一、选题背景介绍
本课题是对学生成绩的分析,本课题用到的数据是从美国的三所高中收集的,用来分析学生成绩和各个方面的关系和影响。
二、数据分析的设计方案
1.导入一些必要的包,为接下来的项目做准备
2.对数据进行预处理,处理一些空数据和没必要的数据
3.把数据分析后的结果用可视化图表展示出来
三、数据集介绍
数据集介绍:
• Gender: 学生的性别(男/女)
• Race/ethnicity: 学生的种族或民族背景(亚洲人、非裔美国人、西班牙裔等)
• Parental level of education: 学生的父母或监护人所获得的最高教育水平
• Lunch: 学生是否获得免费或减价午餐(是/否)
• Test preparation course: 学生是否准备了考试
• Math score: 数学考试中的得分
• Reading score: 阅读考试中的分数
• Writing score:写作考试的分数
四、程序介绍
1.导入必要的包
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 import seaborn as sns 4 import numpy as np 5 plt.rcParams["font.sans-serif"] = "SimHei" 6 plt.rcParams["axes.unicode_minus"] = False 7 file_path = 'C:/Users/Viaa/pythoncode/shujv/exams.csv' 8 data = pd.read_csv(file_path) 9 data.head()
2.对数据进行清洗
1 # 缺失 2 data.dropna(inplace=True) 3 # 去重 4 data.drop_duplicates(inplace=True) 5 data.to_csv('C:/Users/Viaa/pythoncode/shujv/exams.csv', index=False)
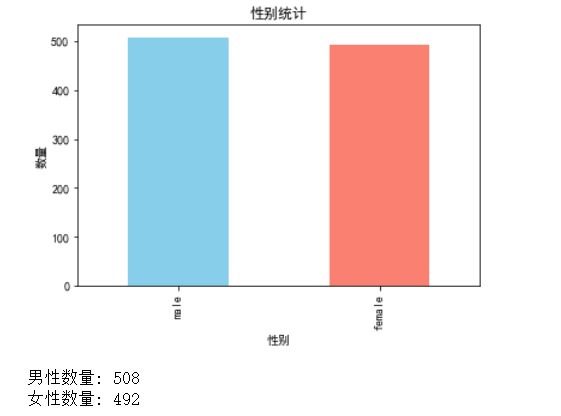
3.统计男女数量
1 gendercounts = data['gender'].value_counts() 2 plt.figure(figsize=(6, 4)) 3 gendercounts.plot(kind='bar', color=['skyblue', 'salmon']) 4 plt.title('性别统计') 5 plt.xlabel("性别") 6 plt.ylabel('数量') 7 plt.show() 8 print('男性数量:',gendercounts['male']) 9 print('女性数量:',gendercounts['female'])
4.统计民族分布
1 racecounts = data['race/ethnicity'].value_counts() 2 plt.figure(figsize=(8, 8)) 3 plt.pie(race_counts, 4 labels=racecounts.index, 5 autopct='%1.1f%%', 6 startangle=140, 7 colors=['lightgreen', 'lightcoral', 'lightskyblue', 'lightpink', 'lightgrey']) 8 plt.axis('equal') 9 plt.title('种族/民族分布') 10 plt.show()
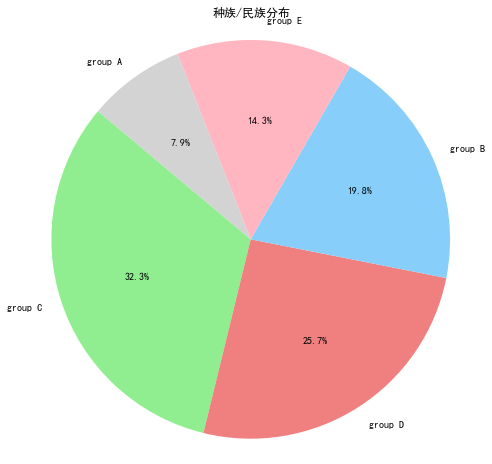
根据图表可以看出来,group c和group d 就占据了接58%,剩下group b占据19.8%,group e占据14.3%,group a占据7.9%。
5.父母教育水平分布
1 plt.figure(figsize=(16, 6)) 2 3 # 绘制条形图 4 ax = sns.countplot(data=data, x='parental level of education') 5 6 # 添加数量标签 7 for p in ax.patches: 8 ax.annotate(f'{p.get_height()}', 9 (p.get_x() + p.get_width() / 2, 10 p.get_height()), ha='center', va='bottom') 11 12 plt.title('父母教育水平分布') 13 plt.xlabel('教育水平') 14 plt.ylabel('数量') 15 plt.xticks(rotation=45, ha='right') 16 17 plt.show()
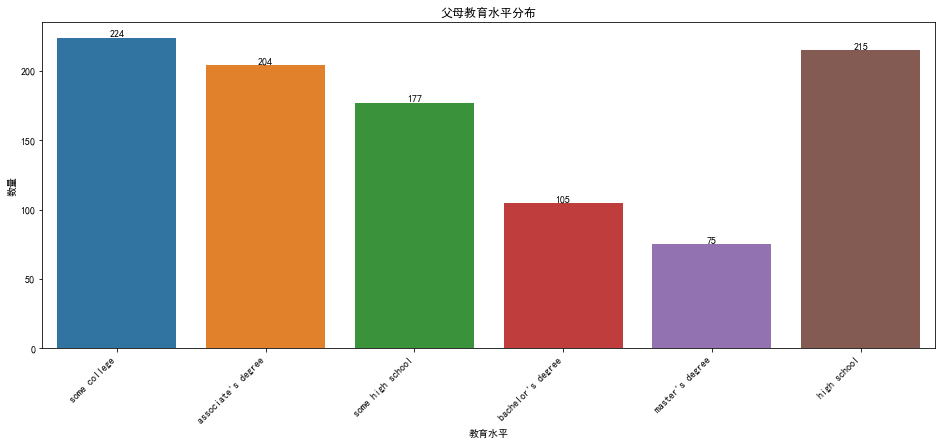
观察柱形图可以看出来,some college(大学,但没有学位),associate's degree(副学士)和high school(高中)三者的数量是差不多的。
some high school(高中但没有毕业)的数量就比最高的三者降了15%。
bachelor's degree(学士)的数量则倒数第二,人数来到了105。
master's degree(硕士)的数量则是最后一名,人数才有75。
可以从以上数据分析出来,学历最高的两批反而是人数最少,这从侧面说明了高学历的稀少和珍贵性。
最多的三者数量都是差不了多少的,说明在学生群体里,这三者教育水平的家庭占据多数。
6.统计学生是否有免费或者优惠午餐
1 lunchcounts = data['lunch'].value_counts() 2 plt.figure(figsize=(6, 6)) 3 sns.barplot(x=lunchcounts.index, y=lunchcounts) 4 # 在每个条形上方添加具体数量 5 for i, count in enumerate(lunchcounts): 6 plt.text(i, count, 7 str(count), 8 ha='center', 9 va='bottom') 10 plt.title('学生是否获得免费或优惠午餐') 11 plt.xlabel('午餐') 12 plt.ylabel('数量') 13 plt.show()
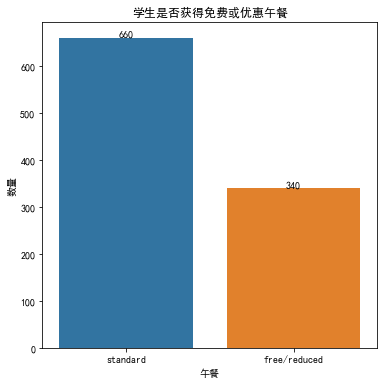
三分之一的学生是有免费/优惠午餐的,剩下的三分之二则没有
7.绘制三科成绩的箱线图
1 fig, axs = plt.subplots(1, 3, figsize=(15, 5)) 2 # 数学 3 sns.boxplot(data=data, x='math score', ax=axs[0]) 4 axs[0].set_title('数学成绩分布') 5 axs[0].set_xlabel('数学成绩') 6 7 # 阅读 8 sns.boxplot(data=data, x='reading score', ax=axs[1]) 9 axs[1].set_title('阅读成绩分布') 10 axs[1].set_xlabel('阅读成绩') 11 12 # 成绩 13 sns.boxplot(data=data, x='writing score', ax=axs[2]) 14 axs[2].set_title('写作成绩分布') 15 axs[2].set_xlabel('写作成绩') 16 # 调整子图之间的间距 17 plt.tight_layout() 18 # 显示图形 19 plt.show()
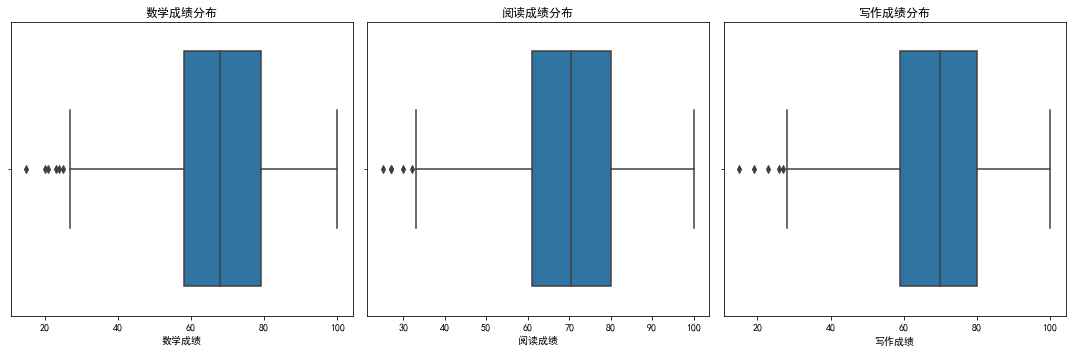
可以通过箱线图看出来。这三者的成绩分布差别并不是很大
8.种族分布与家长教育水平关系热力图
1 # 种族分布和家长教育水平 2 # 创建交叉表 3 jxtable = pd.crosstab(data['race/ethnicity'], data['parental level of education']) 4 5 plt.figure(figsize=(12, 10)) 6 7 # 使用Seaborn绘制热力图 8 sns.heatmap( 9 jxtable, 10 cmap='YlGnBu', 11 annot=True, 12 fmt='d' 13 ) 14 15 plt.title('种族分布和家长教育水平的关系') 16 plt.xlabel('家长教育水平') 17 plt.ylabel('种族分布') 18 19 plt.show()

通过以上热力图可以观察出来 group c中的Associate's Degree、high school和some college的颜色比较深,说明此处人数比较多。
gourp a和gourp c的叫教育水平颜色都比较淡,说明这两个种族人数都比较少。
9.备考是否完成人数
1 testcount = data['test preparation course'].value_counts() 2 plt.figure(figsize=(8, 6)) 3 testcount.plot(kind='bar', color='blue',alpha=0.6) 4 plt.title('备考是否完成') 5 plt.xlabel('是否完成') 6 plt.ylabel('人数') 7 plt.show()
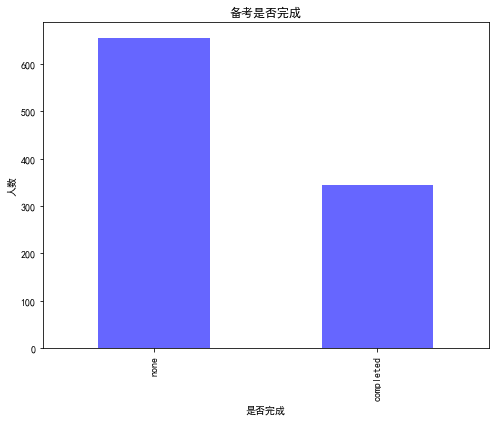
10.备考完成与性别的关系
1 jxtable = pd.crosstab(data['gender'], data['test preparation course']) 2 3 plt.figure(figsize=(8, 6)) 4 5 sns.barplot(x=['Male', 'Female'], 6 y=[jxtable.loc['male', 'completed'], 7 jxtable.loc['female', 'completed']], 8 palette=['blue', 'pink']) 9 10 plt.title('备考已完成与性别的关系') 11 plt.xlabel('性别与备考情况') 12 plt.ylabel('数量') 13 14 plt.show()

通过柱状图可以看的出来,女生的备考情况比男生略高,同时女生在整个数据里面是少于男生的,这说明了女生会更偏向考前复习。
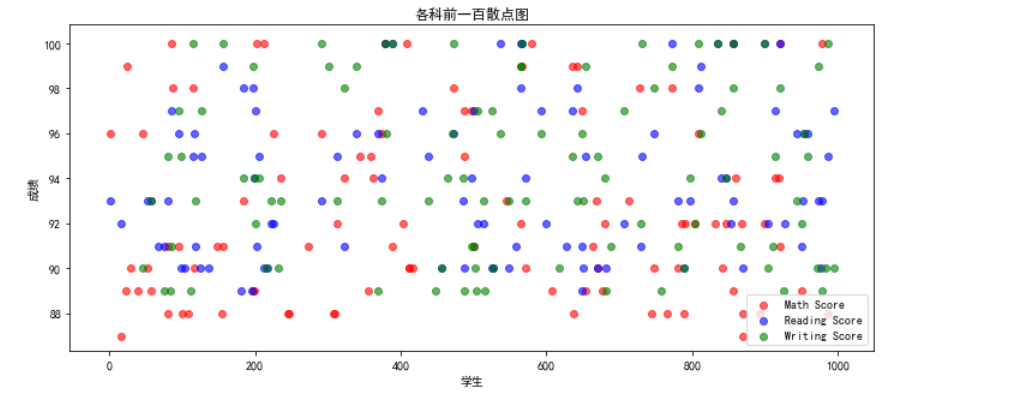
11.各科前一百名的分布散点图
1 # 根据math score的值对数据进行排序 2 sorted_data = data.sort_values('math score', ascending=False) 3 # 获取数学前一百名学生的分数 4 math100 = sorted_data.head(100)[['math score']] 5 6 # 根据reading score的值对数据进行排序 7 sorted_data = data.sort_values('reading score', ascending=False) 8 # 获取阅读前一百名学生的分数 9 reading100 = sorted_data.head(100)[['reading score']] 10 11 # 根据writing score的值对数据进行排序 12 sorted_data = data.sort_values('writing score', ascending=False) 13 # 获取写作前一百名学生的分数 14 writ100 = sorted_data.head(100)[['writing score']] 15 16 fig, ax = plt.subplots(figsize=(12, 5)) 17 # 散点图 18 ax.scatter(math100.index, 19 math100['math score'], 20 c='red', 21 marker='o', 22 label='Math Score', 23 alpha=0.6) 24 25 ax.scatter(reading100.index, 26 reading100['reading score'], 27 c='blue', marker='o', 28 label='Reading Score', 29 alpha=0.6) 30 31 ax.scatter(writ100.index, 32 writ100['writing score'], 33 c='green', 34 marker='o', 35 label='Writing Score', 36 alpha=0.6) 37 38 ax.set_xlabel('学生') 39 ax.set_ylabel('成绩') 40 ax.set_title('各科前一百散点图') 41 ax.legend(loc='lower right') 42 # 展示图形 43 plt.show()
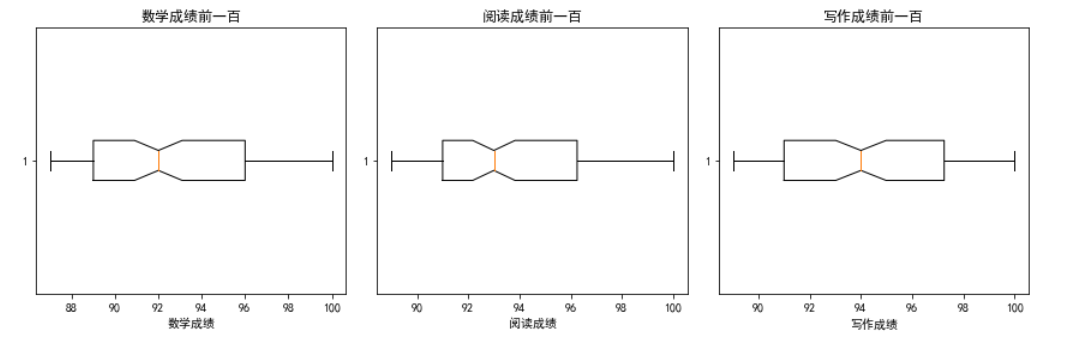
12.三科前一百名箱线图
fig, axs = plt.subplots(1, 3, figsize=(12, 4)) # 数学分数 axs[0].boxplot(math100['math score'], notch=True, vert=False) axs[0].set_xlabel('数学成绩') axs[0].set_title('数学成绩前一百') # 阅读 axs[1].boxplot(reading100['reading score'], notch=True, vert=False) axs[1].set_xlabel('阅读成绩') axs[1].set_title('阅读成绩前一百') # 写作 axs[2].boxplot(writ100['writing score'], notch=True, vert=False) axs[2].set_xlabel('写作成绩') axs[2].set_title('写作成绩前一百') # 间距 fig.tight_layout() # 展示图形 plt.show()
13.三科前一百的趋势图
1 import matplotlib.pyplot as plt 2 3 # 数学折线图 4 plt.plot(range(1, 101), 5 math100['math score'].values, 6 label='Math Score', 7 marker='o') 8 9 # 阅读折线图 10 plt.plot(range(1, 101), 11 reading100['reading score'].values, 12 label='Reading Score', 13 marker='o') 14 15 # 写作折线图 16 plt.plot(range(1, 101), 17 writ100['writing score'].values, 18 label='Writing Score', 19 marker='o') 20 21 plt.title('各科前一百名的成绩') 22 plt.xlabel('排名') 23 plt.ylabel('成绩') 24 plt.legend() 25 plt.show()
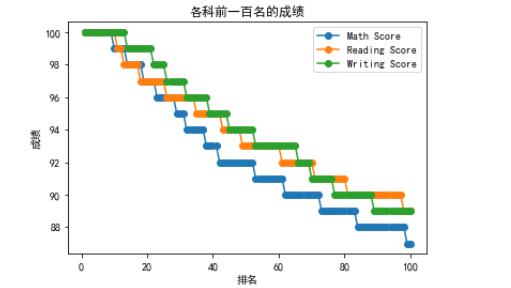
可以看的出来写作成绩和阅读成绩前一百名的成绩下降趋势是差不多的
而数学成绩则下降趋势会比另外两科更快点,这也正说明了数学成绩前一百名的学生成绩浮动是比两外两科大的
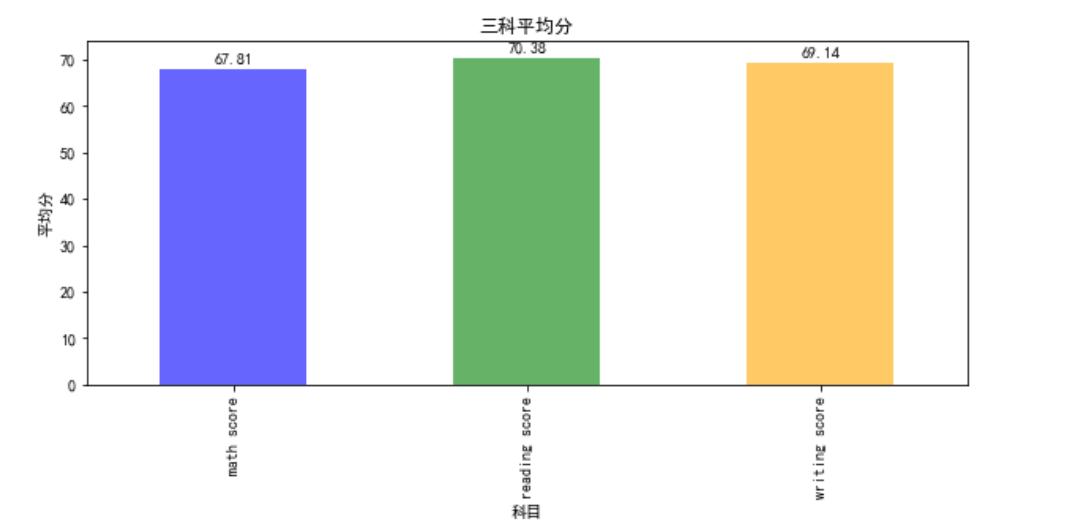
14.计算三科平均分
1 scoresavg = data[['math score', 'reading score', 'writing score']].mean() 2 3 # 绘制柱形图 4 plt.figure(figsize=(10, 4)) 5 scoresavg.plot(kind='bar', color=['blue', 'green', 'orange'],alpha=0.6) 6 plt.title('三科平均分') 7 plt.xlabel('科目') 8 plt.ylabel('平均分') 9 # 在柱形图上显示平均分 10 for i, v in enumerate(scoresavg): 11 plt.text(i, v + 1, str(round(v, 2)), ha='center', va='bottom') 12 plt.show()
15.用性别分组三科平均分
1 # 计算平均分 2 avg_scores_by_gender = data.groupby('gender')[['math score', 'reading score', 'writing score']].mean() 3 n = len(avg_scores_by_gender) 4 bar_width = 0.35 5 index = np.arange(len(avg_scores_by_gender.columns)) 6 7 # 绘制柱形图并显示平均分 8 fig, ax = plt.subplots() 9 bar1 = ax.bar(index - bar_width/2, avg_scores_by_gender.loc['female'], bar_width, label='Female', color='blue',alpha=0.6) 10 bar2 = ax.bar(index + bar_width/2, avg_scores_by_gender.loc['male'], bar_width, label='Male', color='green',alpha=0.6) 11 12 ax.set_xlabel('学科') 13 ax.set_ylabel('平均成绩') 14 ax.set_title('用性别分组三科平均分') 15 ax.set_xticks(index) 16 ax.set_xticklabels(avg_scores_by_gender.columns) 17 ax.legend() 18 19 def autolabel(bars): 20 for bar in bars: 21 height = bar.get_height() 22 ax.annotate('{}'.format(round(height, 2)), 23 xy=(bar.get_x() + bar.get_width() / 2, height), 24 xytext=(0, 3), 25 textcoords="offset points", 26 ha='center', va='bottom') 27 28 autolabel(bar1) 29 autolabel(bar2) 30 ax.legend(loc='lower right') 31 plt.show()
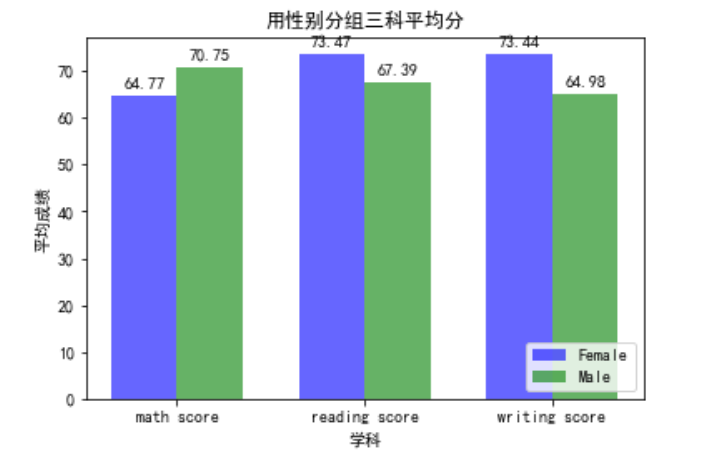
通过图表可以分析中男生是比较擅长数学这个学科的,而女生则更加擅长写作和阅读这两门学科。
16.各个成绩分布人数
1 fig, axes = plt.subplots(1, 3, figsize=(15, 5)) 2 axes[0].hist(data['math score'], bins=20, color='pink') 3 axes[0].set_title('数学成绩分布') 4 axes[0].set_xlabel('数学成绩') 5 axes[0].set_ylabel('人数') 6 7 axes[1].hist(data['reading score'], bins=20, color='orange') 8 axes[1].set_title('阅读成绩分布') 9 axes[1].set_xlabel('阅读成绩') 10 axes[1].set_ylabel('人数') 11 12 axes[2].hist(data['writing score'], bins=20, color='red') 13 axes[2].set_title('写作成绩分布') 14 axes[2].set_xlabel('写作成绩') 15 axes[2].set_ylabel('人数') 16 17 plt.tight_layout() 18 plt.show()
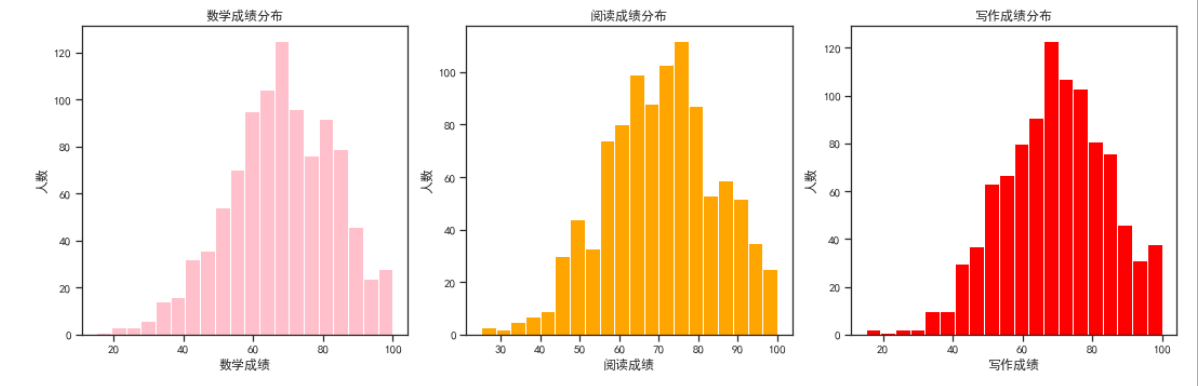
通过上图可以分析出,数学成绩大部分是集中于60-70之间,阅读成绩则大部分集中于70-80之间,写作则大部分集中于65-75之间。
结合三个图表来看,大部分都是集中于60-80这个分数段。
17.按父母教育水平分类三科平均分
1 # 计算平均分 2 average_scores = data.groupby('parental level of education')[['math score', 'reading score', 'writing score']].mean() 3 4 # 绘制条形图 5 average_scores.plot(kind='bar', figsize=(12, 8),width=0.8) 6 plt.title('按父母教育水平分类三科平均分') 7 plt.xlabel('父母教育水平') 8 plt.ylabel('平均分') 9 plt.xticks(rotation=0) 10 plt.legend(loc='upper right') 11 plt.legend(loc='lower right') 12 13 plt.show()
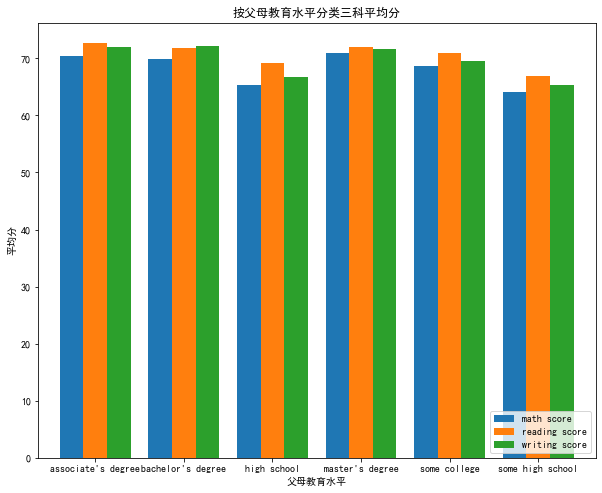
可以很直观的从图表中看的出来High School(高中)和Some High School(高中但没有毕业),的家庭孩子三科平均分会普遍比其它家庭出身的孩子会低不少。
这也正说明了父母教育水平对孩子成绩以及未来的影响
18.统计三科都在同一分数段的人数
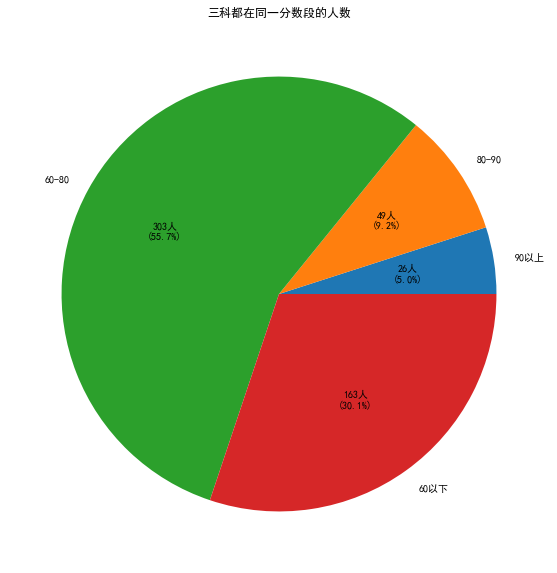 、
、
通过上图可以很直观的看出来三科都在60-80的学生人数最多,说明大部分学生都处于这个水平。
还有163人三个科目都处于60分以下,这说明这163人不是因为偏科而成绩较差,而是成绩普遍较差。
还有49人处于80-90分之间,90分以上有26人,说明这两批人是学习成绩不错且没有偏科或过分偏科的人。
完整代码
1 import pandas as pd 2 import matplotlib.pyplot as plt 3 import seaborn as sns 4 import numpy as np 5 plt.rcParams["font.sans-serif"] = "SimHei" 6 plt.rcParams["axes.unicode_minus"] = False 7 file_path = 'C:/Users/Viaa/pythoncode/shujv/exams.csv' 8 data = pd.read_csv(file_path) 9 data.head() 10 11 # #检查数据是否有空值 12 # print(data.isnull().sum()) 13 # #检查数据是否有重复值 14 # print('重复值数量:',data.duplicated().sum()) 15 # data.info() 16 # 缺失 17 data.dropna(inplace=True) 18 # 去重 19 data.drop_duplicates(inplace=True) 20 data.to_csv('C:/Users/Viaa/pythoncode/shujv/exams.csv', index=False) 21 22 gendercounts = data['gender'].value_counts() 23 plt.figure(figsize=(6, 4)) 24 gendercounts.plot(kind='bar', color=['skyblue', 'salmon']) 25 plt.title('性别统计') 26 plt.xlabel("性别") 27 plt.ylabel('数量') 28 plt.show() 29 print('男性数量:',gendercounts['male']) 30 print('女性数量:',gendercounts['female']) 31 32 racecounts = data['race/ethnicity'].value_counts() 33 plt.figure(figsize=(8, 8)) 34 plt.pie(race_counts, 35 labels=racecounts.index, 36 autopct='%1.1f%%', 37 startangle=140, 38 colors=['lightgreen', 'lightcoral', 'lightskyblue', 'lightpink', 'lightgrey']) 39 plt.axis('equal') 40 plt.title('种族/民族分布') 41 plt.show() 42 43 plt.figure(figsize=(16, 6)) 44 45 # 绘制条形图 46 ax = sns.countplot(data=data, x='parental level of education') 47 48 # 添加数量标签 49 for p in ax.patches: 50 ax.annotate(f'{p.get_height()}', 51 (p.get_x() + p.get_width() / 2, 52 p.get_height()), ha='center', va='bottom') 53 54 plt.title('父母教育水平分布') 55 plt.xlabel('教育水平') 56 plt.ylabel('数量') 57 plt.xticks(rotation=45, ha='right') 58 59 plt.show() 60 61 lunchcounts = data['lunch'].value_counts() 62 plt.figure(figsize=(6, 6)) 63 sns.barplot(x=lunchcounts.index, y=lunchcounts) 64 # 在每个条形上方添加具体数量 65 for i, count in enumerate(lunchcounts): 66 plt.text(i, count, 67 str(count), 68 ha='center', 69 va='bottom') 70 plt.title('学生是否获得免费或优惠午餐') 71 plt.xlabel('午餐') 72 plt.ylabel('数量') 73 plt.show() 74 75 fig, axs = plt.subplots(1, 3, figsize=(15, 5)) 76 # 数学 77 sns.boxplot(data=data, x='math score', ax=axs[0]) 78 axs[0].set_title('数学成绩分布') 79 axs[0].set_xlabel('数学成绩') 80 81 # 阅读 82 sns.boxplot(data=data, x='reading score', ax=axs[1]) 83 axs[1].set_title('阅读成绩分布') 84 axs[1].set_xlabel('阅读成绩') 85 86 # 成绩 87 sns.boxplot(data=data, x='writing score', ax=axs[2]) 88 axs[2].set_title('写作成绩分布') 89 axs[2].set_xlabel('写作成绩') 90 # 调整子图之间的间距 91 plt.tight_layout() 92 # 显示图形 93 plt.show() 94 95 # 种族分布和家长教育水平热力图 96 # 创建交叉表 97 jxtable = pd.crosstab(data['race/ethnicity'], data['parental level of education']) 98 99 plt.figure(figsize=(12, 10)) 100 101 # 使用Seaborn绘制热力图 102 sns.heatmap( 103 jxtable, 104 cmap='YlGnBu', 105 annot=True, 106 fmt='d' 107 ) 108 109 plt.title('种族分布和家长教育水平的关系') 110 plt.xlabel('家长教育水平') 111 plt.ylabel('种族分布') 112 113 plt.show() 114 115 # 统计备考是否完成 116 testcount = data['test preparation course'].value_counts() 117 plt.figure(figsize=(8, 6)) 118 testcount.plot(kind='bar', color='blue',alpha=0.6) 119 plt.title('备考是否完成') 120 plt.xlabel('是否完成') 121 plt.ylabel('人数') 122 plt.show() 123 124 # 备考完成与性别的关系 125 jxtable = pd.crosstab(data['gender'], data['test preparation course']) 126 127 plt.figure(figsize=(8, 6)) 128 129 sns.barplot(x=['Male', 'Female'], 130 y=[jxtable.loc['male', 'completed'], 131 jxtable.loc['female', 'completed']], 132 palette=['blue', 'pink']) 133 134 plt.title('备考已完成与性别的关系') 135 plt.xlabel('性别与备考情况') 136 plt.ylabel('数量') 137 138 plt.show() 139 140 # 各科前一百散点图 141 # 根据math score的值对数据进行排序 142 sorted_data = data.sort_values('math score', ascending=False) 143 # 获取数学前一百名学生的分数 144 math100 = sorted_data.head(100)[['math score']] 145 146 # 根据reading score的值对数据进行排序 147 sorted_data = data.sort_values('reading score', ascending=False) 148 # 获取阅读前一百名学生的分数 149 reading100 = sorted_data.head(100)[['reading score']] 150 151 # 根据writing score的值对数据进行排序 152 sorted_data = data.sort_values('writing score', ascending=False) 153 # 获取写作前一百名学生的分数 154 writ100 = sorted_data.head(100)[['writing score']] 155 156 fig, ax = plt.subplots(figsize=(12, 5)) 157 # 散点图 158 ax.scatter(math100.index, 159 math100['math score'], 160 c='red', 161 marker='o', 162 label='Math Score', 163 alpha=0.6) 164 165 ax.scatter(reading100.index, 166 reading100['reading score'], 167 c='blue', marker='o', 168 label='Reading Score', 169 alpha=0.6) 170 171 ax.scatter(writ100.index, 172 writ100['writing score'], 173 c='green', 174 marker='o', 175 label='Writing Score', 176 alpha=0.6) 177 178 ax.set_xlabel('学生') 179 ax.set_ylabel('成绩') 180 ax.set_title('各科前一百散点图') 181 ax.legend(loc='lower right') 182 # 展示图形 183 plt.show() 184 185 # 三科成绩前一百箱线图 186 fig, axs = plt.subplots(1, 3, figsize=(12, 4)) 187 # 数学分数 188 axs[0].boxplot(math100['math score'], notch=True, vert=False) 189 axs[0].set_xlabel('数学成绩') 190 axs[0].set_title('数学成绩前一百') 191 # 阅读 192 axs[1].boxplot(reading100['reading score'], notch=True, vert=False) 193 axs[1].set_xlabel('阅读成绩') 194 axs[1].set_title('阅读成绩前一百') 195 # 写作 196 axs[2].boxplot(writ100['writing score'], notch=True, vert=False) 197 axs[2].set_xlabel('写作成绩') 198 axs[2].set_title('写作成绩前一百') 199 # 间距 200 fig.tight_layout() 201 202 # 展示图形 203 plt.show() 204 205 import matplotlib.pyplot as plt 206 # 各科前一百名趋势图 207 208 # 数学折线图 209 plt.plot(range(1, 101), 210 math100['math score'].values, 211 label='Math Score', 212 marker='o') 213 214 # 阅读折线图 215 plt.plot(range(1, 101), 216 reading100['reading score'].values, 217 label='Reading Score', 218 marker='o') 219 220 # 写作折线图 221 plt.plot(range(1, 101), 222 writ100['writing score'].values, 223 label='Writing Score', 224 marker='o') 225 226 plt.title('各科前一百名的成绩') 227 plt.xlabel('排名') 228 plt.ylabel('成绩') 229 plt.legend() 230 plt.show() 231 232 # 三科平均分 233 scoresavg = data[['math score', 'reading score', 'writing score']].mean() 234 235 plt.figure(figsize=(10, 4)) 236 scoresavg.plot(kind='bar', color=['blue', 'green', 'orange'],alpha=0.6) 237 plt.title('三科平均分') 238 plt.xlabel('科目') 239 plt.ylabel('平均分') 240 # 在柱形图上显示平均分 241 for i, v in enumerate(scoresavg): 242 plt.text(i, v + 1, str(round(v, 2)), ha='center', va='bottom') 243 plt.show() 244 245 # 性别分组三科平均分 246 avg_scores_by_gender = data.groupby('gender')[['math score', 'reading score', 'writing score']].mean() 247 n = len(avg_scores_by_gender) 248 bar_width = 0.35 249 index = np.arange(len(avg_scores_by_gender.columns)) 250 251 # 绘制柱形图并显示平均分 252 fig, ax = plt.subplots() 253 bar1 = ax.bar(index - bar_width/2, avg_scores_by_gender.loc['female'], bar_width, label='Female', color='blue',alpha=0.6) 254 bar2 = ax.bar(index + bar_width/2, avg_scores_by_gender.loc['male'], bar_width, label='Male', color='green',alpha=0.6) 255 256 ax.set_xlabel('学科') 257 ax.set_ylabel('平均成绩') 258 ax.set_title('用性别分组三科平均分') 259 ax.set_xticks(index) 260 ax.set_xticklabels(avg_scores_by_gender.columns) 261 ax.legend() 262 263 def autolabel(bars): 264 for bar in bars: 265 height = bar.get_height() 266 ax.annotate('{}'.format(round(height, 2)), 267 xy=(bar.get_x() + bar.get_width() / 2, height), 268 xytext=(0, 3), 269 textcoords="offset points", 270 ha='center', va='bottom') 271 272 autolabel(bar1) 273 autolabel(bar2) 274 ax.legend(loc='lower right') 275 plt.show() 276 277 # 各个成绩分布人数 278 fig, axes = plt.subplots(1, 3, figsize=(15, 5)) 279 axes[0].hist(data['math score'], bins=20, color='pink') 280 axes[0].set_title('数学成绩分布') 281 axes[0].set_xlabel('数学成绩') 282 axes[0].set_ylabel('人数') 283 284 axes[1].hist(data['reading score'], bins=20, color='orange') 285 axes[1].set_title('阅读成绩分布') 286 axes[1].set_xlabel('阅读成绩') 287 axes[1].set_ylabel('人数') 288 289 axes[2].hist(data['writing score'], bins=20, color='red') 290 axes[2].set_title('写作成绩分布') 291 axes[2].set_xlabel('写作成绩') 292 axes[2].set_ylabel('人数') 293 294 plt.tight_layout() 295 plt.show() 296 297 # 按父母教育水平分类三科平均分 298 average_scores = data.groupby('parental level of education')[['math score', 'reading score', 'writing score']].mean() 299 300 # 绘制条形图 301 average_scores.plot(kind='bar', figsize=(10, 8),width=0.8) 302 plt.title('按父母教育水平分类三科平均分') 303 plt.xlabel('父母教育水平') 304 plt.ylabel('平均分') 305 plt.xticks(rotation=0) 306 plt.legend(loc='upper right') 307 plt.legend(loc='lower right') 308 309 plt.show() 310 311 # 统计三科都在同一分数段的人 312 # 统计90分以上的人数 313 above_90_math = data['math score'] > 90 314 above_90_reading = data['reading score'] > 90 315 above_90_writing = data['writing score'] > 90 316 above_90 = (above_90_math & above_90_reading & above_90_writing).sum() 317 318 # 统计80-90之间的人数 319 between_80_90_math = data['math score'].between(80, 90) 320 between_80_90_reading = data['reading score'].between(80, 90) 321 between_80_90_writing = data['writing score'].between(80, 90) 322 between_80_90 = (between_80_90_math & between_80_90_reading & between_80_90_writing).sum() 323 324 # 统计60-80之间的人数 325 between_60_80_math = data['math score'].between(60, 80) 326 between_60_80_reading = data['reading score'].between(60, 80) 327 between_60_80_writing = data['writing score'].between(60, 80) 328 between_60_80 = (between_60_80_math & between_60_80_reading & between_60_80_writing).sum() 329 330 # 统计60分以下的人数 331 below_60_math = data['math score'] < 60 332 below_60_reading = data['reading score'] < 60 333 below_60_writing = data['writing score'] < 60 334 below_60 = (below_60_math & below_60_reading & below_60_writing).sum() 335 336 # 创建标签和对应的数量列表 337 labels = ['90以上', '80-90', '60-80', '60以下'] 338 counts = [above_90, between_80_90, between_60_80, below_60] 339 340 # 具体数量方法 341 def countl(pct): 342 count = int(pct / 100 * sum(counts)) 343 return f'{count}人\n({pct:.1f}%)' 344 # 绘制饼图 345 346 plt.figure(figsize=(10, 10)) 347 plt.pie(counts, labels=labels, autopct=countl) 348 plt.title('三科都在同一分数段的人数') 349 plt.show()
5.总结
通过这次数据分析可以看的出来,在学生成绩方面,男生在数学方面更有天赋,而女生则在文科方面学的比较好。
家长的教育水平也影响的孩子的学习成绩,家长教育水平越高,孩子的平均成绩也越高。
关于考试之前是否会备考,女生的会备考的概率比男生更高。
通过成绩分析,大部分都处在60-80这个分数段,还有一小部分人三科都在60分以下,剩下的大概15%的三科成绩都在80分以上。