本文系原创,转载请说明出处
Please Subscribe Wechat Official Account:信安科研人,获取更多的原创安全资讯
原论文:《The Progress, Challenges, and Perspectives of Directed Greybox Fuzzing》
一 提问
阅读全文,回答以下几个问题:
Q1、什么是模糊测试?什么又是定向模糊测试?二者之间有什么不同?
Q2、定向模糊测试有哪些应用场景?每个应用场景有哪些代表工具?这些不同场景下的定向模糊测试技术有无差异?
Q3、研究进展:定向模糊测试技术发展的怎么样了?有哪些技术流派(分类)?每类流派有哪些技术?
Q4、这些技术有什么缺陷?可以通过哪些方法弥补这些缺陷?
Q5、定向模糊测试未来的研究方向?
Q6、.....................?
这我自己提的问题,原文的研究问题是这样的:

![]()
二 回答
2.1 Q1 什么是模糊测试?什么又是定向模糊测试?二者之间有什么关系有什么不同?
模糊测试技术:模糊测试是一种自动化的测试技术,它通过向目标程序或系统输入随机、无效或异常数据,以触发潜在的漏洞或异常行为。
假定你的测试目标是桥梁的稳定性,测试对象是桥梁,通过向桥梁输入随机的车辆数目、车辆重量等,观察桥梁有没有断裂,从而测试桥梁是否具备一定程度的稳定性
模糊测试方法可以大致分为黑盒、白盒、灰盒这三种,本文主要讲灰盒,既不像白盒一样了解完全的细节,也不像黑盒一样完全不了解,即了解源代码的部分细节如源代码架构、源代码部分区域的语义等信息
定向模糊测试(灰盒,缩写为DGF):在灰盒模糊测试的基础上,将更多的计算资源放在到达特定目标上,如探测源代码是否存在UAF漏洞。
不同之处:在于“Directed 定向”,传统灰盒模糊测试更注重提高测试代码的覆盖率,即更全面,而DGF更倾向于测试指定区域,更局部。
定向模糊测试的主要框架:
首先,通过各类方法如静态程序分析、基于知识等方法,确认被测试的程序可能存在问题的区域;然后,在模糊测试过程中,结合这些信息,生成测试用例,输入到被测程序来判断是否存在此漏洞。
![]()
2.2 Q2、定向模糊测试有哪些应用场景?每个应用场景有哪些代表工具?这些不同场景下的定向模糊测试技术有无差异?
(1)补丁测试
应用需求:工程师会用补丁来修复bug,但这个补丁可能只修复了一部分而其他部分的漏洞依然存在,甚至这所修的部分能引起其他的漏洞。DGF则可以用来测试这个补丁是否完整(是否完全修复)且兼容(是否会引起其他bug)。
代表工作or工具:
- DeltaFuzz
- AFLChurn
- SemFuzz
- 1dvul
(2)bug复现
应用需求:很多安全研究员都有复现bug的需求,但并不是所有的bug发现者都会公开验证代码poc,DGF可以逐渐找到这些bug的区域,所用的测试用例就是一个可用poc
代表工作or工具:
- TortoiseFuzz
- DrillerGo
- UAFuzz
(3)特殊bug检测
应用需求:有些bug使用传统的灰盒模糊测试很难检测出来
代表工作or工具:
- 不受控制内存的漏洞发现:Memlock: Memory usage guided fuzzing
- UAF:Binary-level directed fuzzing for use-after-free vulnerabilities,Typestate-guided fuzzer for discovering use-after-free vulnerabilitie
- 算法复杂漏洞发现:Slowfuzz,Understanding and detecting performance bugs in markdown compiler
(4)结果验证
应用需求:很多基于静态程序和数据驱动的程序分析方法假阳率太高了,比如将本不是漏洞识别成是漏洞,所以这些方法只能够用来初步判断哪些区域是可能存在漏洞。然后结合DGF来验证这个bug是否是真的漏洞。
代表工作or工具:
- SUZZER
- DeFuzz
- V-Fuzz
- ParmeSan
(5)知识聚合 和 节约资源
知识聚合指DGF结合了更多的人工经验,让模糊测试少走了很多弯路去发现更多的程序路径;节约资源指的是为了达到挖掘漏洞的目的减小了资源消耗。
不同的应用场景有无技术差异?
有的,比如patch测试一般会检测打过补丁的程序和未打过补丁的程序,而检测特定类型bug的测试一般不会用这种初步分析方式
2.3 Q3、研究进展:定向模糊测试技术研究趋势?定向模糊测试技术发展到现在有哪些技术流派(分类)?每类流派有哪些技术?
2.3.1 研究趋势:
- 为了到达更多样、更深层次的区域,fuzzer的fitness metric更多样化
- 为了加快目标区域或行为的识别,基于AI的方法应运而生:用AI的方法自动化的识别潜在的目标
- 为了生成更优质的测试用例,很多方法用符号执行等分析方法构造测试用例
- 更复杂的定向算法应用(为的是寻找最优解),比如蚁群优化算法、优化模拟退火算法、粒子群算法。
- 为提高fuzzing效率,不考虑或删除到达不了目标区域的输入用例
- 检测特殊类型的bug,如复杂的算法bug、memory consumption bug(比如缓冲区溢出、内存泄漏)
2.3.2 DGF大概有哪几类技术?
技术分类标准:倾向于利用目标位置 和 倾向于利用目标行为 (可以理解为这个技术倾向于利用具体位置发现bug,还是倾向于使用目标行为发现bug)
-
倾向于利用目标位置的工具: 这种工具的主要特征是,它们旨在找到特定的目标位置,目标位置可以是代码的某个位置,如函数、基本块(basic block)或一系列有序的调用点。此类工具的评估标准是基于可见的度量标准,例如在执行跟踪、控制流图或调用图上测量的度量。总之,这种工具具有明确定义的目标位置和可视化的度量标准。
-
倾向于利用目标行为(bug)的工具: 这种工具也具有特定的适应度度量标准(fitness metric),但不同的是,它们没有固定的目标位置。相反,它们旨在测试和发现特定的行为或缺陷,而不关心目标位置。这些工具的目标不需要事先标记,或者在某些情况下无法进行预先标记。此外,它们的适应度度量标准可能不像第一类工具那么容易直观可见。通过优化适应度函数,这种类型的工具可以自动达到目标并揭示缺陷行为。
2.3.3 研究进展:
原文这部分研究进展并不是从类别展开,而是从技术流程展开。DGF技术流程大概有三个主要部分:目标设定、适应性度量、模糊测试主框架,作者分别从这几个方面介绍了目前的研究现状。
1)目标设定。也就是确定测试目标是达到目标位置还是检测目标行为,同时,设定一些标签,说简单点就是高速公路路牌,到达目的地还有100km这种。
倾向于利用目标位置——目标可以是源代码,也可以是编译后的二进制。需要注意的是,“位置” 与 “行为”相比来说更精确,需要一个比行为更准确的信息,如源代码的行数、二进制的虚拟内存地址来表示精确的位置。
利用目标位置的方法首先需要从源代码和二进制中找到能够符合测试目标的位置,手动是不可能的这辈子都不可能的,那这个位置的确定确实很看人工经验啊,那第一种方法就来了,就用人工经验辅助以下,比如利用github上的提交日志、CVE官网的漏洞描述、漏洞补丁的位置、仙人们炼丹炼好的深度学习模型等等,来帮助识别源代码和二进制中的 vulnerable function 、关键位置、语法标记、健全性检查以修补程序相关的区域。
研究人员一看哦哟这光收集数据就够喝一壶的,还不够自动化,那咋办,那第二种方法就来了————使用静态分析的方法,寻找待测程序的可能的危险区域,比如AFLGO使用LLVM Pass标注源代码中潜在的危险区域,又如很多基于深度学习的方法识别二进制程序可能存在漏洞位置。
倾向于利用目标行为——行为的粒度就比位置粗太多了,行为指的是程序运行时,系统上表现出实时程序参数,如内存使用率、程序操作行为序列组合等
2)适应性度量。为了达到目标位置或检测目标行为所设立的一个自适应度量标准,通过不断参考矩阵的数值来判断现在的模糊测试状态离目标达到还差多少,请注意,这里可以是多少距离,也可以是多少相似度,所以我没给出具体的名词。
基于距离的度量
基于距离的度量,简单的说,找到程序中的潜在危险的位置,然后模糊测试构成中计算到这个位置的距离,依据距离不断调整测试用例。
距离度量标准的一个缺点是它仅关注最短距离,因此在存在多条达到相同目标的路径时,可能会忽略较长的选项,导致结果的不一致性。另一个缺点是在基本块级别计算距离时需要相当长的时间。对于某些目标程序,用户报告称,仅计算距离文件可能需要数小时,这是一个相当大的时间成本。
代表作品有:
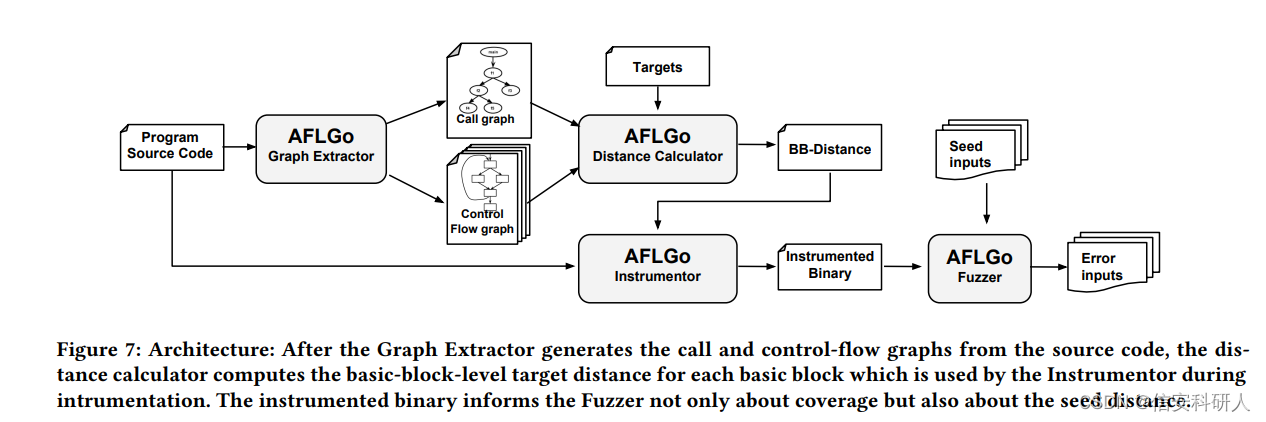
AFLGo方法: AFLGo使用源代码在编译时进行仪器化,并通过计算程序单元测试(PUT)的调用和控制流图中边的数量来计算到目标基本块的距离。然后在运行时,它汇总每个已执行的基本块的距离值,以计算平均值来评估种子。它根据距离对种子进行优先排序,偏向于距离目标更近的种子。
TOFU方法: TOFU的距离度量标准定义为达到目标所需的正确分支决策数量。
RDFuzz方法: RDFuzz将距离与基本块的执行频率结合起来,以对种子进行优先排序。
UAFuzz方法: UAFuzz使用距离度量标准来表示导致目标函数的调用链,这些链更有可能包含分配和释放内存函数,以检测复杂的行为Use-After-Free漏洞。
AFLChurn方法: AFLChurn不同于传统距离计算,它为基本块分配了数值权重,根据基本块的最近更改或更改频率来确定权重。
WindRanger方法: WindRanger在计算距离时考虑了偏离基本块(即,执行跟踪开始偏离目标位置的基本块)。
基于相似度的度量
相似度是某种度量标准的当前状态与目标状态之间的重叠程度,这种度量标准包括漏洞跟踪的长度以及已覆盖的位置、已覆盖的操作或已覆盖的函数的数量。相似度度量标准用于确定种子在多大程度上与期望状态相符,从而用于优先排序种子或评估它们的适应性。
与基于距离的替代方法相比,基于相似度的度量标准更能处理多目标拟合。此外,相似度度量标准可以在相对较高的层次提取,以提高整体效率,而距离度量标准则通常在基本块级别测量,可能引入相当大的开销。
代表作:hawkeye、LOLLY、Berry
漏洞预测模型
研究人员使用漏洞预测模型来确定种子达到目标的概率。这些模型通常基于深度学习,可以预测函数的易受攻击概率,并为易受攻击函数中的每个基本块分配静态易受攻击分数以度量易受攻击的概率。然后,对于每个输入,将执行路径上所有基本块的静态易受攻击分数的总和用作适应性分数,以优先选择具有较高分数的输入。
基于概率的度量标准可以结合种子优先排序和目标识别,从而引导模糊测试朝着潜在易受攻击的位置进行,而无需依赖源代码。使用深度学习模型,基于概率的度量标准可以扩展到目标属性,包括除崩溃之外的其他漏洞类型、信息泄露、攻击利用以及不同的资源使用情况。此外,深度学习方法已被证明能够同时检测多种类型的漏洞。然而,目前的一个主要弱点是准确性在一定程度上受到限制。
代表作:
TAFL提取PUT的语义度量,并使用静态语义度量来标记包括敏感、复杂、深层和难以达到的区域,这些区域具有更高的可能性包含漏洞,然后加强对这些区域的模糊测试。Joffe使用神经网络生成的崩溃概率来引导模糊测试,将其重点放在容易崩溃的执行上。
其他
Online Static Look Ahead分析: W¨ustholz等人使用在线静态前瞻分析来确定一个路径前缀,对于该前缀的所有后缀路径都不能达到目标位置。然后,他们通过策略性地调度模糊测试的能量来强调可能达到目标位置的路径前缀。
Keypoint Coverage: KCFuzz将路径到目标的父节点定义为关键点(keypoints),并使用关键点覆盖来指导模糊测试。
CAFL: CAFL旨在满足一系列约束,而不仅仅是到达一组目标位置。它将约束的距离定义为给定种子满足约束的程度,并按照满足程度较高的种子的顺序来优先选择。
AFL-HR和HDR-Fuzz: 这两种方法采用了面向漏洞的适应性度量标准,称为"headroom",该度量标准指示测试输入在给定漏洞位置上能够多接近暴露难以显现漏洞(例如缓冲区或整数溢出)的程度。
PERFFUZZ: PERFFUZZ使用所有程序位置的执行计数的新极值作为反馈,用于生成病态输入。
多维度度量标准: 定制的适应性度量标准还可以同时考虑多个维度,包括基本代码覆盖率、块权重、状态转换数量、执行时间、异常计数等。
非功能性属性: 非功能性属性,如内存使用和机器人车辆的控制不稳定性,也可以用于指导模糊测试。
3)模糊测试主框架。DGF的适应性度量相当于大脑,模糊测试主框架相当于肢体,大脑决定下一次模糊测试的方向,当然肢体也很重要,作者这里提出了一些优化的方式。
输入优化
这些方法和技术旨在提高种子输入的质量,从而更有效地引导定向灰盒模糊测试,减少不必要的测试开销,并增加发现漏洞的可能性。选择合适的输入优化方法取决于具体的测试需求和上下文。
代表作:
FuzzGuard: FuzzGuard采用基于深度学习的方法,在对输入进行执行之前预测和过滤掉无法到达目标的输入,从而节省了时间,可以用于实际执行。
BEACON: BEACON使用轻量级静态分析来剪枝不可行的路径(即在运行时无法到达目标代码的路径),可以拒绝在模糊测试期间执行的超过80%的路径。
种子优先级
与度量标准紧密相关,如基于距离的方法通过计算程序单元测试(PUT)的调用和控制流图中边的数量,来计算到目标基本块的距离,这类方法旨在将模糊测试的焦点放在距离目标最近的地方。
基于相似度的方法将种子覆盖控制流图上的目标边的能力作为度量标准来评估种子。这些方法通过增加种子与目标之间的相似性来提高测试的效果。
基于预测模型的方法依赖于带属性的控制流图,用于表示二进制程序并提取用于深度学习的特征。这些方法通过深度学习来优化种子的选择,以更好地接近目标。
能量分配
在选择种子后,最接近其目标的种子将获得更多的模糊测试机会,这通过分配更多的能量,即通过变异它们来生成更多输入。虽然AFL使用执行跟踪特性(如跟踪大小、被测程序执行速度和在模糊测试队列中的顺序)来进行能量分配,但大多数定向灰盒模糊测试工具使用模拟退火算法来分配能量。
模拟退火算法: 与传统的随机漫步调度不同,模拟退火算法以一定概率接受比当前解更差的解决方案,因此可以跳出局部最优解并达到全局最优解。AFLGo首次使用基于模拟退火的能量调度,逐渐为距离目标更近的种子分配更多的能量,同时减少远离目标的种子的能量。Hawkeye在模拟退火中添加了优先级,允许更接近目标的种子首先进行变异。AFLChurn提出了一种基于蚁群算法的字节级能量调度,可以为生成更“有趣”的输入的字节分配更多能量。LOLLY和Berry使用温度阈值来优化基于模拟退火的能量调度,以协调探索和利用阶段的冷却计划。在探索阶段,冷却计划随机变异提供的种子以生成许多新输入,而在利用阶段,它从具有更高序列覆盖率的种子生成更多新输入,类似于传统的梯度下降算法。
粒子群算法: GREYHOUND还采用了自定义的生成式粒子群算法,这更适用于协议模型的非线性和随机行为
变异调度
优化变异策略是改进定向灰盒模糊测试的一种可行方法。合理的变异器调度可以通过改进种子变异的精度和速度来增强输入的定向性。一种可行的方法是首先将变异器分类为不同的粒度,例如粗粒度和细粒度,然后根据实际的模糊测试状态动态调整它们。
粗粒度和细粒度变异器: 粗粒度变异器用于在变异过程中更改大块字节,以将执行引导到“vulnerable的函数”,而细粒度变异器只涉及少量字节级别的修改、插入或删除,以监控“关键变量”。当一个种子可以到达目标函数时,fuzzer 会降低粗粒度变异的机会。一旦种子达到目标,细粒度变异的时间增加,而粗粒度变异减少。在实践中,变异器的调度通常由经验值来控制。
一些研究观察到了两个现象:(1) 粗粒度变异器在路径增长方面优于细粒度变异器;(2) 使用多种变异提供了比单个变异更好的性能。
变异操作
对测试用例的变异操作的优化能带来良好的效果提升,而基于数据流分析(如污点分析)的方法是可以反应或显示变异操作对模糊测试器生成的输入的影响,很多工作利用这种方式检验变异出的测试用例的效果,在此基础上进行优化。
-
RDFuzz: RDFuzz利用了扰动检查方法来识别和保护“距离敏感内容”(distance-sensitive content),即保持输入和目标之间距离的关键内容。一旦这些内容被改变,距离将变得更大。在变异过程中保护这些内容可以更有效地接近目标代码位置。
-
UAFL: UAFL采用信息流分析来识别输入和条件语句中的程序变量之间的关系。它将更有可能改变目标语句值的输入字节视为具有更高的“信息流强度”,并为它们分配更高的变异可能性。信息流强度越高,该字节对变量值的影响越大。
-
SemFuzz: SemFuzz通过反向数据流分析来跟踪关键变量依赖的内核函数参数。这有助于更好地理解关键变量和输入之间的关系。
-
TIFF: TIFF通过基于类型的变异来推断输入类型,以增加触发内存损坏漏洞的概率。它还利用内存中的数据结构识别来识别应用程序使用的每个内存地址的类型,并使用动态污点分析来映射输入字节最终存储在哪些内存位置
2.4 Q4、这些技术有什么缺陷?可以通过哪些方法弥补这些缺陷?
2.4.1 寻找目标位置而付出额外计算资源的辅助分析方法会带来较大的性能消耗
解决方法:
-
将重要的与执行无关的计算从运行时移到编译时: 例如,AFLGo将大部分图解析和距离计算移动到编译时的仪器化阶段,以换取运行时的效率。这种编译时的开销在多次测试同一个被测试程序时可以节省。
-
在执行之前过滤掉无法达到目标的输入: 例如,FuzzGuard采用基于深度学习的方法,而BEACON使用轻量级静态分析来提前找到这些无法达到目标的不可行输入,这可以在模糊测试过程中节省超过80%的路径执行。
-
使用更轻量级的算法: 例如,AFLChurn利用轻量级的蚁群算法代替昂贵的污点分析来找到“有趣的字节”并实现字节级别的能量调度。
-
利用并行计算: 例如,HDR-Fuzz利用另一个核心来并行运行AddressSanitizer,并提供指导以增强定向性。还可以采用大规模并行模糊测试来进一步提高效率。
2.4.2 种子平权不等于平等
目前大多数定向灰盒模糊测试工具使用等权度量标准,将不同的分支跳转视为具有相等的重要性,忽略了它们具有不同的概率。这可能导致模糊测试的性能受到偏差影响。
解决方法:
通过考虑分支跳转的概率来构建加权的适应度度量标准,从而更准确地考虑了不同分支跳转的重要性,提高了定向模糊测试的性能。这可以通过蒙特卡洛方法轻松估计分支概率。
而使用概率评估目标可达性可能会引入运行时开销。为了减轻性能损失,可以采用区间采样和定制数据结构等方法,加速概率计算和跳转统计元数据的存储和访问,以平衡时间和空间复杂性。
2.4.3 基于距离的适应性度量可能因为只关注最短路径而存在全局最优解的差异
文章给了个例子:

在这个控制流图片段中,节点K和O是目标节点。对于正在测试的三个种子,一个执行路径A→B→D→G→K,一个执行路径A→C→E→I→M→N→O,最后一个执行路径A→C→E→H→L。
根据B¨ohme等人定义的距离公式,计算了这三条路径到两个目标的每个节点的谐波距离-这些距离在图中标记出来。三个种子的全局距离分别为:
dABDGK = (4/3 + 3 + 2 + 1 + 0)/5 ≈ 1.47,dACEIMNO = (4/3 + 3/4 + 2 + 3 + 2 + 1 + 0)/7 ≈ 1.44,和dACEHL = (4/3 + 3/4 + 2 + 1)/4 ≈ 1.27。
由于dACEHL是三者中最小的,应该优先考虑路径A→C→E→H→L。然而,这是不合理的,因为路径A→B→D→G→K经过目标节点K,而路径A→C→E→I→M→N→O经过目标O,但路径A→C→E→H→L不会到达任何目标。直观地说,由于路径A→C→E→H→L远离目标,不应优先考虑。当存在多个目标时,定向模糊测试的有效性会受到影响,因为寻找全局最短距离存在不一致性。
解决方法:
为了避免这种差异,必须考虑到达目标的所有潜在路径。为了解决这个问题,Hawkeye使用基于轻量级静态分析的“相邻函数距离增强”,根据生成的调用图来增强由调用者和被调用者之间的直接调用关系定义的距离。
协调多个目标的另一种策略是将目标分开。对于每个种子,只选择所有目标的最小距离作为种子距离,并根据这个最小距离对种子进行排序。这样做的效果是消除了偏向全局最优解的可能性,但代价是增加了达到特定目标所需的时间。
2.4.4 探索新路径和路径深度利用之间的平衡
一方面,需要更多的探索来提供足够的信息供利用;另一方面,过多的探索会占用许多资源并延迟利用。难以确定探索阶段和利用阶段之间的界限以实现最佳性能。
大多数定向灰盒模糊器,如AFLGo,采用固定的探索阶段和利用阶段划分。时间预算是在测试配置中预先设置的。这种方案是初步的,因为分割点是固定的,依赖于人的经验。由于每个PUT都不同,这种固定的划分不太适应。一旦探索阶段让位于利用阶段,即使由于路径不足而导致定向性能不佳,也无法回头。
下图展现了AFLGO不同探索和利用阶段划分比例下的效果,实验时间一共是24小时,那么AFLGO-1表示1小时探索和23小时的利用。达到最小距离的时间越短越好,可以看出AFLGO-16的效果最好

这个很看人工经验滴,目前就RDFuzz做了这方面的工作。
2.4.5 大多工作面向源代码测试,针对二进制的工作很少
原因:开销大,很多基于仿真的方法效率太低;收集目标信息困难;往二进制里面打标签很困难。
解决方法:对于二进制代码级别的目标识别和标记问题,可以利用基于机器学习的方法和启发式二进制比对方法来自动识别易受攻击的代码。也可以基于硬件辅助的方法如InteL PT。
2.5 Q5、定向模糊测试未来的研究方向?
2.5.1 寻找多目标之间的关系来优化DGF
DGF会探索多个目标,举个例子,假如DGF被设置成挖掘UAF漏洞,源代码中有多个区域是UAF漏洞,如果这些目标区域之间没有关系,可以通过权重分配来区分重要性,但如果有关系,如其中两个UAF区域是前后条件相关的,找出这俩区域之间的关系能带来fuzzer的效率提升。
例如:UAFL 在寻找使用后释放漏洞时考虑了操作序列的顺序。这是因为,要触发此类行为复杂的漏洞,不仅需要覆盖单个边,还需要按特定顺序遍历一些较长的边序列。这种方法可以扩展到检测语义错误,例如双重释放和API误用。Berry 通过执行上下文(即到达目标序列中的节点所需的必要节点)增强了目标序列。类似地,KCFuzz 将通往目标的路径中的父节点视为关键点进行覆盖。CAFL 将通往目标的路径上的数据条件视为约束(更像是一种子目标),并驱动种子以满足这些约束,最终达到目标。
作者建议考虑这些关系:
-
空间关系:即执行树上目标的相对位置。考虑两个目标之间的关系,包括它们是否占据相同的分支,共享执行的级别以及它们的相对优先级(如果有的话)。
-
状态关系:对于涉及程序状态的目标,考虑它们在状态空间中的位置。例如,两个目标是否共享相同的状态,以及两个状态是否可以在状态转换图上相互转换。
-
交错关系:对于多线程程序,线程调度也会影响不同线程中事件的执行顺序。在相同线程交错下可以达到的目标在交错空间中应该具有密切关系。
2.5.2 做一个多维度的适应度度量标注
当前的模糊测试方法主要关注路径级别的覆盖率,例如最大化整体路径覆盖率或达到特定代码部分,这忽略了一个事实,即即使漏洞代码被执行,某些漏洞可能不会被触发或显现。例如,仅当缓冲区访问指针指向缓冲区之外时,才会在缓冲区溢出漏洞的访问位置显示溢出漏洞。类似地,仅当递增的变量具有足够大的值时,才会在程序位置上观察到整数溢出漏洞。为了检测这种“难以显现”的漏洞,必须将适应度度量扩展为多维度,例如状态空间。
实际上,探索复杂的状态机是困难的,大多数基于模糊测试的方法只有在执行特定代码时才会取得进展,忽略了状态机的更新,并且不会进一步模糊相应的测试输入。然而,某些漏洞可能不会在每次访问程序点时都显现。只有达到漏洞点并具有正确状态的某些执行才会显示出漏洞行为。
为了暴露这种漏洞,需要的输入不仅需要到达漏洞位置,还需要匹配漏洞状态。AFL-HR 定义了一个从0到1的适应度度量,称为"headroom",用于指示测试输入在给定漏洞位置附近多大程度上可以暴露潜在漏洞。例如,对于缓冲区溢出漏洞,"headroom" 被定义为缓冲区访问指针所指位置与缓冲区末尾之间的最小距离,除以缓冲区的大小。因此,状态空间是一个值得考虑的维度,作为适应度度量的一部分,同时也要考虑漏洞位置的可达性。
2.5.3 多指标的同时优化
就是说,单独优化某一项指标如增加覆盖率没有同时优化多个指标有效。
2.5.4 应用场景的多样化
比如应用到内核、多个类型漏洞的检测、应用到智能汽车、应用到无人机等等
三 思考
DGF本身的技术空间广且深,相比传统的模糊测试多出了一个适应性度量标准,可研究的点很多很多。同时,DGF的应用在软测、网安领域也是比较具备经济效益的,等等因素是这几年DGF研究井喷的原因。
模糊测试本身的优化一般分为两个方向,一种是算法本身,一种是应用场景。DGF算法本身已经有很多的优化了,而针对不同应用场景的工作还比较少,这是未来可以研究的一个不冷不热的点。