PCL: Proxy-based Contrastive Learning for Domain Generalization
abstract
领域泛化是指从不同源领域的集合中训练模型,该模型可以直接泛化到未见过的目标领域的问题。一种有前途的解决方案是对比学习,它试图通过利用不同领域之间的样本对之间的丰富语义关系来学习领域不变表示。一种简单的方法是将来自不同领域的正样本对拉近,同时将其他负样本对推远。在本文中,我们发现直接应用基于对比的方法(例如,监督对比学习)在领域泛化中并不有效。我们认为,由于不同领域之间存在显著的分布差异,对齐正样本对往往会妨碍模型的泛化。为解决这个问题,我们提出了一种新颖的基于代理的对比学习方法,它用代理-样本之间的关系代替了原始的样本-样本关系,显著减轻了正向对齐问题。在四个标准基准上的实验证明了所提出方法的有效性。此外,我们还考虑了一个更复杂的情景,即没有提供ImageNet预训练模型。我们的方法始终表现出更好的性能。
Introduction
在本文中,我们发现一些传统的对比方法(例如,监督对比学习)在领域泛化中并不有效。一个潜在的原因是复杂的正样本对之间的关系妨碍了模型的泛化。在对比损失中,太容易或太难的样本对都会妨碍模型性能。如图1所示,在监督对比学习设置中,我们从不同领域中采样正样本对。然而,由于领域差距较大,一些正样本对很难对齐,这降低了模型的泛化性能。
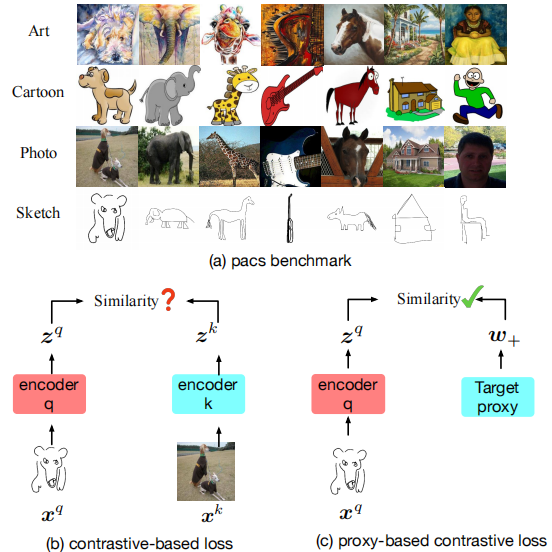
图1。 (a) PACS数据集是一个典型的领域泛化基准,包含四个领域:艺术、卡通、照片和素描,每个领域有七个类别。领域泛化任务旨在从多源域(例如艺术、照片、素描)训练模型,并在目标域(例如卡通)上进行测试。在训练阶段,无法访问目标数据集。 (b) 典型的对比损失(例如,监督对比损失)利用样本对之间的关系,其中来自同一类的不同领域样本可以被视为正样本对。我们认为,优化一些难以对齐的正样本对可能会恶化模型的泛化性能。我们称之为正向对齐问题。 (c) 基于我们的观察,我们提出了一种基于代理的对比损失。通过用代理-样本关系替代样本-样本关系,我们在很大程度上减轻了正向对齐问题。
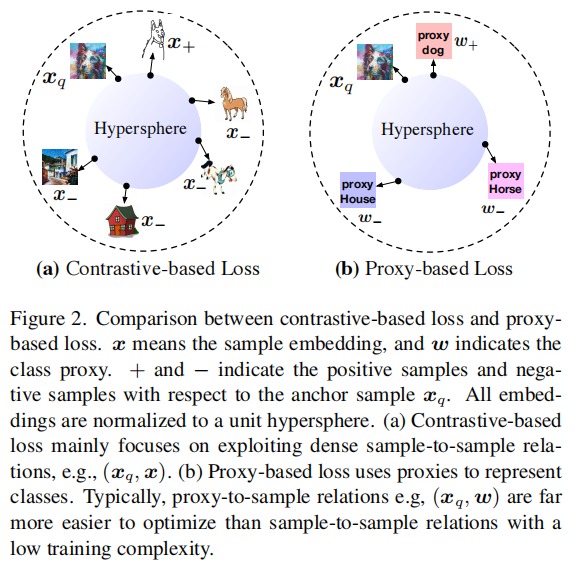
我们尝试从代理的角度解决这个问题。代理可以被视为子数据集的代表,理想情况下更能抵御噪声样本或异常值。标准的代理方法是softmax CE loss(即softmax交叉熵损失),其中代理用于表示类别。对比方法和基于代理的方法之间的主要区别在于关系构建。如图2所示,对比损失主要关注探索丰富的样本对之间的关系,而基于代理的损失使用代理来表示子训练集,实现了安全且快速的收敛,但遗漏了一些语义关系。这激发了我们设计一个基于代理的损失,汲取了对比学习的一些优点。我们将每个代理视为锚点,并考虑所有代理-样本关系。为了防止模型陷入一些微不足道的解决方案,我们在样本嵌入和代理权重上都对齐了投影头,并使用新的嵌入和新的代理权重进行基于代理的对比损失。
我们的贡献如下:
- 我们从对比学习的正向对齐问题中实证揭示了模型泛化的退化。
- 我们为领域泛化提出了一种新颖的基于代理的对比学习技术。所提出的技术相当简单但有效。
- 所提出的算法在多个标准基准上实现了最先进的准确性,并在更复杂的情景中,即没有提供ImageNet预训练模型的情况下,始终提高了模型性能。
3. Method
3.2. Problem Formulation
领域泛化旨在通过利用多个源领域来训练一个能够推广到未见目标领域的模型。源领域和目标领域\(\mathcal{D}=\left\{D_1, D_2, \ldots D_K\right\}\)共享一个公共标签空间。在每个领域中,样本是从数据集\(D_k=\left\{\left(x_i^k, y_i^k\right)\right\}_{i=1}^{N_t}\)中抽取的,其中\(N_t\)是领域\(D_k\)中标记样本的数量。我们的目标是从一组源数据集中学习一个泛化性能良好的模型\(G\),在目标数据上表现出色。我们考虑一个由特征提取器组成的物体识别模型,\(F_\theta:\mathcal{X} \rightarrow \mathcal{Z}\),其中\(\mathcal{Z}\)是特征嵌入空间,以及分类器\(G_\psi:\mathcal{Z} \rightarrow \mathbb{R}^C\),其中\(C\)表示标签空间中的类别数。
3.5. Proxy-based Contrastive Learning
Softmax 损失在学习类别代理方面效率高,实现了快速且安全的收敛,但不考虑样本与样本之间的关系。基于对比的损失利用了丰富的样本与样本之间的关系,但受到了优化密集的样本与样本之间关系的高训练复杂性的影响。因此,一些复杂的关系可能会妨碍性能。设计一种新的损失函数,充分利用 softmax 交叉熵损失和基于对比的损失并不是一件平凡的事情。
对于每个样本 \(\boldsymbol{x}_i\),我们将其与小批量中的所有样本相关联,忽略正样本对,只考虑负样本对。另一方面,我们使用目标类别代理来与样本形成正样本对。基于代理的对比损失可以表示为:
其中 \(Z\) 由以下给出:
这里 \(N\) 是一个小批量中的样本数,\(\boldsymbol{w}_c\) 表示 \(\boldsymbol{x}_i\) 的目标类别代理权重,\(C\) 是类别数,\(K\) 是所有 \(\boldsymbol{x}_i\)-基于样本对之间的负样本对数量。样本嵌入即 \(\boldsymbol{z}\) 和代理权重即 \(\boldsymbol{w}\) 都已标准化。\(\alpha\) 是缩放因子。
Projection Head.
我们进一步考虑应用投影头来处理样本嵌入(即 \(\boldsymbol{z}\)),和代理权重(即 \(\boldsymbol{w}\)),灵感来自于 [10]。投影头是一个小型网络,将嵌入映射到应用代理的对比损失的空间。我们使用一个三层 MLP \(h(\cdot)\) 作为样本嵌入的投影头,以及一个单层 MLP \(g(\cdot)\) 作为代理权重的投影头。因此,新的嵌入和代理权重可以表示为 \(\boldsymbol{e}_i=h\left(\boldsymbol{z}_i\right)\) 和 \(\boldsymbol{v}_i=g\left(\boldsymbol{w}_i\right)\)。应用投影头的动机并不平凡。由于基于代理的方法容易收敛,得分函数的输出往往是一个稀疏矩阵,没有足够的强度来推动代理,即 \(\boldsymbol{w}\) 和样本嵌入 \(\boldsymbol{z}\) 来探索更多的语义特征。投影头可以将代理权重和样本嵌入都映射到另一个空间。然后应用基于代理的对比损失,这比 softmax 损失更难收敛。然后通过反向传播,代理权重和样本嵌入都可以学习更有意义的特征。
In-domain negative pair generation and domain sampling strategy.
我们还考虑了领域内负样本生成。如前面的子节所讨论的,困难对在对比学习中发挥着重要作用。在实践中,一些由不同领域形成的负样本仅包含贡献很小的小值,对优化几乎没有贡献。因此,我们只考虑领域内的负样本。然后我们有:
其中 \(E\) 由下式给出:
样本嵌入 \(\boldsymbol{z}\) 和代理权重 \(\boldsymbol{w}\) 都经过了投影头,并产生了新的样本嵌入 \(e\) 和新的代理权重 \(\boldsymbol{v}\)。所有部分与前面的方程相同,只是考虑了在相同领域内的样本对的负样本。为了平衡负样本的生成,我们还采取了平衡的领域采样策略。在每个训练迭代中,我们从每个源领域中采样相同数量的样本,这意味着在每个小批次的训练迭代中:
Whole structure.
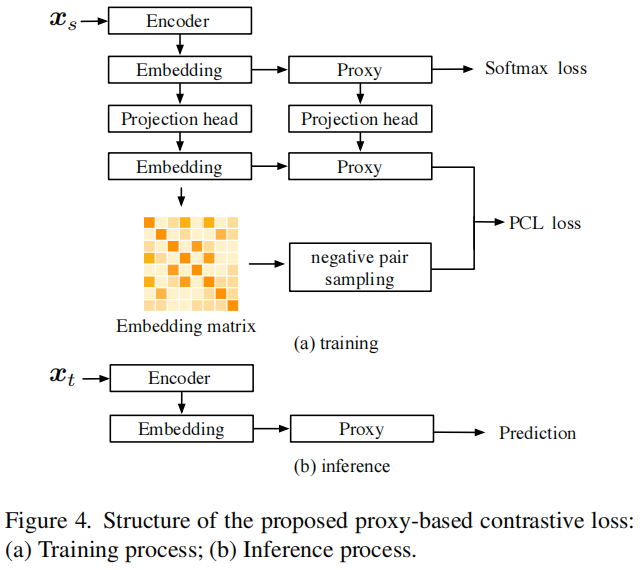
整体结构如图4所示。在训练阶段,我们为样本嵌入和代理权重分别对齐不同的投影头。然后,我们只从嵌入矩阵中选择负样本对来构建与代理权重相结合的基于代理的对比损失。最终的损失由以下方式给出:
其中,\(\mathcal{L}_\text{CE}\) 简单地是一个softmax CE损失。在推理阶段,我们只使用原始的样本嵌入和代理进行预测,而不引入额外的参数。
4. Experimental Results
在本节中,我们首先展示了我们在第3节中介绍的正对齐实验的详细内容。然后,我们在四个标准的领域泛化数据集PACS [27]、Office-Home [55]、DomainNet [39]和TerraIncognita [5]上评估了提出的基于代理的对比损失。在实际应用中,我们使用了方程(7)中介绍的损失,这意味着我们只使用在同一领域生成的负样本对。我们的工作是基于SWAD [8]构建的。为了公平比较,我们遵循相同的训练和评估协议,包括数据划分、超参数搜索和模型选择。我们报告了每个领域的领域外准确性。我们还在非预训练模型设置下对我们的方法进行了标准的领域泛化基准测试。关于结果分析、消融研究、实施细节的更多细节将在接下来的章节中讨论。
4.1. Details of the Positive Alignment experiments
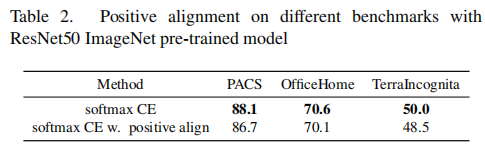
从表2中,我们可以观察到正向对齐目标对不同基准数据集上的模型泛化性能并不有效。
4.2. Datasets
- PACS 包含总共 9991 张图像和 4 个领域:照片、艺术绘画、卡通和素描。
- DomainNet 最近由 [39] 提出,包含近 60 万张图像,分布在 6 个领域中 - 绘画、速写、真实、剪贴画、素描和信息图。
- Office-Home 是一个用于领域泛化评估的常用基准,包括四个风格迥异的领域:艺术、剪贴画、产品和真实世界,每个领域包含约 15,500 张图像的 65 个对象类别。
- TerraIncognita 包含 24788 张图像,10 个类别和 4 个领域。
4.4. Results and Discussion
Results on the Domain Generalization benchmarks
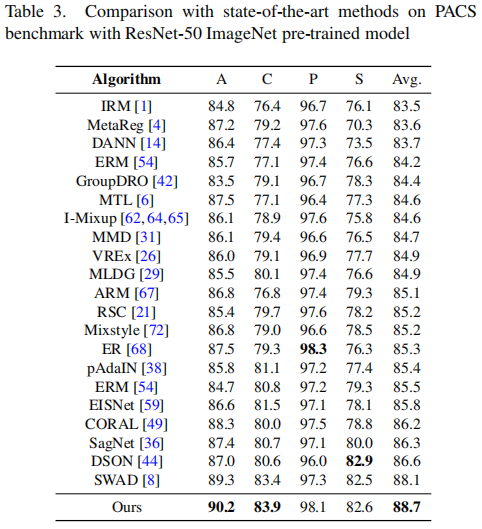
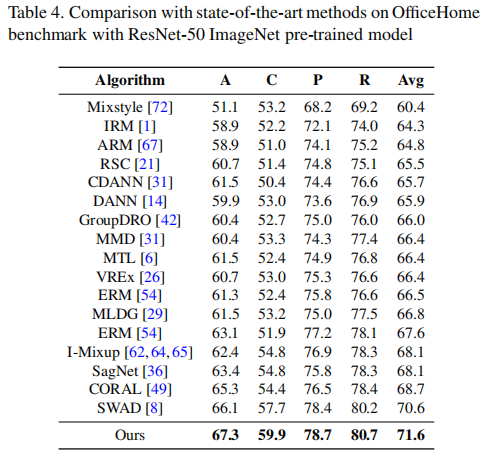
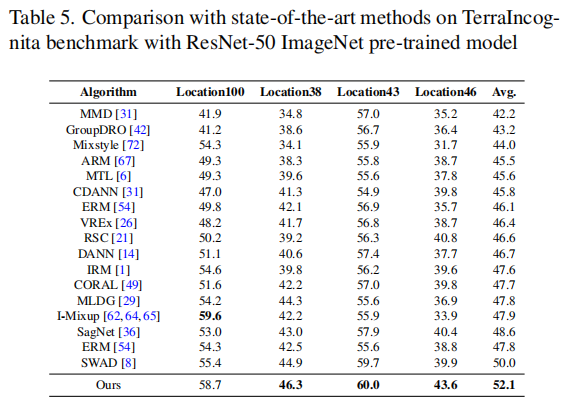
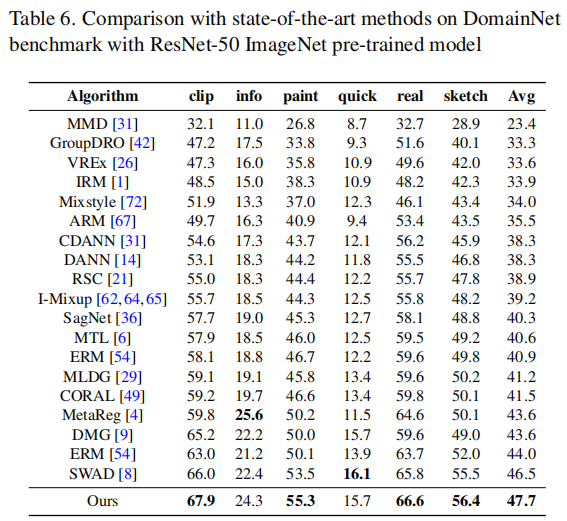
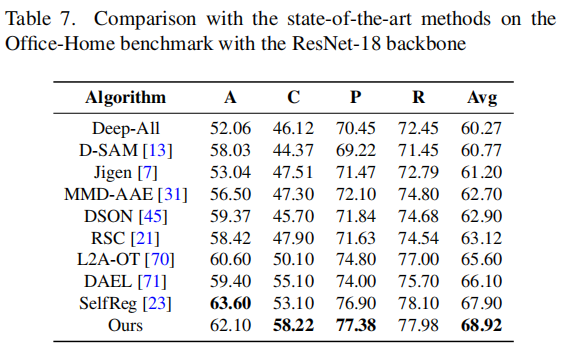
首先,我们将PCL与最先进的方法SWAD进行比较。如表3至表7所示,我们的方法在四个基准测试中(OfficeHome、PACS、TerraIncognita和DomainNet)均优于SWAD。首先,我们的结果优于一些传统的领域泛化方法,如ERM、IRM和MMD。其次,我们的方法也胜过了一些经典的数据增强方法,如Mixup和Jigen的变种。第三,我们的性能也超越了一些集成学习方法,如DAEL和DSON。我们还将我们的方法与最先进的对比学习算法,如EISNet和SelfReg进行了比较,这证明了我们方法的有效性。请注意,我们遵循与SWAD相同的数据分割策略,将数据分为训练集(60%)、测试集(20%)和验证集(20%)。在表7中,我们采用了与SelfReg相同的数据拆分策略。
Comparison with state-of-the-art methods without ImageNet pre-trained.
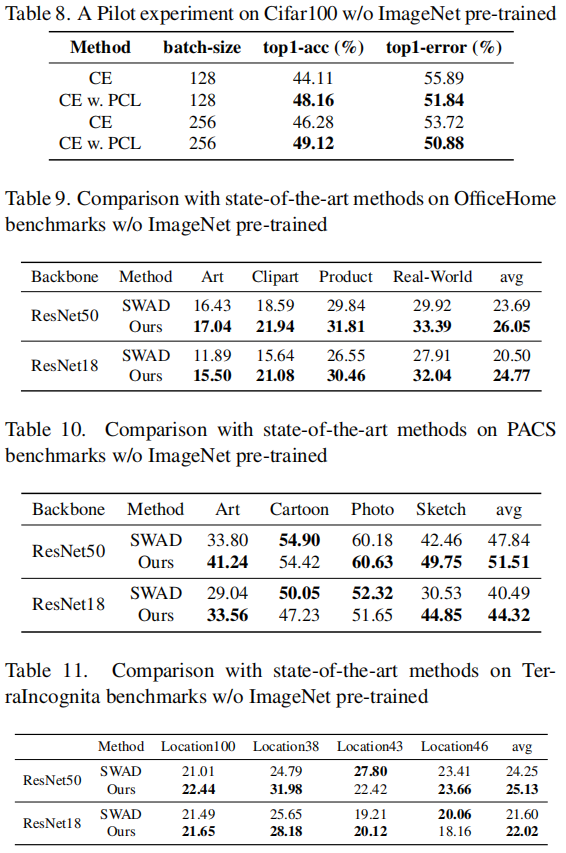
我们还想验证我们的方法在没有ImageNet预训练的情况下的有效性。
我们首先在包含60000个100个类别的32x32图像的小数据集cifar100上验证我们的方法,每个类别有600张图像。我们使用一个简单的AlexNet [25],只有一个线性层。初始化学习率设置为0.1,采用分步衰减调度。
如表8所示,我们使用softmax CE loss作为基准。我们注意到我们的方法可以稳定地超越softmax CE loss。
我们进一步考虑了没有ImageNet预训练的模型泛化在标准的DG基准上的性能。我们在三个标准DG基准上使用SWAD性能:OfficeHome,PACS和TerraIncognita。我们评估了两个骨干i.e., ResNet50和ResNet18。如表9至表11所示,我们的方法在ResNet18和ResNet50骨干上均超越SWAD,证明了我们方法的有效性。
Ablation study on proxy-based and contrastive-based methods.
为了证明提出的基于代理对的损失的有效性,我们将其与其他经典的基于代理的损失进行比较,如softmax CE Loss和proxyanchor loss [24]。我们还将我们提出的损失函数与有监督对比损失(有监督CL)[22]进行比较。
如表12所示,我们可以发现我们的方法超越了基于代理的方法和基于对比的方法。特别是,我们可以发现在小型网络中,有监督CL损失甚至没有超越基线的softmax CE损失。

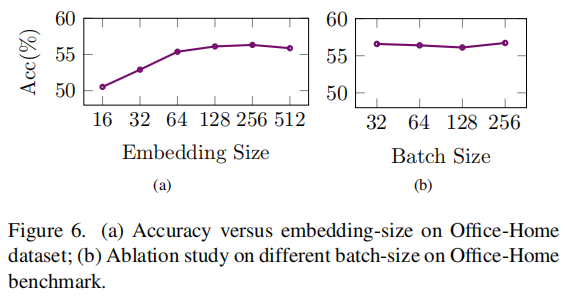
Ablation study on embedding size.
关于嵌入大小的消融研究。我们在Office-Home基准测试中进行了有关源领域为art, product 和 real-world,目标领域为 clipart 的消融研究。
我们可以发现随着嵌入大小的增加,模型具备了更多容量,因此获得了更好的结果。然而,当嵌入大小足够大时(例如128),性能在某种程度上会下降。另一方面,我们可以发现我们的方法对于嵌入大小仍然很稳健,即使使用小的嵌入大小,比如16,模型仍然可以获得可比较的结果。
Ablation study on batch-size.
关于批次大小的消融研究。批次大小是对比损失中的一个重要指标,因为它控制了样本对的数量。
我们可以观察到模型对批次大小是稳定的,这超出了我们的预期,因为较大的批次大小可以生成更多的样本对。另一方面,即使使用小的批次大小,比如32,我们的模型对批次大小也是稳健的。
Effectiveness of negative hard pair selection.
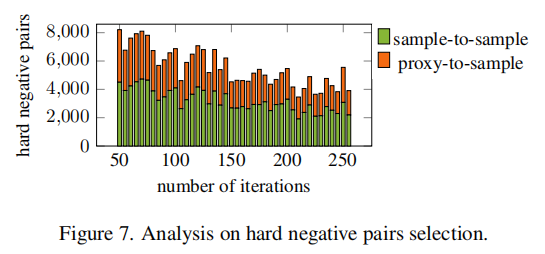
在我们的方法中,困难负样本对的采样起着关键作用,因此我们还在OfficeHome基准上进行了统计分析。我们将困难负样本对定义为其相似度分数大于最小正对的相似度分数的边界 \(s_n+m \leq min(s_p)\),在这项工作中,我们将 \(m\) 设置为0.35。
如图7所示,sample-to-sample 表示从sample-to-sample pairs中选择的困难负样本对的数量,例如 \((x_i,x_{\_})\)。proxy-to-sample 表示从proxy-to-sample pairs中采样的困难负样本对的数量,例如 \((w_{\_},x_j)\) 。我们可以发现,无论是 sample-to-sample pairs 还是 proxy-to-sample pairs 都对困难负样本对产生了稳定的贡献,而难hard sample-to-sample pairs 的数量远大于hard proxy-to-sample pairs的数量。在训练过程中,hard negative 的样本的总数会减小,这意味着网络具有更好的特征提取能力。
- Generalization Contrastive Proxy-based Learning Domaingeneralization contrastive proxy-based learning generalization contrastive proxy-based pcl domain domain-invariant generalization exploration generalization generalizing domains domain domain unsupervised adversarial contrastive domain unsupervised contrastive adaptation contrastive embeddings learning sentence probabilistic contrastive adaptation learning recommendation contrastive adaptive learning contrastive supervised detection learning