实验05 Pandas数据读写
实验学时:2学时
实验类型:验证
实验要求:必修
一、实验目的
- 学会正确使用常见的I/O API函数。
- 解决文本文件、CSV文件、Excel文件、网页文件、数据库文件和JSON格式文件数据的读写问题。
二、实验要求
使用常见的I/O API函数(如:read_csv()、to_csv()、read_excel()、read_html()、read_json()、to_excel()、to_html()、to_json()函数)等知识在PyCharm中编写程序,解决文本文件、CSV文件、Excel文件、网页文件、数据库文件和JSON格式文件数据的读写问题。
三、实验内容
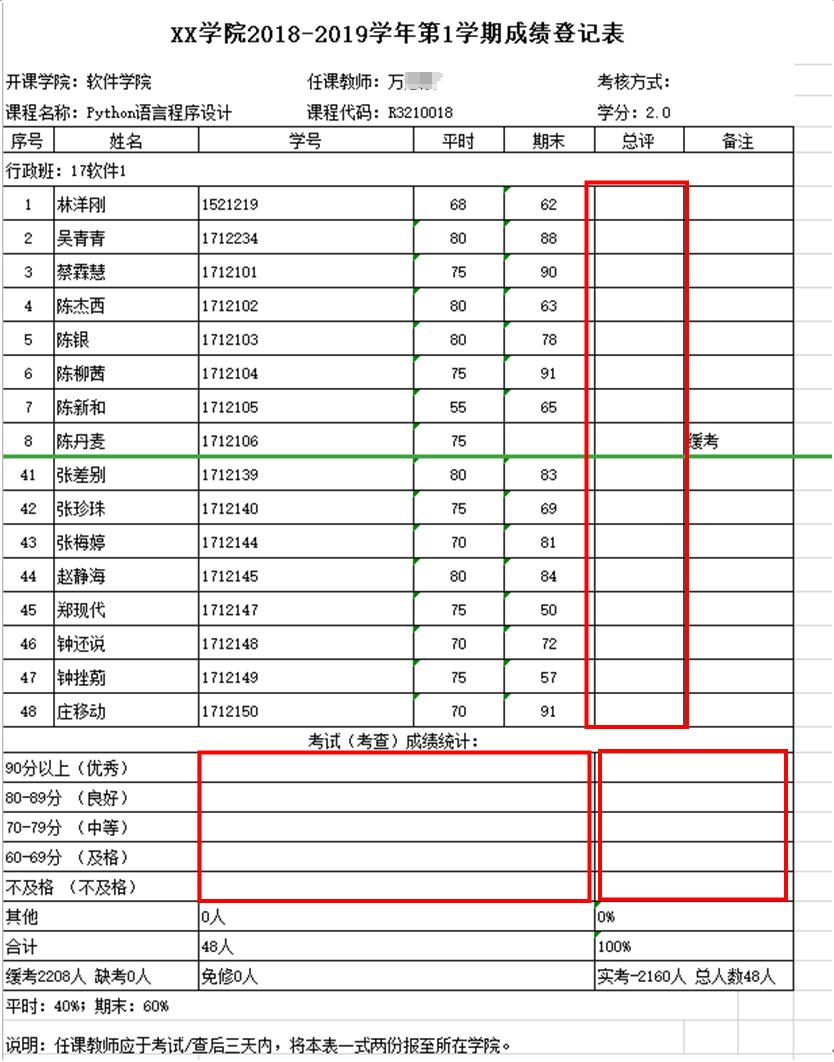
任务0. 向文件python0.xlsx中的红框中写入对应的数据(总评=平时0.3+期末0.7,缓考的同学期末成绩设为0)。用Python编写程序实现。
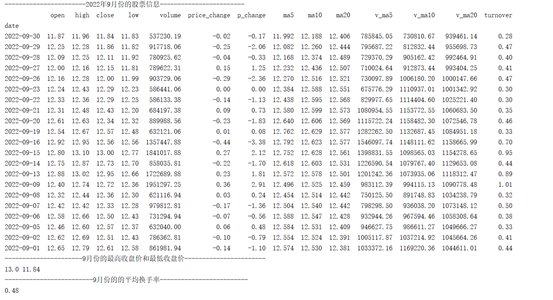
任务1.使用tushare模块,导入“中国平安”(股票代码为000001)实时股票信息。如下图所示。(1)只显示2023年9月份的数据;(2)统计2023年9月份的最高收盘价、最低收盘价及平均换手率。用Python编写程序实现。
任务2.将任务1中导入“中国平安”(股票代码为000001)的实时股票信息写入MySQL数据库的“zgpan”表中。用Python编写程序实现。
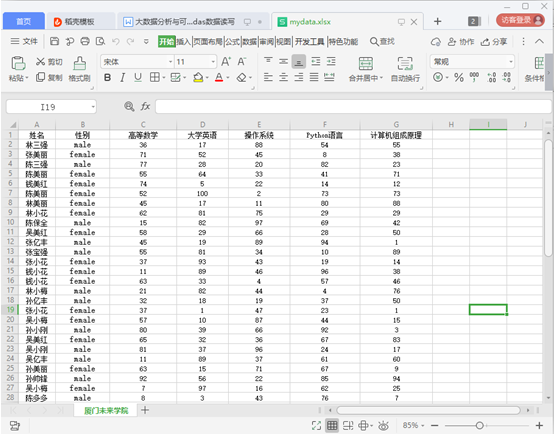
任务3.现有一个文件mydata.xlsx,需要将表格中的数据读出,生成DataFrame对象,然后将性别一列的” female ”改为”女” , ” male ”改为”男” ,之后将数据存入mydataOk.xls文件中。用Python编写程序实现。
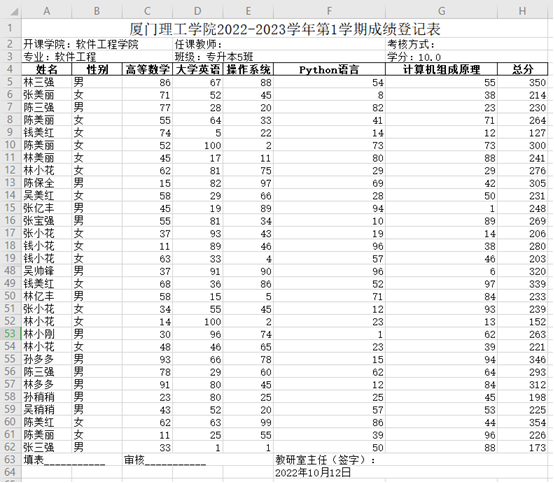
任务4. 在文件xmut.xlsx中生成10个班的成绩单(10个sheet)。用Python编写程序实现。
任务5. 读取文件mydataOk.xls的数据,写入到网页文件ok.html中(注:网页文件具有完整的框架)。用Python编写程序实现。
test5.py
import random
import numpy as np
import openpyxl as opx
from openpyxl.styles import Font, Alignment, Color, Border, Side
import pandas as pd
import tushare as ts
import datetime as dt
from sqlalchemy import create_engine
import xlwt
from openpyxl.utils.dataframe import dataframe_to_rows
from openpyxl import Workbook
pd.set_option('display.unicode.east_asian_width', True)
pd.set_option('display.max_rows', None)
zgpa = ts.get_hist_data('000001')
zgpa.index = pd.to_datetime(zgpa.index)
def task0():
data = pd.read_excel('python0.xlsx', header=3, usecols=(0, 1, 2, 4, 5), skiprows=0)
data = data.drop([0])
data = data.drop(np.arange(49, 61))
data = data.fillna(0)
data['总评'] = round(data['平时'] * 0.3 + data['期末'] * 0.7, 0)
print(data)
workbook = opx.load_workbook('python0.xlsx')
worksheet = workbook['sheet1']
for i, j in zip(range(6, 54), range(1, 49)):
worksheet['G' + str(i)] = data['总评'][j]
worksheet['G' + str(i)].font = Font(name='黑体', size=11, color=Color(indexed=53))
youxiu = len(data[data['总评'] >= 90])
lianghao = len(data[(data['总评'] >= 80) & (data['总评'] < 90)])
zhongdeng = len(data[(data['总评'] >= 70) & (data['总评'] < 80)])
jige = len(data[(data['总评'] >= 60) & (data['总评'] < 70)])
bujige = len(data[data['总评'] < 60])
qita = len(data[data['总评'].isnull()])
worksheet['C55'] = str('优秀') + '人'
worksheet['C55'].font = Font(name='黑体', size=12, color=Color(indexed=52))
worksheet['C56'] = str('良好') + '人'
worksheet['C56'].font = Font(name='黑体', size=12, color=Color(indexed=52))
worksheet['C57'] = str('中等') + '人'
worksheet['C57'].font = Font(name='黑体', size=12, color=Color(indexed=52))
worksheet['C58'] = str('及格') + '人'
worksheet['C58'].font = Font(name='黑体', size=12, color=Color(indexed=52))
worksheet['C59'] = str('不及格') + '人'
worksheet['C59'].font = Font(name='黑体', size=12, color=Color(indexed=52))
worksheet['C60'] = str('其他') + '人'
worksheet['C60'].font = Font(name='黑体', size=12, color=Color(indexed=52))
worksheet['G55'] = '{:.2%}'.format(youxiu / data['姓名'].size)
worksheet['G55'].font = Font(name='黑体', size=12, color=Color(indexed=52))
worksheet['G56'] = '{:.2%}'.format(lianghao / data['姓名'].size)
worksheet['G56'].font = Font(name='黑体', size=12, color=Color(indexed=52))
worksheet['G57'] = '{:.2%}'.format(zhongdeng / data['姓名'].size)
worksheet['G57'].font = Font(name='黑体', size=12, color=Color(indexed=52))
worksheet['G58'] = '{:.2%}'.format(jige / data['姓名'].size)
worksheet['G58'].font = Font(name='黑体', size=12, color=Color(indexed=52))
worksheet['G59'] = '{:.2%}'.format(bujige / data['姓名'].size)
worksheet['G59'].font = Font(name='黑体', size=12, color=Color(indexed=52))
worksheet['G60'] = '{:.2%}'.format(qita / data['姓名'].size)
worksheet['G60'].font = Font(name='黑体', size=12, color=Color(indexed=52))
l_side = Side(style='dashDot', color=Color(indexed=10))
r_side = Side(style='thin', color=Color(indexed=59))
t_side = Side(style='thin', color=Color(indexed=59))
b_side = Side(style='thin', color=Color(indexed=59))
for i in range(4, 63):
worksheet['D' + str(i)].border = Border(top=t_side, bottom=b_side)
worksheet['I' + str(i)].border = Border(top=t_side, bottom=b_side, right=r_side)
for i in range(55, 63):
worksheet['B' + str(i)].border = Border(top=t_side, bottom=b_side)
worksheet['E' + str(i)].border = Border(top=t_side, bottom=b_side)
worksheet['F' + str(i)].border = Border(top=t_side, bottom=b_side)
worksheet['H' + str(i)].border = Border(top=t_side, bottom=b_side)
workbook.save('python0.xlsx')
def display_year_month(year, month):
nine = zgpa.index[(zgpa.index.year == year) & (zgpa.index.month == month)]
df = zgpa.reindex(index=nine)
return df
def task1():
pd.set_option('display.width', None) # 显示全部列
pd.set_option('display.max_rows', None) # 全部显示行
# 9月份的日期--索引
print('2023年9月份的股票信息'.center(60, '-'))
df_2023_9 = display_year_month(2023, 9)
print(df_2023_9)
# 9月份的最高收盘价和最低收盘价
max_close = round(df_2023_9['close'].max(), 2)
min_close = round(df_2023_9['close'].min(), 2)
print('9月份的最高收盘价和最低收盘价'.center(60, '-'))
print(max_close, min_close)
# 9月份的平均换手率
turnover_mean = round(df_2023_9['turnover'].mean(), 2)
print('9月份的平均换手率'.center(60, '-'))
print(turnover_mean)
def task2():
# 获取中国平安(股票代码000001)的实时股票信息
zgpa = ts.get_realtime_quotes('000001')
# 将数据转换为DataFrame
df_zgpa = pd.DataFrame(zgpa)
# 建立到MySQL数据库的连接
db_username = 'root'
db_password = 'root123'
db_host = 'localhost'
db_name = 'bigdata'
engine = create_engine(f'mysql+pymysql://{db_username}:{db_password}@{db_host}/{db_name}')
# 将DataFrame写入MySQL数据库的"zgpan"表中
df_zgpa.to_sql('zgpan', engine, if_exists='replace', index=False)
print("数据已成功写入MySQL数据库的'zgpan'表中。")
def task3():
# 读取原始Excel文件
df = pd.read_excel('mydata.xlsx')
# 将性别列中的值替换为指定的值
df['性别'] = df['性别'].replace({'male': '男', 'female': '女'})
# 创建一个新的Excel文件
workbook = xlwt.Workbook(encoding='utf-8')
worksheet = workbook.add_sheet('Sheet1')
# 写入列名
for col, column_name in enumerate(df.columns):
worksheet.write(0, col, column_name)
# 写入数据
for row, data in df.iterrows():
for col, value in enumerate(data):
worksheet.write(row + 1, col, value)
# 保存Excel文件
workbook.save('mydatatask3.xls')
def task4():
# 创建一个Excel文件
wb = Workbook()
# 生成10个班的成绩单
for class_num in range(1, 11):
# 创建一个DataFrame来表示每个班的成绩单
data = {
'学生姓名': ['学生A', '学生B', '学生C', '学生D', '学生E'],
'成绩': [100,90,80,70,60]
}
df = pd.DataFrame(data)
# 创建一个新的sheet
sheet = wb.create_sheet(title=f'班级{class_num}')
# 将DataFrame写入新的sheet
for r_idx, row in enumerate(dataframe_to_rows(df, index=False, header=True), 1):
for c_idx, value in enumerate(row, 1):
cell = sheet.cell(row=r_idx, column=c_idx, value=value)
# 删除默认的sheet
del wb['Sheet']
# 保存Excel文件
wb.save('xmut.xlsx')
print("已生成包含10个班成绩单的Excel文件:xmut.xlsx")
def task5():
# 读取Excel文件
df = pd.read_excel('mydatatask3.xls')
# 生成HTML表格
html_table = df.to_html(index=False)
# HTML框架
html_template = f"""
<!DOCTYPE html>
<html>
<head>
<title>My Data</title>
</head>
<body>
<h1>My Data</h1>
{html_table}
</body>
</html>
"""
# 将HTML内容写入网页文件
with open('ok.html', 'w', encoding='utf-8') as f:
f.write(html_template)
print("数据已成功写入网页文件 'ok.html' 中。")
if __name__ == '__main__':
task0()
task1()
task2()
task3()
task4()
task5()