1. DBSCAN
Density based clustering
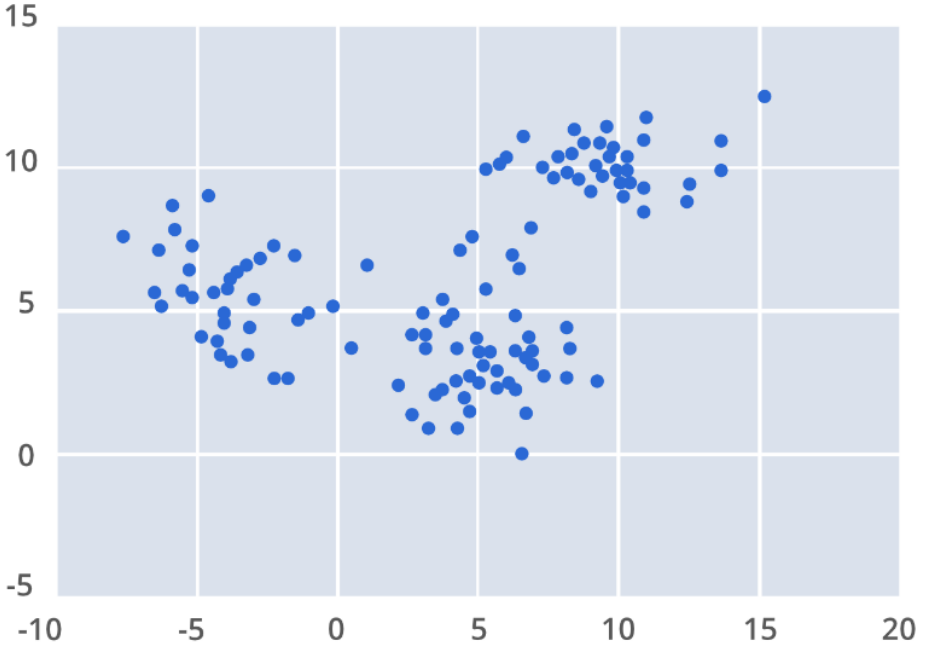
DBSCAN不要求我们指定cluster簇的数量,避免了异常值,并且在任意形状和大小的cluster簇中工作得非常好。它没有质心,聚类簇是通过将相邻的点连接在一起的过程形成的。
超参数:
Epsilon (ɛ):设置的最大半径。
最小点数目(minPts):在一个邻域的半径内minPts数的邻域被认为是一个簇。请记住,初始点包含在minPts中。
核心点:在其近邻距离内至少有minPts个数据点。
对核心点的邻域内的每个点进行评估,以确定它是否在epsilon距离内有minPts (minPts包括点本身)。如果该点满足minPts标准,它将成为另一个核心点,cluster簇将扩展。如果一个点不满足minPts标准,它成为边界点。
离群点:这些点不是近邻点,也不是边界点。这些点位于低密度地区。
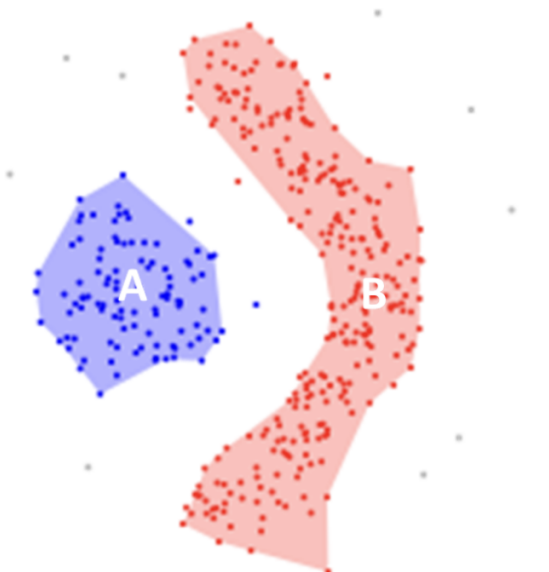
2. OPTICS
Ordering Points To Identify Cluster Structure
目标是识别聚类的内部结构
这个算法本身核心并不直接划分数据到不同的聚类簇。它仅生成一个关于可达距离(纵轴)图形,然后再去读取这个图形做进一步的 聚类。这个图形本质上记录了数据点被处理的顺序(横轴),而
不是数据点的具体划分。这是与DBSCAN最大的不同。
可达距离图:
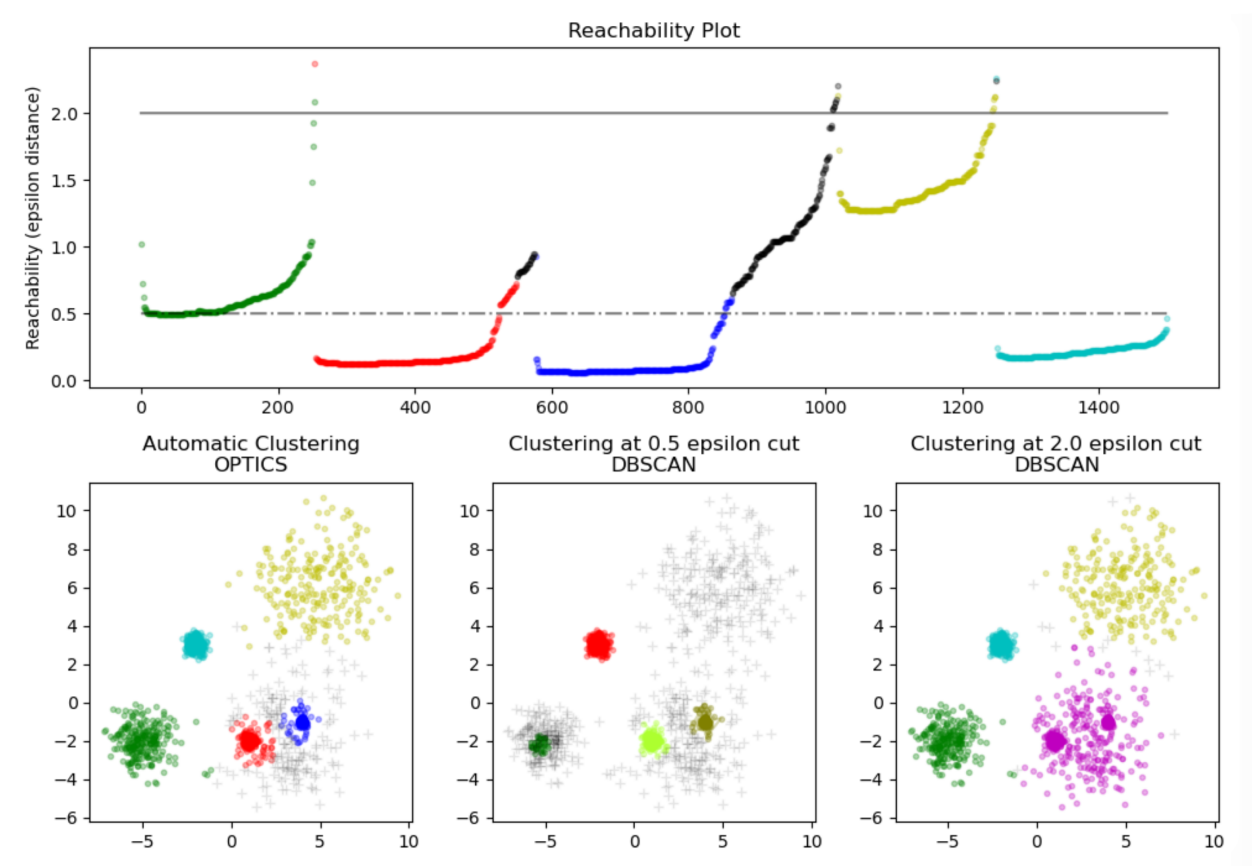
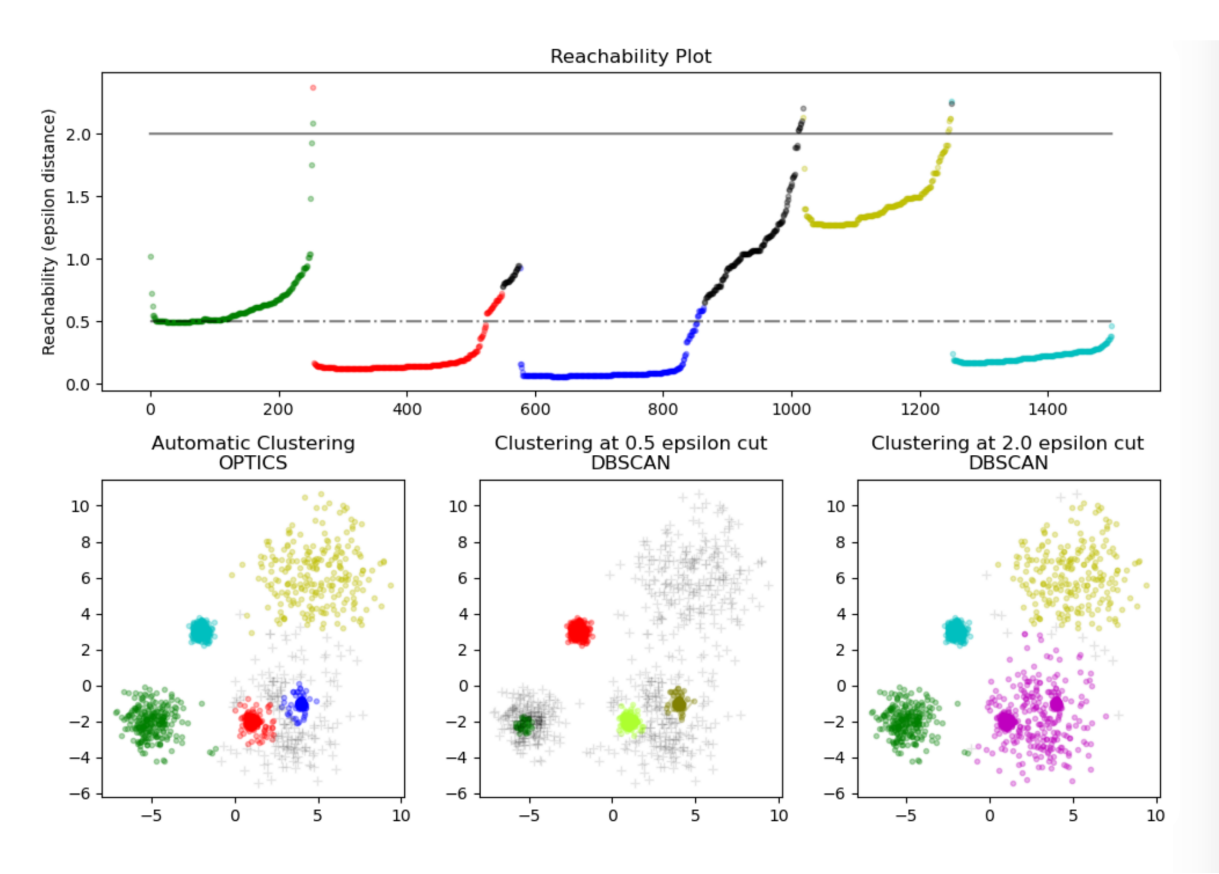
在DBCSAN算法中需要输入两个参数:epsilon和minPts ,选择不同的参数会导致最终聚类的结果千差万别,因此DBCSAN对于输入参数过于敏感。OPTICS算法的提出就是为了帮助DBSCAN算法选择合适的参数,降低输入参数的敏感度。
两个重要的概念:
核心距离:是确定一个给定点是核心点的半径最小值。如果给定点不是一个核心点,那么它的核心距离是 无穷大。
可达距离:
定义相对其它数据点q。点p和q之间的可达距离是p点的核心距离与p和q之间的欧氏距离的最大值 max(core_dist(p), eula(p, q))
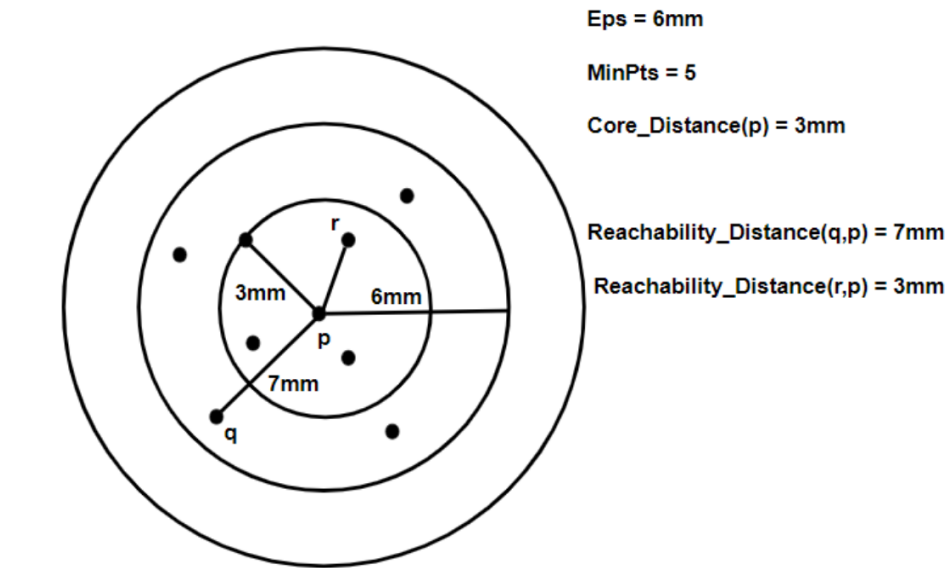
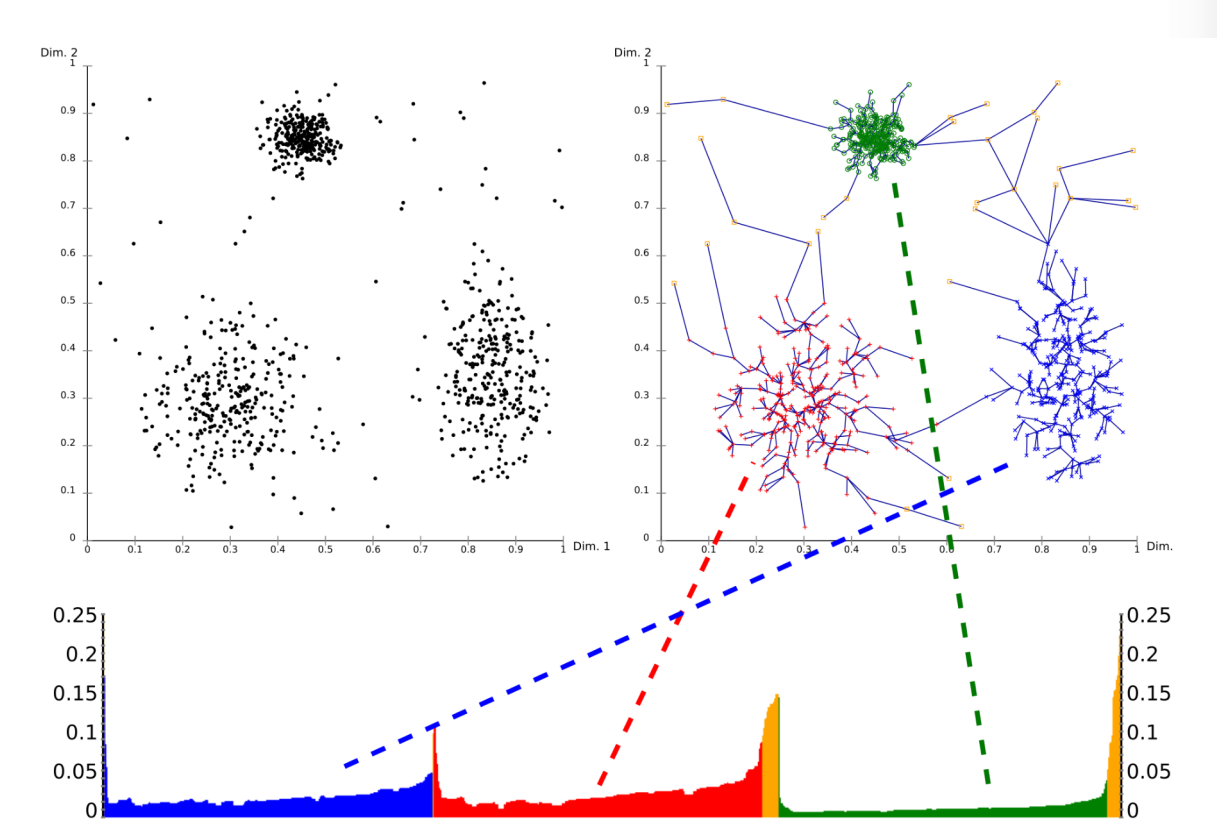
仔细品味这两张 可达距离 云图
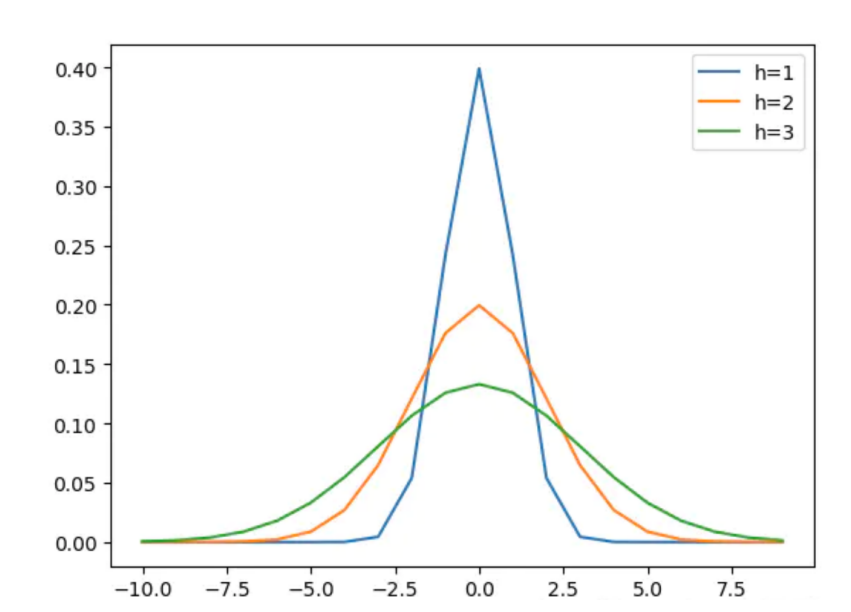
2. MeanShift
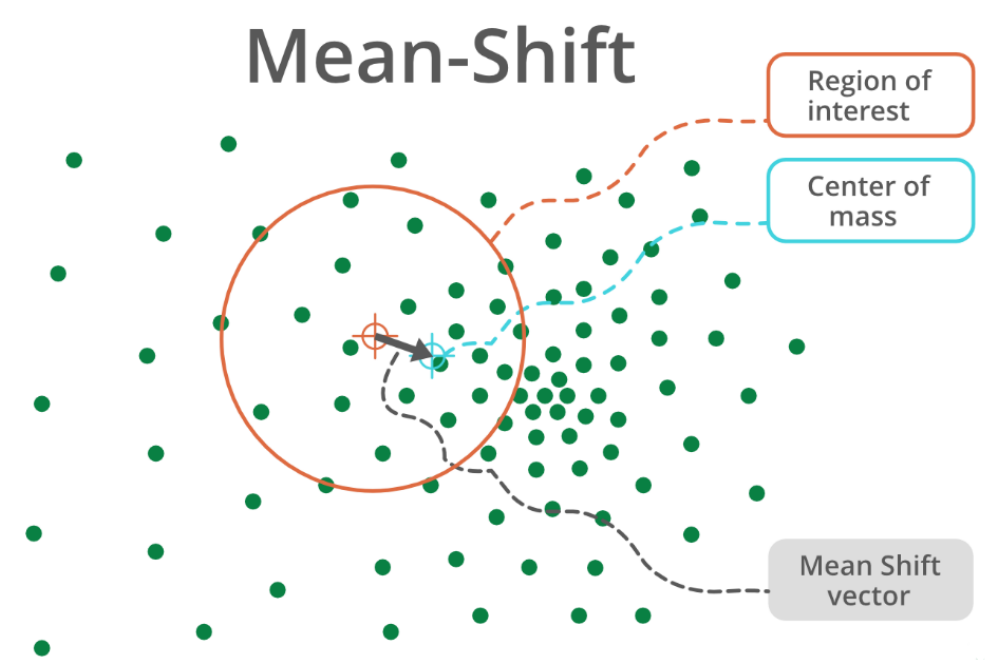
均值漂移, 在目标追踪中应用广泛。本身其实是一种基于密度的聚类算法。
计算某一点A与其周围半径R内的向量距离的平均值M,计算出该点下一步漂移(移动)的方向(A=M+A)
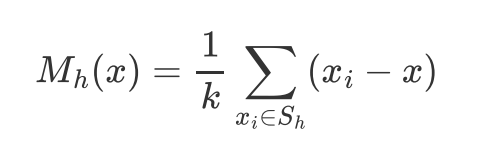
MeanShift向量表示区域中k个样本点相对于点x求偏移量再平均,求出来的向量指向概率密度梯度的方向(指向真实质心方向)。
MeanShift的扩展:
不同的簇包含的数据看成是正太分布采样得到的。