1. 偏函数
1.1 案例引入
给你一个集合 List(1, 2, 3, 4, "abc"),请完成如下要求:
- 将集合中的所有数字 +1,并返回一个新的集合;
- 要求忽略掉非数字的元素,即返回的新的集合形式为 (2, 3, 4, 5)。
object PrePartialFuncTest {
def main(args: Array[String]): Unit = {
// ===== 思路一:filter + map =====
val origin = List(1, 2, 5, "hello")
def intFilter(n: Any): Boolean = n.isInstanceOf[Int]
def any2Int(n: Any): Int = n.asInstanceOf[Int]
def incr(n: Int) = n + 1
val list1 = origin.filter(intFilter).map(any2Int).map(incr)
println(list1)
// ===== 思路二:模式匹配 =====
def plusOne(i: Any): Any = {
i match {
case x: Int => x + 1
case _ =>
}
}
// List(2, 3, 6, ()) -> List(2, 3, 6)
val list2 = origin.map(plusOne).filter(intFilter)
println(list2)
}
}
1.2 偏函数介绍
偏函数是一种只对特定输入进行定义的函数,对于未定义的输入则不执行任何操作。这意味着你可以为特定的输入定义多个偏函数,而其他输入则会被忽略。在 Scala 中,使用 PartialFunction[A, B] 来表示偏函数,其中 A 是输入类型,B 是输出类型。
现在使用偏函数来解决开头的那个问题:
object PartialFuncTest {
def main(args: Array[String]): Unit = {
// ===== 思路三:偏函数 =====
val partialFunc = new PartialFunction[Any, Int] {
override def isDefinedAt(x: Any): Boolean = {
println("INVOKE isDefinedAt " + x)
x.isInstanceOf[Int]
}
override def apply(x: Any): Int = {
println("INVOKE apply " + x)
x.asInstanceOf[Int] + 1
}
}
val list3 = origin.collect(partialFunc)
println(list3)
}
}
- PartialFunction 是个特质,偏函数即创建 PartialFunction 的匿名子类;
- 构建偏函数时,参数形式 [Any, Int] 是泛型,第一个表示参数类型,第二个表示返回类型。
- 在使用偏函数时,通常会将其应用于一个集合(如列表、数组等),通过遍历集合的元素来逐个检查和处理。偏函数的执行流程通常涉及两个方法:isDefinedAt 和 apply。
- isDefinedAt 方法用于检查给定输入是否在偏函数的定义范围内。对于符合偏函数定义的输入,isDefinedAt 返回 true,否则返回 false。
- apply 方法用于对符合偏函数定义的输入进行实际的处理操作,返回处理结果。
- 应用偏函数的集合遍历要使用 collect 方法。

1.3 偏函数简写
声明偏函数,需要重写特质中的方法,有的时候会略显麻烦,而 Scala 其实提供了简单的写法:case 语句可以自动转换为偏函数。
object PartialFuncTest {
def main(args: Array[String]): Unit = {
// 简写一
val divideByTwo: PartialFunction[Int, Int] = {
case x: Int if x % 2 == 0 => x / 2
case y: Int if y % 5 == 0 => y / 5
case z: Int if z % 9 == 0 => z / 9
}
val result1 = divideByTwo(6)
println(result1) // 3
val result2 = divideByTwo.isDefinedAt(7)
println(result2) // false
// 简写二
val list4 = List(1, 2, 5, "hello").collect { case i: Int => i + 1 }
println(list4)
}
}
在上面的代码中,我们定义了一个偏函数 divideByTwo,它接受一个整数作为输入,并且仅对能够被 2/5/9 整除的输入进行处理。对于其他输入,这个偏函数没有定义。还可以通过使用 isDefinedAt 方法来检查给定的输入是否在偏函数的定义范围内,然后可以直接调用偏函数来处理输入。
反编译后的代码将显示偏函数的实现细节,包括其在编译时生成的匿名类和相关方法。偏函数在 Scala 中是一个特质 PartialFunction。
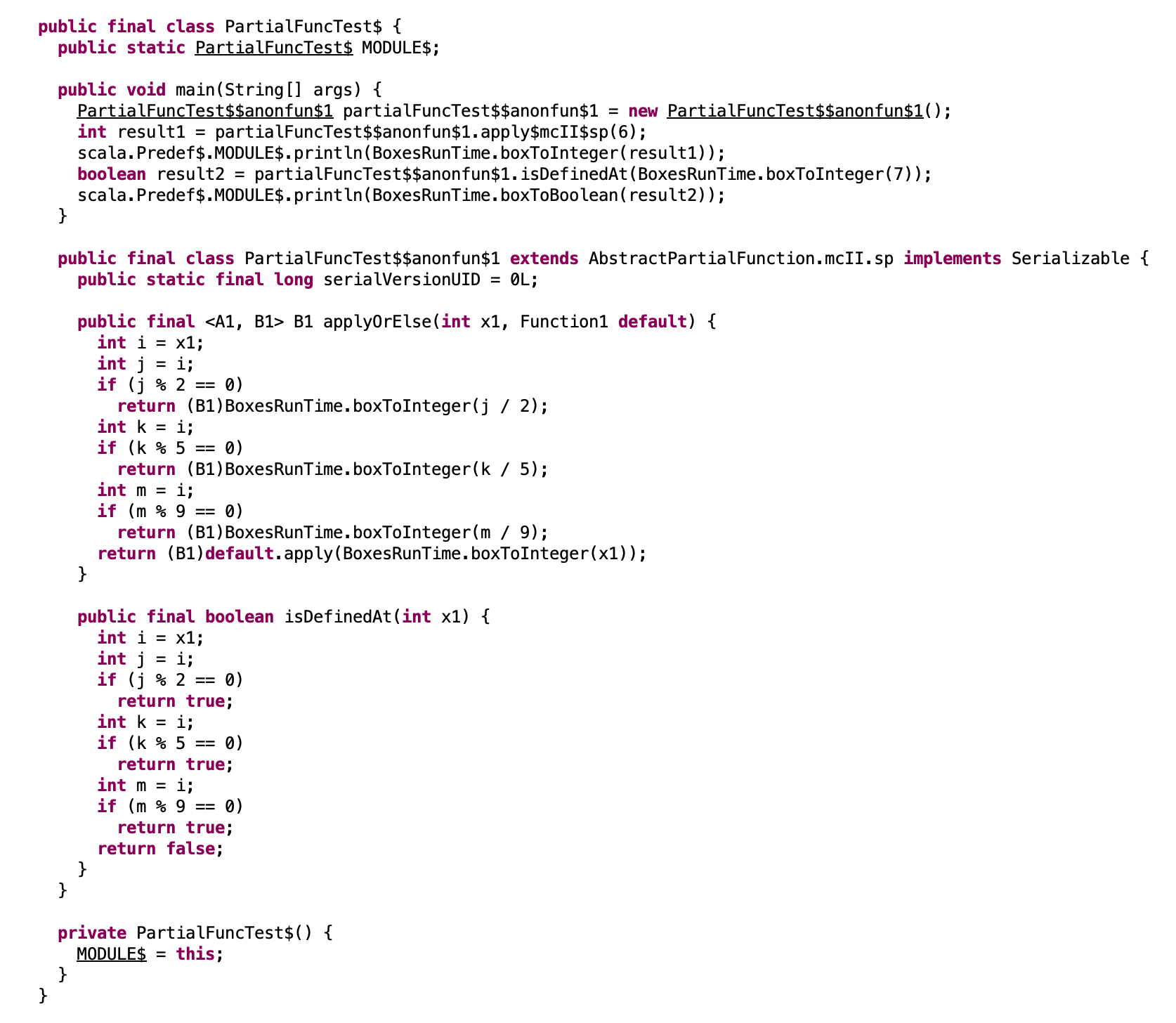
2. 匿名函数
没有名字的函数就是匿名函数,可以通过函数表达式来设置匿名函数。
val triple = (x: Double) => 3 * x
println(triple(3))
(x: Double) => 3 * x就是匿名函数;(x: Double)是形参列表,=>是规定语法表示后面是函数体,3 * x就是函数体,如果有多行,可以{}换行写;triple是指向匿名函数的变量。
在 Scala 中,将一个匿名函数赋值给变量和声明一个函数有以下几点区别:
(1)语法形式
- 函数声明:使用 def 关键字,后跟函数名称和参数列表,并通过等号 = 定义函数体。
- 匿名函数:使用 val 或 var 关键字定义一个变量或可变变量,并通过 => 符号定义匿名函数的参数和函数体。
(2)执行逻辑
- 函数声明:函数声明会在函数被调用时执行函数体中的代码。
- 匿名函数:匿名函数可以直接作为表达式使用,也可以赋值给变量。当匿名函数赋值给变量时,它不会立即执行,而是在后续代码中通过调用该变量时才执行。
(3)反编译结果
- 函数声明:反编译后对应了一个同名的方法,其中包含了函数体的代码。
- 匿名函数:则在反编译后生成了一个实现了 scala.Function1 接口的匿名类,并在构造函数中定义了匿名函数的逻辑。
3. 高阶函数
所有的函数都能被分解成「每次函数调用都一样的公共部分」和「每次调用不一样的非公共部分」。
公共部分是函数体,而非公共部分必须通过实参传入。当你把函数值当作入参的时候,这段算法的非公共部分本身又是另一个算法!每当这样的函数被调用,你都可以传入不同的函数值作为实参,被调用的函数会(在由它选择的时机)调用传入的函数值。这些高阶函数(Higher-Order Functions),即那些接收函数作为参数的函数,让你有额外的机会来进一步压缩和简化代码。
3.1 函数作参
高阶函数的好处之一是可以用来创建减少代码重复的控制抽象。 例如,假定你在编写一个文件浏览器,而你打算提供 API 给用户来查找 匹配某个条件的文件。首先,添加了一个机制用来查找文件名是以指定字符串结尾的文件。比如,这将允许用户查找所有扩展名为“.scala”的文件。可以通过在单例对象中定义一个公共的 filesEnding 方法的方式来提供这样的 API,就像这样:
object FileMatcher {
private def filesHere = new java.io.File(".").listFiles()
def filesEnding(query: String) = {
for (file <- filesHere; if file.getName.endsWith(query)) yield file
}
}
这个 filesEnding 方法用私有的助手方法 filesHere 来获取当前目 录下的所有文件,然后基于文件名是否以用户给定的查询条件结尾来过滤这些文件。由于 filesHere 是私有的,filesEnding 方法就是 FileMatcher(即提供给用户的 API)中定义的唯一一个能被访问到的方法。
到目前为止,一切都很完美,暂时都还没有重复的代码。不过到了后来,用户想要基于文件名的任意部分进行搜索。于是回去给你的 FileMatcher API 添加了这个函数:
def filesContaining(query: String) = {
for (file <- filesHere; if file.getName.contains(query)) yield file
}
这个函数跟 filesEnding 的运行机制没什么两样:搜索 filesHere、检查文件名、如果名字匹配则返回文件。唯一的区别是这个函数用的是 contains 而不是 endsWith。
几个月过去了,这个程序变得更成功了。终于,你对某些高级用户提出的想要基于正则表达式搜索文件的请求屈服了。
def filesRegex(query: String) = {
for (file <- filesHere; if file.getName.matches(query)) yield file
}
有经验的程序员会注意到这些函数中不断重复的代码,有没有办法将它们重构成公共的助手函数呢?按显而易见的方式来并不行。你会想要做到这样的效果:
def filesMatching(query: String, <method>) = {
for (file <- filesHere; if file.getName.<method>(query)) yield file
}
这种方式在某些动态语言中可以做到,但 Scala 并不允许像这样在运行时将代码黏在一起。那怎么办呢?
「函数值」提供了一种答案。虽然不能将方法名像值一样传来传去,但是可以通过传递某个帮你调用方法的函数值来达到同样的效果。在本例中,可以给方法添加一个 matcher 参数,该参数唯一的目的就是检查文件名是否满足某个查询条件:
def filesMatching(query: String, matcher: (String, String) => Boolean) = {
for (file <- filesHere; if matcher(file.getName, query)) yield file
}
在这个版本的方法中,if 子句用 matcher 来检查文件名是否满足查询条件。这个检查具体做什么,取决于给定的 matcher。现在,我们来看看 matcher 这个类型本身。它首先是个函数,因此在类型声明中有个 => 符号。这个函数接收两个字符串类型的参数(分别是文件名和查询条件),返回一个布尔值,因此这个函数的完整类型是 (String, String) => Boolean。
有了这个新的 filesMatching 助手方法,可以将前面三个搜索方法进行简化,调用助手方法,传入合适的函数:
def filesEndings2(query: String) = filesMatching(query, _.endsWith(_))
def filesContaining2(query: String) = filesMatching(query, _.contains(_))
def filesRegex2(query: String) = filesMatching(query, _.matches(_))
本例中展示的函数字面量用的是占位符语法:filesEnding 方法里的函数字面量 _.endsWith(_) 的含义跟下面这段代码是一样的:
(fileName: String, query: String) => fileName.endsWith(query)
由于 filesMatching 接收一个要求两个 String 入参的函数,并不需要显式地给出入参的类型,可以直接写 (fileName, query) => fileName.endsWith(query)。又因为这两个参数在函数体内分别只用到一次(第 1 个参数 fileName 先被用到,然后是第2 个参数 query),可以用占位符语法来写:_.endsWith(_)。第一个下划线是第 1 个参数(即文件名)的占位符,而第二个下划线是第 2 个参数(即查询字符串)的占位符。
这段代码已经很简化了,不过实际上还能更短。注意这里的查询字符串 query 被传入 filesMatching 后,filesMatching 并不对它做任何处理,只是将它传入 matcher 函数。这样的来回传递是不必要的,因为调用者已经知道这个查询字符串了!完全可以将 query 参数从 filesMatching 和 matcher 中移除,这样就得到下述示例代码。
def filesMatching(matcher: String => Boolean) = {
for (file <- filesHere; if matcher(file.getName)) yield file
}
def filesEndings(query: String) = filesMatching(_.endsWith(query))
def filesContaining(query: String) = filesMatching(_.contains(query))
def filesRegex(query: String) = filesMatching(_.matches(query))
这个例子展示了一等函数是如何帮助你消除代码重复的,没有它们,我们很难做到这样。
不仅如此,这个示例还展示了闭包是如何帮助我们减少代码重复的。前一例中我们用到的函数字面量,比如 _.endsWith(_) 和 _.containts(_),都是在运行时被实例化成函数值的,它们并不是闭包,因为它们并不捕获任何自由变量。举例来说,在表达式 _.endsWith(_) 中用到的两个变量都是由下划线表示的,这意味着它们取自该函数的入参。因此,_.endsWith(_) 使用了两个绑定变量,并没有使用任何自由变量。
相反,在最新的这个例子中,函数字面量 _.endsWith(query) 包含了一个绑定变量,即用下划线表示的那一个,和一个名为 query 的自由变量。正因为 Scala 支持闭包,你才能在最新的这个例子中将 query 参数从 filesMatching 中拿掉,从而更进一步简化代码。
高阶函数除了帮助我们在实现 API 时减少代码重复,还有另一个重要的用处是将高阶函数本身放在 API 当中来让调用方代码更加精简(详见《集合操作》)。
3.2 函数特质
Scala 的函数实际上是基于函数类型 trait 的实例。每个函数都有一个对应的函数类型,这个函数类型实际上是一个特质(trait),被称为函数特质(Function Trait)。Scala 提供了一组函数特质,分别对应不同个数的参数和返回值类型。
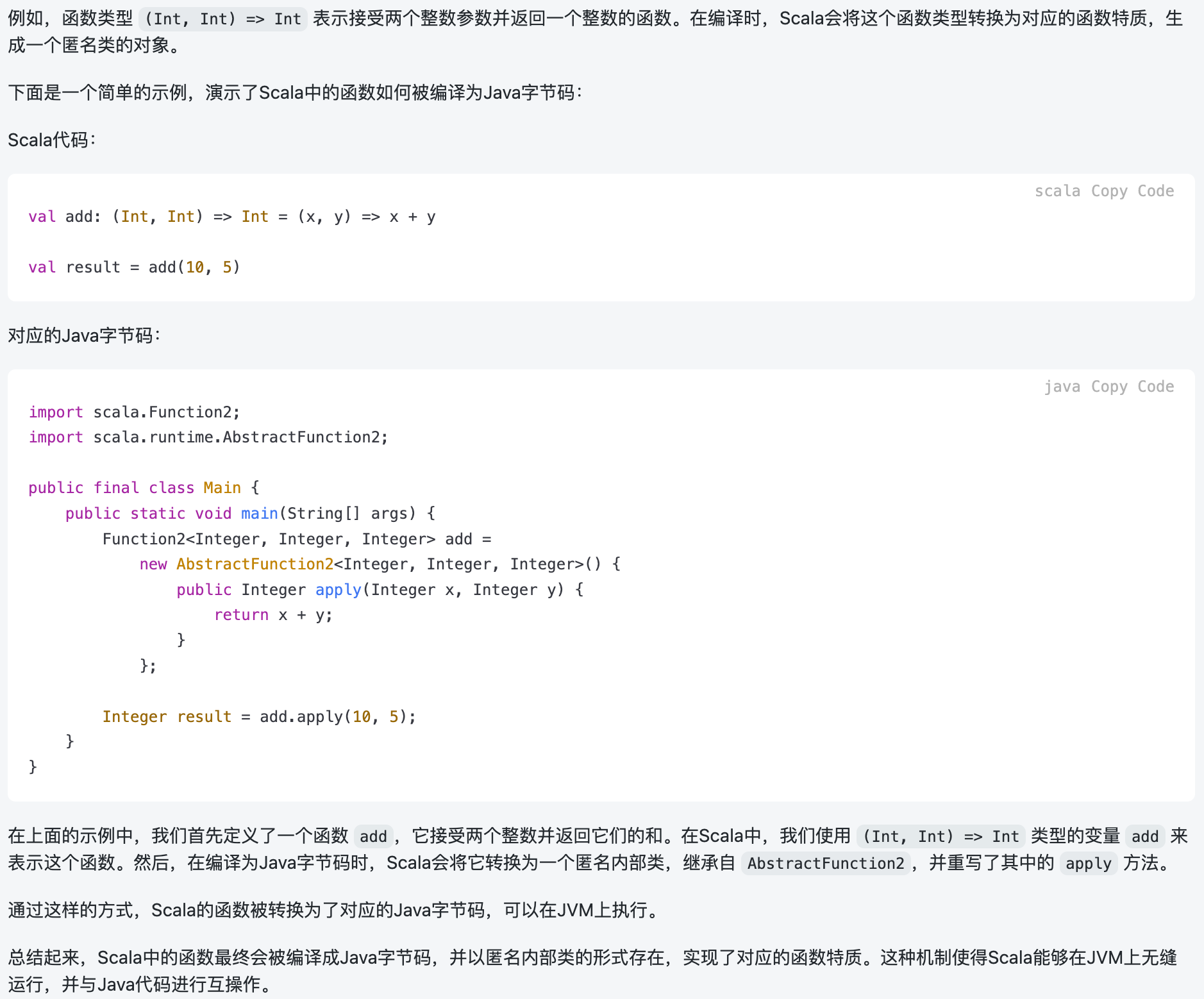
3.3 返回函数
高阶函数可以返回函数类型。
def minusXY(x: Int) = (y: Int) => x - y
// 先执行 minusXY(6) 得到 (y: Int) => 6 - y 这个匿名函数,然后 minusXY(6)(7) 再执行 (y: Int) => 6 - y 这个匿名函数,得到结果 -1。
val result1 = minusXY(6)(7)
println(result1)
// 也可以分步执行
val tmpFunc = minusXY(1)
val result2 = tmpFunc(2)
println(result2)
4. 参数类型推断
Scala 是一门具有强大类型推断能力的编程语言。在 Scala 中,参数类型推断是指编译器能够自动推断函数或方法的参数类型,而无需显式地指定类型信息。参数类型推断的工作原理是根据函数或方法的上下文和表达式的类型进行类型推断。
/**
* @author tree6x7
* @createTime 2023/8/22
* 参数类型推断写法说明:
* 1) 参数类型是可以推断时,可以省略参数类型
* > list.map((x) => x + 1)
* 2) 当传入的函数只有单个参数时,可以省去括号
* > list.map(x => x + 1)
* 3) 如果变量只在 => 右边只出现一次,可以用 `_` 来代替
* > list.map(_ + 1)
*/
object TypeInferenceTest {
def main(args: Array[String]): Unit = {
val list = List(1, 2, 3, 4)
val ret1 = list.map((x: Int) => x + 1)
val ret2 = list.map((x) => x + 1)
val ret3 = list.map(x => x + 1)
val ret4 = list.map(_ + 1)
def f1(n1: Int, n2: Int): Int = n1 + n2
val ret5 = list.reduce(f1)
val ret6 = list.reduce((n1: Int, n2: Int) => n1 + n2)
val ret7 = list.reduce((n1, n2) => n1 + n2)
val ret8 = list.reduce(_ + _)
}
}
5. 闭包
简单粗糙理解:闭包(Closure)是指在一个函数内部定义的函数,它可以访问和操作函数外部的变量。具体来说,闭包包含两部分内容:一个是函数本身,另一个是该函数所在的环境(包括函数定义时所在的作用域和上层作用域中的变量)。
到目前为止,所有的函数字面量示例,都只是引用了传入的参数。不过,也可以引用其他地方定义的变量:
addMore 这个函数将 more 也作为入参,不过 more 是哪里来的?从这个函数的角度来看,more是一个自由变量(free variable),因为函数字面量本身并没有给 more 赋予任何含义。相反,x 是一个绑定变量(bound variable),因为它在该函数的上下文里有明确的含义:它被定义为该函数的唯一参数,一个 Int。
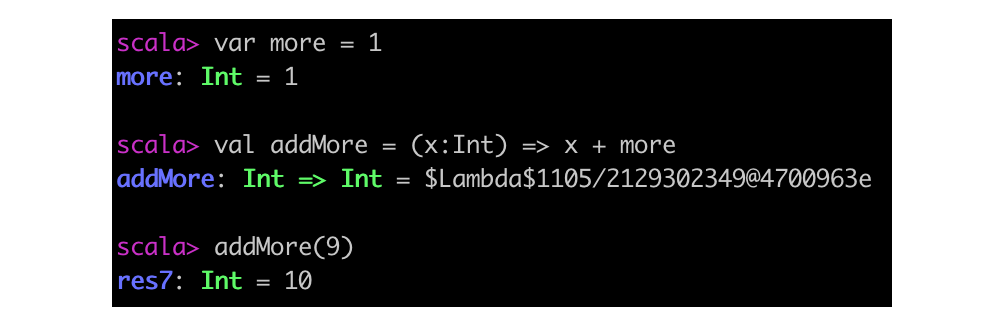
运行时从这个函数字面量创建出来的函数值(对象)被称作闭包(Closure)。该名称源于“捕获”其自由变量从而“闭合”该函数字面量的动作。
没有自由变量的函数字面量,比如 (x: Int) => x + 1, 称为闭合语(closed term),这里的语(term)指的是一段源代码。因此,运行时从这个函数字面量创建出来的函数值严格来说并不是一个闭包,因为 (x: Int) => x + 1 按照目前这个写法已经是闭合的了。
而运行时从任何带有自由变量的函数字面量,比如 (x: Int) => x + more,创建的函数值,按照定义,要求捕获到它的自由变量 more 的绑定。相应的函数值结果(包含指向被捕获的 more 变量的引用)就被称作“闭包”,因为函数值是通过闭合这个开放语(open term)的动作产生的。
这个例子带来一个问题:如果 more 在闭包创建以后被改变会发生什么?在 Scala 中,答案是闭包能够看到这个改变。

很符合直觉的是,Scala 的闭包捕获的是变量本身,而不是变量引用的值。正如前面示例所展示的,为 (x: Int) => x + more 创建的闭包能够看到闭包外对 more 的修改。反过来也是成立的:闭包对捕获到的变量的修改也能在闭包外被看到。
那么如果一个闭包访问了某个随着程序运行会产生多个副本的变 量会如何呢?例如,如果一个闭包使用了某个函数的局部变量,而这个函数又被调用了多次,会怎么样?闭包每次访问到的是这个变量的哪一个实例呢?
只有一个答案是跟 Scala 其他组成部分是一致的:闭包引用的实例是在闭包被创建时活跃的那一个。参考下面这个创建并返回“增加”闭包的函数。该函数每调用一次,就会创建一个新的闭包。每个闭包都会访问那个在它创建时活跃的变量 more。
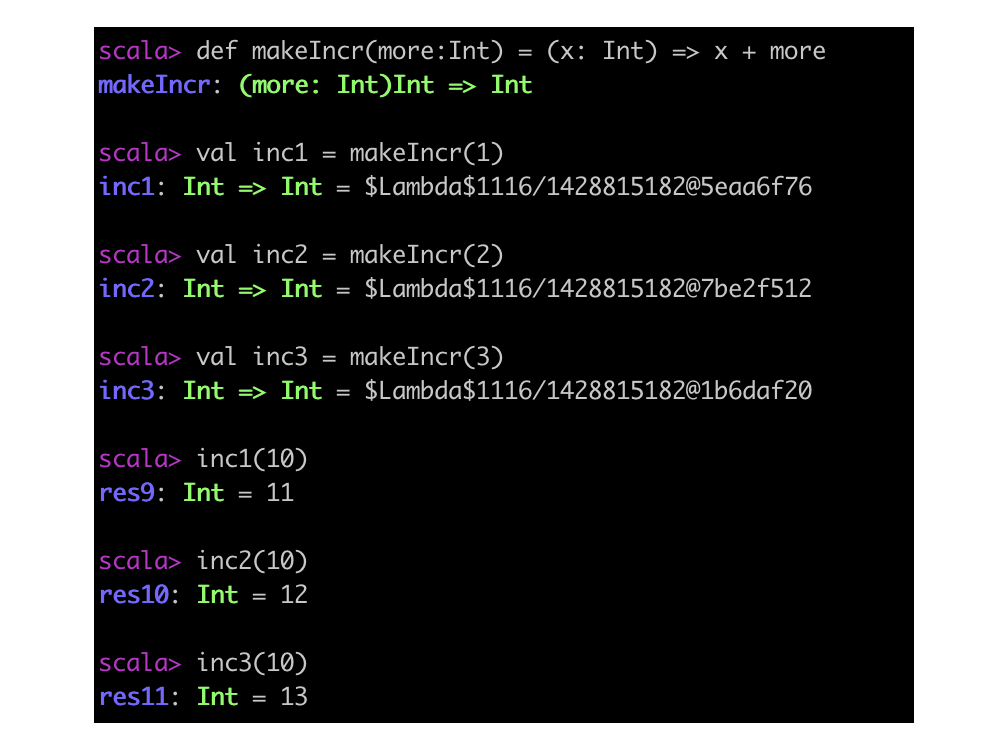
当你调用 makeIncr(1) 时,一个捕获了 more 的绑定值 1 的闭包就被创建并返回出来。同理,当你调用 makeIncr(2) 时,返回的是一个捕获了 more 的绑定值 2 的闭包。当你将这些闭包应用到入参(本例中只有一个必选参数 x),其返回结果取决于闭包创建时 more 的定义。
示例:
object ClosureTest {
def main(args: Array[String]): Unit = {
def minusXY(x: Int) = (y: Int) => x - y
/*
* 1. 返回的 (y: Int) => x - y 是一个匿名函数,又因为该函数引用到函数外的 x,那么该函数和 x 整体形成一个闭包。
* 2. 如 val f = minusXY(20) 的 f 函数就是闭包。你可以这样理解,返回函数是一个对象,而 x 就是该对象的一个字段,他们共同形成一个闭包。
* 3. 当多次调用 f 时(可以理解多次调用闭包),发现使用的是同一个 x,所以 x 不变。
* 4. 在使用闭包时,主要搞清楚返回函数引用了函数外的哪些变量,因为他们会组合成一个整体(实体),形成一个闭包。
*/
val f = minusXY(20)
println("f(1)=" + f(1)) // 19
println("f(2)=" + f(2)) // 18
}
}
闭包的作用主要有以下几个方面:
- 记忆状态:闭包可以记住它被创建时所处的环境,即使离开了这个环境,闭包仍然可以引用和修改环境中的变量。通过闭包,我们可以在函数之间共享状态,实现状态的持久化。
- 封装数据:闭包可以将函数与其相关的数据封装在一起,形成一个独立的单元。这样做有助于提高代码的模块化和可维护性。
- 延迟执行:通过闭包,我们可以延迟函数的执行。例如,可以在一个函数中返回另一个函数作为结果,在需要的时候再调用这个返回的函数。
闭包在实际应用中有多种使用场景,下面列举几个常见的例子:
- 回调函数:闭包可以用作回调函数,用于处理异步操作的结果。例如,在 JS 中可以将一个回调函数作为参数传递给异步函数,当异步操作完成时,回调函数就会被调用,可以在回调函数中访问到外部的变量。
- 私有变量:闭包可以用于创建私有变量。在某些编程语言中,没有直接支持私有变量的特性,但通过闭包可以模拟实现。将变量定义在一个函数内部,并返回一个内部函数,外部无法直接访问该变量,从而实现了私有性。
- 偏函数:闭包可以用于创建偏函数。偏函数是指固定部分参数的函数,返回一个新的函数,调用这个新函数时只需提供剩余的参数。通过闭包创建偏函数可以提高代码的复用性和灵活性。
- 迭代器:闭包可以用于实现迭代器模式。通过闭包,我们可以在每次调用迭代器函数时返回一个新的函数,该函数能够依次访问集合中的每个元素。
总之,闭包是指在一个函数内部定义的函数,它可以访问和操作函数外部的变量。闭包的作用包括记忆状态、封装数据和延迟执行。在实际应用中,闭包常用于回调函数、私有变量、偏函数和迭代器等场景,有助于提高代码的可维护性和扩展性。
下面是几个在 Scala 中使用闭包的示例:
(1)回调函数。在这个例子中,asyncOperation 是一个模拟的异步操作函数,它接受一个回调函数作为参数。通过使用闭包,我们可以在回调函数中访问和处理外部的变量。
def asyncOperation(callback: Int => Unit): Unit = {
// 模拟异步操作
val result = 42
callback(result)
}
// 使用闭包作为回调函数
asyncOperation(result => println(s"异步操作的结果为:$result"))
(2)私有变量。在这个例子中,createCounter 函数返回了一个闭包,该闭包包含一个私有的变量 count 和一个匿名函数。每次调用闭包时,count 的值会自增并返回,实现了一个简单的计数器。
def createCounter(): () => Int = {
var count = 0
() => {
count += 1
count
}
}
val counter = createCounter()
println(counter()) // 1
println(counter()) // 2
println(counter()) // 3
(3)偏函数。在这个例子中,add 是一个偏函数,它接受一个整数 x 并返回一个匿名函数。通过使用闭包,我们可以实现部分应用函数,将函数的一部分参数固定下来并返回一个新的函数。
val add: Int => (Int => Int) = x => y => x + y
val addTen: Int => Int = add(10)
println(addTen(5)) // 15
第一行实际上是定义了一个具有柯里化特性的函数:
Int => (Int => Int):这部分表示一个函数类型,它接受一个整数Int作为参数,并返回一个函数(Int => Int)。x => y => x + y:这是一个函数字面量,表示一个匿名函数。由于Scala中函数是可以嵌套的,所以这里使用了两个箭头=>来表示嵌套的函数。x => y => x + y表示一个函数,它接受一个整数x作为参数,并返回一个函数y => x + y。y => x + y是内部的函数,它接受一个整数y作为参数,并返回x + y的结果。
因此,整个表达式可以解读为一个函数 add,它接受一个整数 x 作为参数,并返回一个函数。这个内部的函数接受一个整数 y 作为参数,并计算 x + y 的结果。
通过这种方式,我们实现了一个偏函数(Partial Function),即将一个多参数函数转换为多个单参数函数的组合。在这个例子中,我们通过柯里化的方式将两个整数相加的函数拆解为两个单独的函数,分别处理其中一个参数。这样可以使部分应用函数变得更加灵活,并可以在需要的时候进行参数的传递和调用。
通过 add(10) 调用 add 函数,我们得到了一个新的函数 addTen,它实际上是将 10 这个参数绑定到了原始函数的第一个参数上。然后我们可以像调用普通函数一样调用 addTen(5),得到最终的结果 15。这就是使用偏函数实现部分应用函数的效果。
(4)迭代器。在这个例子中,createIterator 函数返回了一个闭包,该闭包能够依次返回集合中的每个元素。通过闭包,我们可以实现一个简单的迭代器。
def createIterator(list: List[Int]): () => Option[Int] = {
var index = 0
() => {
if (index < list.length) {
val element = list(index)
index += 1
Some(element)
} else {
None
}
}
}
val iterator = createIterator(List(1, 2, 3))
println(iterator()) // Some(1)
println(iterator()) // Some(2)
println(iterator()) // Some(3)
println(iterator()) // None
6. 柯里化
之前说过 Scala 允许你创建新的控制抽象,“感觉就像是语言原生支持的那样”。尽管到目前为止你看到的例子的确都是控制抽象,应该不会有人会误以为它们是语言原生支持的。为了搞清楚如何做出那些用起来感觉更像是语言扩展的控制抽象,首先需要理解 一个函数式编程技巧,那就是柯里化。
函数柯里化(Currying)是一种将多个参数的函数转换为一系列单参数函数的过程。它的名字来源于逻辑学家 Haskell Curry。函数柯里化是函数式编程中的一种重要概念,用于提高代码的可读性、可组合性和灵活性。
函数柯里化是一种高阶技术,可以将多元函数转换为单元函数序列。具体而言,对于一个接受多个参数的函数,通过函数柯里化,我们可以将其转换为一个接受一个参数的函数,返回一个新的函数,该新函数也接受一个参数,并返回另一个新函数,以此类推,直到最后一个函数返回结果。
通过函数柯里化,我们可以将多个参数的函数拆解成一系列单参数的函数,每个函数只负责处理一个参数。这样做的好处是可以灵活地部分应用函数或将函数组合起来创建更复杂的函数。通过链式调用这些返回的新函数,我们可以逐步传入参数,完成整个函数的调用。
一个经过柯里化的函数在应用时支持多个参数列表,而不是只有一个。
// ===== “普通”的函数 =====
def mul(x: Int, y: Int) = x + y
println(mul(6, 7))
// ===== “柯里化”的函数 =====
// 当你调用 mul2,实际上是连着做了两次传统的函数调用。
// 第 1 次调用接收了一个名为 x 的 Int 参数,返回一个用于
// 第 2 次调用的函数值,这个函数接收一个 Int 参数 y。
def mul2(x: Int)(y: Int) = x + y
println(mul2(3)(4))
// |等价|
def mul3(x: Int) = (y: Int) => x + y
println(mul3(1)(2))
案例:比较两个字符串在忽略大小写的情况下是否相等
// 注意这里是两个任务:① 全部转大写(或小写)② 比较是否相等
implicit class TestEq(s: String) {
def checkEq(ss: String)(f: (String, String) => Boolean): Boolean = {
f(s.toLowerCase, ss.toLowerCase)
}
}
val str1 = "hello"
val str2 = "HellO"
def eq(s1: String, s2: String): Boolean = {
s1.equals(s2)
}
println(str1.checkEq(str2)(eq))
println(str1.checkEq(str2)(_.equals(_)))
7. 控制结构
在拥有一等函数的语言中,可以有效地制作出新的控制接口,尽管语言的语法是固定的。你需要做的就是创建接收函数作为入参的方 法。
例如下面这个“twice”控制结构,它重复某个操作两次,并返回结果:
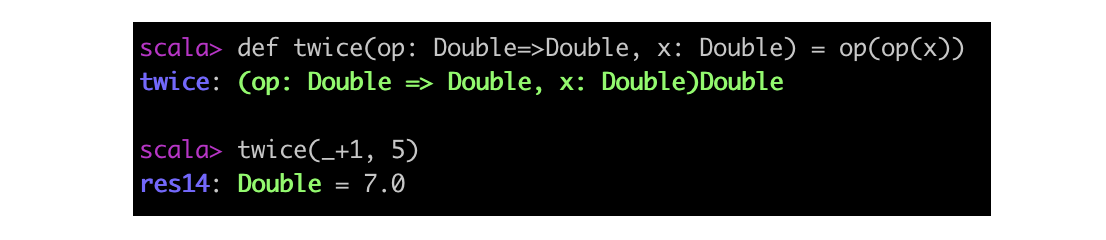
本例中的 op 类型为 Double => Double,意思是这是一个接收一个 Double 作为入参,返回另一个 Double 的函数。
每当你发现某个控制模式在代码中多处出现时,就应该考虑将这个模式实现为新的控制结构。在本章前面的部分看到了 filesMatching 这个非常特殊的控制模式,现在来看一个更加常用的编码模式:打开某个资源,对它进行操作,然后关闭这个资源。可以用类似如下的方 法,将这个模式捕获成一个控制抽象:
def withPrintWriter(file: File, op: PrintWriter => Unit) = {
val writer = new PrintWriter(file)
try {
op(writer)
} finally {
writer.close()
}
}
withPrintWriter(new File("date.txt"), writer => writer.println(new Date))
使用这个方法的好处是,确保文件在最后被关闭的是 withPrintWriter 而不是用户代码的操作。因此不可能出现使用者忘记关闭文件的情况。这个技巧被称作贷出模式(loan pattern),因为是某个控制抽象函数,比如 withPrintWriter,打开某个资源并将这个资源 “贷出”给函数。
该例的 withPrintWriter 将一个 PrintWriter“贷出”给函数 op。当函数完成时,它会表明自己不再需要这个“贷入”的资源。这时这个资源就在 finally 代码块中被关闭了,这样能确保不论函数是正常返回还是抛出异常,资源都会被正常关闭。
可以用花括号 {} 而不是圆括号 () 来表示参数列表,这样调用方的代码看上去更像是在使用内建的控制结构。在 Scala 中,只要有那种只传入一个参数的方法调用,都可以选择使用花括号来将入参包起来,而不是圆括号(注意!这个花括号技巧仅对传入单个入参的场景适用)。
Scala 允许用花括号替代圆括号来传入单个入参的目的是,为了让调用方程序员在花括号当中编写函数字面量。这能让方法用起来更像是控制抽象。
拿前面的 withPrintWriter 举例,在最新的版本中, withPrintWriter 接收两个入参,因此你不能用花括号。尽管如此,由于传入 withPrintWriter 的函数是参数列表中的最后一个,可以用柯里化将第一个 File 参数单独拉到一个参数列表中,这样剩下的函数就独占了第二个参数列表。
下述代码展示了如何重新定义 withPrintWriter。新版本跟老版本的唯一区别在于现在有两个各包含一个参数的参数列表,而不是一个包含两个参数的参数列表。仔细看两个参数之间的部分,在前一个版本的 withPrintWriter中,你看到的是 ...File, op...,而在新的版本中,你看到的是 ...File)(op...。 有了这样的定义,你就可以用更舒服的语法来调用这个方法了:
def withPrintWriter(file: File)(op: PrintWriter => Unit) = {
val writer = new PrintWriter(file)
try {
op(writer)
} finally {
writer.close()
}
}
val file = new File("date.txt")
withPrintWriter(file) {
writer => writer.println(new Date)
}
在本例中,第一个参数列表,也就是那个包含了一个File入参的参数列表,用的是圆括号。而第二个参数列表,即包含函数入参的那个,用的是花括号。
再举两个例子说明抽象控制:
object ControlAbstractionTest {
def main(args: Array[String]): Unit = {
// 1-声明,函数作参
def myRunInThread(f1: () => Unit) = {
new Thread {
override def run(): Unit = f1()
}.start()
}
// 1-调用,传递匿名函数
myRunInThread(
() => {
println("开始")
Thread.sleep(3000)
println("结束")
}
)
// 2-声明,传名参数
def myRunInThread2(f1: => Unit): Unit = {
new Thread {
override def run(): Unit = f1
}.start()
}
// 2-调用,传递代码块;这样写也行:myRunInThread2( {...} )
myRunInThread2 {
println("开始")
Thread.sleep(3000)
println("结束")
}
// 3-编写一个函数实现类似 while 的效果
def until(condition: => Boolean)(block: => Unit): Unit = {
if (!condition) {
block
until(condition)(block)
}
}
// 3-调用
var x = 10
until(x == 0) {
x -= 1
print("x=" + x)
}
// 4-执行相应次数的代码块
def repeat(n: Int)(codeBlock: => Unit): Unit = {
for (_ <- 1 to n) {
codeBlock
}
}
// 4-使用
repeat(3) {
println("Hello, world!")
}
}
}
8. 传名参数
前一节的 withPrintWriter 方法跟语言内建的控制结构(比如 if 和 while)不同,花括号中间的代码接收一个入参。传入 withPrintWriter 的函数需要一个类型为 PrintWriter 的入参,这个入参就是下面代码当中的“writer =>”:
withPrintWriter(file) { writer => writer.println(new Date) }
不过假如你想要实现那种更像是 if 或 while 的控制结构,没有值需要传入花括号中间的代码,该怎么办呢?为了帮助我们应对这样的场 景,Scala 提供了传名参数(by-name parameter)。
我们来看一个具体的例子,假定你想要实现一个名为 myAssert 的断言结构。这个 myAssert 函数将接收一个函数值作为输入,然后通过一个标记来决定如何处理。如果标记位打开,myAssert 将调用传入的函数,验证这个函数返回了 true。而如果标记位关闭,那么 myAssert 将什么也不做。
如果不使用传名参数,你可能会这样来实现 myAssert:
var assertionsEnabled = true
def myAssert(predicate: () => Boolean) = if (assertionsEnabled && !predicate()) throw new AssertionError()
// 这个定义没有问题,不过用起来有些别扭...
myAssert(() => 6 > 7)
你大概更希望能不在函数字面量里写空的圆括号和=>符号,而是直接这样写:myAssert(6 > 7),但以目前的代码,这样写直接编译报错。
「传名参数」就是为此而生的。要让参数成为传名参数,需要给参数一个以 => 开头的类型声明,而不是 () =>。例如,可以像这样将 myAssert 的 predicate 参数转成传名参数:把类型 () => Boolean 改成 => Boolean。示例给出了具体的样子:
def byNameAssert(predicate: => Boolean) = if (assertionsEnabled && !predicate) throw new AssertionError()
byNameAssert(6 > 7)
现在已经可以对要做断言的属性去掉空的参数列表了。这样做的结果就是 byNameAssert 用起来跟使用内建的控制结构完全一样。
对传名(by-name)类型而言,空的参数列表,即 (),是去掉的,这样的类型只能用于参数声明!并不存在传名变量或传名字段!
你可能会好奇为什么不能简单地用老旧的 Boolean 来作为其参数的类型声明,就像下面这样。这种组织方式当然也是合法的,boolAssert 用起来也跟之前看上去完全一样。
def boolAssert(predicate: Boolean) = if (assertionsEnabled && !predicate) throw new AssertionError()
boolAssert(6 > 7)
不过,这两种方式有一个显著的区别需要注意。由于boolAssert 的参数类型为 Boolean,在 boolAssert(6 > 7) 圆括号中的表达式将 “先于”对 boolAssert 的调用被求值。而由于 byNameAssert 的 predicate 参数类型是 => Boolean,在 byNameAssert(6 > 7) 的圆括号中的表达式在调用 byNameAssert 之前并不会被求值,而是会有一个函数值被创建出来,这个函数值的 apply 方法将会对 6 > 7 求值,传入 byNameAssert 的是这个函数值。
因此,两种方式的区别在于如果断言被禁用,你将能够观察到 boolAssert 的圆括号当中的表达式的副作用,而用 byNameAssert 则不 会。例如,如果断言被禁用,那么我们断言 x / 0 == 0 的话, boolAssert 会抛异常;而对同样的代码用 byNameAssert 来做断言的话,不会有异常抛出。

使用传名参数来实现 if-else 结构:
def myIf(condition: => Boolean)(trueBranch: => Unit)(falseBranch: => Unit): Unit = {
if (condition) trueBranch else falseBranch
}
myIf(2 > 1) {
println("2 is greater than 1")
} {
println("2 is not greater than 1")
}
// 代码块只有一行,所以用 () 也可以:myIf(2 > 1)(println("2 is greater than 1"))(println("2 is not greater than 1"))
9. 泛型、界定
9.1 泛型
泛型(Generics)是指在编写代码时不指定具体类型,而是使用类型参数来表示。它使得代码可以在不同类型上工作,实现了代码的通用性和重用性。在 Scala 中可以使用 [] 定义泛型类、方法或函数。类型参数可以是任何合法的标识符,一般使用大写字母来表示。
示例:定义一个泛型类 Box,可以存储不同类型的值,并提供对该值进行读取和设置的操作。
class Box[T](private var value: T) {
def getValue: T = value
def setValue(newValue: T): Unit = value = newValue
}
val box1: Box[Int] = new Box(5)
val box2: Box[String] = new Box("Hello")
val intValue: Int = box1.getValue
val stringValue: String = box2.getValue
在上述示例中,Box 是一个泛型类,使用类型参数 T 来表示存储的值的类型。通过使用泛型,我们可以创建存储不同类型的 Box 实例,分别存储整数和字符串。然后,通过泛型方法 getValue 可以获取所存储的值,无需进行类型转换。
9.2 上下界
上下界(Upper Bounds / Lower Bounds)用于限制泛型的类型范围,指定泛型参数必须是某个特定类型的子类或父类。
- 上界使用
<:符号,表示泛型类型必须是某个类型的「子类」。 - 下界使用
>:符号,表示泛型类型必须是某个类型的「父类」。
通过使用上下界,我们可以根据需要限制传递给泛型方法的类型范围,从而增加代码的类型安全性和灵活性。
【案例一】UpperTest
object UpperTest1 {
def main(args: Array[String]): Unit = {
val g1 = new CompareInt(6, 7).greater
println(g1)
val n1 = new CompareNum(java.lang.Float.valueOf(11.01f), java.lang.Float.valueOf(6.7f))
println(n1.greater)
val n2 = new CompareNum(Integer.valueOf(6), Integer.valueOf(7))
println(n2.greater)
// implicit def double2Double(x: Double): java.lang.Double = x.asInstanceOf[java.lang.Double]
val n3 = new CompareNum[java.lang.Double](1.9, 1.3)
println(n3.greater)
}
}
class CompareInt(n1: Int, n2: Int) {
def greater = if (n1 > n2) n1 else n2
}
/**
* >>>>> 使用上限/上界来完成 <<<<<
* 1. [T <: Comparable[T]] 表示 T 类型是 Comparable 子类型
* 2. 传入的 T 类型要继承 Comparable 接口
* 3. 既然传入类型必继承 Comparable,自然可以调用 compareTo 方法
*
* @param obj1
* @param obj2
* @tparam T
*/
class CompareNum[T <: Comparable[T]](obj1: T, obj2: T) {
def greater = if (obj1.compareTo(obj2) > 0) obj1 else obj2
}
【案例二】LowerTest
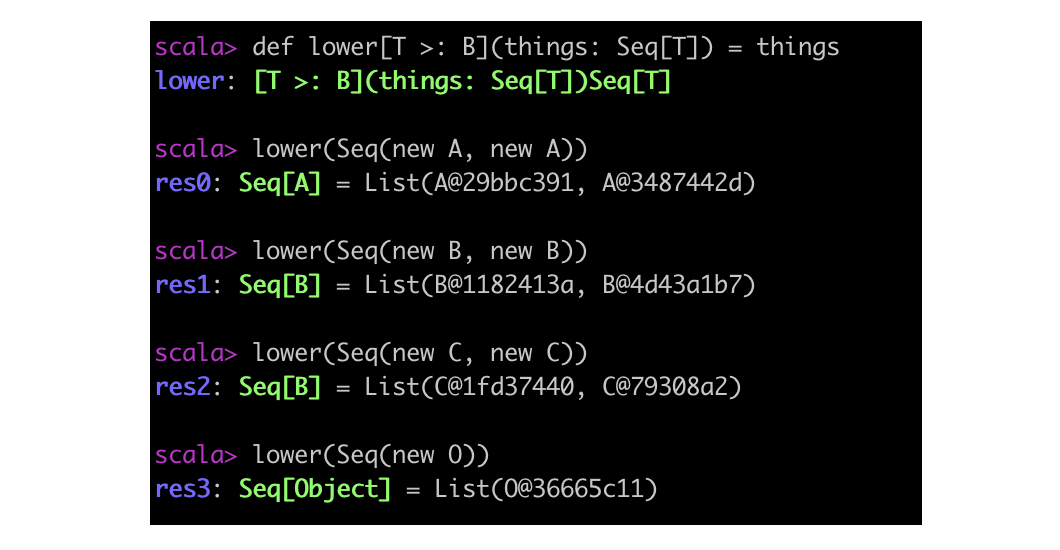
object LowerTest {
def main(args: Array[String]): Unit = {
def upper[T <: B](things: Seq[T]) = things map (_.sound)
upper(Seq(new C, new C))
upper(Seq(new B, new B))
upper(Seq(new B, new C))
// upper(Seq(new A, new A)) [x]
// 不能用「上界」的思路来类推「下界」的含义!下界可以随便传:
// 1. 和 B 有关的,是 B 父类的是父类处理,是 B 子类的按照 B 处理
// 2. 和 B 无关的,一律按照 Object 处理
def lower[T >: B](things: Seq[T]) = things
lower(Seq(new A, new A)).map(_.sound()) // A sound
lower(Seq(new B, new B)).map(_.sound()) // B sound
lower(Seq(new C, new C)).map(_.sound()) // C sound
lower(Seq(new O))
}
}
class A {
def sound() {
println("A sound")
}
}
class B extends A {
override def sound() = {
println("B sound")
}
}
class C extends B {
override def sound() = {
println("C sound")
}
}
class O {
def sound() = {
print("O sound")
}
}
通过 scala 命令执行上面的代码,可以发现下界可以随便传:
- 和 B 有关的,是 B 父类的是父类处理,是 B 子类的按照 B 处理;
- 和 B 无关的,一律按照 Object 处理。
9.3 视图界定
视图界定(View Bounds)使用 <% 符号来定义,它描述了泛型类型 T 需要能够隐式地转换为指定的类型 B。视图界定的语法为 T <% B,表示 T 可以被隐式转换为 B。视图界定使用了「隐式转换机制」,即在需要的时候自动进行类型转换以满足类型要求。
- 泛型是用于参数化类型,可以在编译时对类型进行类型检查和类型安全性。而视图界定是使用隐式转换机制,在运行时进行类型转换以满足类型要求。
- 视图界定允许在定义方法或类时使用隐式转换来拓展类型的能力,使得类型之间的隐式转换变得更加灵活。而泛型则是在编译时对类型进行参数化,通过类型参数来增加代码的重用性和通用性。
- 在视图界定中,我们可以通过隐式转换来使代码更加简洁和灵活,而在泛型中,我们通过指定类型参数来处理不同类型的数据,并利用编译器的类型检查来保证类型安全性。
【案例一】
object ViewBoundsTest {
def main(args: Array[String]): Unit = {
val n1 = new CompareNum(6, 7)
val n2 = new CompareNum(9.1, 9.2)
}
}
/**
* 视图界定:
* 1. `T <% Comparable[T]` 说明 T 是 Comparable 子类型
* 2. `T <% Comparable[T]` 和 `T <: Comparable[T]` 的区别就是视图界定支持隐式转换
* 3. 视图界定不但支持之前上界的写法,同时支持简洁的写法:new CompareNum(1, 20)
*/
class CompareNum[T <% Comparable[T]](obj1: T, obj2: T) {
def greater = if (obj1.compareTo(obj2) > 0) obj1 else obj2
}
【案例二】
object ViewBoundsTest2 {
def main(args: Array[String]): Unit = {
val p1 = new Person("nayeon", 16)
val p2 = new Person("jeongyeon", 15)
val cc = new CompareCom(p1, p2)
println(cc.greater)
val cat1 = new Cat("tree")
val cat2 = new Cat("ljq")
println(new CompareCom(cat1, cat2).greater)
}
}
class Person(val name: String, val age: Int) extends Ordered[Person] {
override def compare(that: Person): Int = this.age - that.age
override def toString: String = s"[Person] ${this.name}, ${this.age}"
}
class Cat(val name: String) extends Ordered[Cat] {
override def compare(that: Cat): Int = this.name.length - that.name.length
override def toString: String = s"[Cat] ${this.name}"
}
/**
* 1. T <% Ordered[T] 表示 T 是 Ordered 子类型 java.lang.Comparable
* 2. 这里调用的 compareTo 方法是 T 这个类型的方法
*/
class CompareCom[T <% Ordered[T]](obj1: T, obj2: T) {
// def > (that: A): Boolean = (this compare that) > 0
def greater = if (obj1 > obj2) obj1 else obj2
// def greater = if (obj1.compareTo(obj2) > 0) obj1 else obj2
}
【案例三】
object ViewBoundsTest3 {
def main(args: Array[String]): Unit = {
val p1 = new Person3("汤姆", 13)
val p2 = new Person3("杰克", 10)
// 引入隐式函数
import MyImplicit._
val compareComm3 = new CompareCom3(p1, p2)
println(compareComm3.getter)
}
}
class Person3(val name: String, val age: Int) {
override def toString: String = this.name + "\t" + this.age
}
class CompareCom3[T <% Ordered[T]](obj1: T, obj2: T) {
def getter = if (obj1 > obj2) obj1 else obj2
// def getter = if (obj1.compareTo(obj2) > 0) obj1 else obj2
}
MyImplicit
object MyImplicit {
implicit def person3toOrderedPerson3(p3: Person3) = new Ordered[Person3] {
override def compare(that: Person3) = p3.age - that.age
}
}
【补充】Ordered 和 Ordering 的区别?
在 Scala 中,Ordered 和 Ordering 是用于比较操作的两个相关 trait。
(1)Ordered
Ordered是一个 trait,用于定义可比较的类型。如果一个类混入了Ordered,那么该类的对象可以直接进行比较操作(如<、>、<=、>=)。Orderedtrait 定义了一组比较方法:<、>、<=、>=、compare。这些方法返回一个Int值,表示比较结果的大小关系。- 在下述示例中,我们定义了一个 Person 类并混入了
Orderedtrait。通过实现compare方法,我们根据年龄来进行比较操作。然后,我们可以直接使用<运算符来比较两个 Person 对象的大小关系。case class Person(name: String, age: Int) extends Ordered[Person] { def compare(that: Person): Int = this.age - that.age } val p1 = Person("Alice", 25) val p2 = Person("Bob", 30) println(p1 < p2) // 输出:true
(2)Ordering
Ordering是一个类型类(type class),用于定义类型之间的比较规则。它提供了丰富的比较方法和操作符,可以用于对任意类型进行比较。Orderingtrait 定义了一组比较方法:lt、gt、lteq、gteq、compare。这些方法返回一个Boolean或Int值,表示比较结果。Ordering实例可以通过隐式参数机制在需要的时候被自动注入,用于提供比较操作的实现。- 在下述示例中,我们定义了一个 Person 类,并定义了一个
Ordering实例来指定比较规则,按照年龄进行排序。然后,我们可以使用sorted方法对 Person 对象的列表进行排序,会根据personOrdering的定义来比较对象的大小关系。case class Person(name: String, age: Int) implicit val personOrdering: Ordering[Person] = Ordering.by(_.age) val people = List(Person("Alice", 25), Person("Bob", 30)) val sortedPeople = people.sorted println(sortedPeople) // 输出:List(Person(Alice,25), Person(Bob,30))
(3)二者区别
Ordered是一个 trait,用于定义可比较的类型,如果一个类混入了Ordered,那么该类的对象可以直接进行比较操作。Ordering是一个类型类,用于定义类型之间的比较规则,它提供了丰富的比较方法和操作符,可以用于对任意类型进行比较。Ordered是为特定类型定义的可比较能力,需要实现compare方法来定义比较规则。Ordering是用于给定类型的比较规则,通过隐式参数机制提供比较操作的实现。可以为任意类型定义Ordering实例,并在需要比较的地方自动注入。
在使用时,如果已经为某个类型定义了 Ordered,则可以直接使用比较操作符进行大小比较;如果需要为某个类型指定特定的比较规则,或在一些集合方法(如 sorted)中需要比较操作,则可以使用 Ordering。
9.4 上下文界定
上下文界定(Context Bounds)使用 : 符号来定义,它描述了泛型类型 T 需要存在一个隐式值类型为 A 的参数。
上下文界定的语法为 T: A,表示 T 类型需要存在一个类型为 A 的隐式值。上下文界定使用了隐式参数机制,即在需要的时候自动注入所需的隐式值。
object ContextBoundsTest {
def main(args: Array[String]): Unit = {
implicit val personComparator = new Ordering[Person4] {
override def compare(p1: Person4, p2: Person4): Int = p1.age - p2.age
}
val p1 = new Person4("mary", 30)
val p2 = new Person4("smith", 35)
val compareCom4 = new CompareCom4(p1, p2)
println(compareCom4.greater)
val compareComm5 = new CompareCom5(p1, p2)
println(compareComm5.greater)
val CompareCom6 = new CompareCom6(p1, p2)
println(CompareCom6.getter)
}
}
class Person4(val name: String, val age: Int) {
override def toString = this.name + "\t" + this.age
}
// [方式1] 将隐式参数放到构造器声明
// 1. [T: Ordering] 泛型
// 2. obj1: T, obj2: T 接受T类型的对象
// 3. implicit comparator: Ordering[T] 是一个隐式参数
class CompareCom4[T: Ordering](obj1: T, obj2: T)(implicit comparator: Ordering[T]) {
def greater = if (comparator.compare(obj1, obj2) > 0) obj1 else obj2
}
// [方式2] 将隐式参数放到方法内
class CompareCom5[T: Ordering](o1: T, o2: T) {
def greater = {
def f1(implicit c: Ordering[T]) = c.compare(o1, o2)
if (f1 > 0) o1 else o2
}
def lower = {
def f1(implicit c: Ordering[T]) = c.compare(o1, o2)
if (f1 > 0) o2 else o1
}
}
// [方式3] 使用 implicitly 语法糖,最简单(推荐使用)
class CompareCom6[T: Ordering](o1: T, o2: T) {
def getter = {
// 发生隐式转换,获取到隐式值 personComparator,底层仍然使用编译器来完成绑定(赋值的)工作
val c = implicitly[Ordering[T]]
if (c.compare(o1, o2) > 0) o1 else o2
}
}
上下文界定(Context Bounds)是 Scala 中的一种特殊的类型约束,用于要求某个泛型类型必须存在一个隐式值。它描述了泛型类型 T 需要存在一个类型为 A 的隐式值,通过隐式参数机制,在需要的时候自动注入所需的隐式值。上下文界定使代码更加灵活和可扩展,可以在运行时为泛型类型提供所需的额外功能或属性。它对于实现多态的数据类型和类型类非常有用,可以在不修改现有类的情况下拓展其功能。
9.5 协变、逆变和不变
协变(covariant)、逆变(contravariant)和不变(invariant)是类型系统中的三个重要概念,用于描述泛型类型参数之间的关系。
(1)协变(Covariant)
- 协变表示子类型关系在泛型参数上是保持的。如果类型 A 是类型 B 的子类型,那么
C[A]也是C[B]的子类型。 - 在 Scala 中,协变可以通过在类型参数前加上
+符号来指定。例如,C[+A]表示类型参数 A 是协变的。 - 在下述示例中,我们定义了一个协变的容器类
Container[+A]。这意味着如果类型 A 是类型 B 的子类型,那么Container[A]也是Container[B]的子类型。因此,我们可以将一个Container[String]赋值给一个Container[Any]变量。class Container[+A](val item: A) val strContainer: Container[String] = new Container("Hello") val objContainer: Container[Any] = strContainer println(objContainer.item) // 输出:Hello
(2)逆变(Contravariant)
- 逆变表示子类型关系在泛型参数上是反转的。如果类型 A 是类型 B 的子类型,那么
C[B]是C[A]的子类型。 - 在 Scala 中,逆变可以通过在类型参数前加上
-符号来指定。例如,C[-A]表示类型参数 A 是逆变的。 - 在下述示例中,我们定义了一个逆变的函数接口
Comparator[-A]。这意味着如果类型 A 是类型 B 的子类型,那么Comparator[B]是Comparator[A]的子类型。因此,我们可以将一个Comparator[String]赋值给一个Comparator[Any]变量。trait Comparator[-A] { def compare(a1: A, a2: A): Int } val stringComparator: Comparator[String] = (a1, a2) => a1.compareTo(a2) val anyComparator: Comparator[Any] = stringComparator println(anyComparator.compare("hello", "world")) // 输出:-15
(3)不变(Invariant)
-
不变表示泛型参数之间没有子类型关系。也就是说,对于类型 A 和类型 B,
C[A]和C[B]没有任何继承关系。 -
在 Scala 中,默认情况下泛型参数是不变的,即没有指定协变或逆变。
-
在下述示例中,我们定义了一个不变的列表类
MyList[A]。这意味着对于类型 A 和类型 B,MyList[A]和MyList[B]之间没有任何继承关系。因此,将一个MyList[Int]赋值给一个MyList[Any]变量会导致编译错误。class MyList[A](val items: List[A]) val intList: MyList[Int] = new MyList(List(1, 2, 3)) val anyList: MyList[Any] = intList // 编译错误 val strList: MyList[String] = new MyList(List("hello", "world")) val anyList: MyList[Any] = strList // 编译错误
(4)示例对比
object Test {
def main(args: Array[String]): Unit = {
val t1: Temp3[Sub] = new Temp3[Sub]("hello")
// val t2: Temp3[Sub] = new Temp3[Super]("hello") [x]
// val t3: Temp3[Super] = new Temp3[Sub]("hello") [x]
val t4: Temp4[Sub] = new Temp4[Sub]("hello")
val t5: Temp4[Super] = new Temp4[Sub]("hello")
// val t6: Temp4[Sub] = new Temp4[Super]("hello") [x]
val t7: Temp5[Sub] = new Temp5[Sub]("hello")
val t8: Temp5[Sub] = new Temp5[Super]("hello")
// val t9: Temp5[Super] = new Temp5[Sub]("hello") [x]
}
}
// 不变
class Temp3[A](title: String) {
override def toString: String = title
}
// 协变
class Temp4[+A](title: String) {
override def toString: String = title
}
// 逆变
class Temp5[-A](title: String) {
override def toString: String = title
}
class Super
class Sub extends Super
小结:
- 协变表示泛型参数在子类型关系上保持不变,可以用
+来指定。 - 逆变表示泛型参数在子类型关系上反转,可以用
-来指定。 - 不变表示泛型参数之间没有子类型关系,默认情况下泛型参数是不变的。
- 协变和逆变允许更灵活地使用泛型类型参数,但需要根据具体需求进行选择和设计。
- 在对集合类型、函数接口或类进行设计时,考虑合适的协变、逆变或不变特性可以提供更好的类型安全性和代码重用性。