最近我老表问我一个面试问题,如果数据量很大,分页查询怎么优化。
个人觉得无非就是sql优化,
那无非就是走索引,
避免回表查询(覆盖索引,也就是不要用select * ,走主键索引,叶子节点有保存了数据),
减少回表查询次数(定位到非聚簇索引树的叶子节点少,小表驱动大表等)
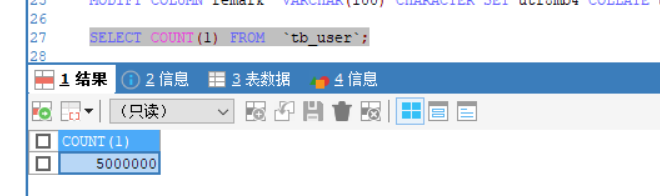
我下面自己测了一个500万数据,取偏移量400万20条数据的例子 ,话不多说 上例子
表tb_user
CREATE TABLE `tb_user` ( `user_id` bigint NOT NULL COMMENT '用户id', `name` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL, PRIMARY KEY (`user_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用户'
500万数据
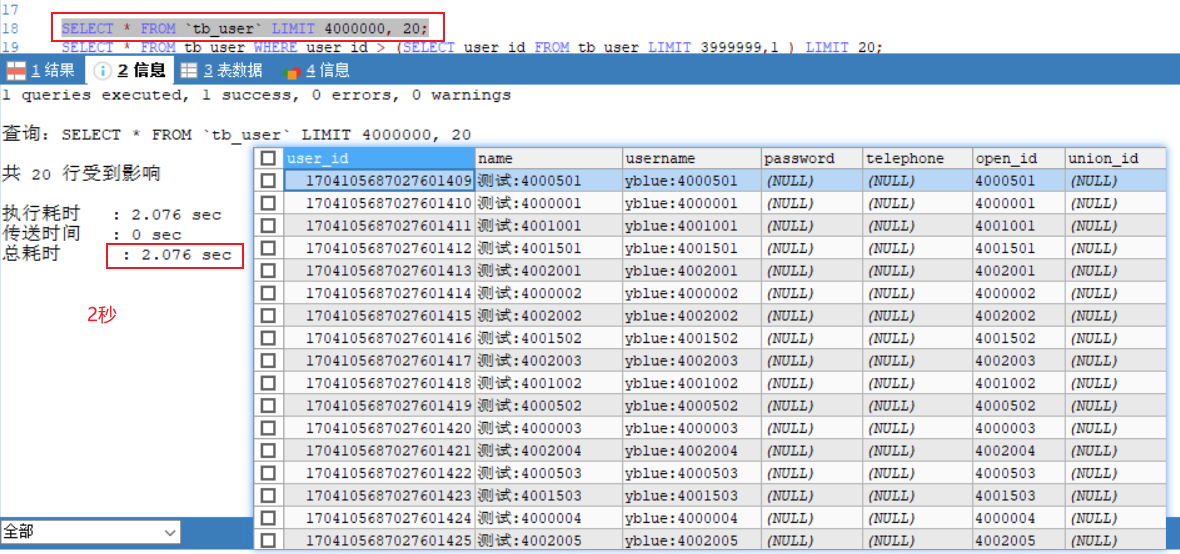
正常的sql
SELECT * FROM `tb_user` LIMIT 4000000, 20; EXPLAIN SELECT * FROM `tb_user` LIMIT 4000000, 20; //执行计划 看了全表扫描

优化后的sql,由于我的是long类型的主键id所以我需要找到主键。
像那些直接是递增的主键id可以直接where user_id > 偏移量,但是是要表数据没被删过
SELECT * FROM tb_user WHERE user_id > (SELECT user_id FROM tb_user LIMIT 3999999,1 ) LIMIT 20; EXPLAIN SELECT * FROM tb_user WHERE user_id > (SELECT user_id FROM tb_user LIMIT 3999999,1 ) LIMIT 20;
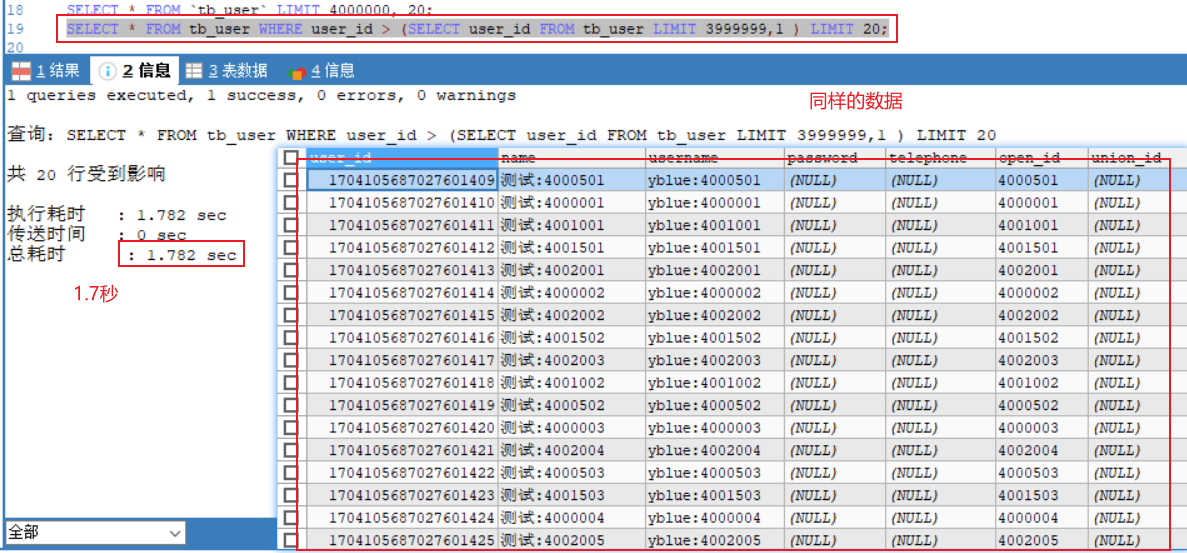

可以看到快了0.3秒。
总之,就是sql优化的问题。