clang架构与示例实践
1 C语言编译器Clang
1.1 Clang和GCC编译器架构
Clang编译器是由APPLE公司的编译器大牛ChrisLattner主导下编写的,其目标是替换大名鼎鼎的GCC编译器;
从源代码到可执行程序一般经过预处理、编译、链接过程,而编译是编译器的工作,编译分为三个阶段,分别为前端、优化器、后端,如图1所示。

图1 编译器的前中后端
1)编译前端:将源代码转化成中间代码。其详细过程包括:词法分析、语法分析、生成中间代码;
2)优化器:对编译器生成的中间代码进行一些优化,最终提供给编译后端;
3)编译后端:根据不同的芯片架构,将中间代码汇编,产生汇编代码,最后解析汇编指令,生成目标代码,也就是机器码,编译器的这种前端、优化器、后端的架构的优点,如图2所示。

图2 编译器的前中后端优点
首先,当为新的语言开发编译器时,只需要针对新的语言开发前端,产生标准通用的中间代码,这样优化器与后端可以不用修改;
其次,当为新的架构开发编译器时,只需要针对新的架构开发后端,而无需修改前端和优化器。
所以,这种架构对编译器的开发维护工作就简单许多,同时可提升执行效率。
1.2 Clang起源
从XCODE4开始,也就是 MacOS X 10.6版本系统上,Apple 宣布停止更新GCC编译器,这样GCC停留在GCC4.2版本,并建议大家使用LLVM Compiler 2.0(LLVM-Clang),该版本完全支持C++/ Objective-C++,并提供libc++库来支持新的C++ standard(C++0x标准),而GCC/LLVM-GCC支持的是GCC标准库libstdc++。
从XCODE4.2开始,就默认使用LLVM-Clang,彻底抛弃了GCC;而LLVM-GCC毕竟也是亲儿子,改为一个GCC的插件DragonEgg。如图3所示表示三种编译器对比。
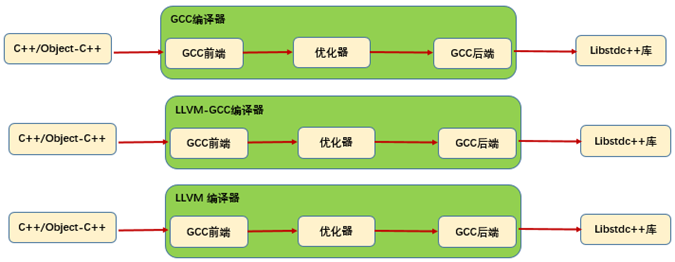
图3 三种编译器对比
由于Clang设计之初就考虑到模块化设计,因此,清晰简单,出错提示更好,易于扩展,容易与IDE集成;而GCC由于早期设计只支持C语言,后面不断扩展C++/ Java/Ada/Fortran/Go等;虽然支持更多平台,而且更流行,使用更广泛,支持更完备;但是其代码接口耦合性强,更新维护和性能等较差。
由于LLVM-Clang的优秀设计,AndroidNDK从R11开始建议大家切换到Clang。并且把GCC标记为deprecated,将GCC版本锁定在GCC 4.9不再更新;Android NDK从R13起,默认使用Clang进行编译。但是暂时也没有把GCC删掉,Google考虑 libc++(LLVM-Clang的c++标准库)还不够稳定;Android NDK 在 R17 中宣称不再支持 GCC 并在后续的 R18 中删掉 GCC。现在GCC主战场只剩Linux与部分Windows应用软件开发。
现在最新LLVM版本号已经到了16.0.0版本,官方地址如下:
LLVM编译器基础架构:http://llvm.org/
Clang:http://clang.llvm.org/
DragonEgg – LLVM-GCC:http://dragonegg.llvm.org/
2 Clang模块内部实现原理及源码分析
开发工程开始支持Swift,在适配Clang模块的过程中,遇到了各种各样的编译问题。为了弄清楚这些编译失败的真正原因,以及Clang模块的最佳实践,通过分析Clang模块的实现代码,以便解开这些谜团。
2.1 编译参数分析
Xcode的构建设置,针对Clang模块有专门的设置分组,如下代码所示:
App Clang-Language-Module
Setting
Allow Non-modular Includes In Framework Modules
Disable Private Modules Warnings
Enable Module Debugging
Enable Modules (C and Objective-C)
Link Frameworks Automatically
针对这几个设置参数,下面分别解释一下其作用。
1. 使能Modules (C and Objective-C)
是否开启Clang模块特性。
当设置为YES的时候,会设置编译器参数-fmodules,开启Clang模块特性。当设置为NO的时候,其它4个选项也会随之失效,不会设置编译器参数-fmodules。
2. 使能Clang模块调试
对引用的外部Clang模块或者预编译头文件生成调试信息。
当设置为YES的时候,会设置编译器参数
-gmodules。举例说明一下这个参数,自己模块的
Objective-C源代码中如果有#import <Foundation/Foundation.h>,那么Foundation(基础)模块就属于被引用的外部Clang模块。当开启Clang模块特性的时候,会根据基础模块提供的modulemap生成Clang模块编译缓存,其缓存的目录是通过编译器参数-fmodules-cache-path来设定的。默认Xcode会设定编译缓存目录为的
ModuleCache.noindex。-fmodules-cache-path=/Users/wjm/Library/Developer/Xcode/DerivedData/ModuleCache.noindexModuleCache.noindex为Clang模块缓存目录,Foundation-3DFYNEBRQSXST.pcm为基础的缓存文件。 当启用Clang模块调试为YES的时候,这个缓存文件为Mach-O格式的文件,其中
__CLANG,__clangast节为缓存内容,这个文件还携带__DWARF,__debug_info等一些调试信息。其中缓存内容的头4个字节签名是CPCH,应该是已编译的PCH的缩写。如图4 CPCH编译器工程示例。
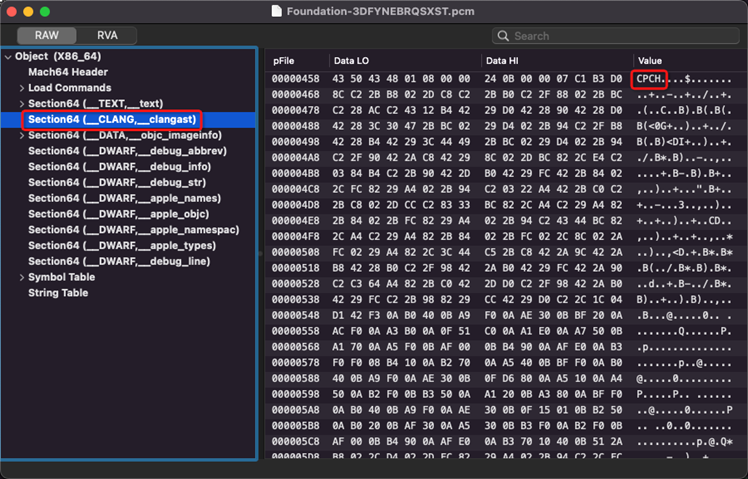
图4 CPCH编译器工程示例
当启用Clang模块调试为NO的时候,缓存文件直接就是CPCH文件,不会生成Mach-O格式且携带调试信息,如图5所示。

图5当Clang模块调试为NO时,CPCH编译器工程示例
建议正常开发的时候关闭这个设置,当出现Clang模块编译问题的时候,可以开启这个调试选项,有了DWARF的调试信息,可以精确定位的错误代码的行号和列号。
开启这个选项后,编译时会有性能损失,因为缓存变成了Mach-O格式,需要完整加载整个文件,读取
__clangast节,才能获取真正的缓存内容。从下面代码中,就可以看出,CPCH文件内容其实就是AST的位码,所以,Clang模块的实现机制是和预编译头文件一致的,Clang模块可以认为是更通用的预编译头文件,如图6所示。
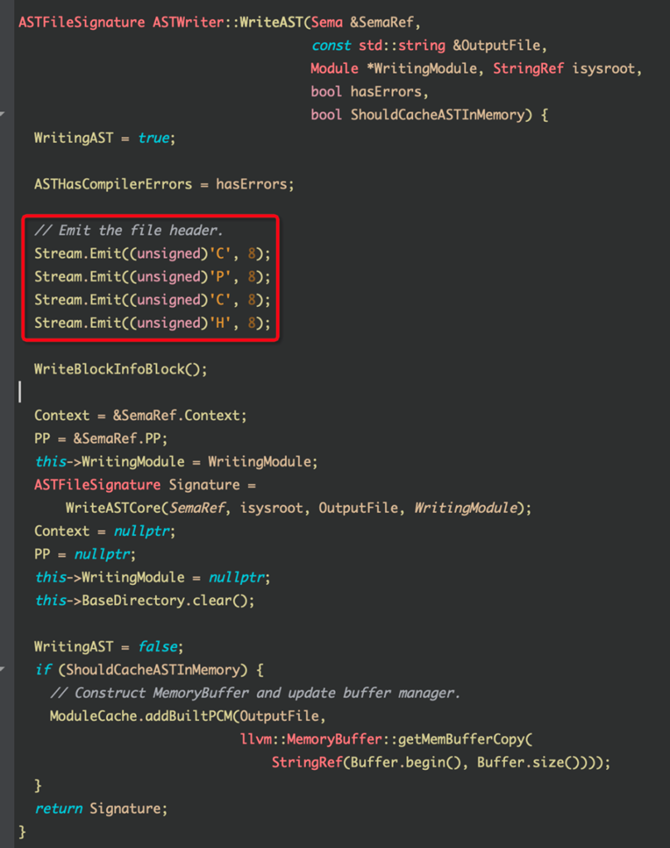
图6 通用的预编译头文件
3. 禁用专用模块警告
私有模块概念比较复杂,后面再展开。
4. 允许非模块化包含在框架内模块
允许框架模块中有非Clang模块的include。
当设置为NO的时候,会设置编译器参数
-Wnon-modular-include-in-framework-module。如果在引用的模块中,遇到非Clang模块的头文件,例如 #import "XXX.h" 这样格式的import指令,就会报错。5. 自动链接框架
对于开启Clang模块后,import clang模块会自动对链接器ld64增加链接参数,如图7红框所示:

图7 增加链接参数
因为都是使用CocoaPod来管理依赖,所以,最好关闭此选项,统一在podspec中声明依赖的框架和weak_frameworks。
关闭后,会增加编译器参数
-fno-autolink。6. 定义Module
Packaging
Setting
Adjust Strings File Names for Info.plist
Convert Copied Files
Create Info.plist Section in Binary
Defines Module
Don't Force Info.plist Generation
当开启的时候,会生成modulemap文件,如果当前编译模块有和已有模块同名的头文件,则modulemap编译器会帮忙合成一个,也支持自定义设置modulemap文件。
会增加两个编译器参数,其中一个是设置Clang模块名。
-fmodule-name=ClangModuleTest另一个是形成虚拟的Clang模块层,让当前源码编译的模块也可以伪装成Clang模块格式。
这个内容是json,如图8所示。
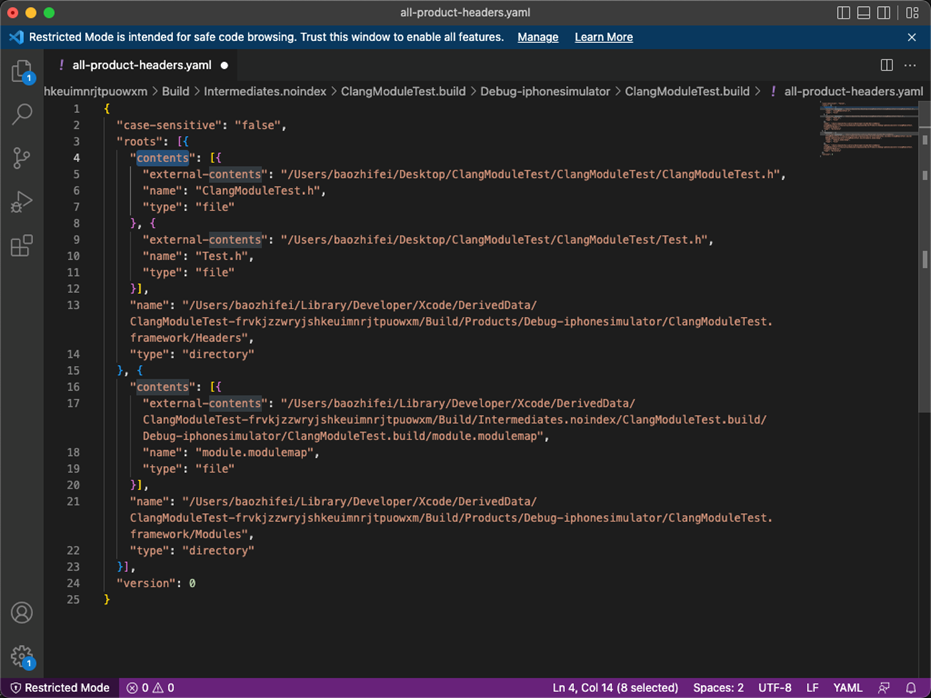
图8 虚拟的Clang模块层
7. 源代码
llvm项目地址:https://github.com/llvm/llvm-project
编译调试的版本是14.0.6,是目前最新的tag。调试的代码,用Xcode创建一个新的框架工程称为ClangModuleTest,新增Test类,分析Test.m的编译流程,如图9所示。

图9 用Xcode创建新的框架工程
Xcode内置的Clang版本应该是有一些功能没有开源,开源的Clang不能识别
-index-unit-output-path和-index-store-path,调试的时候这两个参数删除即可。最新版本的Clang的编译参数,都统一定义在Options.td文件中,通过
clang-tblgen来统一生成,这样生成出来的rst文档和Options.inc是一致的,在Options.td中没有找到上述两个参数。如果是vscode,要配置settings.json和launch.json文件,内容大致如图10与11所示:
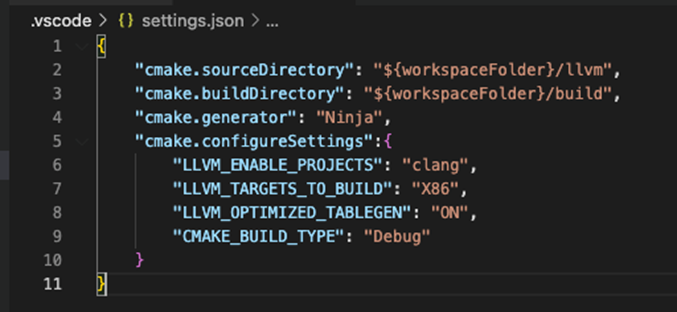
图10 配置settings.json文件
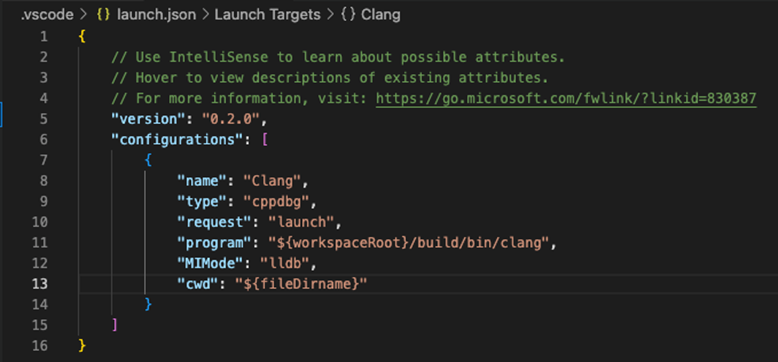
图11 配置launch.json文件
2.2 预处理
clang::Preprocessor是负责预处理的类,预处理主要是处理编译单元中的一些以#开头的预处理指令,比如,#import导入头文件预编译指令,这些指令定义在TokenKinds.def文件中,如图12所示。
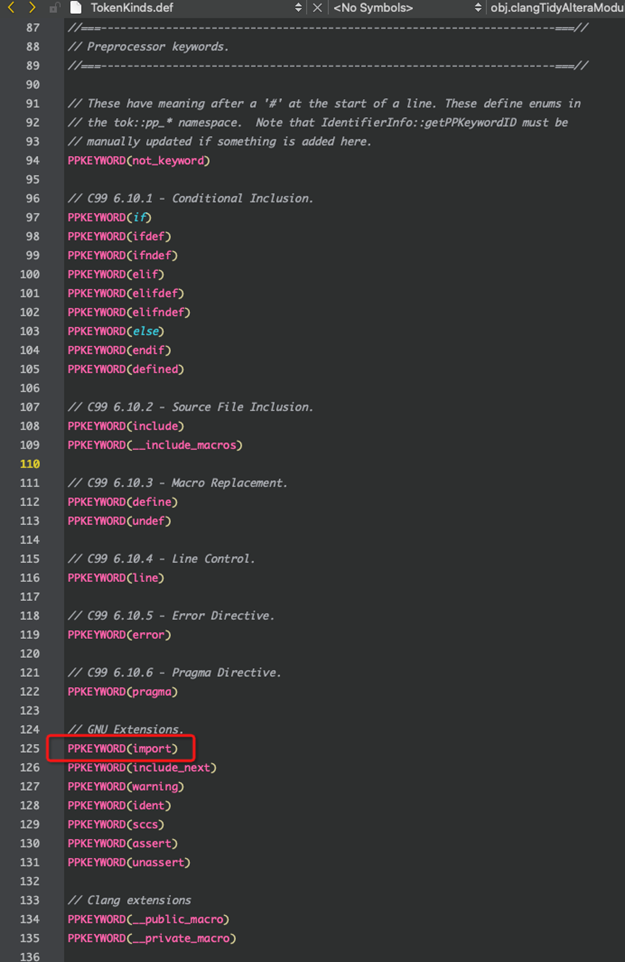
图12 导入预编译指令
所以,Preprocessor是需要分词的词法分析,在开始预处理之前EnterSourceFile中,就会创建词法分析对象,如图13所示。
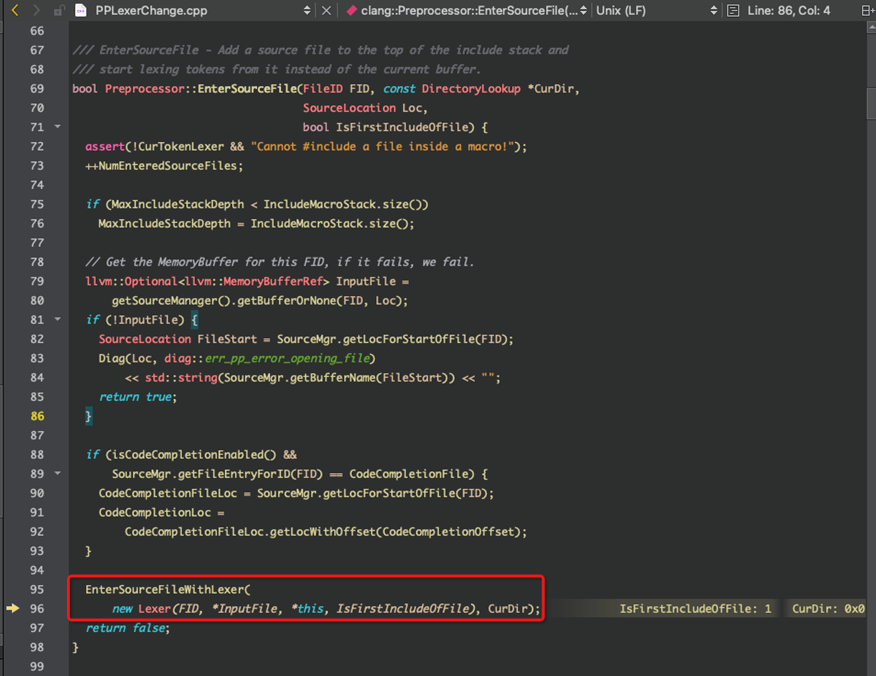
图13 Preprocessor创建词法分析对象
测试代码,第一行就是import指令,如图14所示。
图14 输入指令,测试代码
如图15所示,在HandleDirective方法中分发调用各自预处理指令的处理函数。

图15 HandleDirective预处理指令函数
因为预处理指令是
#import <Foundation/Foundation.h>,可以推断出是基础模块。如图16所示,从HeaderSearch中,找到对应的基础的module.modulemap文件。
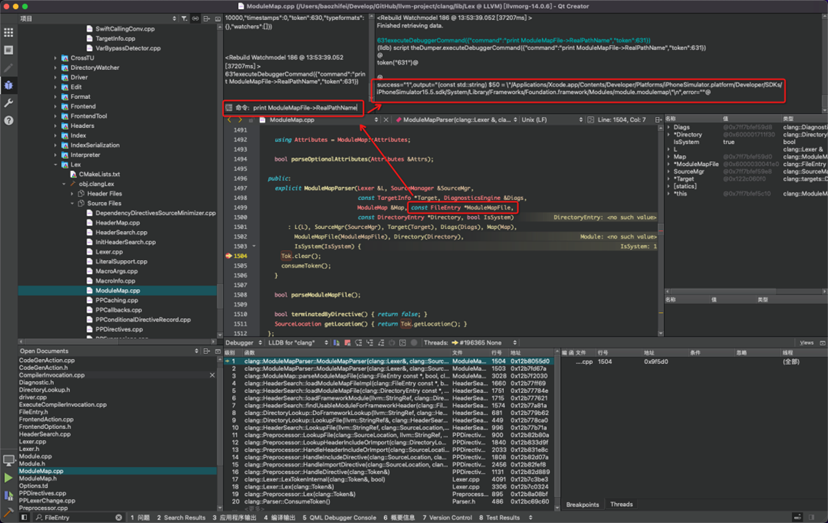
图16 从HeaderSearch中,找到module.modulemap文件
通过分析Clang模块的实现代码,大致清楚了Clang模块的实现原理,当导入一个模块头文件时,如果这个模块是Clang模块,则会直接读取其pcm缓存文件,如果没有缓存,则会开启另外一个编译器来生成pcm文件。pcm是一种多媒体音频文件,pcm文件内容就是AST文件,这样多个编译单元可以最大程度复用,减少编译时间。
3有哪些好用的代码检查工具
常用的静态代码检测工具都列在了如图17中,比如cppcheck。
使用方式在Linux上安装比较方便:
sudo apt install cppcheck
在Windows上,需要下载cppcheck的安装包:cppcheck.sourceforge.io/,也可以下载源码,注意安装成功后需要配置一下它的环境变量。

图17 静态代码检测工具
也可以使用clang-tidy来做静态代码检测,不同于cppcheck使用正则表达式进行静态代码分析,clang-tidy是基于语法分析树的静态代码检查工具,虽然它的速度比正则表达式慢一些,但是它检查的更准确、更全面,而且不仅可以做静态检查,还可以做一些修复工作,自行添加一些自定义检查规则。
这里还重点推荐下cpplint:它可以检测代码是否符合Google的编码规范,会把不符合规范的地方都找出来。
4 Clang在OC中的使用
Clang是一个C语言、C++、Objective-C、C++语言的轻量级编译器。源代码发布于BSD协议下,能在终端的环境中使用。
4.1终端用户特色
1)快速编译和较少内存占用。
2)有诊断功能。
3)兼容GCC。
4.2 Clang的简单使用
1. 编译OC
1)打开终端,使用cd Desktop跳转到桌面上。
2)使用终端命令 vim HelloWord.m来创建一个.m文件。
3)在HelloWord.m中输入如何代码。
#import <Foundation/Foundation.h>
int main(int argc, const char * argv[]) {
@autoreleasepool {
// insert code here...
NSLog(@"好世界!");
}
return 0;
}
4)在终端输入 clang -fobjc-arc -framework Foundation HelloWord.m -o nihao 命令行进行编译。
2. 指令解释
指令解释包括以下几个方面:
A. fobjc-arc 表示编译需要支持ARC特性。
B. -framework Foundation表示引用基础框架,这个框架中定义了很多基本的类,例如字符串、数组、字典等。
C. 后面的HelloWord.m就是待编译的源代码文件名。
D. -o nihao表示输出的可执行文件的文件名是nihao。
5 Clang重排对象类结构分析
5.1 简介
探索了类、元类、根源类的关系。通过属性重排,展示了对成员变量的布局优化:
在开发中,请使用运行时API,而不是指针偏移、mask等更底层的方式获取信息。因为可能对这底层逻辑进行优化,如果直接访问会有不稳定的问题,但对外提供的API是稳定的,所以推荐使用运行时API来解决遇到的问题。
5.2 类、元类、根源类
这里比较可惜的是,无法直观地看到 OBJC_METACLASS_$_NSObject 中的结构,但可以通过运行时或源码分析,已经得到了下面这张经典的图片了。根据前面的代码分析,也可以直观的验证如图18所示的大部分关系。
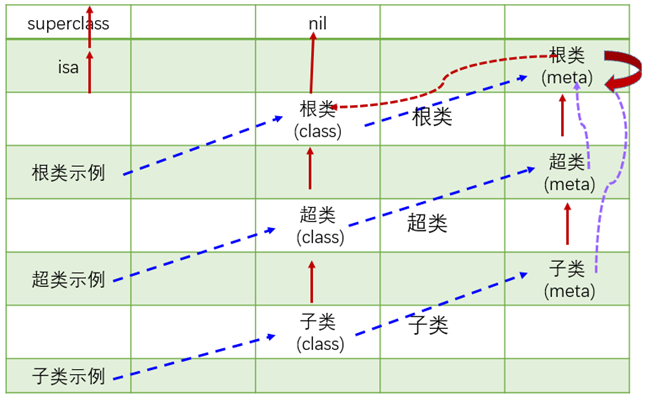
图18 类、元类、根源类的关系图
6 使用Clang编译C程序在安卓设备中执行
由于
Android NDK从R18开始就已经抛弃GCC,转而将Clang当作默认编译器,因此可以直接使用NDK工具包进行编译。1. 实验环境
1)安卓模拟器
2)安装android-ndk-r19c
2. 实验步骤
第一步,源码编写。
新建
test.c文件。#include <stdio.h>
int main()
{
printf("Hello world!\n");
return 0;
}
第二步,源码编译。
在
android-ndk-r19c目录下工具链文件夹中的llvm文件夹,即为Clang编译工具包。在
llvm的子目录bin下存放这针对各个架构的Clang编译器,由于模拟器是ARM架构,这里使用armv7a-linux-androideabi23-clang。在命令窗口执行如下指令:
armv7a-linux-androideabi23-clang test.c -o test
由于Clang已经指定了Android23版本的SDK,这里无需要像GCC那样指定
-static编译。第三步,将编译后的可执行文件传至安卓设备。
adb push test /data/
第四步,执行文件。
直接在控制台输入文件名即可执行。
./test
如果提示权限拒绝,那么使用如下所示命令:
chmod 777 test
如果C语言和汇编语言混合开发,同样也可使用Clang编译:
armv7a-linux-androideabi23-clang aaa.s test.c -o test
7 分析Swift性能高效的原因
绝大多数公司选择Swift语言开发iOS应用,主要原因是因为Swift相比Objc有更快的运行效率,更加安全的类型检测,更多现代语言的特性提升开发效率。这一系列的优点使Swift语言的热度越来越高。
自从2014年Apple发布Swift语言以来,不管是语言还是基础库都日趋稳定,目前国内外大厂也都积极拥抱Swift阵营。
绝大多数公司选择Swift语言开发iOS应用,主要原因是因为Swift相比Objc有更快的运行效率,更加安全的类型检测,更多现代语言的特性提升开发效率。这一系列的优点使Swift语言的热度越来越高。
大多数人知道Swift语言相比于Objc语言运行效率更高,但是却不知道为什么效率更高,在这里通过Swift编译层,探讨一下Swift语言高效的原因。
7.1更加高效的数据类型
在开始讨论Swift数据类型之前,先讨论一下Swift的函数派发机制。
Swift的函数派发机制包括静态派发、动态派发、消息派发(static dispatch、dynamic dispatch、message dispatch)共三个模块。
动态派发:动态派发是指编译期无法确定应该调用哪个方法,需要在运行时才能确定方法的调用。
静态派发:这是在编译期就能确定的调用方法的派发方式。
除了上面两种方式之外,在Swift里面还会使用Objc的消息派发机制;Objc采用了运行时阶段的obj_msgsend进行消息派发,所以Objc的一些动态特性在Swift里面也可以被限制使用。
静态派发相比于动态派发更快,而且静态派发还会进行内联等一些优化,减少函数的寻址及内存地址的偏移计算等一系列操作,使函数的执行速度更快,性能更高。
7.2 数据类型
内存分配可以分为堆区(Heap)和栈区(Stack)。由于栈区内存是连续的,内存的分配和销毁是通过入栈和出栈操作进行的,速度要高于堆区。堆区存储高级数据类型,在数据初始化时,查找没有使用的内存,销毁时再从内存中清除,所以堆区的数据存储不一定是连续的。
类(class)和结构体(struct)在内存分配上是不同的,基本数据类型和结构体默认分配在栈区,而像类这种高级数据类型存储在堆区,且堆区数据存储不是线程安全的,在频繁的数据读写操作时,要进行加锁操作。
在Swift文档里面能看到对结构的描述,结构体是值类型,当值类型的数据赋值给一个变量或常量,或者传递给一个函数时,使用值拷贝方法。
例如:
struct Resolution {
var width = 0
var height = 0
}
let hd = Resolution(width: 1920, height: 1080)
var cinema = hd
cinema.width = 2048
print("cinema is now \(cinema.width) pixels wide")
// Prints "cinema is now 2048 pixels wide"
print("hd is still \(hd.width) pixels wide")
// Prints "hd is still 1920 pixels wide"
struct Resolution {
var width = 0
var height = 0
}
let hd = Resolution(width: 1920, height: 1080)
var cinema = hd
cinema.width = 2048
print("cinema is now \(cinema.width) pixels wide")
// Prints "cinema is now 2048 pixels wide"
print("hd is still \(hd.width) pixels wide")
// Prints "hd is still 1920 pixels wide"
通过这个例子能清楚的看到,当hd赋值给cinema时,是将hd中存储的值拷贝给cinema,所以当给cinema的width属性赋值的时候,并不会改变hd中的属性值,如下图19所示:

图19 当给cinema的width属性赋值的时候,并不会改变hd中的属性值
结构体除了属性的存储更安全、效率更高之外,其函数的派发也更高效。由于结构体不能被继承,也就是结构体的类型被final修饰,对于动态派发及静态派发的描述,有如下所示结论:
1)其内部函数应该是属于静态派发,在编译期就确定了函数的执行方式。
2)其函数的调用通过内联(inline)的方式进行优化。
3)其内存连续,减少了函数的寻址及内存地址的偏移计算。
4)其运行相比于动态派发更加高效。
7.3 协议类型
多态是面向对象的一大特性,在结构体中不能通过继承或者引用多态语言,Swift就引入了协议(protocol),通过这些协议就实现了结构体的多态特性,这也是Swift面向协议编程的核心所在。
对于类(class)来说,每个类都会创建一个虚拟函数表指针,这个指针则指向一个虚拟表,也就是虚函数表,表内存储着该类的函数指针数组,拥有继承关系的子类会在虚函数表内通过继承顺序(C++可以实现多继承)去展示虚函数表指针。类的派发则是根据虚拟函数指针来进行派发。
而结构体(struct)没有继承,也就是说结构体并没有虚拟表用于函数的派发。为了实现这一特性,在结构体的协议的实现里,添加了协议见证表,用于管理协议类型的方法派发。
7.4 编译过程
上面介绍了一些Swift在数据结构上的一些优化,除了数据结构优化之外,Swift在编译过程也进行了大量的优化,其中最核心的优化,这是在编译过程中引入SIL。
SIL全称Swift Intermediate Language,这是为了优化Swift编译过程而设计的中间语言,主要包含了以下功能:
1)一系列的高级别优化保障,用于对运行时和诊断行为提供可预测的基线。
2)对Swift语言数据流分析强制要求,对不满足强制要求的问题产生诊断。例如,变量和结构体必须明确初始化,代码可达性即方法返回的检测,以及转换的覆盖率。
3)确保高级别优化。包含保留/释放优化,动态方法的去虚拟化,闭包内联,内存初始化提升,以及泛型方法实例化。
4)可用于分配脆弱内联的稳定分配格式,将Swift库组件的泛型优化为二进制。
7.5 Clang编译流程
Clang编译过程有以下几个缺点:
1)在代码与LLVM IR之间有巨大的抽象鸿沟。
2)IR不适合源码级别的分析。
3)CFG(Control Flow Graph)缺少精准度(CFG lacks fidelity )。
4)CFG偏离主道。
5)在CFG和IR下译中会出现重复分析。
如图20所示表示Clang的编译流程。
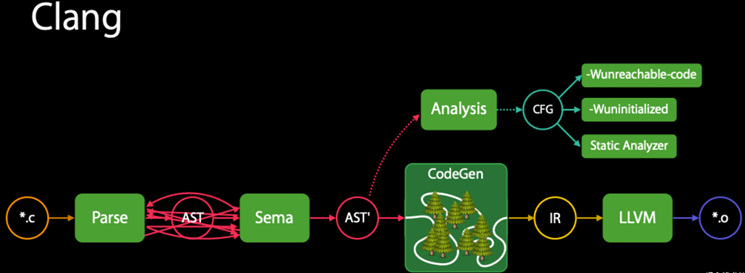
图20 Clang编译过程
由于以上这些缺点,Swift语言开发团队在开发过程中进行了一系列的优化,其中最关键的是引入SIL。
7.6 Swift编译流程
Swift作为一个安全与级别高的语言,具有以下所示特点:
1. 高级别语言
1)通过代码充分的展示语言的特性。
2)支持基于协议的泛型。
2. 安全语言
1)充分的数据流检查:未初始化变量,函数返回处理检测,这些项在检测不合格时,会产生对应的编译错误。
2)边界和溢出的检测。
Swift编译流程,如图21所示:

图21 Swift编译流程
Swift 源码到IR之间的流程,如图22所示:

图22 Swift源码到IR之间的流程
Swift 编译过程引入SIL有以下所示几个优点:
1)完全表示程序语义。
2)既能进行代码的生成,又能进行代码分析。
3)处在编译管线的主通道。
4)构建连接源码与LLVM的桥梁,减少源码与LLVM之间的抽象鸿沟。
3. Swift编译器的流程
Swift编译器作为高级编译器,具有以下严格的传递流程结构。
Swift编译器的流程如下:
1)语法分析组件从Swift源码生成AST。
2)语义分析组件对AST进行类型检查,并对其进行类型信息注释。
3)SILGen组件从AST形成原始的Swift中间语言。
4)在一系列Swift中间语言上运行,用于确定优化和诊断合格,对不合格的代码嵌入特定的语言诊断。这些操作一定会执行,即使在-Onone选项下也不例外。之后会产生可靠的Swift中间语言。
5)运行Swift中间语言优化是可选的,这个检测可以提升可执行结果文件的性能,可以通过优化级别来控制,在-Onone模式下不会执行。
6)IRGen会将Swift中间语言降级为LLVM IR。
7)LLVM后端提供LLVM优化,执行LLVM代码生成器,并产生二进制码。
在上面的流程中,Swift中间语言对编译过程进行了一系列的优化。既保证了代码执行的安全性,又提升了代码执行的效率。