1 同时创建作者和作者详情表
1.1 django项目改名字后顺利运行
# 1 先改文件夹名
# 2 改项目名
# 3 改 项目内的文件夹名
# 4 替换掉所有文件中的 drf_day04 ---》drf_day05
# 5 命令行中启动:python manage.py runserver
# 6 setting--->django--->指定项目根路径

1.1 作者和作者详情
view 视图
from rest_framework.response import Response
from rest_framework.views import APIView
from .models import Author
from .serializer import AuthorSerializer
class AuthorView(APIView):
# 查询所有
def get(self, request):
author = Author.objects.all() # 查询出来的不是列表,要序列化
ser = AuthorSerializer(instance=author, many=True)
# instance要序列化的对象是authors queryset对象
# many=True只要是queryset对象要传many=True,如果是单个对象就不用传
return Response(ser.data)
# 新增
def post(self, request, *args, **kwargs):
# 前端提交过来的数据 request.data
ser = AuthorSerializer(data=request.data)
if ser.is_valid():
# 保存
ser.save()
return Response({'code': 100, 'msg': '增加成功'})
else:
return Response({'code': 101, 'msg': ser.errors})
Serializer
from rest_framework import serializers
from .models import Book, Author
class AuthorSerializer(serializers.Serializer):
name = serializers.CharField()
age = serializers.IntegerField()
sex = serializers.CharField()
hobby = serializers.CharField(write_only=True)
phone = serializers.CharField(write_only=True)
author_detail = serializers.SerializerMethodField(read_only=True)
def get_author_detail(self, instance: Author):
return {'phone': instance.author_detail.phone, 'hobby': instance.author_detail.hobby}
def create(self, validated_data):
# 弹出作者详情
hobby = validated_data.pop('hobby')
phone = validated_data.pop('phone')
# 添加作者详情
author_detail = AuthorDetail.objects.create(hobby=hobby, phone=phone)
# 新增作者
author = Author.objects.create(author_detail=author_detail, **validated_data)
return author
2 ModelSerializer使用
# ModelSerializer它继承了Serializer,它可以直接跟表模型建立关系
-1 要序列化或反序列化的字段,不需要咱们写了---》从表模型中映射过来
-2 封装了 create和update方法---》但是:后期可能自己再重写这俩方法
# 总结:
1 写了 class Meta:model = Book;fields = '__all__' 自动映射表中字段,包括字段属性
2 fields = 列表----》要序列化和反序列化的字段都放在这里,表中没有,也要注册
3 extra_kwargs 给某个字段增加字段属性(包括read_only和write_only)
4 局部钩子和全局钩子一模一样
5 一般情况下不需要重写update和create---》即便多表关联
6 可以重写字段,单一定不要写在class Meta 内部
使用方法
# class BookSerializer(serializers.ModelSerializer):
# '''
# ####### 序列化的时候#########
# 1 有的字段不想做序列化
# 2 publish 默认显示id,我们想显示详情--->重写字段,必须在fields中注册
# 3 作者显示id列表,我们想显示作者详情列表--->重写字段,必须在fields中注册
#
# '''
#
# class Meta:
# model = Book
# # fields = '__all__' # 内部本质:把Book表模型中所有字段,都复制过来的
# fields = ['name', 'price','publish_dict','author_list'] # 要序列化的字段
#
# # 咱们用了方式二重写的,你下午用方式一 重写
# publish_dict = serializers.DictField()
# author_list=serializers.ListField()
class BookSerializer(serializers.ModelSerializer):
'''
反序列化和校验
--校验:
1 限制name 最长不能超过8
-方式一 :重写这个字段 不好
-方式二:extra_kwargs传入
2 publish_dict,author_list只做序列化,必须加read_only
3 之前讲的局部钩子和全局钩子,完全一样
4 可以不重写 create和update的。咱们这个案例就不用重写
-它俩只做反序列化
-'publish'---->不要写成publish_id,就写成表中的字段
'authors'
'''
class Meta:
model = Book
fields = ['name', 'price', 'publish_dict', 'author_list', 'publish', 'authors'] # 要序列化的字段
extra_kwargs = {
'name': {'max_length': 8, 'min_length': 3}, # 等同于name=serializers.CharField(max_length=8,min_length=3)
'publish': {'write_only': True},
'authors': {'write_only': True}
}
# 只做序列化---》加 read_only
publish_dict = serializers.DictField(read_only=True)
author_list = serializers.ListField(read_only=True)
# 局部钩子
def validate_name(self, value):
print('我走了---》', value)
return value
3 模块与包的使用(很重要)
# 模块与包
-模块:一个py文件,被别的py文件导入使用,这个py文件称之为模块,运行的这个py文件称之为脚本文件
- s1自己点右键运行,这个文件s1叫脚本文件
- 在s2中,把s1,引入使用,s1就叫模块
-包:一个文件夹下有__init__.py
-作用:包内部的函数,类..想给外部方便使用(导入的时候路径短一些),就要在里面做注册
# 模块与包的导入问题
'''
0 导入模块有相对导入和绝对导入,绝对的路径是从环境变量开始的
1 导入任何模块,如果使用绝对导入,都是从环境变量开始导入起
import xx #### xx所在路径必须在环境变量
from yy import ####yy所在路径必须在环境变量中
2 脚本文件执行的路径,会自动加入环境变量
3 相对导入的话,是从当前py文件开始计算的
4 以脚本运行的文件,不能使用相对导入,只能用绝对导入
'''
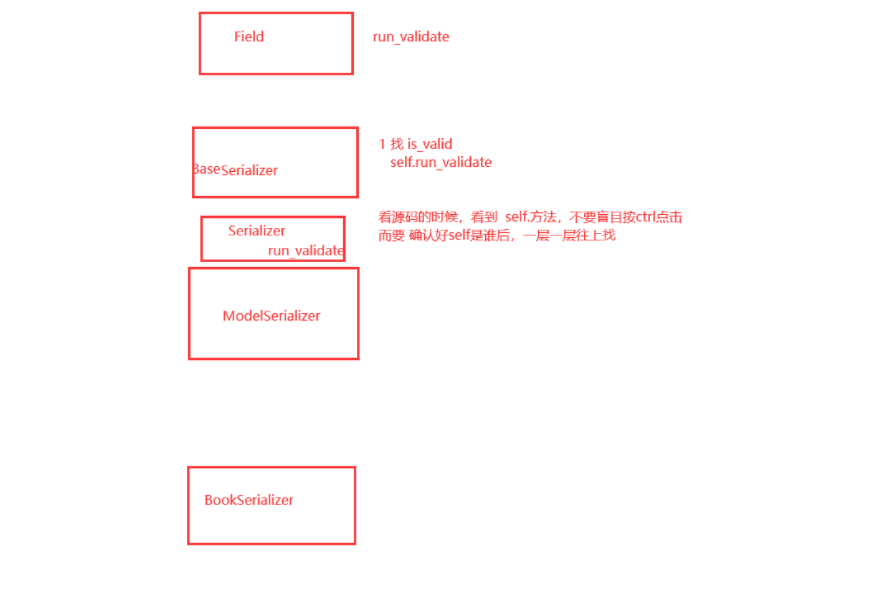
反序列化校验源码分析(了解)
# 之前---》ser.is_valid()--->三层---》局部钩子和全局钩子写法是固定---》源码中规定了是要这么写---》如果不这么写,它就执行不了
# 看源码,为什么 局部钩子要 validate_字段名(self,value) 这么写
-入口:ser.is_valid()
def is_valid(self, *, raise_exception=False):
# 如果 self中有_validated_data这个属性---》if就不走了
# 只要_validated_data这个属性有,说明它之前执行过校验了,只要校验过一次,走过一次,以后就不走了
if not hasattr(self, '_validated_data'):
try:
self._validated_data = self.run_validation(self.initial_data)
except ValidationError as exc:
self._validated_data = {}
self._errors = exc.detail
else:
self._errors = {}
# self._errors有值,说明有错误,校验不通过
# raise_exception 默认是false,如果传入的是True,直接抛异常
if self._errors and raise_exception:
raise ValidationError(self.errors)
return not bool(self._errors)
-核心:self._validated_data = self.run_validation(self.initial_data)
-self是谁?序列化类的对象--》BookSerializer---》应该从根上找:BookSerializer
-Serializer 的run_validation
def run_validation(self, data=empty):
(is_empty_value, data) = self.validate_empty_values(data)
if is_empty_value:
return data
#1 局部钩子规则
value = self.to_internal_value(data)
try:
#2 放在这里
self.run_validators(value)
# self是 BookSerializer的对象---》validate 全局钩子
#3 全局钩子执行位置---》可以抛异常---》因为捕获了
# value是 校验过后的数据--》而一定要返回
value = self.validate(value)
raise ValidationError(detail=as_serializer_error(exc))
return value
-执行了:self.to_internal_value(data)
def to_internal_value(self, data):
for field in fields: # 序列化类中一个个字段类的对象放到列表中,每次拿出一个字段类对象
# self 是BookSerializer的对象
# 去BookSerializer的对象中反射 validate_字段名
validate_method = getattr(self, 'validate_' + field.field_name, None)
try:
if validate_method is not None:
# 如果有值,就会执行局部钩子,传入待校验的数据,局部钩子必须返回数据
validated_value = validate_method(validated_value)
except ValidationError as exc:
errors[field.field_name] = exc.detail
except DjangoValidationError as exc:
errors[field.field_name] = get_error_detail(exc)
return ret
# 总结:
只要执行序列化类对象的.is_valid就会执行 BaseSerializer的is_valid---》就会执行:self._validated_data = self.run_validation(self.initial_data)----》Serializer的run_validation---》两句重要的话:value = self.to_internal_value(data);value = self.validate(value)---》这两句话就是局部钩子和全局钩子---》局部钩子再进去看到了validate_字段名
5 断言
# assert 关键字,断定这个条件是符合的,才能往下走,如果不符合,就抛异常
# 断言
name = '彭于晏'
# assert name == 'lqz', '不是lqz,不能执行了'
# 用代码翻译:翻译这句话
if not name=='lqz':
raise Exception("不是lqz,不能执行了")
print('lqz,来了老弟')
6 drf之请求
6.1 请求源码分析
# 新的request对象---》之前聊过一部分
# from rest_framework.request import Request
# 1 以后视图类的方法中的request都是这个类的对象
# 2 以后使用request.data 取请求体中的数据
# 3 以后使用request.query_params 取请参数中的数据
# 4 以后其他属性,用起来跟之前一样---》重要
-request.method 的时候---》实际上 request._request.'method'---》反射出来的
-这个类from rest_framework.request import Request没有method,他会触发这个类的__getattr__---》
# 5 FILES 用起来跟之前一样,前端传入的文件在里面
# 魔法方法之.拦截
-什么是魔法方法, 在类中 __名字__ 方法是魔法方法,特点是某种情况下自动触发
-__init__---->类名()自动触发
-__str__---->print(对象)自动触发
-__getattr__: 对象.属性,如果属性不存在,会触发__getattr__
-__setattr__:对象.属性=值,会触发__setattr__
# 有很多魔法方法---》就想看看有多少
object类中的方法
6.2 魔法方法之 . 拦截
class Person:
def __getattr__(self, item):
print(item) # 是name 这个字符串
print(type(item)) # 是name 这个字符串
return 'lqz'
def __setattr__(self, key, value):
print(key)
print(value)
# setattr(self,key,value)# 反射内部用的就是setattr 会递归
object.__setattr__(self,key,value)
p = Person()
# print(p.name) # 会报错
p.name='彭于晏'
print(p.name)