ClickHouse数据库
一、软件简介
clickHouse是俄罗斯搜索巨头Yandex公司早2016年开源的一个极具"战斗力"的实时数据分析数据库,开发语言是C++,是一用于联机分析(OLAP)的列式数据库管理系统,简称CK,工作速度比传统方法快100-1000倍,Clickhouse的性能超过了目前市场上可比的面向列的DBMS。每秒服务器每秒处理数亿数据。
使用软件的公司:今日头条、腾讯、携程、快手等
- 特点:
- 开源的列式存储数据管理系统,支持在线性扩展,简单方便,高可靠性。
- 容错跑分快
- 功能多,支持数据统计分析各种场景,支持类SQL查询。
- 优点:
- 真正的面向列的DBMS(数据库管理系统)。
- 数据压缩,默认使用了LZO压缩格式。
- 磁盘存储的数据只能在内存中工作。
- 多核并行处理。
- 在多个服务器上分布式处理。
- SQL支持,基本兼容SQL语法,只不过有少许函数不一样。
- 向量化引擎。
- 实时数据更新
- 支持近似计算。
- 数据复制和对数据完整性的支持。
- 缺点:
- 没有完整的事务处理,不支持Transaction。
- 缺少完整Update/Delete操作,缺少高频率、低延迟的修改或删除已存在数据的能力。
- 聚合结果必须小于一台机器的内存大小
- 支持有限操作系统。
- 不适合Key-value,不支持Blob等文档型数据类型。
二、系统架构
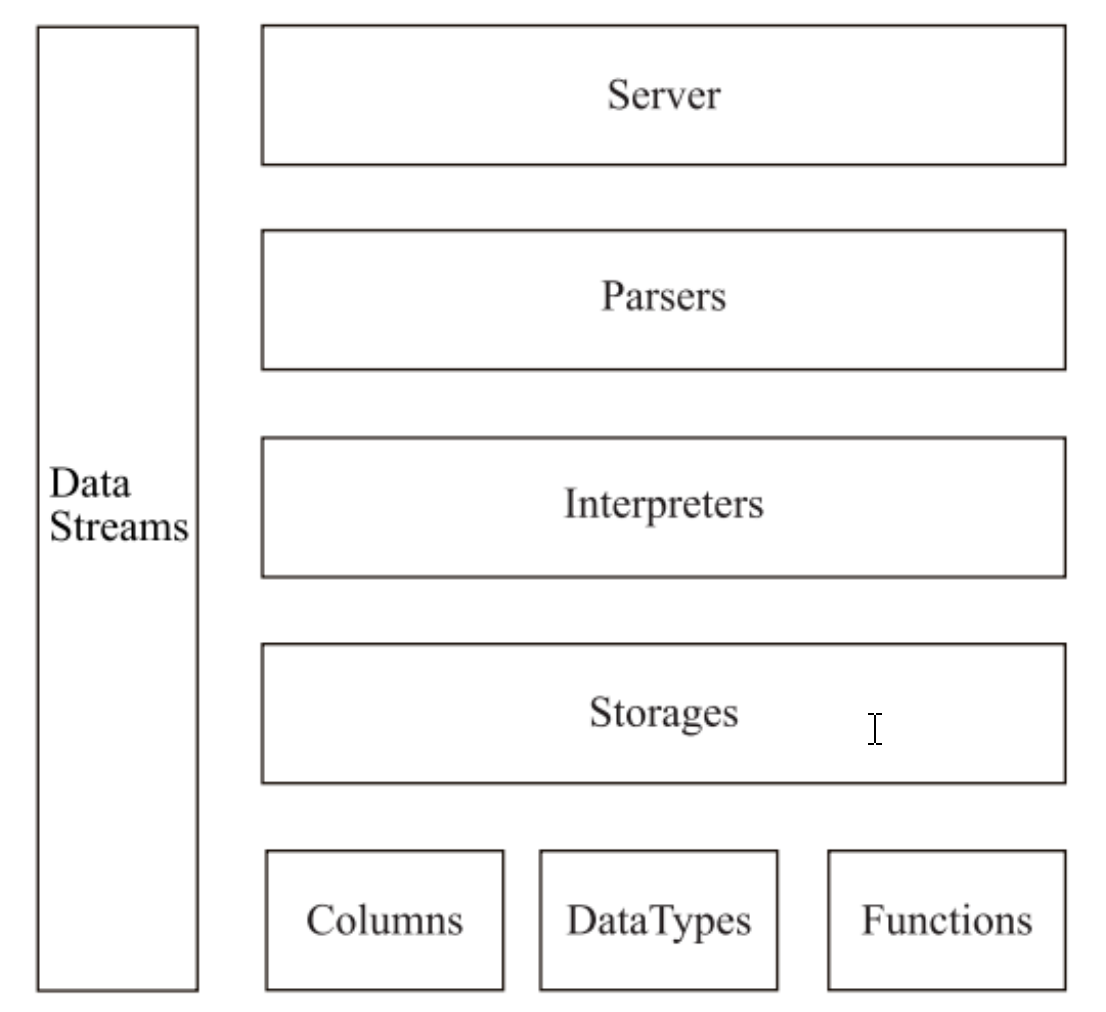
clickHouse是一个真正的列式数据库管理系统。在ck中,数据库始终是按列存储的,包括矢量执行的过程。
- Column与Field
column和Field是clickHouse数据最基础的映射单元。内存中的一列数据由一个Column对象表示。
column对象分为接口和实现两部分 ,在Icolumn接口对象中,定义了对数据进行各种关系运算的方法。几乎所有的操作都是不可变:这些操作不会更改原始列,但是会创建一个新的修改后的列。
在大多数场合,clickHouse都会以整列的方式操作数据。如果需要操作单个具体的数值,则需要使用Field对象代表一个单值。
与Column对象的泛化设计思想不同,Field对象使用了聚合的设计模式。在Field对象内部聚合了Null、UInt64、String和Array等13种数据类型及相应的处理逻辑。
- 数据类型DataType
IDataType负责序列化和反序列化:读写二进制或文本形式的列或单个值构成的块;直接与表的数据类型相对应;IDataType与IColumn之间的关联并不大;IColumn在内存中能表示不同的数据类型;IDataType仅存储元数据;
使用泛化设计模式,具体方法实现逻辑由对应数据类型的实例承载;DataType虽然负责序列化相关工作,但并不直接负责数据的读取,转由从Column或Field对象获取。
- Block
Block是表示内存中表的子集(chunk)的容器,是由三元组:(IColumn,IDataType,列名)构成的集合。
ClickHouse内部的数据操作是面向Block对象进行的,并且采用了流的形式。Block对象可以看作数据表的子集。
Block并没有直接聚合Column和DataType对象,而是通过间接引用。
- 块流BlockStream
块流用于处理数据,我们可以使用块流从某个地方读取数据,执行数据转换,或将数据写到某个地方。
IBlock流操作有两组顶层接口:IBlockInputStream、IBlockOutPutStream;
IBlockInputStream大致分为三类:处理数据定义的DDL操作;用于处理关系运算的相关操作;与表引擎呼应,每一种表引擎都拥有对应的IBlockInputStream实现。
IBlockOutputStream实现类用户表引擎处理,负责将数据写入下一个环节或者最终目的地。
- Formats格式
数据格式同块流一起实现。用于向客户端输出数据的展示格式
如块流IBlockOutputStream提供的Pretty格式,也有其它输入输出格式,比如JSONEachRow。
如行流: IRowInputStream 和 IRowOutputStream 。它们允许你按行 pull/push 数据,而不是按块。
- 数据读写IO
对象面向字节的输入输出,有ReaderBuffer和WriterBuffer这两个抽象类。
ReadBuffer 和 WriteBuffer 由一个连续的缓冲区和指向缓冲区中某个位置的一个指针组成。
ReadBuffer 和 WriteBuffer 的实现用于处理文件、文件描述符和网络套接字(socket),也用于实现压缩和其它用途。
- 数据表Table
在数据表的底层设计中并没有所谓的Table对象;表由 IStorage 接口表示。该接口的不同实现对应不同的表引擎。
- 解析器Parse
查询由一个手写递归下降解析器解析。比如, ParserSelectQuery 只是针对查询的不同部分递 归地调用下层解析器。 解析器创建 AST 。 AST 由节点表示,节点是 IAST 的实例。
- 解释器Interpreter
解释器负责从AST创建查询执行流水线。
查询执行流水线由块输入或输出流组成。
Parser解析器可以将一条SQL语句递归下降方法解析成AST语法树形式。不同SQL会经由不同的分析器实现类解析。
- 函数
函数分为普通函数和聚合函数。
普通函数实际上不会作用于一个单独行上,而是作用以Block为单位的数据上,以实现向量查询执行,采用向量化的方式直接作用于一整列数据,是无状态的函数。
聚合函数是有状态,它们将传入的值激活到某个状态,并允许你从该状态获取结果,比如Count函数,使用了UInt64记录状态,聚合状态可以被序列化和反序列化,在分布式查询执行期间通过网络传递或者内存不够的时候将其写入磁盘中。
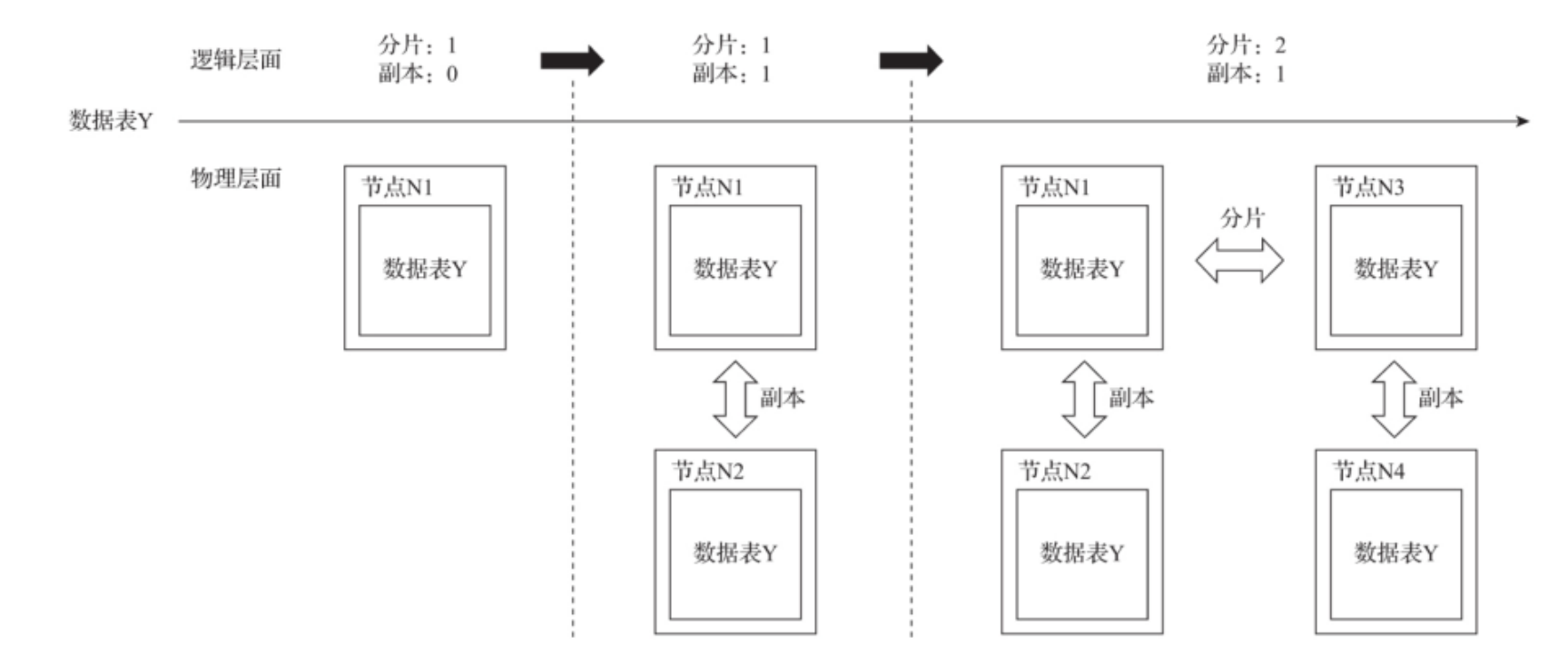
- 集群与副本
ck的集群由分片组成,而每个分片又通过Replication组成;
分片只是逻辑概念,实际上物理承载还是由副本承担的,一个副本只能拥有一个分片!
- 副本与分片
三、环境搭建
- 下载链接
官方文档:
https://clickhouse.com/docs/zhRPM安装包下载:
https://packages.clickhouse.com/rpm/stable/
- 下载以下三个包上传到服务器上

- 安装软件(先安装common组件再安装server组件最后安装client组件)单节点安装即可!
rpm -ivh clickhouse-common-static-22.8.9.24.x86_64.rpm
rpm -ivh clickhouse-server-22.8.9.24.x86_64.rpm
rpm -ivh clickhouse-client-22.8.9.24.x86_64.rpm
- 查看安装软件情况
rpm -qa|grep clickhouse
- 删除安装包
rm -rf clickhouse-*
- 查看服务配置目录
ll /etc/clickhouse-server/

- 授可执行权限config.xml
chmod 644 /etc/clickhouse-server/config.xml
- 配置config.xml文件
<!-- 需要主动添加这一行 -->
187 <listen_host>::</listen_host>
675 <timezone>Asia/Shanghai</timezone>
<!-- 关键配置,默认不需要修改 -->
<!--客户端默认监听端口号8123-->
103 <http_port>8123</http_port>
112 <tcp_port>9000</tcp_port>
<!--ck数据存放目录-->
385 <path>/var/lib/clickhouse/</path>
<!--默认环境配置-->
646 <default_profile>default</default_profile>
<!--默认数据库名-->
661 <default_database>default</default_database>
- 修改users.xml文件权限
chmod 644 /etc/clickhouse-server/users.xml
- 把设置好的密码填进user.xml文件中
<password>123456</password>
- 启动clickhouse服务
systemctl status clickhouse-server
- 登录客户端
#输入配置好的密码 默认用户是default 密码:123456
clickhouse-client -h node1 -u default --password
- 查看节点信息
select * from system.cluster;
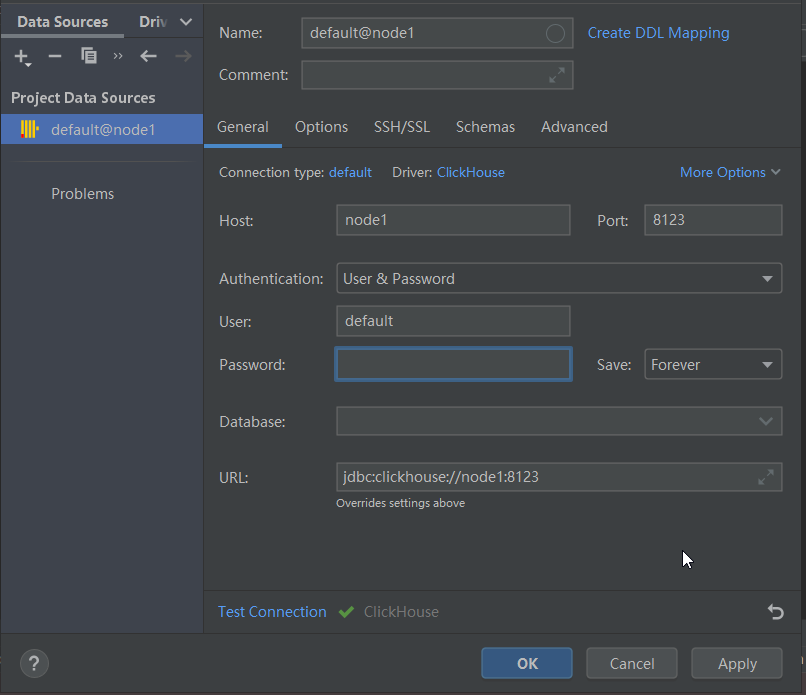
使用DataGrid工具连接
四、数据定义
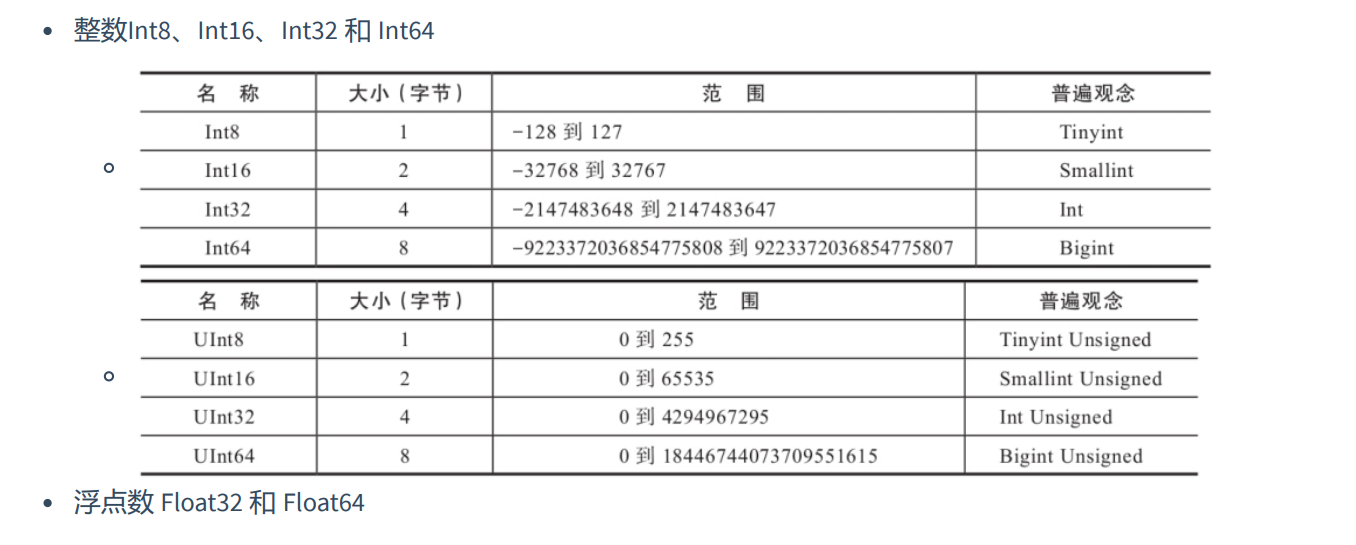
- 基本数据类型
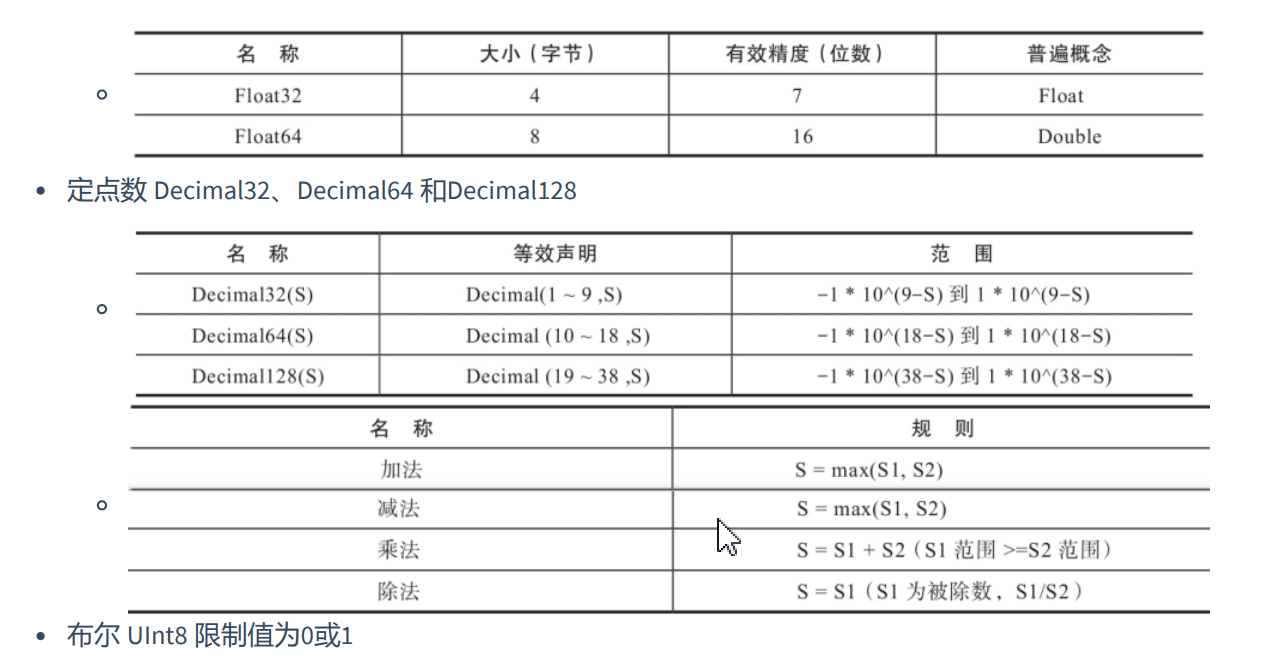
- 字符串
string不限制长度,相当于Varchar、Text、Clob和Blob等字符类型。
FixedString(N)相当于char,长度固定,数据长度不够时,添加空字节(Null)长度过长返回错误信息。
UUID:32位,格式8-4-4-4-12,如果没有值,就用0占位。
create table UUID_TEST(
c1 UUID,
c2 String
)engine=Memory;
-- 第一行UUID有值
insert into UUID_TEST select generateUUIDv4(),'t1';
-- 第二行UUID没有值
insert into UUID_TEST(c2) values('t2');
- 日期函数
Date:精确到日期天 比如2023-12-25
DateTime:精确到秒
DateTime64:精确到亚秒
create table DATE_TEST(
c1 date,
c2 datetime,
c3 datetime64
)engine Memory;
insert into DATE_TEST values ('2023-12-25','2023-12-25 17:36:00','2023-12-25 17:36:30.500');
select *
from DATE_TEST;
- 复合数据类型
array:数组 创建数据:array(T)或[],类型必须相同;
tuple:元组 由多个元素组成,允许不同类型;创建数据:(T1, T2, …),Tuple(T1, T2, …)
Enum:枚举 ClickHouse提供了Enum8和Enum16两种枚举类型,它们除了取值范围不同之外,别无二致。枚举固定使用(String:Int)Key/Value键值对的形式定义数据,所以Enum8和Enum16分别会对应 (String:Int8)和(String:Int16)。用(String:Int) Key/Value键值对的形式定义数据,键值对不能同时为空,不允许重复,key允许为空字符串,需要看到对应的值进行转。
嵌套类型:Nested(Name1 Type1,Name2 Type2,…);相当于表中嵌套一张表,插入时相当于一个多维数组的格式,一个字段对应一个数组。
-- 创建数组类型字段表
create table test_tables(
c1 Array(String) comment '数组类型',
c2 Tuple(String,Int8) comment '元组类型',
c3 Enum8('ready'=1,'start'=2,'success'=3,'error'=4) comment '枚举类型只能插入枚举列出的数据',
c4 Nested(
id UInt8,
name String
) comment '嵌套类型'
)engine Memory;
insert into test_tables values (['one','two','three','four'],('one',1),'ready',[10000,10001,10002],['研发部','技术支持中心','测试部']);
insert into test_tables values (['five','six','seven','eight'],('two',2),'success',[10003,10004,10005],['销售部','后勤部','文案部']);
select * from test_tables;
select c4.id,c4.name from test_tables;
- 其他类型
Nullable(TypeName):只能与基础数据类型搭配使用,表示某个类型的值可以为NULL;Nullable(Int8)表示可以存储Int8类型的值,没有值时存Null。UInt8 8表示8位数(bit),fixedString(32)表示32字节(byte)。
注意:不能与复合类型数据一起使用;不能作为索引字段;尽量避免使用,字段被Nullable修饰后会额外生成[Column].null.bin文件保存Null值,增加开销!
Domain:IPv4使用UInt32存储32位。如116.253.40.133 。 IPv6:使用FixedString(16)存储16字节(byte)128位。
create table test_nullable(
c1 String,
c2 Nullable(UInt8)
)engine Memory;
insert into test_nullable values ('张三',18),('李四',null);
-- 创建domain表
create table test_domain(
url String comment '请求路径',
ip IPv4 comment 'IPv4 32位',
ipv6 IPv6 comment 'IPv6 128位'
)engine Memory;
insert into test_domain values ('www.baidu.com','153.3.238.110','2a02:aa08:e000:3100::2');
select * from test_domain;
- 数据库
数据库起到了命名空间的作用,可以有效规避命名冲突的问题,也为后续的数据隔离提供了支撑。任何一张数据表,都必须归属在某个数据库下。
- 操作语法
create if exeists database scott [ENGINE=engine];
show databases;
drop database if exists db_name;
数据库引擎:
- Ordinary:默认引擎,在绝大多数我们都会使用默认引擎,使用时无需声明,数据库下可以使用任意类型的表引擎。
- Dictionary:字典引擎 此类数据库会自动为所有数据字典创建它们的数据表。
- Memory:用于存放临时数据。此类数据库下的数据表只会停留在内存中,不会涉及任何磁盘操作,当服务重启后数据会被清理。
- Lazy:此类数据库下只能使用Log系统的表引擎。
- MySQL:MySQL引擎,会自动拉取远端MySQL中的数据,为它们创建MySQL表引擎数据表。
- 数据表
第一种创建表方式,使用[db_name.]参数可以为数据表指定数据库,如果不指定此参数,则默认会使用default数据库。
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name (
name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
name2 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
省略…
) ENGINE = engine
CREATE TABLE hits_v1 (
Title String,
URL String ,
EventTime DateTime
) ENGINE = Memory;
第二种定义方法复制其他表结构,支持在不同的数据库之间复制表结构。
CREATE TABLE [IF NOT EXISTS] [db_name1.]table_name AS [db_name2.] table_name2 [ENGINE = engine]
-- 创建新的数据表
CREATE TABLE IF NOT EXISTS new_db.hits_v1 AS default.hits_v1 ENGINE = TinyLog
第三种定义方法是通过SELECT子句的形式创建;根据Select子句建立表结构,同时还要把select子句查询的数据写入。
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name ENGINE = engine AS SELECT …
CREATE TABLE IF NOT EXISTS hits_v1_1 ENGINE = Memory AS SELECT * FROM hits_v1
删除和查看表详情
DROP TABLE [IF EXISTS] [db_name.]table_name
desc table_name
创建临时表:
特点:生命周期与会话绑定,只支持Memory表引擎,会话结束,数据表会被销毁。
临时表不属于任何数据库,建表时没有引擎和数据库参数。
临时表的优先级大于普通表,当临时表和普通表表名称相同时,会优先读取临时表。
create temporary table if not exists table_name(
name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
name2 [type] [DEFAULT|MATERIALIZED|ALIAS expr],
....
);
分区表:数据分区与数据分片不同概念,数据分区是针对本地数据而言,是数据一种纵向切分(数据并行处理),数据分片是数据横行切分(每个节点就是一个分片)。
create table test_partition(
ID String,
URL String,
EventTime Date
)engine =MergeTree()
partition by toYYYYMM(EventTime)
order by ID;
insert into test_partition values ('A000','www.baidu.com','2023-12-25'),('A001','www.google.com','2023-12-26'),('A002','www.hao123.com','2023-12-27');
select *
from test_partition where EventTime='2023-12-25';
-- 查看表名和分区字段 以及数据存储路径
select table,partition,path
from system.parts where table='test_partition';
- 操作表结构
追加新字段
alter table tb_name add column [if not exists] name [type] [default_expr] [after name_after]
-- 添加字段os 默认值是mac
alter table test_partition add column os String default 'mac';
-- 在ID字段后位置添加字段IP
alter table test_partition add column IP String after ID;
修改字段类型
alter table tb_name modify column [if exists] name [type] [default_expr]
-- 修改已有字段的数据类型
alter table testcol_v1 modify column IP IPv4;
修改字段备注
alter table tb_name comment column [if exists] name 'some comment'
-- 修改字段的备注
alter table test_partition comment column ID '主键ID';
删除已有字段
alter table tb_name drop column [if exists] name
-- 删除表中指定的表字段
alter table test_partition drop column ID;
清空表数据
truncate table [if exists] [db_name.]tb_name
truncate table default.test_partition;
- 视图
clickhouse拥有普通视图和物化视图两种!
物化视图支持表引擎,数据保存形式由它的表引擎决定.
物化视图创建好之后,如果源表被写入新数据,那么物化视图也会同步更新。
物化视图声明populate修饰符,创建视图过程中,会连带源表中已存在的数据一并导入,如同执行select into 一般,如果没有声明populate,物化视图只会同步在此之后被写入源表的数据。
物化视图不支持同步删除,如果源表的数据被删除了,物化视图中的数据仍然会保存。
-- 普通视图创建
create view [if not exists] [db_name].view_name as select ...
-- 物化视图创建
create materialized view [if not exists] [db.]table_name [engine=engine] [populate] as
select ....
- 数据的CRUD
数据的写入:
- 使用values常规插入数据。
- 使用指定格式插入数据。
- 使用select子句形式的语法。
-- 常规values数据插入语法
INSERT INTO partition_v2 VALUES ('A0011','www.yjxxt.com', '2019-10-01'),('A0012','www.yjxxt.com', '2019-11-20');
-- 指定格式的插入数据
INSERT INTO partition_v2 FORMAT CSV \
'A0017','www.yjxxt.com', '2019-10-01'\
'A0018','www.yjxxt.com', '2019-10-01'\
-- 使用select子句查询数据插入数据表中
INSERT INTO partition_v2 SELECT 'A0020', 'www.jack.com', now()
数据的删除和修改操作:
- 删除和修改属于Mutation查询,可以看作是alter语句的变种。
- 虽然Mutation能最终实现修改和删除,但是适用于批量数据的删除和修改,并且没有事务,一旦提交无法回滚,会立刻对数据产生影响,并且数据的删除和修改是异步后台过程,语句提交后立即返回。
alter table test_partition delete where ID='A003';
alter table test_partition update ID='100010',OS='android' where ID in (10,20,30);
五、MergeTree
表引擎是clickhouse设计实现中的特色,clickhouse拥有强大的表引擎。合并树家族自身也拥有多种表引擎的变种。其中MergeTree作为ck最基础的表引擎,提供了主键索引、数据分区、数据副本和数据采样等基本能力,而家族中其他的表引擎则在MergeTree的基础之上各有所长。
MergeTree在写入一批数据时,数据总会以数据片段的形式写入磁盘,且数据片段不可修改。为了避免片段过多,ck会通过后台线程,定期合并这些数据片段,属于相同分区的数据片段会被合并成一个新的片段。
- 创表语法
create table [if not exists] tb_name(
name1 [dataType] [Default|materialized|alias expr1] [TTL expr1],
....
)engine=MergeTree()
order by name1,..
[partition by name1]
[primary key name1 ]
[sample by name1]
[TTL expr [delete|to DISK '***'|To VOLUME 'xxx'],...]
[settings name=value,...]
配置选项:
- engine=MergeTree() 表引擎没有参数。
- Order By 在一个数据片段内进行排序,默认排序字段与主键相同;排序字段可以是多个使用元组设置,如:Orderby(column1,column2,...)
- Partition By:分区字段,可选项,指定表数据以何种标准排序。
- Primary Key:主键,用于加速表查询。一般情况下,单个数据片段内,数据与一级索引以相同的规则升序排列。与其他数据库不同,MergeTree主键允许存在重复数据。
- Sample By:抽样表达式,用于声明数据以何种标准进行采样;如果用抽样表达式,主键中必须包含这个表达式,如:SAMPLE BY intHash32(UserID) ORDER BY (CounterID, EventDate, intHash32(UserID))。
- TTL: 指定行存储的持续时间并定义数据片段在硬盘和卷上的移动逻辑的规则列表。
- SETTINGS:控制MergeTree行为的额外参数,可选项:
- index_granularity: 索引粒度。索引中相邻的『标记』间的数据行数,默认值8192 。
- index_granularity_bytes: 索引粒度,以字节为单位,默认值:10Mb。如果想要仅按数据行数限制索引粒度, 可 以设置为0,但是不建议。
- min_index_granularity_bytes: 允许的最小数据粒度,默认值:1024b。该选项用于防止误操作,添加了一个非常 低索引粒度的表。
- enable_mixed_granularity_parts: 是否启用通过index_granularity_bytes控制索引粒度的大小。
- use_minimalistic_part_header_in_zookeeper:ZooKeeper中数据片段存储方式。如果 use_minimalistic_part_header_in_zookeeper=1,ZooKeeper会存储更少的数据。
- min_merge_bytes_to_use_direct_io: 使用直接I/O来操作磁盘的合并操作时要求的最小数据量,设置的字节数。
- merge_with_ttl_timeout: TTL合并频率的最小间隔时间,单位:秒。默认值:86400(1 天)。

-- 建表案例
create table emp(
empno Int32,
ename String,
job String,
mgr Int32,
hiredate DateTime,
sal Float64,
comm Nullable(Float64),
deptno Int32
)engine =MergeTree()
partition by deptno
order by empno
settings
index_granularity=4096,
min_bytes_for_wide_part=0,
min_rows_for_wide_part=0;
insert into emp values (7788, 'scott', 'teacher', 1122, '2012-11-22', 6666.88, 108.0, 10), (8899, 'smith', 'teacher', 1122, '2012-10-22', 7777.88, 108.0, 20);
-- 查看表元数据
select *
from system.tables;
- 存储格式
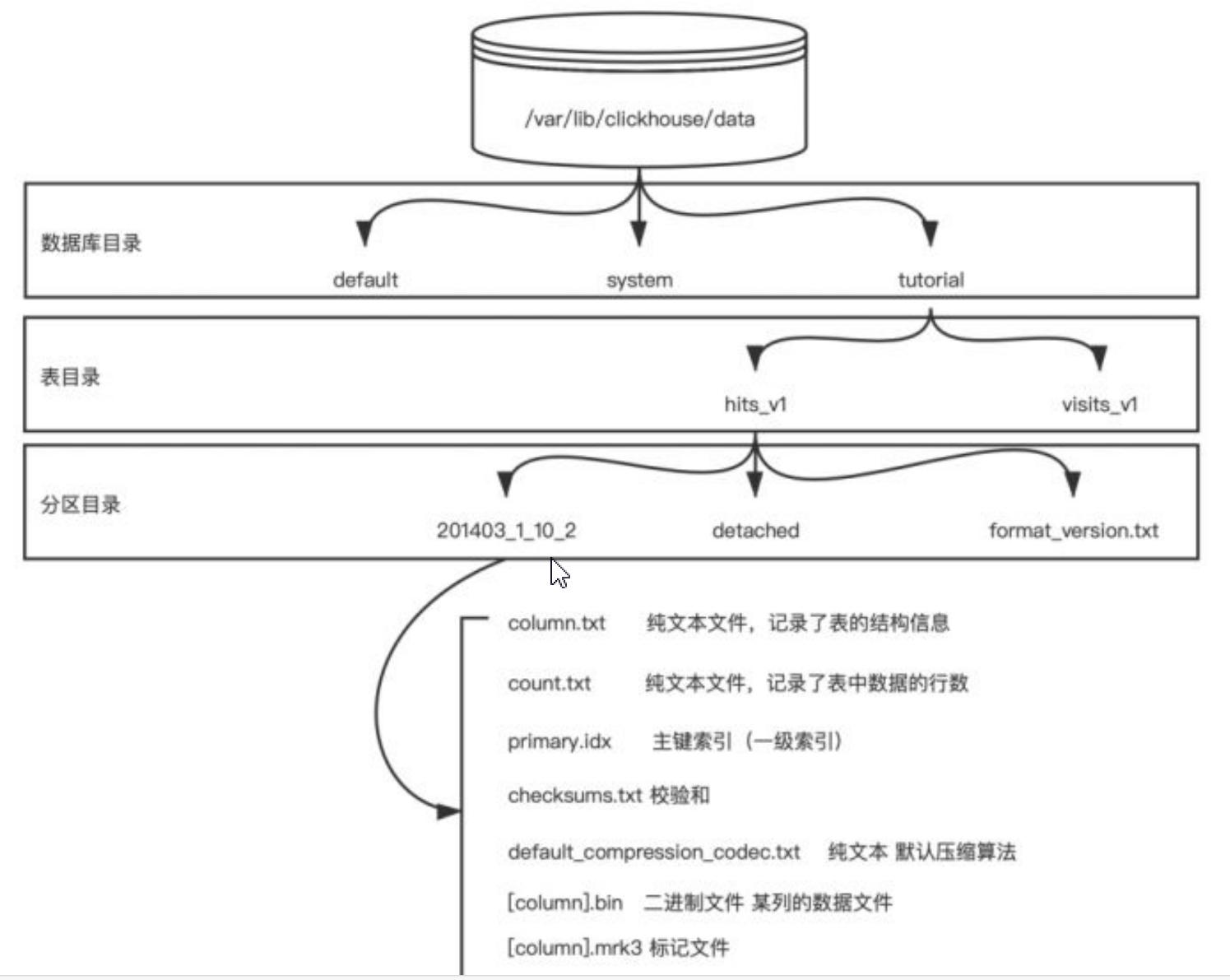
- MergeTree表引擎中的数据是拥有物理存储的,数据会按照分区目录的形式保存到磁盘之上。
- 一张数据表目录在数据库目录下,有数据表目录,数据表目录下有分区目录,分区目录下有各个分区下具体的数据文件如下:
- partition:分区目录,余下各类数据文件(primary.idx、[Column].mrk、[Column].bin等)都是以分区目录的形式组织存放,属于通分区数据会合并到一个分区内,不同分区数据不会合并。
- checksums.txt:校验文件,使用二进制格式存储。用于快速校验文件的完整性和正确性。
- columns.txt: 列信息文件,使用明文格式存储。保存数据分区下的列字段信息。
- count.txt: 计数文件,使用明文格式存储。记录数据分区目录下的数据的总行数。
- primary.idx: 一级索引,使用二进制格式存储。用于存放稀疏索引,减少扫描范围,提升查询效率。
- [Column].bin:数据文件,使用压缩格式存储,默认为LZ4压缩格式,用于存储某一列数据。
- [Column].mrk:列字段标记文件,使用二进制格式存储。标记文件中保存了.bin文件中数据的 偏移量信息。
- [Column].mrk2:如果使用了自适应大小的索引间隔,则标记文件会以.mrk2命名。它的工作 原理和作用与.mrk标记文件相同。
- partition.dat与minmax_[Column].idx:如果使用了分区键,例如PARTITION BY EventTime,则 会额外生成partition.dat与minmax索引文件,它们均使用二进制格式存储。
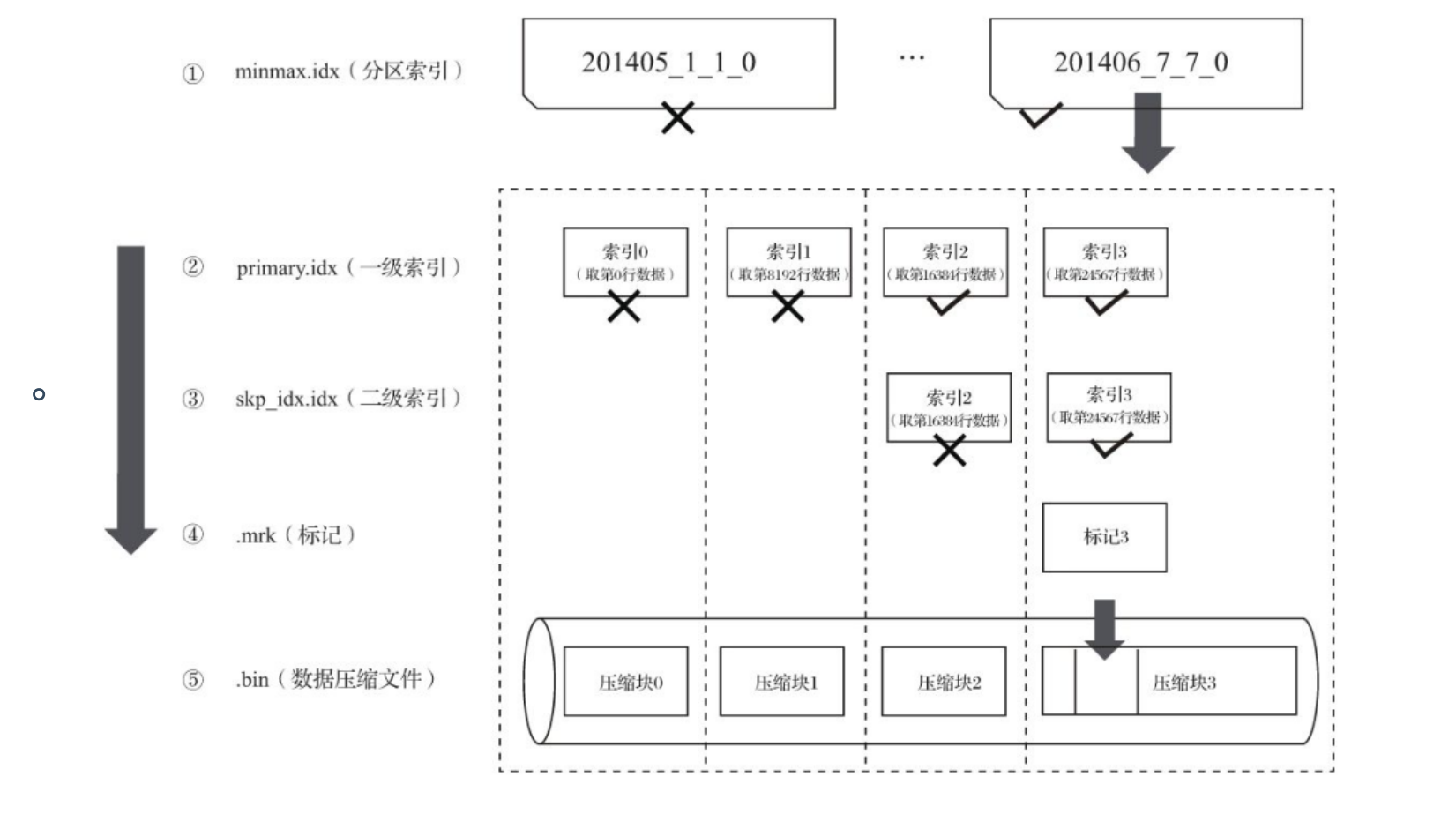
- skp_idx [Column].idx与skp_idx [Column].mrk:如果在建表语句中声明了二级索引,则会额外 生成相应的二级索引与标记文件,它们同样也使用二进制存储。这些索引的最终目标 与一级稀疏索引相同,都是为了进一步减少所需扫描的数据范围,以加速整个查询过程。目前拥有minmax、set、ngrambf_v1和tokenbf_v1四种类型。
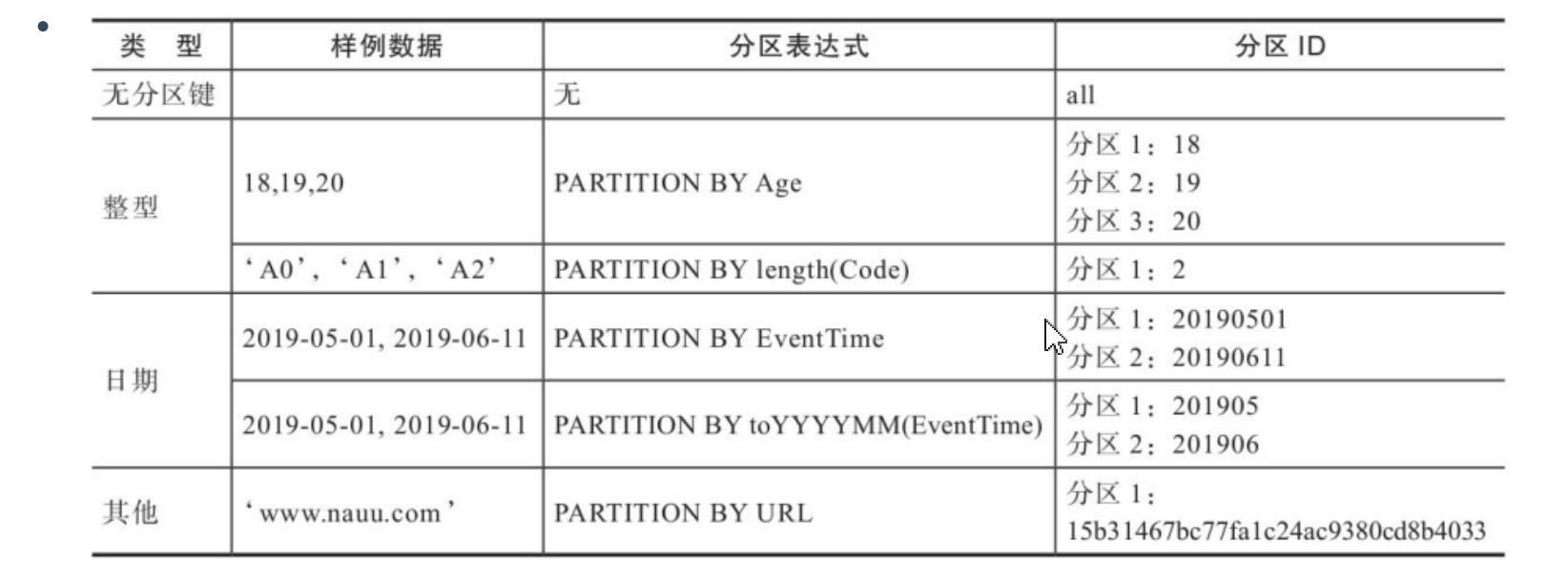
- 数据分区
数据分区规则:数据分区规则由分区ID决定,具体到每个数据分区所对应的ID,则是由分区键的取值决定。
有如下四种规则:
不指定规则:分区ID默认取名为all,所有数据写入all分区。
使用整型:无法转换为日期类型YYYYMMDD格式按照整型格式作为分区ID
使用日期类型:分区键属于日期类型,能够转换为YYYYMMDD格式的整型,按照YYYYMMDD格式输出作为分区ID。
使用其他类:如果既不是整型也不是日期类型,通过128位hash算法取其hash值作为分区ID的取值。
- 分区目录命名
完整分区命名公式:
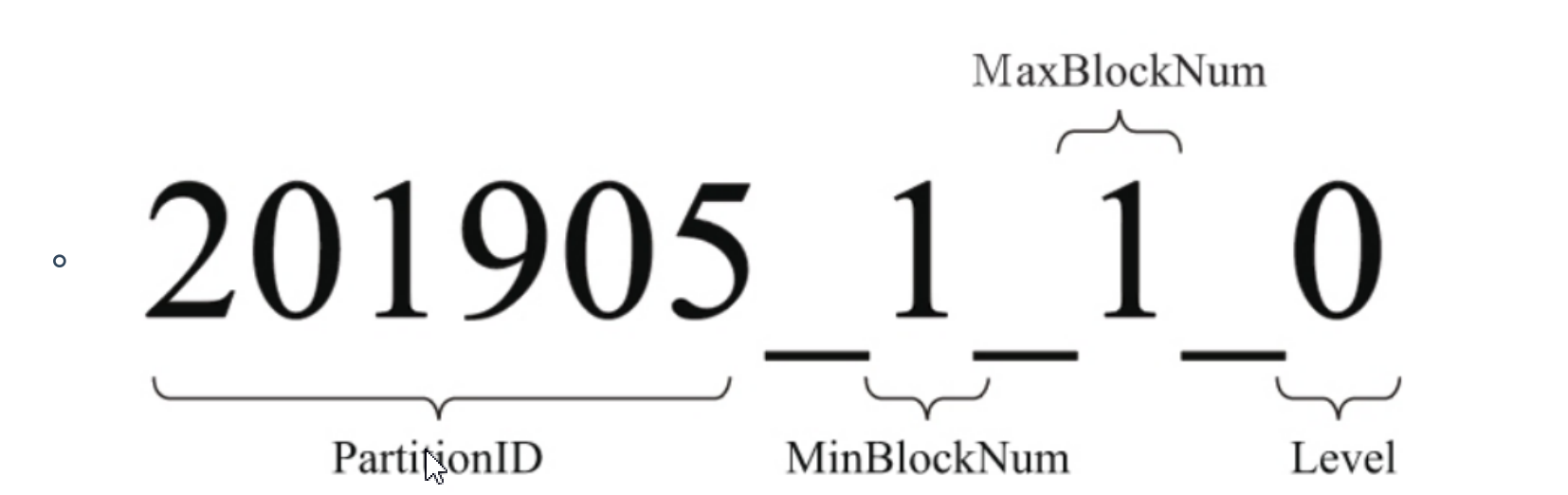
partitionID:表示分区字段值
MinBlockNum:全局最小数据块编号
MaxBlockNum:全局最大数据块编号
level:合并的层级,可以理解为某个分区被合并过的次数,或者这个分区的年龄。数值越高 表示年龄越大。
- 分区目录合并
MergeTree分区目录与传统意义上其他数据库有所不同。MergeTree的分区目录并不是在数据表被创建之后就存在的,而是在数据写入过程中被创建的。一张表没有数据时,就不会有任何分区目录,分区目录也不是一成不变的。
追加数据后自身不会发生变化,相同分区目录中追加新的数据文件。MergeTree伴随的一批数据的写入,会生成一批分区目录。即便不同批次写入的数据属于相同分区,也会生成不同的分区目录。同个分区不同目录会通过后台进行合并(一般10~15分钟)也可以手动执行optimize查询语句,最终合并成最新的目录,已经存在的旧分区目录并不会立即被删除,而是在之后通过后台任务删除(默认8分钟)。
合并后的新分区目录命名规则:
- MinBlockNum:取同一分区内所有目录中最小的MinBlockNum值。
- MaxBlockNum:取同一分区内所有目录中最大的MaxBlockNum值。
- Level:取同一分区内最大Level值并加1。
-- 手动合并
optimize table db_Name.table_Name;
- 一级索引
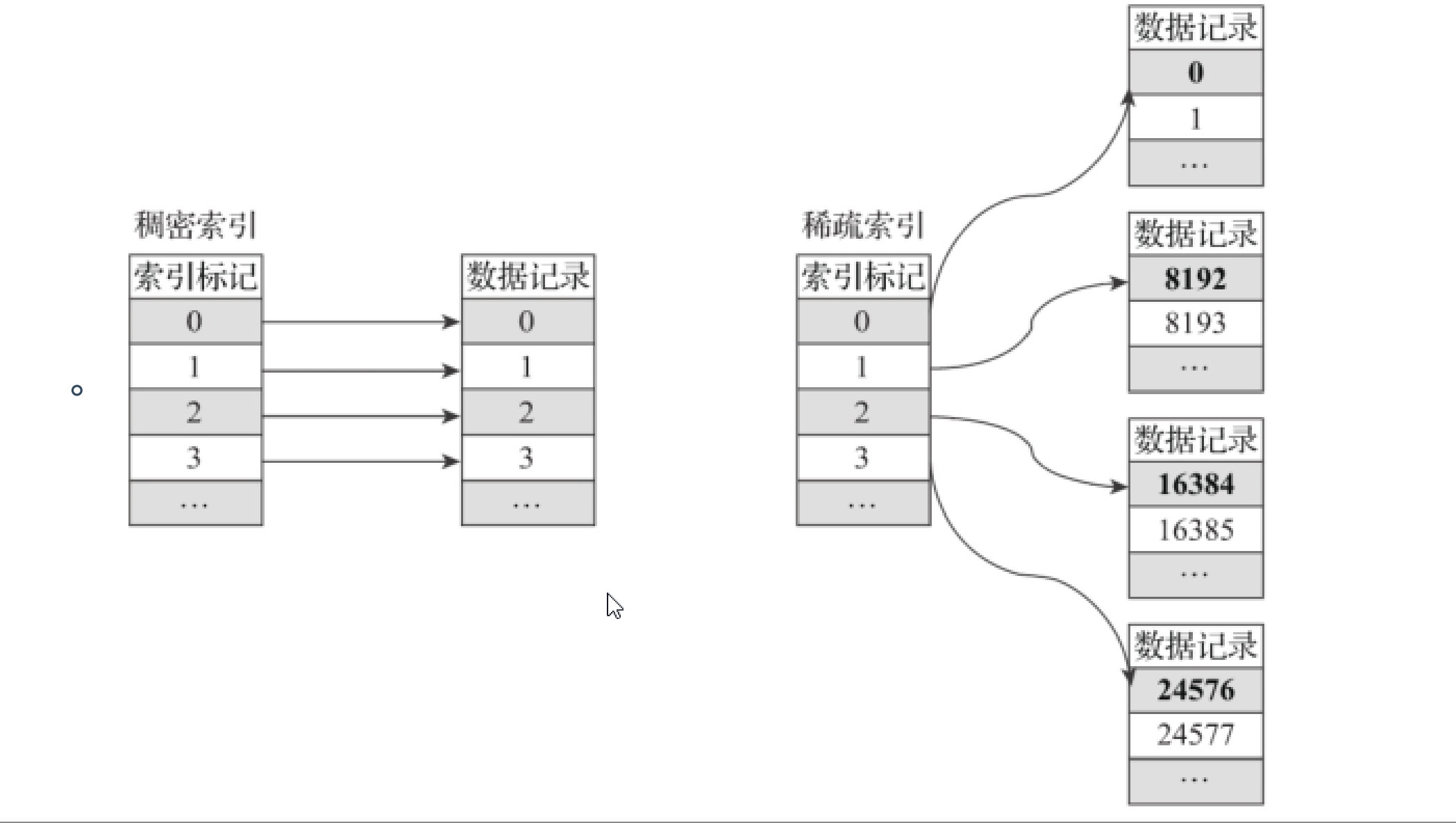
MergeTree主键使用Primary key定义,定义主键后,MergeTree会依据index_granularity间隔(8192行),为数据表生成一级索引并保存至primary.idx文件内,索引按照primary key排序。(稀疏索引)
稀疏索引的优势显而易见的,它仅需使用索引标记大量区间位置信息,数据量越大优势越明显。
- 默认的索引粒度(8192行记录)为例,MergeTree只需要12208行索引标记就能为1亿(12208*8192)数据记录提供索引。
- 由于稀疏索引占用空间小,所以primary.idx内索引数据常驻内存,数据查询效率快!
- 索引文件查看命令(索引文件是二进制文件)
od -An -i -w4 primary.idx
- 索引粒度
索引粒度就如同标尺一般,会丈量整个数据的长度,依照刻度对数据进行标注,最终将数据标记成多个间隔的小段。

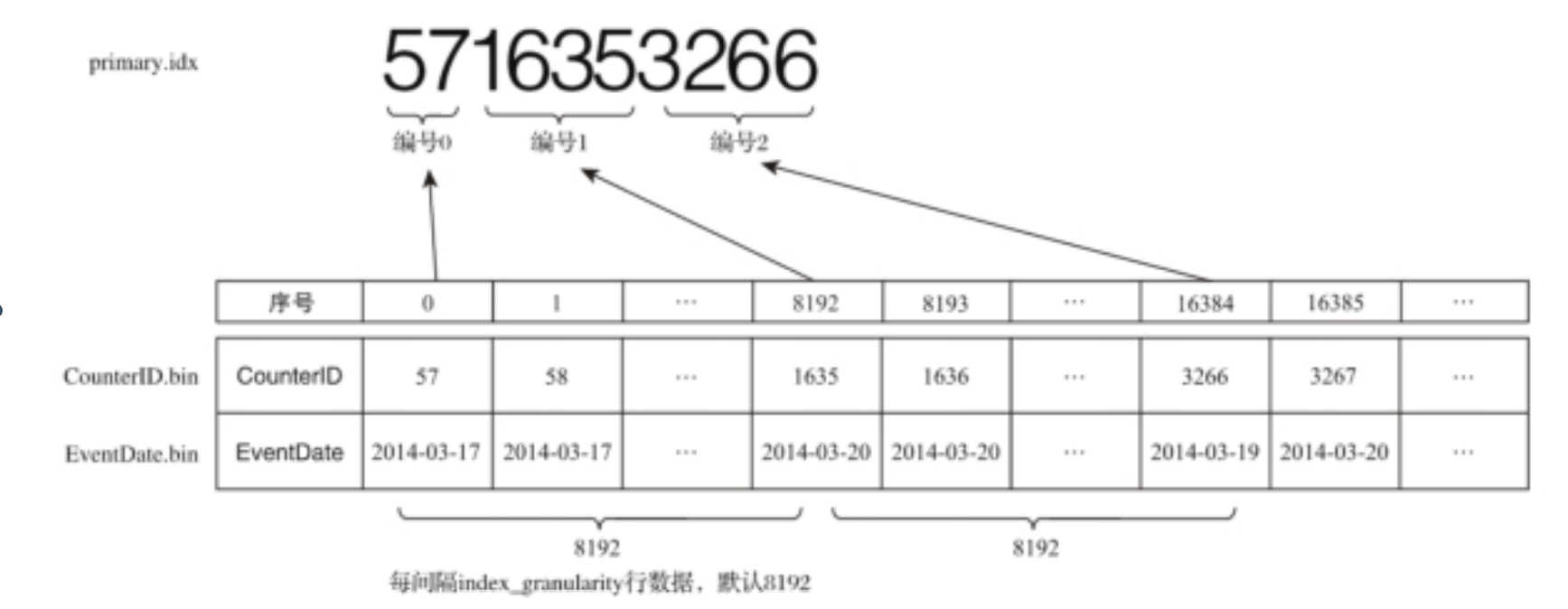
- 单主键稀疏索引图
使用单个主键相当于kafka中index文件中的offset。
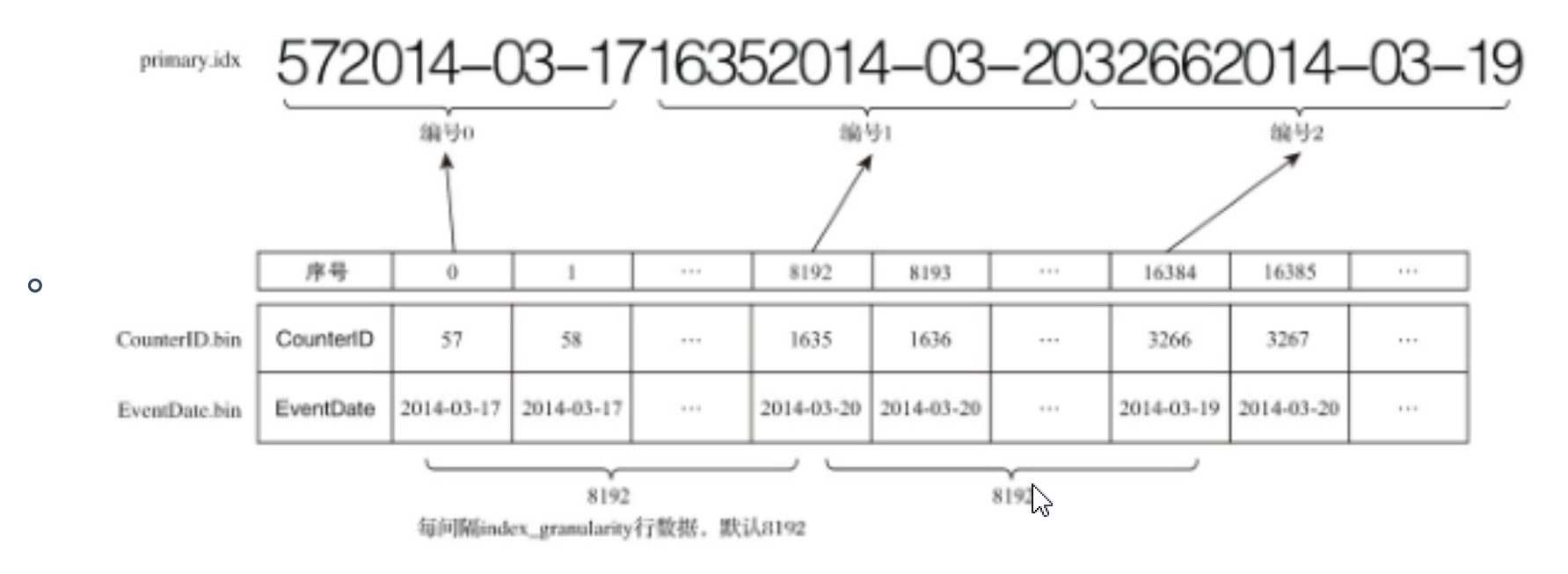
- 多主键稀疏索引图
多个主键值联合在一起,相当于kafka中的offset。
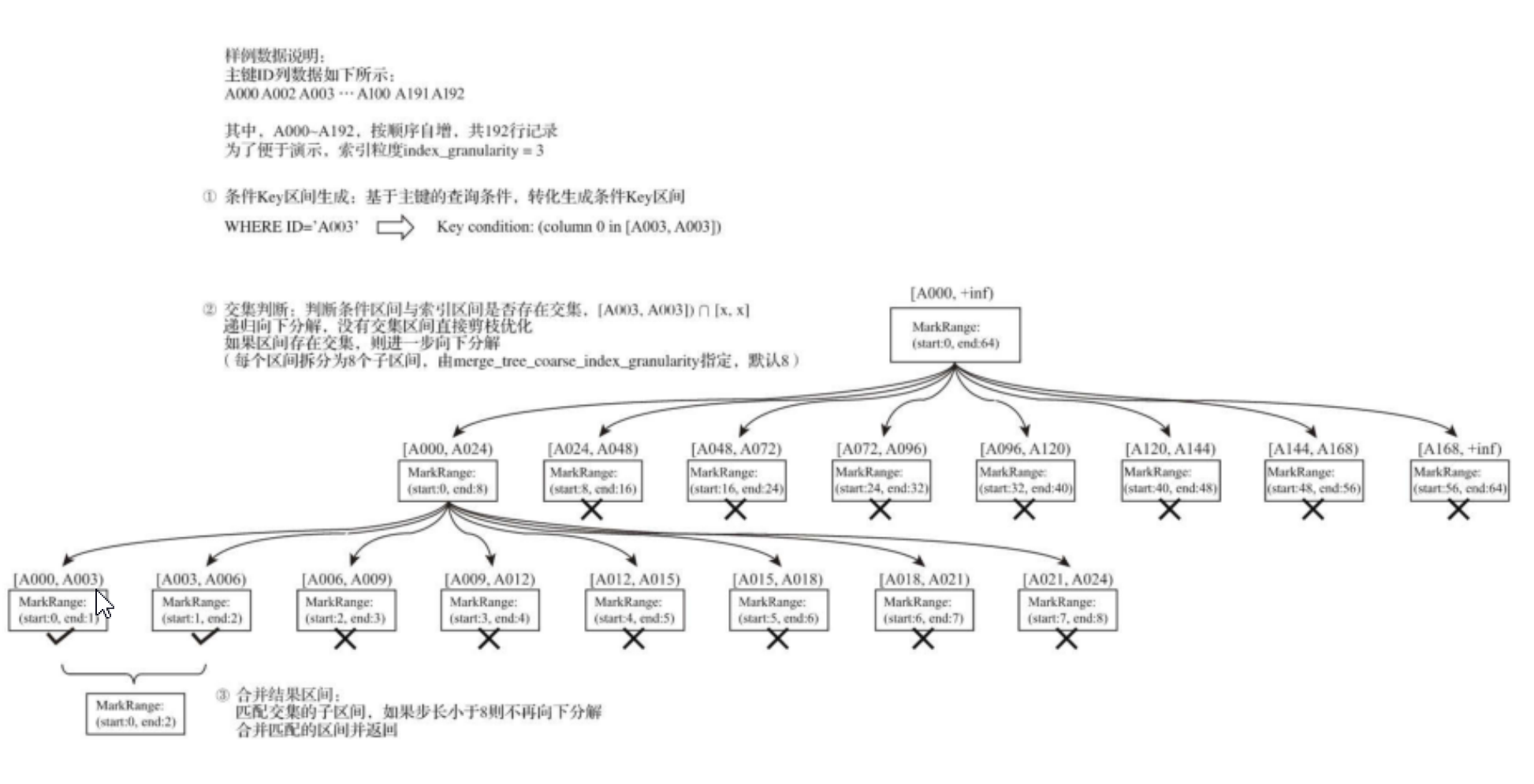
- 索引查询过程

MarkRange:A000 - A003表示一个MarkRange,用于标记稀疏索引粒度的对象。
MergeTree按照index_granularity的间隔粒度,将一段完整的数据划分成了多个小的间隔数据 段,一个具体的数据段即是一个MarkRange。
MarkRange与索引编号对应,使用start和end两个属性表示其区间范围 如:[A000,A003]。
索引查询其实就是两个数值区间的交集判断:
- 递归交集判断:以递归的形式,依次对MarkRange的数值区间与条件区间做交集判断。从最大的区间[A000,+inf)开始:
- 如果不存在交集,则直接通过剪枝算法优化此整段MarkRange。
- 如果存在交集,且MarkRange步长大于8(end-start),则将此区间进一步拆分成8个子区间, 并重复此规则,继续做递归交集判断。
- 如果存在交集,且MarkRange不可再分解(步长小于8),则记录MarkRange并返回。
- 合并MarkRange区间:将最终匹配的MarkRange聚在一起,合并它们的范围。
- 二级索引
有的列不想当做主键,但是这个字段查询次数又多,就需要自定义索引(二级索引),二级索引又称跳数索引,能够跳过index_granularity区间数据。目的也是减小数据查询范围。
跳数索引在默认情况下是关闭的,需要设置allow_experimental_data_skipping_indices
- SET allow_experimental_data_skipping_indices = 1
- 跳数索引需要在CREATE语句内定义,它支持使用元组和表达式的形式声明,其完整的定义语法:
create index index_name expr TYPE index_type(...) GRANULARITY granularity跳数索引有4种分类:
- minmax索引记录了一段数据内的最小和最大极值,其索引作用类似分区目录的minmax索引,能够快速跳过无用的数据区间。
- set索引直接记录了声明字段或表达式的取值(唯一值、无重复),其完整形式为set(max_rows),其中max_rows是一个阈值,表示在索引粒度内,索引最多记录的数据行数。(total_rows/index_granularity)
- ngrambf_v1索引记录的是数据短语的布隆表过滤器,只支持String和FixedString数据类型。只能够提升in、notIn、like、equals和notEquals查询的性能,筛选出不合条件的数据.
- tokenbf_v1:tokenbf_v1索引是布隆过滤器的变种,除了短语token处理方法外,其他都一样,会把非字符串以及数字类型分割token。

create table skip_test(
ID String,
URL String,
Code String,
EventTime String,
Index a ID Type minmax Granularity 5,
Index b (length(ID)*8) Type set(2) granularity 5,
Index c (ID,Code) Type ngrambf_v1(3,256,2,0) granularity 5,
Index d ID Type tokenbf_v1(256,2,0) granularity 5
)engine = MergeTree()
order by ID;
- 数据存储
在MergeTree中,数据按列存储。而具体到每个列字段,数据也是独立存储的,每个列字段都拥有一个与之对应的.bin数据文件。也正是这些.bin文件,最终所有的数据存储到物理存储。
数据文件以分区目录存放,每个分区目录中只保留分区片段内部分数据。
优势:一是可以更好地进行数据压缩;二是能够最小化数据扫描范围。
数据最终压缩程压缩数据块存储到.bin文件中,默认压缩格式:LZ4、ZSTD、Multiple和Delta,默认使用LZ4算法,数据会实现依照order by的声明排序。
- 压缩方式
数据压缩前头信息固定使用9位字节表示,具体由1个UInt8(1字节)整型和2个UInt32(4字节)整型组成;分别代表使用的压缩算法类型、压缩后数据大小和压缩前数据大小
bin压缩文件是由多个压缩数据组成,每个压缩数据块的头信息则是基于
CompressionMethod_CompressedSize_UncompressedSize公式生成的。
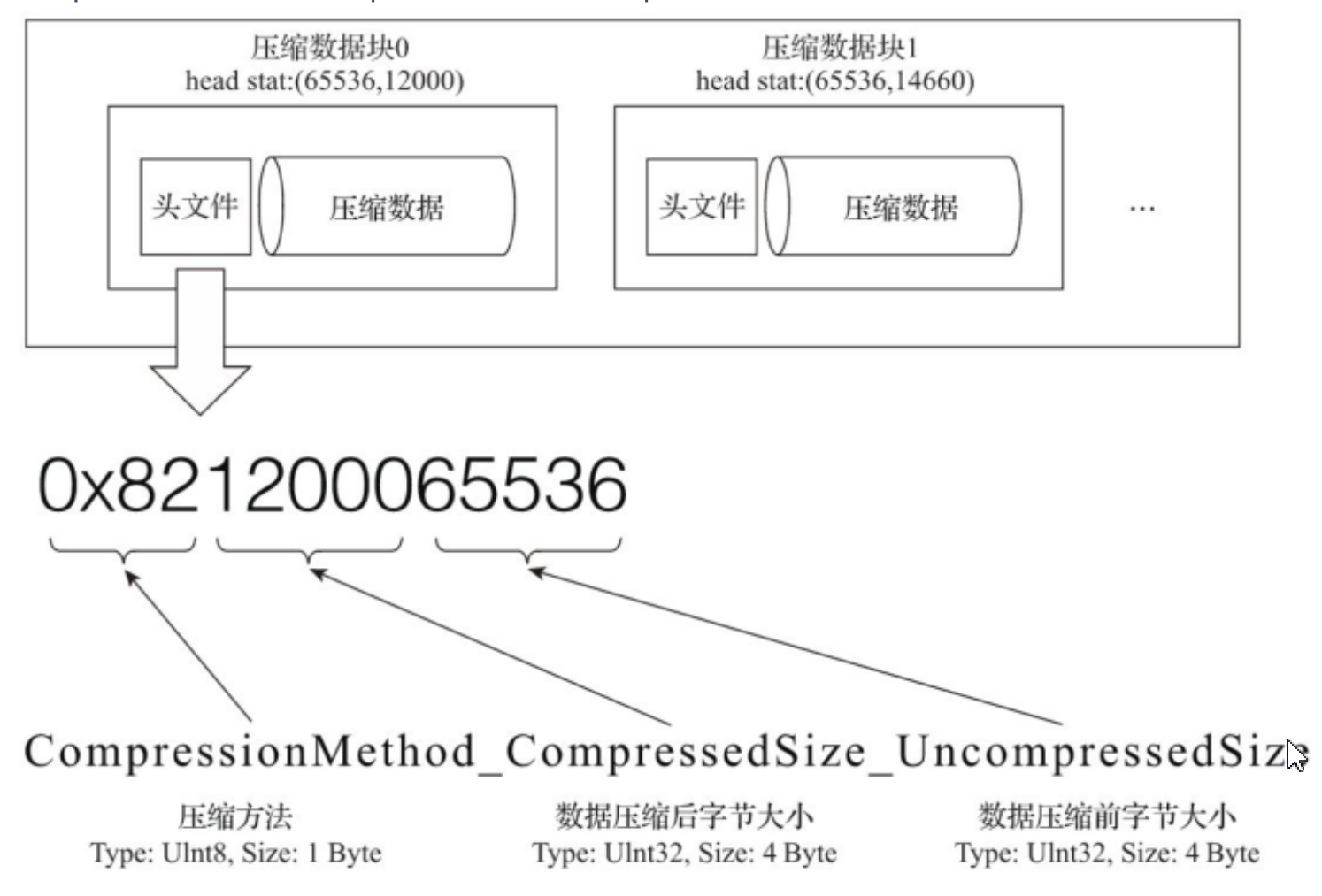
- .bin压缩文件形成果过程
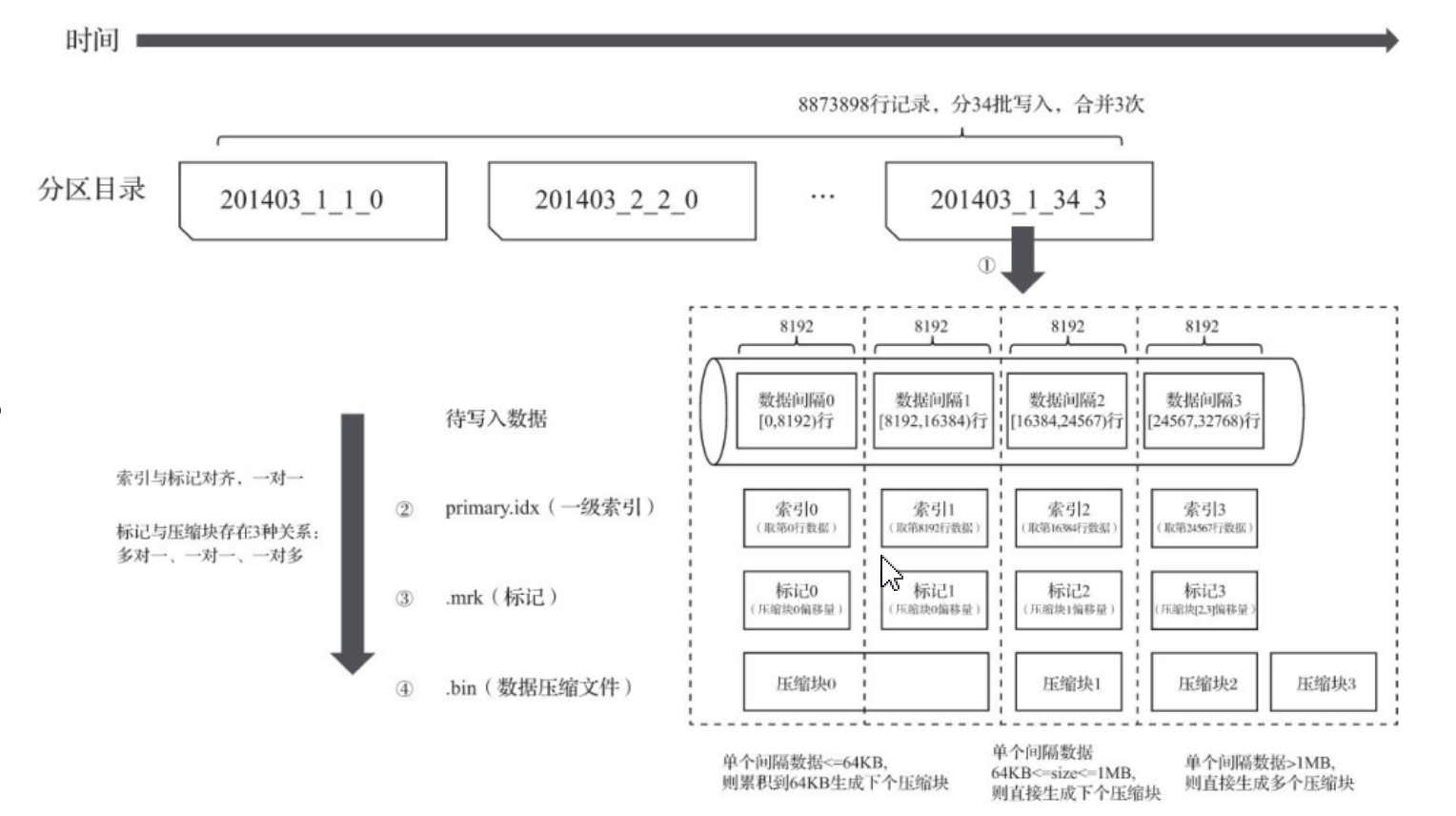
首先默认8192条记录压缩前,形成一个小文件,压缩小文件由头文件和压缩数据组成;为了防止小文件查询影响查询性能,ck数据库默认达到64Kb并且小于等于1MB进一步压缩小文件成数据块,最终所有压缩好的数据块写入.bin文件中。没有达到64Kb数据块跨压缩数据块合并压缩,大于1MB数据块拆成1MB压缩和超出数据块循环以上方式压缩。
优势:降低存储空间并加速数据传输效率; 具体读取某列数据时,可以不读取整个.bin,通过读取粒度降低到压缩数据块级别,进一步缩小数据读取的范围。
压缩后,头信息数据大小由压缩前9字节变成8位字节!
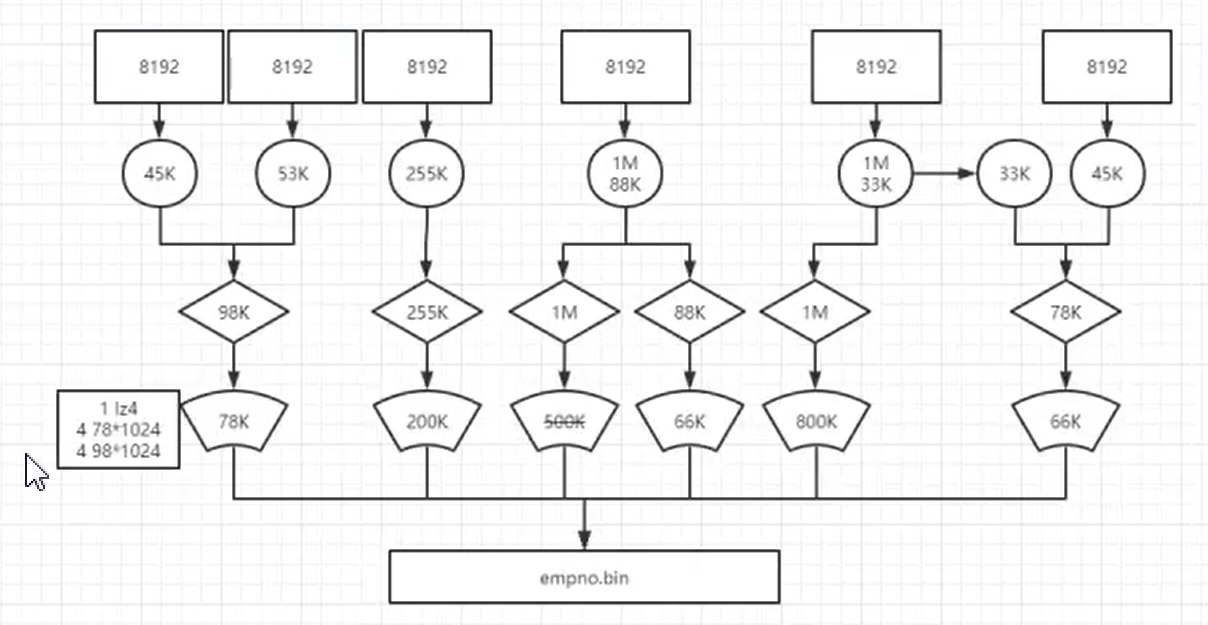

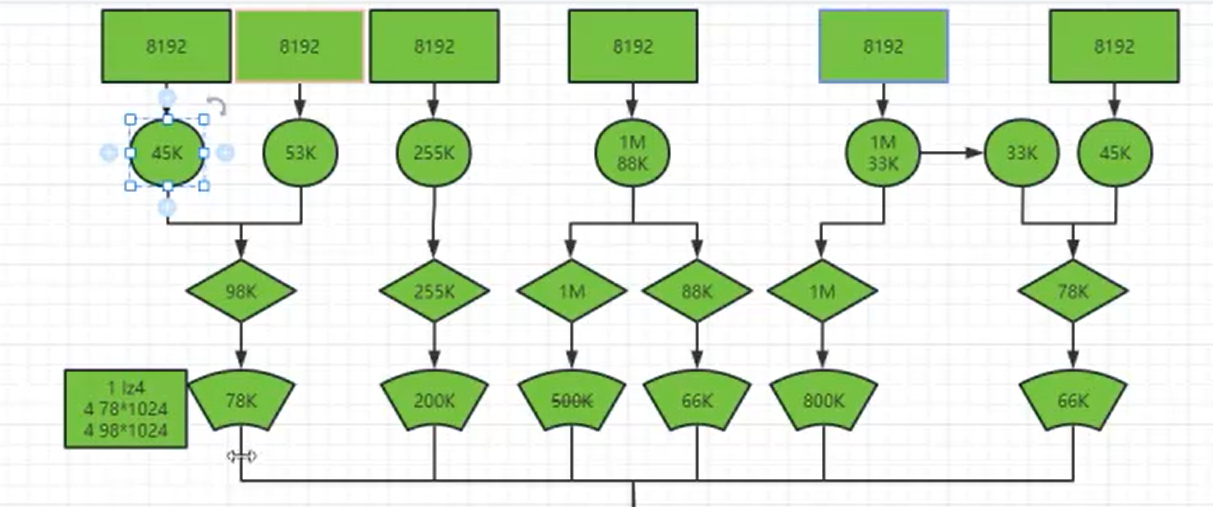
- ck工作方式
ck数据库通过数据标记文件(*.mrk)作为衔接一级索引和数据的桥梁,像我们做过标记小抄的书签,书本中各个章节都有各自书签。
数据理解:
- 假设一条记录为1个字节,那么默认的索引粒度是8192行记录,那么未压缩数据块大小是8192个字节,然后小文件达到65536个字节(64KB)进行压缩,最后65536/8192=8,相当于8个8192条记录小文件才能凑成一个64字节(压缩前大小)数据压缩块==。因此有8个偏移量为0的压缩数据块文件。
- 8个偏移量为0的小文件对应第0个压缩数块,第0个压缩数据块对应的数据压缩大小为12000Byte,头文件大小为8Byte,一个压缩数据块对应的是8个8192条记录小文件,一个小文件索引粒度默认是8192,第0个压缩数据块解压后偏移量就是[0,8192)。
- 然后第1个压缩数据块,数据标记文件中的偏移量是8字节+12000字节+8字节=12016Byte,数据标记文件中从偏移量为12016开始标记,65536/8192=8个小文件(每个小文件8192行记录),就有8个偏移量为12016开始记录,映射第1个压缩数据块,最后映射8个小文件中MarkRange是[8192,16384)范围中寻找数据。
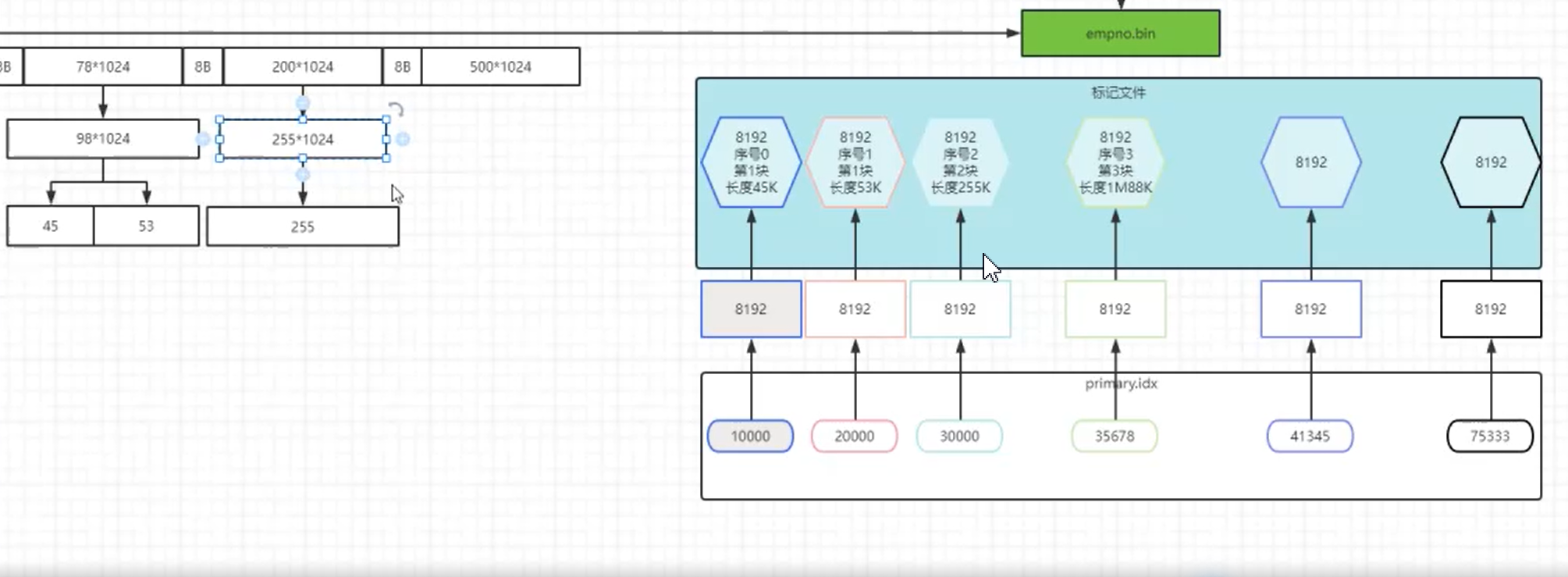
- 总结:
*.mrk文件中保存着读取压缩块起始数据大小偏移量(第n个数据块头信息大小+压缩数据大小+第n+1个数据块头信息大小)。
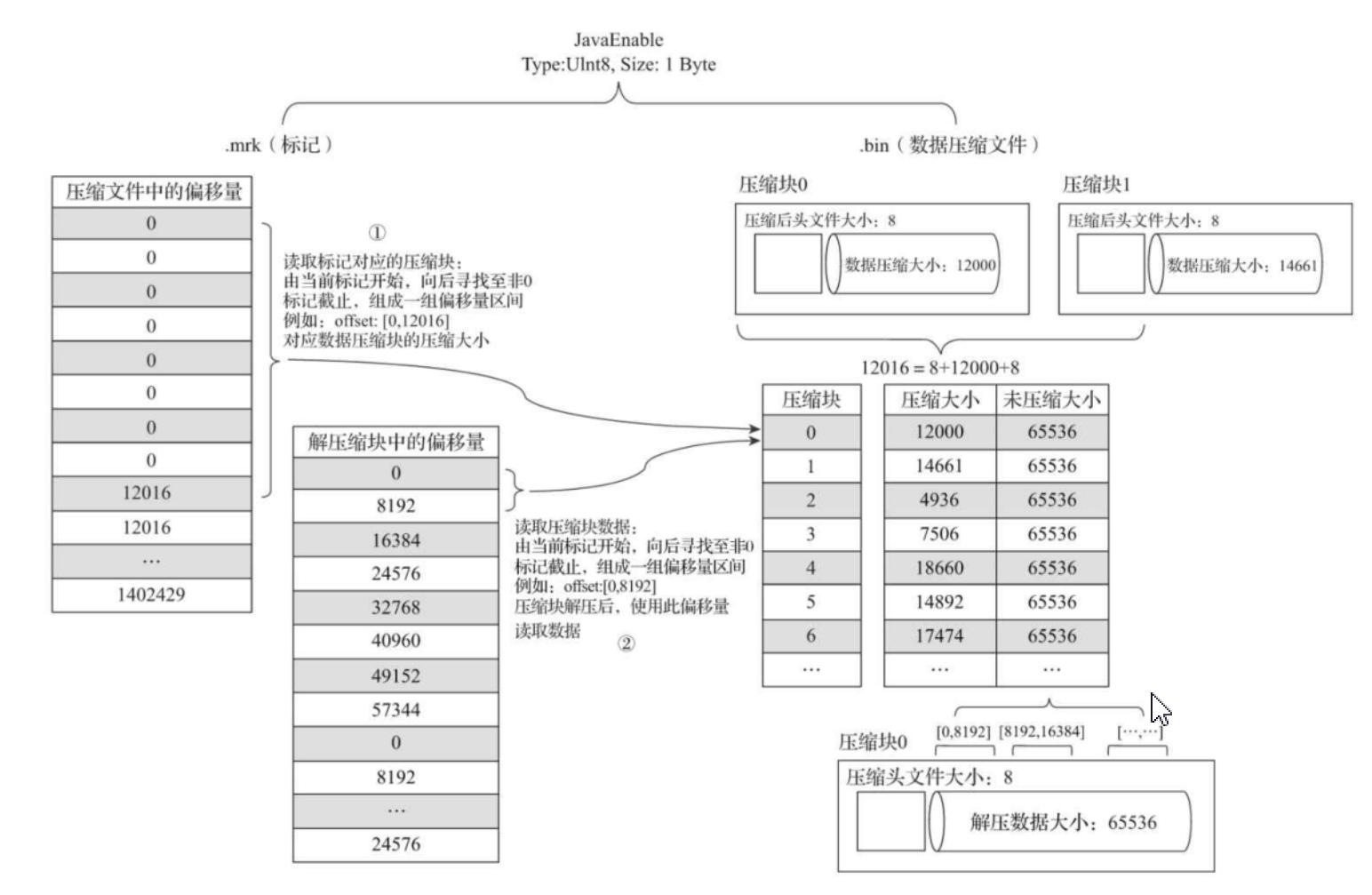
- *.mrk文件内容
压缩文件中的偏移量实际上存储的是压缩后字节大小从0开始读,也就是一个8192行数据小文件压缩后的读取大小对应一个索引粒度中的稀疏索引物理行号([0,8192),[8192,16384)....),一个压缩数据块内有多个小文件,所以有多个重复的起始偏移量。图中第9行以后开始读取下一个压缩数据块,起始偏移量就是2个头信息字节数+压缩文件大小(12016字节)。
有几个重复压缩中的偏移量表示一个压缩数据块内有几个小文件(8192行数据小文件),偏移量为读取压缩块起始数据块数据大小(Byte)。
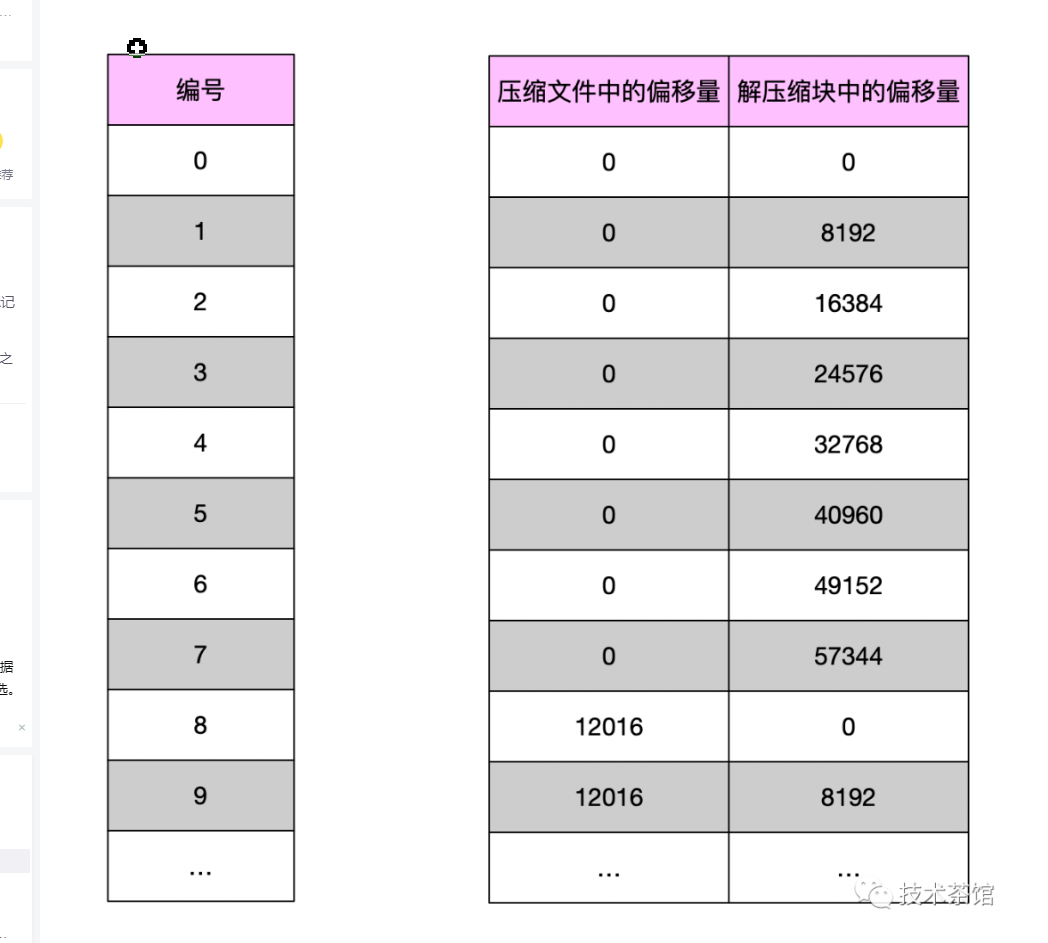
根据小文件压缩前大小与数据标记产生三种不同的对应关系如下:
- 多对一
也就是小文件压缩数据前大小不足64KB时,产生多对一关系,如上ck工作方式图!
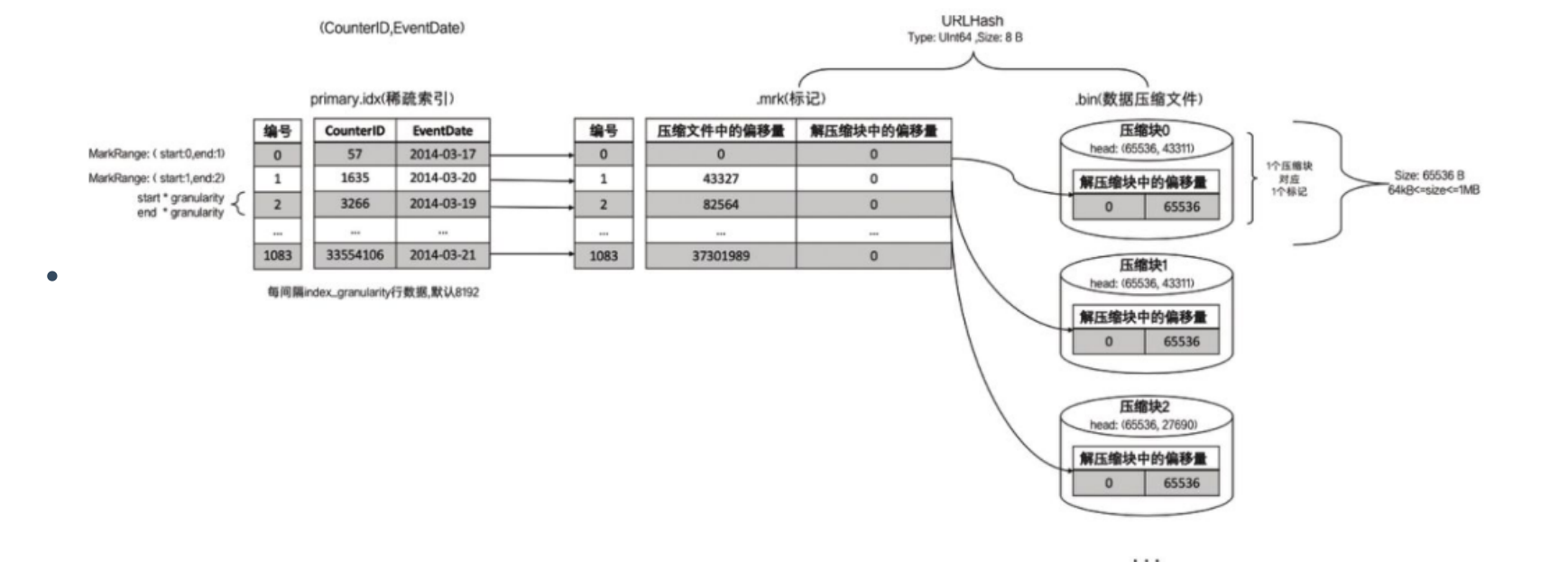
- 一对一
小文件压缩前大小超过64KB小于等于1MB时,产生一对一关系,也就是压缩后数据块就对应一个一次压缩数据块,一个小文件映射一个稀疏索引,如下图:
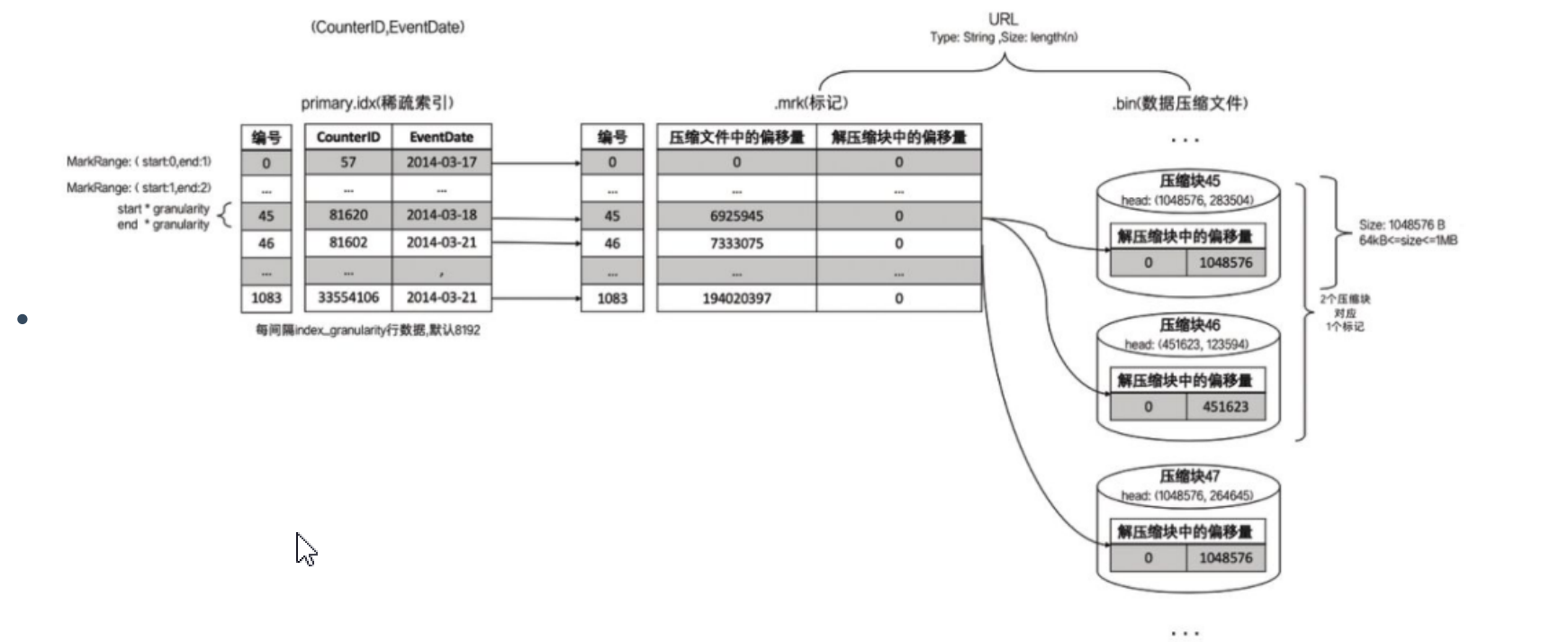
- 一对多
小文件压缩前超过1MB大小,产生一对多关系,也就是一个数据标记对应多个压缩数据块!
- 数据读写流程
写入数据: 数据写入时首先建立分区目录,伴随这每一批数据的写入,都会生成一个新的分区目录。在后续得到某一个时刻,属于相同分区的目录会依照规则合并在一起,最后按照index_granularity索引粒度(默认是8192行数据),会生成primary.idx一级索引、.mrk数据标记文件、bin压缩数据文件。
查询数据:本质是通过一级索引和二级索引不断把扫描数据范围减小。然后借助数据标记,将需要解压与计算的数据范围缩至最小。
六、MergeTree Family
- 数据TTL
在MergeTree中,可以为某个字段或整张表设置TTL。
- 当时间到达时,如果是列字段级别的TTL,则会删除这一列的数据。
- 如果是表级别的TTL,则会删除整张表的数据。
- 如果同时设置了列级别和表级别的TTL,则会以先到期的那个为主。
设置TTL
- interval完整的操作包括Second,Minute、Hour、Week、Month、Quarter和Year。
- clickhouse没有提供取消列级别TTL的方法。
- TTL的运行机制 如果一张MergeTree表被设置了TTL表达式,那么在写入数据时,会以数据分区为单位,在每个分区目录内生成一个名为ttl.txt的文件。
- 表级别设置TTL
-- 只是定时删除表数据 对表结构没有影响!时间越早TTL先生效,后面设置的TTL自动失效!
create table ttl_table_v2(
id String,
create_time Datetime,
code String TTL create_time+interval 10 second,
type UInt8
)engine =MergeTree
partition by toYYYYMM(create_time)
order by create_time
TTL create_time+interval 1 minute;
insert into ttl_table_v2 values ('10001',now(),'100',1),('10002',now(),'200',2),('10003',now(),'300',3);
select * from ttl_table_v2;
- 多路径存储策略
19.15版本之前,MergeTree只支持单路径存储,所有的数据都会被写入config.xml配置中path指定的路径下,即使服务器挂载了多块磁盘,也无法有效利用这些存储空间。
新版开始,MergeTree实现了自定义存储策略的功能,支持以数据分区为最小移动单元,将分区目录写入多块磁盘目录。
- 默认策略:MergeTree原本的存储策略,无须任何配置,所有分区自动保存到config.xml配置中path指定的路径下。
- JBOD策略:JBOD的全称是Just a Bunch of Disks,它是一种轮询策略,每执行一次INSERT或者 MERGE,所产生的新分区会轮询写入各个磁盘。
- HOT/COLD策略:将存储磁盘分为HOT与COLD两类区域。 HOT区域使用SSD这类高性能存储媒介,注重存取性能; COLD区域则使用HDD这类高容量存储媒介,注重存取经济性。
- 数据在写入MergeTree之初,首先会在HOT区域创建分区目录用于保存数据,当分区数据 大小累积到阈值时,数据会自行移动到COLD区域。
- 配置方式
存储配置需要预先定义在config.xml配置文件中,由storage_configuration标签表示。
在storage_configuration之下又分为disks和policies两组标签,分别表示磁盘与存储策略。
<storage_configuration>
<disks>
<disk_name_a> <!--自定义磁盘名称 -->
<path>/chbase/data</path> <!—- 磁盘路径 -->
<keep_free_space_bytes>1073741824</keep_free_space_bytes>
</disk_name_a>
<disk_name_b>
<path>… </path>
<keep_free_space_bytes>...</keep_free_space_bytes>
</disk_name_b>
</disks>
<policies>
<default_jbod> <!--自定义策略名称 -->
<volumes>
<jbod> <!—-自定义名称磁盘组-->
<disk>disk_name_a</disk>
<disk>disk_name_b</disk>
</jbod>
</volumes>
</default_jbod>
</policies>
</storage_configuration>
- ReplacingMergeTree
由于ck数据主键没有唯一键的约束,意味着即便多行数据的主键相同,还是可以正常写入,ReplacingMergeTree是以分区为单位删除重复数据,也就是说每个分区内主键不能重复,不同分区内主键可以重复,要想主键全局唯一表就不能分区。
engine=ReplacingMergeTree(var),var是选填参数,需要指定一个UInt、Date或者DateTime类型的字端作为版本号,这个参数决定去重时算法。
-- 分区主键去重
create table replace_table(
id String,
code String,
create_time Datetime
)engine =ReplacingMergeTree(create_time)
partition by toYYYYMM(create_time)
order by (id,code)
primary key id;
insert into replace_table select number%10 ,'code', '2021-05-01' from numbers(20);
insert into replace_table select number%10 ,'code', '2021-05-03' from numbers(20);
insert into replace_table select number%10 ,'code', '2021-06-01' from numbers(20);
insert into replace_table select number%10 ,'code', '2021-07-01' from numbers(20);
insert into replace_table select number%10 ,'code', '2021-07-03' from numbers(20);
-- 手动合并分区
optimize table replace_table final ;
-- 查询合并分区的数据
select * from replace_table;
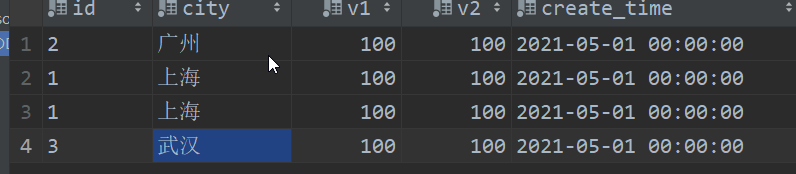
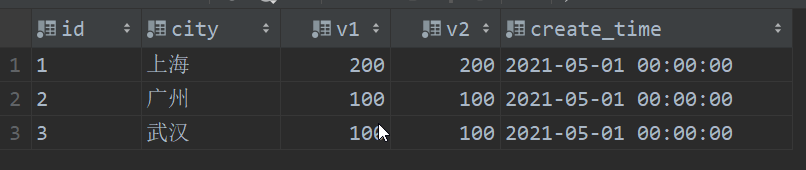
- SummingMergeTree
只需要关注查询数据的汇总结果,不关系明细数据,并且数据的汇总条件是预先明确的,相当于先group by再进行sum()求和。能够在合并分区的时候按照预先定义的条件聚合汇总条件,将同一分组下的多行数据汇总合并成一行,这样既减少数据行,又降低后续汇总查询开销。
summingMergeTree(column)引擎,如果没有指定列字段值,默认以order by中的字段为key进行分组,在进行分区合并时,把每个分区中,除主键外的字段为数值型的数据进行相加聚合(sum())。不参与聚合计算的记录,会显示第一行记录。
- sql案例
create table summing_table(
id String,
city String,
v1 UInt32,
v2 Float32,
create_time datetime
)engine = SummingMergeTree()
partition by toYYYYMM(create_time)
order by (id,city)
primary key id;
insert into summing_table select '1','上海',1,1.0,'2021-05-01' from numbers(100);
insert into summing_table select '2','广州',1,1.0,'2021-05-01' from numbers(100);
insert into summing_table select '3','武汉',1,1.0,'2021-05-01' from numbers(100);
insert into summing_table select '1','上海',1,1.0,'2021-05-01' from numbers(100);
optimize table summing_table final ;
select * from summing_table;
- AggregatingMergeTree
数据立方体,通过以空间换取时间的方式提升查询性能,将需要聚合的数据,预先计算出来,并将结果保存起来。在后续进行聚合查询的时候,直接使用结果数据。
- sql案例
CREATE TABLE agg_table_basic(
id String,
city String,
code String,
value UInt32
)ENGINE = MergeTree()
PARTITION BY city
ORDER BY (id,city);
INSERT INTO TABLE agg_table_basic VALUES
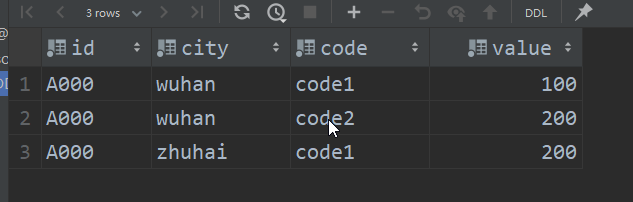
('A000','wuhan','code1',100),('A000','wuhan','code2',200),('A000','zhuhai','code1',200);
-- 一般结合物化视图使用
create materialized view agg_view
engine =AggregatingMergeTree()
partition by city
order by (id,city)
as select id,city,uniqState(code) as code,
sumState(value) as value
from agg_table_basic
group by id,city;
select * from agg_table_basic;
select id,sumMerge(value),uniqMerge(code) from agg_view group by id,city;
- CollapsingMergeTree
增加一个状态字段,以增代删,支持行级数据修改和删除表引擎。通过定义一个sign标记位字段,记录数据行的状态。如果sign标记为1,则表示这是一行有效的数据;如果sign标记为-1,则表示这行数据需要被删除。
当CollapsingMergeTree分区合并时,同一数据分区内,sign标记为1和-1的一组数据会被抵消删除。
- sql案例
--sign用于指定一个Int8类型的标志位字段。
CREATE TABLE collpase_table(
id String,
code Int32,
create_time DateTime,
sign Int8
)ENGINE = CollapsingMergeTree(sign)
PARTITION BY toYYYYMM(create_time)
ORDER BY id;
--修改前的源数据, 它需要被修改
INSERT INTO TABLE collpase_table VALUES('A000',100,now(),1);
--镜像数据, ORDER BY字段与源数据相同(其他字段可以不同),sign取反为-1,它会和源数据折叠
INSERT INTO TABLE collpase_table VALUES('A000',100,now(),-1);
--修改后的数据 ,sign为1
INSERT INTO TABLE collpase_table VALUES('A000',120,now(),1);
-- 修改前的源数据, 它需要被删除
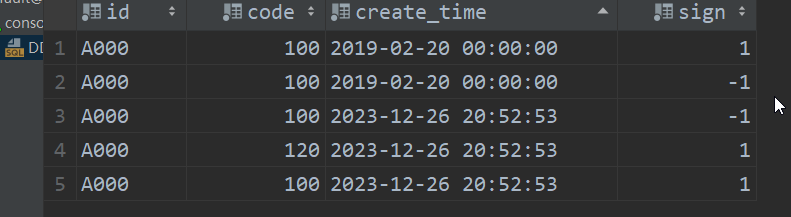
INSERT INTO TABLE collpase_table VALUES('A000',100,'2019-02-20 00:00:00',1);
--镜像数据, ORDER BY字段与源数据相同, sign取反为-1, 它会和源数据折叠
INSERT INTO TABLE collpase_table VALUES('A000',100,'2019-02-20 00:00:00',-1);
-- 手动合并分区 sign字段值1和-1 会抵消合并折叠
optimize table collpase_table final ;
select * from collpase_table;


有时间数据分区合并不能及时,如果只是使用optimize table table_ name final命令强制分区合并,但是这种方法效率极低,实际开发环境中慎用;因此需要改变我们查询方式:
SELECT id,SUM(code),COUNT(code),AVG(code),uniq(code)
FROM collpase_table
GROUP BY id;
-- 通过查询筛选掉sign为-1的记录。
SELECT id,SUM(code * sign),COUNT(code * sign),AVG(code *
sign),uniq(code * sign)
FROM collpase_table
GROUP BY id
HAVING SUM(sign) > 0;
相同分区内的数据才能折叠。
先写入sign=1,再写入sign=-1,能够正常折叠。
先写入sign=-1 再写入sign=1 不能够正常折叠。
- VersionedCollapsingMergeTree
VersionedCollapsingMergeTree与collapsingMergeTree是一样功能,都是同一个区数据能够折叠。只不过VersionedCollapsingMergeTree对任意顺序数据都能够完成折叠操作。
CREATE TABLE ver_collpase_table(
id String,
code Int32,
create_time DateTime,
sign Int8,
ver UInt8
)ENGINE = VersionedCollapsingMergeTree(sign,ver)
PARTITION BY toYYYYMM(create_time)
ORDER BY id
--删除
INSERT INTO TABLE ver_collpase_table VALUES('A000',101,'2019-02-20
00:00:00',-1,1)
INSERT INTO TABLE ver_collpase_table VALUES('A000',102,'2019-02-20
00:00:00',1,1)
--修改
INSERT INTO TABLE ver_collpase_table VALUES('A001',101,'2019-02-20
00:00:00',-1,1)
INSERT INTO TABLE ver_collpase_table VALUES('A001',102,'2019-02-20
00:00:00',1,1)
INSERT INTO TABLE ver_collpase_table VALUES('A001',103,'2019-02-20
00:00:00',1,2)
七、常见数据类型表引擎
把数据存储在HDFS上,直接读取HDFS的文件,这些表只负责元数据管理和数据查询,不负责数据写入!
ENGINE = HDFS(hdfs_uri,format):hdfs_uri表示HDFS的文件存储路径,format表示文件格式。
-- 在HDFS上创建用于存放文件的目录
hadoop fs -mkdir /clickhouse
-- 在HDFS上给ClickHouse用户授权
hadoop fs -chown -R clickhouse:clickhouse /clickhouse
-- 创建把表数据存在hdfs上 以csv文件保存!
create table hdfs_table1(
id UInt32,
code String,
name String
)engine =HDFS('hdfs://node1:8020/clickhouse/hdfs_table1','CSV');
insert into hdfs_table1 select number,concat('code',toString(number)),concat('n',toString(number)) from numbers(5);
select * from hdfs_table1;
-- 其他方式,只能读取
ENGINE = HDFS('hdfs://hdp1.nauu.com:8020/clickhouse/hdfs_table2/*','CSV')
ENGINE =HDFS('hdfs://hdp1.nauu.com:8020/clickhouse/hdfs_table2/organization_{1..3}.cs
v','CSV')
ENGINE =HDFS('hdfs://hdp1.nauu.com:8020/clickhouse/hdfs_table2/organization_?.csv','C
SV')
Mysql表引擎与MySQL数据库中建立映射,通过SQL向其发起远程查询,包括查询、插入数据,但是MySQL引擎不支持数据的更新和删除。
-- 连接MySQL数据库
create table emp(
empno Int32,
ename String,
job String,
mgr Int32,
hiredate date,
sal double,
comm double,
deptno Int32
-- 主机IP:端口,数据库,表名,用户名,密码
)engine =MySQL('192.168.147.120:3306','scott','emp','root','Root@123456.');
select * from emp;
insert into table emp values (778892,'john','president',10000,now(),12000.36,3600.23,10);
JDBC表引擎不仅支持MySQL表映射,还能够与PostgreSQL、SQLite和H2数据库等连接。
- 案例演练
Maven依赖
<dependency>
<groupId>com.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.4.6</version>
</dependency>
<dependency>
<groupId>org.lz4</groupId>
<artifactId>lz4-java</artifactId>
<version>1.8.0</version>
</dependency>
</dependencies>
jdbc.properties
driver=com.clickhouse.jdbc.ClickHouseDriver
url=jdbc:clickhouse://192.168.147.110:8123/scott
user=default
password=123456
Sql工具类
package com.zwf.util;
import java.io.File;
import java.io.IOException;
import java.sql.*;
import java.util.Properties;
/**
* @author MrZeng
* @version 1.0
* @date 2023-12-27 9:35
*/
/**
* 工具类
*/
public class SqlUtil {
private static Properties prop=new Properties();
static {
//加载配置信息
try {
prop.load(SqlUtil.class.getClassLoader().getResourceAsStream("jdbc.properties"));
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static Connection getConnection() throws ClassNotFoundException, SQLException {
String url = prop.getProperty("url");
String driver = prop.getProperty("driver");
String user = prop.getProperty("user");
String password = prop.getProperty("password");
Class.forName(driver);
Connection connection = DriverManager.getConnection(url, user, password);
return connection;
}
public static void closeAll(Connection con, PreparedStatement state, ResultSet rs){
try {
if (rs != null) {
rs.close();
}
if (state != null) {
state.close();
}
if (con != null) {
con.close();
}
}catch (SQLException e){
e.printStackTrace();
}
}
}
测试查询类
package com.zwf.jdbcDemo;
import com.zwf.util.SqlUtil;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
/**
* @author MrZeng
* @version 1.0
* @date 2023-12-27 9:52
*/
public class JdbcTest {
/**
* 测试jdbc sql语句
*/
public static void main(String[] args) throws SQLException, ClassNotFoundException {
Connection connection = SqlUtil.getConnection();
String sql="select * from emp;";
PreparedStatement statement = connection.prepareStatement(sql);
ResultSet resultSet = statement.executeQuery();
while (resultSet.next()){
System.out.print("雇员号:"+resultSet.getObject(1)+"\t\t");
System.out.print("雇员名:"+resultSet.getObject(2)+"\t\t");
System.out.print("工作:"+resultSet.getObject(3)+"\t\t");
System.out.print("领导:"+resultSet.getObject(4)+"\t\t");
System.out.print("生日:"+resultSet.getObject(5)+"\t\t");
System.out.print("工资:"+resultSet.getObject(6)+"\t\t");
System.out.print("奖金:"+resultSet.getObject(7)+"\t\t");
System.out.print("部门号:"+resultSet.getObject(8));
System.out.println();
}
SqlUtil.closeAll(connection,statement,resultSet);
}
}
kafka引擎:ClickHouse不支持恰好一次的语义,需要应用端与kafka深度配合才能实现!
ENGINE = Kafka()
SETTINGS
kafka_broker_list = 'host:port,... ',
kafka_topic_list = 'topic1,topic2,...',
kafka_group_name = 'group_name',
kafka_format = 'data_format'[,]
-- 以下选填
[kafka_row_delimiter = 'delimiter_symbol']
[kafka_schema = '']
[kafka_num_consumers = N]
[kafka_skip_broken_messages = N]
[kafka_commit_every_batch = N]

- 案例
-- 创建kafka映射表
drop table kafka_table;
create table kafka_table(
id UInt32,
code String,
name String
)engine =Kafka()
settings
kafka_broker_list='node1:9092,master:9092,node2:9092',
kafka_topic_list='topic_clickhouse_two',
kafka_group_name='clickhouse',
kafka_format='TabSeparated',
kafka_skip_broken_messages=10;
drop table kafka_view;
select * from kafka_table;
-- 创建kafka视图
CREATE TABLE kafka_view (
id UInt32,
code String,
name String
) ENGINE = MergeTree()
ORDER BY id;
drop view cosumer;
-- 由于kafka不能直接访问数据 需要创建物化视图把数据读取到MergeTree()引擎表中才能访问
create materialized view cosumer to kafka_view
as select id,code,name from scott.kafka_table;
-- 查询clickhouse里的数据
select * from kafka_view;
- 创建主题
kafka-topics.sh --zookeeper node1:2181,master:2181,node2:2181/kafka0110 --create --replication-factor 2 --partitions 3 --topic topic_clickhouse_two
- java代码(kafka工具类)
package com.zwf.kafkaApi;
import com.zwf.kafka_partition.CustomPartitioner;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import java.util.Properties;
/**
* @author MrZeng
* @version 1.0
* @date 2023-12-21 16:07
*/
//kafka连接工具类
public class KafkaUtils {
//创建生产者
public static KafkaProducer<String,String> createProducer(){
//创建配置文件列表
Properties properties=new Properties();
//kafka地址,多个用逗号隔开
properties.setProperty("bootstrap.servers","node1:9092,master:9092,node2:9092");
//设置写出数据格式
properties.setProperty("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
properties.setProperty("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
//应答方式
properties.put("acks","all");
//使用自定义分区器
// properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomPartitioner.class);
//错误重试次数
properties.put("retries",1);
//批量写出 16KB为一批数据
properties.put("batch.size",1024*16);
//创建生产者
KafkaProducer<String,String> kafkaProducer=new KafkaProducer<>(properties);
return kafkaProducer;
}
//创建消费者
public static KafkaConsumer<String,String> createConsumer(String groupId){
//读取配置文件
Properties properties=new Properties();
properties.put("bootstrap.servers","node1:9092,master:9092,node2:9092");
//设置groupId
properties.put("group.id",groupId);
//zk超时时间
properties.put("zookeeper.session,timeout.ms","1000");
//反序列化
properties.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
//当消费者第一次消费时,从最低的偏移量开始消费
properties.put("auto.offset.reset","earliest");
//设置自动提交
properties.put("auto.commit.enable","true");
//消费者自动提交偏移量的时间间隔 1s
properties.put("auto.commit.interval.ms","1000");
//创建消费者对象
KafkaConsumer<String,String> kafkaConsumer=new KafkaConsumer<>(properties);
//返回消费对象
return kafkaConsumer;
}
}
- 生产者发送消息
package com.zwf.clickhouse_kafka;
import com.zwf.kafkaApi.KafkaUtils;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
/**
* @author MrZeng
* @version 1.0
* @date 2023-12-27 10:35
*/
public class clickhouseDemo {
public static void main(String[] args) throws InterruptedException {
KafkaProducer<String, String> producer = KafkaUtils.createProducer();
for (int i=0;i<10000;i++){
ProducerRecord<String,String> record=new ProducerRecord<>("topic_clickhouse_two","clickhouse_"+i,i+"\tcode_"+i+"\tname_"+i);
producer.send(record);
Thread.sleep(1000);
}
}
}
File引擎:File表引擎能够直接读取本地文件的数据,通常被作为一种扩充手段来使用。
File表引擎的定义参数中,并没有包含文件路径这一项。所以,File表引擎的数据文件只能保存在 config.xml配置中由path指定的路径下。
每张File数据表均由目录和文件组成,其中目录以表的名称命名,而数据文件则固定以data.format命名
- 案例
-- 自动创建 会存放在/var/lib/clickhouse/data/yjxxt/file_table/data.CSV
CREATE TABLE file_table (
name String,
value Int32
) ENGINE = File("CSV")
INSERT INTO file_table VALUES ('one', 1), ('two', 2), ('three', 3)
Memory:Memory表引擎直接将数据保存在内存中,数据既不会被压缩也不会被格式转换,数据在内存中保存的形态与查询时看到的如出一辙。
当ClickHouse服务重启的时候,Memory表内的数据会全部丢失。 当数据被写入之后,磁盘上不会创建任何数据文件。适合做临时表!
create table DATE_TEST(
c1 date,
c2 datetime,
c3 datetime64
)engine Memory;
insert into DATE_TEST values ('2023-12-25','2023-12-25 17:36:00','2023-12-25 17:36:30.500');
select *
from DATE_TEST;
Set表引擎是拥有物理存储的,数据首先会被写至内存,然后被同步到磁盘文件中。并且Set具有去重能力,数据写入过程中,重复的数据会被自动忽略。当服务重启时,数据不会丢失,当数据表被重新转载时,文件数据被全量加载内存。
Set引擎存储结构由两部分组成,分别是:
- [num].bin数据文件:保存了所有列字段的数据。其中,num是一个自增Id,从1开始。伴随着每一批数据的写入(每一次insert)都会生成一个新的.bin文件,num也会随之加1.
- tmp临时目录:数据文件首先会被写到这个目录,当一批数据写入完毕后,数据文件被移出此目录。
- sql案例
create table set_1(
id UInt8
)engine =Set();
-- 生成10个值 0 1 2 3 4 5 6 7 8 9
insert into table set_1 select number from numbers(10);
-- 查询下标索引是1 2 3的数值==>1 2 3。
SELECT arrayJoin([1, 2, 3]) AS a WHERE a IN set_1
Join表引擎等同于JOIN查询进行一层简单封装。在JOIN表引擎的底层数据,它与Set表引擎共用了大部分的处理逻辑,因此join与set引擎有许多相似之处。
ENGINE = Join(join_strictness, join_type, key1[, key2, ...])
join_strictness: 连接精度,决定了JOIN查询在连接数据示使用的策略,目前支持ALL、ANY、ASOF三种
join_type: 连接类型,决定了JOIN查询组合左右两个数据集合的策略,形成交集、并集、笛卡尔积或其他形式,目前只支持inner、outer、cross三种类型。当设置为ANY时,数据写入是,join_key重复的数据自动忽略。
join_key: 链接键,决定哪个字段关联多张表。
- sql案例
CREATE TABLE id_join_tb1(
id UInt8,
price UInt32,
time Datetime
) ENGINE = Join(ANY, LEFT, id);
INSERT INTO TABLE id_join_tb1 VALUES (1,100,now()),
(1,105,now());
-- 1,105,now()数据被忽略 因为关联id相同
select * from id_join_tb1;
Log:日志家族系列中性能最高的表引擎。
Log表引擎的存储结构由3个部分组成:[column].bin:数据文件,数据文件按列独立存储,每一列字段都拥有一个与之对应的.bin文件.
marks.mrk:数据标记,统一保存了数据在各个[column].bin文件中的位置信息。利用数据标记能够使用多个线程,以并行的方式读取.bin内的压缩数据块,从而提升数据查询的性能。
sizes.json:元数据文件,记录了[column].bin和__marks.mrk大小的信息。
- sql案例
CREATE TABLE log_1 (
id UInt64,
code UInt64
)ENGINE = Log();
INSERT INTO TABLE log_1 SELECT number,number+1 FROM numbers(200);
接口类型:Merge引擎本身不支持存储和写入任何数据,只负责合并同一个数据库中相同表结构的数据(表名可以不同),两张表中表引擎和分区字段可以不同。
ENGINE = Merge(database, table_name);database表示数据库名称;table_name表示数据表的名称,它支持使用正则表达式;
-- 创建表1
CREATE TABLE test_table_2018(
id String,
create_time DateTime,
code String
)ENGINE = MergeTree
PARTITION BY toYYYYMM(create_time)
ORDER BY id;
-- 创建表2
CREATE TABLE test_table_2019(
id String,
create_time DateTime,
code String
)ENGINE = Log;
-- 合并表一和表二的数据 取别名 engine=Merge(数据库名,表名) 当表名不同时支持正则表达式匹配!
CREATE TABLE test_table_all as test_table_2018
ENGINE = Merge(currentDatabase(), '^test_table_');
insert into test_table_2018 select number,'2018-01-01','08' from numbers(3);
insert into test_table_2019 select number,'2019-01-01','09' from numbers(3);
SELECT _table,* FROM test_table_all;