(一)选题背景:
农业机器人已应用于作物播种、监测、杂草控制、害虫管理和收获等农业领域。对不同生长阶段的花、果进行人工估产,劳动密集,花费高。遥感技术为作物产量预测提供了准确可靠的依据。利用计算机视觉和深度学习模型进行自动化图像分析可以提供更精确的产量估算。番茄是典型的呼吸跃变型果实,在果实成熟过程中会出现乙烯高峰,极易促进果实的成熟,不耐贮藏,影响其采后营养价值和经济效益。 果实成熟后,极易腐烂变质,造成大量的损失。因此设计一种算法对测试集中的生番茄和熟番茄图片进行判别。
(二)机器学习设计案例:
从网站中下载相关的数据集,对数据集进行整理,在python的环境中,给数据集中的文件打上标签,对数据进行预处理,利用keras--gpu和tensorflow,通过构建输入层,隐藏层,输出层建立训练模型,导入图片测试模型。
数据集来源:kaggle,网址:https://www.kaggle.com/
(三)机器学习的实现步骤:
1.下载数据集:
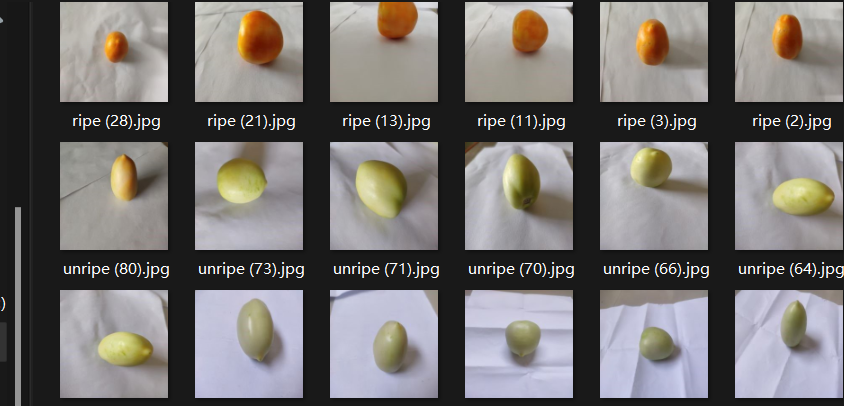
2.导入所需库
import matplotlib.pyplot as plt
import os
import shutil
from tensorflow.keras.layers import Conv2D, MaxPool2D, Dense, Flatten, Dropout
from tensorflow.keras.models import Sequential, Model
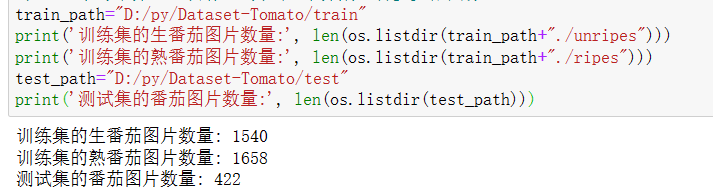
train_path="D:/py/Dataset-Tomato/train"
print('训练集的生番茄图片数量:', len(os.listdir(train_path+"./unripes")))
print('训练集的熟番茄图片数量:', len(os.listdir(train_path+"./ripes")))
test_path="D:/py/Dataset-Tomato/test"
print('测试集的番茄图片数量:', len(os.listdir(test_path)))
4.构建神经网络
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
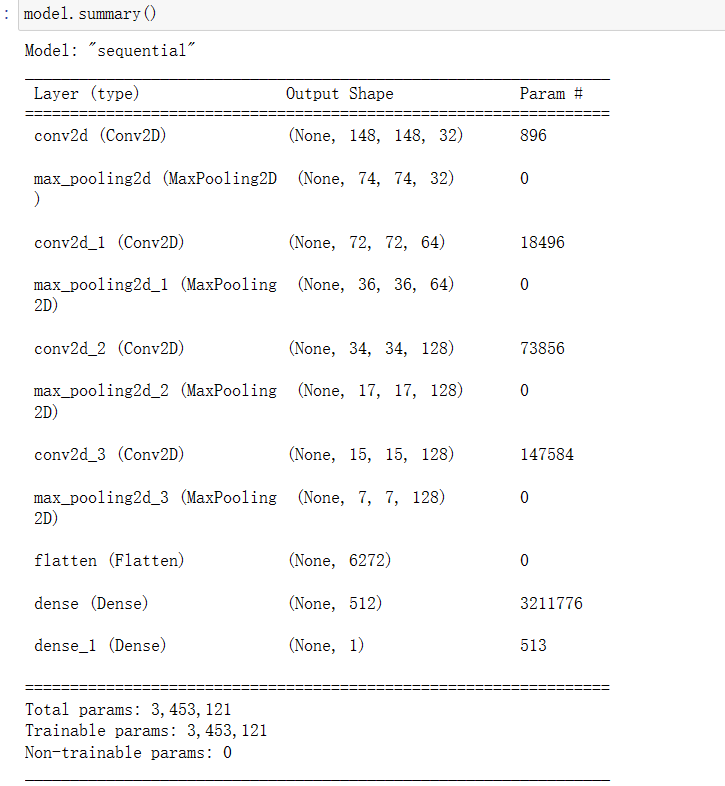
5.目前卷积神经网络的架构如下所示:
6.编译模型
from keras import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
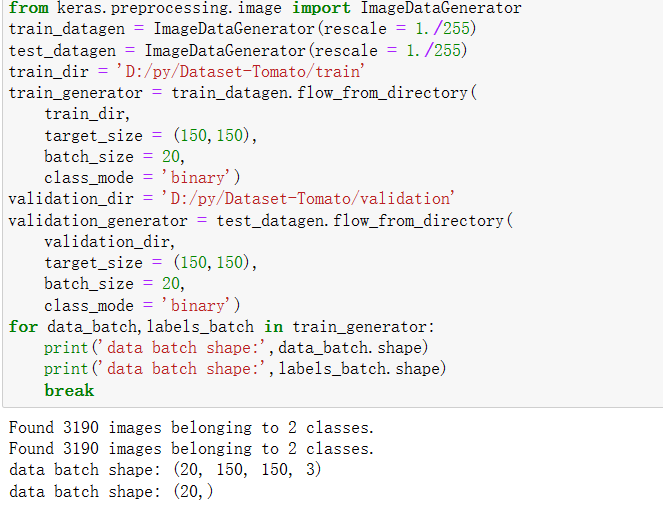
7.图像在输入神经网络之前进行数据处理,建立训练和验证数据
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale = 1./255)
test_datagen = ImageDataGenerator(rescale = 1./255)
train_dir = 'D:/py/Dataset-Tomato/train'
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size = (150,150),
batch_size = 20,
class_mode = 'binary')
validation_dir = 'D:/py/Dataset-Tomato/validation'
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size = (150,150),
batch_size = 20,
class_mode = 'binary')
for data_batch,labels_batch in train_generator:
print('data batch shape:',data_batch.shape)
print('data batch shape:',labels_batch.shape)
break
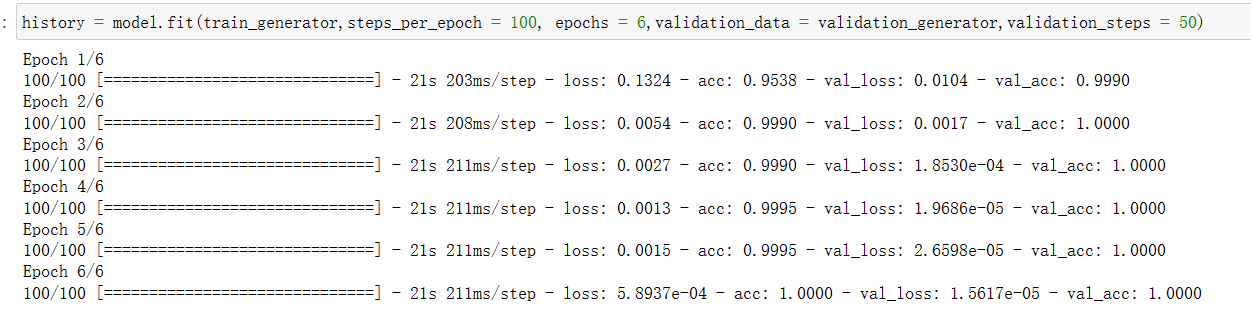
8.训练模型6轮次并将其保存
history = model.fit(
train_generator,
steps_per_epoch = 100,
epochs = 6,
validation_data = validation_generator,
validation_steps = 50)
9.绘制损失曲线
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(['loss','Val'], loc = 'upper right')

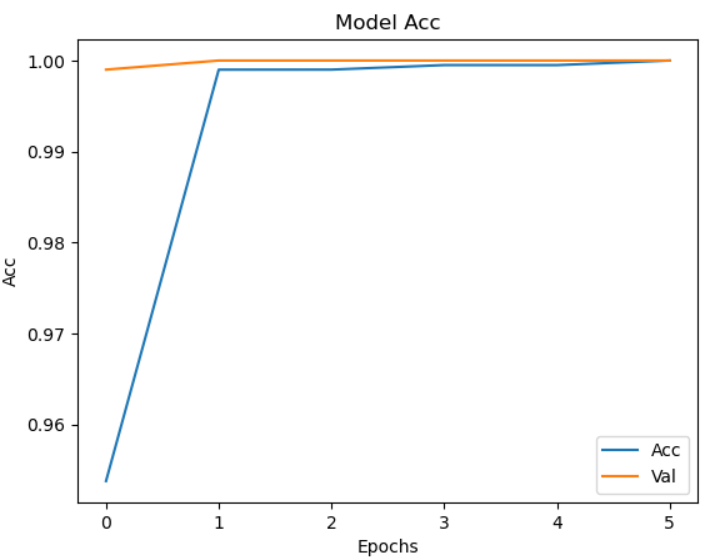
10.绘制精度曲线图
import matplotlib.pyplot as plt
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('Model Acc')
plt.xlabel('Epochs')
plt.ylabel('Acc')
plt.legend(['Acc','Val'], loc = 'lower right')
11.将训练过程产生的数据保存为h5文件
from keras.models import load_model
model.save('D:/py/Dataset-Tomato/ripes_and_unripes_6epoch.h5')

12.选择一张图片,将图片缩小到(150,150)的大小
import matplotlib.pyplot as plt
from PIL import Image
import os.path
def convertjpg(jpgfile,outdir,width=150,height=150):
img=Image.open(jpgfile)
try:
new_img=img.resize((width,height),Image.BILINEAR)
new_img.save(os.path.join(outdir,os.path.basename(new_file)))
except Exception as e:
print(e)
jpgfile="D:/py/Dataset-Tomato/unripe (6).jpg"
new_file="D:/py/Dataset-Tomato/unripe (6).jpg"
convertjpg(jpgfile,r"D:/py/Dataset-Tomato")
img_scale = plt.imread('D:/py/Dataset-Tomato/unripe (6).jpg')
plt.imshow(img_scale)

13.辨别该图片
from keras.models import load_model
model = load_model('D:/py/Dataset-Tomato/ripes_and_unripes_6epoch.h5')
#model.summary()
img_scale = plt.imread("D:/py/Dataset-Tomato/unripe (6).jpg)
img_scale = img_scale.reshape(1,150,150,3).astype('float32')
img_scale = img_scale/255
result = model.predict(img_scale)
img_scale = plt.imread('D:/py/Dataset-Tomato/unripe (6).jpg')
plt.imshow(img_scale)
if result>0.5:
print('该图片是生西红柿的概率为:',result)
else:
print('该图片是熟西红柿的概率为:',1-result)

14.随机选择一张图片进行更改以及预测
import matplotlib.pyplot as plt
from PIL import Image
import os.path
def convertjpg(jpgfile,outdir,width=150,height=150):
img=Image.open(jpgfile)
try:
new_img=img.resize((width,height),Image.BILINEAR)
new_img.save(os.path.join(outdir,os.path.basename(new_file)))
except Exception as e:
print(e)
jpgfile="D:/py/Dataset-Tomato/ripe (41).jpg"
new_file="D:/py/Dataset-Tomato/ripe (41).jpg"
convertjpg(jpgfile,r"D:/py/Dataset-Tomato")
img_scale = plt.imread('D:/py/Dataset-Tomato/ripe (41).jpg')
plt.imshow(img_scale)

from keras.models import load_model
model = load_model('D:/py/Dataset-Tomato/ripes_and_unripes_6epoch.h5')
#model.summary()
img_scale = plt.imread("D:/py/Dataset-Tomato/ripe (41).jpg")
img_scale = img_scale.reshape(1,150,150,3).astype('float32')
img_scale = img_scale/255
result = model.predict(img_scale)
img_scale = plt.imread('D:/py/Dataset-Tomato/ripe (41).jpg')
plt.imshow(img_scale)
if result>0.5:
print('该图片是生西红柿的概率为:',result)
else:
print('该图片是熟西红柿的概率为:',1-result)

(四)总结:
收获:大数据的核心是利用数据的价值,机器学习是利用数据价值的关键技术,对于大数据而言,机器学习是不可或缺的。相反,对于机器学习而言,越多的数据会越 可能提升模型的精确性,同时,复杂的机器学习算法的计算时间也迫切需要分布式计算与内存计算这样的关键技术。因此,机器学习的兴盛也离不开大数据的帮助。 大数据与机器学习两者是互相促进,相依相存的关系。此次的设计,让我对机器学习的掌握更进一步。
缺点:这次的数据集太过于类似,导致过于容易识别,较少次数即可达到非常高的精确度,识别的类型也较少有望改进。
(五)全代码:
import numpy as np
import pandas as pd
import os
import numpy as np
import matplotlib.pyplot as plt
import os
import shutil
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, MaxPool2D, Dense, Flatten, Dropout
from tensorflow.keras.models import Sequential, Model
train_path="D:/py/Dataset-Tomato/train"
print('训练集的生番茄图片数量:', len(os.listdir(train_path+"./unripes")))
print('训练集的熟番茄图片数量:', len(os.listdir(train_path+"./ripes")))
test_path="D:/py/Dataset-Tomato/test"
print('测试集的番茄图片数量:', len(os.listdir(test_path)))
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()
from keras import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale = 1./255)
test_datagen = ImageDataGenerator(rescale = 1./255)
train_dir = 'D:/py/Dataset-Tomato/train'
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size = (150,150),
batch_size = 20,
class_mode = 'binary')
validation_dir = 'D:/py/Dataset-Tomato/validation'
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size = (150,150),
batch_size = 20,
class_mode = 'binary')
for data_batch,labels_batch in train_generator:
print('data batch shape:',data_batch.shape)
print('data batch shape:',labels_batch.shape)
break
history = model.fit(
train_generator,
steps_per_epoch = 100,
epochs = 6,
validation_data = validation_generator,
validation_steps = 50)
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(['loss','Val'], loc = 'upper right')
import matplotlib.pyplot as plt
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('Model Acc')
plt.xlabel('Epochs')
plt.ylabel('Acc')
plt.legend(['Acc','Val'], loc = 'lower right')
from keras.models import load_model
model.save('D:/py/Dataset-Tomato/ripes_and_unripes_6epoch.h5')
import matplotlib.pyplot as plt
from PIL import Image
import os.path
def convertjpg(jpgfile,outdir,width=150,height=150):
img=Image.open(jpgfile)
try:
new_img=img.resize((width,height),Image.BILINEAR)
new_img.save(os.path.join(outdir,os.path.basename(new_file)))
except Exception as e:
print(e)
jpgfile="D:/py/Dataset-Tomato/unripe (6).jfif"
new_file="D:/py/Dataset-Tomato/unripe (6).jfif"
convertjpg(jpgfile,r"D:/py/Dataset-Tomato")
img_scale = plt.imread('D:/py/Dataset-Tomato/unripe (6).jfif')
plt.imshow(img_scale)
from keras.models import load_model
model = load_model('D:/py/Dataset-Tomato/ripes_and_unripes_6epoch.h5')
#model.summary()
img_scale = plt.imread("D:/py/Dataset-Tomato/unripe (6).jfif")
img_scale = img_scale.reshape(1,150,150,3).astype('float32')
img_scale = img_scale/255
result = model.predict(img_scale)
img_scale = plt.imread('D:/py/Dataset-Tomato/unripe (6).jfif')
plt.imshow(img_scale)
if result>0.5:
print('该图片是生西红柿的概率为:',result)
else:
print('该图片是熟西红柿的概率为:',1-result)
import matplotlib.pyplot as plt
from PIL import Image
import os.path
def convertjpg(jpgfile,outdir,width=150,height=150):
img=Image.open(jpgfile)
try:
new_img=img.resize((width,height),Image.BILINEAR)
new_img.save(os.path.join(outdir,os.path.basename(new_file)))
except Exception as e:
print(e)
jpgfile="D:/py/Dataset-Tomato/ripe (41).jpg"
new_file="D:/py/Dataset-Tomato/ripe (41).jpg"
convertjpg(jpgfile,r"D:/py/Dataset-Tomato")
img_scale = plt.imread('D:/py/Dataset-Tomato/ripe (41).jpg')
plt.imshow(img_scale)
from keras.models import load_model
model = load_model('D:/py/Dataset-Tomato/ripes_and_unripes_6epoch.h5')
#model.summary()
img_scale = plt.imread("D:/py/Dataset-Tomato/ripe (41).jpg")
img_scale = img_scale.reshape(1,150,150,3).astype('float32')
img_scale = img_scale/255
result = model.predict(img_scale)
img_scale = plt.imread('D:/py/Dataset-Tomato/ripe (41).jpg')
plt.imshow(img_scale)
if result>0.5:
print('该图片是生西红柿的概率为:',result)
else:
print('该图片是熟西红柿的概率为:',1-result)