实验六-分布式文件系统算法—MapReduce
一、实验目的
掌握 MapReduce 算法的设计与实现。
二、实验原理和内容
1.原理:
MapReduce 的核心思想是“分而治之”,也就是把一个大的数据集拆分成多
个小数据集在多台机器上并行处理。
一个大的 MapReduce 作业,首先会被拆分成多个 Map 任务在多台机器上并
行处理,每个 Map 任务通常运行在数据存储的节点上(也就是所谓的:计算向
数据靠拢)。这样计算和数据就可以放在一起运行,不需要额外的数据传输开销。
当 Map 任务结束后,会生成以<key,value>形式的许多中间结果。
然后,这些中间结果会被分发到多个 Reduce 任务在多台机器上并行执行,
具有相同 key 的<key,value>会被发送到同一个 Reduce 任务,Reduce 任务会对中
间结果进行汇总计算得到最后结果,并输出到分布式文件系统。
2.内容:
本实验要求进行“单词计数”,给一个文档,计算该文档中每一个单词出现的次数。
三、实验步骤
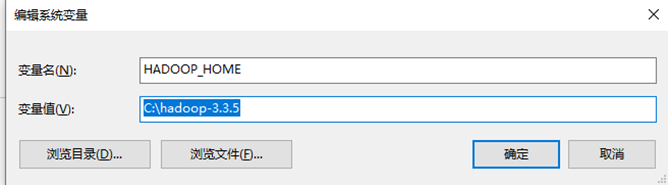
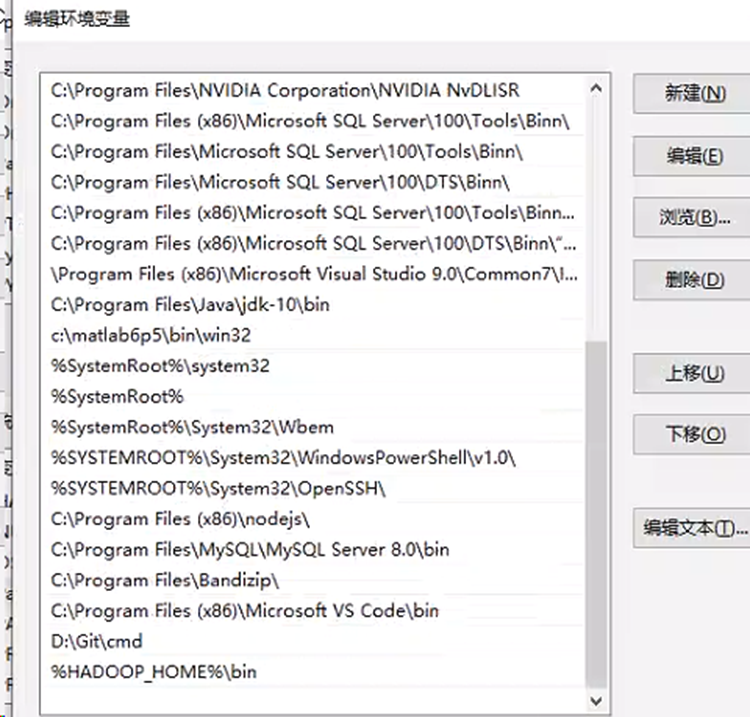
1.下载hadoop-3.3.4.tar.gz,然后添加环境变量,如图所示:
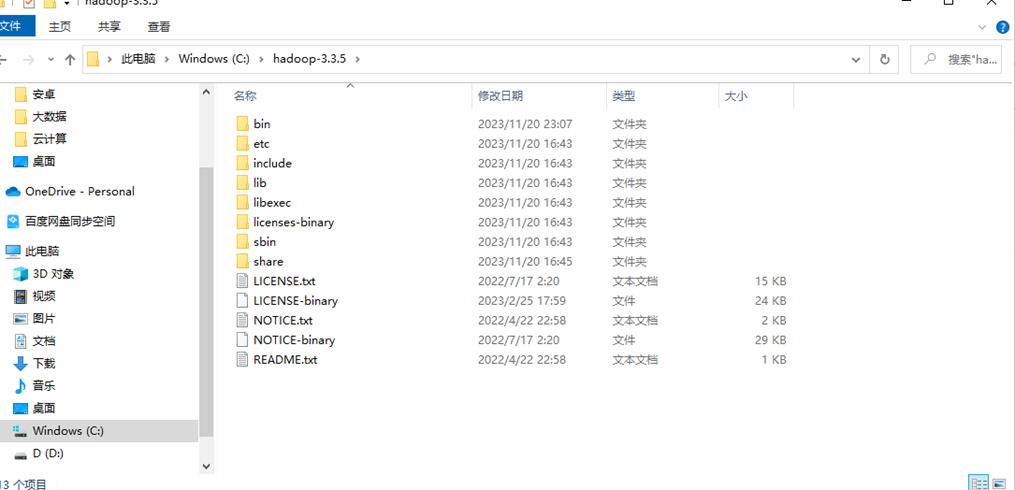
2.下载hadoop.dll和winutils.exe,把hadoop.dll放到A:\hadoop-3.3.5\bin中,如图所示:
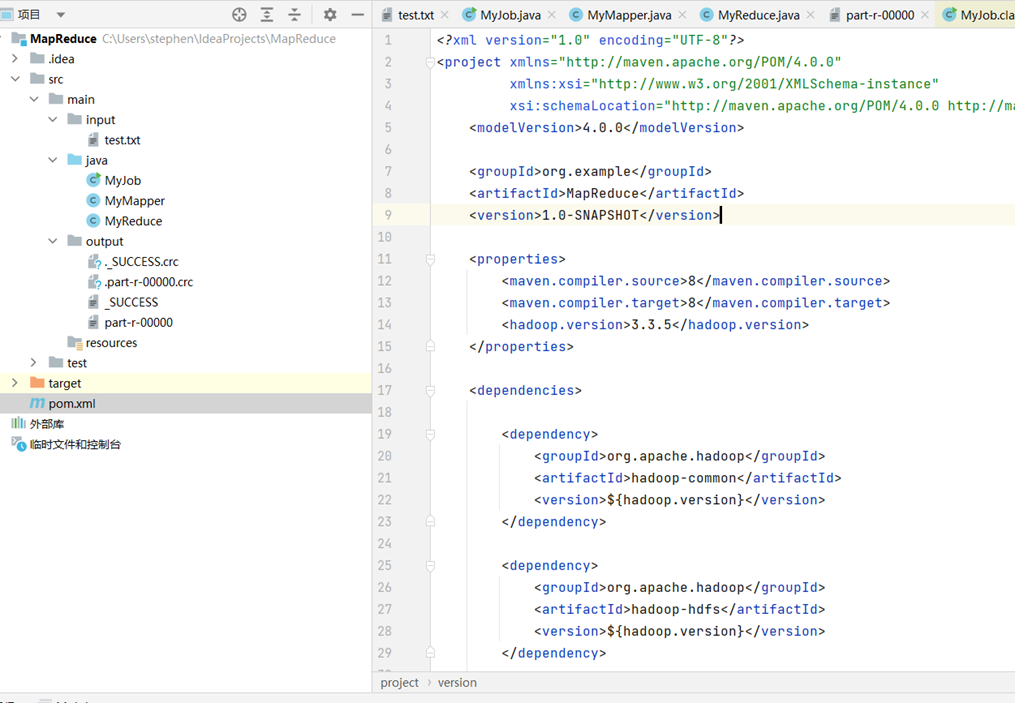
3.创建一个Maven项目,在pom.xml进行环境配置,如图所示:
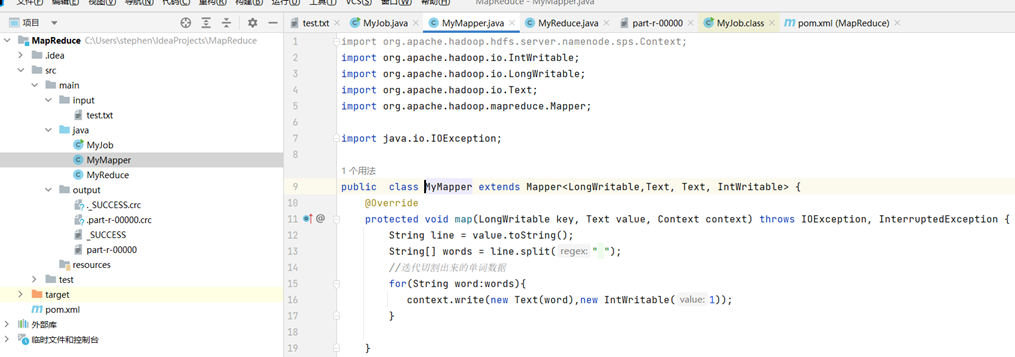
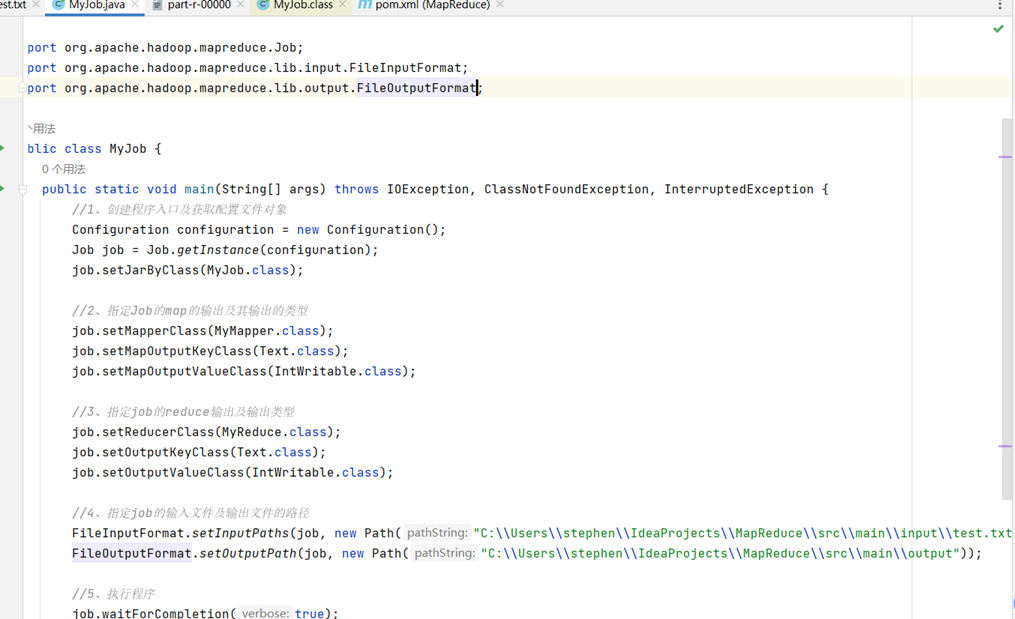
4.分别新建MyMapper、MyReduce、MyJob三个类,如图所示:
MyMapper类:
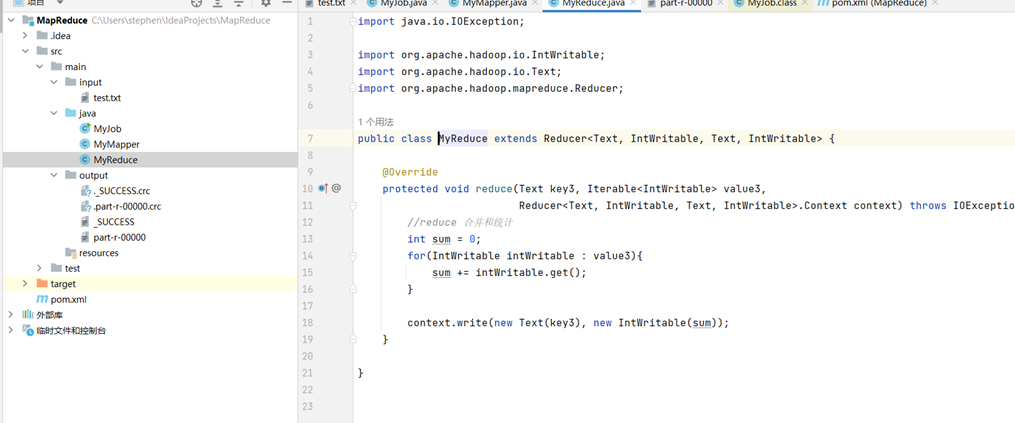
MyReduce类:
MyJob类:
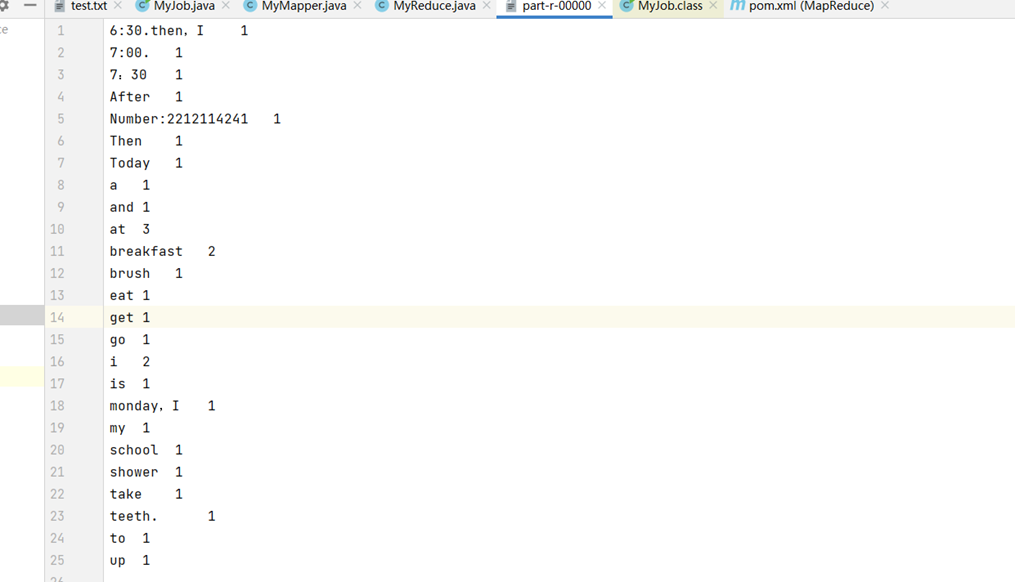
5.准备好测试数据,进行测试,如图所示:
测试数据:

运行结果: