一.选题的背景
据统计今年四月以来,全国彩票销量突破1700亿元,达到1751.50亿元,和2020年、2021年相比涨幅更大,比2019年也高出300多亿。
而且买彩票的年轻人也越来越多,首先现在是自媒体时代,体彩、福彩在媒体上的宣传,年轻人无疑是最大的受众体,而年前人接受新事物的能力比较强,“小小彩票也能成就梦想”这样的口号也渐渐被年轻人接纳。
我也是年轻人的一员,所以我选择对于500彩票网站的超级大乐透的近100期进行爬取,看那些号码适合购买,来完成我的"暴富梦"。
二.主题式网络爬虫设计方案
1.主题式网络爬虫名称
500彩票超级大乐透近100期页面爬取
2.主题式网络爬虫爬取的内容与数据特征分析
500彩票超级大乐透近100期页面爬取主要爬取了页面中表格table中的td数据。
为页面中的期号、前区号码1-5、后区、奖池奖金、一等奖注数、一等奖奖金、二等奖注数、二等奖奖金、总投注额(元)、以及开奖日期。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
思路:查看网页的结构,定位目标数据的位置,爬取数据,将数据进行清洗,最后将清洗后的数据进行可视化。
难点:如何应对网站的反爬虫机制,如何爬取多个页面的数据,请求异常的处理
三、主题页面的结构特征分析
1.主题页面的结构与特征分析
目标内容界面:

2.Htmls 页面解析

3.节点(标签)查找方法与遍历方法
打开网页的源码,然后用鼠标检查工具找打对应大概位置进行查找,然后在元素中分析,用beautifulsoup4方法对获取的页面进行处理

四、网络爬虫程序设计
1.数据爬取与采集
以下为爬取过程代码
1 import requests 2 from bs4 import BeautifulSoup 3 #导入前两个库为爬虫所需要的库 4 5 import pandas as pd 6 #导入后面将数据转化格式的库 7 8 from retry.api import retry_call 9 10 url = "https://datachart.500.com/dlt/history/newinc/history.php?limit=100&sort=0" 11 #所需要访问的网页为https://datachart.500.com/dlt/history/history.shtml 12 #(500)彩票网址 因为要查询的为100期的但 所以在检查里面寻找网络 将30期切换为100期 13 #出现了名称为history.php?limit=100&sort=0的文件 在表头的常规里面找到url即为所需的100期 14 15 response = requests.get(url) 16 if response.status_code==200: 17 print("请求成功") 18 # 发送GET请求获取页面内容 若请求成功则继续 否则输出请求失败 19 20 21 soup = BeautifulSoup(response.content, 'html.parser') 22 # 使用BeautifulSoup解析页面内容 并用'html.parser'的方法解析 23 #在页面的检查界面的元素找到需要的表格信息的html所在地 24 25 table = soup.find('div', attrs={"class": 'chart'}) 26 #在页面寻找到表格的总体class="chart" 所以用soup.find寻找chart总表 27 28 rows = table.find_all('tr') 29 #在检查界面发现所有的表格信息都在tr里面 所以用find_all寻找所有tr的信息放到rows里面 30 31 data = [] 32 # 先创建一个空的DataFrame来存储数据 33 34 35 for row in rows: 36 # 遍历每一行,并提取数据 37 38 cells = row.find_all('td') 39 #找到所有的单元格是td的 40 #用print(cells)查看有多少td 41 #发现是15个 让td长度为15的才通过录入到date里面 否则无法进入 42 43 if len(cells) == 15: 44 date=cells[0].text 45 Front_Area_1=cells[1].text 46 Front_Area_2=cells[2].text 47 Front_Area_3=cells[3].text 48 Front_Area_4=cells[4].text 49 Front_Area_5=cells[5].text 50 Back_Area_1 =cells[6].text 51 Back_Area_2 =cells[7].text 52 all_bonus =cells[8].text 53 first_note =cells[9].text 54 first_prize =cells[10].text 55 second_note =cells[11].text 56 second_prize=cells[12].text 57 Current_bankroll=cells[13].text 58 Award_date =cells[14].text 59 #将每一元素的地址放到不同的单元里面 并且转化为text形式 60 #转化为text形式是为了将数据更好的放到表格中 61 62 data.append([date, Front_Area_1, Front_Area_2, Front_Area_3, Front_Area_4, Front_Area_5, Back_Area_1 , Back_Area_2, 63 all_bonus, first_note, first_prize, second_note, second_prize, Current_bankroll, Award_date]) 64 #将所有数据放入到前面创建的data里面 65 66 df = pd.DataFrame(data, columns=['期号', '前区号码1', '前区号码2', '前区号码3', '前区号码4', '前区号码5', '后区号码1', '后区号码2','奖池奖金(元)', '一等奖注数', '一等奖金(元)', 67 '二等奖注数', '二等奖金(元)', '总投注额(元)', '开奖日期']) 68 # 再将数据转换为DataFrame,加上列名 69 70 df.to_csv('500_lottery_ticket.csv', index=True) 71 # 然后将文件导出为csv文件 72 else: 73 print("请求失败") 74 #若请求失败则直接返回请求失败
现在我们获得了一个名为500_lottery_ticket.csv的csv其中csv如下图所示

包含了我们所需要的所有数据
接下来进行数据清洗
以及可视化分析
1 import pandas as pd 2 #导入pandas库进行数据清洗使用 3 4 import matplotlib.pyplot as plt 5 #导入matplotlib对后面数据可视化使用 6 7 import numpy as np 8 #导入numpu对后面使用随机函数使用 9 10 import seaborn as sns 11 12 plt.rcParams['font.sans-serif'] = ['SimSun'] 13 #让中文可以输出 14 15 df=pd.read_csv("500_lottery_ticket.csv", index_col=0) 16 #将刚刚处理好的csv导出到df内 17 18 Front_Area_1_5=df.iloc[:,1:6] 19 #用切片的方式 获取前区号码1-5放入到Front_Area_1_5 20 21 Back_Area_1_2=df.iloc[:,6:8] 22 #用切片的方式 获取后区号码1-2放入到Back_Area_1_2 23 24 Front_Area_1_5_count=pd.value_counts(Front_Area_1_5.values.flatten()) 25 #用pandas处理将 Front_Area_1_5中数据出现的数据的次数赋值到Front_Area_1_5_count中 26 27 Back_Area_1_2_count=pd.value_counts(Back_Area_1_2.values.flatten()) 28 #用pandas处理将 Front_Area_1_5中数据出现的数据的次数赋值到Back_Area_1_2_count中 29 30 colors = ['#FF0000', '#00FF00', '#0000FF', '#FFFF00', '#00FFFF', '#FF00FF', '#FFFFFF', '#000000', '#808080', 31 '#FFA500', '#800080', '#A52A2A', '#FFC0CB', '#ADD8E6', '#006400', '#FFD700', '#8B4513', '#4B0082', 32 '#00CED1', '#F0E68C', '#7B68EE', '#20B2AA', '#FF69B4', '#C71585', '#F5DEB3', '#ADFF2F'] 33 #为了更好的可视化我添加了一些十六进制的颜色模块 34 35 plt.pie(Front_Area_1_5_count, 36 colors=np.random.choice(colors,len(Front_Area_1_5_count)), 37 labels=Front_Area_1_5_count.index, 38 radius=1, 39 wedgeprops={"width":0.3}) 40 41 plt.pie(Back_Area_1_2_count, 42 colors=np.random.choice(colors,len(Back_Area_1_2_count)), 43 labels=Back_Area_1_2_count.index, 44 radius=0.5, 45 wedgeprops={"width":0.2}) 46 47 #画一张刚刚处理好的数据出现次数的 图案 其中使用颜色时用的np.random随机选择颜色 48 #定义的半径为1和0.5 半径为0.3和0.2 这样两个圆环就可以嵌套在一起了 49 plt.show()
运行后所产生的图像为以下饼图
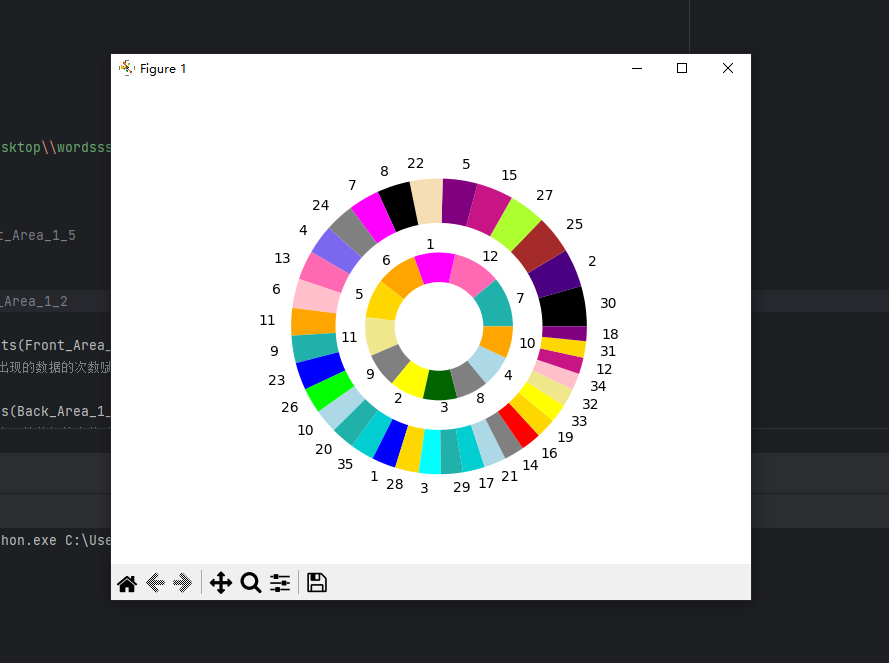
从图像中可知前五个号码为30,2,25,27,15中奖概率大后两个号码为7,12概率大
当日时间为2023/6/4号得到的结果
在2023/6/2号最新所开奖号码06 08 22 24 30 01 08
与结果进行比较不难发现 大多数中间号码都在前40%以内
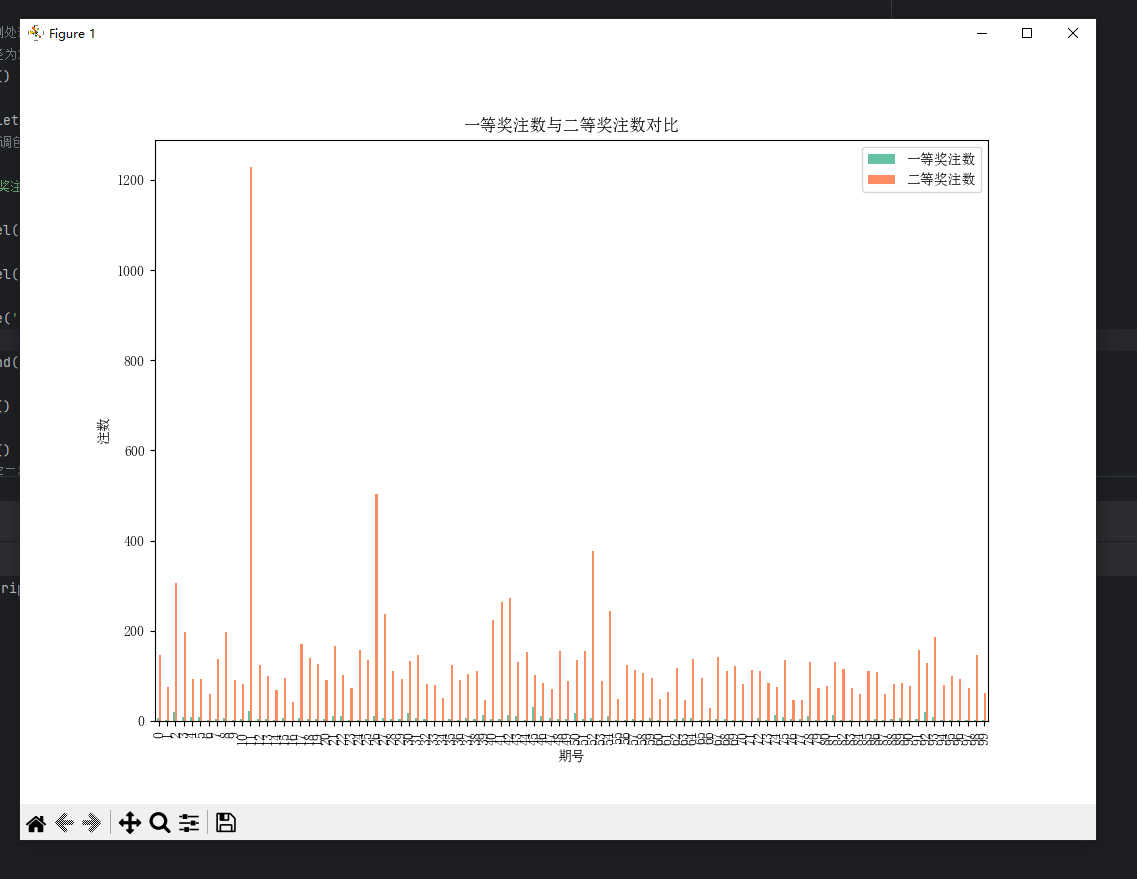
以下画出一等奖注数与二等奖注数对比的箱图
1 color_palette = sns.color_palette("Set2") 2 # 设置颜色调色板 3 4 df[['一等奖注数', '二等奖注数']].plot.bar(color=color_palette) 5 6 plt.xlabel('期号') 7 8 plt.ylabel('注数') 9 10 plt.title('一等奖注数与二等奖注数对比') 11 12 plt.legend(['一等奖注数', '二等奖注数']) 13 14 plt.show() 15 16 plt.show() 17 #画出一等奖二等奖的对比图
以下画出一等奖注数变化趋势图
1 df['一等奖注数'].plot.line() 2 3 plt.xlabel('期号') 4 5 plt.ylabel('一等奖注数') 6 7 plt.title('一等奖注数变化趋势') 8 9 plt.show() 10 #一等奖注数变化趋势图

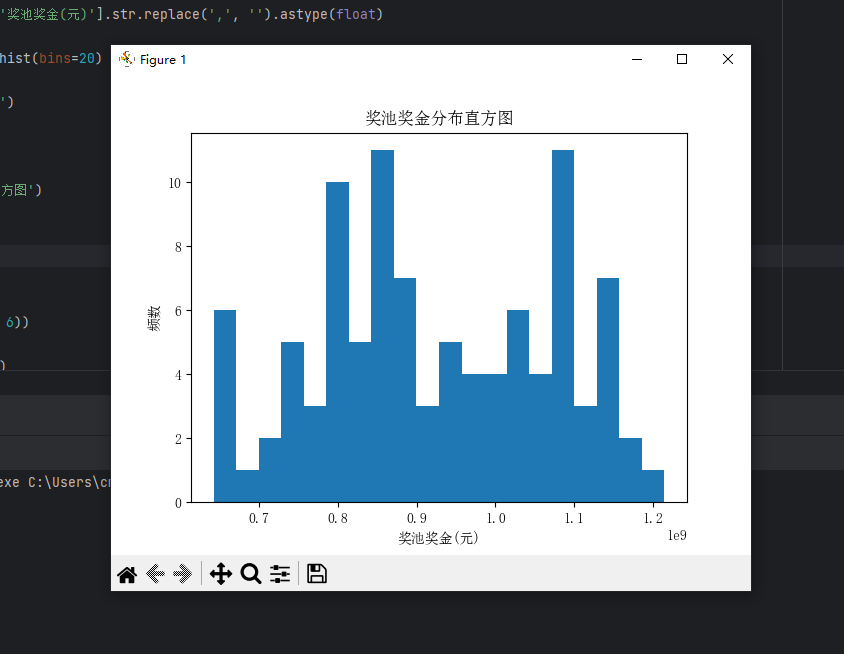
以下画出奖池奖金分布直方图
1 df['奖池奖金(元)'] = df['奖池奖金(元)'].str.replace(',', '').astype(float) 2 3 df['奖池奖金(元)'].plot.hist(bins=20) 4 5 plt.xlabel('奖池奖金(元)') 6 7 plt.ylabel('频数') 8 9 plt.title('奖池奖金分布直方图') 10 11 plt.show() 12 #奖池奖金分布直方图
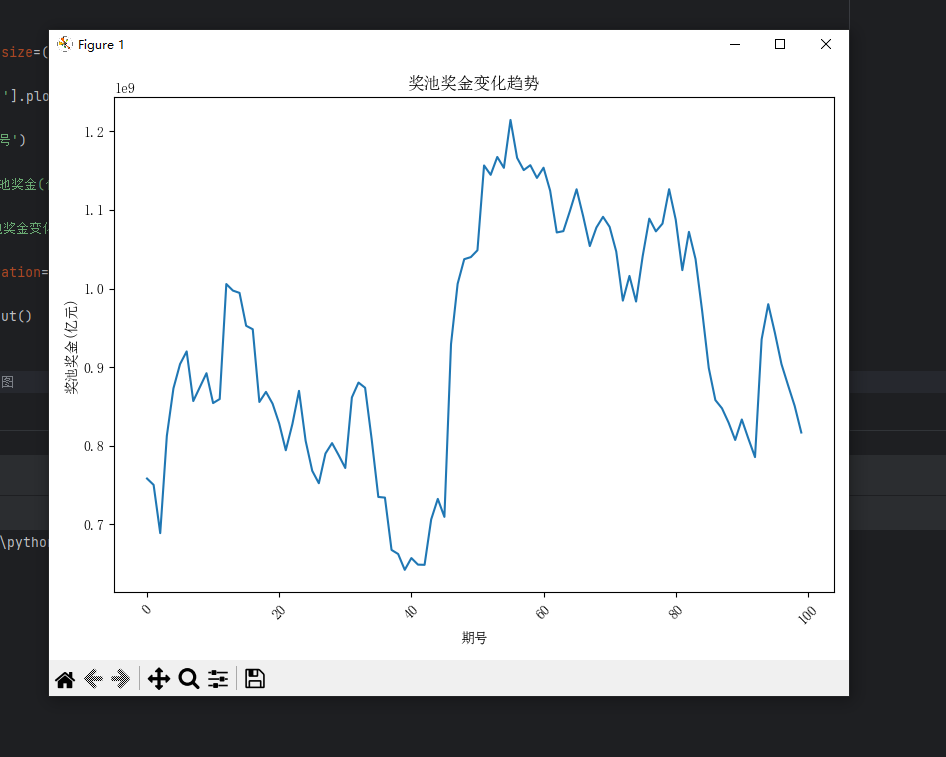
以下画出奖池奖金变化趋势图
1 plt.figure(figsize=(8, 6)) 2 3 df['奖池奖金(元)'].plot() 4 5 plt.xlabel('期号') 6 7 plt.ylabel('奖池奖金(亿元)') 8 9 plt.title('奖池奖金变化趋势') 10 11 plt.xticks(rotation=45) 12 13 plt.tight_layout() 14 15 plt.show() 16 #奖池奖金变化趋势图
5.数据持久化
1 import requests 2 from bs4 import BeautifulSoup 3 import sqlite3 4 import pandas as pd 5 6 url = "https://datachart.500.com/dlt/history/newinc/history.php?limit=100&sort=0" 7 8 response = requests.get(url) 9 if response.status_code == 200: 10 print("请求成功") 11 12 soup = BeautifulSoup(response.content, 'html.parser') 13 table = soup.find('div', attrs={"class": 'chart'}) 14 rows = table.find_all('tr') 15 16 data = [] 17 for row in rows: 18 cells = row.find_all('td') 19 if len(cells) == 15: 20 date = cells[0].text 21 Front_Area_1 = cells[1].text 22 # ... 继续提取其他数据 23 24 data.append([date, Front_Area_1, ...]) 25 26 df = pd.DataFrame(data, columns=['期号', '前区号码1', ...]) 27 28 # 连接到SQLite数据库 29 conn = sqlite3.connect('lottery_data.db') 30 cursor = conn.cursor() 31 32 # 创建表 33 create_table_query = ''' 34 CREATE TABLE IF NOT EXISTS lottery ( 35 id INTEGER PRIMARY KEY AUTOINCREMENT, 36 期号 TEXT, 37 前区号码1 TEXT, 38 前区号码2 TEXT, 39 前区号码3 TEXT, 40 前区号码4 TEXT, 41 前区号码5 TEXT, 42 后区号码1 TEXT, 43 后区号码2 TEXT, 44 奖池奖金 TEXT, 45 一等奖注数 TEXT, 46 一等奖金 TEXT, 47 二等奖注数 TEXT, 48 二等奖金 TEXT, 49 总投注额 TEXT, 50 开奖日期 TEXT 51 ); 52 ''' 53 cursor.execute(create_table_query) 54 55 # 插入数据 56 insert_query = 'INSERT INTO lottery (期号, 前区号码1, 前区号码2, ..., 开奖日期) VALUES (?, ?, ?, ..., ?);' 57 cursor.executemany(insert_query, df.values.tolist()) 58 59 # 提交事务并关闭连接 60 conn.commit() 61 conn.close() 62 63 print("数据已保存到数据库") 64 else: 65 print("请求失败")
在这个示例中,我们使用了SQLite数据库来创建名为"lottery_data.db"的数据库文件,并创建了一个名为"lottery"的表。然后,我们将从网页中提取的数据插入到该表中。
请注意,这只是一个示例,您可以根据自己的需求进行修改和扩展。另外,您需要安装SQLite库(通常已内置在Python中)来运行这段代码。
通过使用数据库进行数据持久化处理,您可以更方便地进行数据管理和查询操作。
6.将以上各部分的代码汇总,附上完整程序代码
(1)爬虫代码部分
1 import requests 2 from bs4 import BeautifulSoup 3 #导入前两个库为爬虫所需要的库 4 5 import pandas as pd 6 #导入后面将数据转化格式的库 7 8 from retry.api import retry_call 9 10 url = "https://datachart.500.com/dlt/history/newinc/history.php?limit=100&sort=0" 11 #所需要访问的网页为https://datachart.500.com/dlt/history/history.shtml 12 #(500)彩票网址 因为要查询的为100期的但 所以在检查里面寻找网络 将30期切换为100期 13 #出现了名称为history.php?limit=100&sort=0的文件 在表头的常规里面找到url即为所需的100期 14 15 response = requests.get(url) 16 if response.status_code==200: 17 print("请求成功") 18 # 发送GET请求获取页面内容 若请求成功则继续 否则输出请求失败 19 20 21 soup = BeautifulSoup(response.content, 'html.parser') 22 # 使用BeautifulSoup解析页面内容 并用'html.parser'的方法解析 23 #在页面的检查界面的元素找到需要的表格信息的html所在地 24 25 table = soup.find('div', attrs={"class": 'chart'}) 26 #在页面寻找到表格的总体class="chart" 所以用soup.find寻找chart总表 27 28 rows = table.find_all('tr') 29 #在检查界面发现所有的表格信息都在tr里面 所以用find_all寻找所有tr的信息放到rows里面 30 31 data = [] 32 # 先创建一个空的DataFrame来存储数据 33 34 35 for row in rows: 36 # 遍历每一行,并提取数据 37 38 cells = row.find_all('td') 39 #找到所有的单元格是td的 40 #用print(cells)查看有多少td 41 #发现是15个 让td长度为15的才通过录入到date里面 否则无法进入 42 43 if len(cells) == 15: 44 date=cells[0].text 45 Front_Area_1=cells[1].text 46 Front_Area_2=cells[2].text 47 Front_Area_3=cells[3].text 48 Front_Area_4=cells[4].text 49 Front_Area_5=cells[5].text 50 Back_Area_1 =cells[6].text 51 Back_Area_2 =cells[7].text 52 all_bonus =cells[8].text 53 first_note =cells[9].text 54 first_prize =cells[10].text 55 second_note =cells[11].text 56 second_prize=cells[12].text 57 Current_bankroll=cells[13].text 58 Award_date =cells[14].text 59 #将每一元素的地址放到不同的单元里面 并且转化为text形式 60 #转化为text形式是为了将数据更好的放到表格中 61 62 data.append([date, Front_Area_1, Front_Area_2, Front_Area_3, Front_Area_4, Front_Area_5, Back_Area_1 , Back_Area_2, 63 all_bonus, first_note, first_prize, second_note, second_prize, Current_bankroll, Award_date]) 64 #将所有数据放入到前面创建的data里面 65 66 df = pd.DataFrame(data, columns=['期号', '前区号码1', '前区号码2', '前区号码3', '前区号码4', '前区号码5', '后区号码1', '后区号码2','奖池奖金(元)', '一等奖注数', '一等奖金(元)', 67 '二等奖注数', '二等奖金(元)', '总投注额(元)', '开奖日期']) 68 # 再将数据转换为DataFrame,加上列名 69 70 df.to_csv('500_lottery_ticket.csv', index=True) 71 # 然后将文件导出为csv文件 72 else: 73 print("请求失败") 74 #若请求失败则直接返回请求失败
(2)数据清洗加可视化代码
1 import pandas as pd 2 #导入pandas库进行数据清洗使用 3 4 import matplotlib.pyplot as plt 5 #导入matplotlib对后面数据可视化使用 6 7 import numpy as np 8 #导入numpu对后面使用随机函数使用 9 10 import seaborn as sns 11 12 plt.rcParams['font.sans-serif'] = ['SimSun'] 13 #让中文可以输出 14 15 df=pd.read_csv("500_lottery_ticket.csv", 16 index_col=0) 17 #将刚刚处理好的csv导出到df内 18 19 Front_Area_1_5=df.iloc[:,1:6] 20 #用切片的方式 获取前区号码1-5放入到Front_Area_1_5 21 22 Back_Area_1_2=df.iloc[:,6:8] 23 #用切片的方式 获取后区号码1-2放入到Back_Area_1_2 24 25 Front_Area_1_5_count=pd.value_counts(Front_Area_1_5.values.flatten()) 26 #用pandas处理将 Front_Area_1_5中数据出现的数据的次数赋值到Front_Area_1_5_count中 27 28 Back_Area_1_2_count=pd.value_counts(Back_Area_1_2.values.flatten()) 29 #用pandas处理将 Front_Area_1_5中数据出现的数据的次数赋值到Back_Area_1_2_count中 30 31 colors = ['#FF0000', '#00FF00', '#0000FF', '#FFFF00', '#00FFFF', '#FF00FF', '#FFFFFF', '#000000', '#808080', 32 '#FFA500', '#800080', '#A52A2A', '#FFC0CB', '#ADD8E6', '#006400', '#FFD700', '#8B4513', '#4B0082', 33 '#00CED1', '#F0E68C', '#7B68EE', '#20B2AA', '#FF69B4', '#C71585', '#F5DEB3', '#ADFF2F'] 34 #为了更好的可视化我添加了一些十六进制的颜色模块 35 36 plt.pie(Front_Area_1_5_count, 37 colors=np.random.choice(colors, 38 (Front_Area_1_5_count)), 39 labels=Front_Area_1_5_count.index, 40 radius=1, 41 wedgeprops={"width":0.3}) 42 43 plt.pie(Back_Area_1_2_count, 44 colors=np.random.choice(colors, 45 len(Back_Area_1_2_count)), 46 labels=Back_Area_1_2_count.index, 47 radius=0.5, 48 wedgeprops={"width":0.2}) 49 50 #画一张刚刚处理好的数据出现次数的 图案 其中使用颜色时用的np.random随机选择颜色 51 #定义的半径为1和0.5 半径为0.3和0.2 这样两个圆环就可以嵌套在一起了 52 plt.show() 53 54 color_palette = sns.color_palette("Set2") 55 # 设置颜色调色板 56 57 df[['一等奖注数', '二等奖注数']].plot.bar(color=color_palette) 58 #导入df中的'一等奖注数', '二等奖注数' 59 60 plt.xlabel(期号) 61 #将x轴设为期号 62 63 plt.ylabel('注数') 64 #将y轴设为'注数' 65 66 plt.title('一等奖注数与二等奖注数对比') 67 #表名'一等奖注数与二等奖注数对比' 68 69 plt.legend(['一等奖注数', '二等奖注数']) 70 71 plt.show() 72 73 plt.show() 74 #画出一等奖二等奖的对比图 75 76 df['一等奖注数'].plot.line() 77 #将'一等奖注数'导入 78 79 plt.xlabel('期号') 80 #x轴设为'期号' 81 82 plt.ylabel('一等奖注数') 83 #y轴设为'一等奖注数' 84 85 plt.title('一等奖注数变化趋势') 86 #表名'一等奖注数变化趋势' 87 88 plt.show() 89 #一等奖注数变化趋势图 90 91 92 df['奖池奖金(元)'] = df['奖池奖金(元)'].str.replace(',', '').astype(float) 93 #更改'奖池奖金(元)'的信息,删去逗号 94 95 df['奖池奖金(元)'].plot.hist(bins=20) 96 #导入'奖池奖金(元)' 97 98 plt.xlabel('奖池奖金(元)') 99 #x轴设为'奖池奖金(元)' 100 101 plt.ylabel('频数') 102 #y轴设为'频数' 103 104 plt.title('奖池奖金分布直方图') 105 #表名'奖池奖金分布直方图' 106 107 plt.show() 108 #奖池奖金分布直方图 109 110 plt.figure(figsize=(8, 6)) 111 112 df['奖池奖金(元)'].plot() 113 #导入'奖池奖金(元)' 114 115 plt.xlabel('期号') 116 #x轴设为'期号' 117 118 plt.ylabel('奖池奖金(亿元)') 119 #y轴设为'奖池奖金(亿元)' 120 121 plt.title('奖池奖金变化趋势') 122 #表名'奖池奖金变化趋势' 123 124 plt.xticks(rotation=45) 125 126 plt.tight_layout() 127 128 plt.show() 129 #奖池奖金变化趋势图
(3)数据持久化代码
1 import requests 2 from bs4 import BeautifulSoup 3 import sqlite3 4 import pandas as pd 5 6 url = "https://datachart.500.com/dlt/history/newinc/history.php?limit=100&sort=0" 7 8 response = requests.get(url) 9 if response.status_code == 200: 10 print("请求成功") 11 12 soup = BeautifulSoup(response.content, 'html.parser') 13 table = soup.find('div', attrs={"class": 'chart'}) 14 rows = table.find_all('tr') 15 16 data = [] 17 for row in rows: 18 cells = row.find_all('td') 19 if len(cells) == 15: 20 date = cells[0].text 21 Front_Area_1 = cells[1].text 22 # ... 继续提取其他数据 23 24 data.append([date, Front_Area_1, ...]) 25 26 df = pd.DataFrame(data, columns=['期号', '前区号码1', ...]) 27 28 # 连接到SQLite数据库 29 conn = sqlite3.connect('lottery_data.db') 30 cursor = conn.cursor() 31 32 # 创建表 33 create_table_query = ''' 34 CREATE TABLE IF NOT EXISTS lottery ( 35 id INTEGER PRIMARY KEY AUTOINCREMENT, 36 期号 TEXT, 37 前区号码1 TEXT, 38 前区号码2 TEXT, 39 前区号码3 TEXT, 40 前区号码4 TEXT, 41 前区号码5 TEXT, 42 后区号码1 TEXT, 43 后区号码2 TEXT, 44 奖池奖金 TEXT, 45 一等奖注数 TEXT, 46 一等奖金 TEXT, 47 二等奖注数 TEXT, 48 二等奖金 TEXT, 49 总投注额 TEXT, 50 开奖日期 TEXT 51 ); 52 ''' 53 cursor.execute(create_table_query) 54 55 # 插入数据 56 insert_query = 'INSERT INTO lottery (期号, 前区号码1, 前区号码2, ..., 开奖日期) VALUES (?, ?, ?, ..., ?);' 57 cursor.executemany(insert_query, df.values.tolist()) 58 59 # 提交事务并关闭连接 60 conn.commit() 61 conn.close() 62 63 print("数据已保存到数据库") 64 else: 65 print("请求失败")
五、总结
爬取的500彩票大乐透近100期的数据经过数据处理和可视化分析后的结果,我得到
数据处理:
- 数据清洗和整理:对于爬取的数据进行清洗,去除重复数据,处理缺失值,规范化数据格式等,确保数据的准确性和一致性。
- 数据转换和格式化:将数据转换为适合分析和可视化的格式,例如将日期转换为时间格式,将奖金金额转换为数字格式等。
- 数据提取和衍生:从原始数据中提取有用的信息,例如分解大乐透号码为前区号码和后区号码,计算奖池奖金的变化量等。
可视化分析:
- 号码分布:使用柱状图或热力图等可视化方法,展示大乐透号码的分布情况,包括前区号码和后区号码的出现频率、遗漏情况等。可以帮助您了解哪些号码相对较热门,哪些号码较冷门。
- 奖池变化趋势:使用折线图展示大乐透奖池的变化趋势,可以观察奖池金额的增长和下降情况,帮助您了解奖池的变化规律。
- 奖项分布:使用条形图展示不同奖项的中奖情况,包括一等奖、二等奖等各个奖项的中奖注数和中奖金额,可以对奖项的分布情况进行直观分析。
- 历史趋势分析:通过绘制折线图或曲线图,分析大乐透历史数据中的趋势和模式,例如号码的周期性出现、奖项的中奖频率等。
这些分析结果可以帮助您更好地理解大乐透的历史数据特征和规律,提供一些参考信息,但并不能保证预测未来的开奖结果。彩票是一种随机的游戏,结果是无法预测的,这些分析结果仅供参考和娱乐。
总之,对于这些数据分析的结果知道想要“一夜暴富”真的蛮难的哦!彩票这种东西是缥缈的,所以大家好好上学,多学知识,这样才能不断完善自身,实现间接性“一夜暴富”。