一、实验目的
熟悉循环神经网络在文本分析和分类上的应用
二、实验原理或实验内容
从keras的数据集中加载影评数据,注意需要填充(截断)数据,并转成数组的形式。
构建一个神经网络模型,要求使用词嵌入和循环层,并使用划分好的训练集数据训练模型,使用划分好的测试集的数据验证模型,训练迭代20次。
获取训练过程中的训练精度、验证精度,并使用matplotlib来绘制精度变化曲线,要求模型的验证精度达到85%以上(注意不是训练精度)。
写实验报告,将实验代码和绘制精度变化曲线截图粘贴到实验报告中。
三、实验器材及实验条件
windows11
jupyter notebook
四、实验步骤与结果
1、导入相关库
from keras.preprocessing.sequence import data_utils
from keras.datasets import imdb
from keras.models import Sequential
from keras.layers import Embedding,LSTM,Dense 2、加载数据
2、加载数据
maxlen=500
feature_num=10000
(train_x,train_y),(test_x,test_y)=imdb.load_data(num_words=feature_num)
train_x=data_utils.pad_sequences(train_x,maxlen=maxlen)
test_x=data_utils.pad_sequences(test_x,maxlen=maxlen)
3、构建模型
model=Sequential()
model.add(Embedding(feature_num,32,input_length=maxlen))
model.add(LSTM(32))
model.add(Dense(1,activation='sigmoid'))
model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['acc'])
model.summary()
4、编译模型
# 编译模型
model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['acc'])
model.summary()
5、训练模型
history = model.fit(
train_dataset,epochs=30,validation_data=validation_dataset,steps_per_epoch=100,val idation_steps=50)
6、训练精度,验证精度的可视化,绘制折线图
history = model.fit(train_x,train_y,epochs=10,batch_size=128,validation_split=0.2)
predict_y=model.predict(test_x)
5、进行可视化,可视化结果
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
train_acc = history.history.get('acc')
valid_acc = history.history.get('val_acc')
data_x = range(1, len(train_acc) + 1)
plt.plot(data_x, train_acc, color='red', label='训练精度')
plt.plot(data_x, valid_acc, color='green', label='验证精度')
plt.legend()
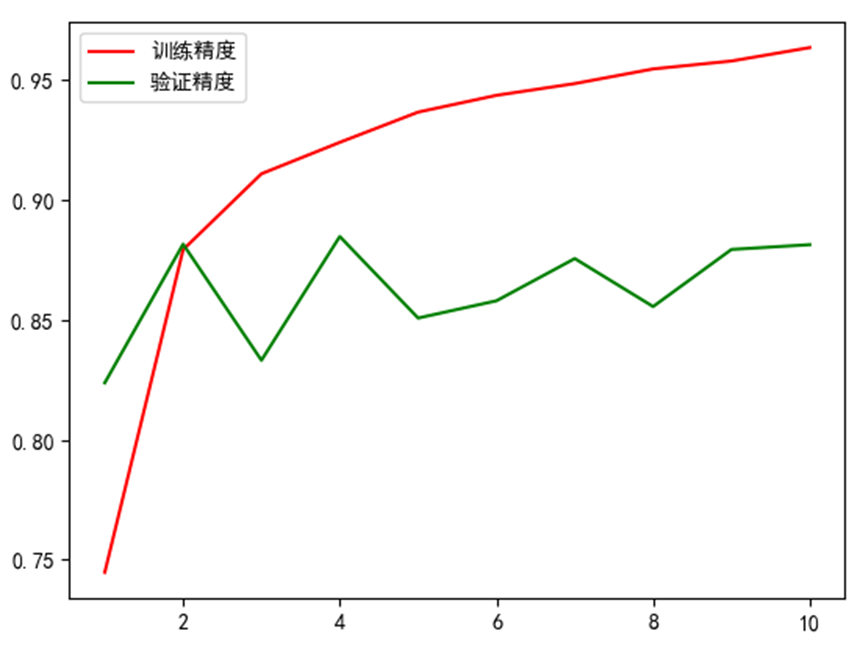
五、 实验分析与结论
总体而言,使用RNN训练的处理IMDB影评分类的神经网络,在最终精确度上并不比密集连接层高多少,可能的原因如下:
l 训练RNN使用的数据较少,500个时间步之后就截断了序列,而Dense层模型则读取了整个序列
l 没有精细地调用LSTM的超参数,如嵌入维度、输出维度等
l 缺少正则化,可能会过拟合
l 对于情感分析问题,LSTM并不是最擅长的。对于这样的基本问题,观察每条评论中出现了哪些词以及它们出现的频率就可以很好地解决
l 对于更加困难的自然语言理解问题,如问答和机器翻译等,LSTM应该会表现更突出