MetaFormer Is Actually What You Need for Vision
* Authors: [[Weihao Yu]], [[Mi Luo]], [[Pan Zhou]], [[Chenyang Si]], [[Yichen Zhou]], [[Xinchao Wang]], [[Jiashi Feng]], [[Shuicheng Yan]]
初读印象
comment:: (PoolFormer)Transformer的通用架构是其良好性能的保障,而不是其中的混合算子。
动机
Vit在CV上获得了良好性能表现。Transformer编码器由两部分组成,一部分是用于混合令牌信息的注意力模块,我们称之为令牌混合器(token mixer)。另一个部分包含其余模块,如通道MLP和剩余连接。通过将注意力模块视为一个特定的令牌混合器,我们进一步将整个Transformer抽象为一个通用架构MetaFormer,其中令牌混合器没有被指定。
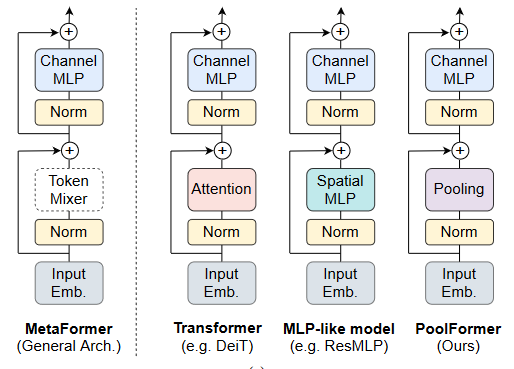 长久以来,Transformers的成功归功于基于注意力的令牌混合器。基于这一共同信念,注意力模块的许多变体被开发出来以改进视觉转换器。最近的工作将令牌混合器替换成完全空间MLP,也有竞争力的性能表现。其他方法将令牌混合器换为傅里叶变换,也有普通VIT97%的准确率。因此,我们假设与特定的令牌混合器相比,MetaFormer对于模型实现竞争性性能更为重要。为了验证这一假设,该文章应用一个极其简单的非参数算子----池化,作为令牌混合器,只进行基本的令牌混合。令人惊讶的是,这种衍生模型称为PoolFormer,取得了有竞争力的性能,甚至一贯优于调优的Transformer和MLP - like模型。
长久以来,Transformers的成功归功于基于注意力的令牌混合器。基于这一共同信念,注意力模块的许多变体被开发出来以改进视觉转换器。最近的工作将令牌混合器替换成完全空间MLP,也有竞争力的性能表现。其他方法将令牌混合器换为傅里叶变换,也有普通VIT97%的准确率。因此,我们假设与特定的令牌混合器相比,MetaFormer对于模型实现竞争性性能更为重要。为了验证这一假设,该文章应用一个极其简单的非参数算子----池化,作为令牌混合器,只进行基本的令牌混合。令人惊讶的是,这种衍生模型称为PoolFormer,取得了有竞争力的性能,甚至一贯优于调优的Transformer和MLP - like模型。
方法
本文考察一个基本问题:什么才是真正对Transformer及其变体的成功负责?其答案是一般架构,即MetaFormer。本文简单地利用池化作为基本的令牌混合器来探测MetaFormer的功效。
MateFormer
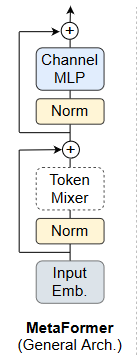 MetaFormer是一个通用的体系结构,其中令牌混合器不被指定,其他组件与Transformers相同。输入I首先通过输入嵌入进行处理。
MetaFormer是一个通用的体系结构,其中令牌混合器不被指定,其他组件与Transformers相同。输入I首先通过输入嵌入进行处理。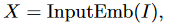
其中\(X\in R^{N\times C}\)表示序列长度为N,嵌入维度为C的嵌入令牌。
第一个块包含一个令牌混合器,用于令牌之间的信息交流:
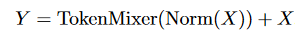 第二个子块主要由具有非线性激活的两层MLP组成:
第二个子块主要由具有非线性激活的两层MLP组成: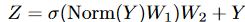
其中
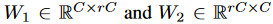 \(\sigma\)是非线性激活函数,如GELU和ReLU。#### PoolFormer
\(\sigma\)是非线性激活函数,如GELU和ReLU。#### PoolFormer
使用尴尬的池化操作符作为令牌混合器,该算子没有可学习的参数,只是使每个令牌平均聚合其附近的令牌特征。该算子可以表示为:
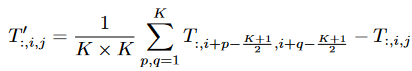
其中K是池化大小,由于MetaFormer块已经有了残差连接,因此在上式中加入了输入本身的减法。
整体架构
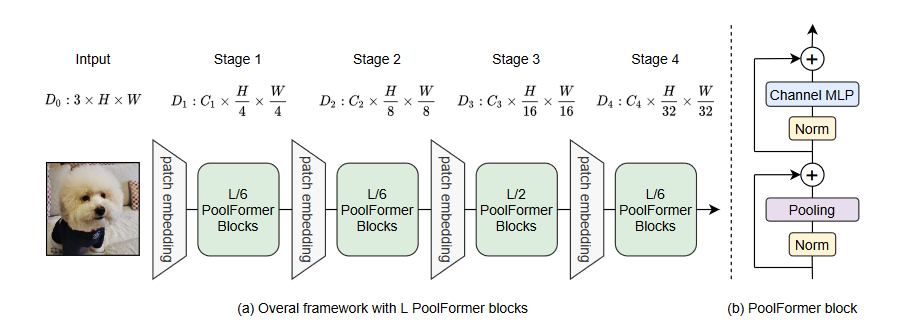 总共有L个PoolFormer块,阶段(1,2, 3, 4)分别有 (L/6, L/6, L/2, L/6)个块。
总共有L个PoolFormer块,阶段(1,2, 3, 4)分别有 (L/6, L/6, L/2, L/6)个块。
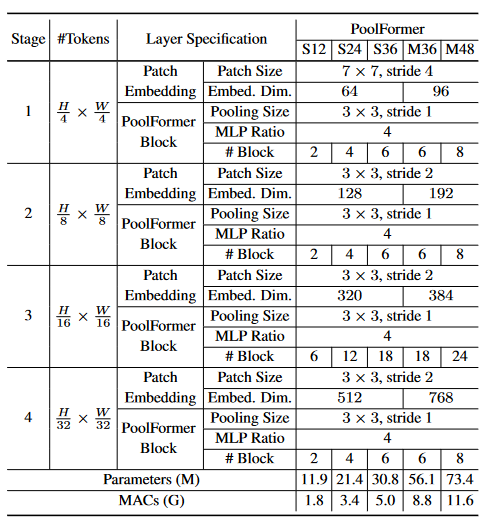
不同PoolFormer模型的配置。嵌入维数有两组,即小尺寸(64、128、320、512)维和中等尺寸(96、196、384、768)维。' S24 '表示模型嵌入维数较小,共有24个PoolFormer块。
表现
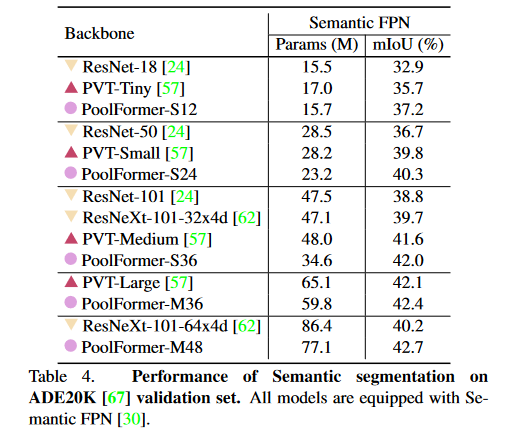
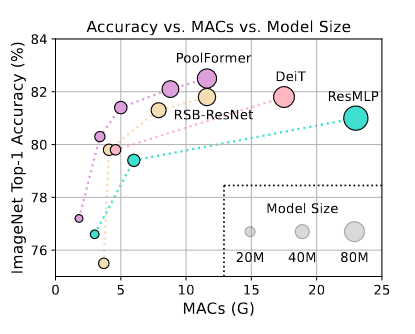
上表展示了使用FPN的不同主干的ADE20K语义分割性能。基于PoolFormer的模型始终优于基于CNN的ResNet和ResNeXt以及基于Transformer的PVT模型。例如,PoolFormer - 12比ResNet - 18和PVT - Tiny分别获得了37.1、4.3和1.5的mIoU
启发
mateformer中的patch embedding或许可以改进,比如用可变形卷积的方式。