【python爬虫课程设计】大数据分析——信用卡风险评估
一、选题的背景
近年来,随着信用卡业务的快速发展,信用卡已经成为人们日常生活中不可或缺的一部分。然而,信用卡违约现象也日益严重,给银行和信用卡公司带来了巨大的风险和损失。因此,对信用卡违约风险进行评估和管理成为了银行业和金融领域中的一个重要课题。随着数据科学和机器学习技术的不断进步,越来越多的研究人员开始尝试利用这些技术来构建更加精准的信用卡违约预测模型。通过利用大量的信用卡交易数据和客户信息,这些模型能够更好地挖掘出潜在的违约风险因素,从而更加准确地预测违约情况。
通过构建效果优越的信用卡违约风险评估模型对降低信用风险、提高风险管理效率、促进金融稳定、满足金融监管要求以及推动数据科学和金融领域的融合等方面十分有价值的。
二、信用卡风险评估大数据分析设计方案
2.1本数据集的数据内容与数据特征分析
本数据集包含了大量的信用卡交易数据,包括交易时间、交易金额、交易类型、持卡人信息(如姓名、身份证号、地址、信用卡号等)等。通过对这些数据进行分析,我们可以对信用卡风险进行评估。
2.2数据分析的课程设计方案概述
本课程将采用大数据分析技术,对信用卡风险评估数据进行深入挖掘和分析。具体实现思路如下:
1. 数据清洗:对数据进行清洗,去除无效和重复数据,确保数据质量。
2. 数据预处理:对数据进行标准化和归一化处理,以便于机器学习算法更好地处理。
3. 特征提取:通过挖掘和分析数据,提取出与信用卡风险相关的特征,如消费习惯、还款能力、信用历史等。
4. 模型构建:使用机器学习算法(如决策树、随机森林、神经网络等)构建信用卡风险评估模型,对持卡人的信用风险进行评估。
5. 模型评估:使用交叉验证、ROC曲线等方法对模型进行评估,确定模型的准确性和可靠性。
6. 结果输出:将评估结果以可视化的形式输出,方便用户查看和解读。
技术难点包括:
1. 数据量庞大:需要处理大量的数据,需要采用高效的分布式计算框架和存储技术。
2. 数据类型多样:数据包含多种类型的数据,需要进行数据类型转换和数据标准化处理。
3. 算法选择与调优:需要根据实际情况选择合适的机器学习算法,并进行算法的调优和优化,以提高模型的准确性和可靠性。
4. 模型解释性:需要解释模型评估结果的可解释性,以便用户更好地理解和应用评估结果。
为了解决以上技术难点,可以采用以下解决方案:
1. 采用分布式计算框架和存储技术,提高数据处理效率。
2. 对数据进行标准化和归一化处理,以便于机器学习算法更好地处理不同类型的数据。
3. 针对不同的算法进行实验和比较,选择最优的算法进行模型构建和评估。
4. 使用可视化工具和工具链,将结果以可视化的形式输出,方便用户理解和应用评估结果。
三、数据源
我选择Credit_card数据集做为实验
数据集(https://www.kaggle.com/datasets/rohitudageri/credit-card-details),该数据集包含1548例客户信息,其中175例为违约客户,1373条良好客户。
四、数据探索和预处理
4.1数据描述性分析
import numpy as np
import pandas as pd
import math
import datetime
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import StandardScaler
# 可视化
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import OneHotEncoder
# 机器学习
from sklearn import datasets
from sklearn import model_selection
from sklearn import tree
from sklearn import preprocessing
from sklearn import metrics
from sklearn import linear_model
from sklearn.svm import LinearSVC
# 网格和随机搜索
import scipy.stats as st
from scipy.stats import randint as sp_randint
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import RandomizedSearchCV
# 指标
from sklearn.metrics import precision_recall_fscore_support, roc_curve, auc
# 警告管理
import warnings
from matplotlib.font_manager import FontProperties
from imblearn.over_sampling import SMOTE,ADASYN,SVMSMOTE
# 机器学习
from sklearn.model_selection import train_test_split
from imblearn.over_sampling import RandomOverSampler
#1.加载数据
data = pd.read_csv('D:\Pycharm\pyside2\数据挖掘\python数据挖掘\信用卡\Credit_card.csv')
# 定义目标变量和特征
y = data['Label']
X = data.drop(['Label'], axis=1)
# 确定分类变量和数值变量
categorical_cols = [cname for cname in X.columns if X[cname].dtype == "object"]
numerical_cols = [cname for cname in X.columns if X[cname].dtype in ['int64', 'float64']]
# 查看数据的前几行
print(data.head())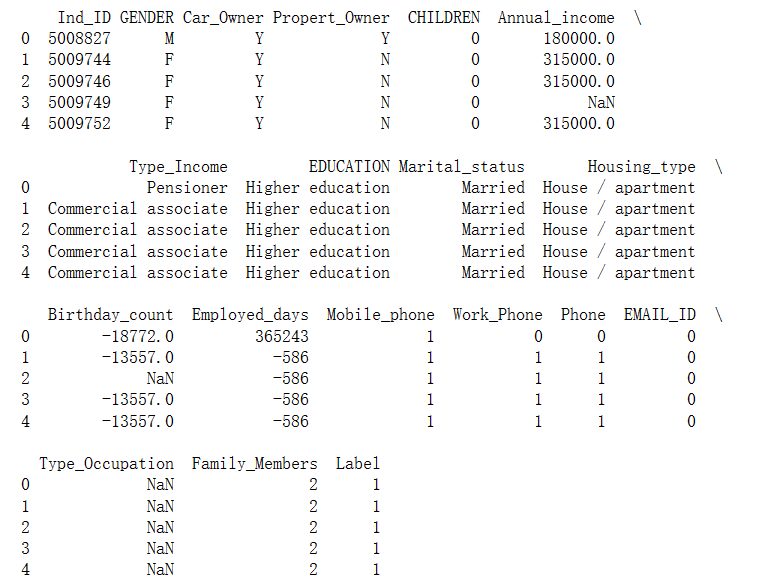
4.2 用户画像分析
sns.set(style="whitegrid")
myfont = FontProperties(fname='C:/Windows/Fonts/simhei.ttf', size=14) # 定义字体属性
sns.set(font=myfont.get_name())
# 1分析性别对信用卡申请的影响
plt.figure(figsize=(8, 6))
sns.countplot(x='GENDER', hue='Label', data=data)
plt.title('根据性别划分的信用卡审批分布', fontproperties=myfont)
plt.xlabel('性别', fontproperties=myfont)
plt.ylabel('数量', fontproperties=myfont)
plt.show()
# 2分析年龄与信用卡申请结果的关系
plt.figure(figsize=(8, 6))
sns.boxplot(x='Label', y='Birthday_count', data=data)
plt.title('年龄与信用卡审批状态的分布', fontproperties=myfont)
plt.xlabel('审批状态', fontproperties=myfont)
plt.ylabel('年龄', fontproperties=myfont)
plt.show()
# 3. 婚姻状况与信用卡申请结果的关系
plt.figure(figsize=(10, 6))
sns.countplot(x='Marital_status', hue='Label', data=data, palette='viridis')
plt.title('根据婚姻状况划分的信用卡审批分布', fontsize=15)
plt.xlabel('婚姻状况', fontsize=12)
plt.ylabel('数量', fontsize=12)
plt.legend(title='审批结果', labels=['未通过', '通过'])
plt.show()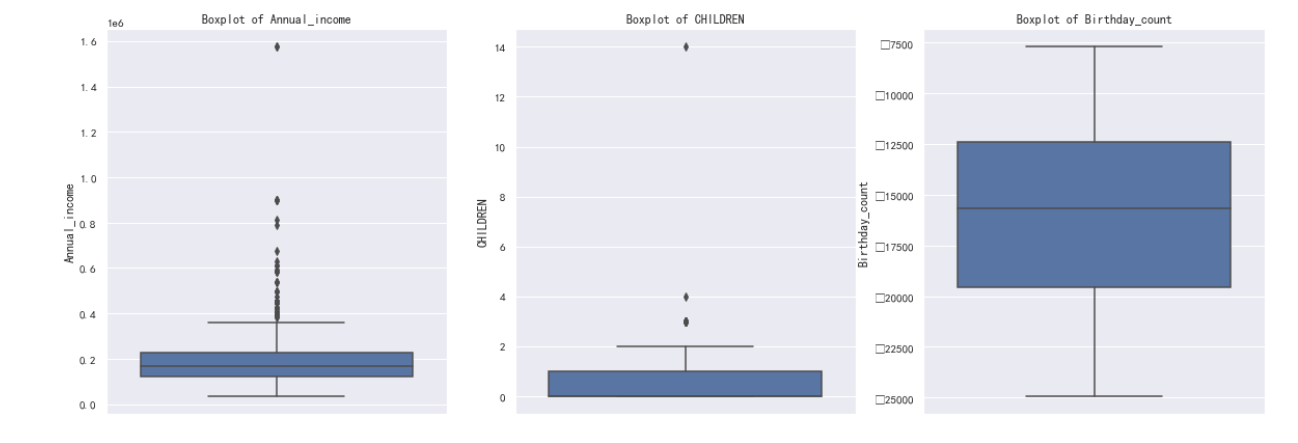
1.根据性别划分的信用卡审批分布
男性和女性在信用卡申请审批上的分布差异不大,两者的通过和未通过分布相似。
2.年龄与信用卡审批状态的分布
在审批和未审批的用户中,年龄分布较为接近。尽管如此,未获批准的用户似乎年龄分布略微年轻一些。
3.根据婚姻状况划分的信用卡审批分布
“未婚”和“已婚”群体在信用卡审批上的差异不是很大,但在“其他”类别中,未通过的比例较高。
import matplotlib.pyplot as plt
import seaborn as sns
# 设置可视化风格
sns.set(style="whitegrid")
# 定义字体属性
myfont = FontProperties(fname='C:/Windows/Fonts/simhei.ttf', size=14)
sns.set(font=myfont.get_name())
# 1. 收入与信用卡申请结果的关系
plt.figure(figsize=(8, 6))
sns.boxplot(x='Label', y='Annual_income', data=data)
plt.title('收入与信用卡审批状态的分布', fontsize=15)
plt.xlabel('审批状态', fontsize=12)
plt.ylabel('收入', fontsize=12)
plt.xticks(ticks=[0,1], labels=['未通过', '通过'])
plt.show()
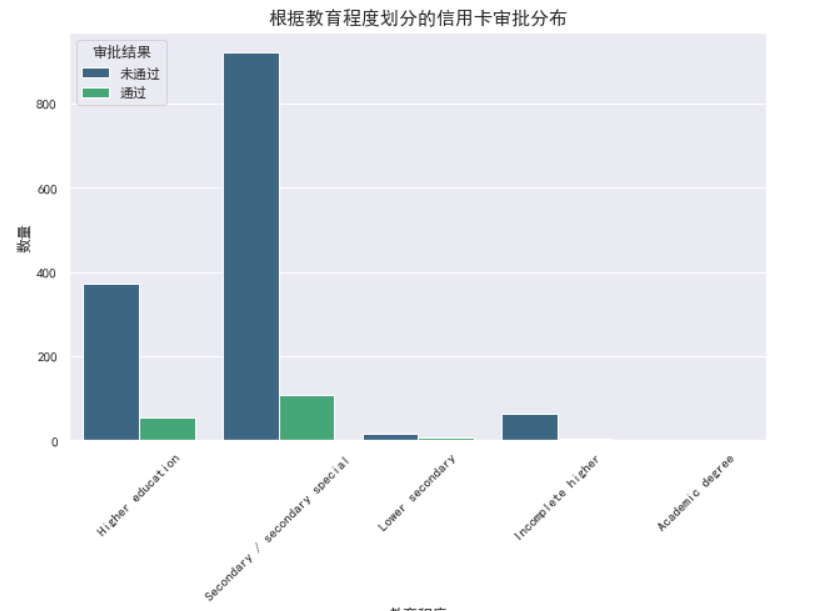
# 2. 教育水平与信用卡申请结果的关系
plt.figure(figsize=(10, 6))
sns.countplot(x='EDUCATION',hue='Label', data=data, palette='viridis')
plt.title('根据教育程度划分的信用卡审批分布', fontsize=15)
plt.xlabel('教育程度', fontsize=12)
plt.ylabel('数量', fontsize=12)
plt.legend(title='审批结果', labels=['未通过', '通过'])
plt.xticks(rotation=45)
plt.show()
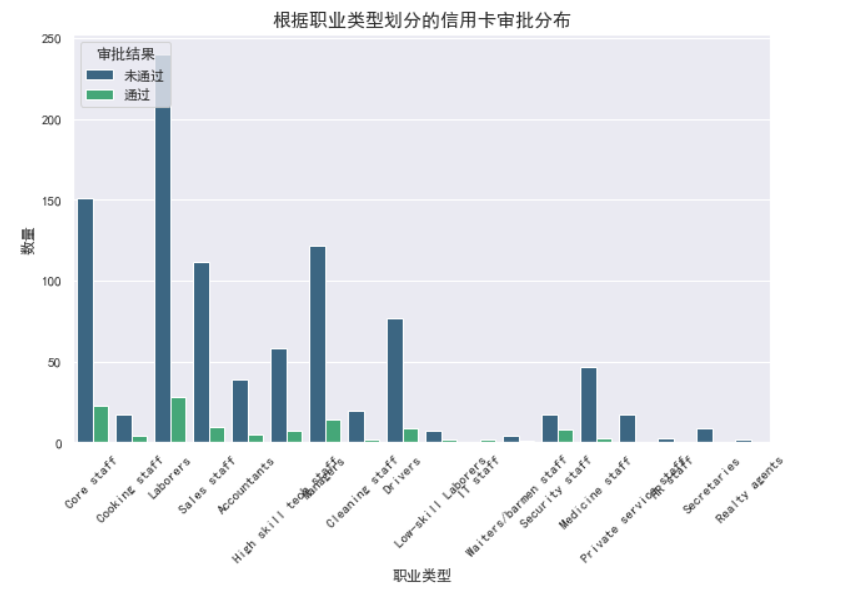
# 3. 职业类型与信用卡申请结果的关系
plt.figure(figsize=(10, 6))
sns.countplot(x='Type_Occupation', hue='Label', data=data, palette='viridis')
plt.title('根据职业类型划分的信用卡审批分布', fontsize=15)
plt.xlabel('职业类型', fontsize=12)
plt.ylabel('数量', fontsize=12)
plt.legend(title='审批结果', labels=['未通过', '通过'])
plt.xticks(rotation=45)
plt.show()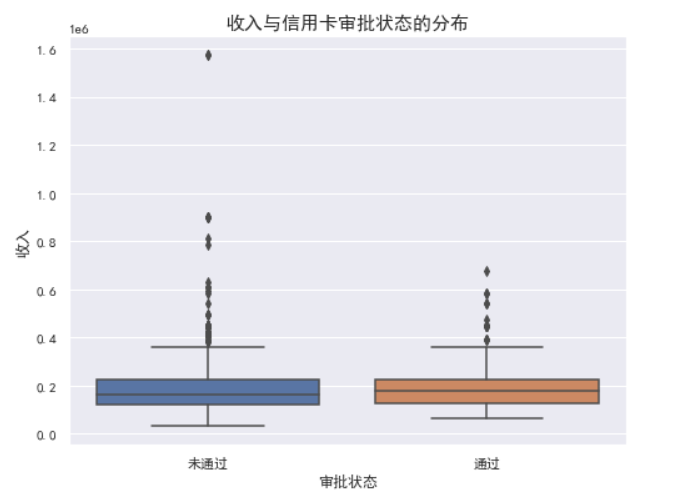
# 设置可视化风格
sns.set(style="whitegrid")
# 定义字体属性
myfont = FontProperties(fname='C:/Windows/Fonts/simhei.ttf', size=14)
sns.set(font=myfont.get_name())
# 绘制被拒绝申请的年收入和年龄分布图
plt.figure(figsize=(15, 5))
# 年收入分布图
plt.subplot(1, 2, 1)
# 绘制直方图
sns.histplot(data[data['Label'] == 0]['Annual_income'], kde=False, bins=30, ).set(title='年收入分布图(被拒绝申请)')
plt.xlabel('年收入')
plt.ylabel('频数')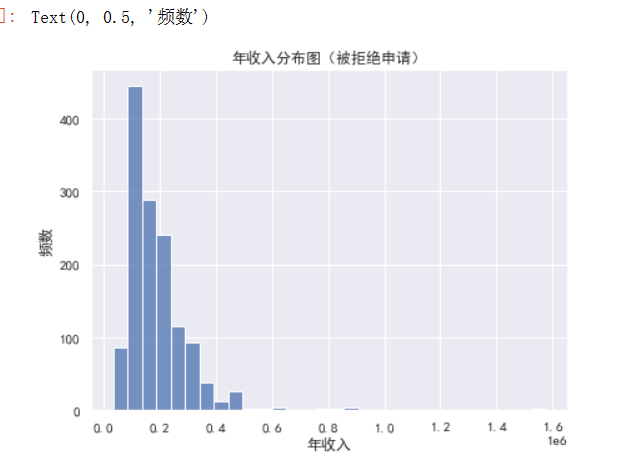
1.收入与信用卡申请结果的关系: 审批通过的申请者通常有较高的收入。 收入较低的申请者更可能被拒绝。
2.教育水平与信用卡申请结果的关系 不同教育程度的人在信用卡申请的通过率上存在一些差异。 有些教育程度类别的人可能更容易获得信用卡批准。
3.职业类型与信用卡申请结果的关系 不同职业类型的人在信用卡申请的通过率上存在显著差异。 某些职业领域的人可能更容易获得信用卡的批准。 总结和策略建议 客户定位:银行或信用卡公司可以将目标客户定位为收入较高的群体,因为他们的申请通过率较高。
4.风险管理:需要仔细考虑教育水平和职业类型在风险管理中的角色。例如,如果某一教育或职业类别的贷款违约率较高,可能需要对这些群体的申请进行更严格的审核。
5.市场策略:针对具有较高通过率的特定教育和职业类别的人群,设计特定的市场策略和优惠方案,以吸引这些潜在客户。
6.优化申请流程:对于那些在特定特征下(如低收入、特定职业或教育水平)申请通过率较低的群体,银行可以考虑优化申请流程,提供更多的辅助和指导,以提高他们的通过率。
7.信用教育:对于那些信用卡申请通过率较低的群体,银行或信用卡公司可以提供信用教育和管理培训,帮助他们提高信用评分,从而提高未来的申请通过率。
4.3 数据清洗与预处理
print(data.info()) # 查看数据信息
data.drop('Ind_ID',axis = 1,inplace = True) # 删除Ind_ID列
print(data.isnull().sum()) # 查看缺失值数量
#1 填补空缺值
'''可以看到“GENDER”、“Annual_income”、“Birthday_count ”、“Type_Occupation”都存在缺失值,针对不同变量我们用不同的填充方式'''
# 用众数填充GENDER和Type_Occupation
data['GENDER'].fillna(data['GENDER'].mode()[0], inplace = True)
data['Type_Occupation'].fillna(data['Type_Occupation'].mode()[0], inplace = True)
# 2 用均值填充Annual_income和Birthday_count
data['Annual_income'].fillna(data['Annual_income'].mean(), inplace = True)
data['Birthday_count'].fillna(data['Birthday_count'].mean(), inplace = True)
print(data.isnull().sum())
#3 字符数据类型处理
#4 Birthday_count 可以处理成Age
data["Age"] = data["Birthday_count"].apply(lambda x: abs(int(x)) / 365)
data = data.drop("Birthday_count", axis=1)
#5 对分类型变量进行独热编码 (将二分类变量转换为1和0)
for column in ['Type_Income', 'Type_Occupation', 'Housing_type', 'Marital_status', 'EDUCATION']:
dummies = pd.get_dummies(data[column], prefix=column).astype(bool)
data = pd.concat([data, dummies], axis=1)
data = data.drop(column, axis=1).reset_index(drop=True)
data['Annual_income'] = data['Annual_income'].astype('int64')
data['Age'] = data['Age'].astype('int64')
def heatmap(data, method='pearson', camp='RdYlGn', figsize=(10 ,8)):
"""
data: 整份数据
method:默认为 pearson 系数
camp:默认为:RdYlGn-红黄蓝;YlGnBu-黄绿蓝;Blues/Greens
figsize: 默认为 10,8
"""
## 消除斜对角颜色重复的色块
# mask = np.zeros_like(df2.corr())
# mask[np.tril_indices_from(mask)] = True
plt.figure(figsize=figsize, dpi= 80)
sns.heatmap(data.corr(method=method),
xticklabels=data.corr(method=method).columns,
yticklabels=data.corr(method=method).columns, cmap=camp,
center=0, annot=True)
plt.show()
# 对角线一半的效果:mask=mask
corr_matrix = data.select_dtypes(np.number).corr()
heatmap(corr_matrix, camp='RdYlGn')
'''
Family_Members和Children的相关性系数很高,可以考虑去除二者之一;
Mobile_phone只有一个取值,没有意义。家庭成员与小孩数量方面,
家庭成员可能更有代表性,因此先尝试去除Children
'''
data = data.drop(['Mobile_phone','CHILDREN'],axis = 1)
data.to_csv("new_data.csv")
data = pd.read_csv('new_data.csv',index_col=0)
X = data.drop("Label", axis=1)
y = data["Label"]
y_table=list(y)
result = pd.value_counts(y_table)
result = result.to_dict()
print('输出类别及个数:',result)
# 1.数据SVMSMOTE过采样处理
scaler = StandardScaler()
X =X.loc[:,['Employed_days', 'Annual_income','Age',]]
svmsmote=SVMSMOTE(random_state=0)
X, y = svmsmote.fit_resample(X, y)
print('过采样后样本维度:',X.shape,y.shape)
# 2 数据归一化处理
X=scaler.fit_transform(X)
#3 按照8:2比例划分训练集,测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,stratify=y, random_state=42)
5.数据建模分析
RF(随机森林)作为信用卡风险评估模型的好处主要有以下几点:
不容易过拟合:RF采用随机采样的方式选择训练样本,每次学习使用不同的训练集,这在一定程度上避免了过拟合。 能够处理高维数据:RF可以处理成千上万的输入变量,并确定最重要的变量,因此被认为是一个不错的降维方法。在处理信用卡风险评估这种高维数据时,RF表现出强大的能力。 输出变量的重要性程度:RF模型能够输出变量的重要性程度,这对于信用卡风险评估模型来说非常有用,可以帮助理解哪些因素对信用风险影响最大。 泛化能力强:由于采用了随机采样,训练出的模型的方差小,泛化能力强,这意味着模型在新数据上的表现也会比较好。 训练速度快:RF的训练可以高度并行化,这对于大数据时代的大样本训练速度有优势。 对部分特征缺失不敏感:在信用卡风险评估中,部分数据可能存在缺失的情况,RF对这种情况不敏感,仍然可以进行有效的训练和预测。
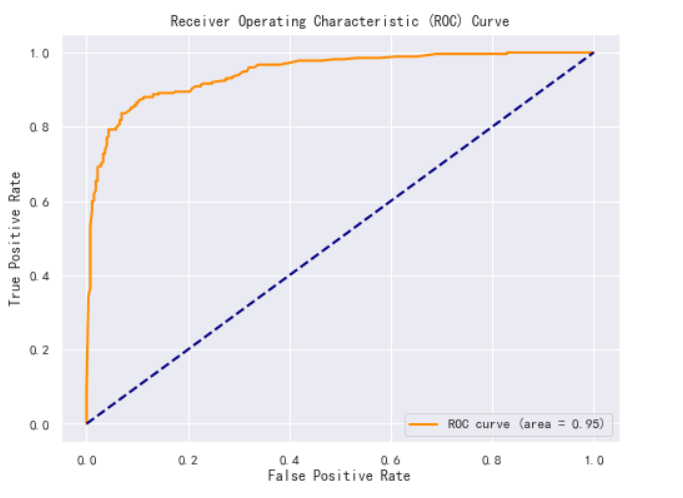
本文使用GridSearchCV 对RF模型进行调参优化,并计算准确率、精准率、召回率、F1分数以及绘制ROC曲线来评估模型的性能。
# 定义参数网格
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import StratifiedKFold,cross_val_score
rf_param_grid = {
'n_estimators': [50, 100, 200],
'max_features': ['auto', 'sqrt'],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
#定义随即森林模型
clf=RandomForestClassifier(random_state=0)
6.结果描述和解释
# 使用 GridSearchCV 进行调参 (采用5则交叉验证训练模型)
kfold = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
model=cross_val_score(clf,X_train,y_train,cv=kfold,scoring='accuracy')
accuracy1=model.mean()
grid_search = GridSearchCV(clf, rf_param_grid, cv=kfold, verbose=2, n_jobs=-1,scoring='accuracy',)
grid_search.fit(X_train, y_train)
# 选择最佳参数组合的模型
best_clf = grid_search.best_estimator_
# 打印最佳参数
print("Best Parameters:")
print("-----------------")
print(grid_search.best_params_, "\n")
from sklearn.model_selection import cross_val_score
from sklearn.metrics import precision_recall_fscore_support
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
accuracy = best_clf.score(X_test, y_test)
print(f"随机森林模型参数优化之前的准确率: {accuracy1:.4f}\n")
print(f"随机森林模型参数优化之后的准确率: {accuracy:.4f}\n")
y_pred = best_clf.predict(X_test)
class_report = classification_report(y_test, y_pred)
print(class_report)
# #绘制混淆矩阵
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(cm,
annot=True, fmt='g', cmap='Blues',
xticklabels=['Predicted 0', 'Predicted 1'],
yticklabels=['Actual 0', 'Actual 1'])
plt.title('Confusion Matrix for Logistic Regression Model')
plt.show()
#
# #绘制ROC取消
fpr, tpr, _ = roc_curve(y_test, best_clf.predict_proba(X_test)[:, 1])
roc_auc = auc(fpr, tpr)
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc="lower right")
plt.show()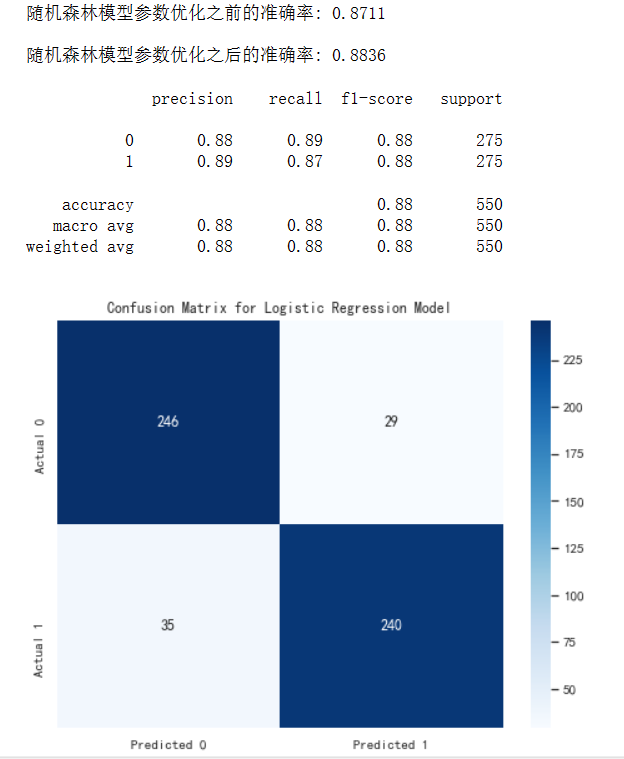
7.总代码
1. import numpy as np
2. import pandas as pd
3. import math
4. import datetime
5. from sklearn.preprocessing import OneHotEncoder
6. from sklearn.preprocessing import StandardScaler
7. # 可视化
8. import matplotlib.pyplot as plt
9. import seaborn as sns
10. from sklearn.preprocessing import OneHotEncoder
11. # 机器学习
12. from sklearn import datasets
13. from sklearn import model_selection
14. from sklearn import tree
15. from sklearn import preprocessing
16. from sklearn import metrics
17. from sklearn import linear_model
18. from sklearn.svm import LinearSVC
19. # 网格和随机搜索
20. import scipy.stats as st
21. from scipy.stats import randint as sp_randint
22. from sklearn.model_selection import GridSearchCV
23. from sklearn.model_selection import RandomizedSearchCV
24. # 指标
25. from sklearn.metrics import precision_recall_fscore_support, roc_curve, auc
26. # 警告管理
27. import warnings
28. from matplotlib.font_manager import FontProperties
29. from imblearn.over_sampling import SMOTE,ADASYN,SVMSMOTE
30. # 机器学习
31. from sklearn.model_selection import train_test_split
32. from imblearn.over_sampling import RandomOverSampler
33.
34. #1.加载数据
35. data = pd.read_csv('D:\Pycharm\pyside2\数据挖掘\python数据挖掘\信用卡\Credit_card.csv')
36. # 定义目标变量和特征
37. y = data['Label']
38. X = data.drop(['Label'], axis=1)
39. # 确定分类变量和数值变量
40. categorical_cols = [cname for cname in X.columns if X[cname].dtype == "object"]
41. numerical_cols = [cname for cname in X.columns if X[cname].dtype in ['int64', 'float64']]
42. # 查看数据的前几行
43. print(data.head())
44. sns.set(style="whitegrid")
45. myfont = FontProperties(fname='C:/Windows/Fonts/simhei.ttf', size=14) # 定义字体属性
46. sns.set(font=myfont.get_name())
47. # 1分析性别对信用卡申请的影响
48. plt.figure(figsize=(8, 6))
49. sns.countplot(x='GENDER', hue='Label', data=data)
50. plt.title('根据性别划分的信用卡审批分布', fontproperties=myfont)
51. plt.xlabel('性别', fontproperties=myfont)
52. plt.ylabel('数量', fontproperties=myfont)
53. plt.show()
54.
55. # 2分析年龄与信用卡申请结果的关系
56. plt.figure(figsize=(8, 6))
57. sns.boxplot(x='Label', y='Birthday_count', data=data)
58. plt.title('年龄与信用卡审批状态的分布', fontproperties=myfont)
59. plt.xlabel('审批状态', fontproperties=myfont)
60. plt.ylabel('年龄', fontproperties=myfont)
61. plt.show()
62.
63. # 3. 婚姻状况与信用卡申请结果的关系
64. plt.figure(figsize=(10, 6))
65. sns.countplot(x='Marital_status', hue='Label', data=data, palette='viridis')
66. plt.title('根据婚姻状况划分的信用卡审批分布', fontsize=15)
67. plt.xlabel('婚姻状况', fontsize=12)
68. plt.ylabel('数量', fontsize=12)
69. plt.legend(title='审批结果', labels=['未通过', '通过'])
70. plt.show()
71.
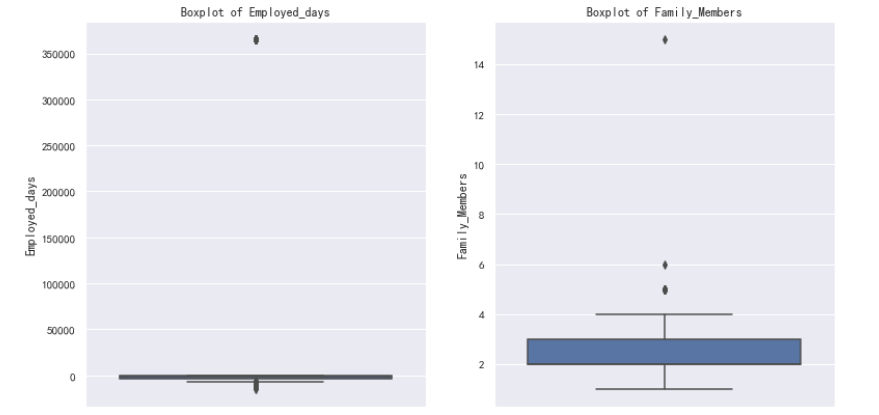
72. #绘制箱线图来观察'Annual_income','CHILDREN','Birthday_count','Employed_days','Family_Members'是否存在异常值
73. columns = ['Annual_income','CHILDREN','Birthday_count','Employed_days','Family_Members']
74. plt.figure(figsize=(20,15))
75. for i,col in enumerate(columns,1):
76. plt.subplot(2,3,i)
77. sns.boxplot(y=data[col])
78. plt.title(f'Boxplot of {col}')
79.
80. import matplotlib.pyplot as plt
81. import seaborn as sns
82.
83. # 设置可视化风格
84. sns.set(style="whitegrid")
85.
86. # 定义字体属性
87. myfont = FontProperties(fname='C:/Windows/Fonts/simhei.ttf', size=14)
88. sns.set(font=myfont.get_name())
89.
90. # 1. 收入与信用卡申请结果的关系
91. plt.figure(figsize=(8, 6))
92. sns.boxplot(x='Label', y='Annual_income', data=data)
93. plt.title('收入与信用卡审批状态的分布', fontsize=15)
94. plt.xlabel('审批状态', fontsize=12)
95. plt.ylabel('收入', fontsize=12)
96. plt.xticks(ticks=[0,1], labels=['未通过', '通过'])
97. plt.show()
98.
99. # 2. 教育水平与信用卡申请结果的关系
100. plt.figure(figsize=(10, 6))
101. sns.countplot(x='EDUCATION',hue='Label', data=data, palette='viridis')
102. plt.title('根据教育程度划分的信用卡审批分布', fontsize=15)
103. plt.xlabel('教育程度', fontsize=12)
104. plt.ylabel('数量', fontsize=12)
105. plt.legend(title='审批结果', labels=['未通过', '通过'])
106. plt.xticks(rotation=45)
107. plt.show()
108.
109. # 3. 职业类型与信用卡申请结果的关系
110. plt.figure(figsize=(10, 6))
111. sns.countplot(x='Type_Occupation', hue='Label', data=data, palette='viridis')
112. plt.title('根据职业类型划分的信用卡审批分布', fontsize=15)
113. plt.xlabel('职业类型', fontsize=12)
114. plt.ylabel('数量', fontsize=12)
115. plt.legend(title='审批结果', labels=['未通过', '通过'])
116. plt.xticks(rotation=45)
117. plt.show()
118.
119. import matplotlib.pyplot as plt
120. import seaborn as sns
121.
122. # 设置可视化风格
123. sns.set(style="whitegrid")
124.
125. # 定义字体属性
126. myfont = FontProperties(fname='C:/Windows/Fonts/simhei.ttf', size=14)
127. sns.set(font=myfont.get_name())
128.
129. # 1. 收入与信用卡申请结果的关系
130. plt.figure(figsize=(8, 6))
131. sns.boxplot(x='Label', y='Annual_income', data=data)
132. plt.title('收入与信用卡审批状态的分布', fontsize=15)
133. plt.xlabel('审批状态', fontsize=12)
134. plt.ylabel('收入', fontsize=12)
135. plt.xticks(ticks=[0,1], labels=['未通过', '通过'])
136. plt.show()
137.
138. # 2. 教育水平与信用卡申请结果的关系
139. plt.figure(figsize=(10, 6))
140. sns.countplot(x='EDUCATION',hue='Label', data=data, palette='viridis')
141. plt.title('根据教育程度划分的信用卡审批分布', fontsize=15)
142. plt.xlabel('教育程度', fontsize=12)
143. plt.ylabel('数量', fontsize=12)
144. plt.legend(title='审批结果', labels=['未通过', '通过'])
145. plt.xticks(rotation=45)
146. plt.show()
147.
148. # 3. 职业类型与信用卡申请结果的关系
149. plt.figure(figsize=(10, 6))
150. sns.countplot(x='Type_Occupation', hue='Label', data=data, palette='viridis')
151. plt.title('根据职业类型划分的信用卡审批分布', fontsize=15)
152. plt.xlabel('职业类型', fontsize=12)
153. plt.ylabel('数量', fontsize=12)
154. plt.legend(title='审批结果', labels=['未通过', '通过'])
155. plt.xticks(rotation=45)
156. plt.show()
157.
158. # 设置可视化风格
159. sns.set(style="whitegrid")
160.
161. # 定义字体属性
162. myfont = FontProperties(fname='C:/Windows/Fonts/simhei.ttf', size=14)
163. sns.set(font=myfont.get_name())
164.
165. # 绘制被拒绝申请的年收入和年龄分布图
166. plt.figure(figsize=(15, 5))
167.
168. # 年收入分布图
169. plt.subplot(1, 2, 1)
170. # 绘制直方图
171. sns.histplot(data[data['Label'] == 0]['Annual_income'], kde=False, bins=30, ).set(title='年收入分布图(被拒绝申请)')
172. plt.xlabel('年收入')
173. plt.ylabel('频数')
174.
175. # 年龄分布图
176. plt.subplot(1, 2, 2)
177. # 绘制直方图
178. sns.histplot(data[data['Label'] == 0]['Age'], kde=False, bins=30).set(title='年龄分布图(被拒绝申请)')
179. plt.xlabel('年龄')
180. plt.ylabel('频数')
181.
182. # 调整布局以防止重叠
183. plt.tight_layout()
184. # 显示图表
185. plt.show()
186.
187. print(data.info()) # 查看数据信息
188. data.drop('Ind_ID',axis = 1,inplace = True) # 删除Ind_ID列
189. print(data.isnull().sum()) # 查看缺失值数量
190.
191. #1 填补空缺值
192. '''可以看到“GENDER”、“Annual_income”、“Birthday_count ”、“Type_Occupation”都存在缺失值,针对不同变量我们用不同的填充方式'''
193. # 用众数填充GENDER和Type_Occupation
194. data['GENDER'].fillna(data['GENDER'].mode()[0], inplace = True)
195. data['Type_Occupation'].fillna(data['Type_Occupation'].mode()[0], inplace = True)
196. # 2 用均值填充Annual_income和Birthday_count
197. data['Annual_income'].fillna(data['Annual_income'].mean(), inplace = True)
198. data['Birthday_count'].fillna(data['Birthday_count'].mean(), inplace = True)
199. print(data.isnull().sum())
200. #3 字符数据类型处理
201. #4 Birthday_count 可以处理成Age
202. data["Age"] = data["Birthday_count"].apply(lambda x: abs(int(x)) / 365)
203. data = data.drop("Birthday_count", axis=1)
204. #5 对分类型变量进行独热编码 (将二分类变量转换为1和0)
205. for column in ['Type_Income', 'Type_Occupation', 'Housing_type', 'Marital_status', 'EDUCATION']:
206.
207. dummies = pd.get_dummies(data[column], prefix=column).astype(bool)
208. data = pd.concat([data, dummies], axis=1)
209. data = data.drop(column, axis=1).reset_index(drop=True)
210. data['Annual_income'] = data['Annual_income'].astype('int64')
211. data['Age'] = data['Age'].astype('int64')
212.
213. def heatmap(data, method='pearson', camp='RdYlGn', figsize=(10 ,8)):
214. """
215. data: 整份数据
216. method:默认为 pearson 系数
217. camp:默认为:RdYlGn-红黄蓝;YlGnBu-黄绿蓝;Blues/Greens
218. figsize: 默认为 10,8
219. """
220. ## 消除斜对角颜色重复的色块
221. # mask = np.zeros_like(df2.corr())
222. # mask[np.tril_indices_from(mask)] = True
223. plt.figure(figsize=figsize, dpi= 80)
224. sns.heatmap(data.corr(method=method),
225. xticklabels=data.corr(method=method).columns,
226. yticklabels=data.corr(method=method).columns, cmap=camp,
227. center=0, annot=True)
228. plt.show()
229. # 对角线一半的效果:mask=mask
230. corr_matrix = data.select_dtypes(np.number).corr()
231. heatmap(corr_matrix, camp='RdYlGn')
232. '''
233. Family_Members和Children的相关性系数很高,可以考虑去除二者之一;
234. Mobile_phone只有一个取值,没有意义。家庭成员与小孩数量方面,
235. 家庭成员可能更有代表性,因此先尝试去除Children
236. '''
237. data = data.drop(['Mobile_phone','CHILDREN'],axis = 1)
238. data.to_csv("new_data.csv")
239.
240. data = pd.read_csv('new_data.csv',index_col=0)
241. X = data.drop("Label", axis=1)
242. y = data["Label"]
243. y_table=list(y)
244. result = pd.value_counts(y_table)
245. result = result.to_dict()
246. print('输出类别及个数:',result)
247. # 1.数据SVMSMOTE过采样处理
248. scaler = StandardScaler()
249. X =X.loc[:,['Employed_days', 'Annual_income','Age',]]
250. svmsmote=SVMSMOTE(random_state=0)
251. X, y = svmsmote.fit_resample(X, y)
252. print('过采样后样本维度:',X.shape,y.shape)
253. # 2 数据归一化处理
254. X=scaler.fit_transform(X)
255. #3 按照8:2比例划分训练集,测试集
256. X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,stratify=y, random_state=42)
257.
258. # 定义参数网格
259. from sklearn.ensemble import RandomForestClassifier
260. from sklearn.model_selection import StratifiedKFold,cross_val_score
261. rf_param_grid = {
262.
263. 'n_estimators': [50, 100, 200],
264. 'max_features': ['auto', 'sqrt'],
265. 'max_depth': [None, 10, 20, 30],
266. 'min_samples_split': [2, 5, 10],
267. 'min_samples_leaf': [1, 2, 4]
268.
269. }
270. #定义随即森林模型
271. clf=RandomForestClassifier(random_state=0)
272.
273. # 使用 GridSearchCV 进行调参 (采用5则交叉验证训练模型)
274. kfold = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
275. model=cross_val_score(clf,X_train,y_train,cv=kfold,scoring='accuracy')
276. accuracy1=model.mean()
277. grid_search = GridSearchCV(clf, rf_param_grid, cv=kfold, verbose=2, n_jobs=-1,scoring='accuracy',)
278. grid_search.fit(X_train, y_train)
279. # 选择最佳参数组合的模型
280. best_clf = grid_search.best_estimator_
281. # 打印最佳参数
282. print("Best Parameters:")
283. print("-----------------")
284. print(grid_search.best_params_, "\n")
285.
286. from sklearn.model_selection import cross_val_score
287. from sklearn.metrics import precision_recall_fscore_support
288. from sklearn.metrics import roc_curve
289. from sklearn.metrics import auc
290. from sklearn.metrics import confusion_matrix
291. from sklearn.metrics import classification_report
292. accuracy = best_clf.score(X_test, y_test)
293.
294. print(f"随机森林模型参数优化之前的准确率: {accuracy1:.4f}\n")
295. print(f"随机森林模型参数优化之后的准确率: {accuracy:.4f}\n")
296. y_pred = best_clf.predict(X_test)
297. class_report = classification_report(y_test, y_pred)
298. print(class_report)
299. # #绘制混淆矩阵
300. cm = confusion_matrix(y_test, y_pred)
301. plt.figure(figsize=(8, 6))
302. sns.heatmap(cm,
303. annot=True, fmt='g', cmap='Blues',
304. xticklabels=['Predicted 0', 'Predicted 1'],
305. yticklabels=['Actual 0', 'Actual 1'])
306. plt.title('Confusion Matrix for Logistic Regression Model')
307. plt.show()
308. #
309. # #绘制ROC取消
310. fpr, tpr, _ = roc_curve(y_test, best_clf.predict_proba(X_test)[:, 1])
311. roc_auc = auc(fpr, tpr)
312.
313. plt.figure(figsize=(8, 6))
314. plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
315. plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
316. plt.xlabel('False Positive Rate')
317. plt.ylabel('True Positive Rate')
318. plt.title('Receiver Operating Characteristic (ROC) Curve')
319. plt.legend(loc="lower right")
320. plt.show()总结:
通过对信用卡风险评估大数据的分析和挖掘,我可以得到以下有益的结论:消费习惯和还款能力是评估信用卡风险的重要因素。通过对交易数据的分析,我们可以发现持卡人的消费习惯,如消费频率、消费金额、消费类型等,以及还款能力,如还款时间、还款金额等,可以对信用卡风险进行更准确的评估。持卡人的信用历史和其他信息也可以对信用卡风险产生影响。通过对持卡人的信用历史和其他信息的分析,我们可以评估持卡人的还款能力和信用风险,从而更好地控制信用卡风险。
通过此设计过程,我提高了数据分析和技术实现的能力,掌握了大数据分析的基本方法和技巧,了解了机器学习算法的应用和优化。学会了如何从数据中提取有用的信息和特征,如何构建和评估模型,如何解释和分析结果。
针对此设计过程,我建议数据清洗和预处理是数据分析的重要环节,需要更加细致和全面,确保数据的质量和准确性。模型构建和评估需要更加深入和细致,确保模型的准确性和可靠性,并且需要更加注重解释性,以便用户更好地理解和应用评估结果。在算法选择和调优方面,需要更加灵活和多样化,根据实际情况选择合适的算法,并且需要进行更多的实验和比较,以找到最优的算法和参数设置。