1.数据特征
探索数据的特征,查看每列属性、最大值、最小值是了解数据的第一步。查看数据特征,
#查看数据特征 import numpy as np import pandas as pd inputfile='D:\\大三下\\大数据实验课\\data\\Unit8\\GoodsOrder.csv' #输入的数据文件 data=pd.read_csv(inputfile,encoding='gbk') #读取数据 data.info() #查看数据属性 data=data['id'] description=[data.count(),data.min(),data.max()]#依次计算总数、最小值、最大值 description=pd.DataFrame(description,index=['Count','Min','Max']).T print('描述性统计结果:\n',np.round(description))
2.分析热销商品
商品热销情况分析管理中不可或缺的一部分,热销情况分析可以助力商品优选。
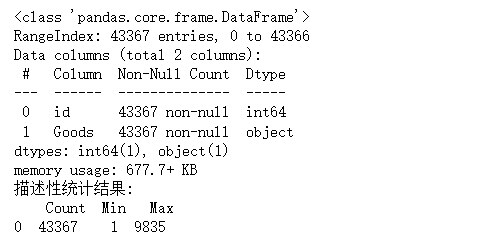
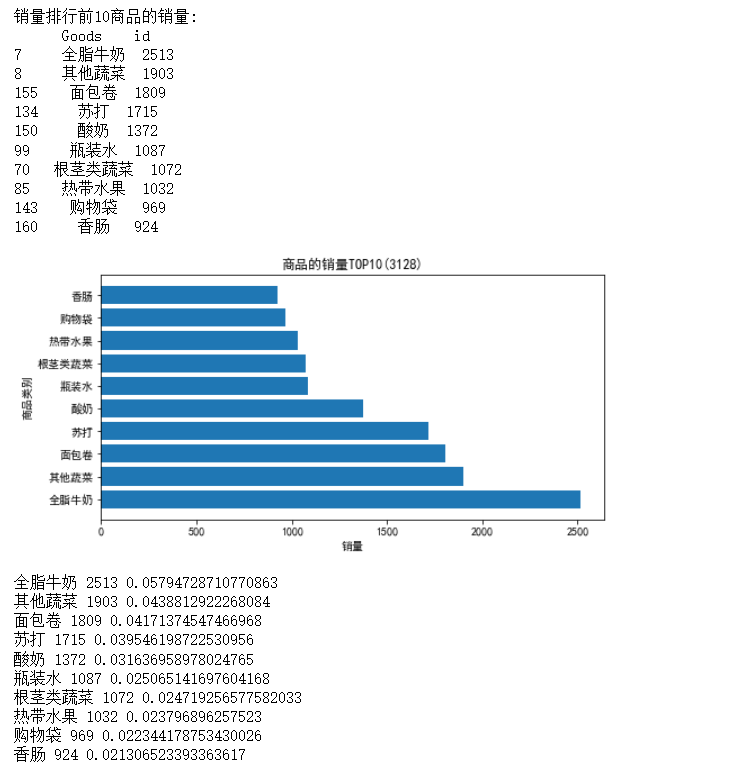
计算商品排行前10的商品及其占比,并绘制条形图显示销量前10 商品销量情况,
#分析热销商品 import pandas as pd inputfile='D:\\大三下\\大数据实验课\\data\\Unit8\\GoodsOrder.csv'#输入的数据文件 data=pd.read_csv(inputfile,encoding='gbk') #读取数据 group=data.groupby(['Goods']).count().reset_index()#对商品进行分类汇总 sorted=group.sort_values('id',ascending=False) print('销量排行前10商品的销量:\n',sorted[:10]) #排序并查看前10位销量商品 #画条形图展示销量排行前10的商品销量 import matplotlib.pyplot as plt x=sorted[:10]['Goods'] y=sorted[:10]['id'] plt.figure(figsize=(8,4)) #设置画布大小 plt.barh(x,y) plt.rcParams['font.sans-serif']='SimHei' plt.xlabel('销量') plt.ylabel('商品类别') plt.title('商品的销量TOP10(3128)') plt.savefig('D:\\大三下\\大数据实验课\\data\\Unit8\\top10.png')#把图片以.png格式保存 plt.show()#展示图片 #销量排行前10的商品销量占比 data_nums=data.shape[0] for index,row in sorted[:10].iterrows(): print(row['Goods'],row['id'],row['id']/data_nums)
3.分析商品结构
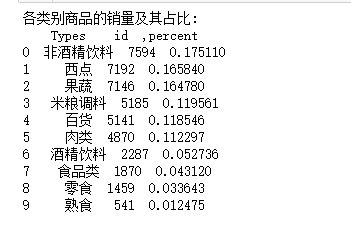
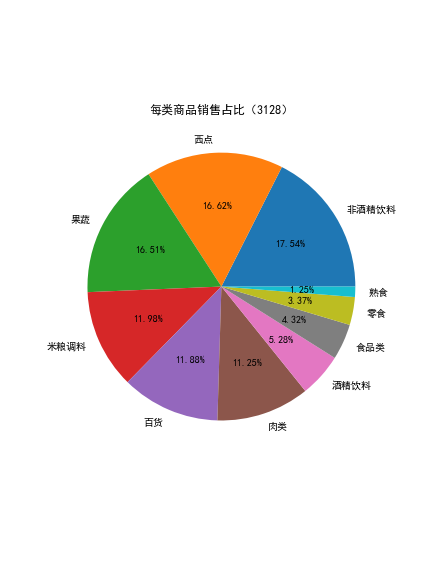
原始数据中的商品本身已经经过归类处理,但是部分商品还是存在一定的重叠,故需要再次对其进行归类处理。分析归类后各类别商品
的销量及其占比后,绘制饼图来显示各类商品的销量占比情况,
#各类别商品的销量及其占比 import pandas as pd inputfile1='D:\\大三下\\大数据实验课\\data\\Unit8\\GoodsOrder.csv' inputfile2='D:\\大三下\\大数据实验课\\data\\Unit8\\GoodsTypes.csv' data=pd.read_csv(inputfile1,encoding='gbk') types=pd.read_csv(inputfile2,encoding='gbk') #输入数据 group=data.groupby(['Goods']).count().reset_index() sort=group.sort_values('id',ascending=False).reset_index() data_nums=data.shape[0] del sort['index'] #总量 sort_links=pd.merge(sort,types) #根据type合并两个data-freame #根据类别求和,每个商品类别的总量,并排序 sort_link=sort_links.groupby(['Types']).sum().reset_index() sort_link=sort_link.sort_values('id',ascending=False).reset_index() del sort_link['index'] #删除“index”列 #求百分比,然后更换列名,最后输出到文件 sort_link['count']=sort_link.apply(lambda line:line['id']/data_nums,axis=1) sort_link.rename(columns={'count':'percent'},inplace=True) print('各类别商品的销量及其占比:\n',sort_link) outfile='D:\\大三下\\大数据实验课\\data\\Unit8\\percent.csv' sort_link.to_csv(outfile,index=False,header=True,encoding='gbk') #画饼图展示每类商品的销量占比 import matplotlib.pyplot as plt data=sort_link['percent'] labels=sort_link['Types'] plt.figure(figsize=(6,8)) #设置画布大小 plt.pie(data,labels=labels,autopct='%1.2f%%') plt.rcParams['font.sans-serif']='SimHei' plt.title('每类商品销售占比(3128)') plt.savefig('D:\\大三下\\大数据实验课\\data\\Unit8\\persent.png')#把图片以.png格式保存 plt.show()
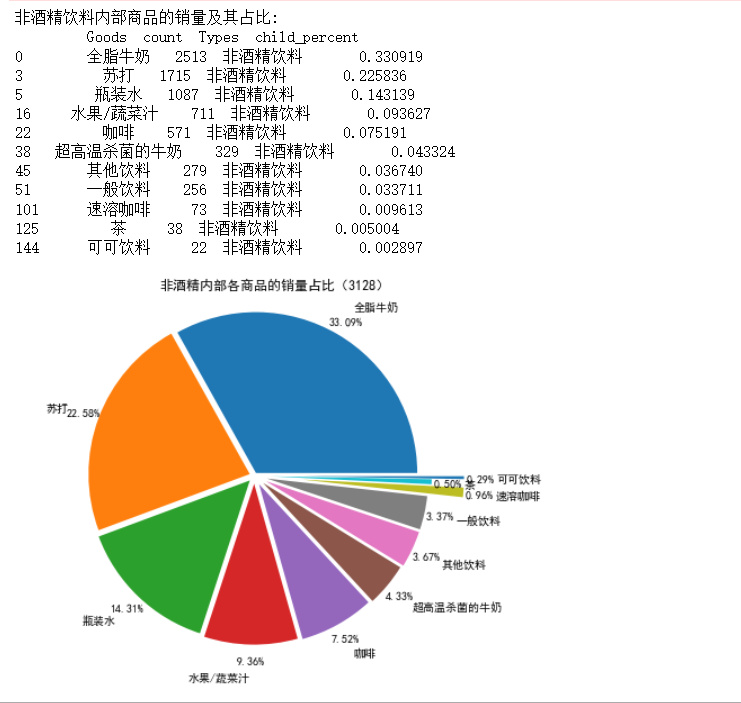
#非酒精饮料内部商品的销量及其比例 #先筛选“非酒精饮料”类型商品,然后求百分比,然后输出结果到文件 selected=sort_links.loc[sort_links['Types']=='非酒精饮料'] child_nums=selected['id'].sum() #对所有“非酒精饮料”求和 selected['child_percent']=selected.apply(lambda line:line['id']/child_nums,axis=1) #求百分比 selected.rename(columns={'id':'count'},inplace=True) print('非酒精饮料内部商品的销量及其占比:\n',selected) outfile2='D:\\大三下\\大数据实验课\\data\\Unit8\\child_percent.csv' sort_link.to_csv(outfile2,index=False,header=True,encoding='gbk')#输出结果 #画出图展示非酒精饮品内部各商品的销量占比 import matplotlib.pyplot as plt data=selected['child_percent'] labels=selected['Goods'] plt.figure(figsize=(8,6)) #设置画布大小 explode=(0.02,0.03,0.04,0.05,0.06,0.07,0.08,0.08,0.3,0.1,0.3) #设置每一块分割出的间隙大小 plt.pie(data,explode=explode,labels=labels,autopct='%1.2f%%',pctdistance=1.1,labeldistance=1.2) plt.rcParams['font.sans-serif']='SimHei' plt.title("非酒精内部各商品的销量占比(3128)")#设置标题 plt.axis('equal') plt.savefig('D:\\大三下\\大数据实验课\\data\\Unit8\\child_percent.png')#保存图形 plt.show()
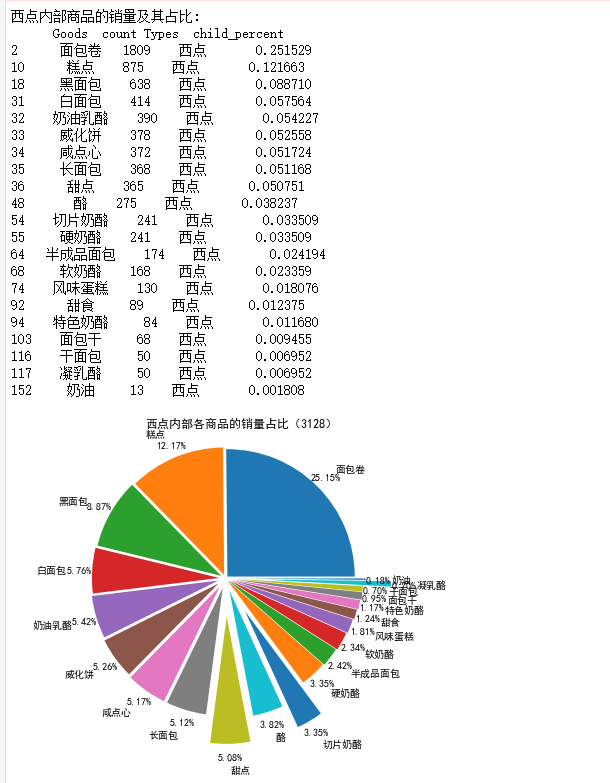
#西点类内部商品的销量及其比例 #先筛选“西点类”类型商品,然后求百分比,然后输出结果到文件 selected=sort_links.loc[sort_links['Types']=='西点'] child_nums=selected['id'].sum() #对所有“西点”求和 selected['child_percent']=selected.apply(lambda line:line['id']/child_nums,axis=1) #求百分比 selected.rename(columns={'id':'count'},inplace=True) print('西点内部商品的销量及其占比:\n',selected) outfile2='D:\\大三下\\大数据实验课\\data\\Unit8\\西点类\\child_percent.csv' sort_link.to_csv(outfile2,index=False,header=True,encoding='gbk')#输出结果 #画出图展示西点内部各商品的销量占比 import matplotlib.pyplot as plt data=selected['child_percent'] labels=selected['Goods'] plt.figure(figsize=(8,6)) #设置画布大小 explode=(0.02,0.03,0.04,0.05,0.06,0.07,0.08,0.08,0.3,0.1,0.3,0.02,0.03,0.04,0.05,0.06,0.07,0.08,0.08,0.3,0.1) #设置每一块分割出的间隙大小 plt.pie(data,explode=explode,labels=labels,autopct='%1.2f%%',pctdistance=1.1,labeldistance=1.2) plt.rcParams['font.sans-serif']='SimHei' plt.title("西点内部各商品的销量占比(3128)")#设置标题 plt.axis('equal') plt.savefig('D:\\大三下\\大数据实验课\\data\\Unit8\\西点类\\child_percent.png')#保存图形 plt.show()
#数据转换 # -*- coding: utf-8 -*- # 代码8-5 数据转换 import pandas as pd inputfile='D:\\大三下\\大数据实验课\\data\\Unit8\\GoodsOrder.csv' data = pd.read_csv(inputfile,encoding = 'gbk') # 根据id对“Goods”列合并,并使用“,”将各商品隔开 data['Goods'] = data['Goods'].apply(lambda x:','+x) data = data.groupby('id').sum().reset_index() # 对合并的商品列转换数据格式 data['Goods'] = data['Goods'].apply(lambda x :[x[1:]]) data_list = list(data['Goods']) # 分割商品名为每个元素 data_translation = [] for i in data_list: p = i[0].split(',') data_translation.append(p) print('数据转换结果的前5个元素:\n', data_translation[0:5])

# -*- coding: utf-8 -*- # 代码8-6 构建关联规则模型 from numpy import * def loadDataSet(): return [['a', 'c', 'e'], ['b', 'd'], ['b', 'c'], ['a', 'b', 'c', 'd'], ['a', 'b'], ['b', 'c'], ['a', 'b'], ['a', 'b', 'c', 'e'], ['a', 'b', 'c'], ['a', 'c', 'e']] def createC1(dataSet): C1 = [] for transaction in dataSet: for item in transaction: if not [item] in C1: C1.append([item]) C1.sort() # 映射为frozenset唯一性的,可使用其构造字典 return list(map(frozenset, C1)) # 从候选K项集到频繁K项集(支持度计算) def scanD(D, Ck, minSupport): ssCnt = {} for tid in D: # 遍历数据集 for can in Ck: # 遍历候选项 if can.issubset(tid): # 判断候选项中是否含数据集的各项 if not can in ssCnt: ssCnt[can] = 1 # 不含设为1 else: ssCnt[can] += 1 # 有则计数加1 numItems = float(len(D)) # 数据集大小 retList = [] # L1初始化 supportData = {} # 记录候选项中各个数据的支持度 for key in ssCnt: support = ssCnt[key] / numItems # 计算支持度 if support >= minSupport: retList.insert(0, key) # 满足条件加入L1中 supportData[key] = support return retList, supportData def calSupport(D, Ck, min_support): dict_sup = {} for i in D: for j in Ck: if j.issubset(i): if not j in dict_sup: dict_sup[j] = 1 else: dict_sup[j] += 1 sumCount = float(len(D)) supportData = {} relist = [] for i in dict_sup: temp_sup = dict_sup[i] / sumCount if temp_sup >= min_support: relist.append(i) # 此处可设置返回全部的支持度数据(或者频繁项集的支持度数据) supportData[i] = temp_sup return relist, supportData # 改进剪枝算法 def aprioriGen(Lk, k): retList = [] lenLk = len(Lk) for i in range(lenLk): for j in range(i + 1, lenLk): # 两两组合遍历 L1 = list(Lk[i])[:k - 2] L2 = list(Lk[j])[:k - 2] L1.sort() L2.sort() if L1 == L2: # 前k-1项相等,则可相乘,这样可防止重复项出现 # 进行剪枝(a1为k项集中的一个元素,b为它的所有k-1项子集) a = Lk[i] | Lk[j] # a为frozenset()集合 a1 = list(a) b = [] # 遍历取出每一个元素,转换为set,依次从a1中剔除该元素,并加入到b中 for q in range(len(a1)): t = [a1[q]] tt = frozenset(set(a1) - set(t)) b.append(tt) t = 0 for w in b: # 当b(即所有k-1项子集)都是Lk(频繁的)的子集,则保留,否则删除。 if w in Lk: t += 1 if t == len(b): retList.append(b[0] | b[1]) return retList def apriori(dataSet, minSupport=0.2): # 前3条语句是对计算查找单个元素中的频繁项集 C1 = createC1(dataSet) D = list(map(set, dataSet)) # 使用list()转换为列表 L1, supportData = calSupport(D, C1, minSupport) L = [L1] # 加列表框,使得1项集为一个单独元素 k = 2 while (len(L[k - 2]) > 0): # 是否还有候选集 Ck = aprioriGen(L[k - 2], k) Lk, supK = scanD(D, Ck, minSupport) # scan DB to get Lk supportData.update(supK) # 把supk的键值对添加到supportData里 L.append(Lk) # L最后一个值为空集 k += 1 del L[-1] # 删除最后一个空集 return L, supportData # L为频繁项集,为一个列表,1,2,3项集分别为一个元素 # 生成集合的所有子集 def getSubset(fromList, toList): for i in range(len(fromList)): t = [fromList[i]] tt = frozenset(set(fromList) - set(t)) if not tt in toList: toList.append(tt) tt = list(tt) if len(tt) > 1: getSubset(tt, toList) def calcConf(freqSet, H, supportData, ruleList, minConf=0.7): for conseq in H: #遍历H中的所有项集并计算它们的可信度值 conf = supportData[freqSet] / supportData[freqSet - conseq] # 可信度计算,结合支持度数据 # 提升度lift计算lift = p(a & b) / p(a)*p(b) lift = supportData[freqSet] / (supportData[conseq] * supportData[freqSet - conseq]) if conf >= minConf and lift > 1: print(freqSet - conseq, '-->', conseq, '支持度', round(supportData[freqSet], 6), '置信度:', round(conf, 6), 'lift值为:', round(lift, 6)) ruleList.append((freqSet - conseq, conseq, conf)) #生成规则 def gen_rule(L, supportData, minConf = 0.7): bigRuleList = [] for i in range(1, len(L)): # 从二项集开始计算 for freqSet in L[i]: # freqSet为所有的k项集 # 求该三项集的所有非空子集,1项集,2项集,直到k-1项集,用H1表示,为list类型,里面为frozenset类型, H1 = list(freqSet) all_subset = [] getSubset(H1, all_subset) # 生成所有的子集 calcConf(freqSet, all_subset, supportData, bigRuleList, minConf) return bigRuleList if __name__ == '__main__': dataSet = data_translation L, supportData = apriori(dataSet, minSupport = 0.02) rule = gen_rule(L, supportData, minConf = 0.35)
