数据采集与融合技术实践第四次作业
作业一
要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
Gitee文件夹链接:https://gitee.com/hong-songyu/crawl_project/tree/master/%E4%BD%9C%E4%B8%9A4/4.1
代码:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import sqlite3
import time
class myspider:
header = {
"User-Agent": "Mozilla/5.0(Windows;U;Windows NT 6.0 x64;en-US;rv:1.9pre)Gecko/2008072531 Minefield/3.0.2pre"
}
def start(self, url):
chrome_options = Options()
chrome_options.add_argument("——headless")
chrome_options.add_argument("——disable-gpu")
self.driver = webdriver.Chrome(options=chrome_options)
self.count = 0
self.num = 0
try:
self.con = sqlite3.connect("stock.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("drop table stock")
except:
pass
try:
sql = "create table stock(count varchar(256) ,num varchar(256),stockname varchar(256),lastest_price varchar(64),ddf varchar(64),dde varchar(64),cjl varchar(64),cje varchar(32),zhenfu varchar(32),top varchar(32),low varchar(32),today varchar(32),yestd varchar(32))"
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
self.driver.get(url)
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err)
def insertDB(self, count,num,stockname,lastest_price,ddf,dde,cjl,cje,zhenfu,top,low,today,yestd):
try:
sql = "insert into stock (count,num,stockname,lastest_price,ddf,dde,cjl,cje,zhenfu,top,low,today,yestd) values (?,?,?,?,?,?,?,?,?,?,?,?,?)"
self.cursor.execute(sql, (count,num,stockname,lastest_price,ddf,dde,cjl,cje,zhenfu,top,low,today,yestd))
except Exception as err:
print(err)
def showDB(self):
try:
con = sqlite3.connect("stock.db")
cursor = con.cursor()
print("count","num","stockname","lastest_price","ddf","dde","cjl","cje","zhenfu","top","low","today","yestd")
cursor.execute("select count,num,stockname,lastest_price,ddf,dde,cjl,cje,zhenfu,top,low,today,yestd from stock order by count")#sql语句获取数据
rows = cursor.fetchall()
for row in rows:
print(row[0], row[1], row[2], row[3], row[4],row[5], row[6], row[7], row[8], row[9],row[10], row[11], row[12])
con.close()
except Exception as err:
print(err)
def execute(self, url):
print("Starting......")
self.start(url)
print("Processing......")
self.process()
print("Closing......")
self.closeUp()
print("Completed......")
def process(self):
time.sleep(1)
try:
lis = self.driver.find_elements(By.XPATH,"//div[@class='listview full']/table[@id='table_wrapper-table']/tbody/tr")
time.sleep(1)
for li in lis:
time.sleep(1)
num = li.find_element(By.XPATH,".//td[position()=2]/a[@href]").text
stockname = li.find_element(By.XPATH,".//td[@class='mywidth']/a[@href]").text #在网页审查元素找到对应的右键Copy 可以查看具体位置
lastest_price = li.find_element(By.XPATH,".//td[position()=5]/span").text
ddf = li.find_element(By.XPATH,".//td[position()=6]/span").text #//tr[1]/td[6]/span
dde = li.find_element(By.XPATH,".//td[position()=7]/span").text #//*[@id="table_wrapper-table"]/tbody/tr[1]/td[7]/span
cjl = li.find_element(By.XPATH,".//td[position()=8]").text #//*[@id="table_wrapper-table"]/tbody/tr[1]/td[8]
time.sleep(1)
cje = li.find_element(By.XPATH,".//td[position()=9]").text #//*[@id="table_wrapper-table"]/tbody/tr[1]/td[9]
zhenfu = li.find_element(By.XPATH,".//td[position()=10]").text #//*[@id="table_wrapper-table"]/tbody/tr[1]/td[10]
top = li.find_element(By.XPATH,".//td[position()=11]/span").text #//./td[11]/span
low = li.find_element(By.XPATH,".//td[position()=12]/span").text #//tr[1]/td[12]/span
today = li.find_element(By.XPATH,".//td[position()=13]/span").text #//td[13]/span
yestd = li.find_element(By.XPATH,".//td[position()=14]").text #
time.sleep(1)
self.count = self.count + 1
count=self.count
self.insertDB(count,num,stockname,lastest_price,ddf,dde,cjl,cje,zhenfu,top,low,today,yestd )
nextPage = self.driver.find_element(By.XPATH,
"//div[@class='dataTables_wrapper']//div[@class='dataTables_paginate paging_input']//a[@class='next paginate_button']")
time.sleep(10)
self.num += 1
if (self.num < 2):
nextPage.click()
self.process()
except Exception as err:
print(err)
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
spider = myspider()
myspider().execute(url)
myspider().showDB()
结果:
Navicat可视化:
心得体会:
学习了如何用selenium模拟网站访问相对应的网页,对selenium库丰富的方法和功能有初步了解
作业二:
要求:熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
:Gitee文件夹链接:https://gitee.com/hong-songyu/crawl_project/tree/master/%E4%BD%9C%E4%B8%9A4/4.2
代码:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
from scrapy.selector import Selector
import sqlite3
def login(driver, username, password):
driver.get("https://www.icourse163.org/")
driver.maximize_window()
button = driver.find_element(By.XPATH,'//div[@class="_1Y4Ni"]/div')
button.click()
frame = driver.find_element(By.XPATH,
'/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div[1]/div/iframe')
driver.switch_to.frame(frame)
account = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input')
account.send_keys(username)
code = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]')
code.send_keys(password)
login_button = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a')
login_button.click()
driver.switch_to.default_content()
time.sleep(10)
def search_courses(driver, keyword):
select_course = driver.find_element(By.XPATH, '/html/body/div[4]/div[1]/div/div/div/div/div[7]/div[1]/div/div/div[1]/div/div/div/div/div/div/input')
select_course.send_keys(keyword)
search_button = driver.find_element(By.XPATH, '/html/body/div[4]/div[1]/div/div/div/div/div[7]/div[1]/div/div/div[2]/span')
search_button.click()
time.sleep(3)
wait = WebDriverWait(driver, 10)
element = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".th-bk-main-gh")))
html = driver.page_source
selector = Selector(text=html)
datas = selector.xpath("//div[@class='m-course-list']/div/div")
for i, data in enumerate(datas, start=1):
name = data.xpath(".//span[@class=' u-course-name f-thide']//text()").extract()
name = "".join(name)
schoolname = data.xpath(".//a[@class='t21 f-fc9']/text()").extract_first()
teacher = data.xpath(".//a[@class='f-fc9']//text()").extract_first()
team = data.xpath(".//a[@class='f-fc9']//text()").extract()
team = ",".join(team)
number = data.xpath(".//span[@class='hot']/text()").extract_first()
process = data.xpath(".//span[@class='txt']/text()").extract_first()
production = data.xpath(".//span[@class='p5 brief f-ib f-f0 f-cb']//text()").extract()
production = ",".join(production)
store_course_info(i, name, schoolname, teacher, team, number, process, production)
def store_course_info(i, name, school, teacher, team, number, process, production):
conn = sqlite3.connect('course.db')
cursor = conn.cursor()
cursor.execute('''CREATE TABLE IF NOT EXISTS mooc
(Id INT, cCourse TEXT, cCollege TEXT, cTeacher TEXT, cTeam TEXT, cCount INT, cProcess TEXT, cBrief TEXT)''')
cursor.execute("INSERT INTO mooc (Id, cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief) VALUES (?, ?, ?, ?, ?, ?, ?, ?)",
(i, name, school, teacher, team, number, process, production))
conn.commit()
conn.close()
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("——headless")
chrome_options.add_argument("——disable-gpu")
driver = webdriver.Chrome(options=chrome_options)
login(driver, '15880980287', 'Hsy102102146')
search_courses(driver, '大数据')
# 关闭浏览器
driver.quit()
Navicat可视化

心得体会:
多次失败后发现实现模拟登陆需要switch_to.frame跳转,然后再跳转回来,学习到了窗口的转换并对selenium爬去网页有了更深的认识
作业三
要求:掌握大数据相关服务,熟悉Xshell的使用完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
实时分析开发实战:
任务一:Python脚本生成测试数据
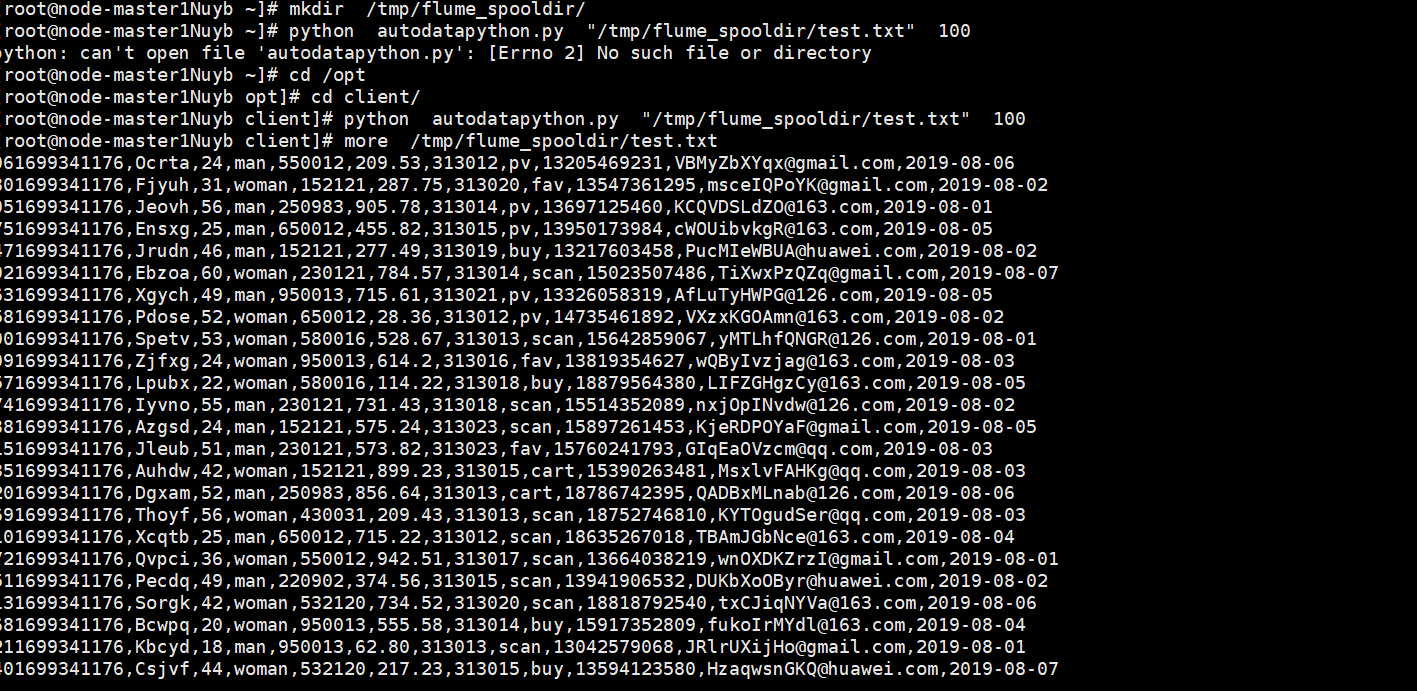
任务二:配置Kafka:

任务三: 安装Flume客户端

任务四:配置Flume采集数据

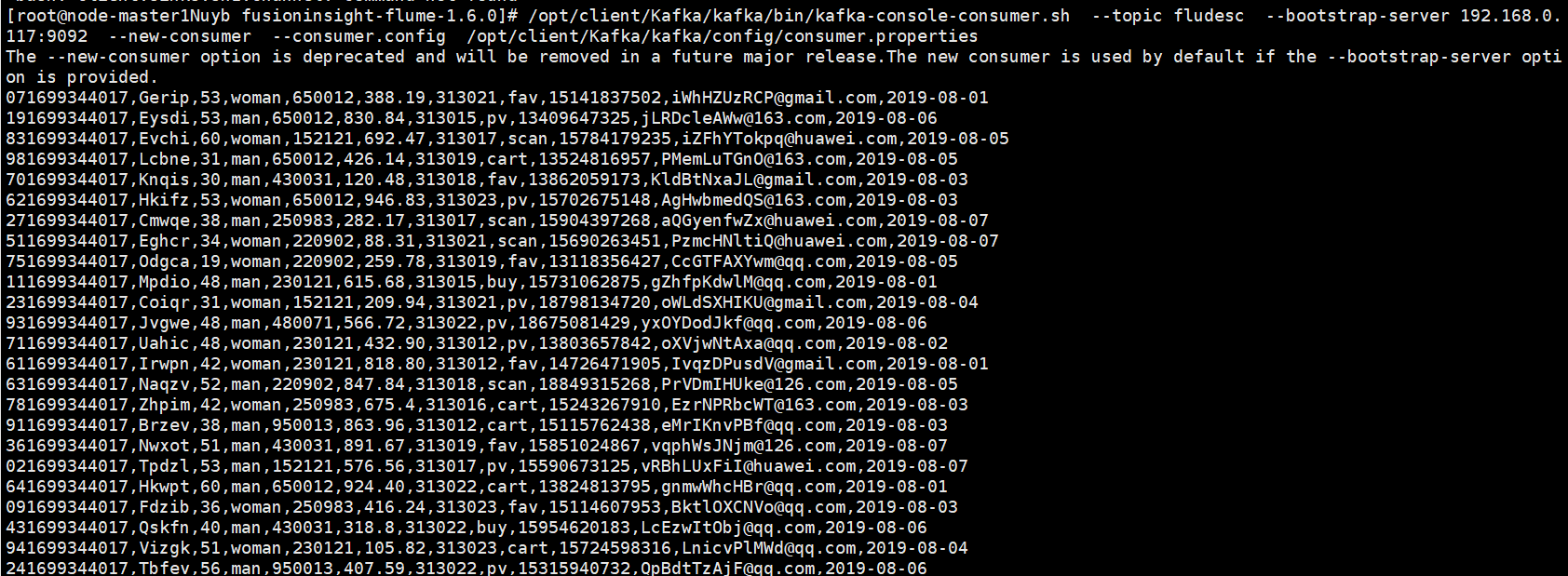
心得体会:
学习了华为云集群的部署和如何搭建Flume以及如何进行数据采集,了解到Flume的强大功能