用requests库的get()函数访问百度主页20次
import requests url = 'https://www.baidu.com' for i in range(20): response = requests.get(url) response.encoding = 'utf-8'#加编码方式,防止乱码 print(f"第{i+1}次访问") print(f'Response status: {response.status_code}') print(f'Text content length: {len(response.text)}') print(f'Content length: {len(response.content)}') print(response.text)
输出结果

创建html文件(文件名:test1.html,路径:D:\前端学习\其他练习\test1.html)
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</title> </head> <body> <h1>我的学号:11</h1> <h1>我的第一个标题</h1> <p id="first">我的第一个段落。</p> </body> <table border="1"> <tr> <td>row 1, cell 1</td> <td>row 1, cell 2</td> </tr> <tr> <td>row 2, cell 1</td> <td>row 2, cell 2</td> </tr> </table> </html>
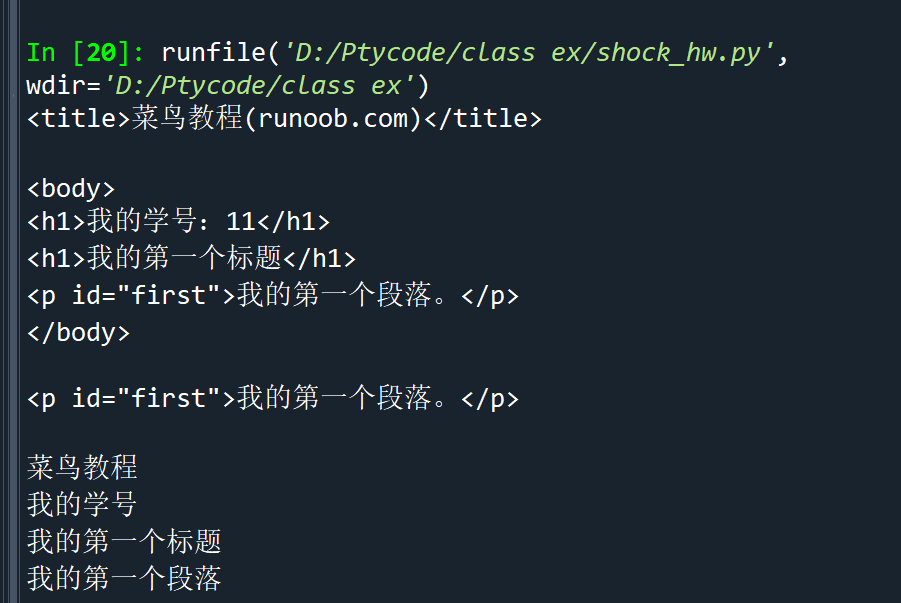
代码
import re from bs4 import BeautifulSoup import requests with open('D:\\前端学习\\其他练习\\test1.html', 'r', encoding='utf-8') as file: r = file.read() demo = BeautifulSoup(r,'html.parser') print(demo.title) print("") print(demo.body) print("") # 获取id为"first"的标签对象 first_tag = demo.find(id="first") # 打印标签对象 print(first_tag) print("") # 使用正则表达式匹配只包含中文字符的文本 pattern = re.compile('[\u4e00-\u9fa5]+') result = pattern.findall(demo.get_text()) # 打印只包含中文字符的文本 for text in result: print(text)
输出结果