ChatGPT已经成为家喻户晓的名字,而大语言模型在ChatGPT刺激下也得到了快速发展,这使得我们可以基于这些技术来改进我们的业务。
但是大语言模型像所有机器/深度学习模型一样,从数据中学习。因此也会有garbage in garbage out的规则。也就是说如果我们在低质量的数据上训练模型,那么在推理时输出的质量也会同样低。
这就是为什么在与LLM的对话中,会出现带有偏见(或幻觉)的回答的主要原因。
有一些技术允许我们对这些模型的输出有更多的控制,以确保LLM的一致性,这样模型的响应不仅准确和一致,而且从开发人员和用户的角度来看是安全的、合乎道德的和可取的。目前最常用的技术是RLHF.
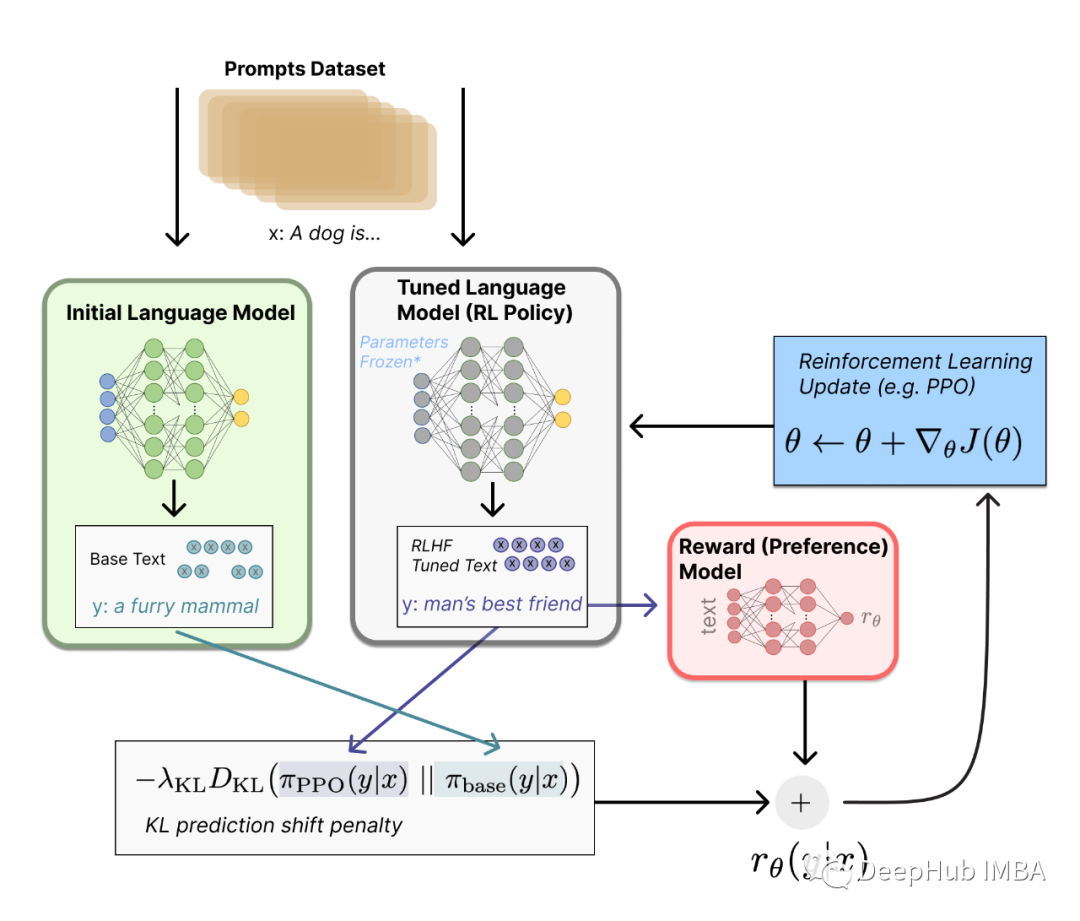
基于人类反馈的强化学习(RLHF)最近引起了人们的广泛关注,它将强化学习技术在自然语言处理领域的应用方面掀起了一场新的革命,尤其是在大型语言模型(llm)领域。在本文中,我们将使用Huggingface来进行完整的RLHF训练。
RLHF由以下阶段组成:
特定领域的预训练:微调预训练的型语言模型与因果语言建模目标的原始文本。
监督微调:针对特定任务和特定领域(提示/指令、响应)对特定领域的LLM进行微调。
RLHF奖励模型训练:训练语言模型将反应分类为好或坏(赞或不赞)
RLHF微调:使用奖励模型训练由人类专家标记的(prompt, good_response, bad_response)数据,以对齐LLM上的响应
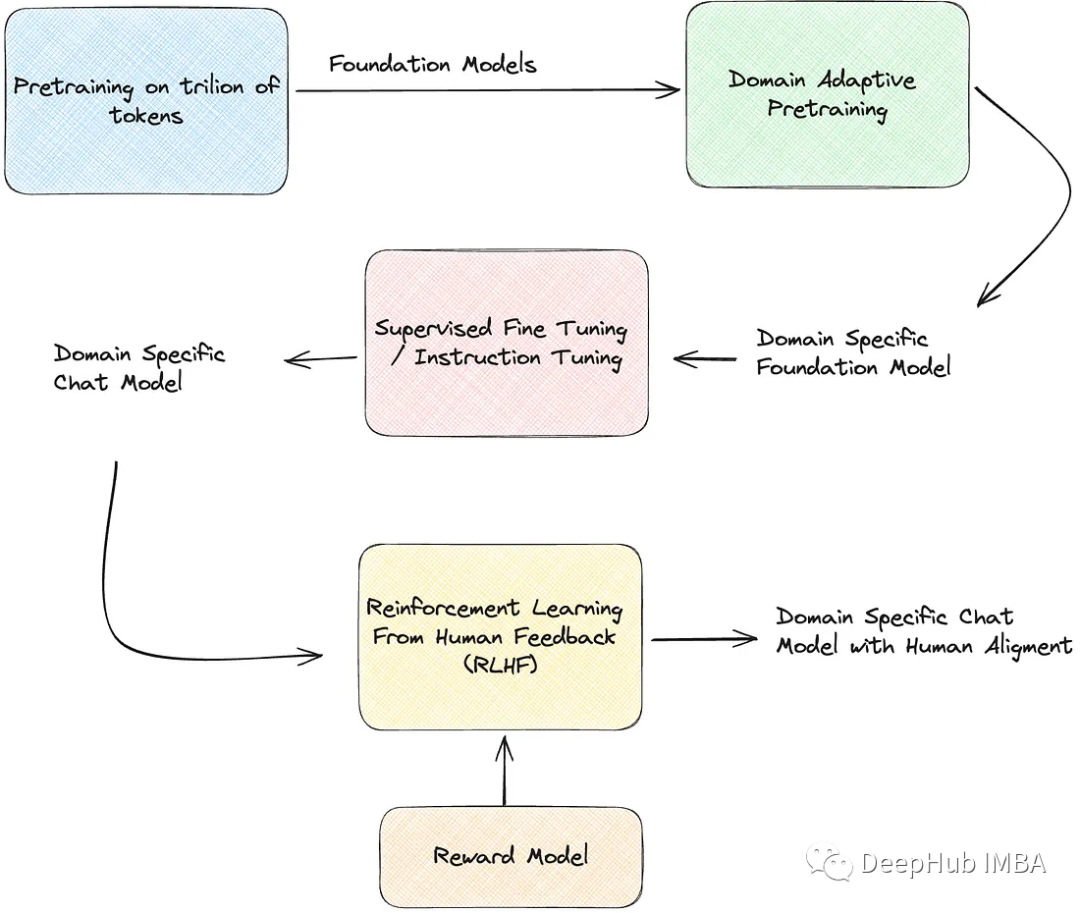
下面我们开始逐一介绍
https://avoid.overfit.cn/post/d87b9d5e8d0748578ffac81fbd8a4bc6