Deep One-Class Classifification
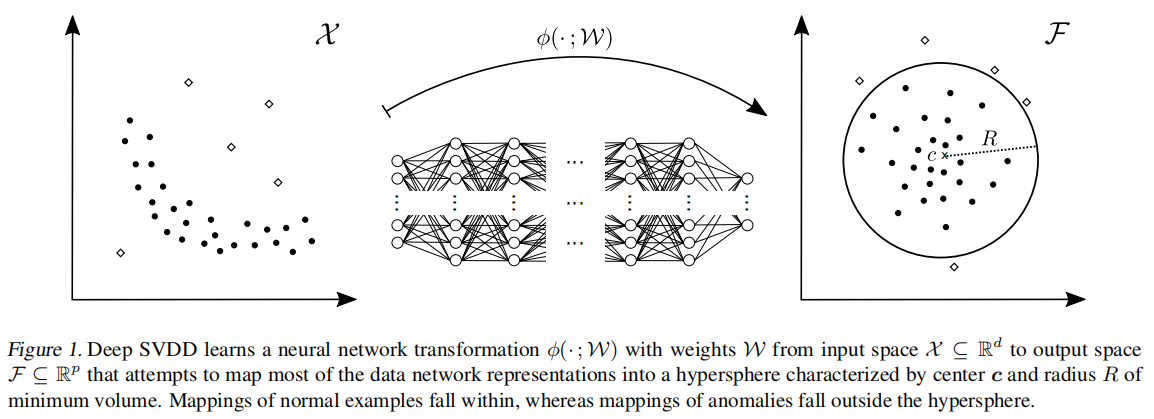
Deep SVDD (Deep Support Vector Data Description)训练一个神经网络,最小化包含数据表征的超球的体积(如图1所示)
Deeo SVDD的目标函数
soft-boundary Deep SVDD
输入空间 \(\mathcal{X} \subseteq \mathbb{R}^d\) 和输出空间 \(\mathcal{F} \subseteq \mathbb{R}^p\)。\(\phi(\cdot ; \mathcal{W}): \mathcal{X} \rightarrow \mathcal{F}\) 为一个拥有 \(L \in \mathbb{N}\) 层隐层的神经网络。\(\mathcal{W}=\left\{\boldsymbol{W}^1, \ldots, \boldsymbol{W}^L\right\}\) ,其中 \(W^{\ell}\) 表示第 \(\ell \in\{1, \ldots, L\}\) 层的权重。\(\phi(\boldsymbol{x} ; \mathcal{W}) \in \mathcal{F}\) 表示输入 \(\boldsymbol{x} \in \mathcal{X}\) 经过参数为 \(\mathcal{W}\) 的神经网络 \(\phi\) 后得到的表征。Deep SVDD的目标是在学习网络参数 \(\mathcal{W}\) 的同时,最小化输出空间 \(\mathcal{F}\) 中半径为 \(R>0\) ,中心为 \(c \in \mathcal{F}\) 的封闭数据超球的体积。给定 \(\mathcal{X}\) 上的一些数据集 \(\mathcal{D}_n=\left\{\boldsymbol{x}_1, \ldots, \boldsymbol{x}_n\right\}\) ,我们将soft-boundary Deep SVDD 目标定义为
- 最小化 \(R^2\) 就是最小化超球体的体积。
- 第二项是对于经过神经网络后落在球外的点的惩罚项,即其距离 \(\| \phi\left(\boldsymbol{x}_i ; \mathcal{W}\right)- \boldsymbol{c} \| > R\)。超参数 \(\nu \in(0,1]\) 控制球体体积与超出边界之间的权衡,即它允许一些点进过映射后,落在超球体外面。参数 \(v\) 实际上允许我们控制模型中异常值的比例。
- 最后一项是网络参数\(\mathcal{W}\) 上的权重衰减正则器,其中\(\|\cdot\|_F\) 表示F范数.
优化目标(3)让网络学习参数 \(\mathcal{W}\),使数据点紧密映射到超球的中心 \(c\)。为了实现这一目标,网络必须提取数据变化的共同因素。因此,正常样本被紧密映射到中心c,而异常样本则被映射到远离中心或超球外的地方。
One-Class Deep SVDD
对于我们假设大多数训练数据 \(\mathcal{D}_n\) 是正常的情况,这是在单类分类任务中经常出现的情况,我们提出了一个额外的简化目标。我们定义 One-Class Deep SVDD 的目标函数为
One-Class Deep SVDD 简单地使用二次损失来惩罚每个网络表示 \(\phi(\boldsymbol{x}_i; \mathcal{W})\) 到 \(c \in \mathcal{F}\) 的距离。第二项是一个带超参数 \(\lambda > 0\) 的网络权衰减正则器。
在soft-boundary Deep SVDD中,超球通过直接惩罚半径和落在球外的数据表示来收缩。与soft-boundary Deep SVDD 不同,One-Class Deep SVDD通过最小化所有数据表示到中心的平均距离来收缩球。惩罚所有数据点的平均距离,而不是允许一些点落在超球之外,这与one-class假设是一致的。
异常分数
对于给定的测试点 \(\boldsymbol{x} \in \mathcal{X}\),我们可以很自然地通过该点到超球中心的距离定义Deep SVDD的两个变体的异常分数,即
其中 \(\mathcal{W}^*\)是训练模型的网络参数。对于soft-boundary Deep SVDD,我们可以通过减去训练模型的最终半径 \(R^*\) 来调整这个分数,这样异常(具有球外表示的点)具有正分数,而正常具有负分数。
Deep SVDD的优化
我们使用随机梯度下降(SGD)及其变体(例如,Adam),使用反向传播来优化两个深度SVDD目标中的神经网络的参数 \(\mathcal{W}\)
对于soft-boundary Deep SVDD,我们建议使用alternating minimization/block coordinate descent approach,交替优化网络参数 \(\mathcal W\) 和半径 \(R\)。也就是说,在半径 \(R\) 固定的情况下,我们训练 \(k\in \mathbb{N}\) 个epoch的网络参数 \(\mathcal W\)。然后,在每 \(k\) 个epoch之后,我们使用最新更新的网络参数 \(\mathcal W\) 来求解给定网络数据表示的半径 \(R\)。\(R\) 可以很容易地通过行搜索求解。
Deep SVDD的性质
对于不正确的网络或超球中心 \(c\),Deep SVDD会学习琐碎的、无信息的解决方案。
All-zero-weights solution
权重 \(\mathcal W_0\) 是全0的话,网络产生一个常数函数映射到超球中心,即对于任意的 \(x \in \mathcal{X}\), \(\phi(x;\mathcal{W}_0)=c_0\in \mathcal{F}\)。如果 \(c =c_0\),则会Deep SVDD的最优解为 \(\mathcal{W}^*=\mathcal{W}_0,R^*=0\)。我们称呼这种解为“超球体坍缩”(hypersphere collapse),因为超球半径为0。
根据经验,我们发现,将一些训练数据样本进行初始向前传递后产生的网络表示的平均值作为 \(c\) 是一个很好的策略。同时我们发现将 \(c\) 固定在初始网络输出的附近,可以使SGD收敛更快,更鲁棒。
Bias terms
如果网络中的隐藏层有偏移项 bias,则可能会学习到一个常数函数映射,使得其与输入无关,导致超球体坍缩。
对于输入 \(x \in \mathcal{X}\),第 \(\ell\) 层的输出为
其中 \(\cdot\) 表示线性变换,\(\sigma^\ell(\cdot)\) 为第 \(\ell\) 层的激活函数,第 \(\ell-1\) 层的输出为 \(z^{\ell-1}(\boldsymbol{x})\) 。当 \(\boldsymbol{W}^\ell=\boldsymbol{0}\) 时,\(z^\ell(\boldsymbol{x})=\sigma^\ell(\boldsymbol{b}^\ell)\) ,第 \(\ell\) 层的输出与输入 \(x\) 无关。
因此具有Deep SVDD的神经网络中不应该使用偏差项,因为该网络可以直接学习到映射到超球中心的常数函数,从而导致超球坍塌。
Bounded activation functions
具有有界激活函数的网络单元可能对一个特征的输入饱和,从而模拟下一层的偏置项,这会导致超球坍缩。
考虑激活函数 \(\sigma\) 的上界 \(B:=\sup_z\sigma(z) \neq 0\),然后特征 \(k\) 在所有输入样本中都大于0即 \(z_i^{(k)}>0,i=1,\dots,n\)。那么,可以选择第 \(k\) 个元素的权重足够大(将所有其他网络单元的权重设置为零),从而导致 \(\sigma(w_kz_i^{(k)})\) 无限接近上界 \(B\)
因此,在Deep SVDD中,应该优先使用像ReLU这样的无界激活函数(或仅以0为界的函数),以避免由于“习得”偏差项而导致的超球崩溃。
总结上面的分析:
- 超球中心 \(c\) 的选择必须无法得到全零解
- Deep SVDD中的神经网络应该没有偏置项
- Deep SVDD中不应该使用有界激活函数