apple的m1芯片比以往cpu芯片在机器学习加速上听说有15倍的提升,也就是可以使用apple mac训练深度学习pytorch模型!!!惊呆了
安装apple m1芯片版本的pytorch
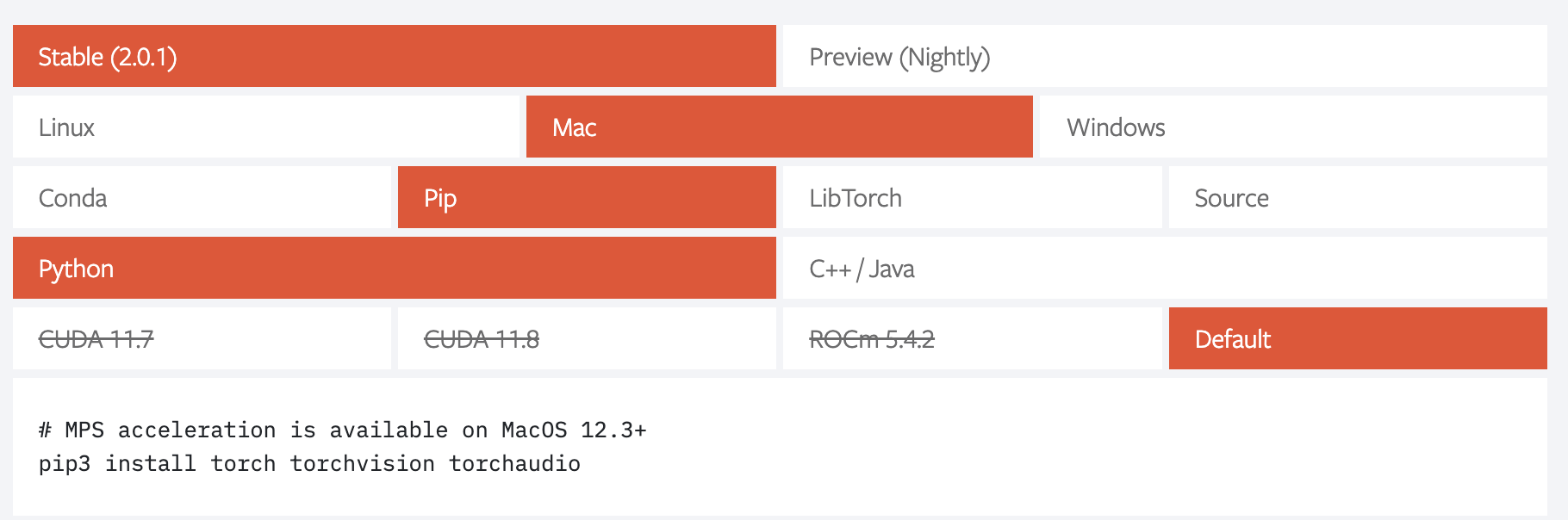
然后使用chatGPT生成一个resnet101的训练代码,这里注意,如果网络特别轻的话是没有加速效果的,还没有cpu的计算来的快
这里要选择好设备不是"cuda"了,cuda是nvidia深度学习加速的配置
# 设置设备
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device = torch.device("mps") #torch.device("cpu")
resnet101的训练代码,训练mnist手写数字识别,之前我还尝试了两层linear的训练代码,低估了apple 的 torch.device("mps"),这两层linear的简单神经网络完全加速不起来,还不如torch.device("cpu")快,换成了resnet101加速效果就很明显了,目测速度在mps上比cpu快了5倍左右
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
from torchvision.models import resnet101
from tqdm import tqdm
# 设置设备
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device = torch.device("mps") #torch.device("cpu")
# 加载 MNIST 数据集
train_dataset = MNIST(root="/Users/xinyuuliu/Desktop/test_python/", train=True, transform=ToTensor(), download=True)
test_dataset = MNIST(root="/Users/xinyuuliu/Desktop/test_python/", train=False, transform=ToTensor())
# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# 定义 ResNet-101 模型
model = resnet101(pretrained=False)
model.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)
model.fc = nn.Linear(2048, 10) # 替换最后一层全连接层
model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练和评估函数
def train(model, dataloader, optimizer, criterion):
model.train()
running_loss = 0.0
for inputs, labels in tqdm(dataloader, desc="Training"):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
epoch_loss = running_loss / len(dataloader.dataset)
return epoch_loss
def evaluate(model, dataloader):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in tqdm(dataloader, desc="Evaluating"):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total * 100
return accuracy
# 训练和评估
num_epochs = 10
for epoch in range(num_epochs):
print(f"Epoch {epoch+1}/{num_epochs}")
train_loss = train(model, train_loader, optimizer, criterion)
print(f"Training Loss: {train_loss:.4f}")
test_acc = evaluate(model, test_loader)
print(f"Test Accuracy: {test_acc:.2f}%")
结果:
在mps device上,训练时间在10分钟左右

在cpu device上,训练时间在50分钟左右,明显在mps device上速度快了5倍
