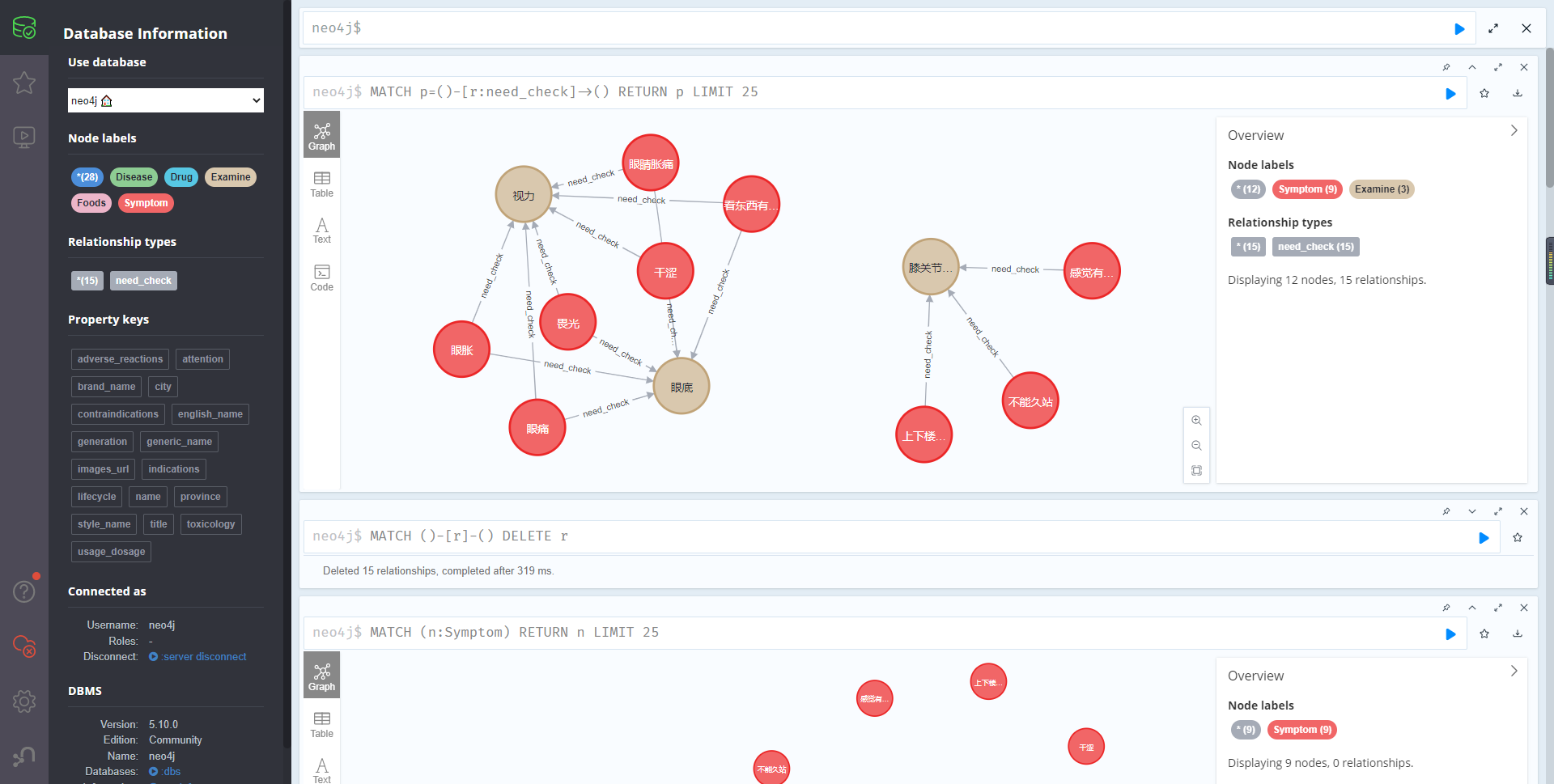
关系:症状-检查
relationship_data.csv
症状,检查
"上下楼梯疼,不能久站,感觉有点肿","膝关节核磁"
"眼睛胀痛,干涩,畏光,眼胀,眼痛,看东西有时候清楚有时候不清楚","视力,眼底"
关系:疾病-症状
import logging
from utils.neo4j_provider import driver
import pandas as pd
logging.root.setLevel(logging.INFO)
# 关系去重函数
def deduplicate(rels_old):
rels_new = []
for each in rels_old:
if each not in rels_new:
rels_new.append(each)
return rels_new
def generate_examine() -> list:
"""
关系:疾病-检查
"""
rels_check = []
df = pd.read_csv('relationship_data.csv')
for idx, row in df.iterrows():
for symptom in row['检查'].split(','):
for exam in row['症状'].split(','):
rels_check.append([exam, symptom])
rels_check = deduplicate(rels_check)
return rels_check
def execute_write(cql):
"""
执行写的命令
:param cql: cql 语句
:return:
"""
with driver.session() as session:
session.execute_write(execute_cql, cql)
driver.close()
def execute_cql(tx, cql):
"""
执行 CQL 语句
:param tx:
:param cql:
:return:
"""
tx.run(cql)
def generate_cql(start_node, end_node, edges, rel_type, rel_name) -> str:
"""
生成 CQL
"""
cql = []
for edge in edges:
p = edge[0]
q = edge[1]
# 创建关系的 Cypher 语句
cql.append(
"MATCH(p:%s),(q:%s) WHERE p.name='%s' and q.name='%s' CREATE (p)-[rel:%s{name:'%s'}]->(q)" % (start_node, end_node, p, q, rel_type, rel_name))
print('创建关系 {}-{}->{}'.format(p, rel_type, q))
return cql
def clear_relationship():
"""
# 创建关系
match(p:Symptom),(q:Examine) where p.name='上下楼梯疼' and q.name='膝关节核磁' create (p)-[rel:need_check{name:'症状检查'}]->(q)
# 删除关系
MATCH(p: Symptom)-[r: need_check]-(q:Examine)
WHERE p.name = '上下楼梯疼' and q.name = '膝关节核磁'
DELETE r
"""
cql = "MATCH(p:Symptom)-[r:need_check]-(q:Examine) DELETE r"
execute_write(cql)
if __name__ == "__main__":
clear_relationship()
res = generate_examine()
print(res)
cql_list = generate_cql('Symptom', 'Examine', res, 'need_check', '症状检查')
for cql in cql_list:
execute_write(cql)
print(cql)