环境python3.9版本及以上,开发工具pycharm
君子协议:robots.txt协议
规定了网站中哪些数据可以被爬虫爬取哪些不可以被爬虫爬取

下面是我学习的第一个爬虫的开发:
from urllib.request import urlopen url = "http://www.baidu.com" resp = urlopen(url) # print(resp.read().decode("utf-8·")) # 此时拿到的是页面源代码 with open("mybaidu.html", mode='w', encoding='utf-8') as f: f.write(resp.read().decode("utf-8"))
如果将URL的地址改成:https://www.baidu.com,
得到的mybaidu.html为:
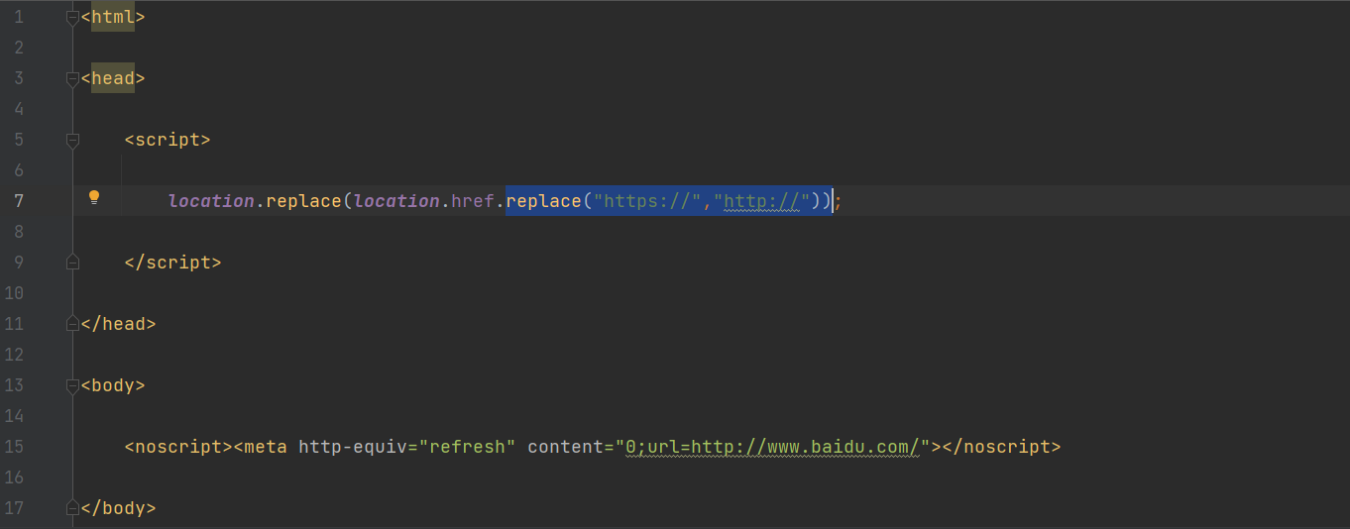
此时表示当前URL会被替换为http://,具体原理未知。
接下来是web请求全过程:
1.服务器渲染
含义就是我们在请求服务器的时候,服务器直接把数据全部写入到HTML中,浏览器就能直接拿到带有数据的HTML内容。
这里我们依旧以百度为例。在访问百度时,浏览器会把这一次请求发送到百度的服务器,由服务器接收到这个请求,然后加载一些数据,返回给浏览器,再由浏览器进行显示。注意:百度的服务器返回给浏览器的不直接是页面,而是页面源代码(由HTML,css,js组成),再由浏览器把页面源代码进行执行,然后把执行之后的结果展示给用户,所以我们能直接看到上一节的内容,我们拿到的是百度的源代码。具体过程如图:

由于数据是直接写在HTML中,所以我们能看到的数据都在页面源代码中能找到。
这种网页一般都相对比较容易就能抓取到页面内容。
2.前端JS渲染
这种机制一般是第一次请求服务器返回一堆HTML框架结构,然后再次请求到真正保存数据的服务器,由这个服务器返回数据,最后在浏览器上对数据进行加载。具体过程如图:

这样做的好处是服务器那边能缓解压力,而且分工明确比较容易维护。典型如京东。