逻辑结构
逻辑结构揭示了数据元素之间的逻辑关系。
- 线性数据结构:数组、链表、栈、队列、哈希表。
- 非线性数据结构:树、堆、图、哈希表。
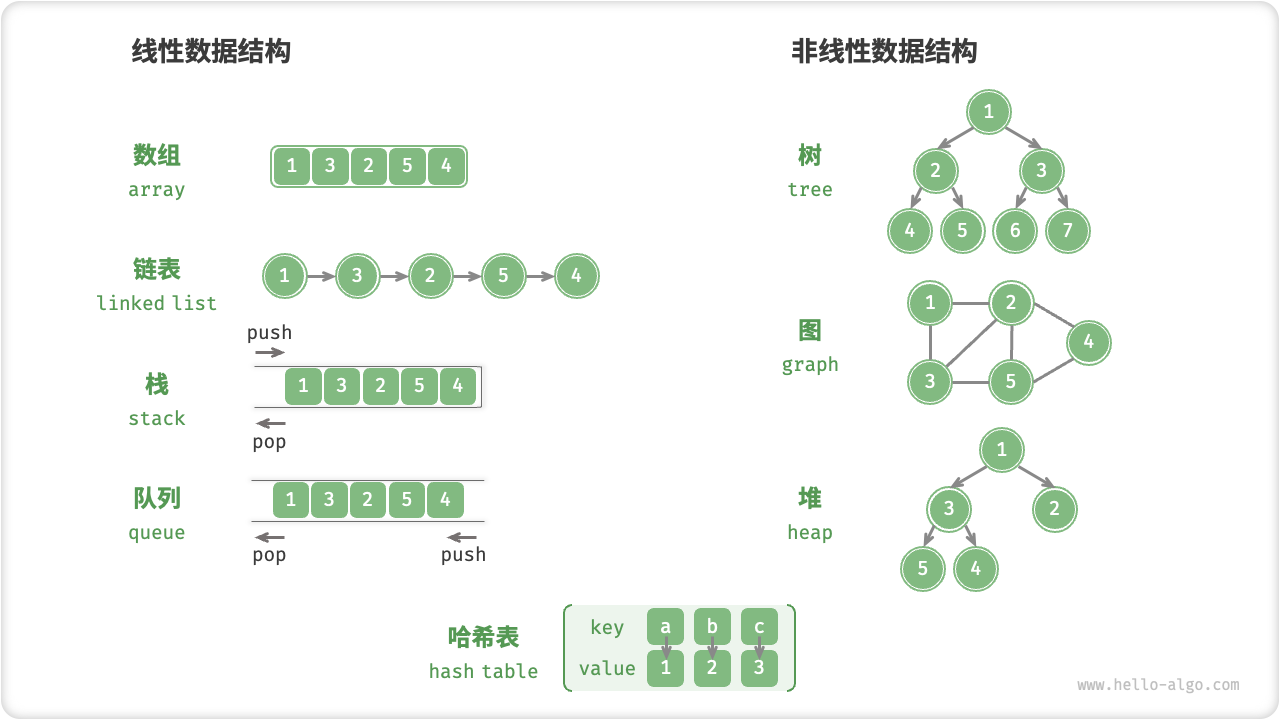
- 线性结构:数组、链表、队列、栈、哈希表,元素之间是一对一的顺序关系。
- 树形结构:树、堆、哈希表,元素之间是一对多的关系。
- 网状结构:图,元素之间是多对多的关系。
物理结构
连续与离散
在算法运行过程中,相关数据都存储在内存中。系统通过内存地址来访问目标位置的数据。因此在数据结构与算法的设计中,内存资源是一个重要的考虑因素。
物理结构反映了数据在计算机内存中的存储方式,所有数据结构都是基于数组、链表或二者的组合实现的。

基本数据类型


基本数据类型提供了数据的“内容类型”,而数据结构提供了数据的“组织方式”



计算机内部的硬件电路主要是基于加法运算设计的。通过将加法与一些基本逻辑运算结合,计算机能够实现各种其他的数学运算。
基于补码表示,计算机可以用同样的电路和操作来处理正数和负数的加法,不需要设计特殊的硬件电路来处理减法,并且无须特别处理正负零的歧义问题。这大大简化了硬件设计,提高了运算效率。
字符编码
然而,ASCII 码仅能够表示英文。随着计算机的全球化,诞生了一种能够表示更多语言的字符集「EASCII」。它在 ASCII 的 7 位基础上扩展到 8 位,能够表示 256 个不同的字符。
在世界范围内,陆续出现了一批适用于不同地区的 EASCII 字符集。这些字符集的前 128 个字符统一为 ASCII 码,后 128 个字符定义不同,以适应不同语言的需求。
EASCII 码仍然无法满足许多语言的字符数量要求。比如汉字大约有近十万个,光日常使用的就有几千个。中国国家标准总局于 1980 年发布了「GB2312」字符集,其收录了 6763 个汉字,基本满足了汉字的计算机处理需要。
然而,GB2312 无法处理部分的罕见字和繁体字。「GBK」字符集是在 GB2312 的基础上扩展得到的,它共收录了 21886 个汉字。在 GBK 的编码方案中,ASCII 字符使用一个字节表示,汉字使用两个字节表示。
如果推出一个足够完整的字符集,将世界范围内的所有语言和符号都收录其中,不就可以解决跨语言环境和乱码问题了吗?在这种想法的驱动下,一个大而全的字符集 Unicode 应运而生。
「Unicode」的全称为“统一字符编码”,理论上能容纳一百多万个字符。它致力于将全球范围内的字符纳入到统一的字符集之中,提供一种通用的字符集来处理和显示各种语言文字,减少因为编码标准不同而产生的乱码问题。Unicode 是一种字符集标准,本质上是给每个字符分配一个编号(称为“码点”),但它并没有规定在计算机中如何存储这些字符码点。我们不禁会问:当多种长度的 Unicode 码点同时出现在同一个文本中时,系统如何解析字符?例如给定一个长度为 2 字节的编码,系统如何确认它是一个 2 字节的字符还是两个 1 字节的字符?

- UTF-16 编码:使用 2 或 4 个字节来表示一个字符。所有的 ASCII 字符和常用的非英文字符,都用 2 个字节表示;少数字符需要用到 4 个字节表示。对于 2 字节的字符,UTF-16 编码与 Unicode 码点相等。
- UTF-32 编码:每个字符都使用 4 个字节。这意味着 UTF-32 会比 UTF-8 和 UTF-16 更占用空间,特别是对于 ASCII 字符占比较高的文本。

需要注意的是,以上讨论的都是字符串在编程语言中的存储方式,这和字符串如何在文件中存储或在网络中传输是两个不同的问题。在文件存储或网络传输中,我们通常会将字符串编码为 UTF-8 格式,以达到最优的兼容性和空间效率。

数组
「数组 array」是一种线性数据结构,其将相同类型元素存储在连续的内存空间中。我们将元素在数组中的位置称为该元素的「索引 index」。图 4-1 展示了数组的主要术语和概念。

从地址计算公式的角度看,索引的含义本质上是内存地址的偏移量。
总的来看,数组的插入与删除操作有以下缺点。
- 时间复杂度高:数组的插入和删除的平均时间复杂度均为 O(n) ,其中 n为数组长度。
- 丢失元素:由于数组的长度不可变,因此在插入元素后,超出数组长度范围的元素会丢失。
- 内存浪费:我们可以初始化一个比较长的数组,只用前面一部分,这样在插入数据时,丢失的末尾元素都是“无意义”的,但这样做也会造成部分内存空间的浪费。

数组存储在连续的内存空间内,且元素类型相同。这种做法包含丰富的先验信息,系统可以利用这些信息来优化数据结构的操作效率。
- 空间效率高: 数组为数据分配了连续的内存块,无须额外的结构开销。
- 支持随机访问: 数组允许在 O(1) 时间内访问任何元素。
- 缓存局部性: 当访问数组元素时,计算机不仅会加载它,还会缓存其周围的其他数据,从而借助高速缓存来提升后续操作的执行速度。
连续空间存储是一把双刃剑,其存在以下缺点。
- 插入与删除效率低:当数组中元素较多时,插入与删除操作需要移动大量的元素。
- 长度不可变: 数组在初始化后长度就固定了,扩容数组需要将所有数据复制到新数组,开销很大。
- 空间浪费: 如果数组分配的大小超过了实际所需,那么多余的空间就被浪费了。
数组是一种基础且常见的数据结构,既频繁应用在各类算法之中,也可用于实现各种复杂数据结构。
- 随机访问:如果我们想要随机抽取一些样本,那么可以用数组存储,并生成一个随机序列,根据索引实现样本的随机抽取。
- 排序和搜索:数组是排序和搜索算法最常用的数据结构。快速排序、归并排序、二分查找等都主要在数组上进行。
- 查找表:当我们需要快速查找一个元素或者需要查找一个元素的对应关系时,可以使用数组作为查找表。假如我们想要实现字符到 ASCII 码的映射,则可以将字符的 ASCII 码值作为索引,对应的元素存放在数组中的对应位置。
- 机器学习:神经网络中大量使用了向量、矩阵、张量之间的线性代数运算,这些数据都是以数组的形式构建的。数组是神经网络编程中最常使用的数据结构。
- 数据结构实现:数组可以用于实现栈、队列、哈希表、堆、图等数据结构。例如,图的邻接矩阵表示实际上是一个二维数组。
链表
「链表 linked list」是一种线性数据结构,其中的每个元素都是一个节点对象,各个节点通过“引用”相连接。引用记录了下一个节点的内存地址,通过它可以从当前节点访问到下一个节点。
链表的设计使得各个节点可以被分散存储在内存各处,它们的内存地址是无须连续的。

链表的组成单位是「节点 node」对象。每个节点都包含两项数据:节点的“值”和指向下一节点的“引用”。
- 链表的首个节点被称为“头节点”,最后一个节点被称为“尾节点”。
- 尾节点指向的是“空”,它在 Java、C++ 和 Python 中分别被记为 null、nullptr 和 None 。
- 在 C、C++、Go 和 Rust 等支持指针的语言中,上述的“引用”应被替换为“指针”。
如以下代码所示,链表节点 ListNode 除了包含值,还需额外保存一个引用(指针)。因此在相同数据量下,链表比数组占用更多的内存空间。


链表典型应用¶
单向链表通常用于实现栈、队列、哈希表和图等数据结构。
- 栈与队列:当插入和删除操作都在链表的一端进行时,它表现出先进后出的的特性,对应栈;当插入操作在链表的一端进行,删除操作在链表的另一端进行,它表现出先进先出的特性,对应队列。
- 哈希表:链地址法是解决哈希冲突的主流方案之一,在该方案中,所有冲突的元素都会被放到一个链表中。
- 图:邻接表是表示图的一种常用方式,在其中,图的每个顶点都与一个链表相关联,链表中的每个元素都代表与该顶点相连的其他顶点。
双向链表常被用于需要快速查找前一个和下一个元素的场景。
- 高级数据结构:比如在红黑树、B 树中,我们需要访问节点的父节点,这可以通过在节点中保存一个指向父节点的引用来实现,类似于双向链表。
- 浏览器历史:在网页浏览器中,当用户点击前进或后退按钮时,浏览器需要知道用户访问过的前一个和后一个网页。双向链表的特性使得这种操作变得简单。
- LRU 算法:在缓存淘汰算法(LRU)中,我们需要快速找到最近最少使用的数据,以及支持快速地添加和删除节点。这时候使用双向链表就非常合适。
循环链表常被用于需要周期性操作的场景,比如操作系统的资源调度。
- 时间片轮转调度算法:在操作系统中,时间片轮转调度算法是一种常见的 CPU 调度算法,它需要对一组进程进行循环。每个进程被赋予一个时间片,当时间片用完时,CPU 将切换到下一个进程。这种循环的操作就可以通过循环链表来实现。
- 数据缓冲区:在某些数据缓冲区的实现中,也可能会使用到循环链表。比如在音频、视频播放器中,数据流可能会被分成多个缓冲块并放入一个循环链表,以便实现无缝播放。
列表
数组长度不可变导致实用性降低。在实际中,我们可能事先无法确定需要存储多少数据,这使数组长度的选择变得困难。若长度过小,需要在持续添加数据时频繁扩容数组;若长度过大,则会造成内存空间的浪费。
为解决此问题,出现了一种被称为「动态数组 dynamic array」的数据结构,即长度可变的数组,也常被称为「列表 list」。列表基于数组实现,继承了数组的优点,并且可以在程序运行过程中动态扩容。我们可以在列表中自由地添加元素,而无须担心超过容量限制。
许多编程语言都提供内置的列表,例如 Java、C++、Python 等。它们的实现比较复杂,各个参数的设定也非常有考究,例如初始容量、扩容倍数等。感兴趣的读者可以查阅源码进行学习。
为了加深对列表工作原理的理解,我们尝试实现一个简易版列表,包括以下三个重点设计。
- 初始容量:选取一个合理的数组初始容量。在本示例中,我们选择 10 作为初始容量。
- 数量记录:声明一个变量 size,用于记录列表当前元素数量,并随着元素插入和删除实时更新。根据此变量,我们可以定位列表尾部,以及判断是否需要扩容。
- 扩容机制:若插入元素时列表容量已满,则需要进行扩容。首先根据扩容倍数创建一个更大的数组,再将当前数组的所有元素依次移动至新数组。在本示例中,我们规定每次将数组扩容至之前的 2 倍。
class MyList:
"""列表类简易实现"""
def __init__(self):
"""构造方法"""
self.__capacity: int = 10 # 列表容量
self.__nums: list[int] = [0] * self.__capacity # 数组(存储列表元素)
self.__size: int = 0 # 列表长度(即当前元素数量)
self.__extend_ratio: int = 2 # 每次列表扩容的倍数
def size(self) -> int:
"""获取列表长度(即当前元素数量)"""
return self.__size
def capacity(self) -> int:
"""获取列表容量"""
return self.__capacity
def get(self, index: int) -> int:
"""访问元素"""
# 索引如果越界则抛出异常,下同
if index < 0 or index >= self.__size:
raise IndexError("索引越界")
return self.__nums[index]
def set(self, num: int, index: int):
"""更新元素"""
if index < 0 or index >= self.__size:
raise IndexError("索引越界")
self.__nums[index] = num
def add(self, num: int):
"""尾部添加元素"""
# 元素数量超出容量时,触发扩容机制
if self.size() == self.capacity():
self.extend_capacity()
self.__nums[self.__size] = num
self.__size += 1
def insert(self, num: int, index: int):
"""中间插入元素"""
if index < 0 or index >= self.__size:
raise IndexError("索引越界")
# 元素数量超出容量时,触发扩容机制
if self.__size == self.capacity():
self.extend_capacity()
# 将索引 index 以及之后的元素都向后移动一位
for j in range(self.__size - 1, index - 1, -1):
self.__nums[j + 1] = self.__nums[j]
self.__nums[index] = num
# 更新元素数量
self.__size += 1
def remove(self, index: int) -> int:
"""删除元素"""
if index < 0 or index >= self.__size:
raise IndexError("索引越界")
num = self.__nums[index]
# 索引 i 之后的元素都向前移动一位
for j in range(index, self.__size - 1):
self.__nums[j] = self.__nums[j + 1]
# 更新元素数量
self.__size -= 1
# 返回被删除元素
return num
def extend_capacity(self):
"""列表扩容"""
# 新建一个长度为原数组 __extend_ratio 倍的新数组,并将原数组拷贝到新数组
self.__nums = self.__nums + [0] * self.capacity() * (self.__extend_ratio - 1)
# 更新列表容量
self.__capacity = len(self.__nums)
def to_array(self) -> list[int]:
"""返回有效长度的列表"""
return self.__nums[: self.__size]
- 数组和链表是两种基本的数据结构,分别代表数据在计算机内存中的两种存储方式:连续空间存储和离散空间存储。两者的特点呈现出互补的特性。
- 数组支持随机访问、占用内存较少;但插入和删除元素效率低,且初始化后长度不可变。
- 链表通过更改引用(指针)实现高效的节点插入与删除,且可以灵活调整长度;但节点访问效率低、占用内存较多。常见的链表类型包括单向链表、循环链表、双向链表。
- 动态数组,又称列表,是基于数组实现的一种数据结构。它保留了数组的优势,同时可以灵活调整长度。列表的出现极大地提高了数组的易用性,但可能导致部分内存空间浪费。
