| multiply | 将数组的对应元素相乘 |
| divide | 相除 |
| floor_divide | 整除,放弃余数 |
| power | 幂函数 |
| maxium | 逐个元素计算最大值 |
| minimum | 逐个元素计算最小值 |
| mod | 按元素进行求模运算 |
7、通用函数特性
7.1、指定输出
在进行大量运算时,有时候指定一个用于存放运算结果的数组是非常有用的。不同于创建临时数组,你可以用这个特性将计算结果直接写入到你期望的存储位置。所有的通用函数都可以通过 out 参数来指定计算结果的存放位置:
In[24]: x = np.arange(5)
y = np.empty(5)
np.multiply(x, 10, out=y)
print(y)
[ 0. 10. 20. 30. 40.]
这个特性也可以被用作数组视图,例如可以将计算结果写入指定数组的每隔一个元素的位置:
In[25]: y = np.zeros(10)
np.power(2, x, out=y[::2])
print(y)
[ 1. 0. 2. 0. 4. 0. 8. 0. 16. 0.]
如果这里写的是 y[::2] = 2 ** x,那么结果将是创建一个临时数组,该数组存放的是 2 ** x 的结果,并且接下来会将这些值复制到 y 数组中。对于上述例子中比较小的计 算量来说,这两种方式的差别并不大。但是对于较大的数组,通过慎重使用 out 参数 将能够有效节约内存。
7.2、聚合
二元通用函数有些非常有趣的聚合功能,这些聚合可以直接在对象上计算。例如,如果我们希望用一个特定的运算 reduce 一个数组,那么可以用任何通用函数的 reduce 方法。一个reduce 方法会对给定的元素和操作重复执行,直至得到单个的结果。
例如,对 add 通用函数调用 reduce 方法会返回数组中所有元素的和:
In[26]: x = np.arange(1, 6)
np.add.reduce(x)
Out[26]: 15
同样,对 multiply 通用函数调用 reduce 方法会返回数组中所有元素的乘积:
In[27]: np.multiply.reduce(x)
Out[27]: 120
如果需要存储每次计算的中间结果,可以使用 accumulate:
In[28]: np.add.accumulate(x)
Out[28]: array([ 1, 3, 6, 10, 15])
In[29]: np.multiply.accumulate(x)
Out[29]: array([ 1, 2, 6, 24, 120])
请注意,在一些特殊情况中,NumPy 提供了专用的函数(np.sum、np.prod、np.cumsum、 np.cumprod ) ,它们也可以实现以上 reduce 的功能。
7.3、外积
最后,任何通用函数都可以用 outer 方法获得两个不同输入数组所有元素对的函数运算结 果。这意味着你可以用一行代码实现一个乘法表:
In[30]: x = np.arange(1, 6)
np.multiply.outer(x, x)
Out[30]: array([[ 1, 2, 3, 4, 5],
[ 2, 4, 6, 8, 10],
[ 3, 6, 9, 12, 15],
[ 4, 8, 12, 16, 20],
[ 5, 10, 15, 20, 25]])
通用函数另外一个非常有用的特性是它能操作不同大小和形状的数组,一组这样的操作被 称为广播(broadcasting)。
索引、切片、迭代
对于一维数组,和Python列表一样进行索引、切片和迭代。
>>> a = np.arange(10)**3
>>> a
array([ 0, 1, 8, 27, 64, 125, 216, 343, 512, 729])
>>> a[2]
8
>>> a[2:5]
array([ 8, 27, 64])
>>> a[:6:2] = -1000 # 首先按步长区间切片,然后将每个元素设置为-1000
>>> a
array([-1000, 1, -1000, 27, -1000, 125, 216, 343, 512, 729])
>>> a[ : :-1] # 反转a
array([ 729, 512, 343, 216, 125, -1000, 27, -1000, 1, -1000])
>>> for i in a:
... print(i)
-1000
1
-1000
27
-1000
125
216
343
512
729
1、索引:获取或修改单个元素
1.1、在一维数组中,你也可以通过中括号指定索引获取第 i 个值(从 0 开始计数):
In[5]: x1
Out[5]: array([5, 0, 3, 3, 7, 9])
In[6]: x1[0]
Out[6]: 5
In[7]: x1[4]
Out[7]: 7
1.2、为了获取数组的末尾索引,可以用负值索引:
In[8]: x1[-1]
Out[8]: 9
In[9]: x1[-2]
Out[9]: 7
1.3、在多维数组中,可以用逗号分隔的索引元组获取元素:
In[10]: x2
Out[10]: array([[3, 5, 2, 4],
[7, 6, 8, 8],
[1, 6, 7, 7]])
In[11]: x2[0, 0]
Out[11]: 3
In[12]: x2[2, 0]
Out[12]: 1
In[13]: x2[2, -1]
Out[13]: 7
1.4、也可以用以上索引方式修改元素值:
In[14]: x2[0, 0] = 12
x2
Out[14]: array([[12, 5, 2, 4],
[ 7, 6, 8, 8],
[ 1, 6, 7, 7]])
2、切片:获取子数组
正如此前用中括号获取单个数组元素,我们也可以用切片(slice)符号获取子数组,切片符号用冒号(:)表示。NumPy 切片语法和 Python 列表的标准切片语法相同。Numpy的切片操作,默认是修改原数组的,而不是原生Python那样,以复制为主。为了获取数组 x 的一个切片,可以用以下方式:
x[start:stop:step]
注:如果以上3 个参数都未指定,那么它们会被分别设置默认值 start=0、stop= 维度的大小 (size of dimension)和 step=1。
2.1、一维子数组
In[16]: x = np.arange(10)
x
Out[16]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In[17]: x[:5] # 前五个元素
Out[17]: array([0, 1, 2, 3, 4])
In[18]: x[5:] # 索引五之后的元素
Out[18]: array([5, 6, 7, 8, 9])
In[19]: x[4:7] # 中间的子数组
Out[19]: array([4, 5, 6])
In[20]: x[::2] # 每隔一个元素
Out[20]: array([0, 2, 4, 6, 8])
In[21]: x[1::2] # 每隔一个元素,从索引1开始
Out[21]: array([1, 3, 5, 7, 9])
你可能会在步长值为负时感到困惑。在这个例子中,start 参数和 stop 参数默认是被交换的。因此这是一种非常方便的逆序数组的方式:
In[22]: x[::-1] # 所有元素,逆序的
Out[22]: array([9, 8, 7, 6, 5, 4, 3, 2, 1, 0])
In[23]: x[5::-2] # 从索引5开始每隔一个元素逆序
Out[23]: array([5, 3, 1])
2.2、多维子数组
多维切片也采用同样的方式处理,用冒号分隔。
In[24]: x2
Out[24]: array([[12, 5, 2, 4],
[ 7, 6, 8, 8],
[ 1, 6, 7, 7]])
In[25]: x2[:2, :3] # 两行,三列
Out[25]: array([[12, 5, 2],
[ 7, 6, 8]])
In[26]: x2[:3, ::2] # 所有行,每隔一列
Out[26]: array([[12, 2],
[ 7, 8],
[ 1, 7]])
最后,子数组维度也可以同时被逆序:
In[27]: x2[::-1, ::-1]
Out[27]: array([[ 7, 7, 6, 1],
[ 8, 8, 6, 7],
[ 4, 2, 5, 12]])
2.3、获取数组的行和列
一种常见的需求是获取数组的单行和单列。你可以将索引与切片组合起来实现这个功能, 用一个冒号(:)表示空切片:
In[28]: print(x2[:, 0]) # x2的第一列
[12 7 1]
In[29]: print(x2[0, :]) # x2的第一行
[12 5 2 4]
在获取行时,出于语法的简介考虑,可以省略空的切片:
In[30]: print(x2[0]) #等于x2[0, :]
[12 5 2 4]
2.4、非副本视图的子数组
关于数组切片有一点很重要也非常有用,那就是数组切片返回的是数组数据的视图,而不是数值数据的副本。这一点也是NumPy 数组切片和Python 列表切片的不同之处:在 Python 列表中,切片是值的副本。
In[31]: print(x2)
[[12 5 2 4]
[ 7 6 8 8]
[ 1 6 7 7]]
从中抽取一个 2×2 的子数组:
In[32]: x2_sub = x2[:2, :2]
print(x2_sub)
[[12 5]
[ 7 6]]
现在如果修改这个子数组,将会看到原始数组也被修改了!结果如下所示:
In[33]: x2_sub[0, 0] = 99
print(x2_sub)
[[99 5]
[ 7 6]]
In[34]: print(x2)
[[99 5 2 4]
[ 7 6 8 8]
[ 1 6 7 7]]
这种默认的处理方式实际上非常有用:它意味着在处理非常大的数据集时,可以获取或处理这些数据集的片段,而不用复制底层的数据缓存。
2.5、创建数组的副本
尽管数组视图有一些非常好的特性,但是在有些时候明确地复制数组里的数据或子数组也是非常有用的。可以很简单地通过 copy() 方法实现:
In[35]: x2_sub_copy = x2[:2, :2].copy()
print(x2_sub_copy)
[[99 5]
[ 7 6]]
如果修改这个子数组,原始的数组不会被改变:
In[36]: x2_sub_copy[0, 0] = 42
print(x2_sub_copy)
[[42 5]
[ 7 6]]
In[37]: print(x2)
[[99 5 2 4]
[ 7 6 8 8]
[ 1 6 7 7]]
2.6、简写
在上面的最后例子中,省略了列的索引。有时候,它们会被写作这样的格式x[i,...]。三个连续的圆点,代表其它未给出的所有轴的索引。例如假设有数组x,它有5个轴,那么:
x[1,2,...]相当于x[1,2,:,:,:]x[...,3]相当于x[:,:,:,:,3]x[4,...,5,:]相当于x[4,:,:,5,:]
参考下面的例子:
>>> c = np.array( [[[ 0, 1, 2],
... [ 10, 12, 13]],
... [[100,101,102],
... [110,112,113]]])
>>> c.shape
(2, 2, 3)
>>> c[1,...] # 等同于c[1,:,:] or c[1]
array([[100, 101, 102],
[110, 112, 113]])
>>> c[...,2] # 等同于c[:,:,2]
array([[ 2, 13],
[102, 113]])
这是偷懒的做法,不建议大家使用,省不了多少事,但带来的理解困难却很多。
3、迭代
对于多维数组的迭代其实就是对它的第一轴进行迭代,从下例子中可以看出,每个被打印的对象都是原来的一行:
>>> for row in b:
... print(row)
...
[0 1 2 3]
[10 11 12 13]
[20 21 22 23]
[30 31 32 33]
[40 41 42 43]
如果想对多维数组进行类似Python列表的那样迭代,可以使用数组的flat属性,如下例所示:
>>> for element in b.flat:
... print(element)
...
0
1
2
3
10
11
12
...
更多内容请了解:Indexing, newaxis, ndenumerate, indices
添加删除去重
下面是几个常见的数组操作:
- append:将值添加到数组末尾
- insert: 沿指定轴将值插入到指定下标之前
- delete: 返回删掉某个轴的子数组的新数组
- unique: 寻找数组内的唯一元素
>>> a = np.array([[1,2,3],[4,5,6]])
>>> np.append(a, [7,8,9]) # 附加后,变成了一维的
array([1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> a #原来的数组没有改变
array([[1, 2, 3],
[4, 5, 6]])
>>> a.append([10,11,12]) # ndarray没有这个方法
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-165-a36f3ca1308b> in <module>()
----> 1 a.append([10,11,12])
AttributeError: 'numpy.ndarray' object has no attribute 'append'
>>> np.append(a, [[7,8,9]],axis = 0) # 注意参数格式
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
>>> a = np.array([[1,2],[3,4],[5,6]])
>>> np.insert(a,3,[11,12]) # 在3号位置前插入,变成一维了
array([ 1, 2, 3, 11, 12, 4, 5, 6])
>>> a
array([[1, 2],
[3, 4],
[5, 6]])
>>> np.insert(a,1,[11],axis = 0) # 按行插入
array([[ 1, 2],
[11, 11],
[ 3, 4],
[ 5, 6]])
>>> np.insert(a,1,[11],axis = 1) #按列插入
array([[ 1, 11, 2],
[ 3, 11, 4],
[ 5, 11, 6]])
>>> a = np.arange(12).reshape(3,4)
>>> a
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> np.delete(a,5)# 删除指定位置的元素后,变成一维了
array([ 0, 1, 2, 3, 4, 6, 7, 8, 9, 10, 11])
>>> np.delete(a,1,axis = 0)
array([[ 0, 1, 2, 3],
[ 8, 9, 10, 11]])
>>> a # 并不会修改原来的数组
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> np.delete(a,1,axis = 1)
array([[ 0, 2, 3],
[ 4, 6, 7],
[ 8, 10, 11]])
unique是numpy中非常重要的方法:
>>> a = np.array([0,1,4,7,2,1,4,3])
>>> a
array([0, 1, 4, 7, 2, 1, 4, 3])
>>> np.unique(a)
array([0, 1, 2, 3, 4, 7])
>>> b = np.array([[0,1,4,],[7,2,1],[4,3,0]])
>>> b
array([[0, 1, 4],
[7, 2, 1],
[4, 3, 0]])
>>> np.unique(b)
array([0, 1, 2, 3, 4, 7])
>>> np.unique(b,axis=0)
array([[0, 1, 4],
[4, 3, 0],
[7, 2, 1]])
>>> np.unique(b,axis=1)
array([[0, 1, 4],
[7, 2, 1],
[4, 3, 0]])
>>> b = np.array([[0,1,4,],[7,2,1],[4,3,0],[0,1,4,]])
>>> b
array([[0, 1, 4],
[7, 2, 1],
[4, 3, 0],
[0, 1, 4]])
np.unique(b,axis=0)
array([[0, 1, 4],
[4, 3, 0],
[7, 2, 1]])
形状变换
| 方法 | 作用 |
|---|---|
| numpy.ravel() | 平铺数组成为一维数组,并且不修改原始本身(视图变维:数据共享) |
| numpy.reshape() | 变换数组的形状,并且不修改原始数组本身(视图变维:数据共享) |
| numpy.T | 返回转置数组 |
| numpy.resize() | 变换数组的形状,并且修改原始数组(就地变维:直接改变原数组对象的维度,不返回新数组) |
| numpy.flatten() | 将数组复制并变换为一维数组(复制变维:数据独立) |
下面的例子中,先通过numpy的random函数生成一个随机3行4列数组,再对每个元素乘10,最后用floor函数取整。
>>> a = np.floor(10*np.random.random((3,4)))
>>> a
array([[ 2., 8., 0., 6.],
[ 4., 5., 1., 1.],
[ 8., 9., 3., 6.]])
>>> a.shape
(3, 4)
有很多数组方法可以变换它的形状,并且不修改原始数组本身:
>>> a.ravel() # 平铺数组成为一维数组
array([ 2., 8., 0., 6., 4., 5., 1., 1., 8., 9., 3., 6.])
>>> a.reshape(6,2) # 调整形状
array([[ 2., 8.],
[ 0., 6.],
[ 4., 5.],
[ 1., 1.],
[ 8., 9.],
[ 3., 6.]])
>>> a.T # 返回转置数组
array([[ 2., 4., 8.],
[ 8., 5., 9.],
[ 0., 1., 3.],
[ 6., 1., 6.]])
>>> a.T.shape
(4, 3)
>>> a.shape
(3, 4)
reshape方法不会修改数组本身,resize则正好相反:
>>> a
array([[ 2., 8., 0., 6.],
[ 4., 5., 1., 1.],
[ 8., 9., 3., 6.]])
>>> a.resize((2,6))
>>> a
array([[ 2., 8., 0., 6., 4., 5.],
[ 1., 1., 8., 9., 3., 6.]])
>>> a.resize((2,7)) # 突发奇想,作死试试
alueError Traceback (most recent call last)
<ipython-input-162-8df1a3f67bca> in <module>()
----> 1 a.resize(2,7)
ValueError: cannot resize an array that references or is referenced
by another array in this way. Use the resize function
>>> np.resize(a, (2,7)) # 但是...居然可以这么干!
array([[2., 8., 0., 6., 4., 5., 1.],
[1., 8., 9., 3., 6., 2., 8.]])
# 再次提醒,在numpy中有各种类似的坑,你根本踩不过来,所以不要尝试一些自己不确定的东西。
如果reshape方法的一个参数是-1,那么这个参数的实际值会自动计算得出:
>>> a.reshape(3,-1)
array([[ 2., 8., 0., 6.],
[ 4., 5., 1., 1.],
[ 8., 9., 3., 6.]])
还可以更简单地在一个切片操作中利用 newaxis 关键字:
In[39]: x = np.array([1, 2, 3])
# 通过变形获得的行向量
x.reshape((1, 3))
Out[39]: array([[1, 2, 3]])
In[40]: # 通过newaxis获得的行向量
x[np.newaxis, :]
Out[40]: array([[1, 2, 3]])
In[41]: # 通过变形获得的列向量
x.reshape((3, 1))
Out[41]: array([[1],
[2],
[3]])
In[42]: # 通过newaxis获得的列向量
x[:, np.newaxis]
Out[42]: array([[1],
[2],
[3]])
更多内容参考:ndarray.shape, reshape, resize, ravel
拼接数组
| 方法 | 作用 |
|---|---|
| numpy.concatenate() | 按参数方向拼接多个数组;0: 垂直方向,1: 水平方向,2: 深度方向 |
| numpy.vstack() | 按垂直栈方向拼接数组 |
| numpy.hstack() | 按水平栈方向拼接数组 |
| numpy.dstack() | 按第三个维度拼接数组 |
| numpy.row_stack() | 将一维数组按行拼接成数组 |
| numpy.column_stack() | 将一维数组按列拼接成数组 |
可以在不同的轴上堆积数组:
>>> x = np.array([1, 2, 3])
>>> y = np.array([3, 2, 1])
>>> z = [99, 99, 99]
>>> print(np.concatenate([x, y, z]))
[ 1 2 3 3 2 1 99 99 99]
>>> grid = np.array([[1, 2, 3], [4, 5, 6]])
>>> np.concatenate([grid, grid]) # 沿着第一个轴拼接
array([[1, 2, 3],
[4, 5, 6],
[1, 2, 3],
[4, 5, 6]])
>>> np.concatenate([grid, grid], axis=1) # 沿着第二个轴拼接(从0开始索引)
array([[1, 2, 3, 1, 2, 3],
[4, 5, 6, 4, 5, 6]])
>>> a = np.floor(10*np.random.random((2,2)))
>>> a
array([[ 8., 8.],
[ 0., 0.]])
>>> b = np.floor(10*np.random.random((2,2)))
>>> b
array([[ 1., 8.],
[ 0., 4.]])
>>> np.vstack((a,b))
array([[ 8., 8.],
[ 0., 0.],
[ 1., 8.],
[ 0., 4.]])
>>> np.hstack((a,b))
array([[ 8., 8., 1., 8.],
[ 0., 0., 0., 4.]])
>>> np.row_stack((x, y))
array([[1, 2, 3],
[3, 2, 1],
[3, 2, 1]])
>>> np.row_stack((x, y))
array([[1, 2, 3],
[3, 2, 1],
[3, 2, 1]])
>>> np.column_stack((x, y))
array([[1, 3],
[2, 2],
[3, 1]])
与之类似,np.dstack 将沿着第三个维度拼接数组。
注意:
- 不同于reshape方法,vstack和hstack是numpy级别的功能,不能通过数组对象来调用
- v和h实际上就是垂直方向和水平方向,英文字母
- 参数要以元组的方式提供
numpy还有一个column_stack方法,其工作机制比较难以理解和记忆,建议查看范例,对照使用:
>>> from numpy import newaxis # 引入一个新轴
>>> np.column_stack((a,b))
array([[ 8., 8., 1., 8.],
[ 0., 0., 0., 4.]])
>>> a = np.array([4.,2.])
>>> b = np.array([3.,8.])
>>> np.column_stack((a,b)) # 返回一个二维数组
array([[ 4., 3.],
[ 2., 8.]])
>>> np.hstack((a,b)) # 与上面的结果是不一样的
array([ 4., 2., 3., 8.])
>>> a[:,newaxis] # 为a添加一个轴
array([[ 4.],
[ 2.]])
>>> np.column_stack((a[:,newaxis],b[:,newaxis]))
array([[ 4., 3.],
[ 2., 8.]])
>>> np.hstack((a[:,newaxis],b[:,newaxis])) # 但这时结果是一样的
array([[ 4., 3.],
[ 2., 8.]])
如果组合的数组长度不相等:
>>> a = np.array([1,2,3,4,5])
>>> b = np.array([1,2,3,4])
>>> b = np.pad(b, pad_width=(0, 1), mode='constant', constant_values=-1) # 填充b数组使其长度与a相同,头部添加0个元素,尾部添加1个元素
>>> b
array([ 1, 2, 3, 4, -1])
>>> c = np.vstack((a, b)) # 垂直方向完成组合操作,生成新数组
>>> c
array([[ 1, 2, 3, 4, 5],
[ 1, 2, 3, 4, -1]])
重要提示:在Numpy中,一维和多维,垂直和水平,不同的操作可能产生完全不同的结果和逻辑,这点不但新手容易迷惑,老手也经常出问题。最好的办法是现用现查,或者写个例子测试一下!
分割数组
| 方法 | 作用 |
|---|---|
| numpy.split() | 以分裂点列表为参数分裂数组;或按参数方向分裂数组,split必须要均等分,否则会报错;0: 垂直方向,1: 水平方向,2: 深度方向 |
| numpy.vsplit() | 以垂直栈方向分裂数组 |
| numpy.hsplit() | 以水平栈方向分裂数组 |
| numpy.dsplit() | 以第三维度分裂数组 |
| numpy.array_split() | 按参数方向分裂数组,不是必须均等分 |
使用hsplit,可以沿着数组的水平轴拆分数组,方法是指定要返回的相等形状数组的数目,或者指定在其后面进行拆分的列:
>>> x = [1, 2, 3, 99, 99, 3, 2, 1]
>>> x1, x2, x3 = np.split(x, [3, 5])
print(x1, x2, x3)
[1 2 3] [99 99] [3 2 1]
>>> A = np.arange(12).reshape(3, 4)
>>> print(np.split(A, 3))# 横向分割, 分成三部分, 按行分割
[array([[0, 1, 2, 3]]), array([[4, 5, 6, 7]]), array([[ 8, 9, 10, 11]])]
>>> print(np.split(A, 3, axis = 0))
[array([[0, 1, 2, 3]]), array([[4, 5, 6, 7]]), array([[ 8, 9, 10, 11]])]
>>> print(np.split(A, 2, axis = 1))# 纵向分割, 分成两部分, 按列分割
[array([[0, 1],
[4, 5],
[8, 9]]), array([[ 2, 3],
[ 6, 7],
[10, 11]])]
>>> a = np.floor(10*np.random.random((2,12)))
>>> a
array([[ 9., 5., 6., 3., 6., 8., 0., 7., 9., 7., 2., 7.],
[ 1., 4., 9., 2., 2., 1., 0., 6., 2., 2., 4., 0.]])
>>> np.hsplit(a,3) # 将数据均匀分割成3份
[array([[ 9., 5., 6., 3.],
[ 1., 4., 9., 2.]]), array([[ 6., 8., 0., 7.],
[ 2., 1., 0., 6.]]), array([[ 9., 7., 2., 7.],
[ 2., 2., 4., 0.]])]
>>> np.hsplit(a,(3,4)) # 在指定的列位置,分割数组
[array([[ 9., 5., 6.],
[ 1., 4., 9.]]), array([[ 3.],
[ 2.]]), array([[ 6., 8., 0., 7., 9., 7., 2., 7.],
[ 2., 1., 0., 6., 2., 2., 4., 0.]])]
>>> import numpy as np
>>> x = np.arange(8.0)
>>> print(np.array_split(x,3))
[array([0., 1., 2.]), array([3., 4., 5.]), array([6., 7.])]
显然有vsplit方法,对数组进行垂直方向的分割;与之类似,np.dstack 将沿着第三个维度拼接数组。
视图和复制
在操作或变换数组的时候,有时候会修改数组本身,有时候又不会,这往往让新手很迷惑。具体有下面三种情况:
1. 完全不复制
下面的结果,是因为数组是一个可变的对象:
>>> a = np.arange(12)
>>> b = a # 不会创建新的数组对象,而是多了一个引用
>>> b is a # a和b只是同一个数组的两个名字
True
>>> b.shape = 3,4 # 会同时修改a的形状
>>> a.shape
(3, 4)
参考Python的例子:
>>> a = [1,2,3]
>>> b=a
>>> b is a
True
>>> b.reverse()
>>> b
[3, 2, 1]
>>> a
[3, 2, 1]
2. view视图
不同的数组对象可以共享同样的数据。view方法就可以实现这一操作:
>>> c = a.view() # 现在开始c是一个新的数组,并且和a共享数据
>>> c is a # 说明c和a是两个不同的对象
False
>>> c.base is a # c是a数组的数据视图
True
>>> c.flags.owndata # 可以看到c没有自己的数据
False
>>>
>>> c.shape = 2,6 # a的形状不会发生改变
>>> a.shape
(3, 4)
>>> c[0,4] = 1234 # 但是a的数据会跟着发生改变
>>> a
array([[ 0, 1, 2, 3],
[1234, 5, 6, 7],
[ 8, 9, 10, 11]])
理解view,只需要注意两者共享数据,此外其它所有都是独立的。
切片操作,则会返回一个数组的view视图:
>>> s = a[ : , 1:3]
>>> s[:] = 10 # s[:]是s的一个视图。注意与s=10区分开,不要混淆。
>>> a
array([[ 0, 10, 10, 3],
[1234, 10, 10, 7],
[ 8, 10, 10, 11]])
3. 深度拷贝
copy方法生成数组的一个完整的拷贝,包括其数据。
>>> d = a.copy()
>>> d is a
False
>>> d.base is a
False
>>> d[0,0] = 9999
>>> a
array([[ 0, 10, 10, 3],
[1234, 10, 10, 7],
[ 8, 10, 10, 11]])
广播机制
广播允许通用函数以有意义的方式处理异构的输入。也就是让形状不一样的数组在进行运算的时候,能够得到合理的结果。其规则如下:
- 如果所有输入数组的维数都不相同,则会重复在较小数组的形状前面加上“1”,直到所有数组的维数都相同。
- 如果两个数组的形状在任何一个维度上都不匹配,那么数组的形状会沿着维度为 1 的维度扩展以匹配另外一个数组的形状。
- 如果两个数组的形状在任何一个维度上都不匹配并且没有任何一个维度等于 1, 那么会引发异常。
应用广播规则后,所有数组的大小将会匹配。请看下面的例子,加深理解:
>>> a=np.array([[0,0,0], [10,10,10],[20,20,20],[30]*3])
>>> a
array([[ 0, 0, 0],
[10, 10, 10],
[20, 20, 20],
[30, 30, 30]])
>>> b = np.array([0,1,2])
>>> b
array([0, 1, 2])
>>> a + b
array([[ 0, 1, 2],
[10, 11, 12],
[20, 21, 22],
[30, 31, 32]])
>>> c= np.array([[1],[2],[3],[4]])
>>> c
array([[1],
[2],
[3],
[4]])
>>> a + c
array([[ 1, 1, 1],
[12, 12, 12],
[23, 23, 23],
[34, 34, 34]])
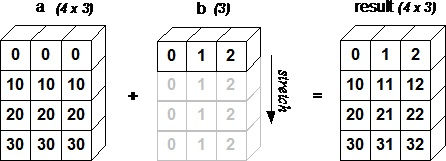
广播的实际应用:
- 数组归一化
- 画一个二维函数
布尔索引
1、比较操作
。NumPy 还实现了如 <(小于)和 >(大于)的逐元素比 较的通用函数。这些比较运算的结果是一个布尔数据类型的数组。一共有 6 种标准的比较操作:
| 运算符 | 对应的通用函数 |
|---|---|
| == | np.equal |
| != | np.not_equal |
| < | np.less |
| <= | np.less_equal |
| > | np.greater |
| >= | np.greater_equal |
In[4]: x = np.array([1, 2, 3, 4, 5])
In[5]: x < 3 # 小于
Out[5]: array([ True, True, False, False, False], dtype=bool)
In[6]: x > 3 # 大于
Out[6]: array([False, False, False, True, True], dtype=bool)
In[7]: x <= 3 # 小于等于
Out[7]: array([ True, True, True, False, False], dtype=bool)
In[8]: x >= 3 # 大于等于
Out[8]: array([False, False, True, True, True], dtype=bool)
In[9]: x != 3 # 不等于
Out[9]: array([ True, True, False, True, True], dtype=bool)
In[10]: x == 3 # 等于
Out[10]: array([False, False, True, False, False], dtype=bool)
另外,利用复合表达式实现对两个数组的逐元素比较也是可行的:
In[11]: (2 * x) == (x ** 2)
Out[11]: array([False, True, False, False, False], dtype=bool)
和算术运算通用函数一样,这些比较运算通用函数也可以用于任意形状、大小的数组。下 面是一个二维数组的示例:
In[12]: rng = np.random.RandomState(0)
x = rng.randint(10, size=(3, 4))
x
Out[12]: array([[5, 0, 3, 3],
[7, 9, 3, 5],
[2, 4, 7, 6]])
In[13]: x < 6
Out[13]: array([[ True, True, True, True],
[False, False, True, True],
[ True, True, False, False]], dtype=bool)
这样每次计算的结果都是布尔数组了。NumPy 提供了一些简明的模式来操作这些布尔结果。
2、操作布尔数组
给定一个布尔数组,你可以实现很多有用的操作。
2.1、统计记录个数
| 方法 | 作用 |
|---|---|
| numpy.count_nonzero() | 统计布尔数组中 True 记录的个数 |
| numpy.sum() | |
| numpy.any() | |
| numpy.all() |
如果需要统计布尔数组中 True 记录的个数,可以使用 np.count_nonzero 函数:
In[14]: print(x)
[[5 0 3 3]
[7 9 3 5]
[2 4 7 6]]
In[15]: # 有多少值小于6?
np.count_nonzero(x < 6)
Out[15]: 8
我们看到有 8 个数组记录是小于 6 的。另外一种实现方式是利用 np.sum。在这个例子中, False 会被解释成 0,True 会被解释成 1:
In[16]: np.sum(x < 6)
Out[16]: 8
sum() 的好处是,和其他 NumPy 聚合函数一样,这个求和也可以沿着行或列进行:
In[17]: # 每行有多少值小于6?
np.sum(x < 6, axis=1)
Out[17]: array([4, 2, 2])
这是矩阵中每一行小于 6 的个数。
如要快速检查任意或者所有这些值是否为True,可以用(你一定猜到了)np.any() 或 np.all():
In[18]: # 有没有值大于8?
np.any(x > 8)
Out[18]: True
In[19]: # 有没有值小于0?
np.any(x < 0)
Out[19]: False
In[20]: # 是否所有值都小于10?
np.all(x < 10)
Out[20]: True
In[21]: # 是否所有值都等于6?
np.all(x == 6)
Out[21]: False
np.all() 和 np.any() 也可以用于沿着特定的坐标轴,例如:
In[22]: # 是否每行的所有值都小于8?
np.all(x < 8, axis=1)
Out[22]: array([ True, False, True], dtype=bool)
这里第 1 行和第 3 行的所有元素都小于 8,而第 2 行不是所有元素都小于 8。
最后需要提醒的是,正如在 2.4 节中提到的,Python 有内置的 sum()、any() 和 all() 函数, 这些函数在 NumPy 中有不同的语法版本。如果在多维数组上混用这两个版本,会导致失败或产生不可预知的错误结果。因此,确保在以上的示例中用的都是 np.sum()、np.any() 和 np.all() 函数。
2.2、布尔运算符
| 运算符 | 对应通用函数 |
|---|---|
| & | np.bitwise_and |
| | | np.bitwise_or |
| ^ | np.bitwise_xor |
| ~ | np.bitwise_not |
使用~可以对布尔值取反,|表示或,&表示与:
In[25]: print("Number days without rain: ", np.sum(inches == 0))
print("Number days with rain: ", np.sum(inches != 0))
print("Days with more than 0.5 inches:", np.sum(inches > 0.5))
print("Rainy days with < 0.1 inches :", np.sum((inches > 0) & (inches < 0.2)))
Number days without rain: 215
Number days with rain: 150
Days with more than 0.5 inches: 37
Rainy days with < 0.1 inches : 75
关键字 and/or 与逻辑操作运算符 &/|的区别:and 和 or 判断整个对象是真或假,而 & 和 | 是指每个对象中的比特位。
2.3、将布尔数组作为掩码
在前面的小节中,我们看到了如何直接对布尔数组进行聚合计算。一种更强大的模式是使用布尔数组作为掩码,通过该掩码选择数据的子数据集。以前面小节用过的 x 数组为例, 假设我们希望抽取出数组中所有小于 5 的元素:
In[26]: x
Out[26]: array([[5, 0, 3, 3],
[7, 9, 3, 5],
[2, 4, 7, 6]])
如前面介绍过的方法,利用比较运算符可以得到一个布尔数组:
In[27]: x < 5
Out[27]: array([[False, True, True, True],
[False, False, True, False],
[ True, True, False, False]], dtype=bool)
现在为了将这些值从数组中选出,可以进行简单的索引,即掩码操作:
In[28]: x[x < 5]
Out[28]: array([0, 3, 3, 3, 2, 4])
现在返回的是一个一维数组,它包含了所有满足条件的值。换句话说,所有的这些值是掩 码数组对应位置为 True 的值。
现在,可以对这些值做任意操作,例如可以根据西雅图降水数据进行一些相关统计:
In[29]: # 为所有下雨天创建一个掩码
rainy = (inches > 0)
# 构建一个包含整个夏季日期的掩码(6月21日是第172天)
summer = (np.arange(365) - 172 < 90) & (np.arange(365) - 172 > 0)
print("Median precip on rainy days in 2014 (inches): ", np.median(inches[rainy]))
print("Median precip on summer days in 2014 (inches): ", np.median(inches[summer]))
print("Maximum precip on summer days in 2014 (inches): ", np.max(inches[summer])) print("Median precip on non-summer rainy days (inches):", np.median(inches[rainy & ~summer]))
Median precip on rainy days in 2014 (inches): 0.194881889764
Median precip on summer days in 2014 (inches): 0.0
Maximum precip on summer days in 2014 (inches): 0.850393700787
Median precip on non-summer rainy days (inches): 0.200787401575
下面是一个复杂的实际例子,它使用布尔数组对原始数组进行索引,最终生成了曼德勃罗特函数,并通过matplotlib将它绘制出来:
import numpy as np
import matplotlib.pyplot as plt
def mandelbrot( h,w, maxit=20 ):
"""Returns an image of the Mandelbrot fractal of size (h,w)."""
y,x = np.ogrid[ -1.4:1.4:h*1j, -2:0.8:w*1j ]
c = x+y*1j
z = c
divtime = maxit + np.zeros(z.shape, dtype=int)
for i in range(maxit):
z = z**2 + c
diverge = z*np.conj(z) > 2**2 # 生成布尔数组
div_now = diverge & (divtime==maxit) # 进一步处理
divtime[div_now] = i # 进行索引
z[diverge] = 2 # 避免多次操作
return divtime
plt.imshow(mandelbrot(400,400))
plt.show()
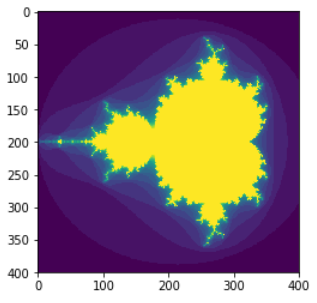
注:曼德勃罗特集是人类有史以来做出的最奇异,最瑰丽的几何图形,曾被称为“上帝的指纹”。这个点集均出自公式:Zn+1=(Zn)^2+C。这是一个迭代公式,式中的变量都是复数。这是一个大千世界,从他出发可以产生无穷无尽美丽图案,他是曼德勃罗特教授在二十世纪七十年代发现的。
花式索引
numpy提供了比常规的python序列更多的索引工具。正如我们前面看到的,除了按整数、布尔掩码和切片索引之外,还可以使用数组进行索引
1、探索索引
>>> a = np.arange(12)**2
array([ 0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100, 121], dtype=int32)
>>>print([x[1], x[1], x[3], x[8], x[5]]) #获取5个不同的元素
[ 1, 1, 9, 64, 25]
>>>ind = [ 1,1,3,8,5 ] #通过传递索引的单个列表或数组来获得同样的结果
>>>x[ind]
[ 1, 1, 9, 64, 25]
>>> i = np.array( [ 1,1,3,8,5 ] ) #一个包含索引数据的数组
>>> a[i]
array([ 1, 1, 9, 64, 25])
>>>
>>> j = np.array( [ [ 3, 4], [ 9, 7 ] ] ) #一个二维索引数组
>>> a[j] # 最终结果和j的形状保持一致
array([[ 9, 16],
[81, 49]])
当被索引的数组是多维数组时,将按照它的第一轴进行索引的,比如下面的例子:
>>> palette = np.array( [ [0,0,0],
... [255,0,0],
... [0,255,0],
... [0,0,255],
... [255,255,255] ] )
>>> image = np.array( [ [ 0, 1, 2, 0 ],
... [ 0, 3, 4, 0 ] ] )
>>> palette[image]
array([[[ 0, 0, 0],
[255, 0, 0],
[ 0, 255, 0],
[ 0, 0, 0]],
[[ 0, 0, 0],
[ 0, 0, 255],
[255, 255, 255],
[ 0, 0, 0]]])
我们这么理解:从image中每拿出一个元素,比如第一个元素0,然后去palette中找第0个行元素,也就是[0,0,0],将[0,0,0]作为一个整体放在结果数组的第一个元素位置,如此类推,就得到了最终结果。
其实,还可以提供多个索引参数,如下所示:
>>> a = np.arange(12).reshape(3,4)
>>> a
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> i = np.array( [ [0,1],
... [1,2] ] )
>>> j = np.array( [ [2,1],
... [3,3] ] )
>>>
>>> a[i,j]
array([[ 2, 5],
[ 7, 11]])
>>>
>>> a[i,2]
array([[ 2, 6],
[ 6, 10]])
>>>
>>> a[:,j]
array([[[ 2, 1],
[ 3, 3]],
[[ 6, 5],
[ 7, 7]],
[[10, 9],
[11, 11]]])
上面的例子,其实就是从i中拿一个数,再从j的相同位置拿一个数,组成一个索引坐标,再去a中找元素。这有个前提,就是i和j必须是同构的。
我们还可以这么做:
>>> k = [i,j]
>>> a[k] # 等同于a[i,j]
array([[ 2, 5],
[ 7, 11]])
但却不能这么做:
# 这个例子让人迷惑,所以不要自己给自己挖坑。简单的索引能达成目标,就不要玩花样。
>>> s = np.array( [i,j] )
>>> a[s] # 错误做法
Traceback (most recent call last):
File "<stdin>", line 1, in ?
IndexError: index (3) out of range (0<=index<=2) in dimension 0
>>>
>>> a[tuple(s)] # 等同于a[i,j]
array([[ 2, 5],
[ 7, 11]])
比较有用的是下面的技巧:
# 用一个列表作为索引参数
>>> a = np.arange(5)
>>> a
array([0, 1, 2, 3, 4])
>>> a[[1,3,4]] = 0
>>> a
array([0, 0, 2, 0, 0])
但是当索引出现重复的情况下,由最后的值决定最终结果:
>>> a = np.arange(5)
>>> a[[0,0,2]]=[1,2,3]
>>> a
array([2, 1, 3, 3, 4])
看起来一切都很美好,但是当使用Python的+=这一类操作符的时候,结果却不那么美妙:
>>> a = np.arange(5)
>>> a[[0,0,2]]+=1
>>> a
array([1, 1, 3, 3, 4])
即使0在索引列表中出现两次,第0个元素也只增加一次。这是因为python要求“a+=1”等同于“a=a+1”。
2、组合索引
花哨的索引可以和其他索引方案结合起来形成更强大的索引操作:
In[9]: print(X)
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
可以将花哨的索引和简单的索引组合使用:
In[10]: X[2, [2, 0, 1]]
Out[10]: array([10, 8, 9])
也可以将花哨的索引和切片组合使用:
In[11]: X[1:, [2, 0, 1]]
Out[11]: array([[ 6, 4, 5],
[10, 8, 9]])
更可以将花哨的索引和掩码组合使用:
In[12]: mask = np.array([1, 0, 1, 0], dtype=bool)
X[row[:, np.newaxis], mask]
Out[12]: array([[ 0, 2],
[ 4, 6],
[ 8, 10]])
索引选项的组合可以实现非常灵活的获取和修改数组元素的操作。
3、修改值
正如花哨的索引可以被用于获取部分数组,它也可以被用于修改部分数组。例如,假设我们有一个索引数组,并且希望设置数组中对应的值:
In[18]: x = np.arange(10)
i = np.array([2, 1, 8, 4])
x[i] = 99
print(x)
[ 0 99 99 3 99 5 6 7 99 9]
可以用任何的赋值操作来实现,例如:
In[19]: x[i] -= 10
print(x)
[ 0 89 89 3 89 5 6 7 89 9]
不过需要注意,操作中重复的索引会导致一些出乎意料的结果产生,如以下例子所示:
In[20]: x = np.zeros(10)
x[[0, 0]] = [4, 6]
print(x)
[ 6. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
赋值中的4去哪里了呢?这个操作首先赋值 x[0] = 4,然后赋值 x[0] = 6,因此当然 x[0] 的值为 6。
以上还算合理,但是设想以下操作:
In[21]: i = [2, 3, 3, 4, 4, 4]
x[i] += 1
x
Out[21]: array([ 6., 0., 1., 1., 1., 0., 0., 0., 0., 0.])
你可能期望 x[3] 的值为 2,x[4] 的值为 3,因为这是这些索引值重复的次数。但是为什么 结果不同于我们的预想呢?从概念的角度理解,这是因为 x[i] += 1 是 x[i] = x[i] + 1 的简写。x[i] + 1 计算后,这个结果被赋值给了 x 相应的索引值。记住这个原理后,我们却发现数组并没有发生多次累加,而是发生了赋值,显然这不是我们希望的结果。
因此,如果你希望累加,该怎么做呢?你可以借助通用函数中的 at() 方法来实现。进行如下操作:
In[22]: x = np.zeros(10)
np.add.at(x, i, 1)
print(x)
[ 0. 0. 1. 2. 3. 0. 0. 0. 0. 0.]
at() 函数在这里对给定的操作、给定的索引(这里是 i)以及给定的值(这里是 1)执行的是就地操作。另一个可以实现该功能的类似方法是通用函数中的 reduceat() 函数,你可 以在 NumPy 文档中找到关于该函数的更多信息。
排序
1、NumPy中的快速排序:np.sort和np.argsort
可以使用sort方法对数组或数组某一维度进行就地排序,这会修改数组本身。
>>> a = np.array([[1,6,2],[6,1,3],[1,5,2]])
>>> b=a
>>> b.sort()
>>> b
array([[1, 2, 6],
[1, 3, 6],
[1, 2, 5]])
>>> a
array([[1, 2, 6],
[1, 3, 6],
[1, 2, 5]])
>>> a = np.array([[1,6,2],[6,1,3],[1,5,2]])
>>> a
array([[1, 6, 2],
[6, 1, 3],
[1, 5, 2]])
>>> a.sort(axis=1)
>>> a
array([[1, 2, 6],
[1, 3, 6],
[1, 2, 5]])
>>> a = np.array([[1,6,2],[6,1,3],[1,5,2]])
>>> a.sort(axis=0)
>>> a
array([[1, 1, 2],
[1, 5, 2],
[6, 6, 3]])
另外一个相关的函数是 argsort,该函数返回的是原始数组排好序的索引值:
In[7]: x = np.array([2, 1, 4, 3, 5])
i = np.argsort(x)
print(i)
[1 0 3 2 4]
以上结果的第一个元素是数组中最小元素的索引值,第二个值给出的是次小元素的索引值,以此类推。这些索引值可以被用于(通过花哨的索引)创建有序的数组:
2、部分排序:分隔
有时候我们不希望对整个数组进行排序,仅仅希望找到数组中第K小的值,NumPy 的 np.partition 函数提供了该功能。np.partition 函数的输入是数组和数字 K,输出结果是 一个新数组,最左边是第 K 小的值,往右是任意顺序的其他值:
In[12]: x = np.array([7, 2, 3, 1, 6, 5, 4])
np.partition(x, 3)
Out[12]: array([2, 1, 3, 4, 6, 5, 7])
请注意,结果数组中前三个值是数组中最小的三个值,剩下的位置是原始数组剩下的值。 在这两个分隔区间中,元素都是任意排列的。
与排序类似,也可以沿着多维数组任意的轴进行分隔:
In[13]: np.partition(X, 2, axis=1)
Out[13]: array([[3, 4, 6, 7, 6, 9],
[2, 3, 4, 7, 6, 7],
[1, 2, 4, 5, 7, 7],
[0, 1, 4, 5, 9, 5]])
输出结果是一个数组,该数组每一行的前两个元素是该行最小的两个值,每行的其他值分布在剩下的位置。
最后,正如 np.argsort 函数计算的是排序的索引值,也有一个 np.argpartition 函数计算的是分隔的索引值,
大 O 标记是一种描述一个算法对于相应的输入数据的大小需要执行的操作步骤数。要想正确使用它,需要深入理解计算机科学理论,并且将其和小 o 标记、大 θ 标记、大 Ω 标记以及其他混合变体区分开。虽然区分这些概念可以提高算法复杂度计量的准确性,但是除了在计算机科学理论和学究的博客评论外,实际中很少有这种区分。在数据科学中,更常见的还是不太严谨的大 O 标记——一种通用的(或许是不准确的)算法复杂度的度量描述。在这里要向相关的理论学家和学者致歉,本书中都会使用这种表述方式。
如果不用太严谨的眼光看待大O 标记,那么它其实是告诉你:随着输入数据量的增长,你的算法将花费多少时间。如果你有一个 [N](读作“N 阶”)复杂度的算法, 该算法花费1 秒钟来执行一个长度为N = 1000 的列表,那么它执行一个长度为N = 5000 的列表花费的时间大约是 5 秒钟。如果你有一个算法复杂度为 [N 2](读作“N 的平方阶”),且该算法花费 1 秒钟来执行一个长度为 N = 1000 的列表,那么它执行一 个长度为 N = 5000 的列表花费的时间大约是 25 秒钟。 在计算算法复杂度时,N 通常表示数据集的大小(数据点的个数、维度的数目等)。当我们试图分析数十亿或数百万亿的数据时,算法复杂度为 [N] 和算法复杂度为 [N 2] 会有非常明显的差别! 需要注意的是,大 O 标记并没有告诉你计算的实际时间,而仅仅告诉你改变N 的值 时,运行时间的相应变化。通常情况下, [N] 复杂度的算法比 [N 2] 复杂度的算法更 高效。但是对于小数据集,算法复杂度更优的算法可能未必更快。例如对于给定的问题, [N 2] 复杂度的算法可能会花费 0.01 秒,而更“优异”的 [N] 复杂度的算法可 能会花费 1 秒。按照 1000 的因子将 N 倍增,那么 [N] 复杂度的算法将胜出。
即使是这个非严格版本的大 O 标记对于比较算法的性能也是非常有用的。我们将在本书中用这个标记来测量算法复杂度。
统计方法
可以通过以下的基本统计方法对整个数组或者数组的某个轴的数据进行统计:
| 方法 | 说明 |
|---|---|
| sum | 求和 |
| mean | 算术平均数 |
| std | 标准差 |
| var | 方差 |
| min | 最小值 |
| max | 最大值 |
| ptp | 极差 |
| argmax | 最大元素在指定轴上的索引 |
| argmin | 最小元素在指定轴上的索引 |
| cumsum | 累积的和 |
| cumprod | 累积的乘积 |
| average | 加权平均值 |
| maximum | 将两个同维数组中对应元素中最大元素构成一个新的数组 |
| minimum | 将两个同维数组中对应元素中最小元素构成一个新的数组 |
示例:
>>> a = np.arange(12).reshape(3,4)
>>> a
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> a.sum()
66
>>> a.sum(axis=1)
array([ 6, 22, 38])
>>> a.mean()
5.5
>>> a.mean(axis=1)
array([1.5, 5.5, 9.5])
>>> a.std()
3.452052529534663
>>> a.var()
11.916666666666666
>>> a.max()
11
>>> a.cumsum()
array([ 0, 1, 3, 6, 10, 15, 21, 28, 36, 45, 55, 66], dtype=int32)
>>> a.cumsum(axis=1)
array([[ 0, 1, 3, 6],
[ 4, 9, 15, 22],
[ 8, 17, 27, 38]], dtype=int32)
>>> a.cumprod()
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], dtype=int32)
>>> a.cumprod(axis=1)
array([[ 0, 0, 0, 0],
[ 4, 20, 120, 840],
[ 8, 72, 720, 7920]], dtype=int32)
>>> a.argmin()
0
>>> a.argmax()
11
除了以上的统计方法,还有针对布尔数组的三个重要方法:sum、any和all:
- sum : 统计数组或数组某一维度中的True的个数
- any: 统计数组或数组某一维度中是否存在一个/多个True,只要有则返回True,否则返回False
- all:统计数组或数组某一维度中是否都是True,都是则返回True,否则返回False
实际上,对于普通的数组,以上三个操作也是可以的。对于any和all函数,将非0的数字都看作True,0看作False。
>>> a
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> a.any()
True
>>> a.all()
False
>>> b = np.arange(1,3)
>>> b
array([1, 2])
>>> b.all()
True
>>> b.any()
True
>>> x = np.array([[True,False],[True,False]])
>>> x.sum()
2
>>> x.any()
True
>>> x.all()
False
>>> c = np.array([-1,2,3+1j])
>>> c.any()
True
>>> c.all()
True
随机数
numpy带有一个random模块,它弥补了Python标准自建random模块的一些不足,效率更高、速度更快、功能更强大。当然这些数都是伪随机数,可以通过seed种子来初始化。下表是numpy.random中的部分函数:
| 函数 | 功能 |
|---|---|
| random | 返回一个区间[0.0, 1.0)中的随机浮点数 |
| seed | 向随机数生成器传递随机状态种子 |
| permutation | 返回一个序列的随机排列,或者返回一个乱序的整数范围序列 |
| shuffle | 随机排列一个序列 |
| rand | 从均匀分布中抽取样本 |
| randint | 根据给定的由低到高的范围抽取随机整数 |
| randn | 从均值0,方差1的正态分布中抽取样本 |
| binomial | 从二项式分布中抽取样本 |
| normal | 从正态分布中抽取样本 |
| beta | 从beta分布中抽取样本 |
| chisquare | 从卡方分布中抽取样本 |
| gamma | 从伽马分布中抽取样本 |
| uniform | 从均匀[0,1)中抽取样本 |
>>> import numpy.random as npr # 常用导入方法
>>> npr.random() # 生成1个
0.8898080952787953
>>> npr.random(5) # 生成5个
array([0.32815036, 0.47386 , 0.06808472, 0.3827107 , 0.11855414])
>>> npr.random((2,3)) # 生成2行3列
array([[0.89632852, 0.76430853, 0.37540494],
[0.02581418, 0.90653093, 0.78641778]])
>>> npr.seed(1234) # 设置种子
>>> npr.randn() # 生成1个
-0.008678581361935722
>>> npr.randn(3) # 生成3个
array([-1.60921761, -1.26864685, 0.52483734])
>>> npr.randn(2,3) # 生成2行3列
array([[-0.32106129, 1.05697037, -0.59017955],
[-0.38786434, -0.04653935, -0.99871643]])
>>> npr.randint(4) # 生成不大于4的整数
2
>>> npr.randint(1,10) # 生成一个1到10之间的整数
1
>>> npr.randint(1,10,5) # 生成5个1到10之间的整数
array([1, 4, 3, 4, 2])
>>> npr.randint(1,10,(2,3)) # 生成2行3列1到10之间的整数,或者用size参数
array([[2, 6, 8],
[5, 8, 8]])
>>> npr.rand()
0.4527298092633677
>>> npr.rand(3)
array([0.53814784, 0.7906221 , 0.46583634])
>>> npr.rand(2,3)
array([[0.76453077, 0.59973081, 0.08094696],
[0.70454447, 0.16401332, 0.03234935]])
>>> npr.normal()
-0.8241256032186633
>>> npr.normal(3,4) # 指定正态分布的两个重要参数
7.059397334847745
>>> npr.normal(3,4,(2,3)) # 生成2行3列
array([[0.77190185, 1.30157588, 3.54998357],
[2.71794779, 4.30157729, 1.1059138 ]])
结构化数组
大多数时候,我们的数据可以通过一个异构类型值组成的数组表示,但有时却并非如此。 这里介绍NumPy 的结构化数组和记录数组,它们为复合的、异构的数据提供了非常有效的存储。尽管这里列举的模式对于简单的操作非常有用,但是这些场景通常也可以用 Pandas 的 DataFrame 来实现。
假定现在有关于一些人的分类数据(如姓名、年龄和体重),我们需要存储这些数据用于 Python 项目,那么一种可行的方法是将它们存在三个单独的数组中:
In[2]: name = ['Alice', 'Bob', 'Cathy', 'Doug']
age = [25, 45, 37, 19]
weight = [55.0, 85.5, 68.0, 61.5]
但是这种方法有点笨,因为并没有任何信息告诉我们这三个数组是相关联的。如果可以用一种单一结构来存储所有的数据,那么看起来会更自然。NumPy 可以用结构化数组实现这 种存储,这些结构化数组是复合数据类型的。
前面介绍过,利用以下表达式可以生成一个简单的数组:
In[3]: x = np.zeros(4, dtype=int)
与之类似,通过指定复合数据类型,可以构造一个结构化数组:
In[4]: # 使用复合数据结构的结构化数组
data = np.zeros(4, dtype={'names':('name', 'age', 'weight'),
'formats':('U10', 'i4', 'f8')})
print(data.dtype)
[('name', '<U10'), ('age', '<i4'), ('weight', '<f8')]
这里 U10 表示“长度不超过 10 的 Unicode 字符串”,i4 表示“4 字节(即 32 比特)整型”, f8 表示“8 字节(即 64 比特)浮点型”。
现在生成了一个空的数组容器,可以将列表数据放入数组中:
In[5]: data['name'] = name
data['age'] = age
data['weight'] = weight
print(data)
[('Alice', 25, 55.0) ('Bob', 45, 85.5) ('Cathy', 37, 68.0) ('Doug', 19, 61.5)]
正如我们希望的,所有的数据被安排在一个内存块中。
结构化数组的方便之处在于,你可以通过索引或名称查看相应的值:
In[6]: # 获取所有名字
data['name']
Out[6]: array(['Alice', 'Bob', 'Cathy', 'Doug'], dtype='<U10')
In[7]: # 获取数据第一行
data[0]
Out[7]: ('Alice', 25, 55.0)
In[8]: # 获取最后一行的名字
data[-1]['name']
Out[8]: 'Doug'
利用布尔掩码,还可以做一些更复杂的操作,如按照年龄进行筛选:
In[9]: # 获取年龄小于30岁的人的名字
data[data['age'] < 30]['name']
Out[9]: array(['Alice', 'Doug'], dtype='<U10')
请注意,如果你希望实现比上面更复杂的操作,那么你应该考虑使用 Pandas 包。
1、生成结构化数组
结构化数组的数据类型有多种制定方式。此前我们看过了采用字典的方法:
In[10]: np.dtype({'names':('name', 'age', 'weight'), 'formats':('U10', 'i4', 'f8')})
Out[10]: dtype([('name', '<U10'), ('age', '<i4'), ('weight', '<f8')])
为了简明起见,数值数据类型可以用 Python 类型或 NumPy 的 dtype 类型指定:
In[11]: np.dtype({'names':('name', 'age', 'weight'), 'formats':((np.str_, 10), int, np.float32)})
Out[11]: dtype([('name', '<U10'), ('age', '<i8'), ('weight', '<f4')])
复合类型也可以是元组列表:
In[12]: np.dtype([('name', 'S10'), ('age', 'i4'), ('weight', 'f8')])
Out[12]: dtype([('name', 'S10'), ('age', '<i4'), ('weight', '<f8')])
如果类型的名称对你来说并不重要,那你可以仅仅用一个字符串来指定它。在该字符串中数据类型用逗号分隔:
In[13]: np.dtype('S10,i4,f8')
Out[13]: dtype([('f0', 'S10'), ('f1', '<i4'), ('f2', '<f8')])
简写的字符串格式的代码可能看起来令人困惑,但是它们其实基于非常简单的规则。第一个(可选)字符是 < 或者 >,分别表示“低字节序”(little endian)和“高字节序”(bid endian),表示字节(bytes)类型的数据在内存中存放顺序的习惯用法。后一个字符指定的 是数据的类型:字符、字节、整型、浮点型,等等(如表 2-4 所示)。最后一个字符表示该 对象的字节大小。
| NumPy数据类型符号 | 描述 | 示例 |
|---|---|---|
| 'b' | 字节型 | numpy.dtype('b') |
| 'i' | 有符号整型 | numpy.dtype('i4') == numpy.int32 |
| 'u' | 无符号整型 | numpy.dtype('u1') == numpy.uint8 |
| 'f' | 浮点型 | numpy.dtype('f8') == numpy.int64 |
| 'c' | 复数浮点型 | numpy.dtype('c16') == numpy.complex128 |
| 'S'、'a' | 字符串 | numpy.dtype('S5') |
| 'U' | Unicode 编码字符串 | numpy.dtype('U') == numpy.str_ |
| 'V' | 原生数据,raw data(空,void) | numpy.dtype('V') == numpy.void |
2、更高级的复合类型
NumPy 中也可以定义更高级的复合数据类型。例如,你可以创建一种类型,其中每个元素 都包含一个数组或矩阵。我们会创建一个数据类型,该数据类型用 mat 组件包含一个 3×3 的浮点矩阵:
In[14]: tp = np.dtype([('id', 'i8'), ('mat', 'f8', (3, 3))])
X = np.zeros(1, dtype=tp)
print(X[0])
print(X['mat'][0])
(0, [[0.0, 0.0, 0.0], [0.0, 0.0, 0.0], [0.0, 0.0, 0.0]])
[[ 0. 0. 0.]
[ 0. 0. 0.]
[ 0. 0. 0.]]
现在 X 数组的每个元素都包含一个 id 和一个 3×3 的矩阵。为什么我们宁愿用这种方法存储数据,也不用简单的多维数组,或者 Python 字典呢?原因是 NumPy 的 dtype 直接映射到 C 结构的定义,因此包含数组内容的缓存可以直接在 C 程序中使用。如果你想写一个 Python 接口与一个遗留的 C 语言或 Fortran 库交互,从而操作结构化数据,你将会发现结构化数组非常有用!
3、记录数组:结构化数组的扭转
NumPy 还提供了 np.recarray 类。它和前面介绍的结构化数组几乎相同,但是它有一个独特的特征:域可以像属性一样获取,而不是像字典的键那样获取。前面的例子通过以下代 码获取年龄:
In[15]: data['age']
Out[15]: array([25, 45, 37, 19], dtype=int32)
如果将这些数据当作一个记录数组,我们可以用很少的按键来获取这个结果:
In[16]: data_rec = data.view(np.recarray)
data_rec.age
Out[16]: array([25, 45, 37, 19], dtype=int32)
记录数组的不好的地方在于,即使使用同样的语法,在获取域时也会有一些额外的开销, 如以下示例所示:
In[17]: %timeit data['age']
%timeit data_rec['age']
%timeit data_rec.age
1000000 loops, best of 3: 241 ns per loop
100000 loops, best of 3: 4.61 µs per loop
100000 loops, best of 3: 7.27 µs per loop
是否值得为更简便的标记方式花费额外的开销,这将取决于你的实际应用。
常用函数
加载文件
numpy提供了函数用于加载逻辑上可被解释为二维数组的文本文件,格式如下:
数据项1 <分隔符> 数据项2 <分隔符> ... <分隔符> 数据项n
例如:
AA,AA,AA,AA,AA
BB,BB,BB,BB,BB
...
或:
AA:AA:AA:AA:AA
BB:BB:BB:BB:BB
...
调用numpy.loadtxt()函数可以直接读取该文件并且获取ndarray数组对象:
np.loadtxt('../aapl.csv', delimiter=',', usecols=(1, 3), unpack=False, dtype='U10, f8', converters={1:func})
直接读取该文件并且获取ndarray数组对象
主要参数说明:
- '':文件路径
- delimiter:分隔符
- usecols: 读取列数
- unpack:是否按列拆包
- False:返回一个二维数组
- True: 多个一维数组
- dtype:制定返回每一列数组中元素的类型
- converters:转换器函数字典
示例:读取aapl.csv文件,得到文件中的信息:
import numpy as np
import datetime as dt
# 日期转换函数
def dmy2ymd(dmy):
dmy = str(dmy, encoding='utf-8')
time = dt.datetime.strptime(dmy, '%d-%m-%Y').date()
t = time.strftime('%Y-%m-%d')
return t
dates, opening_prices,highest_prices, \
lowest_prices, closeing_pric es = np.loadtxt(
'../data/aapl.csv', # 文件路径
delimiter=',', # 分隔符
usecols=(1, 3, 4, 5, 6), # 读取1、3两列 (下标从0开始)
unpack=True,
dtype='M8[D], f8, f8, f8, f8', # 制定返回每一列数组中元素的类型
converters={1:dmy2ymd})