SC-Depth系列。
SCDepthV1
之前的单目深度估计网络的重投影损失,更多的是利用前后帧的颜色误差进行约束,得到了比较精确的结果。但它们基本上都有一个共性问题:深度值不连续!连续几张图像之间的深度值不连续!也就是说,在不同的帧上产生尺度不一致的预测,因为它们承受了每帧图像的尺度不确定性。这种问题这不会影响基于单个图像的任务,但对于基于视频的应用至关重要,例如不能用于VSLAM系统中的初始化。因此,SC-DepthV1为解决此问题提出了尺度一致性约束。具体来说,就是给前后两帧图像都预测深度,利用两张图像的深度和位姿投影到3D空间中,进而去计算尺度一致性损失。这种方法确保了相邻帧之间尺度的一致性,如果每连续两帧图像的尺度都是一致的,那么整个视频序列的深度序列也就是连续的。
此外,SC-DepthV1还使用了一种Mask,对应视频上出现不连续的区域。作者认为这就是动态物体,通过去除这种Mask可以使得网络具备一定的动态环境鲁棒性。
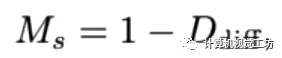
定量结果显示,SC-DepthV1取得了与Monodepth2相持平的结果。但SC-DepthV1估计出的深度图具有连续性,因此还是SC-DepthV1更胜一筹。
SCDepthV3
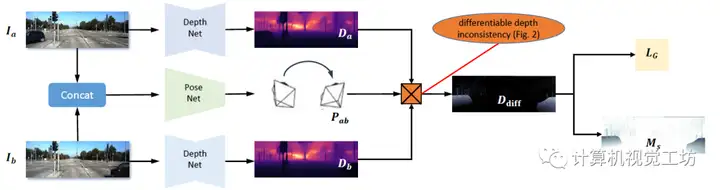
SC-DepthV1面向室外场景,SC-DepthV2面向室内场景,可以说实现了很好的通用性和泛化能力。但SC-DepthV1和SC-DepthV2都是基于静态环境假设的,虽然作者也利用Mask剔除了一些动态物体的影响,但当应用场景是高动态环境时,算法很容易崩溃。为了解决动态物体和遮挡问题,现有网络通常是检测动态物体,然后在训练时剔除这些区域。这些方法在训练时效果比较好,但是在推理时往往很难得到高精度。也有一些方法对每个动态对象进行建模,但网络会变得非常笨重。因此,SC-Depth系列作者又在近日提出了SC-DepthV3,面向高动态场景的单目深度估计网络!在各种动态场景中都可以鲁棒的运行!具体来说,SC-DepthV3首先引入了一个在大规模数据集上有监督预训练的单目深度估计模型LeReS,并通过零样本泛化提供单图像深度先验,也就是伪深度,同时引入了一个新损失来约束网络的训练。注意,LeReS只需要训练一次,在新场景中不需要进行finetune,因此这一网络的引入并不会加入额外的成本。

LeReS显示了很好的定性结果,但伪深度的精度很低,伪深度的误差图也说明了这一问题。不过SC-DepthV3认为经过合适的模块设计,伪深度可以很好得促进无监督单目深度估计的结果。

解决动态区域问题的关键是作者提出的动态区域细化(DRR)模块,该方法的来源是,作者发现伪深度在任意两个物体或像素之间保持极好的深度有序度。因此,SC-DepthV3提取动态和静态区域之间的真值深度序信息,并使用它来规范动态区域的自监督深度估计。为了从静态背景中分割动态区域,SC-DepthV3使用了SC-DepthV1中提出的Mask,并通过计算自监督训练中的前后向深度不一致性来生成,因此不需要外部分割网络。

此外,伪深度显示了光滑的局部结构和物体边界。因此SC-DepthV3提出一个局部结构优化(LSR)模块来改进深度细节的自监督深度估计。该模块包含两个部分:一方面从伪深度和网络预测深度中提取表面法线,并通过应用法线匹配损失来约束;另一方面应用相对法向角度损失来约束物体边界区域的深度估计。在损失函数的设置上,除了之前的几何一致性损失、光度损失外,SC-DepthV3还提出了边缘感知平滑损失来正则化预测的深度图。
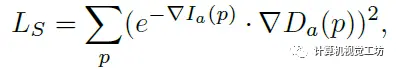
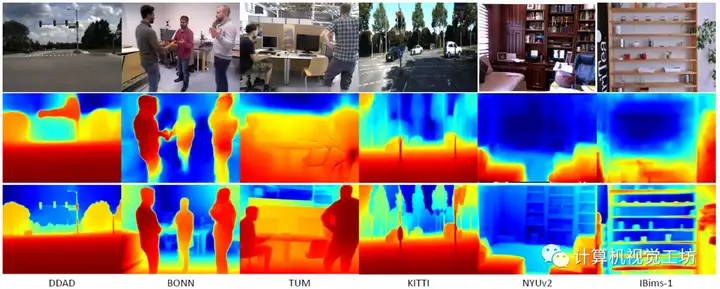
在具体的评估上,SC-DepthV3在DDAD、BONN、TUM、KITTI、NYUv2和IBims-1这六个数据集进行了大量实验,定性结果显示SC-DepthV3在动态环境中具有极强的鲁棒性。定量结果也说明了SC-DepthV3在动态环境中的性能远超Monodepth2和SC-Depth。
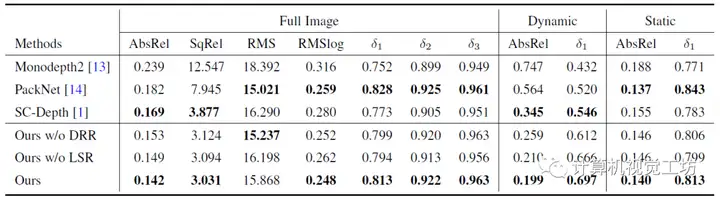
一句话总结:SC-DepthV3解决了动态环境问题。