通常我们如果要设计一个 Hash 表,那么我们需要考虑这几个问题:
- 有没有并发操作
- Hash冲突如何解决
- 以什么样的方式扩容
对 Redis 来说,首先它是单线程的工作模式,所以不需要考虑并发问题。
想实现一个性能优异的 Hash 表,就要重点解决哈希冲突和 rehash 开销这两个问题。
一、哈希冲突解决
对于 Hash 冲突的解决,通常来说有,开放寻址法、再哈希法、拉链法等。但是大多数的编程语言都用拉链法实现哈希表,它的实现复杂度也不高,并且平均查找的长度也比较短,各个用于存储节点的内存都是动态申请的,可以节省比较多的存储空间。
所以对于 Redis 来说也是使用了拉链法来解决 hash 冲突,如下所示,通过链表的方式把一个个节点串起来:
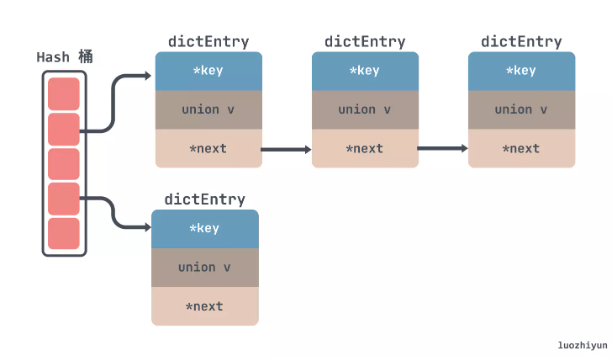
至于为什么没有向 JDK 的 HashMap 一样红黑树来解决冲突,我觉得其实有两方面,一方面是链表转红黑数其实也是需要时间成本的,会影响链表的操作效率;另一方面就是红黑树其实在节点比较少的情况下效率是不如链表的。
二、hash表扩容实现
再来看看扩容,对于扩容来说,一般要新起一块内存,然后将旧数据迁移到新的内存块中,这个过程中因为是单线程,所以在扩容的时候,不能阻塞主线程很长时间,在 Redis 中采用的是渐进式 rehash + 定时 rehash 。
1、渐进式 rehash 如何实现?
简单来说,渐进式 rehash 的意思就是 Redis 并不会一次性把当前 Hash 表中的所有键,都拷贝到新位置,而是会分批拷贝,每次的键拷贝只拷贝 Hash 表中一个 bucket 中的哈希项。
这样一来,每次键拷贝的时长有限,对主线程的影响也就有限了。
渐进式 rehash 会在执行增删查改前,先判断当前字典是否在执行rehash。如果是,则rehash一个节点。这其实是一种分治的思想,通过通过把大任务划分成一个个小任务,每个小任务只执行一小部分数据,最终完成整个大任务。
定时 rehash 如果 dict 一直没有操作,无法渐进式迁移数据,那主线程会默认每间隔 100ms 执行一次迁移操作。
这里一次会以 100 个桶为基本单位迁移数据,并限制如果一次操作耗时超时 1ms 就结束本次任务,待下次再次触发迁移
Redis 在结构体中设置两个表 ht[0] 和 ht[1],如果当前 ht[0]的容量是 0 ,那么第一次会直接给4个容量;如果不是 0 ,那么容量会直接翻倍,然后将新内存放入到ht[1]中返回,并设置标记0表示在扩容中。
这里我画了一张图,以便于你理解 ht[0]和 ht[1]交替使用的过程。
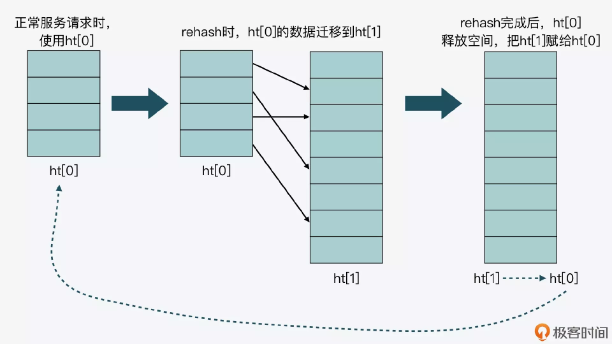
迁移 hash 桶的操作会在增删改查哈希表时每次迁移 1 个哈希桶从ht[0] 迁移到ht[1],在迁移拷贝完所有桶之后会将ht[0] 空间释放,然后将ht[1]赋值给ht[0] ,并把ht[1]大小重置为0 ,并将表示设置标记1表示 rehash 结束了。
对于查找来说,在 rehash 的过程中,因为没有并发问题,所以查找 dict 也会依次先查找 ht[0] 然后再查找 ht[1]。
2、什么时候触发 rehash?
首先要知道,Redis 用来判断是否触发 rehash 的函数是** _dictExpandIfNeeded**。
实际上,_dictExpandIfNeeded 函数中定义了三个扩容条件。
- 条件一:ht[0]的大小为 0。
- 条件二:ht[0]承载的元素个数已经超过了 ht[0]的大小,同时 Hash 表可以进行扩容。
- 条件三:ht[0]承载的元素个数,是 ht[0]的大小的 dict_force_resize_ratio 倍,其中,dict_force_resize_ratio 的默认值是 5。