免模型预测
这节学习的主要是蒙特卡洛方法和时序差分法
有模型与免模型
状态转移概率是已知的,这种情况下使用算法我们称为有模型算法,而对于智能体来说环境是未知的,在该情况下使用算法,我们称之为免模型算法。在这里应该注意,除了动态规划外,其他的基础强化学习算法都是免模型的。
有模型强化学习的优点是不与真实的环境交互依然可以学习,可以节省实验成本,但是其缺点便是模型不完美,复杂到难以学习和计算,而免模型直接从与环境的交互中学习,不需要建立任何预测环境动态的模型。其优点是不需要学习可能是较为复杂的环境模型,更加简单直接,但是缺点是在学习过程中需要与真实环境进行大量的交互。
1.蒙特卡洛估计
蒙特卡洛估计方法在强化学习中是免模型预测价值函数的方式之一,本质是一种统计模拟方法
蒙特卡洛估计(Monte Carlo estimation)是一种基于随机抽样的数值估计方法,适用于在复杂问题中求解概率或数值解的问题。其基本思想是通过生成大量的随机样本,来逼近所求解问题的概率或数值解。
具体而言,蒙特卡洛估计的步骤如下:
1.定义问题:确定所要求解的问题,以及其解的形式。
2.建立模型:将所要求解的问题建立相应的数学模型,其中包括概率分布函数、密度函数等。
3.生成随机样本:使用各种随机数生成方法生成指定数量的随机样本。
4.估计概率或数值解:根据随机样本,估计所要求解问题的概率或数值解。
蒙特卡洛估计可以应用于很多领域,如金融、物理学、生物学、化学工程、计算机科学等等,对于某些复杂问题,蒙特卡洛估计是一种有效的求解方法。
2.时序差分估计
时序差分估计(temporal-difference learning)是一种增强学习的方法,也是一种启发式学习方法。它通过与目标状态的差值来更新当前状态的估计值,从而实现从历史经验中学习的目的。
时序差分估计算法大致可以分为以下几个步骤:
1.初始化:对状态值函数进行初始化。
2.选择行动:从当前状态中选择一个行动。
3.获得反馈:执行选择的行动,获得当前状态下的反馈。
4.更新状态值函数:通过对当前状态值函数的估计值和后继状态的估计值进行差分,估计当前状态的值,并将其更新到状态值函数中。
5.转换状态:将当前状态转换为下一个状态,重复上述步骤直到达到停止条件为止。
时序差分估计的优点在于,它可以在完全未知的环境中进行学习,而不需要预先制定任何规则或基础模型。由于时序差分估计具有高度的灵活性和适用性,因此被广泛应用于许多强化学习问题中,如自适应控制、机器人导航、游戏及智能体等。
3.蒙特卡洛与时序差分的比较
时序差分方法可以在线学习(online learning),每走一步就可以更新,效率高。蒙特卡洛方法必须等游戏结束时才可以学习。
时序差分方法可以从不完整序列上进行学习。蒙特卡洛方法只能从完整的序列上进行学习。
时序差分方法可以在连续的环境下(没有终止)进行学习。蒙特卡洛方法只能在有终止的情况下学习。
时序差分方法利用了马尔可夫性质,在马尔可夫环境下有更高的学习效率。蒙特卡洛方法没有假设环境具有马尔可夫性质,利用采样的价值来估计某个状态的价值,在不是马尔可夫的环境下更加有效
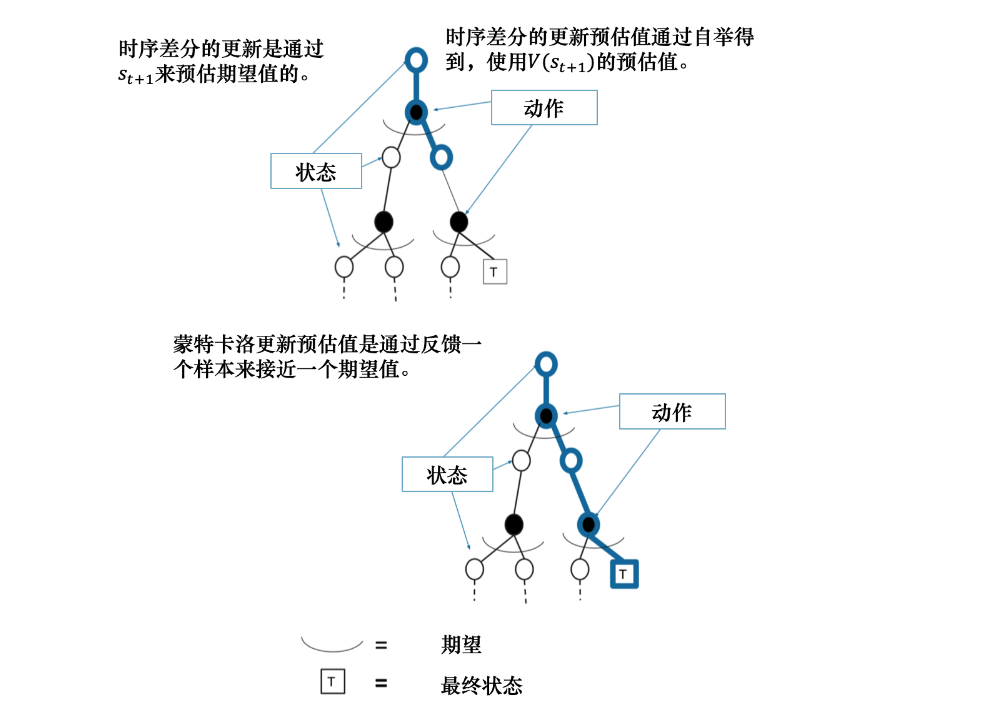
4.蒙特卡洛方法和时序差分方法的优劣势
蒙特卡洛方法和时序差分方法都是强化学习中常用的方法,它们各自具有不同的优势和劣势。
蒙特卡洛方法的优势:
- 无模型依赖:蒙特卡洛方法不需要对环境做任何假设或建模,只需要通过采样来估计值函数或策略。
- 收敛性:在有限次采样下,蒙特卡洛方法可以确保最终达到真实价值函数的估计。
- 泛化性:蒙特卡洛方法能够更好地处理状态空间较大的问题,因为它只需要通过样本计算估计值。
蒙特卡洛方法的劣势:
- 高方差:由于蒙特卡洛方法是基于采样的,估计值的方差通常较高,特别是在稀疏回报的情况下,需要采样大量的轨迹才能得到稳定的估计。
- 需要完成整个轨迹:蒙特卡洛方法需要等到整个轨迹结束才能进行更新,这对于长期任务来说会导致计算复杂度的增加。
时序差分方法的优势:
- 低方差:时序差分方法的估计值方差通常较低,因为每次更新只依赖于一个时间步的转换,而不需要等到整个轨迹结束。
- 增量更新:时序差分方法可以在每个时间步进行增量更新,效率较高,也有助于实现在线学习。
- 模型无关:时序差分方法可以学习未知的模型,对环境的要求较低。
时序差分方法的劣势:
- 收敛性:时序差分方法的收敛性较蒙特卡洛方法略差,需要采用合适的参数选择和更新策略来保证收敛。
- 依赖于初始条件:由于时序差分方法是基于行动的估计值差分来更新状态值函数,因此对初始条件和初始估计值很敏感。
综上所述,蒙特卡洛方法适用于具有较少样本、整个轨迹可获得以及对模型没有先验知识的情况,而时序差分方法适用于大规模状态空间、增量更新以及对环境模型要求较低的情况。选择哪种方法取决于具体问题的性质和需求。
免模型控制
Q学习是一种异策略(off-policy)算法。
异策略在学习的过程中,有两种不同的策略:目标策略(target policy)和行为策略(behavior policy)。
目标策略就是我们需要去学习的策略,相当于后方指挥的军师,它不需要直接与环境进行交互
行为策略是探索环境的策略,负责与环境交互,然后将采集的轨迹数据送给目标策略进行学习,而且为送给目标策略的数据中不需要a t + 1 a_{t+1}a
t+1,而Sarsa是要有a t + 1 a_{t+1}a t+1的。
Q学习不会管我们下一步去往哪里探索,它只选取奖励最大的策略
接下来我们利用自己的Python环境进行简单的算法实现
在简单的了解了Q-learing算法之后,我们便着手实现悬崖行走问题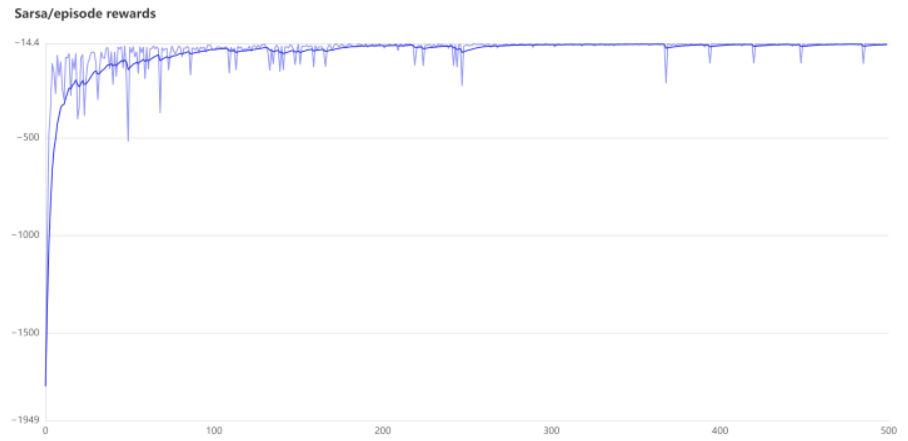
最后实现了这个效果图,不足之处便是消融实验没有做出来,后续会再次尝试