摘要:普遍认为,优秀的深度神经网络离不开数千个标注训练样本。在本文中,我们提出了一种网络和训练策略:该策略通过使用大量数据增强,从而充分利用带标注的训练样本;该网络结构包括了用于捕获上下文的收缩路径和用于实现精确定位的对称扩展路径。我们通过实验结果表明:这种网络能够在很少的图像数据集上进行端到端的训练,并且在“ISBI挑战赛:分割电子显微镜堆栈中的神经结构”表现更优于先前的最佳方案(滑动窗口神经网络)。我们使用了同一个经过训练的网络,针对透射光显微镜图像(相衬显微镜和差示干涉对比显微镜),在2015年ISBI细胞追踪挑战赛中,以较大优势取得了胜利。此外网络计算速度很快,在最新的GPU上分割512x512的图像,耗时不到一秒。完整实现(基于Caffe)和完成训练的网络可通过https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/获取。
1 介绍
在过去两年中,深度卷积网络在许多视觉识别任务中的表现都优于现有技术,如文献[7,3]。虽然卷积网络已经发展了很长一段时间[8],但受限于可用训练集的大小和采用的网络深度,取得的优势很有限。Krizhevsky[7]等人打破了惯例:他们在具有100万训练图像的ImageNet数据集上对具有8层和数百万参数的大型网络进行监督训练。从那时起,网络训练向着更大更深方向发展。
卷积网络常用于分类任务,其中对于图像的输出是单个类别标签。然而,在许多视觉任务中,特别是生物医学图像处理中,所需的输出应该还包括定位,即为每个像素分配一个类别标签。此外,在生物医学任务中很难获取大量的训练图像。因此Ciresan等人[1]在滑动窗口设置中训练一个网络,通过提供该像素周围的局部区域(补丁)作为输入来预测每个像素的类别标签。首先,这个网络可以定位;其次,以块为单位的训练数据数量远大于图像。最后,该网络以压倒性优势赢得了2012年ISBI的EM分割挑战赛。
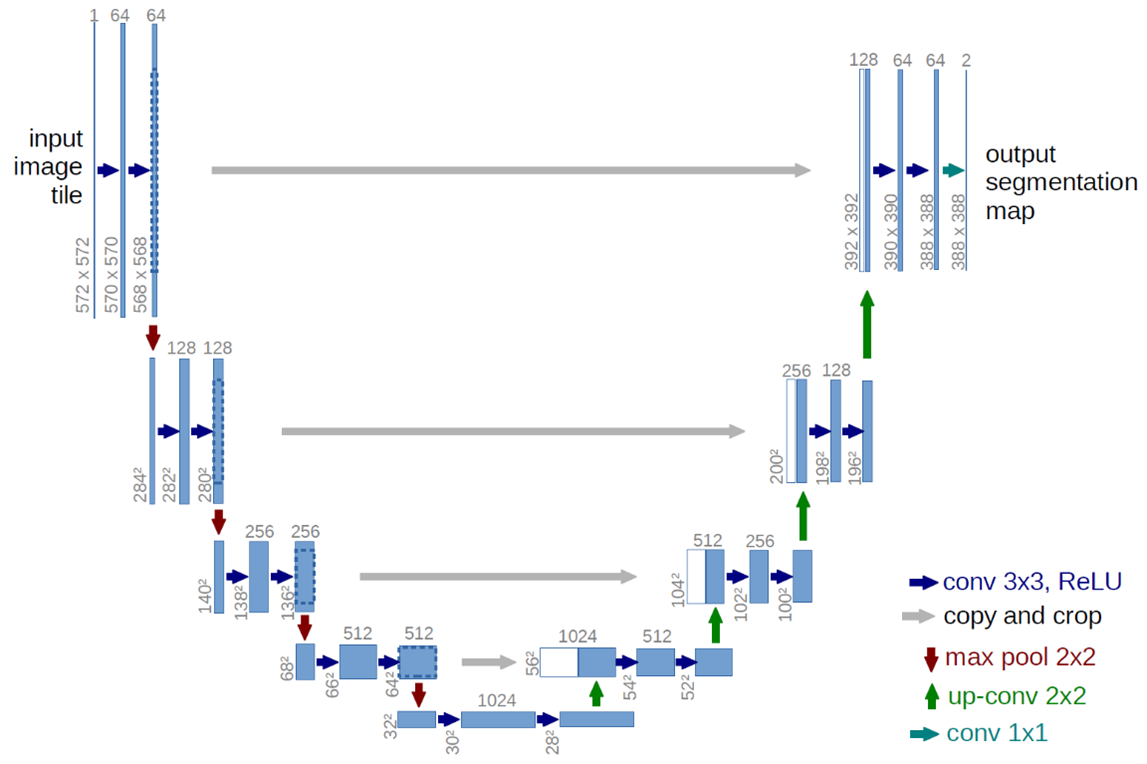
图1 U-Net架构(以最低分辨率下的32x32像素为例)。每一个蓝色框对应一个多通道特征图。通道数位于框的顶部。图像x与y的大小位于框的左下。白框表示复制的特征图。箭头表示不同操作。
显而易见,Ciresan等人的策略[1]有两个缺点:1、训练慢,因为网络必须为每个补丁单独运行,并且由于补丁重叠而存在大量冗余;2、需要权衡定位精度和上下文的使用,较大的补丁需要更多的池化层,这会降低定位精度,而小的补丁只被允许在网络上看到很少的上下文。最新的研究[11,4]提出了一种考虑多层特征的分类器输出,可以同时进行优秀的定位和上下文使用
在本文,我们将基于一个更优雅的架构,即所谓的“全卷积网络”[9]。我们修改并扩展该架构,使其适用于极少的训练图像并产生更精确的分割,如图1所示。文献[9]的主要思想是通过连续的层补充一般的收缩网络,其中池化操作被上采样操作替代,因此,这些层会增加输出的分辨率。为了实现定位,来自收缩路径的高分辨率特征与上采样输出相结合,然后,连续的卷积层可以学习并集成更精确的输出。
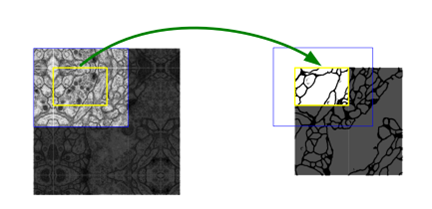
图2 任意大小图像无缝分割的重叠平铺策略(此处为EM堆栈中神经结构的分割)。对黄色区域的分割预测需要蓝色区域内的图像数据作为输入,此外丢失的输入数据可通过镜像外推弥补。
上采样部分以及大量的特征通道是我们架构的重要修改,这允许网络将上下文信息传播到更高分辨率的层。因此,扩展路径总是与收缩路径对称,并形成了一个“U”形结构。该网络不含全连接层,仅使用每个卷积的有效部分,即分割图仅包含在输入图像中具有完整上下文的像素。该策略允许通过重叠平铺策略对任意大小的图像进行无缝分割(如图2)。为了预测图像边界区域的像素,可以通过对输入图像进行镜像操作,来推断缺失的上下文。这种平铺策略网络在处理大图像时非常重要,否则分辨率将受到GPU存储的限制。
对于我们的任务,可用的训练数据非常少,因此我们对训练图像使用弹性形变进行大量数据增强。这样可以使网络学习这种变形不变性,而不需要在带注释的图像语料库中额外添加。这在生物医学分割中尤为重要,因为变形是最常见的组织变化,而这样做可以有效地模拟真实情况。在无监督特征学习领域,Dosovitskiy等人[2]已经证实了数据增强对于该学习的用途。
许多细胞分割任务的另一个难题是同一类别的接触对象的分离,如图3所示。为此,我们使用加权损失,其中在损失函数中,细胞接触之间的分离背景标签获得更大的权重。
该网络适用于各种生物医学分割问题。在本文中,我们展示了EM堆栈(自2012年ISBI组织的一场持续进行的竞赛)中神经元结构分割的结果,我们的表现优于Ciresan等人[1]的网络。此外,我们还展示了2015年ISBI细胞跟踪挑战的光学显微图像的细胞分割结果。我们在这两个最具挑战性的2D透射光数据集上,均以巨大优势获胜。
2 网络架构
网络架构如图1所示,它由收缩路径(左侧)和扩展路径(右侧)组成。收缩路径遵循卷积网络的典型架构。它由两个反复应用的3x3卷积(无填充卷积)组成,每个卷积后跟一个整流线性单元(ReLU)和一个2x2的最大池化操作,步长为2,用于下采样。在每个下采样步骤中,我们将特征通道的数量加倍。扩展路径中的每一步都包括特征图的上采样,然后是将特征通道数减半的2x2卷积(“上卷积”)与来自收缩路径的对应裁剪特征图的连接,以及两个3x3卷积,其中每个卷积后有一个ReLU。由于每次卷积都会丢失边界像素,因此裁剪是必要的。在最后一层,使用1x1卷积将每个64维特征向量映射到所需的类别数量。网络总共有23个卷积层。
为了实现输出分割图的无缝拼接(参见图2),输入分块大小的选择非常重要,需要确保所有2x2最大池化操作都应用于偶数大小的x和y尺寸的层。
3 训练
使用输入图像及其相应的分割图和Caffe[6]的随机梯度下降来训练网络。由于未填充卷积,输出图像较输入图像小一个固定的边界宽度。为了最大限度地减少开销并最大化利用GPU存储,我们选择使用较大的batch size,而不是一个batch size仅含单个图片。因此,我们使用高动量(0.99),以便先行观察大量的训练样本,再更新当前的优化步骤。
能量函数通过对最终特征图进行像素级的soft-max计算,并与交叉熵函数结合计算。Soft-max函数定义为:\(p_x(x)=\exp\left(a_k(x)\right)/\left(\sum^{K}_{k'}\exp(a_{k'}(x))\right)\),其中\(a_k (x)\)表示在像素位置\(x\in\Omega\)处的特征通道k的激活值,此外,\(\Omega\subset Z^2\)。\(K\)是类别数,\(p_k(x)\)是近似最大函数,即对于具有最大激活值的k,\(p_k(x)≈1\);而对于其他所有的\(k\),\(p_k(x)≈0\)。交叉熵损失函数在每个位置上惩罚\(p_{\ell(x)}(x)\)与\(1\)之间的偏差,使用:
其中,\(\ell:\Omega\rightarrow{1,\cdots,K}\)是每个像素的真实标签,\(\omega:\Omega\rightarrow R\)是我们引入的权重图,以便在训练中突出一些像素的重要性。
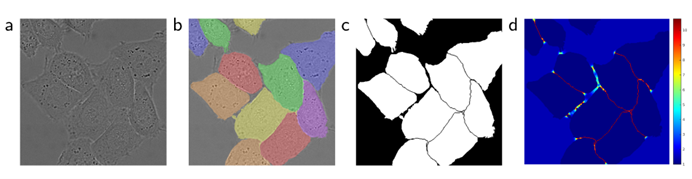
图3 DIC(微分干涉对比)显微镜记录下的玻璃上的HeLa细胞:(a)原始图像;(b)与真实分割结果的叠加显示,不同的颜色表示HeLa细胞的不同实例;(c)生成的分割掩膜(白色:前景;黑色:背景);(d)使用像素级别的损失权重映射,以迫使网络学习边界像素。
我们预先计算了每个真实分割的权重映射,以补偿训练数据集中某个类别中的像素的不同频率,并迫使网络学习我们在相邻细胞之间引入的小分隔边界(参见图3中的c和d)。使用形态学运算计算分离边界,然后将权重图计算为:
其中,\(\omega_c: \Omega \rightarrow \mathbb{R}\)是平衡类别频率的权重图;\(d_1: \Omega \rightarrow \mathbb{R}\)表示到最近细胞边界的距离;\(d_2: \Omega \rightarrow \mathbb{R}\)表示到第二近细胞边界的距离。在我们的实验中,设置\(\omega_0=10\)和\(\sigma≈5\)。
在具有许多卷积层和不同网络路径的深度网络中,良好的权重初始化非常重要。否则网络的某些部分可能会产生过多的激活结果,而其他部分不会贡献任何内容。理想情况下,应调整初始权重,使网络中的每个特征图都具有相近的单位方差。对于类似我们架构(交替卷积和ReLU层)的网络,可通过从标准差为\(\sqrt{2/N}\)的高斯分布中提取初始权重来实现,其中N表示一个神经元的传入节点数[5]。例如,对于3x3卷积和前一层的64个特征通道,\(N=9\cdot64 = 576\)。
3.1 数据增强
当训练样本较少时,数据增强对于提高网络的稳定性和健壮性至关重要。以显微镜的图像为例,我们要求网络对于图像的平移、旋转、变形以及灰度值变化的处理保持健壮性。特别是在标注图像较少,随机弹性变形的训练样本更可能是训练分割网络的关键要素。我们在粗糙的3x3网格上使用随机位移矢量生成平滑变形。位移距离由标准差为10像素的高斯分布中采样获得。然后使用双三次插值计算每个像素的位移。在收缩路径的最后使用Dropout层进一步进行隐式数据增强。
4 实验
我们演示了u-net在三种不同分割任务中的应用。第一项任务是分割电子显微镜记录的神经元结构。图2是数据集和我们分割结果的样例,我们提交了完整的结果作为补充材料。该数据集由EM分割挑战赛[14]提供,该挑战赛始于2012年的ISBI ,目前仍能向其提供数据。训练数据是透射电子显微镜下的30张图像(512x512像素)的集合,来自果蝇一龄幼虫腹神经索(VNC)的连续切片。每张图像都带有相应的完整注释细胞(白色)和细胞膜(黑色)真实分割图。测试集是公开可用的,但相应的分割图保密,可通过将预测的膜的概率图发送给组织者来获得评估,评估方式是通过在10个不同的阈值水平上进行阈值处理,并计算“变形误差”、“随机误差”和“像素误差”[14]。
网络u-net(对输入数据的7个旋转版本进行平均计算)在没有任何进一步预处理或后处理的情况下实现了0.0003529的变形误差(新的最佳分数,参见表1)和0.0382的随机误差。
结果明显优于Ciresan等人的滑动窗口卷积网络结果[1]:变形误差为0.000420,随机误差为0.0504。就随机误差而言,在该数据集上,唯一表现更好的算法是基于Ciresan等人的概率图[1]并针对数据集使用了特定后处理方法。
表1 EM分割挑战排名[14](2015年3月6日),按变形误差排序
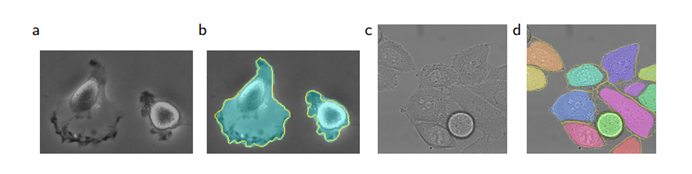
图4 ISBI细胞追踪挑战的结果:(a)部分“PhC-U373”数据集输入图像;(b)分割结果(青色掩膜)与手动标注的真值(黄色边框);(c)“DIC-HeLa”数据集的输入图像;(d)分割结果(随机彩色掩膜)与手动标注的真值(黄色边框)。
表2 2015年ISBI细胞追踪挑战赛分割结果(IOU)
我们还将u-net应用于光学显微镜图像中的细胞分割任务。此分割任务是2014年和2015年ISBI细胞追踪挑战[10,13]的一部分。第一个数据集“PhC-U373”2包含了通过相衬显微镜记录在聚丙烯酰胺基质上的胶质细胞瘤-星形细胞瘤U373细胞(参见图4 a、b和补充材料)。它包含35个部分注释的训练图像。在该数据集,我们实现了92%的平均交并集(IOU),明显优于排名第二的算法。第二个数据集“DIC-HeLa”3是通过微分干涉对比(DIC)显微镜记录的平板玻璃上的HeLa细胞(参见图3、图4c、d和补充材料),该数据集包含20个部分注释的训练图像。在该数据集,我们实现了77.5%的平均IOU,明显优于排名第二的算法46%。
5 结论
该u-net架构在不同的生物医学分割应用取得了非常好的性能。通过使用弹性变形的数据集增强方法,只需要很少的标注图像,并且在NVidia Titan GPU (6 GB)上仅需10小时的训练时间就能取得理想的训练效果。我们提供了完整的基于Caffe[6]实现和完成训练的网络4。我们确信u-net架构可以轻松地应用于更多的任务。
致谢
这项研究得到了德国联邦和州政府卓越计划(EXC 294)和BMBF (Fkz 0316185B)的支持。