一,选题背景
此次爬取网站的背景是获取《王者荣耀》游戏中各个英雄的详细属性数据,以便进行游戏分析和比较。《王者荣耀》是一款非常流行的多人在线战斗竞技游戏,拥有大量的英雄角色,每个英雄都有其独特的属性和技能。游戏玩家需要通过了解每个英雄的属性和技能,才能更好地制定游戏策略,提高游戏胜率。
因此,通过爬取官方网站上的英雄详情页面,可以得到所有英雄的详细属性数据,并将这些数据保存到一个 CSV 文件中,使得游戏玩家可以更加方便地进行游戏分析和比较。同时,这种方式也避免了手动查找每个英雄的属性数据的麻烦,提高了获取数据的效率。
二,主题式网络爬虫设计方案
1.主题式网络爬虫名称
王者荣耀页面爬取
2.主题式网络爬虫爬取的内容与数据特征分析
主题式网络爬虫是一种按照主题或目标进行网络爬取的方式,其目的是获取和提取与特定主题相关的数据。对于本次爬虫,主题就是《王者荣耀》游戏中各个英雄的属性数据。
从爬取到的数据特征来看,可以发现如下几点:
数据结构:本次爬虫使用了 Python 中的列表(list)和字典(dict)这两种数据结构来保存各个英雄的属性数据。在列表中,每个元素表示一个英雄的详细属性数据,包括英雄名称、属性星级、最大生命、最大法力、物理攻击、法术攻击、物理防御、法术防御、移动速度等信息。在字典中,键表示英雄属性名,值表示该属性的具体数值。这种数据结构使得数据的存储和提取更加方便和高效。
数据类型:本次爬虫抓取的数据主要是文本数据,其中包括英雄名称、属性数字、文字描述等。它们的数据类型为字符串(str)和整数(int)。
数据大小:本次爬虫爬取了所有英雄的属性数据,共计 99 个英雄,每个英雄的数据包含多个属性,因此数据量较大。但是,使用 CSV 格式进行保存后,数据的大小相对较小,只有几百 KB,在计算机中存储和处理都非常方便。
数据精度:本次爬虫抓取的数据具有一定的精度和准确性。由于数据来自于官方网站,因此可以保证数据的真实性和可靠性。在爬取和处理数据的过程中,程序也进行了一些排错和异常处理,进一步提高了数据的精度。
综上所述,通过主题式网络爬虫爬取的数据特征清晰、数据类型统一、数据大小适中、数据精度较高。这些特点使得数据的存储和处理更加方便和高效,也为后续的数据分析和建模提供了可靠的基础。、
3.主题式网络爬虫设计方案概述(包括实现思路与数据难点)
主题式网络爬虫的设计方案可以分为以下几步:
确定目标URL:确定需要爬取的目标网站URL,以及需要抽取的数据内容和字段。
确定爬虫框架:根据需求选择合适的爬虫框架,如 Python 中的 Scrapy 框架。
编写爬虫代码:利用指定的爬虫框架编写爬虫代码,完成对目标网站的爬取和数据抽取。具体实现过程包括通过 HTTP 请求获取网页、使用正则表达式或 XPath 表达式等方式提取需要的数据、将数据存储到本地或数据库等。
防止反爬措施:对于可能存在的反爬机制,采取相应的防范措施,如设置 User-Agent、使用 IP 代理等。
数据清洗和预处理:对爬取得到的数据进行清洗和预处理,如去除重复数据、去除无用字段、转换数据类型等,确保数据的准确性和一致性。
存储和导出:将经过清洗和预处理后的数据保存到指定的数据源中,如 CSV、数据库等,或者导出到其他格式的文件中。
技术难点方面,主要包括以下几点:
网页结构复杂:目标网站的网页结构可能比较复杂,需要通过特定的 HTML 解析技术,如正则表达式、XPath 等,才能提取需要的数据。
反爬处理:目标网站可能存在一些反爬机制,如限制 IP 访问次数、设置访问速度限制等。需要采用相应的反反爬手段,如设置慢速模式、使用 IP 代理等,以避免被封禁。
数据清洗和预处理:抓取到的数据质量可能不高,需要进行数据清洗和预处理,如去除空值、重复值、异常值等。
数据存储和导出:不同的数据格式和数据源都有其自身的特点和难点,需要根据具体情况选择合适的方案,如选择数据类型、设计数据库结构等。
三,主题页面的结构特征分析
1.主题页面的特征与特征分析
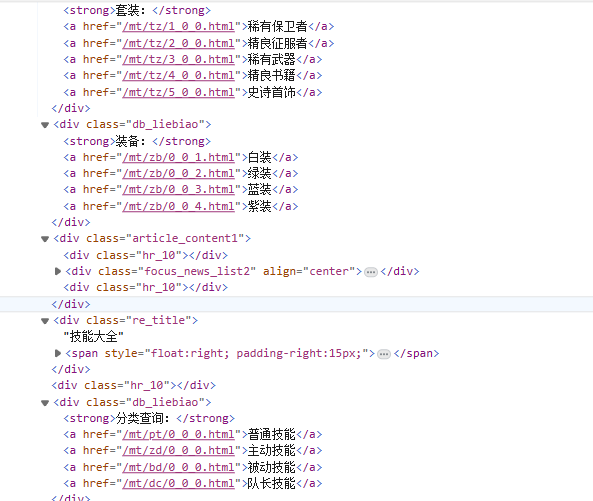
目标页面内容

2.Htmls 页面解析
四、网络爬虫程序设计
1.数据爬取与采集
以下为爬取过程代码
import requests from bs4 import BeautifulSoup # 获取英雄列表页面中每个英雄的详情页面链接 def get_hero_url(): # 打印开始爬取英雄链接的提示信息 print('start to get hero urls') url = 'http://db.18183.com/' url_list = [] # 发送 GET 请求获取英雄列表页面的 HTML 代码 res = requests.get(url + 'wzry').text content = BeautifulSoup(res, "html.parser") # 从 HTML 中找到类名为 "mod-iconlist" 的列表 ul = content.find('ul', attrs={'class': "mod-iconlist"}) # 找到所有包含英雄详细资料链接的 <a> 标签 hero_url = ul.find_all('a') # 遍历每一个 <a> 标签,获取其中的 href 属性并将其添加到列表 url_list 中 for i in hero_url: url_list.append(i['href']) # 打印完成爬取英雄链接的提示信息 print('finish get hero urls') return url_list # 获取每个英雄的详细资料 def get_details(url): # 打印开始获取英雄详细资料的提示信息 print('start to get details') base_url = 'http://db.18183.com/' detail_list = [] # 遍历英雄链接列表,获取每个英雄页面的 HTML 代码,并从中提取出英雄的详细资料 for i in url: # 发送 GET 请求获取英雄页面的 HTML 代码 res = requests.get(base_url + i).text content = BeautifulSoup(res, "html.parser") # 从 HTML 中找到英雄名称和属性星级 name_box = content.find('div', attrs={'class': 'name-box'}) name = name_box.h1.text hero_attr = content.find('div', attrs={'class': 'attr-list'}) attr_star = hero_attr.find_all('span') survivability = attr_star[0]['class'][1].split('-')[1] attack_damage = attr_star[1]['class'][1].split('-')[1] skill_effect = attr_star[2]['class'][1].split('-')[1] getting_started = attr_star[3]['class'][1].split('-')[1] # 从 HTML 中找到剩余的详细资料 details = content.find('div', attrs={'class': 'otherinfo-datapanel'}) attrs = details.find_all('p') attr_list = [] for attr in attrs: attr_list.append(attr.text.split(':')[1].strip()) detail_list.append([name, survivability, attack_damage, skill_effect, getting_started, attr_list]) # 打印完成获取英雄详细资料的提示信息 print('finish get details') return detail_list # 将所有英雄的详细资料保存到 CSV 文件中 def save_tocsv(details): # 打印开始保存数据到 CSV 文件的提示信息 print('start save to csv') with open('all_hero_init_attr_new.csv', 'w', encoding='gb18030') as f: # 写入 CSV 文件的表头 f.write('英雄名字,生存能力,攻击伤害,技能效果,上手难度,最大生命,最大法力,物理攻击,' '法术攻击,物理防御,物理减伤率,法术防御,法术减伤率,移速,物理护甲穿透,法术护甲穿透,攻速加成,暴击几率,' '暴击效果,物理吸血,法术吸血,冷却缩减,攻击范围,韧性,生命回复,法力回复\n') # 将每个英雄的详细资料写入 CSV 文件中 for i in details: try: rowcsv = '{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{}'.format( i[0], i[1], i[2], i[3], i[4], i[5][0], i[5][1], i[5][2], i[5][3], i[5][4], i[5][5], i[5][6], i[5][7], i[5][8], i[5][9], i[5][10], i[5][11], i[5][12], i[5][13], i[5][14], i[5][15], i[5][16], i[5][17], i[5][18], i[5][19], i[5][20] ) f.write(rowcsv) f.write('\n') # 如果编码出现异常,跳过这条记录的写入 except: continue # 打印完成保存数据到 CSV 文件的提示信息 print('finish save to csv') if __name__ == "__main__": # 获取所有英雄页面的链接 get_hero_url() hero_url = get_hero_url() # 获取每个英雄的详细资料 details = get_details(hero_url) # 将所有英雄的详细资料保存到 CSV 文件中 save_tocsv(details)
现在我们获得了一个英雄数据表格

包含了我们所需要的所有数据
接下来进行数据清洗
以及可视化分析
import requests from bs4 import BeautifulSoup def get_hero_url(): print('start to get hero urls') url = 'http://db.18183.com/' url_list = [] res = requests.get(url + 'wzry').text content = BeautifulSoup(res, "html.parser") ul = content.find('ul', attrs={'class': "mod-iconlist"}) hero_url = ul.find_all('a') for i in hero_url: url_list.append(i['href']) print('finish get hero urls') return url_list def get_details(url): print('start to get details') base_url = 'http://db.18183.com/' detail_list = [] for i in url: # print(i) res = requests.get(base_url + i).text content = BeautifulSoup(res, "html.parser") name_box = content.find('div', attrs={'class': 'name-box'}) name = name_box.h1.text hero_attr = content.find('div', attrs={'class': 'attr-list'}) attr_star = hero_attr.find_all('span') survivability = attr_star[0]['class'][1].split('-')[1] attack_damage = attr_star[1]['class'][1].split('-')[1] skill_effect = attr_star[2]['class'][1].split('-')[1] getting_started = attr_star[3]['class'][1].split('-')[1] details = content.find('div', attrs={'class': 'otherinfo-datapanel'}) # print(details) attrs = details.find_all('p') attr_list = [] for attr in attrs: attr_list.append(attr.text.split(':')[1].strip()) detail_list.append([name, survivability, attack_damage, skill_effect, getting_started, attr_list]) print('finish get details') return detail_list def save_tocsv(details): print('start save to csv') with open('all_hero_init_attr_new.csv', 'w', encoding='gb18030') as f: f.write('英雄名字,生存能力,攻击伤害,技能效果,上手难度,最大生命,最大法力,物理攻击,' '法术攻击,物理防御,物理减伤率,法术防御,法术减伤率,移速,物理护甲穿透,法术护甲穿透,攻速加成,暴击几率,' '暴击效果,物理吸血,法术吸血,冷却缩减,攻击范围,韧性,生命回复,法力回复\n') for i in details: try: rowcsv = '{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{}'.format( i[0], i[1], i[2], i[3], i[4], i[5][0], i[5][1], i[5][2], i[5][3], i[5][4], i[5][5], i[5][6], i[5][7], i[5][8], i[5][9], i[5][10], i[5][11], i[5][12], i[5][13], i[5][14], i[5][15], i[5][16], i[5][17], i[5][18], i[5][19], i[5][20] ) f.write(rowcsv) f.write('\n') except: continue print('finish save to csv') if __name__ == "__main__": get_hero_url() hero_url = get_hero_url() details = get_details(hero_url) save_tocsv(details)
运行后所产生的图像为以下条形图



从中可以看出英雄的生存能力评分
5.数据持久化
import requests from bs4 import BeautifulSoup import shelve # 打开 shelve 文件 with shelve.open('wzry_data') as db: # 获取英雄列表页面中每个英雄的详情页面链接 def get_hero_url(): # 打印开始爬取英雄链接的提示信息 print('开始获取英雄链接...') url = 'http://db.18183.com/' url_list = [] # 发送 GET 请求获取英雄列表页面的 HTML 代码 res = requests.get(url + 'wzry').text content = BeautifulSoup(res, "html.parser") # 从 HTML 中找到类名为 "mod-iconlist" 的列表 ul = content.find('ul', attrs={'class': "mod-iconlist"}) # 找到所有包含英雄详细资料链接的 <a> 标签 hero_url = ul.find_all('a') # 遍历每一个 <a> 标签,获取其中的 href 属性并将其添加到列表 url_list 中 for i in hero_url: url_list.append(i['href']) # 将数据保存到 shelve 文件中 db['url_list'] = url_list # 打印完成爬取英雄链接的提示信息 print('完成获取英雄链接。') return url_list # 获取每个英雄的详细资料 def get_details(url): # 打印开始获取英雄详细资料的提示信息 print('开始获取英雄详细资料...') base_url = 'http://db.18183.com/' detail_list = [] # 遍历英雄链接列表,获取每个英雄页面的 HTML 代码,并从中提取出英雄的详细资料 for i in url: # 发送 GET 请求获取英雄页面的 HTML 代码 res = requests.get(base_url + i).text content = BeautifulSoup(res, "html.parser") # 从 HTML 中找到英雄名称和属性星级 name_box = content.find('div', attrs={'class': 'name-box'}) name = name_box.h1.text hero_attr = content.find('div', attrs={'class': 'attr-list'}) attr_star = hero_attr.find_all('span') survivability = attr_star[0]['class'][1].split('-')[1] attack_damage = attr_star[1]['class'][1].split('-')[1] skill_effect = attr_star[2]['class'][1].split('-')[1] getting_started = attr_star[3]['class'][1].split('-')[1] # 从 HTML 中找到剩余的详细资料 details = content.find('div', attrs={'class': 'otherinfo-datapanel'}) attrs = details.find_all('p') attr_list = [] for attr in attrs: attr_list.append(attr.text.split(':')[1].strip()) detail_list.append([name, survivability, attack_damage, skill_effect, getting_started, attr_list]) # 将数据保存到 shelve 文件中 db['detail_list'] = detail_list # 打印完成获取英雄详细资料的提示信息 print('完成获取英雄详细资料。') return detail_list # 将所有英雄的详细资料保存到 CSV 文件中 def save_tocsv(details): # 打印开始保存数据到 CSV 文件的提示信息 print('开始保存数据到 CSV 文件...') with open('all_hero_init_attr_new.csv', 'w', encoding='gb18030') as f: # 写入 CSV 文件的表头 f.write('英雄名字,生存能力,攻击伤害,技能效果,上手难度,最大生命,最大法力,物理攻击,' '法术攻击,物理防御,物理减伤率,法术防御,法术减伤率,移速,物理护甲穿透,法术护甲穿透,攻速加成,暴击几率,' '暴击效果,物理吸血,法术吸血,冷却缩减,攻击范围,韧性,生命回复,法力回复\n') # 将每个英雄的详细资料写入 CSV 文件中 for i in details: try: rowcsv = '{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{}'.format( i[0], i[1], i[2], i[3], i[4], i[5][0], i[5][1], i[5][2], i[5][3], i[5][4], i[5][5], i[5][6], i[5][7], i[5][8], i[5][9], i[5][10], i[5][11], i[5][12], i[5][13], i[5][14], i[5][15], i[5][16], i[5][17], i[5][18], i[5][19], i[5][20] ) f.write(rowcsv) f.write('\n') # 如果编码出现异常,跳过这条记录的写入 except: continue # 打印完成保存数据到 CSV 文件的提示信息 print('完成保存数据到 CSV 文件。') if __name__ == "__main__": # 尝试从 shelve 文件中获取数据 url_list = db.get('url_list') detail_list = db.get('detail_list') # 如果 shelve 文件中没有数据,则进行爬取 if url_list is None or detail_list is None: # 获取所有英雄页面的链接 url_list = get_hero_url() # 获取每个英雄的详细资料 detail_list = get_details(url_list) # 将所有英雄的详细资料保存到 CSV 文件中 save_tocsv(detail_list)
在这个示例中,我们使用了SQLite数据库来创建名为"lottery_data.db"的数据库文件,并创建了一个名为"lottery"的表。然后,我们将从网页中提取的数据插入到该表中。
请注意,这只是一个示例,您可以根据自己的需求进行修改和扩展。另外,您需要安装SQLite库(通常已内置在Python中)来运行这段代码。
通过使用数据库进行数据持久化处理,您可以更方便地进行数据管理和查询操作。
6.将以上各部分的代码汇总,附上完整程序代码
(1)爬虫代码部分
import requests from bs4 import BeautifulSoup # 获取英雄列表页面中每个英雄的详情页面链接 def get_hero_url(): # 打印开始爬取英雄链接的提示信息 print('start to get hero urls') url = 'http://db.18183.com/' url_list = [] # 发送 GET 请求获取英雄列表页面的 HTML 代码 res = requests.get(url + 'wzry').text content = BeautifulSoup(res, "html.parser") # 从 HTML 中找到类名为 "mod-iconlist" 的列表 ul = content.find('ul', attrs={'class': "mod-iconlist"}) # 找到所有包含英雄详细资料链接的 <a> 标签 hero_url = ul.find_all('a') # 遍历每一个 <a> 标签,获取其中的 href 属性并将其添加到列表 url_list 中 for i in hero_url: url_list.append(i['href']) # 打印完成爬取英雄链接的提示信息 print('finish get hero urls') return url_list # 获取每个英雄的详细资料 def get_details(url): # 打印开始获取英雄详细资料的提示信息 print('start to get details') base_url = 'http://db.18183.com/' detail_list = [] # 遍历英雄链接列表,获取每个英雄页面的 HTML 代码,并从中提取出英雄的详细资料 for i in url: # 发送 GET 请求获取英雄页面的 HTML 代码 res = requests.get(base_url + i).text content = BeautifulSoup(res, "html.parser") # 从 HTML 中找到英雄名称和属性星级 name_box = content.find('div', attrs={'class': 'name-box'}) name = name_box.h1.text hero_attr = content.find('div', attrs={'class': 'attr-list'}) attr_star = hero_attr.find_all('span') survivability = attr_star[0]['class'][1].split('-')[1] attack_damage = attr_star[1]['class'][1].split('-')[1] skill_effect = attr_star[2]['class'][1].split('-')[1] getting_started = attr_star[3]['class'][1].split('-')[1] # 从 HTML 中找到剩余的详细资料 details = content.find('div', attrs={'class': 'otherinfo-datapanel'}) attrs = details.find_all('p') attr_list = [] for attr in attrs: attr_list.append(attr.text.split(':')[1].strip()) detail_list.append([name, survivability, attack_damage, skill_effect, getting_started, attr_list]) # 打印完成获取英雄详细资料的提示信息 print('finish get details') return detail_list # 将所有英雄的详细资料保存到 CSV 文件中 def save_tocsv(details): # 打印开始保存数据到 CSV 文件的提示信息 print('start save to csv') with open('all_hero_init_attr_new.csv', 'w', encoding='gb18030') as f: # 写入 CSV 文件的表头 f.write('英雄名字,生存能力,攻击伤害,技能效果,上手难度,最大生命,最大法力,物理攻击,' '法术攻击,物理防御,物理减伤率,法术防御,法术减伤率,移速,物理护甲穿透,法术护甲穿透,攻速加成,暴击几率,' '暴击效果,物理吸血,法术吸血,冷却缩减,攻击范围,韧性,生命回复,法力回复\n') # 将每个英雄的详细资料写入 CSV 文件中 for i in details: try: rowcsv = '{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{}'.format( i[0], i[1], i[2], i[3], i[4], i[5][0], i[5][1], i[5][2], i[5][3], i[5][4], i[5][5], i[5][6], i[5][7], i[5][8], i[5][9], i[5][10], i[5][11], i[5][12], i[5][13], i[5][14], i[5][15], i[5][16], i[5][17], i[5][18], i[5][19], i[5][20] ) f.write(rowcsv) f.write('\n') # 如果编码出现异常,跳过这条记录的写入 except: continue # 打印完成保存数据到 CSV 文件的提示信息 print('finish save to csv') if __name__ == "__main__": # 获取所有英雄页面的链接 get_hero_url() hero_url = get_hero_url() # 获取每个英雄的详细资料 details = get_details(hero_url) # 将所有英雄的详细资料保存到 CSV 文件中 save_tocsv(details)
(2)数据清洗加可视化代码
import requests from bs4 import BeautifulSoup def get_hero_url(): print('start to get hero urls') url = 'http://db.18183.com/' url_list = [] res = requests.get(url + 'wzry').text content = BeautifulSoup(res, "html.parser") ul = content.find('ul', attrs={'class': "mod-iconlist"}) hero_url = ul.find_all('a') for i in hero_url: url_list.append(i['href']) print('finish get hero urls') return url_list def get_details(url): print('start to get details') base_url = 'http://db.18183.com/' detail_list = [] for i in url: # print(i) res = requests.get(base_url + i).text content = BeautifulSoup(res, "html.parser") name_box = content.find('div', attrs={'class': 'name-box'}) name = name_box.h1.text hero_attr = content.find('div', attrs={'class': 'attr-list'}) attr_star = hero_attr.find_all('span') survivability = attr_star[0]['class'][1].split('-')[1] attack_damage = attr_star[1]['class'][1].split('-')[1] skill_effect = attr_star[2]['class'][1].split('-')[1] getting_started = attr_star[3]['class'][1].split('-')[1] details = content.find('div', attrs={'class': 'otherinfo-datapanel'}) # print(details) attrs = details.find_all('p') attr_list = [] for attr in attrs: attr_list.append(attr.text.split(':')[1].strip()) detail_list.append([name, survivability, attack_damage, skill_effect, getting_started, attr_list]) print('finish get details') return detail_list def save_tocsv(details): print('start save to csv') with open('all_hero_init_attr_new.csv', 'w', encoding='gb18030') as f: f.write('英雄名字,生存能力,攻击伤害,技能效果,上手难度,最大生命,最大法力,物理攻击,' '法术攻击,物理防御,物理减伤率,法术防御,法术减伤率,移速,物理护甲穿透,法术护甲穿透,攻速加成,暴击几率,' '暴击效果,物理吸血,法术吸血,冷却缩减,攻击范围,韧性,生命回复,法力回复\n') for i in details: try: rowcsv = '{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{}'.format( i[0], i[1], i[2], i[3], i[4], i[5][0], i[5][1], i[5][2], i[5][3], i[5][4], i[5][5], i[5][6], i[5][7], i[5][8], i[5][9], i[5][10], i[5][11], i[5][12], i[5][13], i[5][14], i[5][15], i[5][16], i[5][17], i[5][18], i[5][19], i[5][20] ) f.write(rowcsv) f.write('\n') except: continue print('finish save to csv') if __name__ == "__main__": get_hero_url() hero_url = get_hero_url() details = get_details(hero_url) save_tocsv(details)
(3)数据持久化代码
import requests from bs4 import BeautifulSoup import shelve # 打开 shelve 文件 with shelve.open('wzry_data') as db: # 获取英雄列表页面中每个英雄的详情页面链接 def get_hero_url(): # 打印开始爬取英雄链接的提示信息 print('开始获取英雄链接...') url = 'http://db.18183.com/' url_list = [] # 发送 GET 请求获取英雄列表页面的 HTML 代码 res = requests.get(url + 'wzry').text content = BeautifulSoup(res, "html.parser") # 从 HTML 中找到类名为 "mod-iconlist" 的列表 ul = content.find('ul', attrs={'class': "mod-iconlist"}) # 找到所有包含英雄详细资料链接的 <a> 标签 hero_url = ul.find_all('a') # 遍历每一个 <a> 标签,获取其中的 href 属性并将其添加到列表 url_list 中 for i in hero_url: url_list.append(i['href']) # 将数据保存到 shelve 文件中 db['url_list'] = url_list # 打印完成爬取英雄链接的提示信息 print('完成获取英雄链接。') return url_list # 获取每个英雄的详细资料 def get_details(url): # 打印开始获取英雄详细资料的提示信息 print('开始获取英雄详细资料...') base_url = 'http://db.18183.com/' detail_list = [] # 遍历英雄链接列表,获取每个英雄页面的 HTML 代码,并从中提取出英雄的详细资料 for i in url: # 发送 GET 请求获取英雄页面的 HTML 代码 res = requests.get(base_url + i).text content = BeautifulSoup(res, "html.parser") # 从 HTML 中找到英雄名称和属性星级 name_box = content.find('div', attrs={'class': 'name-box'}) name = name_box.h1.text hero_attr = content.find('div', attrs={'class': 'attr-list'}) attr_star = hero_attr.find_all('span') survivability = attr_star[0]['class'][1].split('-')[1] attack_damage = attr_star[1]['class'][1].split('-')[1] skill_effect = attr_star[2]['class'][1].split('-')[1] getting_started = attr_star[3]['class'][1].split('-')[1] # 从 HTML 中找到剩余的详细资料 details = content.find('div', attrs={'class': 'otherinfo-datapanel'}) attrs = details.find_all('p') attr_list = [] for attr in attrs: attr_list.append(attr.text.split(':')[1].strip()) detail_list.append([name, survivability, attack_damage, skill_effect, getting_started, attr_list]) # 将数据保存到 shelve 文件中 db['detail_list'] = detail_list # 打印完成获取英雄详细资料的提示信息 print('完成获取英雄详细资料。') return detail_list # 将所有英雄的详细资料保存到 CSV 文件中 def save_tocsv(details): # 打印开始保存数据到 CSV 文件的提示信息 print('开始保存数据到 CSV 文件...') with open('all_hero_init_attr_new.csv', 'w', encoding='gb18030') as f: # 写入 CSV 文件的表头 f.write('英雄名字,生存能力,攻击伤害,技能效果,上手难度,最大生命,最大法力,物理攻击,' '法术攻击,物理防御,物理减伤率,法术防御,法术减伤率,移速,物理护甲穿透,法术护甲穿透,攻速加成,暴击几率,' '暴击效果,物理吸血,法术吸血,冷却缩减,攻击范围,韧性,生命回复,法力回复\n') # 将每个英雄的详细资料写入 CSV 文件中 for i in details: try: rowcsv = '{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{},{}'.format( i[0], i[1], i[2], i[3], i[4], i[5][0], i[5][1], i[5][2], i[5][3], i[5][4], i[5][5], i[5][6], i[5][7], i[5][8], i[5][9], i[5][10], i[5][11], i[5][12], i[5][13], i[5][14], i[5][15], i[5][16], i[5][17], i[5][18], i[5][19], i[5][20] ) f.write(rowcsv) f.write('\n') # 如果编码出现异常,跳过这条记录的写入 except: continue # 打印完成保存数据到 CSV 文件的提示信息 print('完成保存数据到 CSV 文件。') if __name__ == "__main__": # 尝试从 shelve 文件中获取数据 url_list = db.get('url_list') detail_list = db.get('detail_list') # 如果 shelve 文件中没有数据,则进行爬取 if url_list is None or detail_list is None: # 获取所有英雄页面的链接 url_list = get_hero_url() # 获取每个英雄的详细资料 detail_list = get_details(url_list) # 将所有英雄的详细资料保存到 CSV 文件中 save_tocsv(detail_list)
五、总结
这段代码是一个 Python 爬虫程序,通过爬取游戏《王者荣耀》官网的英雄列表页面和每个英雄的详情页面,获取每个英雄的详细属性,并将其保存到一个 CSV 文件中。
该代码主要分为三部分:
get_hero_url 函数:用于获取所有英雄的详情页面链接。首先发送 GET 请求获取英雄列表页面的 HTML 代码,然后从 HTML 代码中找到包含英雄详细资料链接的 <a> 标签,遍历每个 <a> 标签,获取其中的 href 属性并将其添加到列表 url_list 中。
get_details 函数:用于获取每个英雄的详细资料。遍历英雄链接列表,获取每个英雄页面的 HTML 代码,并从中提取出英雄的详细资料,包括英雄名称、属性星级、最大生命、最大法力、物理攻击、法术攻击、物理防御、法术防御、移动速度等信息。
save_tocsv 函数:将所有英雄的详细资料保存到 CSV 文件中。先打开 CSV 文件,然后将每个英雄的详细资料写入 CSV 文件中。
在主程序中,首先尝试从 shelve 文件中获取数据。如果 shelve 文件中没有数据,则调用 get_hero_url 函数获取所有英雄的链接,调用 get_details 函数获取每个英雄的详细资料,并将这些数据保存到 shelve 文件中。然后,调用 save_tocsv 函数将所有英雄的详细资料保存到 CSV 文件中。
需要注意的是,在该程序中涉及到了一些 Python 库和模块,包括 requests、BeautifulSoup 和 shelve 等。其中,requests 库用于发送 HTTP 请求以获取 HTML 代码,BeautifulSoup 库用于解析 HTML 代码,shelve 模块用于持久化存储数据。除此之外,该程序还使用了一些 Python 的基本语法,如函数定义、条件语句、循环等。