SLAM技术参数与构图分析
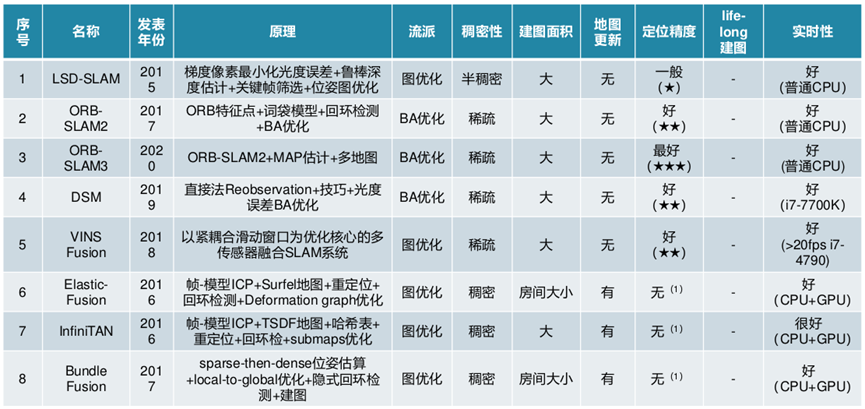
SuMa方案
原理介绍:此算法使用Surfel地图去实现前端里程计和闭环检测,此前Surfel地图曾被用在RGBD-SLAM中,第一次被用在在室外大场景三维SLAM中。Surfel地图最早是用在基于RGB-D相机的三维重建任务中的。SuMa的整体流程就是先处理点云把点云从三维展开成二维,然后生成局部地图用来给当前帧做匹配,接着通过ICP方法进行位姿更新,然后更新surfel地图,最后做闭环检测与后端优化。
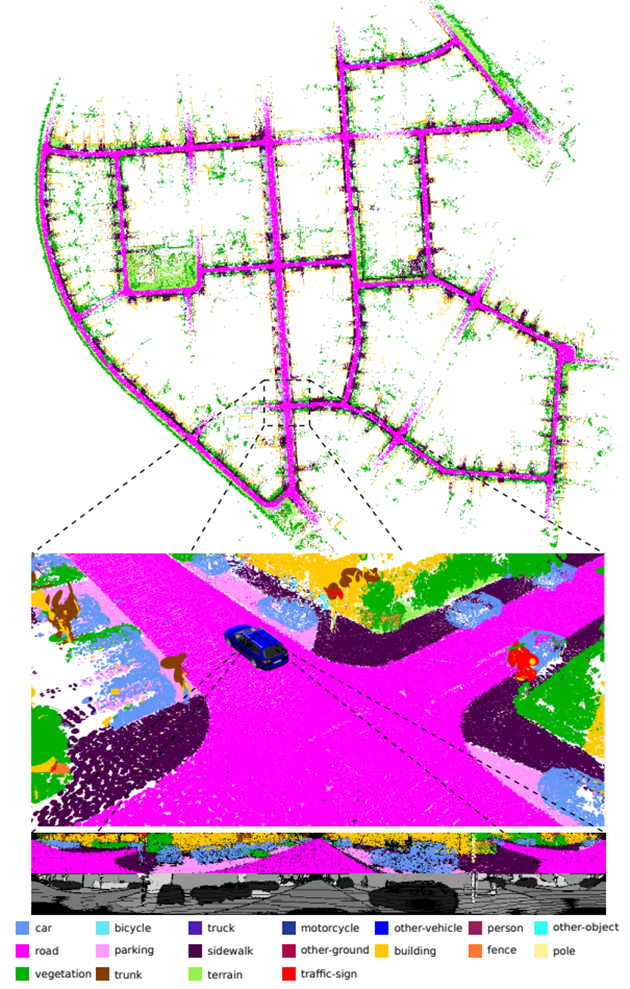
图1:使用方法仅使用激光雷达扫描生成的KITTI数据集的语义图。地图由具有由相应颜色指示的类标签的曲面表示。
总体而言语义SLAM管道能够提供比非语义管道具有更高度量精度的高质量语义图。
SuMa++
原理介绍:这是一种新的基于语义信息的激光雷达SLAM系统,可以更好地解决真实环境中的定位与建图问题。该系统通过语义分割激光雷达点云来获取点云级的密集语义信息,并将该语义信息集成到激光雷达SLAM中来提高激光雷达的定位与建图精度。通过基于深度学习的卷积神经网络,可以十分高效地在激光雷达“范围图(range image)”上进行语义分割,并对整个激光雷达点云进行语义标记。通过结合几何深度信息,进一步提升语义分割的精度。基于带语义标记的激光雷达点云,此方法能够构建带有语义信息且全局一致的密集“面元(surfel)”语义地图。基于该语义地图,也能够可靠地过滤移除动态物体,而且还可以通过语义约束来进一步提高投影匹配ICP的位姿估计精度。
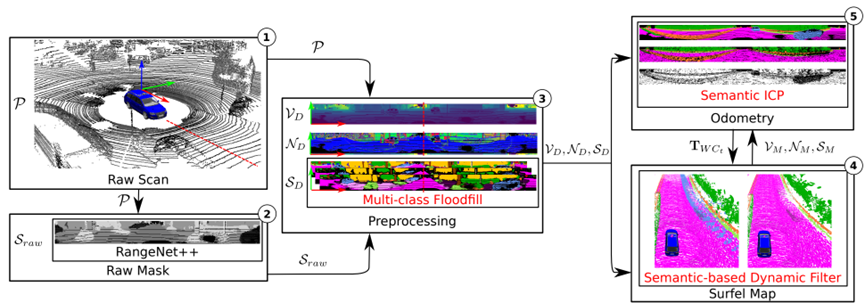
图2:提出的方法的管道概述。以紧凑的方式将语义预测集成到SuMa管道中:(1)输入仅为激光雷达扫描P。(2)在处理原始点云P之前,首先使用RangeNet++的语义分割来预测每个点的语义标签,并生成原始语义掩码Sraw。(3) 在给定原始掩码的情况下,在预处理模块中使用多类泛洪填充生成细化的语义图SD。(4) 在地图更新过程中,添加了一个动态检测和删除模块,该模块检查新观测SD和世界模型SM之间的语义一致性,并删除异常值。(5) 同时,在ICP过程中添加了额外的语义约束,使其对异常值更具鲁棒性。
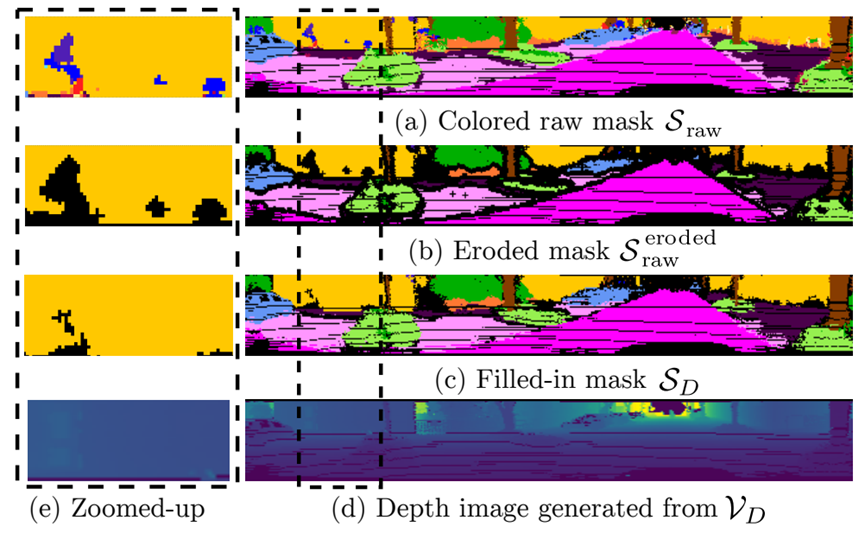
图3:所提出的洪水填充算法的处理步骤的可视化。给定(a)原始语义图Sraw,首先使用侵蚀来去除边界标签和小面积的错误标签,导致(b)侵蚀掩模S被原始侵蚀。(c) 然后,最后用相邻的标签填充侵蚀的标签,以获得更一致的结果SD。黑点表示标签为0的空像素。(d) 显示带虚线边框的区域内的深度和(e)细节。
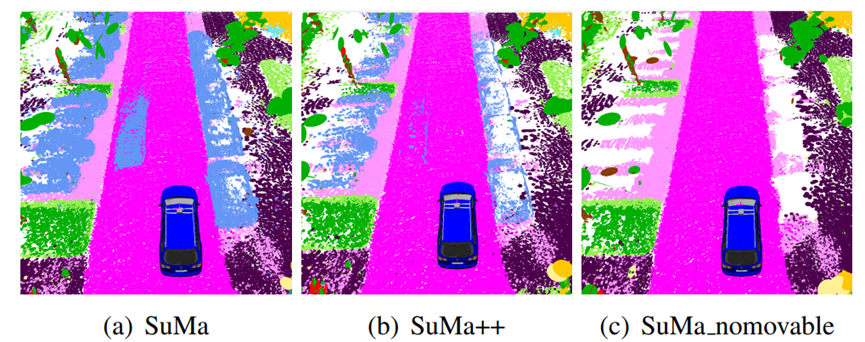
图4:所提出的动力学滤波的效果。对于所有的图,显示了相应标签的颜色,但请注意,SuMa没有使用语义信息。(a) SuMa生成的Surfels;(b) 创新方法;(c) 移除所有可能移动的对象。

图5:语义ICP的可视化:(a)当前激光扫描的语义图SD,(b)从模型中呈现的相应语义图SM,(c)ICP期间的权重图。像素越暗,对应像素的权重就越低。
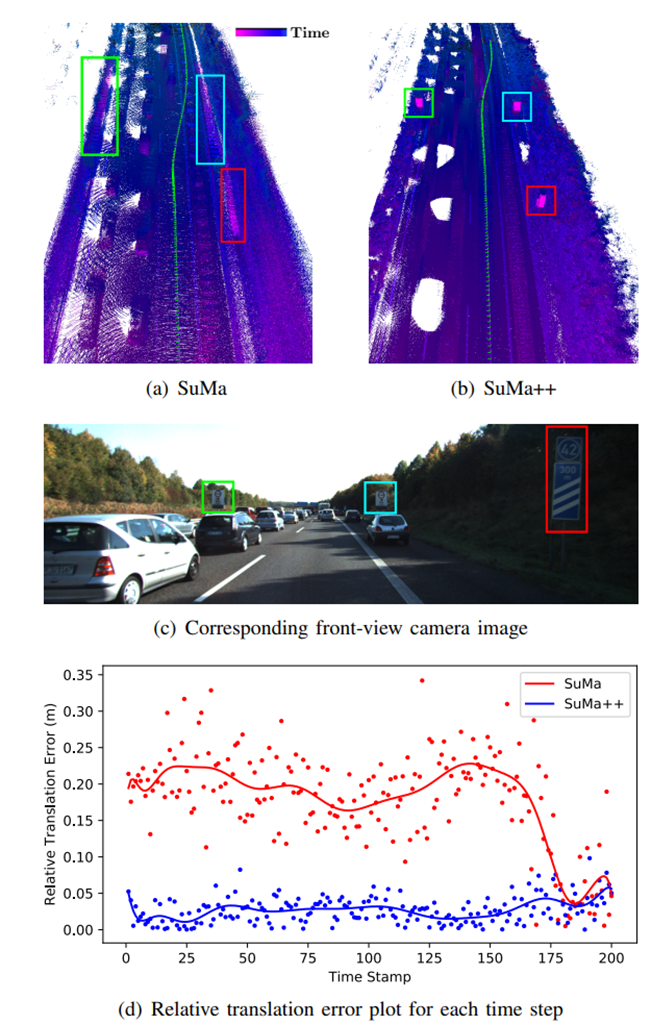
图6:定性结果。(a) 由于汽车在传感器附近的一致运动,没有语义的SuMa无法正确估计传感器的运动。ICP的帧断层模型锁定在持续移动的汽车上,导致地图不一致,用矩形突出显示。(b) 通过结合语义,能够正确地估计传感器的运动,从而通过ICP获得更一致的环境图和更好的传感器姿态估计。3D点的颜色是指第一次记录该点时的时间戳。(c) 相应的前视图摄像头图像,在其中突出显示交通标志。(d) 每个时间步长对应的相对平移误差图。点是每个时间戳中计算的相对平移误差,曲线是这些点的多项式拟合结果。
表I:KITTI Road数据集的结果
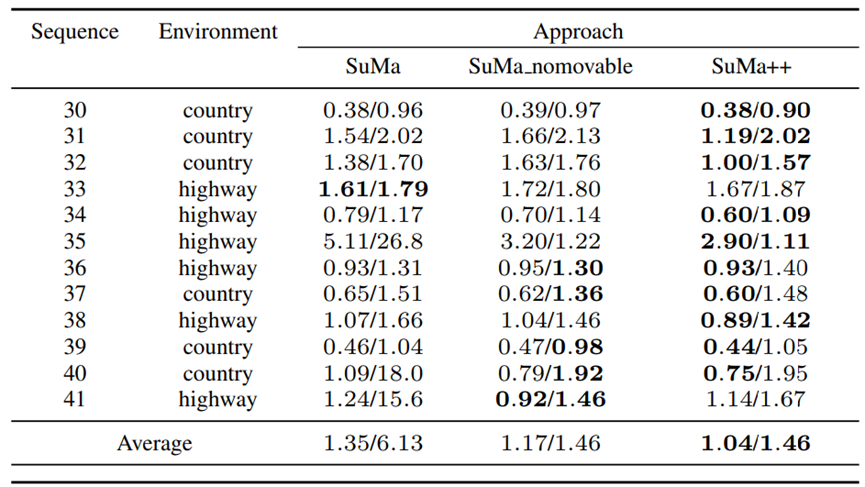
在5至400米长的轨迹上平均的相对误差:相对旋转误差,单位为每100米度数/相对平移误差,单位%。粗体数字表示基于激光的方法的最高性能。

图7:KITTI道路数据集上不同方法测试的轨迹。
表II:KITTI里程测量结果(训练)

在100至800米长的轨迹上平均的相对误差:相对旋转误差,单位为每100米度数/相对平移误差,单位%。
标有星号的序列包含循环闭包。粗体数字表示平移误差方面的最佳性能。
VINS-Fusion 方案
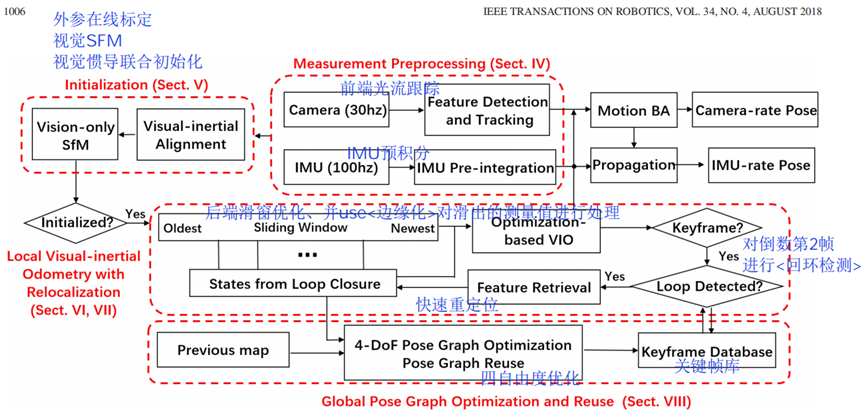
VINS系列由港科大沈劭劼课题组发表和公开,其中VINS-Fusion 是继 VINS-Mono (单目视觉惯导 SLAM 方案)后的双目视觉惯导 SLAM 方案,VINS-Fusion 是一种基于优化的多传感器状态估计器,可实现自主应用(无人机,无人车, AR / VR)的精确自定位。 VINS-Fusion 是 VINS-Mono 的扩展,支持多种视觉惯性传感器类型(单目相机+ IMU,双目相机+ IMU,双目相机-only),但两者的技术框架是相同的,如下图所示。其主要技术模块有:
- 轻量级前端(视觉光流跟踪+IMU预积分)
- 传感器在线标定+视觉惯导联合初始化
- 紧耦合滑窗优化(同时具有快速重定位功能)
- 回环检测
- 全局四自由度位姿优化
(注:红色加粗表示核心工作)
VINS方案本身是基于特征点的,因此只能用于稀疏建图。VINS的优点在于实现了很高的定位精度,这种精度来源于视觉+IMU融合以及紧耦合滑窗优化算法。VINS对计算资源的消耗比较小,在普通CPU上既可以实现在线实时运行,适合于对实时性有要求的移动设备。

ElasticFusion 方案
ElasticFusion (2016) 是由帝国理工发表的一项优秀RGB-D SLAM系统,具有稠密建图、在线实时运行、轻量级等显著特点。如前文所述,ElasticFusion 以稠密建图为主要目标(而非定位),建图的精度和质量是主要指标。ElasticFusion 的技术特点如下:
- 基于 RGB-D 的稠密三维重建一般使用网格模型融合点云,ElasticFusion 是为数不多使用 surfel 模型的方案。
- 传统的 SLAM 算法一般通过优化位姿或者路标点来提高精度,而 ElasticFusion 采用优化 deformation graph 的方式。
- 融合了重定位算法(当相机跟丢时,重新计算相机的位姿)。
- ElasticFusion 算法融合了 RGB信息(颜色一致性约束) 和深度信息(ICP 算法)进行位姿估计。
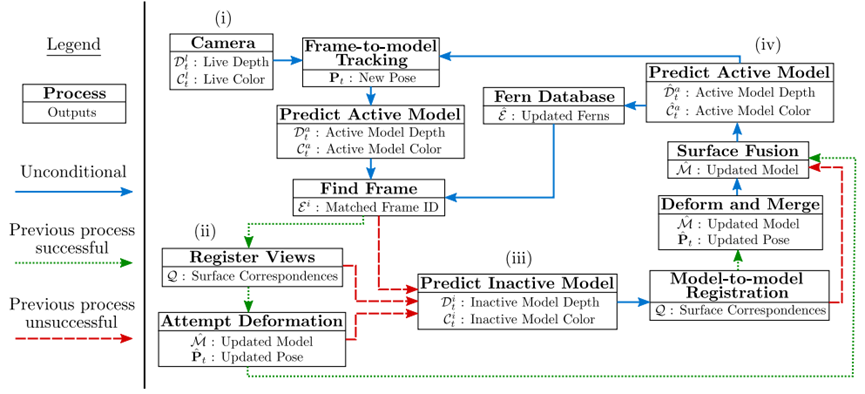
ElasticFusion首先根据RGB-D图像配准估算位姿,根据位姿误差决定进行重定位还是回环检测;若存在回环,则首先优化Deformation graph 然后优化 surfel地图;若不存在,则更新和融合全局地图,并估算当前视角下的模型,用于下一帧图像配准。总体来说,ElasticFusion具有较高的重建精度,在重建房间大小的场景时效果很好;但没有对代码做特别的优化,在大场景重建时效果不佳。


InfiniTAM 方案
InfiniTAM 是牛津大学于2016年发表的稠密 SLAM 方案,该方案基于 KinectFusion 和 体素块哈希表(voxel block hashing)发展而来。首先,InfiniTAM 方案在建图部分利用 TSDF 模型(截断符号距离场)进行建模,只是在建模的时候,不是对整个空间都划分等大小的网格,而是只在场景表面的周围划分网格(voxel blocks),且只为待重建的表面上的Voxel block分配显存,并使用哈希表这一结构来管理GPU对Voxel block的内存分配和数据访问。通过这样的方法,InfiniTAM 大大减小了稠密建图对 GPU 的内存消耗,提升了算法效率。
InfiniTAM 的 算法流程 如右图所示,InfiniTAM 系统的前端与KinectFusion较为相似,主要分为三个阶段:
- 跟踪阶段:对新输入的图像进行定位,估算对应的相机位姿;
- 融合阶段:用于将新数据集成到现有的3D世界模型当中(更新voxel中存储的SDF值);
- 渲染阶段:利用光线投影算法(Raycasting)从世界模型中提取与下一个跟踪步骤相关的模型区域,用于下一帧的位姿估算;
在后端部分,InfiniTAM 维护一个 Active Submaps List(基于Voxel block + Hashing),从而实现轻量级的后端优化。
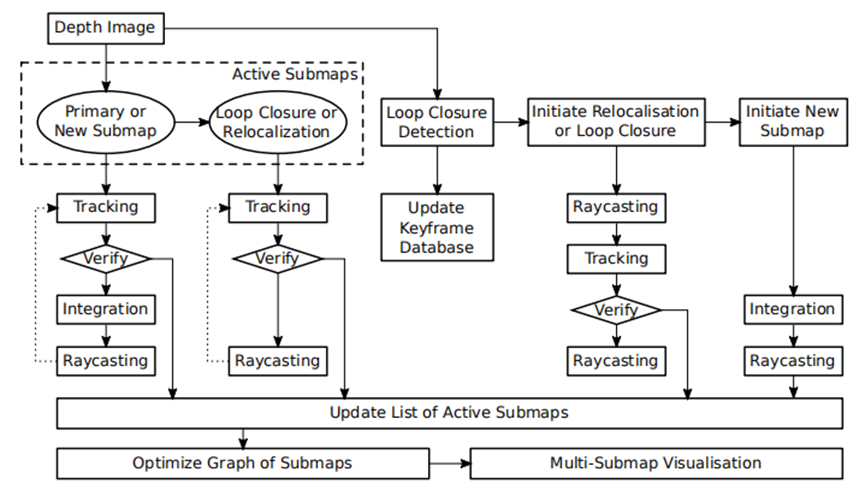
InfiniTAM 是一个完整的稠密SLAM系统,包括前端位姿估计,回环检测,重定位,后端优化等全部SLAM功能。InfiniTAM使用哈希表来管理体素(voxel),大大节约了GPU内存占用,因此可以构建更大规模场景的地图。


BundleFusion 方案
斯坦福大学2017年提出的BundleFusion技术,被认为可能是目前基于RGB-D相机进行稠密三维重建效果最好的方法。BundleFusion的整体流程是比较清晰的:输入的color+depth的数据流首先需要做帧与帧之间的匹配信息搜索,然后基于“稀疏特征+稠密特征”融合匹配以求得精确位姿变化;把连续相邻帧聚合为“帧段”并在帧段内做局部位姿优化,获得帧段地图/Chunk;然后基于“帧段”做全局位姿优化,将整体的漂移矫正;融合相邻Chunk,得到全局位姿和地图。整个过程持续动态更新。
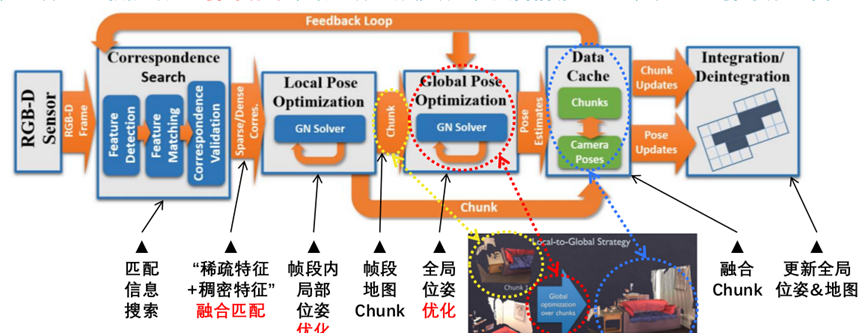
【融合匹配】在匹配方面,论文使用的是一种sparse-then-dense的并行全局优化方法。也就是说,先使用稀疏的SIFT特征点来进行比较粗糙的配准,因为稀疏特征点本身就可以用来做loop closure检测和relocalization。然后使用稠密的几何和光度连续性进行更加细致的配准。图1展示了sparse+dense这种方式和单纯sparse的对比结果。
【优化】在位姿优化方面,论文使用了一种分层的 local-to-global 优化方法,如图2所示。总共分为两层,在第一层,每连续10帧组成一个chunk,第一帧作为关键帧,然后对chunk内所有帧做局部位姿优化。在第二层,只使用所有的chunk的关键帧进行互相关联然后进行全局优化。通过这种分层处理技巧,一方面可以剥离出关键帧,减少存储和待处理的数据;另一方面,分层优化方法减少了每次优化时的未知量,保证该方法可扩展到大场景而漂移很小。
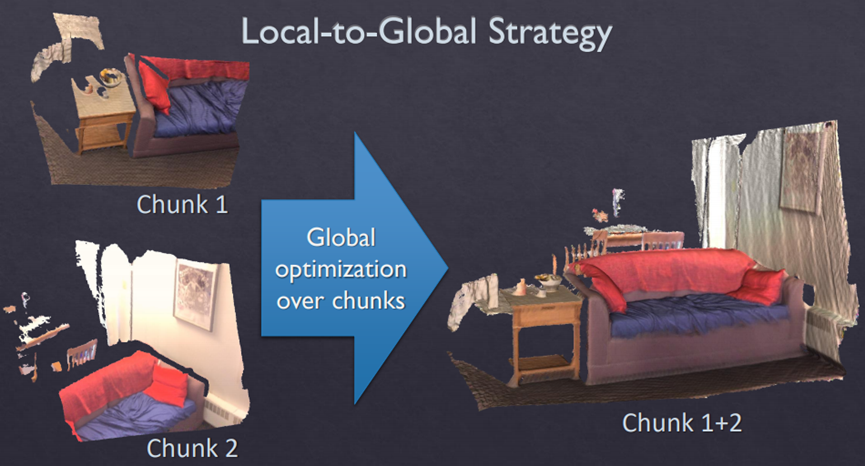
local-to-global 优化策略


BundleFusion 方案在算法上具有明显的优点:
- 使用持续的local to global分层优化,去除了时域跟踪的依赖。
- 不需要任何显示的loop closure检测。因为每一帧都和历史帧相关,所以其实包含了持续的隐式的loop closure。
- 支持在GPU上实时鲁棒跟踪,可以在跟踪失败时移动到重建成功的地方进行relocalization,匹配上后继续跟踪。
实验表明,BundleFusion的重建效果确实是目前该领域效果最好的方法,下图是和其他方法的对比,重建优势明显。
BundleFusion 的良好效果除了算法的功劳,还必须有强大硬件算力的支撑。当使用两块GPU(GTX Titan X + GTX Titan Black)时,BundleFusion在各大数据集上可以达到 36 fps 左右的处理深度;当使用一块 GTX Titan X 时,处理速度则是 20 fps 左右。也即:目前算法需要两块GPU才能实时运行,因此算法的优化和加速仍是可改进的地方。

4. 激光SLAM中的挑战和阶段分析
1.非结构化道路的SLAM问题?
2.地图表达与实际环境的差异?
3.占栅格地图和高精地图有哪些差别?

1.非结构化道路的SLAM问题?抑或者激光SLAM的退化特性?
- 在广场、机场等开阔区域,即使是多线激光,也只能看到几圈地面上的点云。仅使用地面点云进行匹配,很可能在水平面上发生随机移动。
- 在长隧道、单侧墙、桥梁等场地中,激光匹配会存在一个方向上的额外自由度。也就是说,沿着隧道前进时,获取到的激光点云是一样的,使得匹配算法无法准确估计这个方向上的运动。类似地,如果机器绕着一个圈柱形物体运动时,也会发生这种情况。
- 在一些异形建筑面前,激光可能发生意想不到的失效情形。
解决思路:建图算法适当降低激光轨迹的权重,利用其他轨迹(或者数据约束)来补偿激光的失效。

2.地图表达与实际环境的差异?
- 机器人用的栅格地图,主要表达何处有障碍物,何处是可通行的区域,此外就没有了。它具有基础的导航与定位功能,精度也不错(厘米级),制作起来十分简单,基本可以让机器人自动生成。
- 但除了通行区域,还有什么是需要机器人从地图中获取的环境信息?
3.占栅格地图和高精地图有哪些差别?
- 在室内,机器人可以去任意可以通过的地方,不会有太多阻拦,而对于自动驾驶来说,每条路都有对应的交通规则:有些地方只能靠右行驶,有些地方不能停车,十字路口还有复杂的通行规则。
- 室内机器人可以利用栅格地图进行导航,但在室外可不能在十字路口上横冲直撞。所以,在导航层面,室内与室外的机器人出现了明显的区别。室内的导航可以基于栅格来实现诸如A*那样的算法,但室外基本要依赖事先画好的车道。
- 但自动化的高精地图标注该如何进行和实现工程落地?
目前SLAM程序的流程大抵上都一样,基本的流程都是:
- 对陌生环境进行一次扫描,建立地图;
- 保存地图;
- 以后运行时,打开这张地图进行定位。
而在第一和第三流程阶段,回到文章的开头,其本质就是State Estimation in Robotics。而由此进行分析的话,受到一致认可的方向大抵有以下三类:
- 精度:传感器选型、传感器布局和传感器标定,但若相同的传感器“条件”,精度本质上还是由硬件决定了上限;
- 鲁棒性:多传感器融合,传感器差异特性互补;
- 效率:点云配准 & 优化计算的效率提升
SLAM的通用架构
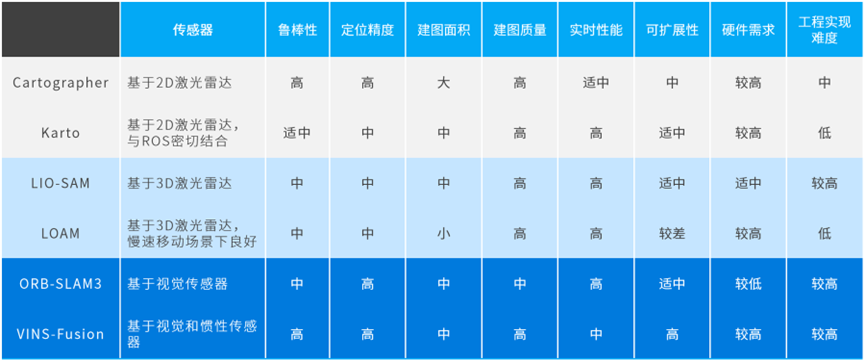
根据传感器的不同,机器人用的SLAM算法可以分为二维激光SLAM、三维激光SLAM,以及视觉SLAM。
其中,二维激光SLAM常用的有Cartographer、Karto,三维激光SLAM较流行的是LIO-SAM和LOAM系列,视觉SLAM主流的方案为ORB-SLAM3、VINS-Fusion……
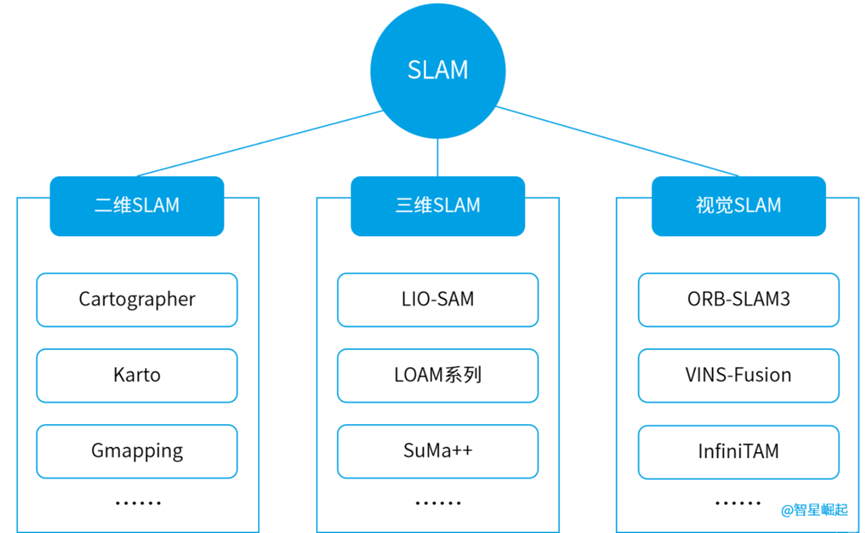
6大主流SLAM算法
Cartographer
由谷歌开发的一款基于激光雷达和RGB-D相机数据的SLAM算法。可以跨平台使用,支持Lidar、IMU、Odemetry、GPS、Landmark等多种传感器配置,被广泛用于机器人导航、自动驾驶等领域。
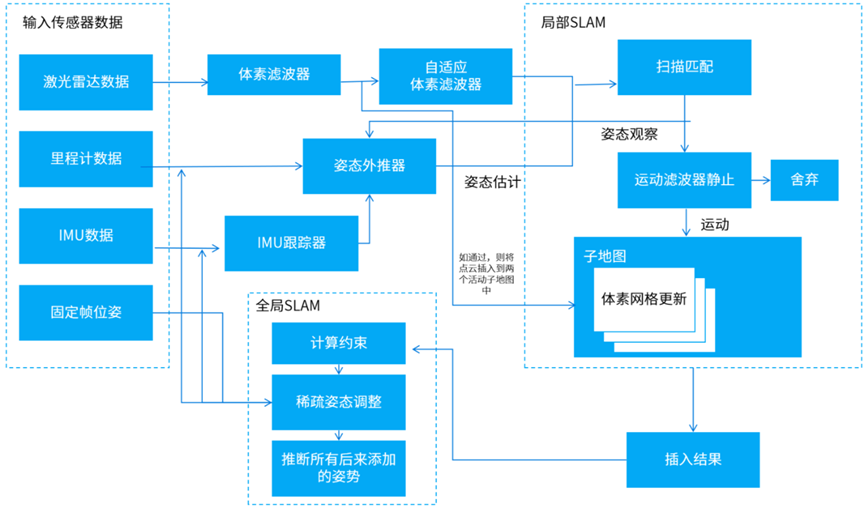
Cartographer系统架构图
Cartographer算法在前端完成占据栅格地图的构建,得出激光雷达扫描帧的最佳位姿后,将扫描帧插入到子地图Submap中,得到局部优化的子地图并记录位姿。
后端根据扫描帧间的位姿关系进行全局的地图优化,并使用分支定界法加速求解,进而得出闭环扫描帧在全局地图中的最佳位姿。
Karto
一种基于位姿图优化的SLAM方法,使用了高度优化和非迭代的cholesky矩阵对系统进行解耦并求解。适用于各种室内环境,可以处理静态和动态障碍物。

Karto系统架构图
Karto使用图论的标准形式表示地图,其中每个节点代表了移动机器人运行轨迹上的一个位姿点,以及当前位姿下传感器返回的感知信息。
节点之间的边,代表了相邻机器人位姿之间的位移矢量。对每一个新的位姿点定位,需要节点间匹配关系和边带来的约束,保持定位估计误差的前后一致。
LIO-SAM
一种新型的激光惯性导航系统,结合了激光雷达和惯性测量单元数据,可以实现机器人的高精度定位和运动轨迹的建图。
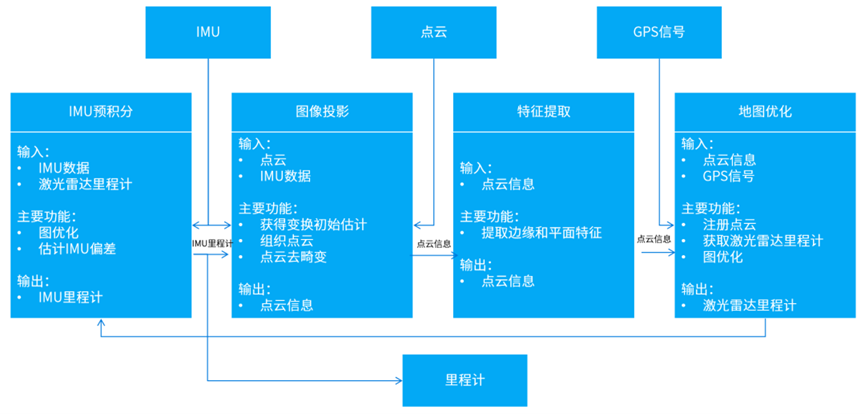
LIO-SAM系统架构图
前端在传统的LIDAR-SLAM基础上,利用卡尔曼滤波和因子图优化算法,将激光雷达和IMU数据融合,进一步提高机器人的定位精度和建图效果。后端加入优化算法,使得机器人的定位精度和建图精度都得到极大提升。
LOAM系列
一种成熟的基于激光雷达的SLAM算法,包括LOAM、LOAM-Velodyne、LOAM-LiDAR等。
其中LOAM使用3D激光雷达的数据来进行建图和定位,利用点云数据的特征,如空间聚类、连续性约束等来估计位姿。
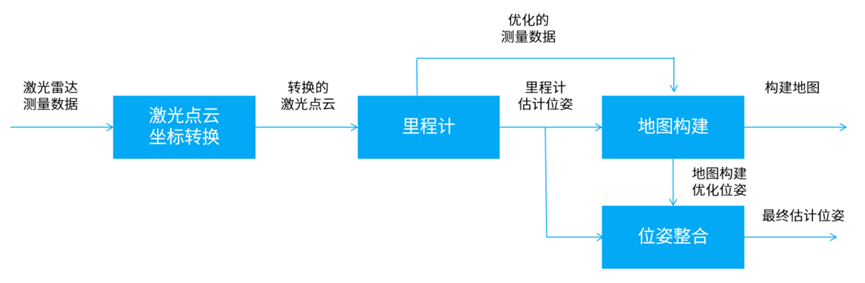
LOAM系统架构图
LOAM-Velodyne则使用Velodyne激光雷达的3D点云数据,以实现更高精度的地图重建和定位;LOAM-LiDAR采用LiDAR传感器来进行建图和定位,可以高效获取目标物体的三维坐标信息,在一些机器人应用场景具有很大的优势。
- ORB-SLAM3
当前最优秀的基于特征点的视觉SLAM系统之一,支持单目、双目、RBG-D等多种相机模式,在特征提取、关键帧选取、地图维护、位姿优化等方面进行了优化,并能建立短期、中期和长期的数据关联,使得该系统兼具精度和鲁棒性。
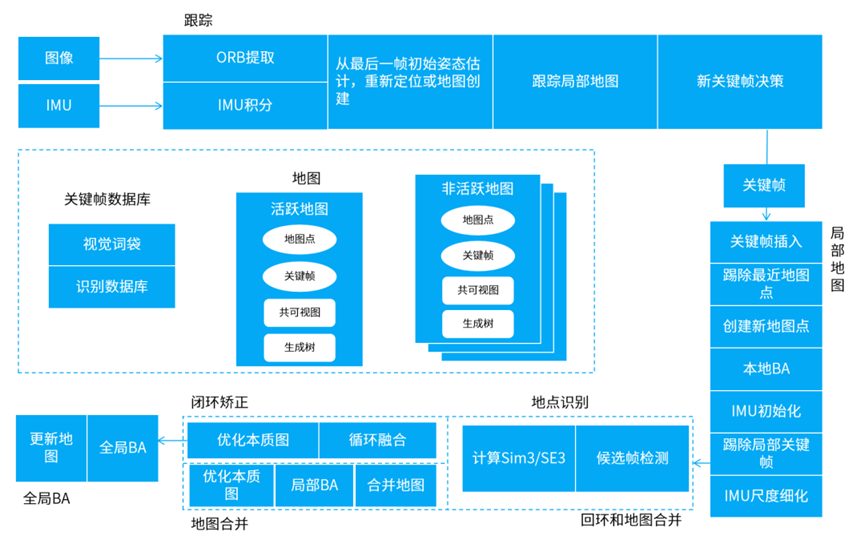
前端视觉里程计基于ORB特征,建立图像帧之间特征点的数据关联,以及图像特征点和地图点之间3D到2D的数据关联,具有较好的鲁棒性和提取效率,回环检测和重定位也基于ORB特征实现。
VINS-Fusion
一种基于视觉惯性传感器的视觉SLAM算法。它将视觉和惯性信息进行融合,来提高机器人在未知环境下的定位和导航能力。
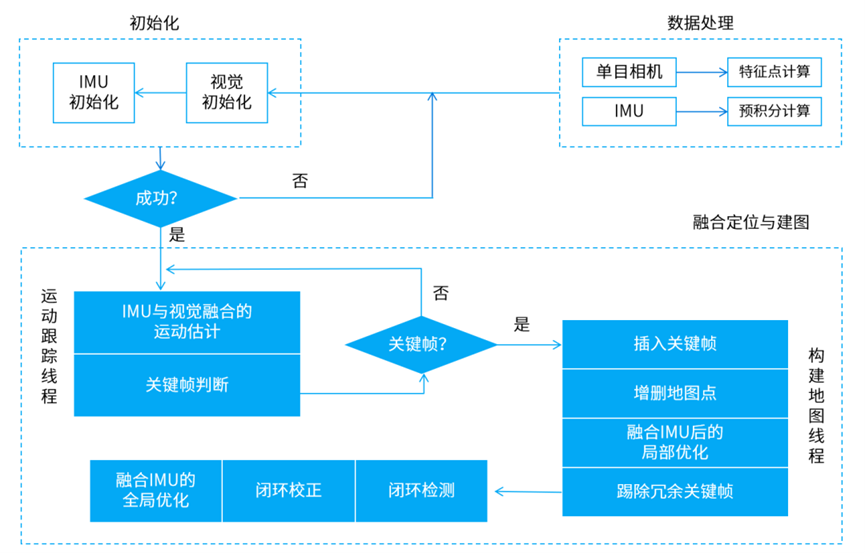
VINS-Fusion系统架构图
前端和后端之间通过一个状态传递机制来交换数据。前端将IMU和图像数据合并,生成一组状态量,然后将其传递给后端进行融合和优化;后端将优化后的状态量传递回前端,以便更新机器人的运动估计。
04 如何选择SLAM方案?
事实上,不同方案的SLAM算法,都有它的应用空间。
二维SLAM就适合在二维平面上运动的机器人,如扫地机、配送机器人、迎宾机器人等。
具体来看,Cartographer的总体表现最为优秀,定位精度和建图质量都很高,同时鲁棒性也很强,能承受一定的噪声和漂移干扰,可以应用于大范围建图;Karto适合建图面积不是太大的低成本应用场景,可以在一定程度上满足建图需求,同时工程实现难度也不太高。
三维SLAM则适用于机器人需要在三维空间中进行建模和定位的场景,比如无人机在室外飞行、机器人在户外环境中进行探测等。
其中,LIO-SAM的鲁棒性和实时性表现相对优秀,适用于建图面积和硬件资源有限的小型机器人应用场景;在建图面积和鲁棒性方面比较弱的LOAM方案,适用于小而快速的机器人及小型场景的定位、建图任务。
视觉SLAM通过摄像头等可视传感器来获取机器人与环境之间的相对位置关系,不需要其他传感器,更为轻量化。但对于光照变化、运动模糊等情况的处理仍存在挑战。
定位精度和实时性都比较高的ORB-SLAM3,面对场景变化能够快速适应,适用于多种场景的建图。与之相比,VINS-Fusion适用于对定位精度要求较高,且建图面积相对较小的机器人应用场景。
总的来说,这些算法各有优劣,如何选择最合适的算法,需要根据具体的应用场景和实际需求来综合考虑。