作业1
-
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。 -
文件夹链接:https://gitee.com/scholaar/crawl_project/tree/master/第三次实践作业
代码
items.py
class work1_Item(scrapy.Item):
img_url = scrapy.Field()
pipelines.py
class ImgSpiderPipeline:
count = 0
images_store = "C:\\Users\\zmk\\PycharmProjects\\pythonProject\\ImgSpider"
threads = []
def open_spider(self, spider):
picture_path = self.images_store + '\\images'
if os.path.exists(picture_path): # 判断文件夹是否存在
for root, dirs, files in os.walk(picture_path, topdown=False):
for name in files:
os.remove(os.path.join(root, name)) # 删除文件
for name in dirs:
os.rmdir(os.path.join(root, name)) # 删除文件夹
os.rmdir(picture_path) # 删除文件夹
os.mkdir(picture_path) # 创建文件夹
单线程(写在pipelines中)
# 单线程
def process_item(self, item, spider):
url = item['img_url']
print(url)
# 创建文件夹逻辑
single_threaded_path = '.\\images\\Single threaded'
os.makedirs(single_threaded_path, exist_ok=True)
img_data = urllib.request.urlopen(url=url).read()
img_path = os.path.join(single_threaded_path, f'{self.count}.jpg')
with open(img_path, 'wb') as fp:
fp.write(img_data)
self.count = self.count + 1
return item
多线程(写在pipelines中)
# 多线程
def process_item(self, item, spider):
url = item['img_url']
print(url)
T=threading.Thread(target=self.download_img,args=(url,))
T.setDaemon(False)
T.start()
self.threads.append(T)
return item
def download_img(self, url):
# 创建文件夹逻辑
thread_path = os.path.join('.\\images\\Thread')
os.makedirs(thread_path, exist_ok=True)
img_data = urllib.request.urlopen(url=url).read()
img_path = os.path.join(thread_path, f'{self.count}.jpg')
with open(img_path, 'wb') as fp:
fp.write(img_data)
self.count = self.count + 1
def close_spider(self,spider):
for t in self.threads:
t.join()
spider.py
import scrapy
from demo.items import work1_Item
class Work1Spider(scrapy.Spider):
name = 'work1'
# allowed_domains = ['www.weather.com.cn']
start_urls = ['http://www.weather.com.cn/']
def parse(self, response):
data = response.body.decode()
selector=scrapy.Selector(text=data)
img_datas = selector.xpath('//a/img/@src')
for img_data in img_datas:
item = work1_Item()
item['img_url'] = img_data.extract()
yield item
运行结果
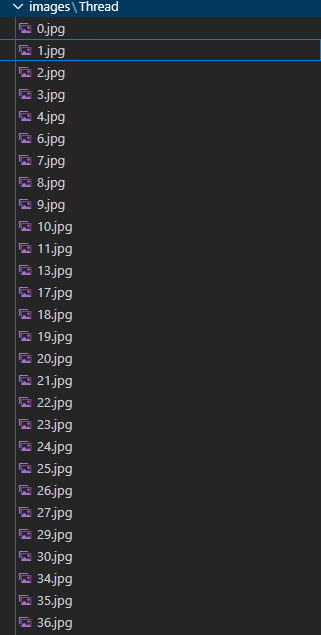
心得体会
在多线程的方面卡了一些时间,对于多线程还是比较不熟练
作业2
-
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/ -
输出信息:
MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStock -
文件夹链接:https://gitee.com/scholaar/crawl_project/tree/master/第三次实践作业
代码
items.py
class StockItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
code = scrapy.Field()
name = scrapy.Field()
new_price = scrapy.Field()
price_limit = scrapy.Field()
change_amount = scrapy.Field()
turnover = scrapy.Field()
volume = scrapy.Field()
rise = scrapy.Field()
highest = scrapy.Field() # 最高
lowest = scrapy.Field() # 最低
today_open = scrapy.Field() # 今开
yesterday_receive = scrapy.Field() # 昨收
pass
pipelines.py
import sqlite3
class StockPipeline:
def open_spider(self, spider):
print("opened")
try:
self.con = sqlite3.connect('stocks.db') # 连接到名为 stocks.db 的数据库文件
self.cursor = self.con.cursor()
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS stocks (
id INTEGER PRIMARY KEY,
code TEXT,
name TEXT,
new_price TEXT,
price_limit TEXT,
change_amount TEXT,
turnover TEXT,
volume TEXT,
rise TEXT,
highest TEXT,
lowest TEXT,
today_open TEXT,
yesterday_receive TEXT
)
''')
self.opened = True
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
def process_item(self, item, spider):
try:
self.cursor.execute('''
INSERT INTO stocks (
code, name, new_price, price_limit, change_amount,
turnover, volume, rise, highest, lowest, today_open, yesterday_receive
)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', (
item['code'], item['name'], item['new_price'], item['price_limit'],
item['change_amount'], item['turnover'], item['volume'], item['rise'],
item['highest'], item['lowest'], item['today_open'], item['yesterday_receive']
))
self.con.commit()
except Exception as err:
print(err)
return item
spider.py
import json
from shijian3_2.items import StockItem
import scrapy
class MySpider(scrapy.Spider):
name = 'stocks'
def parse(self, response):
url = [
'http://64.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124019574933852728926_1697704464511&pn=1&pz=20&po=1&np=2&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1697704464512']
try:
data = response.body.decode('utf-8')
print(data)
data = data[41:-2]
responseJson = json.loads(data)
stocks = responseJson.get('data').get('diff')
for stock in stocks:
item = StockItem()
item['code'] = stock.get('f12')
item['name'] = stock.get('f14')
item['new_price'] = stock.get('f2')
item['price_limit'] = stock.get('f3')
item['change_amount'] = stock.get('f4')
item['turnover'] = stock.get('f5')
item['volume'] = stock.get('f6')
item['rise'] = stock.get('f7')
item['highest'] = stock.get('f15')
item['lowest'] = stock.get('f16')
item['today_open'] = stock.get('f17')
item['yesterday_receive'] = stock.get('f18')
yield item
yield scrapy.Request(url, callback=self.parse)
except Exception as err:
print(err)
运行结果
保存为db文件:
保存为csv文件方便查看:

心得体会
有了上一次的作业的打底,这个写起来轻松一点,但是把一份代码转化成scrapy框架还是让我做了好久
作业3
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/ -
文件夹链接:https://gitee.com/scholaar/crawl_project/tree/master/第三次实践作业
代码
items.py
import scrapy
class MoneyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
currency = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
Time = scrapy.Field()
pipelines.py
import sqlite3
class MoneyPipeline(object):
def open_spider(self, spider):
print("opened")
try:
self.con = sqlite3.connect('new_money.db') # 创建或连接到新数据库文件
self.cursor = self.con.cursor()
self.cursor.execute("CREATE TABLE IF NOT EXISTS changes ("
"bId INTEGER PRIMARY KEY AUTOINCREMENT,"
"bCurrency TEXT,"
"bTSP REAL,"
"bCSP REAL,"
"bTBP REAL,"
"bCBP REAL,"
"bTime TEXT)") # 创建表格
self.opened = True
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
def process_item(self, item, spider):
try:
print("货币名称\t", "现汇买入价\t", "现钞买入价\t ", "现汇卖出价\t ", "现钞卖出价\t", "时间\t")
print("{:^10}{:>10}{:>10}{:>10}{:>12}{:>13}".format(item["currency"],item["TSP"],item["CSP"],item["TBP"],item["CBP"],item["Time"]))
if self.opened:
self.cursor.execute("INSERT INTO changes (bCurrency,bTSP,bCSP,bTBP,bCBP,bTime) VALUES (?,?,?,?,?,?)",
(item["currency"],item["TSP"],item["CSP"],item["TBP"],item["CBP"],item["Time"]))
except Exception as err:
print(err)
return item
spider.py
import scrapy
from bs4 import UnicodeDammit
from shijian3_3.items import MoneyItem
class ChangeSpider(scrapy.Spider):
name = 'change'
def start_requests(self):
url = 'https://www.boc.cn/sourcedb/whpj/'
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
money = selector.xpath("/html/body/div/div[5]/div[1]/div[2]/table/tbody/tr[2]/td[1]")
for moneyitem in money[1:]: # 处理表头
currency = moneyitem.xpath("./td[@class='fontbold']/text()").extract_first()
TSP = moneyitem.xpath("/html/body/div/div[5]/div[1]/div[2]/table/tbody/tr[2]/td[2]").extract_first()
CSP = moneyitem.xpath("/html/body/div/div[5]/div[1]/div[2]/table/tbody/tr[2]/td[3]").extract_first()
TBP = moneyitem.xpath("/html/body/div/div[5]/div[1]/div[2]/table/tbody/tr[2]/td[4]").extract_first()
CBP = moneyitem.xpath("/html/body/div/div[5]/div[1]/div[2]/table/tbody/tr[2]/td[5]").extract_first()
Time = moneyitem.xpath("/html/body/div/div[5]/div[1]/div[2]/table/tbody/tr[2]/td[7]").extract_first()
item = MoneyItem()
item["currency"] = currency.strip() if currency else "" # 处理空标签
item["TSP"] = TSP.strip() if TSP else ""
item["CSP"] = CSP.strip() if CSP else ""
item["TBP"] = TBP.strip() if TBP else ""
item["CBP"] = CBP.strip() if CBP else ""
item["Time"] = Time.strip() if Time else ""
yield item
except Exception as err:
print(err)
运行结果
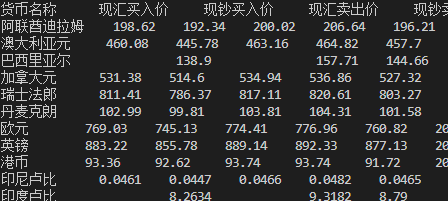
心得体会
对于scrapy的使用更上一层楼