前言
数据分片是指将数据按某种方式存储到不同的服务上来解决单机服务容量不足的问题。
本文围绕 Redis 讲述逻辑拆分、随机分配、哈希取模、一致性哈希等分片算法原理和使用场景。并在此基础上对比客户端分片、代理(Proxy) 和 Redis Cluster 各自的优缺点。
客户端分片
三种普通方式
- 逻辑拆分:适用于数据可以按逻辑分类、交集不多,一个 Redis 服务的容量足以支撑一个类别的情况。实现时按逻辑将数据分配到同一个Redis 服务,比如按业务分类。
- 随机分配:类似消息队列的使用场景,将数据写到任意 Redis 服务,每个 Redis 服务都有消费者消费数据。一般会使用到 List 数据类型 PUSH POP 等操作。
- 哈希取模:使用哈希算法接收 Key 作为参数,然后对预先计算好的、固定数量的 Redis 服务数量进行取模,最后落到对应服务。缺点是影响扩展性,因为取模数必须先估算好,不然增减节点所有数据都需要重新进行哈希取模运算。
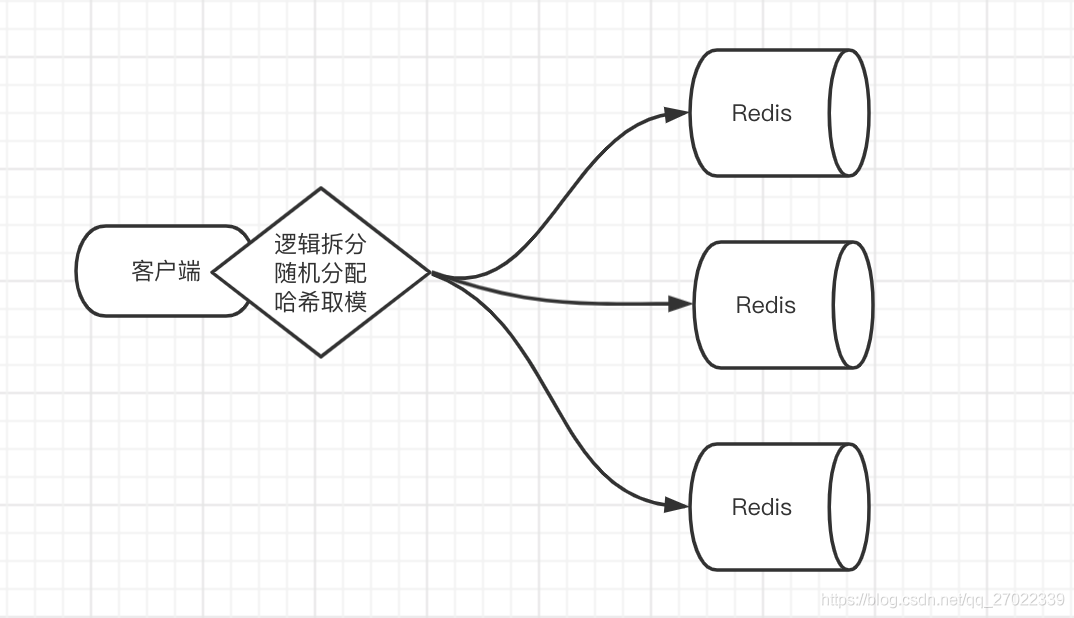
一致性哈希
一致性哈希是在哈希取模方式的基础上解决了不方便动态增减节点的问题。
先虚拟出 2 的 32 次方个节点,按顺时针方向看成一个首尾相连的环形。拿到你 Redis 实体服务的信息经过哈希运算再对虚拟节点数量进行取模映射到环上的虚拟节点,如图中 A、C 两个点。
当数据读写的时候同样用同样方式将 Key 作为参数运算后映射到环上的某个虚拟节点(如数据A),如果该虚拟节点没有对应 Redis 实体服务则顺时针找最近的实体服务完成操作。
新增节点时,原本 A → C 断的数据都交给了 C,当新加入节点 B 后,A → B 段的数据则会交给 B,B → C 段的数据交给C。但这样会产生小部分数据不能命中的新问题,就是原本 A → B 段缓存到 C 的老数据访问不到了,因为现在访问落到了 B 上,最终导致缓存击穿,访问压力落到了数据库,并且还占用了 C 的内存。
第一种解决方案是访问数据的时候按顺时针取两个节点;第二种方式就是给缓存数据设置过期时间,访问不到的数据从数据库读取缓存到新节点,旧的数据会因为到期淘汰掉。
数据倾斜是指当数据经过计算映射到同一段时会导致最近的实体服务压力过大,比如数据都映射到了 C → A 这个区域,则 A 节点访问压力会很大。解决办法是 Redis 实体服务映射到多个点上,分摊多节映射区域的压力。
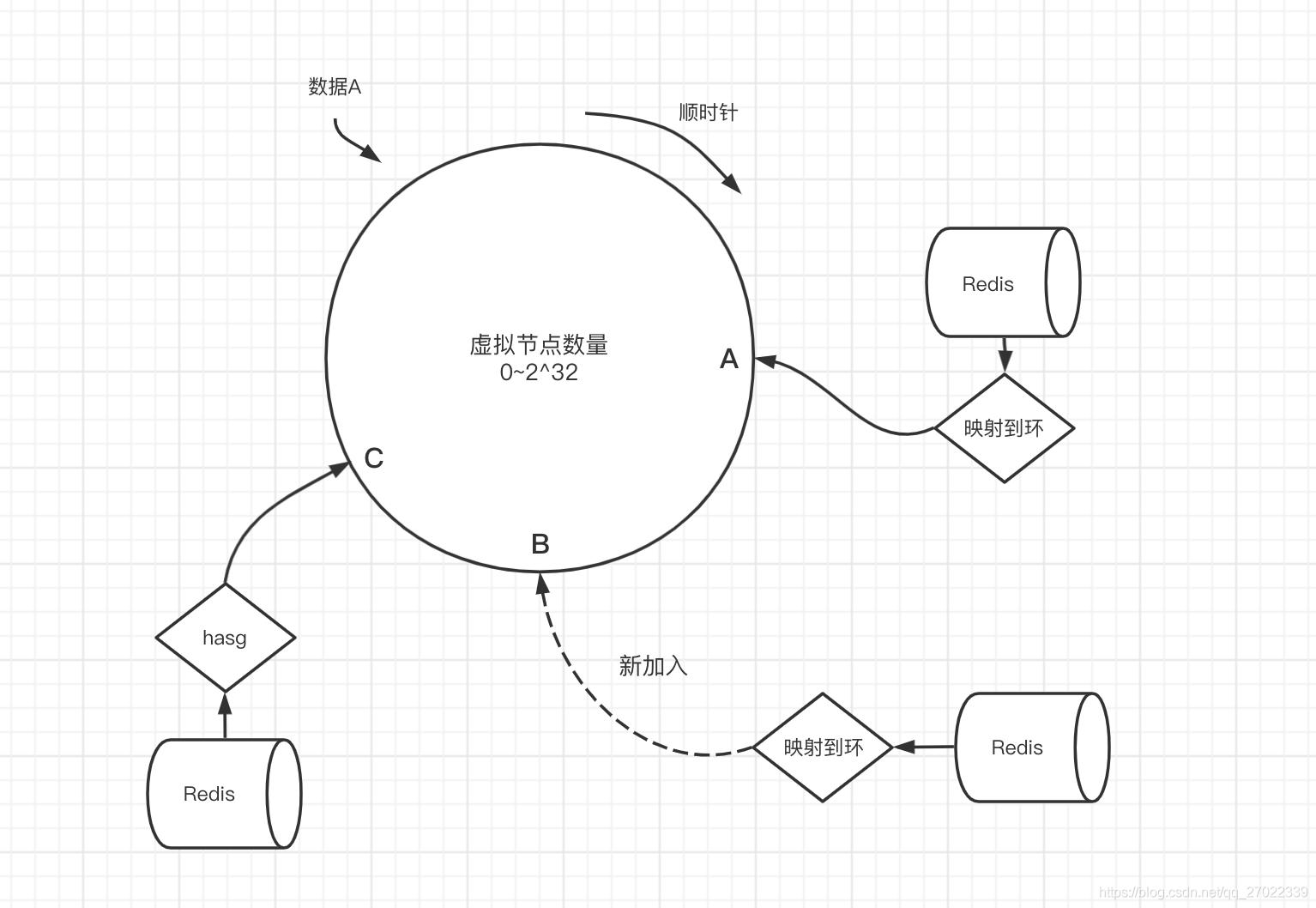
客户端分片问题
在客户端执行分片算法后需要连接对应 Redis 完成操作,那就意味着每个客户端都会跟每个 Redis 产生连接。当客户端增多的时候 Redis 服务的连接开销比较大。
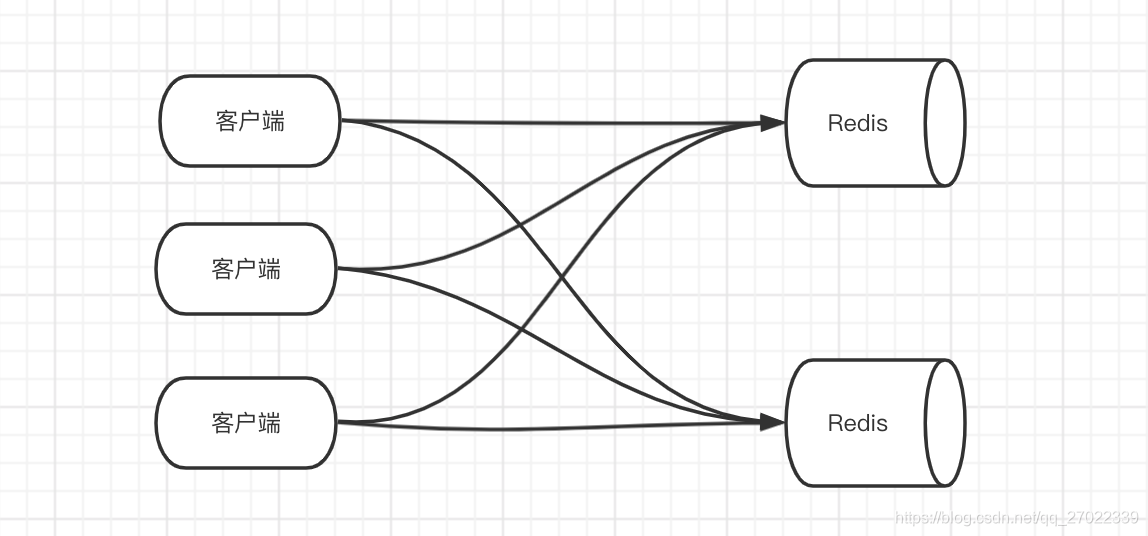
代理(Proxy)
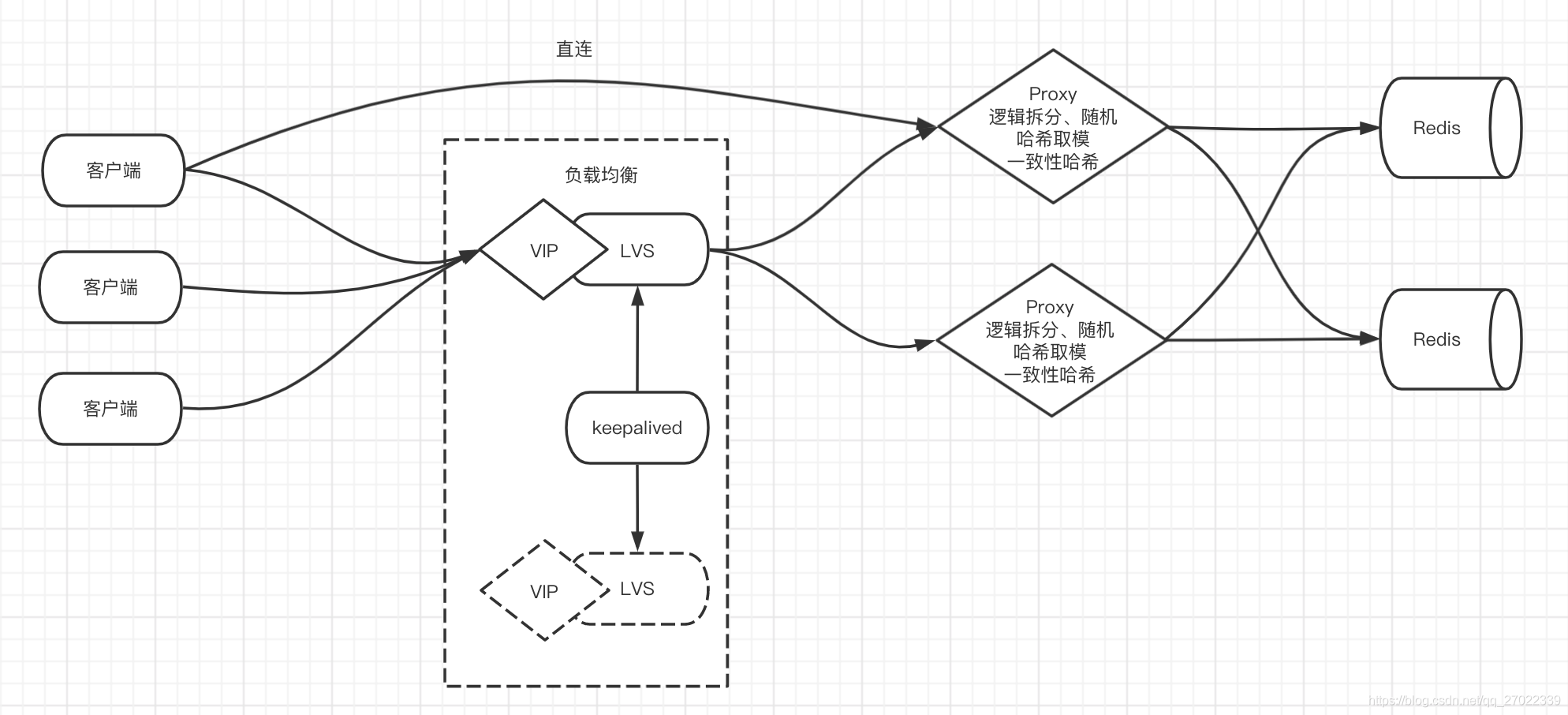
代理的出现主要是解决客户端分片时 Redis 连接开销过大的问题。客户端只连接代理,代理去跟后面的 Redis 服务建立连接。并且,让代理去实现分片算法,它是无状态的,只负责计算和将操作落到对应 Redis 服务,不存储数据。为了高可用还可以在客户端与代理之间加一层负载均衡,比如 LVS + Keepalived。
Redis Cluster
无论是客户端分片还是代理分片,扩展性、新增节点重新分片都是难以避免的问题;这些方式适合将 Redis 作缓存,而不适合作数据库用,因为作数据库用数据是不能够丢失的。
Redis Cluster 则是用预分配的方式来规避这些问题,虽然难免要进行数据迁移,但是只需要迁移部分,减小了问题规模。
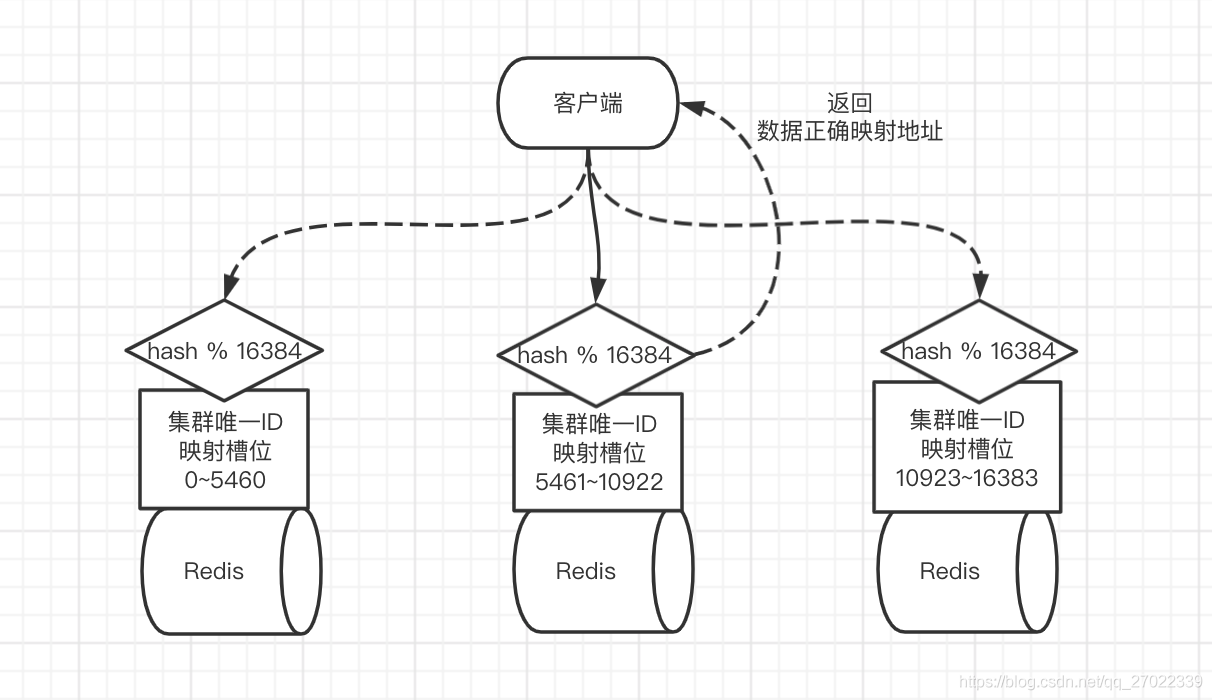
Redis Cluster 是一个无主模型。通过哈希运行算对 16384 个槽位进行取模,让集群中的所有节点一起分摊这些槽位。每个节点都有一套相同的哈希算法,并保存了集群所有节点和槽位的映射关系。
客户端可以连接集群任意节点进行操作,节点经过计算后对比映射关系,如果规自己管,则在自己这完成对应操作。否则返回给客户端一个 MOVE 错误并附带正确的节点地址,让客户的连接正确的地址来完成操作。
槽位是在集群创建时用操作命令分配好的,并且每个节点都可以分配一个或多个副本实现高可用。增减节点时使用命令将部分槽位进行迁移来完成。
聚合操作问题
数据分片的情况下如 KEYS 、MULTI 等聚合操作难以实现,因为数据分布在不同的节点。Redis Cluster 给出的方案是在 Key 前加入统一的 {tag} 格式如 {tag}key。这样就只会对 tag 进行哈希运算让这些数据落到同一个节点。其他代理也有类似的使用方式来实现聚合操作。